整理一下tensorflow中的一些常用函数,方便自己查找
张量Tensor的产生
- tf.constant(张量内容,dtype=数据类型):创建一个张量
- tf.convert_to_tensor(数据名,dtype=数据类型):将numpy的数据类型转换为Tensor数据类型
- tf.zeros(维度):创建全为0的张量
- tf.ones(维度):创建全为1的张量
- tf.fill(维度,指定值):创建全为指定值的张量
- tf.random.normal(维度,mean=均值,stddev=标准差):生成正态分布的随机数,默认均值为0,标准差为1
- tf. random.truncated_normal(维度,mean= 均值,stddev= 标准差):生成截断式正态分布的随机数

8.tf. random. uniform( 维度,minval= 最小值,maxval= 最大值):生成均匀分布随机数 [ minval, maxval )
(左闭右开)
张量的运算
- tf.cast ( 张量名,dtype=数据类型):强制tensor转换为该数据类型
- tf.reduce_min (张量名):计算张量维度上元素的最小值
- tf.reduce_max ( 张量名):计算张量维度上元素的最大值
- tf.reduce_mean ( 张量名,axis= 操作轴):计算张量沿着指定维度的平均值
- tf.reduce_sum ( 张量名,axis= 操作轴):计算张量沿着指定维度的和
- tf.Variable( 初始值): tf.Variable () 将变量 将变量 标记为“可训练” ,被标记的变量会在反向传播
中记录梯度信息。神经网络训练中,常用该函数标记待训练参数。
数学运算
-
tf.add ( 张量1 ,张量2):实现两个张量的对应元素相加
-
tf.subtract ( 张量1 ,张量2):实现两个张量的对应元素相减
-
tf.multiply ( 张量1 ,张量2):实现两个张量的对应元素相乘
-
tf.divide ( 张量1 ,张量2):实现两个张量的对应元素相除,张量1为被除数
需要额外注意,只有维度相同的张量才可以做四则运算 -
tf.square ( 张量名):计算某个张量的平方
-
tf.pow ( 张量名,n次方数):计算某个张量的n次方
-
tf.sqrt (张量名):计算某个张量的开方
-
tf.matmul( 矩阵1 ,矩阵2):实现两个矩阵的相乘
注意: tf.matmul()和tf.multiply ( 张量1 ,张量2)的运算不一样,前者是矩阵上的运算,计算方法和线性代数里面矩阵相乘相同,而后者只是对应元素相乘。 -
tf.data.Dataset.from_tensor_slices:切分传入张量的第一维度,生成输入特征/标签对,构建数据集 标签对,构建数据集data = tf.data.Dataset.from_tensor_slices(( 输入特征, 标签))
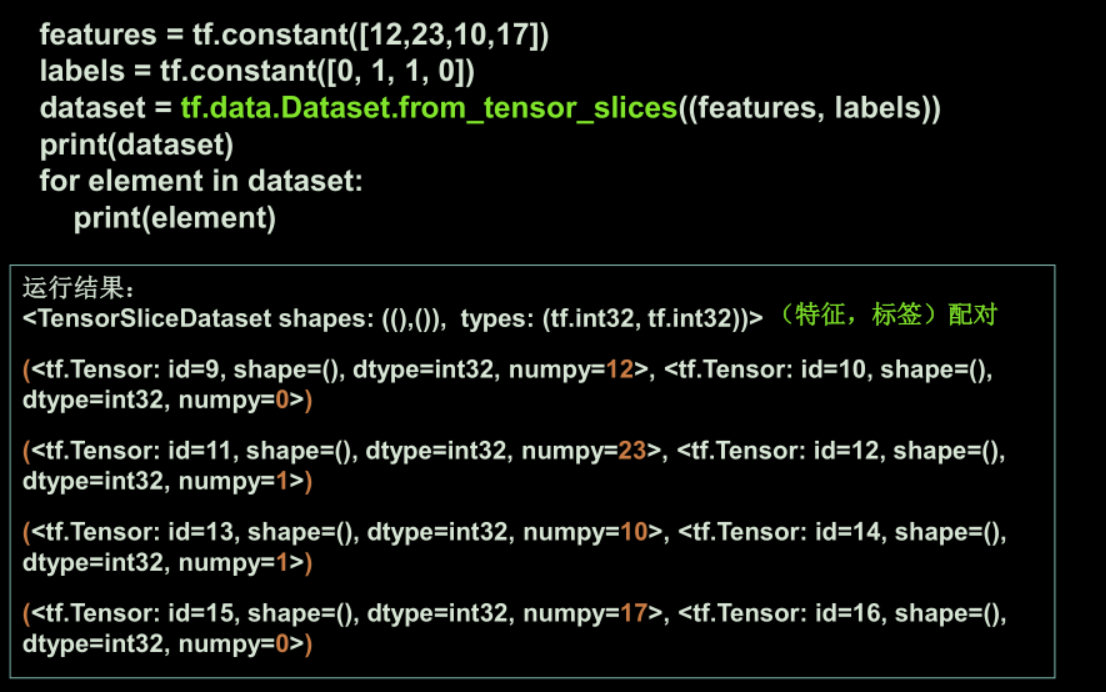
-
tf.GradientTape():with 结构记录计算过程,gradient求出张量的梯度

-
enumerate():enumerate 是python 的内建函数,它可遍历每个元素(如列表、元组 如列表、元组或字符串 或字符串), , 组合为:索引 元素,常在 ,常在for循环中使用。

-
tf.one_hot ( 待转换数据, depth=几分类): tf.one_hot() 函数将待转换数据,转换为one-hot形式的数据输出。

-
tf.nn.softmax(x):当 当n 分类的n个输出 个输出 ( (y 0 , ,y 1 , …… y n-1 )通过 )通过softmax( ) 函数,便符合概率分布了。
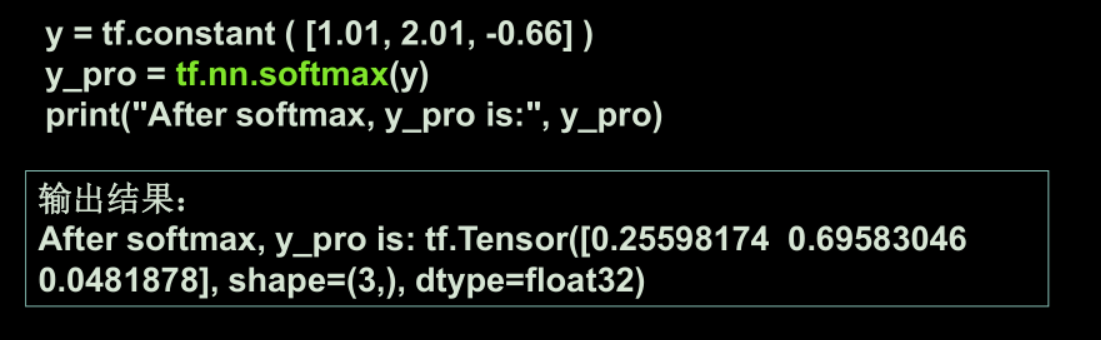
-
assign_sub():赋值操作,更新参数的值并返回。调用assign_sub 前,先用 tf.Variable 定义变量 w 为可训练(可自更新)。

-
tf.argmax ( 张量名,axis= 操作轴):返回张量沿指定维度最大值的索引

最后
以上就是机智诺言最近收集整理的关于tensorflow常用函数整理的全部内容,更多相关tensorflow常用函数整理内容请搜索靠谱客的其他文章。








发表评论 取消回复