全文下载链接 http://tecdat.cn/?p=23947
分布滞后非线性模型(DLNM)表示一个建模框架,可以灵活地描述在时间序列数据中显示潜在非线性和滞后影响的关联。该方法论基于交叉基的定义,交叉基是由两组基础函数的组合表示的二维函数空间,它们分别指定了预测变量和滞后变量的关系。本文在R软件实现DLNM,然后帮助解释结果,并着重于图形表示。本文提供指定和解释DLNM的概念和实践步骤,并举例说明了对实际数据的应用(点击文末“阅读原文”获取完整代码数据)。
关键字:分布滞后模型,时间序列,平滑,滞后效应,R。
相关视频
1.简介
统计回归模型的主要目的是定义一组预测变量与结果之间的关系,然后估计相关影响。当依赖项显示某些滞后影响时,会进一步增加复杂性:在这种情况下,预测变量的发生(我们称其为暴露事件)会在远远超出事件周期的时间范围内影响结果。此步骤需要定义更复杂的模型以表征关联,并指定依赖项的时间结构。
1.1 概念框架
对滞后效应的适当统计模型的说明及其结果的解释,有助于建立适当的概念框架。这个框架的主要特点是定义了一个额外的维度来描述关联,它指定了暴露和结果之间在滞后维度上的时间依赖性。这个术语,借用了时间序列分析的文献,代表了评估影响滞后时暴露事件和结果之间的时间间隔。在长时间暴露的情况下,数据可以通过等距时间段的划分来构造,定义一系列暴露事件和结果实现。这种划分也定义了滞后单位。在这个时间结构中,暴露-反应关系可以用两种相反的观点中的任何一种来描述:我们可以说一个特定的暴露事件对未来的多个结果产生影响,或者说一个特定的结果可以用过去多个暴露事件的贡献来解释。然后,可以使用滞后的概念来描述向前(从固定结果到未来结果)或向后(从固定结果到过去的结果)的关系。
最终,滞后效应统计模型的主要特征是它们的二维结构:该关系同时在预测变量的通常空间和滞后的维度上进行描述。
1.2 分布滞后模型
最近,在评估环境压力因素的短期影响的研究中已经解决了滞后影响的问题:一些时间序列研究报告说,暴露于高水平的污染或极端温度会在其发生后的几天内持续影响健康( Braga等,2001;Goodman等,2004;Samoli等,2009;Zanobetti和Schwartz,2008)。
给定定义的数据时间结构和简单的滞后维度定义,时间序列研究设计可提供多种优势来处理滞后影响,其中时间划分是由等间隔和有序的时间点直接指定的。在这种情况下,滞后效应可以用分布滞后模型(DLM)来优雅地描述,该模型最初是在计量经济学中开发的(Almon 1965),最近在环境因素研究中用于量化健康效应(Schwartz 2000; Zanobetti et al。2000; 2007)。Muggeo和Hajat,2009年)。通过这种方法,可以使用多个参数来解释在不同时滞下的影响,从而将单个暴露事件的影响分布在特定的时间段内,
1.3 本文目的
统计环境R提供了一组用于指定和解释DLNM结果的工具。本文的目的是提供该程序包函数的全面概述,包括函数的详细摘要以及以实际数据为例的示例。该示例涉及1987-2000年期间两个环境因素(空气污染(臭氧)和温度)对死亡率的影响。在本文中,我重新考虑了定义DLNM,预测效果并借助图形函数解释结果的主要概念和实践步骤。
2.非线性和滞后效应
在本节中,我介绍了时间序列模型的基本公式,然后介绍了描述非线性效应和滞后效应的方法,后者通过简单DLM的模型来描述。
2.1 基本模型
时间序列数据的模型通常可以表示为:
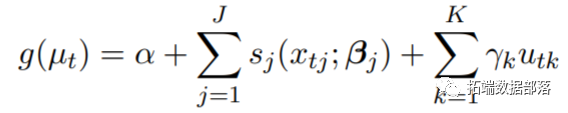
其中µt≡E(Yt),Yt是t = 1时的一系列结果...,n,假设来自指数族的分布。函数sj指定变量xj和线性预测变量之间的关系,该变量由参数向量βj定义。变量uk包含具有由相关系数γk指定的线性效应的其他预测变量
之前描述的数据说明性示例中,结果Yt是每日死亡计数,假定是泊松分布,其中E(Y)= µ,V(Y)= φµ。
臭氧和温度的非线性和滞后影响通过函数sj建模,该函数定义了预测变量和滞后变量两个维度之间的关系
2.2 非线性暴露-反应关系
DLNM开发的第一步是定义预测变量空间中的关系。通常,非线性暴露-反应依赖性通过适当的函数s在回归模型中表示。在完全参数化的方法中,提出了几种不同的函数,每个函数都具有不同的假设和灵活性。主要选择通常依赖于描述光滑曲线的函数,例如多项式或样条函数(Braga等,2001;Dominici等,2004)。关于线性阈值参数化的使用(Muggeo 2010; Daniels et al。2000); 或通过虚拟参数化进行简单分层。
所有这些函数都对原始预测变量进行了转换,以生成包含在模型中作为线性项的一组转换变量。相关的基础函数包括原始变量x的一组完全已知的转换,这些转换生成一组称为基础变量的新变量。代数表示可以通过以下方式给出:
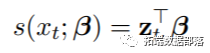
定义DLNM的第一步是在函数mkbasis()中执行的,该函数用于创建基础矩阵Z。此函数的目的是提供一种通用的方式来包含x的非线性效应。举例来说,我建立了一个将所选基函数应用于向量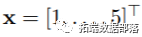 的基矩阵:
的基矩阵:
R> mkais(1:5, tpe = "s", df = 4, egree = 2, cenvlue = 3)
结果是一个列表对象,存储基础矩阵和定义该矩阵的自变量。在这种情况下,所选基准是具有4个自由度的二次样条,由参数类型df和度定义。
可以通过第二个参数类型选择不同类型的基础。可用的选项是自然三次方或简单的B样条(类型=“ ns”或“ bs”);虚拟变量层;多项式(“ poly”);阈值类型的函数和简单的线性(“ lin”)。参数df定义了基础的维数(基础的列数,基本上是转换后的变量的数目)。该值可能取决于参数“结点”。如果未定义,则默认情况下将结放置在等距的分位数上。自变量度数选择“ bs”和“ poly”的多项式度数。
参数cen和cenvalue用于使连续函数(类型“ ns”,“ bs”,“ poly”和“ lin”)的基准居中,如果未提供cenvalue,则默认为原始变量的均值。
2.3滞后效应
定义DLNM的第二步是指定函数,以对附加滞后维度中的关系进行建模,以实现滞后效果。在这种情况下,给定时间t的结果Yt可以用过去的暴露量xt-L来解释。给定最大滞后L时,附加滞后维度可以由n×(L +1)矩阵Q表示,例如:
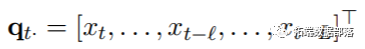
简单的DLM使用描述结果与滞后风险之间的依赖关系的函数来允许线性关系的滞后效应。
第二步通过函数mklagbasis()进行,该函数调用mkbasis()来构建基础矩阵C。例如:
R> mkgbais(mxlag =5,type ="strta", kots = c(2, 4))
在此示例中,在通过第一个参数maxlag将最大滞后固定为5之后,滞后向量0:maxlag对应于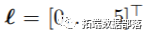 ,将自动创建并应用所选函数。
,将自动创建并应用所选函数。
3.定义DLNM
DLNM规范的最后一步涉及同时定义预测器和滞后两个维度中的关系。尽管非线性和滞后效应的术语不同,但这两个过程在概念上是相似的:定义表示相关空间中关系的基础。
然后,通过交叉基的定义来指定DLNM,交叉基是二维函数空间,同时描述了沿预测变量范围及其滞后维度的依存关系。首先,选择x的基函数得出Z,然后为x的每个基变量创建附加的滞后维度,从而生成一个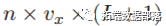 数组R˙。通过定义的C,DLNM可以表示为:
数组R˙。通过定义的C,DLNM可以表示为:
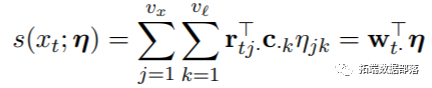
选择交叉基等于如上所述选择两组基函数,将其组合以生成交叉基函数。这是通过函数crossbasis()执行的,该函数调用函数mkbasis()和mklagbasis()分别生成两个基本矩阵Z和C,而不是通过张量积将它们组合起来以产生W。可以使用此函数指定臭氧和温度的两个交叉基。相关代码为:
basi.o3 <- crossbasis(o3 varype= "hthr"
+ vnots = 40, laty = "sata", lanot = c(2,6), mag= 10)
bai.te <- crossbasis(tmp varype = "bs",
+ vrgre 3, vad = 6 cevalu = 25 ladf = 5, malag = 30)在此示例中,臭氧的交叉基包括一个预测空间的阈值函数,线性关系超过40.3 µgr / m3,并且虚拟参数化假设沿滞后0-1、2-5和6-10的层具有恒定的分布滞后效应。相比之下,温度的选项是:以25摄氏度为中心的6 自由度的立方样条(默认为等距的结点),以及以5自由度的立方样条(默认为lagtype =“ ns”)(结为25℃)。默认情况下,最多30个滞后。
如果未设置中心值,则默认的中心点是预测变量的平均值(例如,对于上述温度的交叉基,温度为25℃)。该值代表来自DLNM的预期效果的参考。参考值的选择不影响模型的拟合,并且可以根据解释问题选择不同的值。
这些选择可以通过函数summary()进行检查。例如:
R> summary(basis.temp)
为了估计相应参数η,可以在通用回归函数的模型公式中包括交叉基矩阵。在该示例中,最终模型还包括一个自然立方样条,以模拟季节性趋势和长期趋势分量,代码是:
odel <- glmdeath ~ bais.temp+ basis.o +ns(tim 7 * 14) dw,
+ fmily = quasiposson())4.根据DLNM进行预测
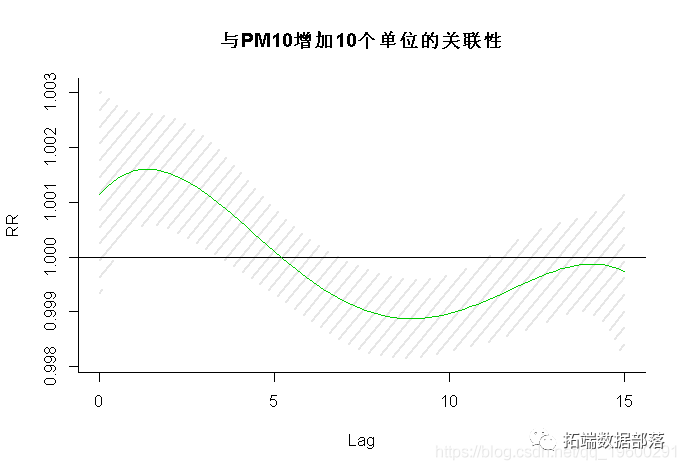
如第3节所示,DLNM的规范涉及暴露序列的复杂参数化,但是参数η的估算是使用常见的回归命令进行的。但是,定义沿两个维度的关系的此类参数的含义并不简单。可以通过预测在具有适当暴露值和L + 1滞后的网格上的滞后特定效果来辅助解释。此外,可以通过将滞后特定贡献相加来计算从滞后L到0持续暴露所预测的总体效果。预测的效果通过函数crosspred()在dlnm中计算。以下代码在示例中计算了对臭氧和温度的预测:
pre.o <- crosspred(basis, odel at = c(0:6,0., .3))传递给crosspred()的前两个参数是“ crossbasis”类的对象和用于估计的模型对象。像上面的第一个示例一样,可以通过at参数直接指定必须为其预测效果的暴露值向量。在这里,我选择了臭氧中从0到65 µgr / m3的整数,再加上所选阈值的值和10个单位以上的值(分别为40.3和50.3 µgr / m3)。然后,该函数调用crossbasis()来构建预测基准,并根据模型中的参数生成预测效果和标准误差。结果是“ crosspred”类的列表对象,该对象存储了预测的效果。它包括滞后效应矩阵和总体效应向量,以及相应的标准误差矩阵和向量。如第5节所示。例如,臭氧增加10个单位的总体效果表示为RR和95%置信区间,可以通过以下公式得出:
R> pred.o3$allRRfit["50.3"]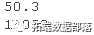
R> cbind(lRlow,alRigh)["50.3",]
5.描述DLNM
由DLNM估算的二维暴露-反应关系可能难以概括。关联的图形表示提供了一般描述。调用高级函数plot.default(),persp()和filled.contour()来生成散点图,3-D和等高线图。例如,臭氧和死亡率之间的关系可以通过RR进行总结,即每次滞后会比阈值高出10 µgr / m3。该图如图1(左)所示,可通过以下方式获得:
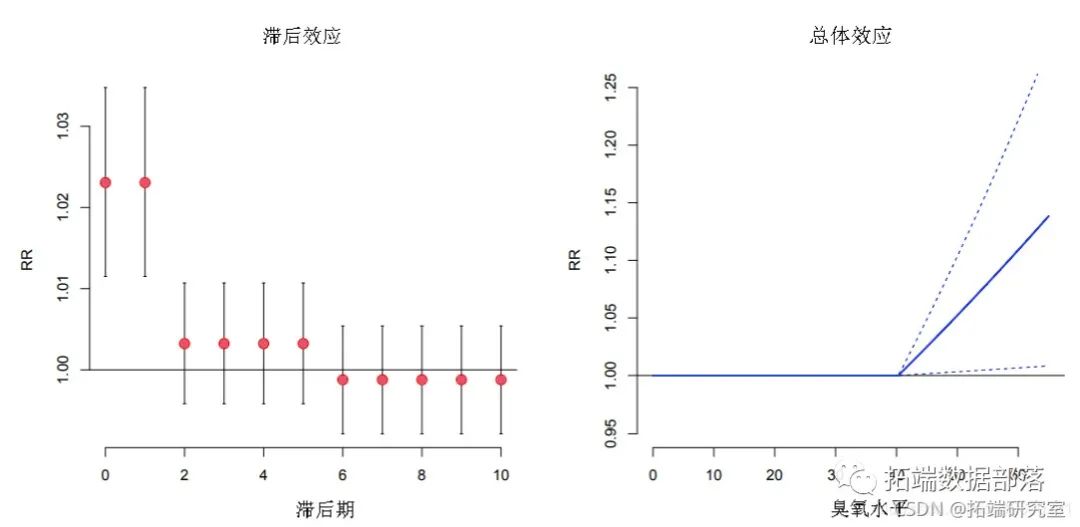
图1:在阈值(40.3 µgr / m3)以上的臭氧增加10个单位时,滞后效应(左)和总体效应(右)对死亡率的影响。
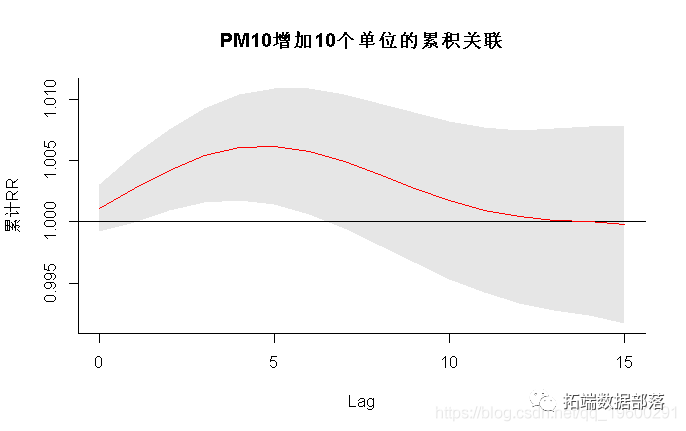
R> plot(re.o3)参数ptype =“ slices”指定图的类型,在这种情况下,沿着滞后空间在预测值var = 50.3处的预测效果矩阵的切片,对应于在40.3 µgr / m3的阈值之上增加了10个单位。自变量ci表示置信区间的图类型。如果使用cumul = TRUE,则绘制累积效果。
根据概念定义,可以使用两种不同的观点来读取图1中的左图:它表示在第t天以50.3 µgr / m3的臭氧进行单次暴露后,未来每一天的风险增加。
点击标题查阅往期内容

R语言分布滞后线性和非线性模型(DLMs和DLNMs)分析时间序列数据

左右滑动查看更多
01
02
03
04
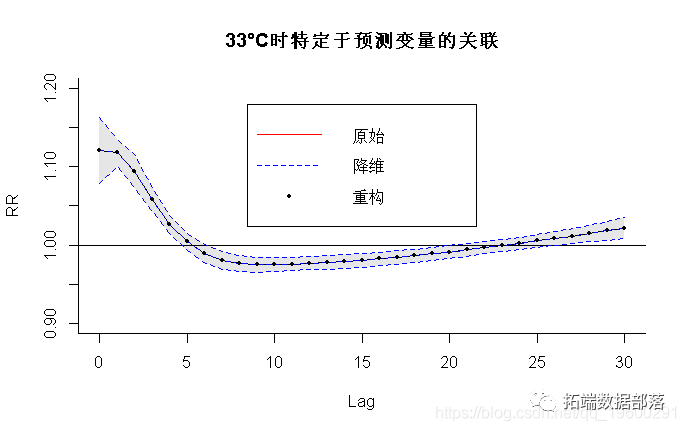
或者,可以绘制总体效果,该总体效果是通过使用参数ptype =“ overall”将滞后效应相加得出的:
R> plot(pred )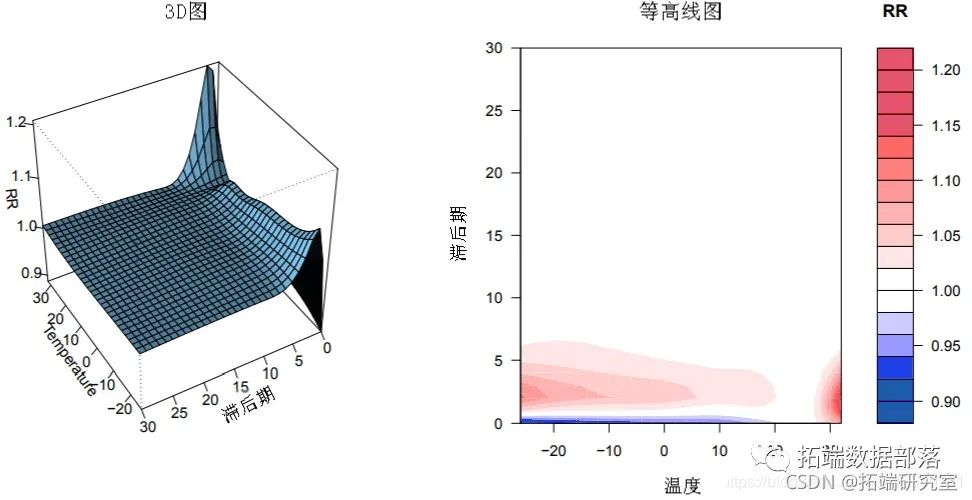
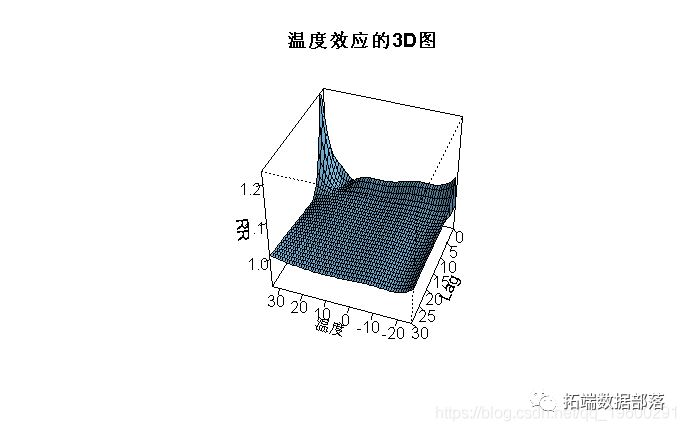
图2:温度和全因死亡率之间的暴露-反应关系的三维图,以25°C为参考。
一种更详细的方法来表示温度与死亡率之间的平滑关系,其中样条函数已用于定义这两个维度的相关性。可以使用3-D和等高线图对这种复杂的依赖关系进行一般描述,该图说明了由预测效果的整个网格给出的效果表面。所示的图是通过以下方式获得的:
R> plot(pred.temp, "contour")参考点(此处为25℃)是crossbasis函数在crossbasis()中中心的值。
三维图或等高线图提供了关系的全面摘要,但在表示特定预测值或滞后值的影响方面的能力有限。下面给出了更全面的图,该图片通过以下方式获得:
R> plot(pred.temp, "slices
+ ci.g , ltensity =20 colr(0)))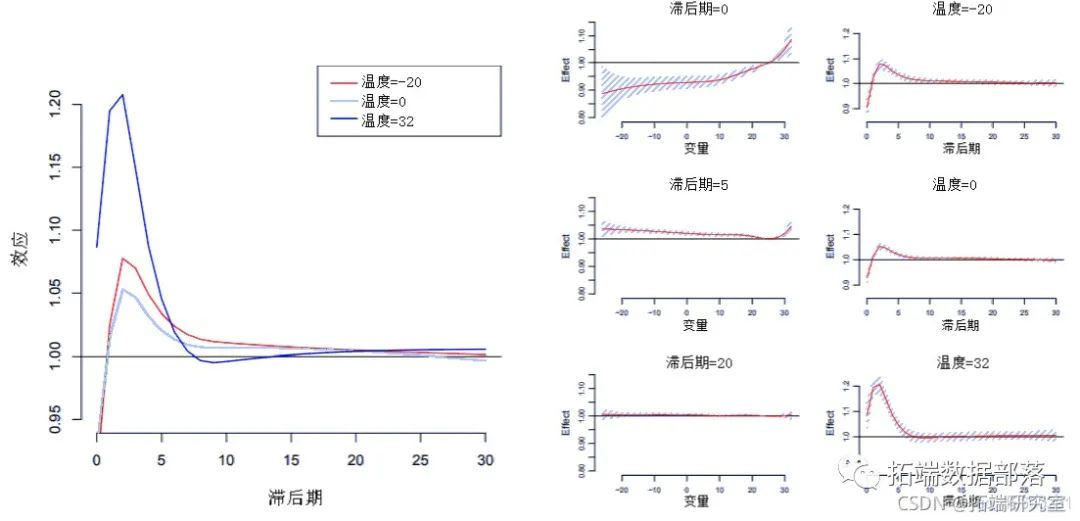
图3(左)显示了由plot()和lines()中的参数var选择的温度值的预测滞后效应影响。另外,图3(右)显示了针对特定滞后的沿温度的预测效应的多重曲线图(左),以及图3(右)中绘制的相同滞后效应,以及99%的置信区间。
这些图表显示了高温和低温影响的不同模式,高温的影响非常强烈且迅速,低温影响更为延迟,在最初的滞后中为负。
6.建模策略
DLNM框架提供了机会,可以通过为预测变量和滞后变量两个维度中的每个维度选择基本函数来指定广泛的模型选择。前面各节中说明的示例代表了一种潜在的建模替代方法。为了讨论该方法的灵活性以及模型选择的相关问题,下面显示了与不同模型的比较,以估计与温度的关联。具体来说,为预测变量的空间选择多项式和层次函数,同时保持相同的自然三次样条,以模拟长达30天的滞后分布的滞后曲线。指定交叉基础,运行模型并预测效果的代码为:
R> basis.temp2 <- crossbasis(emp, vrtpe = "poly",
R> model2 <- update(mdel, .~. - bsis.emp + baiste2)
R> model3 <- updat(model .~. -bais.tmp + bass.mp3)对于预测变量,第一种方法建议使用与第5节中的原始三次样条相同的自由度的多项式函数。第二种模型基于一个更简单的双阈值函数,将单个阈值置于25°C,之前确定为最低死亡率。此选择还便于模型比较,因为这是其他两个连续函数的中心点。这三个模型估计的总体效果显示在由代码产生的图4(左)中:
R> plot(pre.temp, "overall", ylim = c(0.5, 2.5), ci = "n", lwd = 1.5,
+ main = "Overall effect")
R> lines(pretemp2, "overall", col = 3, lty = 2, lwd = 2)
R> lines(pretemp3, "overall", col = 4, lty = 4, lwd = 2
+ p, c("natural spline", "polynomial", "double threshold",
+ col = 2:4, lty = c(1:2, 4), lwd = 1.5, inset = 0.1, cex = 0.8)正如预期的那样,替代模型会产生不同的结果。特别是,如果与具有等距结点的三次样条进行比较,则多项式模型会估计出低温的“摆动”关系。取而代之的是,这两个函数提供了非常接近的高温影响估算值。相反,虽然双阈值模型的线性假设似乎足以模拟低温的依赖性,但有一些证据表明,这种方法往往会低估热的影响。估计的分布滞后曲线的第二次比较如图4所示(右),如下所示:
R> plot(pred, slices", va =32, im =95 .2="n"尽管在所有三个模型中都为滞后空间选择了完全相同的函数,但对预测变量的不同选择提供了分布滞后曲线的不同估计值,与32°C的参考点相比,代表了32°C的影响。
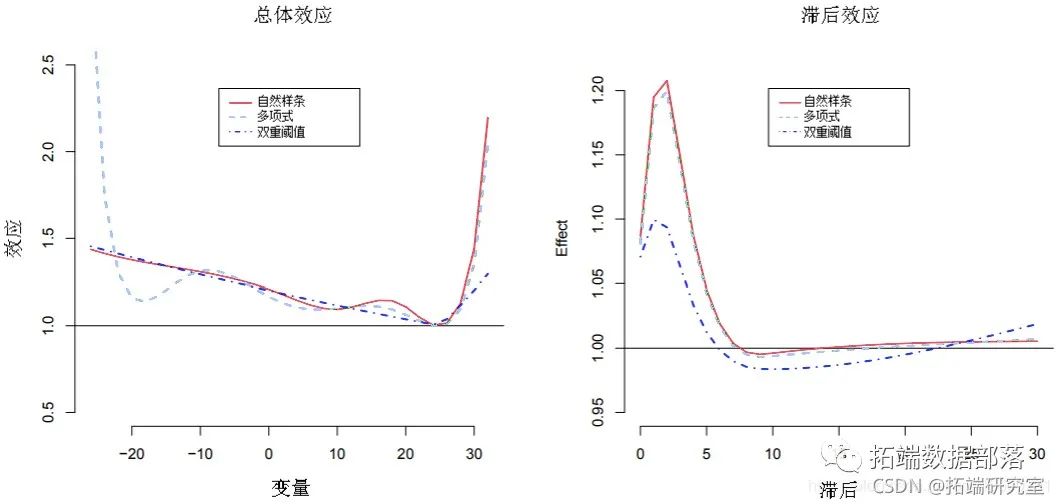
图4:温度为32°C时的总体效应(左)和滞后特异性效应(右)对3种替代模型的全因死亡率的影响(以25°C为参考)。芝加哥1987-2000。
特别是,样条曲线和多项式模型会产生非常相似的效果(正如预期的那样,考虑到高温度尾部曲线在其他维度上的拟合几乎相同),而双阈值模型的曲线显示出截然不同的形状。具体而言,由于缺乏此模型的灵活性,因此暗示收获效果(较长滞后的负估计)可能表示伪像。
缺乏通用标准,无法在可用的选择中选择总结关联的最佳模型,从而减轻了对各种替代产品的规格要求的这种丰富性。在上面的示例中,我对样条线模型表现出了明显的偏爱。这种选择既基于对函数属性的了解,例如灵活性和稳定性,又基于给出图4所示结果的合理论据。但是,该结论是有问题的,而不是基于可靠的和一般的统计选择标准。此外,结论是基于几个先验的选择,就像阈值位置或结数或多项式次数一样。
通常,在DLNM中,可以描述两个不同的选择级别。第一个涉及不同函数的规范。如上所示,该选择应既基于假设的暴露反应形状的合理性,又基于复杂性,可概括性和易于解释之间的折衷。第二级重点关注特定函数内的不同选择,例如用于定义样条曲线基的结的数量和位置。后者更难解决,尽管不是DLNM开发所固有的。一些研究人员在时间序列分析中研究了这个问题,提出了基于信息准则(Akaike,Bayesian和其他变体),偏自相关或(广义)交叉验证的方法(Peng等,2006;Baccini等,2006)。2007)。用户可以在DLNM中应用相同的方法,但是他应该记住,这些模型的二维性质带来了额外的复杂性,例如最大滞后的定义。此外,关于执行不同准则的依据还不是结论性的(Dominici等人,2008年)。需要进一步研究以提供有关DLNM中模型选择的一些指导。
可以建议使用其他方法。Muggeo(2008)提出了一个模型,该模型具有对预测变量空间进行约束的分段参数化,以及基于惩罚性样条的双重惩罚基于分布滞后的参数化。此方法包括自动选择阈值和分布滞后曲线的平滑度,并且已在R(Muggeo 2010)中完全实现。这种方法与灵活的DLNM的比较可以放宽对预测变量维度上形状的假设,从而可以提供有关此关系的其他一些见解。
7.数据要求
本文介绍的DLNMs框架是为时间序列数据开发的。(1)中基本模型的一般表达式允许将此方法应用于(广义)线性模型(GLM)中的任何族分布和链接函数,并扩展到广义加法模型(GAM)或基于广义估计方程的模型(GEE)。但是,DLNM的当前实现需要一系列等距,完整和有序的数据。
还使用选定滞后时间段中包含的先前观察值来计算一系列转换变量中的每个值。因此,将转换变量中的第一个最大滞后观测值设置为NA。允许在x中缺少值,但是由于相同的原因,将相同且下一个maxlag转换后的值设置为NA。尽管正确,但对于零散的缺失观测值存在的较长滞后时间的DLNM,这可能会产生计算问题。在这种情况下,可以考虑一些插补方法。
dlnm的主要优点之一是,用户可以使用标准回归函数执行DLNM,只需在模型公式中包括交叉基矩阵即可。通过函数lm(),glm()或gam(),可以直接使用它。但是,用户可以与数据的时间序列结构兼容地应用不同的回归函数。这些函数应该具有针对coef()和vcov()的方法,或者用户必须提取参数并将其包含在crosspred()的参数coef和vcov中(请参见第4节)。
8.最终结论
DLNM类代表描述描述非线性效应和滞后效应的现象的统一框架。该模型系列的主要优点是在一个独特的框架中统一了许多以前的方法来处理滞后效应,还为关系提供了更灵活的选择。DLNM的规范仅涉及选择两个基数以生成(5)中的交叉基函数,例如,包括线性阈值,层次,多项式和样条变换。
交叉基和参数估计的分离提供了多个优点。首先,如示例中所示,可以通过交叉基函数转换多个显示滞后效果的变量,并将其包含在模型中。其次,可以使用标准回归命令进行估计,并使用默认的诊断工具和相关函数集。更重要的是,此实现提供了一个开放平台,可以在其中实现使用不同回归命令指定的其他模型,来帮助在其他情况下或研究设计中开发方法。

本文摘选《R语言分布滞后线性和非线性模型(DLNM)分析空气污染(臭氧)、温度对死亡率时间序列数据的影响》,点击“阅读原文”获取全文完整资料。
点击标题查阅往期内容
R语言中的分布滞后非线性模型DLNM与发病率和空气污染示例
【视频】R语言中的分布滞后非线性模型(DLNM)与发病率,死亡率和空气污染示例
R语言分布滞后线性和非线性模型(DLNM)分析空气污染(臭氧)、温度对死亡率时间序列数据的影响
R语言分布滞后线性和非线性模型(DLMs和DLNMs)分析时间序列数据
R语言分布滞后非线性模型(DLNM)空气污染研究温度对死亡率影响建模应用
R语言分布滞后非线性模型(DLNM)研究发病率,死亡率和空气污染示例
R语言分布滞后线性和非线性模型(DLM和DLNM)建模
R语言广义相加模型 (GAMs)分析预测CO2时间序列数据
Python | ARIMA时间序列模型预测航空公司的乘客数量
R语言中生存分析模型的时间依赖性ROC曲线可视化
R语言ARIMA,SARIMA预测道路交通流量时间序列分析:季节性、周期性
ARIMA模型预测CO2浓度时间序列-python实现
R语言基于递归神经网络RNN的温度时间序列预测
R语言用多元ARMA,GARCH ,EWMA, ETS,随机波动率SV模型对金融时间序列数据建模
R语言神经网络模型预测车辆数量时间序列
卡尔曼滤波器:用R语言中的KFAS建模时间序列
在Python中使用LSTM和PyTorch进行时间序列预测
R语言从经济时间序列中用HP滤波器,小波滤波和经验模态分解等提取周期性成分分析
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
Python中的ARIMA模型、SARIMA模型和SARIMAX模型对时间序列预测
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言多元Copula GARCH 模型时间序列预测
欲获取全文文件,请点击左下角“阅读原文”。


![]()

最后
以上就是儒雅铃铛最近收集整理的关于分布滞后线性和非线性模型(DLNM)分析空气污染(臭氧)、温度对死亡率时间序列数据的影响...全文下载链接 http://tecdat.cn/?p=23947 1.简介1.1 概念框架1.2 分布滞后模型1.3 本文目的2.非线性和滞后效应2.3滞后效应3.定义DLNM4.根据DLNM进行预测5.描述DLNM6.建模策略7.数据要求8.最终结论的全部内容,更多相关分布滞后线性和非线性模型(DLNM)分析空气污染(臭氧)、温度对死亡率时间序列数据的影响...全文下载链接 http://tecdat.cn/?p=23947 1.简介1.1内容请搜索靠谱客的其他文章。








发表评论 取消回复