1. 语音编解码介绍
声音编码就是将模拟语音信号转换成数字化语音信号的过程。
声音解码就是将数字化语音信号转换输出为模拟语音信号的过程。将模拟连续的声音信号转换成数字信号这个过程叫做音频数字化,它一般需要完成采集,量化,编码三个步骤,如图示:
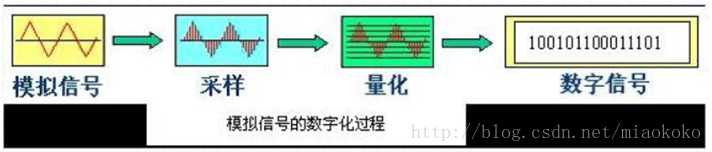
采 样
采样就是从一个时间上连续变化的模拟信号中取出若干个有代表性的样本值,来代表这个连续变化的模拟信号,如图示:
量 化
采样只是解决了音频波形信号在时间轴(横坐标)上把一个波形切成若干等份的数字化问题,还需要用某种数字化来表示在某个时刻声波幅度的电压值大小,该值的大小影响音量的高低。对声波波形幅度的数字化表示成称为“量化”。量化的过程就是将采样后的信号按整个声波的幅度划分成有限个区段的集合,把落入某个区段的样值归为一类,并赋予相同的量化值,常见有8bit和16bit来划分纵轴。8bit表示把纵轴划分为256个量化等级,量化位数越高,量化值越接近采样值,其精度越高,但要求的信息存储量就越大。
量化又分两种:均匀量化和非均匀量化
均匀量化来量化输入信号时,无论对大的输入信号还是小的输入信号,均采用相同的量化间隔,这样要想既适应幅度大的输入信号又保证量化精度,只能增加量化位数。
非均匀量化是指在大的输入信号时采用较大的量化间隔,小的输入信号时采用较小的量化间隔,这样就能在保证精度的前提下采用较小的量化位数。非均匀量化方法下输入信号幅度和量化输出数据之间的关系有两种描述方法:u律压缩算法和A律压缩算法。
编 码
采样、量化后的数据还不是数字信号,需要把它转化成数字脉冲,这个过程称为编码。音频编码方法归纳起来有3类: 波形编码,它尽量保持输入波形不变,即重建的语音信号基本与原始语音信号相同,压缩比较大,但音质还原较好。常见有 PCM,DPCM,ADPCM
参数编码,它要求重建的语音信号听起来与输入语音一样,但波形可以不同,它是以语音信号产生的数学模型为基础的一种编码方式,压缩比较高。常见有 LPC
混合编码,是综合了波形编码的高音质和参数编码的高压缩率的优点的一种混合编码方式,它是目前低码率编码的方向。常见有MPLPC
常见语音压缩技术标准与对应音质要求
| 分类 | 标准 | 说明 |
| 电话语 音质量 | G.711 | 采样8kHz,量化8bit,码率64kbps |
| G.721 | 采用ADPCM编码,码率32kbps | |
| G.723 | 采用ADPCM有损压缩,码率24kbps | |
| G.728 | 采用LD-CELP压缩技术,码率16kbps | |
| 调幅广 播质量 | G.722 | 采样16kHz,量化14bit,码率224(64)kbps |
| 高保真 立体声 | MPEG 音频 | 采样44.1kHz,量化16bit,码率705kbps (MPEG三个压缩层次,384-64kbps) |
| 采样频率 (kHz) | 量化位数 (bit) | 数据量(KB/s) | |
| 单声道 | 立体声 | ||
| 11.025 | 8 | 10.77 | 21.35 |
| 16 | 21.53 | 43.07 | |
| 22.05 | 8 | 21.53 | 43.07 |
| 16 | 43.07 | 86.13 | |
| 44.1 | 8 | 43.07 | 86.13 |
| 16 | 86.13 | 172.27 | |
采样频率决定着音域(高音和低音)的宽广度
量化位数决定着音质的还原程度,即影响音效
2. 音频电路设计参考
根据声音流向不同,音频电路大致要实现如下两块功能
1) 录音功能:声音的流向是

2) 播放功能:声音的流向是

以上电路中音频编解码芯片,比如 es8388,它通过I2S接口将数字语音送给语音处理单元,因此只有具有I2S接口的CPU都可以作为语音处理单元,比如esp32。功放芯片比如mix3001,如果解码输出直接接耳机的,可以不需要功放。
3. 本文参考
http://blog.csdn.net/mianhuantang848989/article/details/39673017
最后
以上就是彪壮母鸡最近收集整理的关于语音编解码过程概述的全部内容,更多相关语音编解码过程概述内容请搜索靠谱客的其他文章。








发表评论 取消回复