一、微服务框架和组件介绍
自从springboot诞生之后(好多年前的事情),就标志着微服务设计和架构思想就已经是服务集群建设的主流。但是微服务建设之后,就会面临一些列问题,服务之间调用如何更好的实现?服务信息更新之后如何更好的被告知?服务的调用如何被监管(服务均被调用的方式实现,如何监管性能)?springcloud出现之后,面对微服务架构管理和监管机制被面向一线开发,开发者通过利用springcloud各个组件有能力去进行服务治理和服务管理。dubbo的出现,更是将微服务的开发和治理更加便捷和轻量化,使得服务管理和治理有更加高效、简单和便捷。
springcloud组件:服务注册中心->nacos,Eureka,zookeeeper;负载均衡->Ribben,springCloudLoader Banlance; 服务熔断->Hystrix, sentinel, resilience4J; 配置中心->config; 服务网关->springCloudGateway,Zuul; 服务接口调用-> feign,openFeign,restTemplate; 链路发现和追踪-> slueth + zipkin + ELK(统一日志收集检索和可视化方案),skywalking(华为 大牛私下开发的),国外社交LINE公司的pinPoint.
Dubbo是面向服务治理的轻量级高性能的RPC框架,其原理主要涉及两个,其一是SPI,本身基于jdk的spi做了定制化改造和开发(classLoader->ExtensionClassLoader),使得Dubbo配置化,根据不同的配置key加载不同的接口实现,这也是Dubbo container实现的原理。其二是Dubbo基于动态代理和反射对服务的调用的实现,也就是provider的实现,调用不同的接口对象,本质上就是调用通过代理实现的,方法则是通过代理实现的字节码植入方法 proxyFactory.invoke();最终通过invoke发送网络请求,实现RPC。Dubbo的高性能主要还是基于了Netty实现的RPC,Netty主要在性能上有两大特点,其一就是NIO,事件驱动的异步IO.其二就是netty的io读写都是零拷贝的方式实现的。对于dubbo的接口通信,需要数据对象序列化,其也支持很多种,本身netty也是封装了几种序列化的实现,传统的序列化有xml,json,fastjson,Gson等,dubbo也支持protobuf,hessian,fst等。
二、springcloud框架与dubbo的区别
那么dubbo和springCloud的区别是什么呢?上面也简单说明了,springcloud是微服务框架有极为丰富的组件,微服务各种管理和功能的组件,而dubbo仅仅是面向微服务调用的rpc框架,是可以这么理解的。但是dubbo有自己不可忽略的优势,首先dubbo采用了netty的nio模式,同时dubbo采用web通信是自身实现的二进制dubbo协议,和自身实现的序列化方法。这些都比传统的rpc组件性能更加突出。springcloud依托各种组件实现强大整体微服务解决方案的能力,上面也提到很多组件。
dubbo对于负载均衡,网关还有限流也有实现的机制模块,在gatway模块中有不同的负载均衡策略,同时也有限流的策略的选择。dubbo自身也有熔断和降级的实现部分,这部分逻辑依据mock机制实现的,当然dubbo也可以和spring cloud其他组件配合使用,如:hystrix实现熔断和降级的策略;和slueth结合实现链路的追踪能力等。
三、各组件工作方式和原理介绍
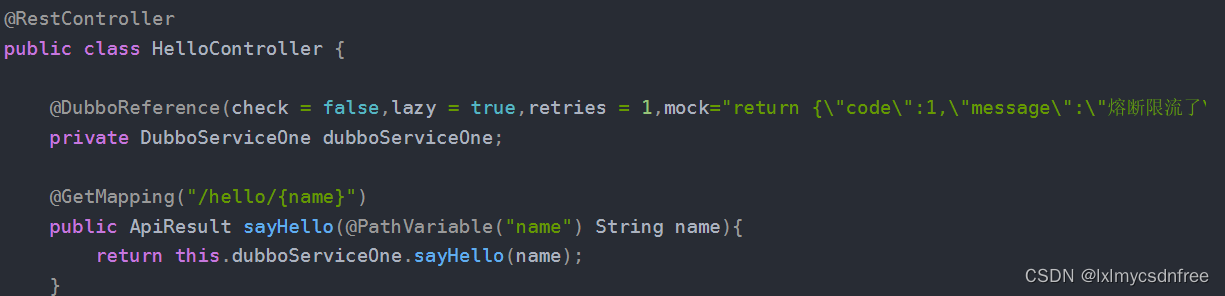
1)服务注册中心,zookeeper是注重CP,注重服务注册信息的一致性,因为自己的有一套分布式事务算法,所以注重的是一致性。Erueka 它是注重CA,注重可用性。注册中心原理:就是收集服务的信息和暴露的接口信息,然后存储起来,或者直接集群文件存储,或者借助数据库,然后注册中心会和服务直接保持心跳活动,实时检测服务状态来保持记录的服务列表信息准确性。注册中心如果出现宕机,那么我们也可以配置从已有的活跃服务列表中再次拉取服务信息。一般服务注册中心都有自己的dashboard,也就是组件都有会web页面的展示。
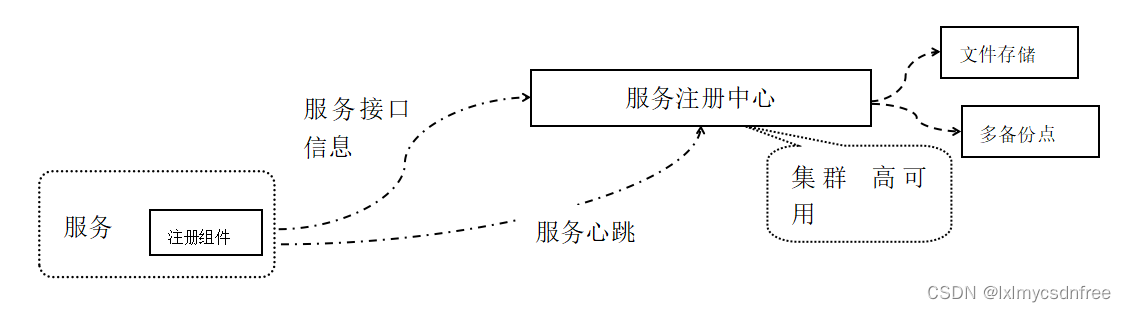
2)服务网关,组件有zuul, springcloud gateway;网关的原理就是接收请求之后统计设计的拦截器和过滤器,我们可以通过谓词和filter来配置转发,同时还可以添加一些参数或者token的认证等。一般使用的时候主要是配置文件的配置,通过yaml脚本或者lue脚本或者xml配置,去添加统一的转发或者过滤规则。本事上就是http/sevlet dispacher的实现,监听端口统一收集所有的监听请求,然后做转发。
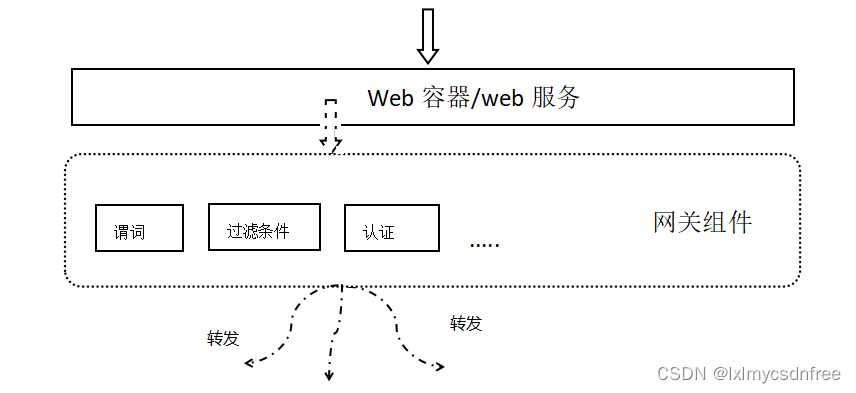
3)负载均衡器,组件有bibbon, springcloud loaderbanlence;负载均衡说白了也是请求转发,但是其可以使用在server端,也可以使用在网关client端(也就是结合网关使用)。只是负载均衡器实现了均衡算法,比如随机数,轮询,最小活跃数等算法。那么上述组件的使用也主要是配置文件的配置,选择使用哪种算法,但是也支持了代码实现的入口,来扩展算法实现负载均衡。
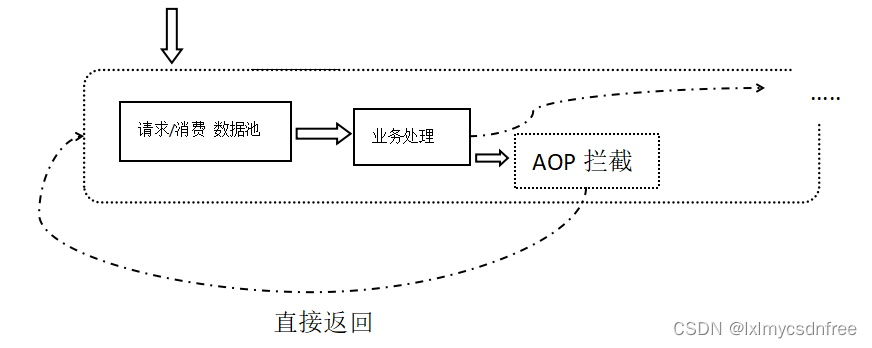
4)流量控制,熔断和降级组件有hystrix, sentinel(阿里的),流量控制组件主要的机制就是反射+aop,在对应接口调用前后追加操作方法,来实现对请求的控制和截断。这类组件一般都有dashboard,用来查看接口调用的流量,以及还可以配置接口的拦截效能。对应hystrix组件就是标准的aop机制,使用它主要要在接口处添加注解,以及配置流量控制机制,那么这就设置到对于代码的侵入和代码的耦合。而阿里开发sentinel只要依赖jar包,通过配置,然后通过反射知道对应的代码方法,aop实现对方法的监控和操作,所以sentinel的dashboard方式很方便,实现了代码的解耦。
5)接口调用,组件有feign,openfeign,restTemplate;使用该组件主要是在对应接口上添加注解,那么组件就会通过动态代理字节码植入的方式实现外部接口的方式。本身就是字节码构现了接口方法,该方法会向外界发送网络请求,返回来的会进行发序列化构建对象。restTemplate组件注重的是通过配置的方式实现,而不是代码注解的方式,所以更加方便解耦。
6)链路追踪和记录,组件有slueth + zipkin,华为大牛(skywalking),pinPoint;链路追踪本质上就是在对应的网络请求接口输出日志,核心原理也是AOP。输出节点日志也可以配置导入到数据库,当然也可以结合ELK组件来收集和管理。
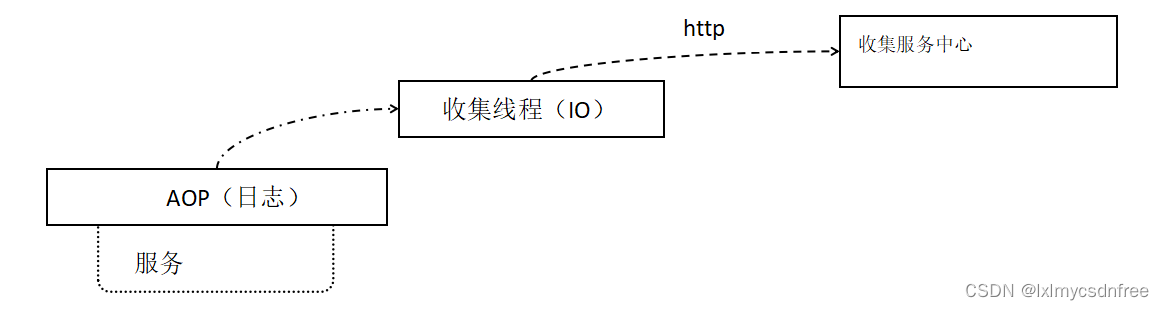
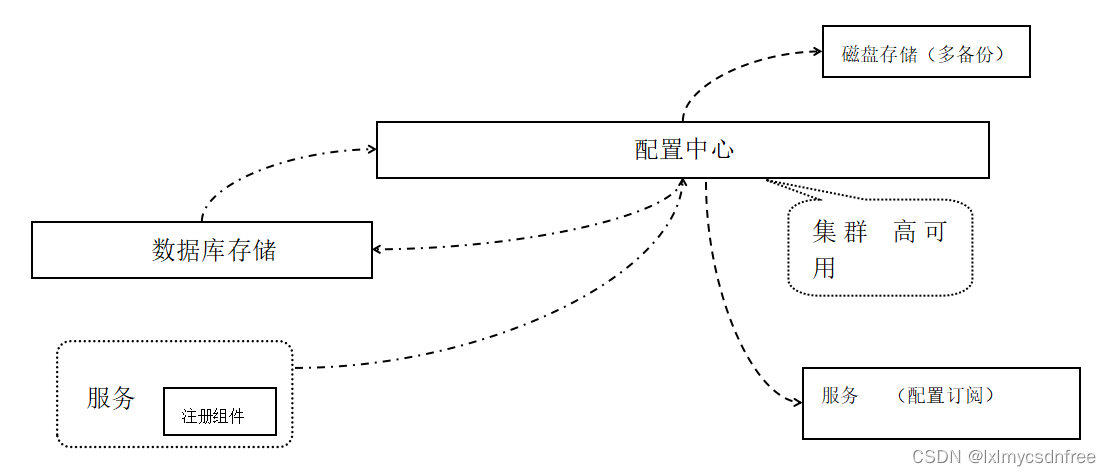
8)配置中心,config,appolo,nacos(阿里);配置中心原理:收集服务的配置信息,存储到数据库或者文件系统中,配置中心保证配置数据的安全,采用加密存储和认证的方式来返回服务的配置。同时配置中心当收到配置的时候,会下发给bus,告诉其他服务配置的更改,其他服务就会感知配置的变化从而重新获取配置。配置中心一般采用nio通信方式来追求传输效率。
9)监控中心,spring-admin
四、微服务分布式架构
由于不同业务点就是一组服务集群,所有是分布式集群,其实在微服务的架构中,保证服务之间的性能,不仅仅是上述的这些基本的组件,那么各种中间件也是极为重要的存在。如支撑高并发的消息中间件与缓存中间件(消息中间件有kafka, rabbitMQ,ActiveMq,缓存中间件有reids,memeryMq),当然我们还需要对集群机器进行管理的组件如zookeeper,或者分布式事务支撑的组件zookeeper,或者seata组件等。我们还有对大量数据存储的文件存储中间件,如HDFS,fastDFS(阿里c语言开发) 等。
对于分布式有一个很业务上要经常要面对的问题,那就是分布式id的问题;1.要保证id是全局唯一的 2.id需要整体单调增加的 3.id最好不是连续的,防止安全攻击。第一种方案:通过uuid来生成,但是没有办法保证递增,uuid是由32个16为数据段组成,数据太大,也不宜存储,不宜最为主键或者建立索引。第二种方案:通过redis,首先本身redis就是单线程的,本身吞吐能力很大,通过其原子操作INCR/INCRBY来增加返回id数值。redis本身也是集群能达到五个9的安全可用性标准。 第三种方案:就是zookeeper来生成,但是zk需要我们去做分布式锁,保证zk的同步。 第四种方案就是通过雪花算法,这也是目前使用比较多的,雪花算法的核心就是对id划分片段,然后片段段位控制增长和唯一性。
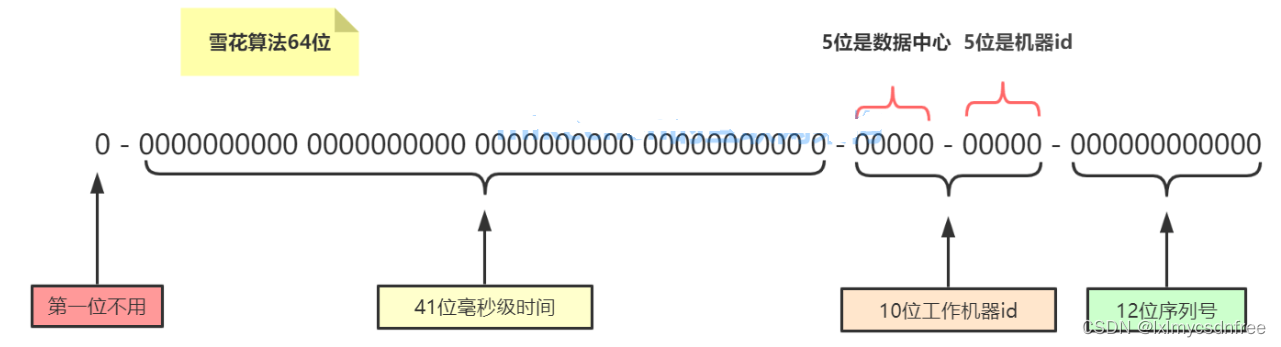
由于时间戳位位于高位所以肯定是递增的,且是有一定的不连续性,而且只有8个字节,64bit.更关键的是本地生成性能极为高效。
最后
以上就是会撒娇发夹最近收集整理的关于微服务建设浅述的全部内容,更多相关微服务建设浅述内容请搜索靠谱客的其他文章。








发表评论 取消回复