一、概述
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接
受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应,从
而实现集群中类似Master/Slave管理模式
特点:
A、Zookeeper是为别的分布式程序服务的
B、Zookeeper是简单的,其核心是一个精简的文件系统(实际上是分布式文件系统;只要有半数以上节点存活,zk就能正常服务)。它支持
一些简单的操作和一些抽象操作,例如,排序和通知。
C、Zookeeper所提供的服务涵盖:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统一名称服务……
D、虽然说可以提供各种服务,但是zookeeper在底层其实只提供了两个功能:
管理(存储,读取)用户程序提交的数据;
为用户程序提供数据节点监听服务;
E、Zookeeper是富有表现力的(应用非常广泛),SOA架构中的服务管理、分布式队列等
F、Zookeeper是高可用的。支持集群模式,可以很容易的解决单点故障问题。
G、Zookeeper采用松耦合交互方式。不同进程间的交互不需要了解彼此,甚至可以不必同时存在,某进程在zookeeper中留下消息后,该进
程结束后其它进程还可以读这条消息。
H、Zookeeper是通用分布式协议的资源库。 实现了一个关于通用协调模式的开源共享存储库,这能使开发者免于编写这类通用协议。
Zookeeper=文件系统+通知机制
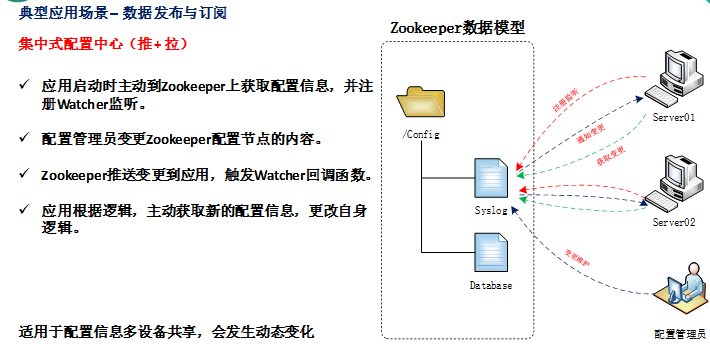
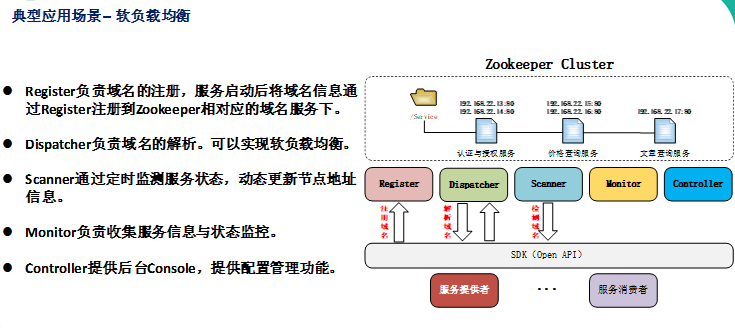
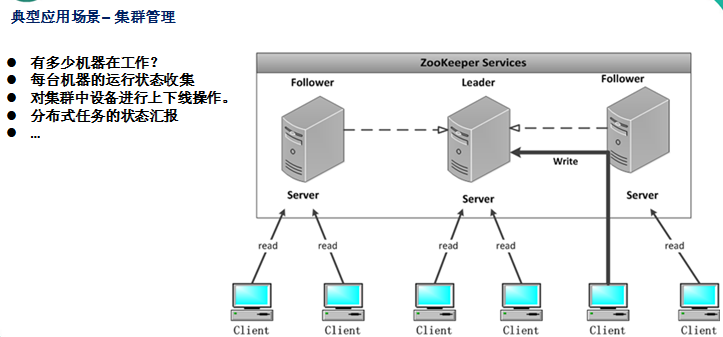
应用场景:
分布式消息同步和协调机制、服务器节点动态上下线、统一配置管理、负载均衡、集群管理等。
二、安装
分布式安装部署
0)集群规划
在hadoop2、hadoop3和hadoop4三个节点上部署Zookeeper。
1)解压安装
(1)解压zookeeper安装包到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
(2)在/opt/module/zookeeper-3.4.10/这个目录下创建data/zkData
mkdir -p data/zkData
(3)重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg
2)配置zoo.cfg文件
(1)具体配置
dataDir=/opt/module/zookeeper-3.4.10/data/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(2)配置参数解读
Server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
3)集群操作
(1)在/opt/module/zookeeper-3.4.10/data/zkData目录下创建一个myid的文件
touch myid
添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
(2)编辑myid文件
vi myid
在文件中添加与server对应的编号:如2
(3)拷贝配置好的zookeeper到其他机器上
scp -r zookeeper-3.4.10/ root@hadoop3.atguigu.com:/opt/app/
scp -r zookeeper-3.4.10/ root@hadoop4.atguigu.com:/opt/app/
并分别修改myid文件中内容为3、4
(4)分别启动zookeeper
[root@hadoop2 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop3 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop4 zookeeper-3.4.10]# bin/zkServer.sh start
(5)查看状态
[root@hadoop2 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/…/conf/zoo.cfg
Mode: follower
[root@hadoop3 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/…/conf/zoo.cfg
Mode: leader
[root@hadoop4 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/…/conf/zoo.cfg
Mode: follower
配置参数解读:
解读zoo.cfg 文件中参数含义
1)tickTime:通信心跳数,Zookeeper服务器心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
2)initLimit:LF初始通信时限
集群中的follower跟随者服务器(F)与leader领导者服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
投票选举新leader的初始化时间
Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。
Leader允许F在initLimit时间内完成这个工作。
3)syncLimit:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,
Leader认为Follwer死掉,从服务器列表中删除Follwer。
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。
如果L发出心跳包在syncLimit之后,还没有从F那收到响应,那么就认为这个F已经不在线了。
4)dataDir:数据文件目录+数据持久化路径
保存内存数据库快照信息的位置,如果没有其他说明,更新的事务日志也保存到数据库。
5)clientPort:客户端连接端口
监听客户端连接的端口
三、选举机制
1)半数机制:集群中半数以上机器存活,集群可用。所以zookeeper适合装在奇数台机器上。
2)Zookeeper虽然在配置文件中并没有指定master和slave。但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通过内部的选举机制临时产生的
3)以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
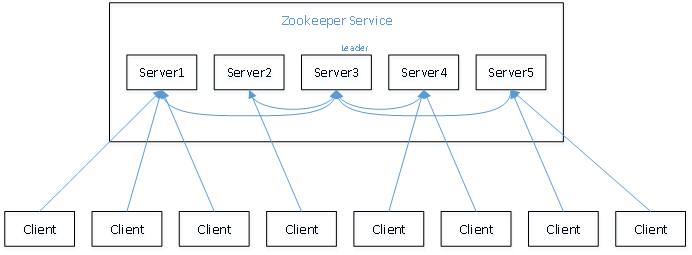
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样当小弟。
非全新集群的选举机制(数据恢复)
待补充
那么,初始化的时候,是按照上述的说明进行选举的,但是当zookeeper运行了一段时间之后,有机器down掉,重新选举时,选举过程就
相对复杂了。需要加入数据id、leader id和逻辑时钟。
数据id:数据新的id就大,数据每次更新都会更新id。
Leader id:就是我们配置的myid中的值,每个机器一个。
逻辑时钟:这个值从0开始递增,每次选举对应一个值,也就是说: 如果在同一次选举中,那么这个值应该是一致的 ; 逻辑时钟值越大,说明
这一次选举leader的进程更新.
选举的标准就变成:
1、逻辑时钟小的选举结果被忽略,重新投票
2、统一逻辑时钟后,数据id大的胜出
3、数据id相同的情况下,leader id大的胜出
根据这个规则选出leader。
四、zookeeper结构和命令
zookeeper特性
1)Zookeeper:一个领导者(leader),多个跟随者(follower)组成的集群。
2)Leader负责进行投票的发起和决议,更新系统状态,分布式读写,更新请求转发。
3)Follower用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票
4)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。
5)全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的。
6)更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行。
7)数据更新原子性,一次数据更新要么成功,要么失败。
8)实时性,在一定时间范围内,client能读到最新数据。
zookeeper数据结构
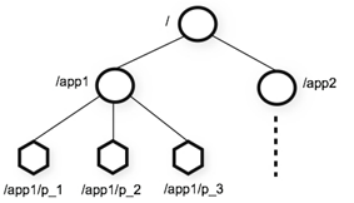
zookeeper集群自身维护了一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,我们称之为"znode",znode用于存储数据。每一个znode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识
节点类型
1、Znode有两种类型:
短暂(ephemeral)(断开连接自己删除)
持久(persistent)(断开连接不删除)
2、Znode有四种形式的目录节点(默认是persistent )
(1)持久化目录节点(PERSISTENT)
客户端与zookeeper断开连接后,该节点依旧存在
(2)持久化顺序编号目录节点(PERSISTENT_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
(3)临时目录节点(EPHEMERAL)
客户端与zookeeper断开连接后,该节点被删除
(4)临时顺序编号目录节点(EPHEMERAL_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
3、创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
4、在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
五、zookeeper命令行操作
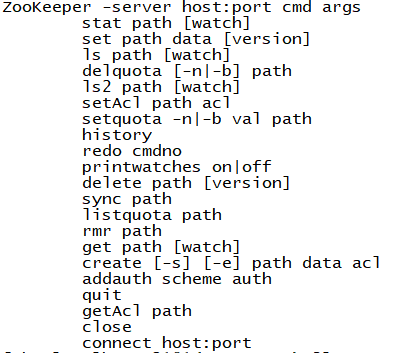
1)zkCli.sh进入命令行工具
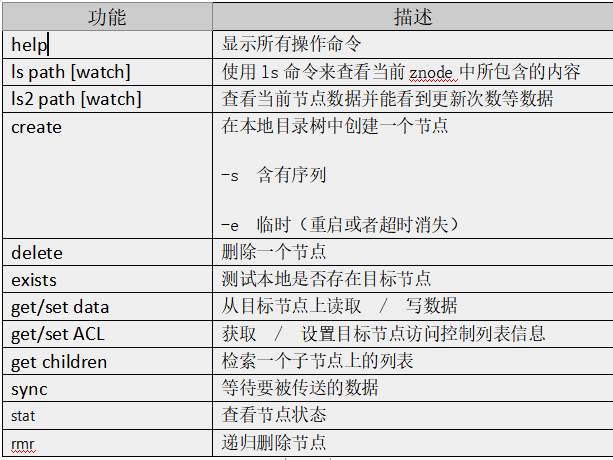
2)显示所有操作命令
[zk: localhost:2181(CONNECTED) 1] help
3)查看当前znode中所包含的内容
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
4)查看当前节点数据并能看到更新次数等数据
[zk: localhost:2181(CONNECTED) 1] ls2 /
[zookeeper]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
5)创建普通节点
[zk: localhost:2181(CONNECTED) 2] create /app1 “hello app1”
Created /app1
[zk: localhost:2181(CONNECTED) 4] create /app1/server101 “192.168.1.101”
Created /app1/server101
6)获得节点的值
[zk: localhost:2181(CONNECTED) 6] get /app1
hello app1
cZxid = 0x20000000a
ctime = Mon Jul 17 16:08:35 CST 2017
mZxid = 0x20000000a
mtime = Mon Jul 17 16:08:35 CST 2017
pZxid = 0x20000000b
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 10
numChildren = 1
[zk: localhost:2181(CONNECTED) 8] get /app1/server101
192.168.1.101
cZxid = 0x20000000b
ctime = Mon Jul 17 16:11:04 CST 2017
mZxid = 0x20000000b
mtime = Mon Jul 17 16:11:04 CST 2017
pZxid = 0x20000000b
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 13
numChildren = 0
7)创建短暂节点
[zk: localhost:2181(CONNECTED) 9] create -e /app-emphemeral 8888
(1)在当前客户端是能查看到的
[zk: localhost:2181(CONNECTED) 10] ls /
[app1, app-emphemeral, zookeeper]
(2)退出当前客户端然后再重启启动客户端
[zk: localhost:2181(CONNECTED) 12] quit
[atguigu@hadoop104 zookeeper-3.4.10]$ bin/zkCli.sh
(3)再次查看根目录下短暂节点已经删除
[zk: localhost:2181(CONNECTED) 0] ls /
[app1, zookeeper]
8)创建带序号的节点
(1)先创建一个普通的根节点app2
[zk: localhost:2181(CONNECTED) 11] create /app2 “app2”
(2)创建带序号的节点
[zk: localhost:2181(CONNECTED) 13] create -s /app2/aa 888
Created /app2/aa0000000000
[zk: localhost:2181(CONNECTED) 14] create -s /app2/bb 888
Created /app2/bb0000000001
[zk: localhost:2181(CONNECTED) 15] create -s /app2/cc 888
Created /app2/cc0000000002
如果原节点下有1个节点,则再排序时从1开始,以此类推。
[zk: localhost:2181(CONNECTED) 16] create -s /app1/aa 888
Created /app1/aa0000000001
9)修改节点数据值
[zk: localhost:2181(CONNECTED) 2] set /app1 999
10)节点的值变化监听
(1)在104主机上注册监听/app1节点数据变化
[zk: localhost:2181(CONNECTED) 26] get /app1 watch
(2)在103主机上修改/app1节点的数据
[zk: localhost:2181(CONNECTED) 5] set /app1 777
(3)观察104主机收到数据变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/app1
11)节点的子节点变化监听(路径变化)
(1)在104主机上注册监听/app1节点的子节点变化
[zk: localhost:2181(CONNECTED) 1] ls /app1 watch
[aa0000000001, server101]
(2)在103主机/app1节点上创建子节点
[zk: localhost:2181(CONNECTED) 6] create /app1/bb 666
Created /app1/bb
(3)观察104主机收到子节点变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/app1
12)删除节点
[zk: localhost:2181(CONNECTED) 4] delete /app1/bb
13)递归删除节点
[zk: localhost:2181(CONNECTED) 7] rmr /app2
14)查看节点状态
[zk: localhost:2181(CONNECTED) 12] stat /app1
cZxid = 0x20000000a
ctime = Mon Jul 17 16:08:35 CST 2017
mZxid = 0x200000018
mtime = Mon Jul 17 16:54:38 CST 2017
pZxid = 0x20000001c
cversion = 4
dataVersion = 2
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 2
stat结构体
1)czxid- 引起这个znode创建的zxid,创建节点的事务的zxid(ZooKeeper Transaction Id)
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
2)ctime - znode被创建的毫秒数(从1970年开始)
3)mzxid - znode最后更新的zxid
4)mtime - znode最后修改的毫秒数(从1970年开始)
5)pZxid-znode最后更新的子节点zxid
6)cversion - znode子节点变化号,znode子节点修改次数
7)dataversion - znode数据变化号
8)aclVersion - znode访问控制列表的变化号
9)ephemeralOwner- 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
10)dataLength- znode的数据长度
11)numChildren - znode子节点数量
六、API应用
eclipse环境搭建
1)创建一个工程
2)解压zookeeper-3.4.10.tar.gz文件
3)拷贝zookeeper-3.4.10.jar、jline-0.9.94.jar、log4j-1.2.16.jar、netty-3.10.5.Final.jar、slf4j-api-1.6.1.jar、slf4j-log4j12-1.6.1.jar到工程的lib目录。并build一下,导入工程。
4)拷贝log4j.properties文件到项目根目录
增删改查
import java.util.List;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import org.junit.Before;
import org.junit.Test;
public class SimpleZkClient {
private static final String connectString = "master:2181,slave1:2181,slave2:2181";
private static final int sessionTimeout = 2000;
ZooKeeper zkClient = null;
@Before
public void init() throws Exception {
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 收到事件通知后的回调函数(应该是我们自己的事件处理逻辑)
System.out.println(event.getType() + "---" + event.getPath());
try {
zkClient.getChildren("/", true);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* 数据的增删改查
*
* @throws InterruptedException
* @throws KeeperException
*/
// 创建数据节点到zk中
public void testCreate() throws KeeperException, InterruptedException {
// 参数1:要创建的节点的路径 参数2:节点大数据 参数3:节点的权限 参数4:节点的类型
String nodeCreated = zkClient.create("/eclipse", "hellozk".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
//上传的数据可以是任何类型,但都要转成byte[]
}
//判断znode是否存在
@Test
public void testExist() throws Exception{
Stat stat = zkClient.exists("/eclipse", false);
System.out.println(stat==null?"not exist":"exist");
}
// 获取子节点
@Test
public void getChildren() throws Exception {
List<String> children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
Thread.sleep(Long.MAX_VALUE);
}
//获取znode的数据
@Test
public void getData() throws Exception {
byte[] data = zkClient.getData("/eclipse", false, null);
System.out.println(new String(data));
}
//删除znode
@Test
public void deleteZnode() throws Exception {
//参数2:指定要删除的版本,版本为 -1 的话匹配所有版本
/*version参数指定要更新的数据的版本, 如果version和真实的版本不同,
更新操作将失败. 指定version为-1则忽略版本检查.*/
zkClient.delete("/eclipse", -1);
}
//修改znode
@Test
public void setData() throws Exception {
//版本设为-1则匹配所有版本;
zkClient.setData("/app1", "imissyou angelababy".getBytes(), -1);
byte[] data = zkClient.getData("/app1", false, null);
System.out.println(new String(data));
}
}
getType():
EventType.NodeCreated : 节点创建事件类型
EventType.NodeDeleted : 节点被删除
EventType.NodeDataChanged : 节点被修改
EventType.None : 客户端与服务器成功建立会话
EventType.NodeChildrenChanged : 子节点列表发生变更
Zookeeper的监听器工作机制
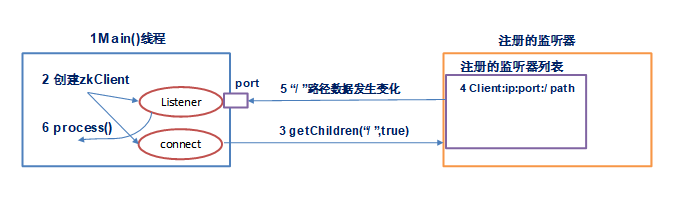
监听器是一个接口,我们的代码中可以实现Wather这个接口,实现其中的process方法,方法中即我们自己的业务逻辑
监听器的注册是在获取数据的操作中实现:
getData(path,watch?)监听的事件是:节点数据变化事件
getChildren(path,watch?)监听的事件是:节点下的子节点增减变化事件
七、监听服务器节点动态上下线案例
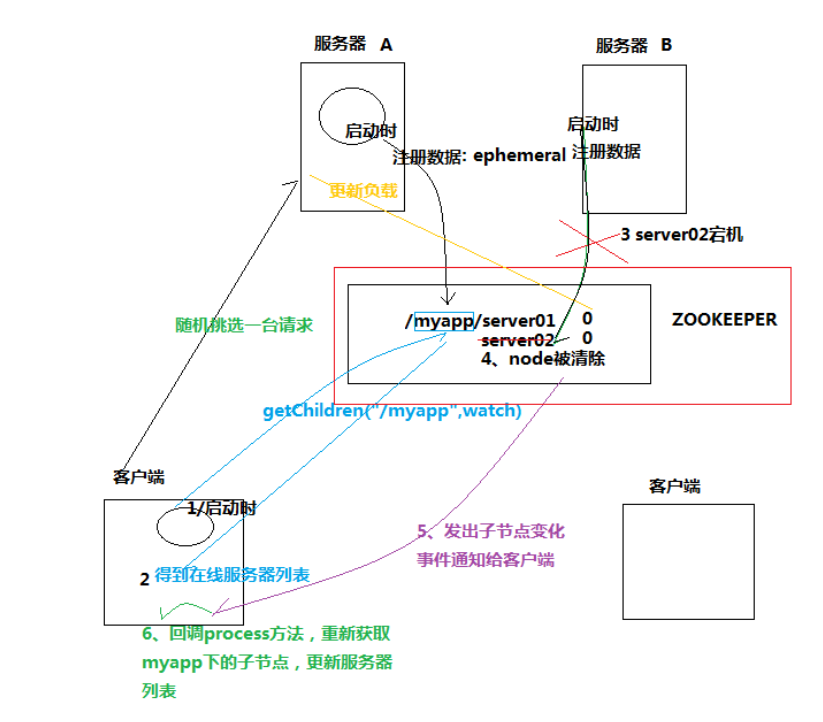
注册时创建的是临时节点
客户端启动就去获取当前在线服务器列表,并注册监听(getChildren("/myapp",watch))。
此时服务器slave2宕机了,服务器节点下线,node被清除。然后zookeeper发出子节点变化事件通知给客户端,客户端会回调process方法重新获取/myapp下的子节点,更新服务器列表并注册监听。
实现:
(0)先集群上创建/servers节点
[zk: localhost:2181(CONNECTED) 10] create /servers “servers”
(1)服务器端代码:
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
public class DistributedServer {
private static final String connectString = "master:2181,slave1:2181,slave2:2181";
private static final int sessionTimeout = 2000;
private static final String parentNode = "/servers";
private ZooKeeper zk = null;
/**
* 创建到zk的客户端连接
* @throws Exception
*/
public void getConnect() throws Exception {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 收到事件通知后的回调函数(应该是我们自己的事件处理逻辑)
System.out.println(event.getType() + "---" + event.getPath());
try {
zk.getChildren("/", true);
} catch (Exception e) {
}
}
});
}
/**
* 向zk集群注册服务器信息
* @param hostname
* @throws Exception
*/
public void registerServer(String hostname) throws Exception {
String create = zk.create(parentNode + "/server", hostname.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
//CreateMode:CreateMode value determines how the znode is created on ZooKeeper.
//CreateMode.EPHEMERAL_SEQUENTIAL:znode将在客户机断开连接时被删除,其名称将添加一个单调递增的数字。
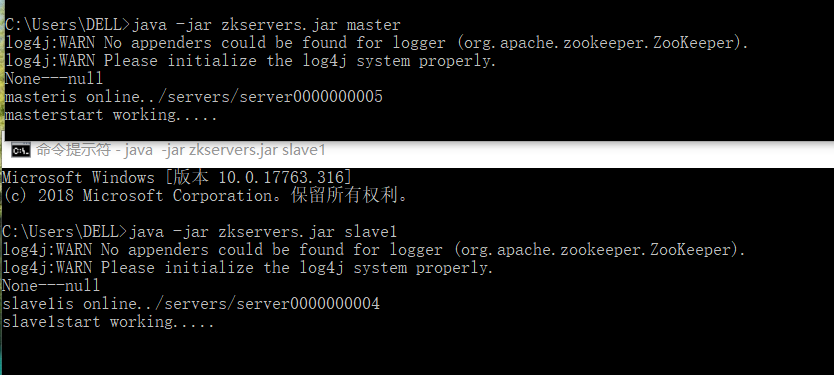
System.out.println(hostname + "is online.." + create);
}
/**
* 业务功能
* @throws InterruptedException
*/
public void handleBussiness(String hostname) throws InterruptedException {
System.out.println(hostname + "start working.....");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 获取zk连接
DistributedServer server = new DistributedServer();
server.getConnect();
// 利用zk连接注册服务器信息
server.registerServer(args[0]);
// 启动业务功能
server.handleBussiness(args[0]);
}
}
(2)客户端代码:
import java.util.ArrayList;
import java.util.List;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
public class DistributedClient {
private static final String connectString = "master:2181,slave1:2181,slave2:2181";
private static final int sessionTimeout = 2000;
private static final String parentNode = "/servers";
// 注意:加volatile的意义何在?
private volatile List<String> serverList;
private ZooKeeper zk = null;
/**
* 创建到zk的客户端连接
*
* @throws Exception
*/
public void getConnect() throws Exception {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 收到事件通知后的回调函数(应该是我们自己的事件处理逻辑)
try {
//重新更新服务器列表,并且注册了监听
getServerList();
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* 获取服务器信息列表
*
* @throws Exception
*/
public void getServerList() throws Exception {
// 获取服务器子节点信息,并且对父节点进行监听
List<String> children = zk.getChildren(parentNode, true);
// 先创建一个局部的list来存服务器信息
List<String> servers = new ArrayList<String>();
for (String child : children) {
// child只是子节点的节点名
byte[] data = zk.getData(parentNode + "/" + child, false, null);
servers.add(new String(data));
}
// 把servers赋值给成员变量serverList,已提供给各业务线程使用
serverList = servers;
//打印服务器列表
System.out.println(serverList);
}
/**
* 业务功能
*
* @throws InterruptedException
*/
public void handleBussiness() throws InterruptedException {
System.out.println("client start working.....");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 获取zk连接
DistributedClient client = new DistributedClient();
client.getConnect();
// 获取servers的子节点信息(并监听),从中获取服务器信息列表
client.getServerList();
// 业务线程启动
client.handleBussiness();
}
}
运行结果:
服务器:
客户端:
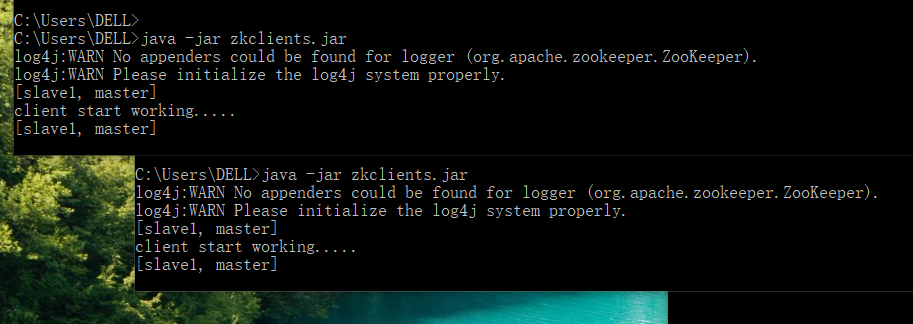
干掉slave1后,只显示[master]。
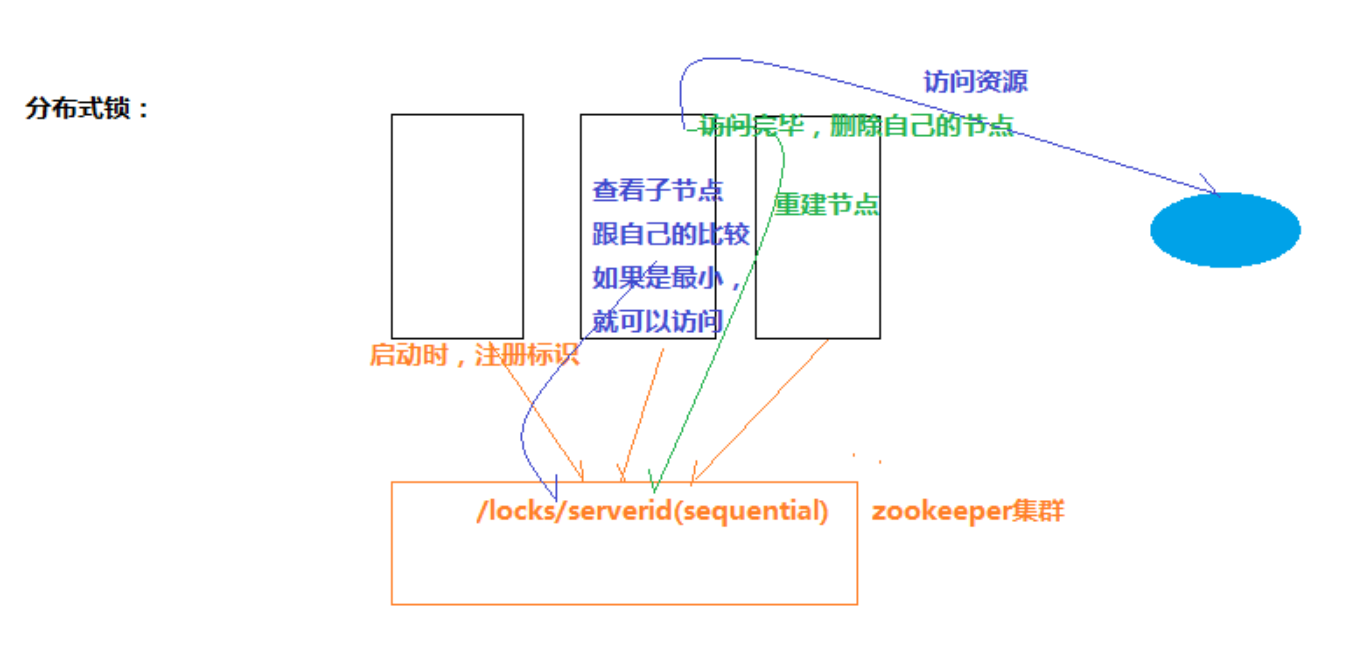
八、分布式共享锁
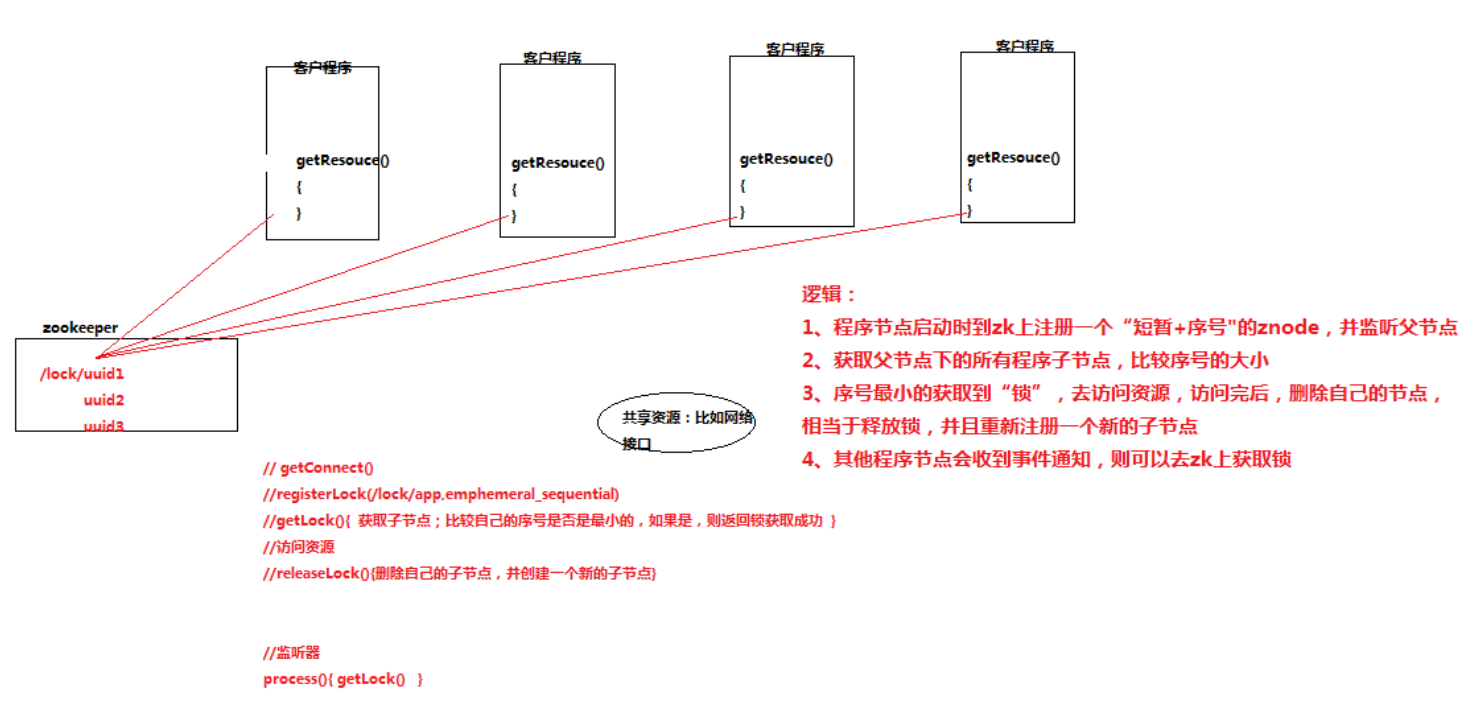
import java.util.Collections;
import java.util.List;
import java.util.Random;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.EventType;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
public class DistributedClientLock {
// 会话超时
private static final int SESSION_TIMEOUT = 2000;
// zookeeper集群地址
private String hosts = "master:2181,slave1:2181,slave2:2181";
private String groupNode = "locks";
private String subNode = "sub";
private boolean haveLock = false;
private ZooKeeper zk;
// 记录自己创建的子节点路径
private volatile String thisPath;
/**
* 连接zookeeper
*/
public void connectZookeeper() throws Exception {
zk = new ZooKeeper(hosts, SESSION_TIMEOUT, new Watcher() {
public void process(WatchedEvent event) {
try {
// 判断事件类型,此处只处理子节点变化事件
if (event.getType() == EventType.NodeChildrenChanged && event.getPath().equals("/" + groupNode)) {
// 获取子节点,并对父节点进行监听
List<String> childrenNodes = zk.getChildren("/" + groupNode, true);
String thisNode = thisPath.substring(("/" + groupNode + "/").length());
// 去比较是否自己是最小id
Collections.sort(childrenNodes);
if (childrenNodes.indexOf(thisNode) == 0) {
// 访问共享资源处理业务,并且在处理完成之后删除锁
doSomething();
// 重新注册一把新的锁
thisPath = zk.create("/" + groupNode + "/" + subNode, null, Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
// 1、程序一进来就先注册一把锁到zk上
thisPath = zk.create("/" + groupNode + "/" + subNode, null, Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// wait一小会,便于观察
Thread.sleep(new Random().nextInt(1000));
// 从zk的锁父目录下,获取所有子节点,并且注册对父节点的监听
List<String> childrenNodes = zk.getChildren("/" + groupNode, true);
// 如果争抢资源的程序就只有自己,则可以直接去访问共享资源
if (childrenNodes.size() == 1) {
doSomething();
thisPath = zk.create("/" + groupNode + "/" + subNode, null, Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
}
}
/**
* 处理业务逻辑,并且在最后释放锁
*/
private void doSomething() throws Exception {
try {
System.out.println("gain lock: " + thisPath);
Thread.sleep(2000);
// do something
} finally {
System.out.println("finished: " + thisPath);
// 锟斤拷thisPath删锟斤拷, 锟斤拷锟斤拷thisPath锟斤拷client锟斤拷锟斤拷锟酵ㄖ�
// 锟洁当锟斤拷锟酵凤拷锟斤拷
zk.delete(this.thisPath, -1);
}
}
public static void main(String[] args) throws Exception {
DistributedClientLock dl = new DistributedClientLock();
dl.connectZookeeper();
Thread.sleep(Long.MAX_VALUE);
}
}
最后
以上就是昏睡钢笔最近收集整理的关于Zookeeper-1待补充的全部内容,更多相关Zookeeper-1待补充内容请搜索靠谱客的其他文章。








发表评论 取消回复