文章目录
- 第一章:计算机基础
- 1.1 硬件组成
- 1.2 操作系统分类
- 1.3 解释型和编译型介绍
- 第二章:Python入门
- 2.1 介绍
- 2.2 python涉及领域
- 2.2.1 哪些公司有使用Python开发应用
- 2.3 环境的安装
- 2.4 编码
- 2.4.1 python解释器默认编码
- 2.4.1.1 Python解释器种类以及特点
- 2.5 变量
- 2.5.1变量命名规则
- 2.6 python的关键字
- 第三章:数据类型
- 3.1 整型
- 3.1.1 整型(int)
- 3.1.2 浮点数(float)
- 3.1.3 复数(complex)
- 3.2 布尔(bool)
- 3.3 字符串
- 3.3.1 字符串格式
- 3.3.2字符串方法
- 索引 | 切片
- 拼接
- 分割
- 重复
- 替换
- 删除两边空格或指定字符
- 字母大小写操作
- 判断字符串内容
- 判断开头/结尾
- 计数/长度
- 查找
- 居中/左/右
- 字节(bytes)
- 转义字符
- 字符串格式化
- 3.4 运算符
- 3.4.1 算术运算符
- 3.4.2 比较运算符
- 3.4.3 赋值运算符
- 3.4.4 成员运算符
- 3.4.5 位运算符
- 3.4.6 逻辑运算符
- 3.4.7 身份运算符
- 3.4.8 运算符优先级
- 3.5 注释
- 3.6 列表(list)
- 3.6.1 列表格式
- 3.6.2 列表方法
- 3.6 元组(tuple)
- 3.7 字典(dict)
- 3.8 集合(set)
- 3.9 公共函数
- 3.10 条件语句| 循环语句 | 退出循环
- 3.11 三元运算符(三目运算符)
- 第四章:文件操作
- 4.1 文件基本操作
- 4.2 打开模式
- 4.3 操作
- 4.4 关闭文件
- 4.5 文件内容修改
- 4.6 目录文件相关操作
- 4.6.1 路径区分:
- 第五章:函数
- 5.1 定义函数规则:
- 5.1.1 函数的执行(调用):
- 5.2 参数
- 5.3 变量作用域
- 5.4 return 返回值:
- 5.5 匿名函数(lambda)
- 5.6 内置函数
- 5.7 闭包函数
- 5.8 高阶函数
- 5.9 装饰器
- 5.10 推导式
第一章:计算机基础
1.1 硬件组成
计算机基本硬件由:CPU/内存/主板/硬盘/显卡/网卡等组成。
1.2 操作系统分类
-
Windows
-
Linux
- CentOs(一般线上使用)
- Ubuntu
- RedHat
-
Mac
1.3 解释型和编译型介绍
编程语言开发的一个工具,主要是用于把代码编译成计算机(系统)能识别的内容并执行。
-
编译型语言:
执行代码之前,有一个专门的编译过程。把源高级程序编译成一个机器语言,只做一个翻译,运行时不需要编译,所以编译型语言执行效率比较高。语言:C / C++ / Java / C# / Go
-
解释型语言:解释性语言编写的程序不需要编译,在执行的时候,专门有一个解释器能够将VB语言翻译成机器语言,每个语句都是在执行的时候才能编译,这样解释型语言每执行一次就要编译一次,效率比较低。语言:Python / PHP / ruby
第二章:Python入门
2.1 介绍
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,Guido开始写Python语言的编译器。Python这个名字,来自Guido所挚爱的电视剧Monty Python’s Flying Circus。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。
最新的TIOBE排行榜,Python赶超PHP占据第4, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。
2.2 python涉及领域
- WEB开发——最火的Python web框架Django, 支持异步高并发的Tornado框架,短小精悍的flask,bottle, Django官方的标语把Django定义为the framework for perfectionist with deadlines(大意是一个为完全主义者开发的高效率web框架)
- 网络编程——支持高并发的Twisted网络框架, py3引入的asyncio使异步编程变的非常简单
- 爬虫——爬虫领域,Python几乎是霸主地位,ScrapyRequestBeautifuSoapurllib等,想爬啥就爬啥
- 云计算——目前最火最知名的云计算框架就是OpenStack,Python现在的火,很大一部分就是因为云计算
- 人工智能——谁会成为AI 和大数据时代的第一开发语言?这本已是一个不需要争论的问题。如果说三年前,Matlab、Scala、R、Java 和 Python还各有机会,局面尚且不清楚,那么三年之后,趋势已经非常明确了,特别是前两天 Facebook 开源了 PyTorch 之后,Python 作为 AI 时代头牌语言的位置基本确立,未来的悬念仅仅是谁能坐稳第二把交椅。
- 自动化运维——问问中国的每个运维人员,运维人员必须会的语言是什么?10个人相信会给你一个相同的答案,它的名字叫Python
- 金融分析——我个人之前在金融行业,10年的时候,我们公司写的好多分析程序、高频交易软件就是用的Python,到目前,Python是金融分析、量化交易领域里用的最多的语言
- 科学运算—— 你知道么,97年开始,NASA就在大量使用Python在进行各种复杂的科学运算,随着NumPy, SciPy, Matplotlib, Enthought librarys等众多程序库的开发,使的Python越来越适合于做科学计算、绘制高质量的2D和3D图像。和科学计算领域最流行的商业软件Matlab相比,Python是一门通用的程序设计语言,比Matlab所采用的脚本语言的应用范围更广泛
- 游戏开发——在网络游戏开发中Python也有很多应用。相比Lua or C++,Python 比 Lua 有更高阶的抽象能力,可以用更少的代码描述游戏业务逻辑,与 Lua 相比,Python 更适合作为一种 Host 语言,即程序的入口点是在 Python 那一端会比较好,然后用 C/C++ 在非常必要的时候写一些扩展。Python 非常适合编写 1 万行以上的项目,而且能够很好地把网游项目的规模控制在 10 万行代码以内。另外据我所知,知名的游戏<文明> 就是用Python写的
2.2.1 哪些公司有使用Python开发应用
- 谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发
- CIA: 美国中情局网站就是用Python开发的
- NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算
- YouTube:世界上最大的视频网站YouTube就是用Python开发的
- Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载
- Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发
- Facebook:大量的基础库均通过Python实现的
- Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
- 豆瓣: 公司几乎所有的业务均是通过Python开发的
- 知乎: 国内最大的问答社区,通过Python开发(国外Quora)
- 春雨医生:国内知名的在线医疗网站是用Python开发的
- 除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务。
2.3 环境的安装
官方教程
2.4 编码
计算机中的所有数据,不论是文字、图片、视频、还是音频文件,本质上最终都是按照类似 01010101 的二进制存储的。
-
ASCII
最多只能用8位来表示(一个字节),即:2**8 -1 = 256(即pow(2,8)=256),
所以,ASCII码最多只能表示255个符号。 -
utf-8
万国码的升级版,一个中文字符==三个字节,英文是一个字节,欧洲的是2个字节
-
GB2312
国家1980年的一个标准《中华人民共和国国家标准 信息交换用汉字编码字符集 基本集 GB2312-80》。这个标准用两个数来编码汉字和中文符号。第一个数称为“区”,第二个数称为“位”。所以也称为区位码。
-
GBK
在国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。一个中文字符==2个字节,英文是一个字节。
-
unicode # 包含所有语言的编码。用一个字符==两个字节(如果要用到非常偏僻的字符,就需要4个字节)。
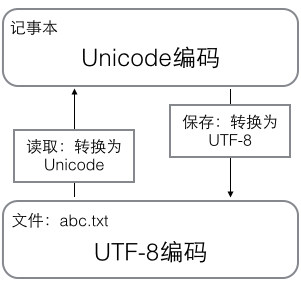
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
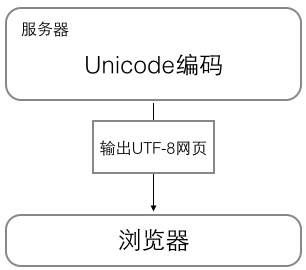
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
2.4.1 python解释器默认编码
2.*版本: ASCII
3.*版本: UTF-8
如果要修改默认编码,只需在代码首行添加:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
2.4.1.1 Python解释器种类以及特点
1、Cpython:最常用的官方版本,使用C语言实现。使用最为广泛。
2、Jpython:Python的Java实现,Jpython会将Python代码动态编译成Java字节码,然后在JVM上运行。
3、IronPython:Python的C#实现,IronPython将Python代码编译成C#字节码,然后再CLR运行(与Jpython类似)
4、PYPY(特殊): Python实现的Python,将Python的字节码再编译成机器码。
2.5 变量
2.5.1变量命名规则
- 必须以:字母、下划线(_)、数字组成,其中数字不能开头;
- 不能以python关键字命名变量,但可以包含关键字;
- 不能包含空格;
2.6 python的关键字
- 关键字
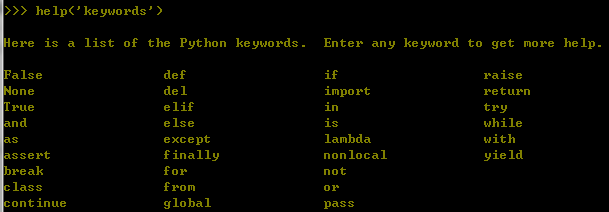
None
del
True / False
if / elif / else
for / in / while / break / continue / yield / with
and / or / not / is / as
def / return / global / nonlocal / lambda / pass / class / assert
import / form / raise / finally
try / except
第三章:数据类型
3.1 整型
Python 数字数据类型用于存储数值。数据类型是不可变,这就意味着如果改变数字数据类型的值,将重新分配内存空间。
3.1.1 整型(int)
由十进制整数0~9组成的数为int类型。
py2.*版本中有:int / long
py3.*版本只有:int
>>> a = 1
>>> type(a)
<class 'int'>
-
除法区别
在py2.*版本中,作除法运算时,会把小数点后面的部分去掉,只保留整数部分;
在py3.*版本中,作除法运算时,会把小数点后面的部分保留,返回值为浮点数类型;
# py2.7 >>> 1/2 0 # py3.6 >>> 1/2 0.5
3.1.2 浮点数(float)
带小数的整数,都为浮点数类型。
>>> b = 1.5
>>> type(b)
<class 'float'>
3.1.3 复数(complex)
复数是由一个实数和一个虚数组合构成,表示为:x+yj;一个复数时一对有序浮点数 (x,y),其中 x 是实数部分,y 是虚数部分。
>>> a = 3.14j
>>> a
3.14j
>>> type(a)
<class 'complex'>
3.2 布尔(bool)
布尔值是用来表示真假,用True和False表示。
False: None /’ ’ /[ ] /( ) /{ } / 0
True:非空非0的都为真
3.3 字符串
python 要求字符必须使用引号括起来的,可以为单引号、双引号、三引号;字符串可以包含任意字符,数据类型为不可变。字符串在内存中使用编码Unicode编码储存数据。
注意:字符串的所有方法基本上都是返回新的值。
3.3.1 字符串格式
>>> a = 'abc'
>>> b = '123'
>>> c = "世...界"
>>> d = ''' def '''
>>> print(type(a), type(b), type(c),type(d))
<class 'str'> <class 'str'> <class 'str'><class 'str'>
3.3.2字符串方法
索引 | 切片
- 用索引方式对字符串进行切片操作,索引从0开始计数
>>> string = 'hello world'
>>> string[:]
'hello world'
>>> string[0] # 第一个字符
'h'
>>> string[-1] # 最后一个字符
'd'
>>> string[0:5] # 从第0位至第4位,前包后闭
'hello'
>>> string[:5]
'hello'
>>> string[6:-1] # 从第6位至倒数第二位,前包后闭
'worl'
>>> string[6:]
'world'
>>> string[::2] # 从头到尾,每次隔2步取一次
'hlowrd'
>>> string[::-2] # 同上,倒取字符
'drwolh'
>>> string[::-1] # 同上,倒取字符
'dlrow olleh'
- str() | repr()
ss = 'abcd' # 两种不同的数据类型转换显示格式
print(str(s)) >>> abcd # 不带冒号
print(repr(s)) >>> 'abcd' # 带冒号
拼接
- + 字符串连接
>>> s1 = 'hello'
>>> s2 = 'world'
>>> s1 + s2
'helloworld'
- join 将序列中的元素以指定的字符连接生成一个新的字符串
>>> s1 = 'abcd'
>>> s2 = '-'
>>> s2.join(s1)
'a-b-c-d'
>>> '*'.join(s1) # 可以指定符号(任意类型)进行拼接
'a*b*c*d'
分割
-
split() # 从右边开始按指定字符分割,可限制分割次数,返回list
-
rsplit() # 从左边开始按指定字符分割,可限制分割次数,返回list
-
partition() # 按指定的字符串分为三份:前面、自己、后面。
>>> s1 = '欢迎,来到python,世界!'
>>> s1.rsplit(',',1)
['欢迎,来到python', '世界!']
>>> s1.split(',',1)
['欢迎', '来到python,世界!']
>>> s1 = '欢迎,来到python,世界!'
>>> print(s1.partition("python"))
('欢迎,来到', 'python', ',世界!')
重复
- * 字符串重复次数
>>> s1 = 'a'
>>> s1 * 5
'aaaaa'
>>> s2 = '中国'
>>> s2*2
'中国中国'
替换
- replace() 把指定的内容替换成别的内容
>>> s1 = 'Hello world'
>>> s2 = 'Python'
>>> s1.replace('world',s2)
'Hello Python'
>>> s1.replace('world','Python')
'Hello Python'
删除两边空格或指定字符
- strip() 删除两边的空格(默认:n,t,空格)
- lstrip() 删除左边的空格
- rstrip() 删除右边的空格
>>> s1 = " ab cd " # 删除空格,注意字符与字符之间的空格不会被删除
>>> s1.strip()
'abcd'
>>> s1.lstrip()
'abcd '
>>> s1.rstrip()
' abcd'
>>> s1 = "****ab**cd****" # 删除指定字符
>>> s1.strip("*")
'ab**cd'
>>> s1.lstrip("*")
'ab**cd****'
>>> s1.rstrip("*")
'****ab**cd'
字母大小写操作
- title() 改为标题格式(单词首字母大写)
>>> s = 'this is a title'
>>> s.title() #
'This Is A Title'
- upper() | isupper() 全部改为大写|判断全部字符串为大写
>>> s = 'abcdefg'
>>> s.upper()
'ABCDEFG'
- lower() | islower() | casefold() 全部改为小写|判断全部字符串为小写|全部改为小写包括特殊字符
>>> s = 'ABCDEFG'
>>> s.lower()
'abcdefg'
>>> s.islower()
False
>>> s.casefold()
'abcdefg'
- capitalize() 第一个字母改为大写
>>> s = 'abcdefg'
>>> s.capitalize()
'Abcdefg'
- swapcase() 互转,全部字母大小写转换
>>> s = 'ABC def'
>>> s.swapcase()
'abc DEF'
判断字符串内容
- isdecimal() 判断是否为十进制数字
- isdigit() 判断是否为数字,特殊数字也可以判断为真True(非中文)
- isalpha() 判断字符串是否为字母
- isalnum() 判断字符串是否为字母或数字或字母数字组合
>>> s1 = 'abcd'
>>> s2 = '1234'
>>> s3 = '123①②③'
>>> s1.isdecimal() # 只判断十进制数字
False
>>> s2.isdecimal()
True
>>> s3.isdigit()
True
#######################################
>>> s1 = 'abcd'
>>> s2 = '1234'
>>> s1.isalpha()
True
>>> s2.isalpha()
False
#######################################
>>> s1 = 'abcd'
>>> s1.isalnum()
True
>>> s4 = '1234'
>>> s4.isalnum()
True
>>> s2 = 'abcd1234'
>>> s2.isalnum()
True
>>> s3 = 'abc123...'
False
判断开头/结尾
- startswith() 判断开头是否为指定的字符开头
- endswith() 判断结尾是否为指定的字符结尾
>>> s = 'abcd1234'
>>> s.startswith('a')
True
>>> s.startswith('b')
False
>>> s.endswith('a')
False
>>> s.endswith('4')
True
计数/长度
- count() 计算个数
>>> s = "this is string example....wow!!!"
>>> s.count('i') # 计算指定的字符,在目标字符串中有几个
3
>>> s.count('i',5,13) # 5,13 表示计算的范围
2
- len() 计算字符串长度
>>> s = "this is string example....wow!!!"
>>> len(s)
32
查找
- find() # 查询指定字符是否存在目标字符串中,是:返回索引,否:返回-1;
- index() # 查询指定字符是否存在目标字符串中,是:返回索引,否:报错;
>>> s = "abcdefg"
>>> s.find('g')
6
>>> s.find('2')
-1
>>> s.index('g')
6
>>> s.index('2')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
居中/左/右
- center() 将字符串居中,并用空格或指定字符填充
- ljust() 将字符串左对齐,并用空格或指定字符填充
- rjust() 将字符串右对齐,并用空格或指定字符填充
>>> s = 'abcd'
>>> s.center(8)
' abcd '
>>> s.center(8,'-')
'--abcd--'
>>> s.rjust(8)
' abcd'
>>> s.ljust(8)
'abcd '
>>> s.ljust(8,'-')
'abcd----'
>>> s.rjust(8,'-')
'----abcd'
字节(bytes)
>>> s = b'hello'
>>> print(s)
b'hello'
>>> print(s[0])
104
>>> print(s[2:4])
b'll'
>>> s1 = bytes('我爱python', encoding='utf-8')
>>> print(s1)
b'xe6x88x91xe7x88xb1python'
转义字符
| 转义字符 | 描述 |
|---|---|
| \ | 反斜杠符号 |
| ’ | 单引号 |
| ’’ | 双引号 |
| n | 换行 |
| t | 制表符 |
| r | 回车 |
字符串格式化
| 符号 | 描述 |
|---|---|
| %s | 格式化字符串 |
| %r | 格式化字符串,repr()格式显示 |
| %d | 格式化整数 |
| %f | 格式化浮点数 |
| %i | 格式化十进制整数 |
| str.format() | 基本语法是通过 {} 和 : 来代替以前的 % 。可以接受不限个参数,位置可以不按顺序。 |
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
3.4 运算符
3.4.1 算术运算符
| 运算符 | 描述 |
|---|---|
| + | 加 - 两个对象相加 |
| - | 减 - 得到负数或是一个数减去另一个数 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 |
| / | 除 - x 除以 y |
| % | 取模 - 返回除法的余数 |
| ** | 幂 - 返回x的y次幂 |
| // | 取整除 - 向下取接近商的整数 |
3.4.2 比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写。 | (a < b) 返回 True。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 True。 |
3.4.3 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符。 | 在这个示例中,赋值表达式可以避免调用 len() 两次:if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)") |
3.4.4 成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
3.4.5 位运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位 与 运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位 或 运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位 异或 运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位 取反 运算符:对数据的每个二进制位取反,即把1变为0,把0变为1。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动 运算符:运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动 运算符:把">>“左边的运算数的各二进位全部右移若干位,”>>"右边的数指定移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
3.4.6 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 |
|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 True,x and y 返回 y 的计算值,否则它返回 x。 |
| or | x or y | 布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 |
3.4.7 身份运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
3.4.8 运算符优先级
| 运算符 | 描述 |
|---|---|
| x[index] 或 x[index: index2[:index2]] | 索引运算符 (最高优先级) |
| x.attribute | 属性访问 |
| ** | 指数 |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,求余数和取整除 |
| + - | 加法 减法 |
| >> << | 右移,左移运算符 |
| & ^ | | 与 、异或、或(左高) |
| == != > < >= <= | 比较运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
3.5 注释
- #号注释
# 这是一种单行注释,只针对一行注释
- 三引号注释
''' 单引号注释,多行注释'''
""" 双引号注释,多行注释"""
3.6 列表(list)
3.6.1 列表格式
list = [] 中括号表示列表,列表中的每个元素都对应一个索引,第一个元素的索引值是0,第二个元素的索引值是1,依次类推;列表是可变数据类型。
注意:列表所有的方法基本上都是返回None。
3.6.2 列表方法
- 索引 | 切片 | + | *
lists = ['a','b','c','d','e','f']
print(lists[0]) # 索引
print(lists[-1])
print(lists[:]) # 切片
print(lists[1:-1])
lists1 = [1,2]
print(lists + lists1) # + 连接
print(lists1 * 3) # * 重复
>>a # 以下为输出值
>>f
>>['a', 'b', 'c', 'd', 'e', 'f']
>>['b', 'c', 'd', 'e']
>>['a', 'b', 'c', 'd', 'e', 'f', 1, 2]
>>[1, 2, 1, 2, 1, 2]
-
append() # 列表中添加元素
-
extend() # 列表中追加元素
-
insert() # list.insert(index, obj),插入指定索引位置。
-
index() # list.index(str, beg=0, end=len(string)),查询目标中是否包含子字符串 str,是返回索引值,否报错(ValueError)。
lists1 = [1,2]
lists1.append('a')
print(lists1) #>>> [1, 2, 'a']
lists1.append([33,44])
print(lists1) #>>> [1, 2, 'a', [33, 44]]
lists1.extend('b')
print(lists1) #>>> [1, 2, 'a', [33, 44], 'b']
lists1.extend([11,22])
print(lists1) #>>> [1, 2, 'a', [33, 44], 'b', 11, 22]
lists1.insert(0,'aa')
print(lists1) #>>> ['aa', 1, 2, 'a', [33, 44], 'b', 11, 22]
print(lists1.index(2)) #>>> 2
- remove() # 删除指定元素
- pop() # 删除,指定索引位置,默认最后一位
- del a[:] # 删除全部或指定索引
- clear() # 清空全部元素
lists1 = ['aa', 1, 2, 'a', [33, 44], 'b', 11, 22]
lists1.remove('a')
print(lists1) #>> ['aa', 1, 2, [33, 44], 'b', 11, 22]
a1 = lists1.pop()
print(a1, lists1) #>> 22 ['aa', 1, 2, [33, 44], 'b', 11]
a2 = lists1.pop(3)
print(a2,lists1) #>> [33, 44] ['aa', 1, 2, 'b', 11]
del(lists1[1])
print(lists1) #>> ['aa', 2, 'b', 11]
a3 = lists1.clear()
print(a3,lists1) #>> None []
- reverse() # 反转,列表反过来
- sort() # 排序,默认从小到大,还可传入key和reverse两个参数,当key=len时会按长度排序;当reverse=True时按从大到小排序,默认为False。
- count() # str.count(sub, start= 0,end=len(string)),统计个数
- copy() #浅拷贝,返回新的值
L = ['a', 'b', 'c', 'd']
L.reverse()
print(L) #>> ['d', 'c', 'b', 'a']
L = [9,1,5,3,2,4]
L.sort()
print(L) #>> [1, 2, 3, 4, 5, 9]
L = [9,1,5,1,2,1]
a = L.count(1) # 计算元素在列表中存在个数
print(a) #>> 3
L = [9,1,5,1,2,1]
a = L.copy() # 浅拷贝
print(a) #>> [9, 1, 5, 1, 2, 1]
3.6 元组(tuple)
- count() # str.count(sub, start= 0,end=len(string)),统计个数,可指定统计的元素,是返回个数,否返回0
- indxe() # str.index(str, beg=0, end=len(string)),查找目标中是否包含子字符串 str,是返回索引值,否报错(ValueError值错误)。
- max(tuple) # 返回元组中最大的元素,必须元素类型一致,否则报错(TypeError类型错误)
- min(tuple) # 返回元组中最小的元素,必须元素类型一致,否则报错(TypeError类型错误)
tuple1 = ('aa', 1,1,1, 2, 'a', [33, 44], 'b', 11, 22)
tuple2 = (1,2,3,4,5,6,7)
# lists2 = ('a','b','c')
print(tuple1.index('b')) #>> 7
print(tuple1.count(1)) #>> 3
print(max(tuple2)) #>> 7 c
print(min(tuple2)) #> 1 a
3.7 字典(dict)
- keys() # 字典的键值
- values() # 字典的值
- items() # 字典的键值对
- get() # 获取键对应的值,需指定键,如没有返回None
- update(dict2) # 更新字典中的value,可追加新的字典,返回值为None
d = {'a':1,'b':2}
s1 = d.keys()
print(list(s1),d.keys()) #>>['a', 'b'] dict_keys(['a', 'b'])
s2 = d.values()
print(list(s2),d.values()) #>>[1, 2] dict_values([1, 2])
s3 = d.items()
print(list(s3),d.items()) #>>[('a', 1), ('b', 2)] dict_items([('a', 1), ('b', 2)])
print(d.get('a')) #>>1
d2 = {'c':11}
print(d,d.update(d2)) #>>{'a': 1, 'b': 2, 'c': 11} None
d2 = {'a':22}
print(d,d.update(d2)) #>>{'a': 22, 'b': 2, 'c': 11} None
- clear() # 清空字典,返回None
- pop() # 删除指定键的值,返回被删除的值
- popitem() # 随机返回并删除字典中的最后一对键和值,字典为空时报错(KeyError)
- del dict[keys] # 删除全部键值对或指定键对应的值
dict1 = {'Name': 'Runoob', 'Age': 7}
c = dict1.clear()
print(dict1) #>> {}
pi = dict1.popitem()
print(pi,dict1) #>> ('Age', 7) {'Name': 'Runoob'}
po = dict1.pop('Name')
print(po,dict1) #>> Runoob {'Age': 7}
del dict1['Name']
print(dict1) #>> {'Age': 7}
- copy() # 返回一个字典的浅复制。
d1 = {'a':1,"b":2}
d2 = d1.copy()
print("d1:%s, d2:%s" %(d1,d2))
>> d1:{'a': 1, 'b': 2}, d2:{'a': 1, 'b': 2}
- fromkeys() # dict.fromkeys(seq[, value]),用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值(默认:None)。
d = ('a','b','c')
new_d = new_d.fromkeys(d)
print(new_d) #>> {'a': None, 'b': None, 'c': None}
new_d2 = new_d.fromkeys(d,10)
print(new_d2) #>> {'a': 10, 'b': 10, 'c': 10}
- setdefault() # dict.setdefault(key, default=None), 和 get()方法类似,返回指定键的值,如果键不存在于字典中,将会添加键并将值设为默认值。
dict1 = {'Name': 'Runoob', 'Age': 7}
print(dict1.setdefault('Age', None)) #>> 7
print(dict1.setdefault('Sex', None)) #>> None
print("新字典为:", dict1) #>>新字典为: {'Name': 'Runoob', 'Age': 7, 'Sex': None}
3.8 集合(set)
- add() # 添加元素,如元素存在则忽略
- update() # 更新元素,如元素存在则忽略
s = {1}
s.add('a')
print(s) #>> {1, 'a'}
s2 = {11,22}
s.update(s2)
print(s) #>> {1, 11, 'a', 22}
- clear() # 清空全部
- discard() # 删除集合中指定的元素
- pop() # 删除
- remove() # 删除元素
- copy() # 浅拷贝
s = {1, 11, 'a', 22}
a = s.clear()
print(s,a) #>> set() None
s.discard('a')
print(s) #>> {1, 11, 22}
s.pop()
print(s) #>> {11, 'a', 22}
s.remove(22)
print(s) #>> {1, 11, 'a'}
s1 = s.copy()
print(s1) #>> {1, 11, 'a', 22}
- a.intersection(b) # 交集
- a.union(b) # 并集
- a.difference(b) # 差集
s1 = {1, 11,22}
s2 = {1,2}
print(s1.intersection(s2)) # >> {1}
print(s1.union(s2)) #>>{1, 2, 22, 11}
print(s1.difference(s2)) #>> {11, 22}
3.9 公共函数
索引
切片
步长
len() # 支持:list|tuple|dict |set
count() # 支持:list|tuple
indxt() # 支持:list|tuple
romove() # 支持:list|set
update() # 支持:dict|set
clear() # 支持:list|dict |set
copy() # 支持:list|dict |set
pop() # 支持:list|dict|set
del() # 支持:list(可指定索引)|dict(可指定keys)
3.10 条件语句| 循环语句 | 退出循环
- if :…elif :…else :…
if 条件:
语句体
elif 条件:
语句体
else:
语句体
- for…in… :
- range() # 生成数列,从0开始
for i in 条件:
语句体
- while True: …
while 条件(True|False):
语句体
-
break # 终止循环
-
continue # 跳出当前循环
3.11 三元运算符(三目运算符)
格式:v = 前面 if 条件 else 后面 # 适合于简单的判断语句。
v = 前面 if 条件 else 后面
# 上面和下面的用意一致
if 条件:
v = 前面
else:
v = 后面
第四章:文件操作
注意:操作文件时,要按照:以什么编码写入,就需用什么编码打开。
4.1 文件基本操作
file = open('路径',mode='读取方式',encoding='编码格式')
file.wite() # 写
file.read() # 读
file.close() # 关闭文件
4.2 打开模式
- r | w | a | + # 只读|只写|只追加 | 更新文件(可读可写)
- r+ | w+ | a+ # 可读写追加
- rb | wb | ab # # 二进制只读|二进制只写|二进制只追加
- rb+ | wb+ | ab+ # 二进制可读写追加
4.3 操作
- read() 读取文件全部内容
- read(1) 1表示读取一个字符,二进制读取只取一个字节
- readline() 从文件读取一整行,包括 “n” 字符。
- readlines() 读取所有行并返回列表
- write() 写,支持字符串,二进制
- writelines( [str] ) 向文件中写入一序列的字符串,换行需要加n。
- seek(3) 3表示光标跳转位置,无论什么模式打开,都是按字节处理
- tell() 返回光标所在的字节位置
- flush() 强制把内存中写的内容更新到文件中
4.4 关闭文件
- close() 手动强制关闭
- with open() as f: 内部执行完毕后自动关闭文件
4.5 文件内容修改
- 方式一:先读取文件的所有内容,在修改指定的内容,最后在修改后的全部内容写入文件中。
with open('a.txt',r)as f1:
date = f1.read() # 先读取文件内容
n_date = date.replace(替换内容) # 修改指定的内容
with open('a.txt',r)as f2:
date = f1.write(n_date) # 再把修改后的全部内容重新写入文件中
- 方式二(适合大文件):先一点点按行读取文件,在修改指定的内容,最后把修改的内容写入另一个文件中。
with open()as f1, open()as f2: # 同时打开两个文件格式
for line in f1: # 读取第一个文件,循环每一行
n_line = line.replace(替换内容) # 修改指定的内容
f2.write(n_line) # 把修改后的内容写入到新文件中
4.6 目录文件相关操作
4.6.1 路径区分:
- 相对路径:使用 . 或者 … 开头的路径表达方式
window: ./system32/a.txt
linux: …image
unix: …image
- 绝对路径:完整描述路径的表达方式
window: ./system32/a.txt
linux: homexd1image
unix: homexd1image
python内置的 os 模块,就是针对文件夹、目录相关操作的。
第五章:函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
5.1 定义函数规则:
- 函数代码块以 def 关键字开头,后接函数名和小括号组成:def name(参数):pass
- 任何传入参数和自变量必须放在圆括号中。
- 函数内容以冒号开始,并且代码块缩进(4空格)。
- 一般代码块的第一行需添加注释函数说明。
- return[表达式] 输出内容,并结束函数(注意:返回多个数据时,格式为元组)。
def names():
print('这是一个自定义函数')
return 1,2,3 #>> (1,2,3) 返回为元组
5.1.1 函数的执行(调用):
注意:函数不被调用,内部代码永远不会执行。
每次调用函数时,都会为此调用开辟一块内存空间,内存中保存以后想要用的值。
def names():
print('这是一个自定义函数')
return 1,2,3
names() # 调用自定义函数
5.2 参数
函数中的参数支持任意类型(可变类型 | 不可变类型)的数据;
注意:位置传参必须在关键字传参的前面;
函数定义的参数叫形式参数(形参);
调用函数时传递的参数叫实际参数(实参);
参数分类:
-
位置参数
- 位置参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
-
默认参数
-
调用函数时,默认参数的值如果没有传入,则被认为直接使用默认值,注意:默认值如果是可变类型(慎用)。
解释:因为value是可变类型,每次调用这个方法value不会每次都初始化[].而是调用相同的[].def func(data,value=[]): pass # 不推荐参数value=[]定义 def func(data,value=None): if not value: # 推荐函数内部中定义参数类型 value = []
-
-
不定长参数(*args)
- 需要一个函数能处理比当初声明时更多的参数,这些参数叫做不定长参数。
-
关键字参数(**kwargs)
- 可变参数允许传入0个~多个参数,而关键字参数允许在调用时以字典形式传入0个或多个参数(注意区别,一个是字典一个是列表);在传递参数时用等号(=)连接键和值
-
命名关键字参数( * )
- 命名关键字参数需要一个用来区分的分隔符 *****,它后面的参数被认为是命名关键字参数;命名关键字参数在关键字参数的基础上限制传入的关键字的变量名和普通关键字参数不同。
-
函数当参数
- 函数的参数传递的是什么? 传递的是:内存地址(引用)
def names(a, b, c=0, *args, **kwargs):
print('位置参数:',a) #>> 1
print('位置参数:',b) #>> 2
print('默认参数:',c) #>> 5
print('不定长参数:',args) #>> ('a', 'b')
print('关键字参数:',kwargs) #>> {'x': 9}
names(1,2,5,'a','b',x=9)
#----------------------------------------------------#
def names2(a,b,*,name,age):
print('a:',a) #>>a: A
print('b:',b) #>>b: B
print('name:',name) #>> name: 张三
print('age:',age) #>> age: 17
names2('A',"B",name='张三',age=17)
#----------------------------------------------------#
def func(arg): arg()
def show(): pass
func(show) # 把函数当参数传递到func中
5.3 变量作用域
一个函数是一个作用域。
作用域规则:优先在自己的作用域中找数据,自己没有就去"父级"-> “父级” 查找一直到全局,全局在没有会报错。
- 全局变量(命名规范:大写)
- 定义在函数外部的变量为全局变量,可以在整个程序范围内访问。
- 局部变量(命名规范:小写)
- 定义在函数内部的变量为局部变量,只能在其被声明的函数内部访问。
- 注意:全局变量为不可变类型时,局部变量不能对全局变量进行直接修改;当全局变量为可变类型时,局部变量能对全局变量直接修改; 用关键字(global / nonlocal)声明后可以修改。
A = 0
def s():
A = 5 # 不能对全局变量修改,只能局部重新赋值
print('局部变量:',A) #>> 局部变量: 5
s()
print("全局变量:",A) #>> 全局变量: 0
#---------------------------------------------------------------#
A = []
def s():
A.append(5) # 这是对全局变量进行修改
print('局部变量:',A) #>> 局部变量: [5]
s()
print("全局变量:",A) #>> 全局变量: [5]
- global 声明变量为全局变量,后可对全局变量修改。
- nonlocal 只找上一级的作用域,后可对父级变量修改。
B = 10
def func():
B = 0
def s():
nonlocal B # 只针对上一级变量
B = 5 # 不能对全局变量修改,只能局部重新赋值
print('局部变量:',B) #>> 局部变量: 5
s()
func()
print("全局变量:",B) #>> 全局变量: 10
#---------------------------------------------------------------#
B = 10
def func():
B = 0
def s():
global B # 声明为全局变量
B = 5 # 同时修改全局变量
print('局部变量:',B) #>> 局部变量: 5
s()
func()
print("全局变量:",B) #>> 全局变量: 5
5.4 return 返回值:
- 默认返回:None
- 特殊情况:
def func():
return 1,2,3,4
print(func()) # 返回一个元组格式
5.5 匿名函数(lambda)
用于表示简单的函数。lambda函数内部隐藏了return方法,默认带返回值。
应用场景:闭包、函数式编程
def func1(a):
return a
# 上面和下面表达一致
func2 = lambda a: a # func2得到函数内存地址
func3 = lambda : 100 # 不带参数,直接返回100
5.6 内置函数
python内部的函数:
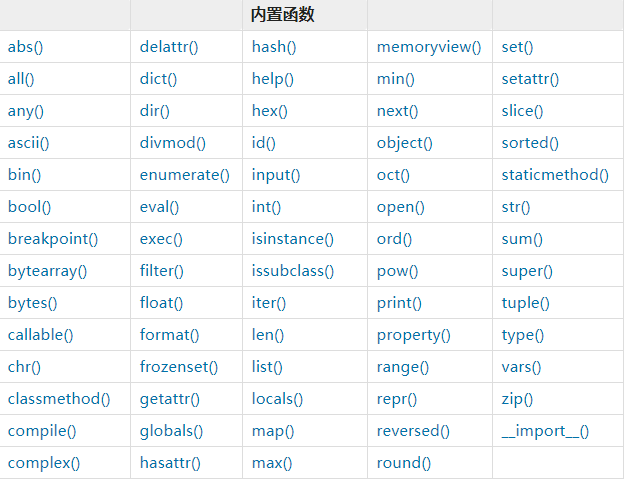
-
计算相关
- divmod(a,b) 两个数相除,返回商和余数两个值。
- abs(num) 返回数据的绝对值
- pow(x,y) 就幂运算,同2**3
a = 2**3 b = pow(2,3) print(a,b) #>> 8 8- round(num) 将数字计算结果四舍五入到给定的精度(小数点后位数),默认不带小数点位
a = 0.35567 print(round(a, 2)) #>> 0.36 -
进制转换
- bin(int) 将十进制转换成二进制
- oct(int) 将十进制转换成八进制
- int(num,base=[2,8,16]) 将其他进制转换成十进制
- hex(int) 将十进制转换成十六进制
a = bin(2) # 先转二进制 0b开头
print(int(a, base=2)) # 在转十进制
b = oct(8) # 先转八进制 0o开头
print(int(b, base=8)) # 在转十进制
c = hex(100) # 先转十六进制 0x开头
print(int(c, base=16)) # 在转十进制
-
编码转换
- chr() 将十进制的数字转换成Unicode编码中的对应字符
print(chr(65)) #>> A- ord() 根据字符在Unicode编码中找到成对应的十进制数字
print(ord('A')) #>> 65应用场景:
# 随机验证码 import random def rand_data(lenth): data = [] for i in range(length): # 控制验证码长度 v = random.randint(65,90) # 获取随机生成数字 data.append(chr(v)) # 将数字转换成对应的字符,添加到列表中 return ''.join(data) print(rand_data(6)) # 输出转换后的字符 -
高级函数
- map(x,y) x: 函数,y: 必须可迭代类型数据;循环y中每个元素,然后让每个元素执行x函数,将每个函数执行的结果保存到新列表中,并返回;使用结果需要 list 强制转换下结果或循环,可以得到对应的数据。
- filter(x,y) x: 函数,y: 必须可迭代类型数据;通过x函数循环y列表,剔除不需要的元素,将函数执行的结果保存到新列表中,并返回;使用结果需要 list 强制转换下结果或循环,可以得到对应的数据。
- reduce(x,y) x: 函数,y: 必须可迭代类型数据; 通过x函数循环操作(运算、拼接等) y 列表中每个元素,最终返回一个值。
a = [1,2,3,4] result = map(lambda x:x+100, a) # 每个元素加100 print(result) #>> <map object at 0x00000000023CB8D0> # 返回对象 print(list(result)) #>> [101, 102, 103, 104]b = [1,2,'a','b'] result = filter(lambda x:True if type(x)==int else False, b) print(result) #>> <filter object at 0x00000000021DB780> print(list(result)) #>> [1, 2] #-------------------------------------------------------# def func(x): return True if type(x)==int else False result = filter(func,b) print(result) #>> <filter object at 0x00000000021DB780> print(list(result)) #>> [1, 2] #-------------------------------------------------------# result = filter(lambda x: type(x)==int, b) print(result) #>> <filter object at 0x00000000021DB780> print(list(result)) #>> [1, 2]import functools c = [1,2,3,4,5] def func(x,y): return x+y result = functools.reduce(func,c) print(result) #>> 15 #-------------------------------------------------------# result = functools.reduce(lambda x,y:x+y, c) print(result) #>> 15
5.7 闭包函数
维基百科中的解释:
在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外
父类函数中嵌套子类函数,子类函数引用父类函数的变量,并且父类函数return子类函数对象(内存地址)。
另一个解释:内层函数引用了外层函数的变量,然后返回内层函数的情况,成为闭包。
闭包必备条件:外函数有传递值 + 内层函数有使用
作用:在循环的过程中,将传递的值保存到内存中,以便于以后使用。
def func(name):
def inner():
print(name)
return inner
v = func('alex')
v()
例子:
info = []
def func(i):
def inner():
print(i)
return inner
for i in range(10):
info.append(func(i))
info[0]() #>> 0
info[4]() #>> 4
逻辑说明:1.程序从上往下开始执行,先执行for循环 i=0 ,i 的值传入函数 func 中,返回子函数 inner 的内存地址,添加到 info 列表中。
2.继续for循环 i=1 ,i 的值传入函数 func 中,返回子函数 inner 的内存地址,添加到 info 列表中;以此执行到 i=9 后,info 列表中已有9个 子函数 inner 的内存地址数据。
3.程序往下执行:info[0]() ,调用列表 info 中的第0索引的内存地址,并执行子函数 inner() 输出 i 值,由于子函数 inner 中没有 i 进行赋值需要从父函数中查找,把父函数的 i=0 值传入子函数中并输出:0
4.程序往下执行:info[4]() ,调用列表 info 中的第4索引的内存地址,并执行子函数 inner() 输出 i 值,由于子函数 inner 中没有 i 进行赋值需要从父函数中查找,把父函数的 i=4 值传入子函数中并输出:4
5.8 高阶函数
- 把函数当作参数传递
- 把函数当作返回值
- 对函数进行赋值
5.9 装饰器
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。
装饰器的作用就是为已经存在的函数或对象添加额外的功能。
装饰器标准语法格式:
def 外层函数(参数):
def 内层函数(*arg,**kwarg):
return 参数(*arg,**kwarg)
return 内层函数
@外层函数
def index(*arg,**kwarg):pass
index()
# 函数赋值示例:
def c(): print('11')
def d(): print('22')
d = c
d() #>> 11
#-----------------------------------------------------#
def func(arg): #2. arg=f1函数
def inner(): arg() #5. arg()=调用f1函数
return inner #3. 返回inner函数
def f1(): print('123') #6. 最后输出print
v1 = func(f1) #1. v1=inner函数
v1() #4. 执行inner函数
def func(arg):
def inner(): return arg()
return inner
def index():
print('123')
return '666'
#示例一:
v1 = index() # 执行inner函数,打印123并返回666赋值v1
#示例二:
v2 = func(index) # v2=inner函数,arg=index函数
index = 888 # index重新赋值
v3 = v2() # 还是执行inner函数,打印123并返回666赋值v3
#示例三:
v4 = func(index) # func返回inner函数内存地址,赋值给v4
index = v4 # v4中inner内存地址再赋值给index
index() # 执行inner函数,arg()在调用index(),最后print:123
def func(arg):
def inner():
print("添加内容一")
v = arg() # 这里arg还是指向原来的index函数
print("添加内容二")
return v
return inner
def index():
print('123')
return '666'
#示例四:
index = func(index) # 把index函数对象传入func函数的arg参数中,返回inner函数对象=index变量
index() # 因index变量已指向inner函数对象,所以index()执行的是inner函数
def func(arg):
def inner():
print("添加内容一")
v = arg() # 这里arg还是指向原来的index函数
return v
return inner
# @func 等价于 index = func(index)
#第一步:执行func函数并将下面的函数当参数传递;
#第二步:将func的返回值重新赋值给下面的函数名。
@func # 装饰器语法
def index():
print('123')
index()
# 带参数--装饰器示例:
def getsss(*args, **kwargs): # 接收参数
def c(ff): # 接收装饰的函数
def inner():
if args: # 条件成立,执行计算
return ff() + 100
else: # 条件成立,执行计算
return ff() + 200
return inner
return c
@getsss(True) # 传入参数
def func1():
return 10
@getsss(False)
def func2():
return 11
# 返回计算后的结果
print(func1())
print(func2())
5.10 推导式
-
列表推导式
列表推导式是Python构建列表(list)的一种快捷方式,可以使用简洁的代码就创建出一个列表.
- 基本格式
result = [i for i in range(10)] # 变量 = [ for循环的变量 for循环一个可迭代对象] #------------------上下等同---------------# r = [] for i in range(10): r.append(i) #示例一: v1 = [i+100 for i in range(10)] # [100, 101, 102, 103, 104, 105, 106, 107, 108, 109] v2 = ['i大' if i>5 else 'i小' for i in range(10)] # ['i小', 'i小', 'i小', 'i小', 'i小', 'i小', 'i大', 'i大', 'i大', 'i大'] v3 = [lambda :100 for i in range(1)] # [<function <listcomp>.<lambda> at 0x000000000513A950>] v4 = [lambda :100+i for i in range(10)] print(v4[4]()) #>> 109 #i只传递for循环最后一个值9,匿名函数中的i值永远都是9#面试题: v5 = [lambda x:x+i for i in range(10)] # 1. v5是什么? 10个函数对象 #2.v5[0](2)结果是什么? 11 #-----------------------------------------------# def num(): return [lambda x:x*i for i in range(4)] print(num()) # 输出4个lambda函数对象 print([m(2) for m in num()]) #>> [6,6,6,6]#循环函数对象,把实参2传递函数中,return结果 #------------------- 筛选 -------------------------# v6 = [i for i in range(10) if i>5] print(v6) #>> [6,7,8,9] #先执行for循环i=0,在if判断i的值为True则append:i值,依次循环。 -
字典推导式
- 同理列表,模板: { key:value for key,value in existing_data_structure }
strings = ['import','is','with','if'] dict = {k:v for v,k in enumerate(strings)} print(dict) #>> {'import': 0, 'is': 1, 'with': 2, 'if': 3} #--------------------keys和value互换------------------------------# person = {'naem':'aaa','axg':18} print(person.items()) #>>dict_items([('naem', 'aaa'), ('axg', 18)]) person_reverse = {v:k for k,v in person.items()}#也可以实现 print(person_reverse) #>>{'aaa': 'naem', 18: 'axg'} -
集合推导式
- 同理列表,模板: { expression for item in Sequence if conditional }
names = [ 'Bob', 'JOHN', 'alice', 'bob' ] new_names = {n[0].upper() + n[1:].lower() for n in names} print(new_names) #>> {'Alice', 'Bob', 'John'}
递归:
-
官方规定:递归最大次数:1000
-
修改递归次数:sys.setrecursionlimit(999999999) # 不管数值多大,最多到20963次
递归的特点:
- 必须有一个明确的结束条件,要不就会变成死循环了,最终撑爆系统
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 递归执行效率不高,递归层次过多会导致栈溢出
import sys
sys.getrecursionlimit() #>> 返回递归最大值 int
def func(a): # 递归案例
if a ==5:
return 10000
result = func(a+1) +10 # 注意 func(a+1)调用循环次数
return result
v = func(1)
print(v) #>> 10040
####################### 未完待续 ################################
最后
以上就是平淡大船最近收集整理的关于python--零基础入门--自学笔记第一章:计算机基础第二章:Python入门第三章:数据类型第四章:文件操作第五章:函数的全部内容,更多相关python--零基础入门--自学笔记第一章内容请搜索靠谱客的其他文章。








发表评论 取消回复