尽量减少网络io 和磁盘io占用cpu资源的时候cpu能去做别的事 提升CPU利用率
ps:为什么要使用多线程, 就是为了在磁盘或者网络IO的时候CPU能去做其他的事,在单线程的时候 无关IO的时候 无需多线程 如果多核 使用多线程的话 可以几个线程同时工作 提升CPU利用率.
1. 自用代码优化
- 常用思路
@Test
Integer sellpOne(Integer time){
System.out.println("调用----");
try {
Thread.sleep(time);
System.out.println("调用完成");
return time;
} catch (Exception e) {
System.out.println(e.getMessage());
}
return time;
}
@Test
void jumpTimeOne() {
long startTime = System.currentTimeMillis();
sellpOne(1000);
sellpOne(1000);
sellpOne(1000);
System.out.println("所用时间"+(System.currentTimeMillis()-startTime));
}
上面这一段代码 就是平常写程序所用代码,耗时3s多 结果
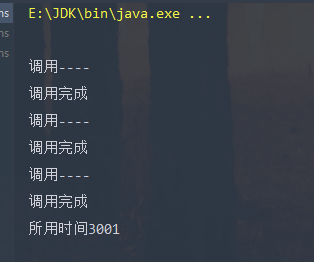
- 上面的代码只用了一个线程,当一个方法执行完成之后才能执行下一个方法,线程就阻塞在这里 造成时间非常的长,上面我们这里 另一个方法的执行并不依赖上一个方法的返回值,相互也不影响 我们可以引入线程池,但是只是引入线程池的话 我们这里不能知道方法的返回值这个返回值我们是有用的.所以还需要引入Future类。
- 线程池 这里引用的线程池可以有两种 ThreadPoolTaskExecutor 和 Executors 工具类中生产的线程池.
- Future 当非阻塞模型需要获取到结果时需要用到这个类
下面我们就可以吧代码改成这样
@Test
Integer sellp(Integer time){
System.out.println("调用----");
try {
Thread.sleep(time);
System.out.println("调用完成");
return time;
} catch (Exception e) {
System.out.println(e.getMessage());
}
return time;
}
@Test
void jumpTime() {
long startTime = System.currentTimeMillis();
ArrayList<Future<Integer>> list = new ArrayList<>();
ExecutorService threadPool = Executors.newCachedThreadPool();
list.add(threadPool.submit(() -> sellp(1000)));
list.add(threadPool.submit(() -> sellp(1000)));
list.add(threadPool.submit(() -> sellp(1000)));
list.forEach(future -> {
try {
Integer integer = future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
long endTime = System.currentTimeMillis();
System.out.println(endTime-startTime);
}
下面是执行结果
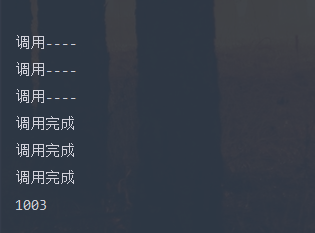
这里用了一个list 放入Future 然后把要执行的线程放进去 统一执行 之后再for循环获取返回值,这样的话执行的时间只是最长执行线程的那个时间 ,而不是所有方法执行时间的总和.
- 还可以使用多线程来对代码进行优化,CountDownLatch 和 Future 我认为不同的地方在于CountDownLatch可以对方法不同返回值进行异步,Future 已经确定了每一个执行线程的返回值 放在Future 列表中了.下面我们对代码进行优化.
//加了一个不同返回值的test
@Test
String sellpStr(Integer time){
System.out.println("调用----");
try {
Thread.sleep(time);
System.out.println("调用完成");
return time+"";
} catch (Exception e) {
System.out.println(e.getMessage());
}
return time+"";
}
@Test
void synThread() {
long startTime = System.currentTimeMillis();
//注意这里构造方法中数字是下面执行的数量
CountDownLatch countDownLatch = new CountDownLatch(3);
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(()->{
Integer sellp = sellp(1000);
//执行到这里会吧上面的数字减一
countDownLatch.countDown();
});
executorService.execute(()->{
Integer sellp = sellp(1000);
//执行到这里会吧上面的数字减一
countDownLatch.countDown();
});
executorService.execute(()->{
String sellp = sellpStr(1000);
//执行到这里会吧上面的数字减一
countDownLatch.countDown();
});
try {
//这里等待上面那个数字为0 的时候就说明都执行完了 里面可以设置超时时间
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println(endTime-startTime);
}
执行时间是
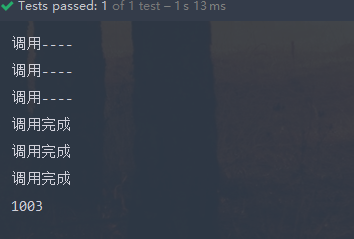
这样也是可以等到每一个方法执行完之后才返回的.执行时间也是每一个方法中使用时间最长的.
二.使用代码优化
- 使用stream流
因为java8新特性加了stream流,现在基本上我对list 的操作都使用流来完成,用着就非常舒服.
@Test
void streamTest() {
List<Integer> integerList = Arrays.asList(1, 5, 6, 2, 8, 4, 6, 9, 10);
integerList.stream().forEach(System.out::print);
System.out.println("n");
integerList.parallelStream().forEach(System.out::print);
}
使用 parallelStream 流的话 是并发执行的 但是不保证线程安全 和不保证代码执行的顺序
- 事务中调用方法异步
在一些方法中想要调用别的方法使用异步 但是这个时候又想等当前事务提交之后才执行 这个时候可以再方法中加这些 可以保证在调用方法的事务提交之后才执行
boolean synchronizationActive = TransactionSynchronizationManager.isSynchronizationActive();
if (synchronizationActive) {
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronizationAdapter() {
@Override
public void afterCommit() {
baseExecutor.execute(() ->执行的方法);
}
});
} else {
baseExecutor.execute(() -> 执行的方法);
}
return true;
三 总结
看着上面写的自以为的代码优化,其实是有一个误区的 以前一直以为只要是处理数据多 多开几个线程 这个时候就会非常快 将上面的sellp(10) 理解成了程序处理代码运行了10 毫秒 这样可以优化 其实如果只是程序运行 这样多开只是多核的在处理 真正是这里在进行 数据库读写 或者别的时候 这个时候多线程才是真正的用到了。
最后
以上就是健忘云朵最近收集整理的关于使用多线程Future 或者 CountDownLatch 对代码的优化的全部内容,更多相关使用多线程Future内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复