大家好,欢迎关注我的CSDN博客,我是【沂水寒城】,搜索
https://yishuihancheng.blog.csdn.net即可查看我的博客专栏文章,谢谢
在时间序列相关的很多建模工作中,LSTM模型是经常会使用到的,从提出到现在LSTM模型已经有了很多的扩展、变种和应用,今天我们简单地实现基于LSTM模型来对多个变量的数据进行建模预测,在简单地预测中只能做单步预测,这里实现了多步的预测分析。
具体实现如下:
#!usr/bin/env python#encoding:utf-8from __future__ import division '''__Author__:沂水寒城功能:基于堆叠式LSTM神经网络的多变量序列预测模型''' import osimport jsonimport sysimport mathimport timeimport kerasimport randomimport pymysqlimport datetimeimport platformimport numpy as npimport pandas as pdfrom keras.utils import plot_modelfrom keras.layers.pooling import MaxPooling1Dfrom keras.layers import LSTM,Dense,Input,add,Flattenimport matplotlib.pyplot as pltfrom keras.models import Sequential,Modelfrom sklearn.preprocessing import MinMaxScaler,LabelBinarizer,LabelEncoder,Imputerfrom keras.layers.core import Activation,Dropout,Dense,Flattenfrom sklearn.model_selection import train_test_splitfrom scipy.stats import pearsonr,spearmanr,kendalltau from keras.callbacks import EarlyStopping,ModelCheckpoint,Callbackfrom keras.layers.normalization import BatchNormalization from keras.optimizers import SGD, Adadelta, Adagrad,RMSprop from keras.layers.advanced_activations import PReLU from utils import predictFuturefrom sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squared_error, r2_scorefrom keras.layers.convolutional import Conv1D,ZeroPadding1D,Conv2D,MaxPooling2D,AveragePooling2D,Convolution2D,ZeroPadding2Dfrom keras.layers import Dense, Dropout, Embedding, LSTM, Bidirectionalfrom keras.layers import TimeDistributed def sliceWindow(data,step): ''' 移动滑窗创建数据集 ''' X,y=[],[] for i in range(0,len(data)-step,1): end=i+step oneX,oney=data[i:end,:],data[end, :] X.append(oneX) y.append(oney) return np.array(X),np.array(y) def dataSplit(dataset,step): ''' 数据集分割 ''' datasetX,datasetY=sliceWindow(dataset,step) train_size=int(len(datasetX)*0.70) X_train,y_train=datasetX[0:train_size,:],datasetY[0:train_size,:] X_test,y_test=datasetX[train_size:len(datasetX),:],datasetY[train_size:len(datasetX),:] X_train=X_train.reshape(X_train.shape[0],step,-1) X_test=X_test.reshape(X_test.shape[0],step,-1) print('X_train.shape: ',X_train.shape) print('X_test.shape: ',X_test.shape) print('y_train.shape: ',y_train.shape) print('y_test.shape: ',y_test.shape) return X_train,X_test,y_train,y_test def seq2seqModel(X,step): ''' 序列到序列堆叠式LSTM模型 ''' model=Sequential() model.add(LSTM(256, activation='relu', return_sequences=True,input_shape=(step,X.shape[2]))) model.add(LSTM(256, activation='relu')) model.add(Dense(X.shape[2])) model.compile(optimizer='adam', loss='mse') return model if __name__=='__main__': #数据集加载 with open('dataset.txt') as f: data_list=[one.strip().split(',') for one in f.readlines()[1:] if one] dataset=[] for i in range(len(data_list)): dataset.append([float(O) for O in data_list[i][1:]]) dataset=np.array(dataset) step=7 X_train,X_test,y_train,y_test=dataSplit(dataset,step) model=seq2seqModel(X_train,step) model.fit(X_train,y_train,epochs=50,verbose=0) # test=[ # [30.0,58.0,7.0,24.0,0.9,83.0,103.0], # [43.0,72.0,6.0,23.0,1.1,85.0,103.0], # [66.0,105.0,6.0,22.0,1.3,134.0,103.0], # [54.0,94.0,7.0,27.0,1.1,125.0,103.0], # [64.0,90.0,6.0,19.0,1.2,127.0,103.0], # [59.0,92.0,6.0,20.0,1.1,126.0,103.0], # [61.5,91.0,6.0,19.5,1.15,134.0,103.0] # ] # #真实值 [38.0,66.0,5.0,17.0,1.2,138.0,103.0] # test=np.array(test) # test=test.reshape((1,step,7)) # y_pre=model.predict(test,verbose=0) # print('y_pre: ',y_pre) future=predictFuture(model,dataset,7,step,60) for one in future: print('one: ',one) dataset=[] for i in range(len(data_list)): dataset.append([float(O) for O in data_list[i][1:]]) D1=[one[0] for one in dataset] D2=[one[0] for one in future] plt.plot(list(range(len(D1))),D1,label='F1 True') plt.plot(list(range(len(D1),len(D1)+len(D2))),D2,label='F1 Future Predict') plt.legend() plt.title('Data True and Predict Cruve') plt.savefig('demo.png')我们在代码中提供了单个样本的测试样例,如下所示:
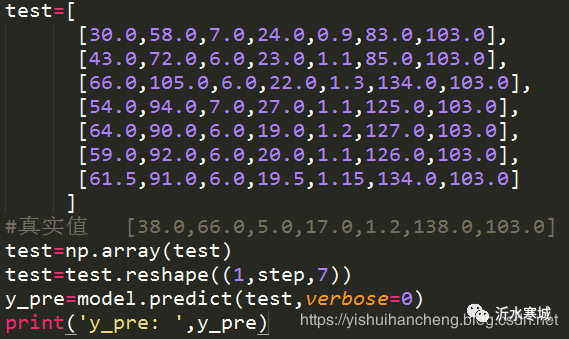
测结果如下:
接下来我们基于滚动预测对未来60个时刻的数据进行了预测分析,部分输出截图如下:

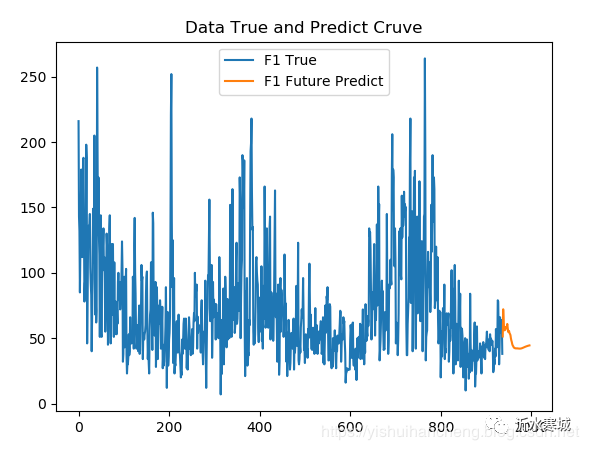
为了对比分析,我们绘制了原始数据曲线和预测的数据曲线,如下图所示:
最后
以上就是谨慎香水最近收集整理的关于lstm预测模型_Python实现多变量序列堆叠式LSTM模型,并实现未来多时刻预测的全部内容,更多相关lstm预测模型_Python实现多变量序列堆叠式LSTM模型内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复