音视频会议,直播连麦以及短视频已经成为人们工作、教学以及娱乐的一部分,其背后都离不开音视频实时通信等关键技术的广泛应用。音频方面,可预见的是客户业务形式的多样性,环境的复杂性,以及接入设备的差异性会带来的一系列问题,我们意识到单一场景的技术与策略已经无法满足日趋暴露的线上问题,音频前处理 3A(AEC,ANS, AGC)算法走向全场景自适应才是唯一出路。为了解决复杂环境中的噪声问题,我们上线了 AliCloudDenoise - 语音增强算法,补强了传统降噪技术在非稳态噪声抑制方面的缺陷;为了解决音量问题,我们上线了 AliAGC - 自动增益控制算法,极大地改善了不同环境、设备、场景下音量不统一的问题,相比传统 WebRTC AGC 更加智能。
现有 WebRTC AGC 算法存在什么问题?
在《详解 WebRTC 高音质低延时的背后 — AGC(自动增益控制)》一文中对 WebRTC AGC 不同模式的核心原理做了深入的解读,其以固定增益模式为基础,扩展出数字 / 模拟自适应模式都存在不同程度的响应过激和不及时、补偿增益估计不精准等稳定性问题,技术细节这里就不展开了,从方向上看 WebRTC AGC 追求自适应的目标是对的,也是我们首先需要优化的部分,我先来看看线上都遇到了哪些痛点问题:
(1)音量不统一的问题
多人会议中,音频采集效果受到设备差异性、环境以及说话人自身等诸多因素影响,如果仅采用固定增益方案,听感上就会出现不同说话人音量不统一的问题,持续的小音量或突然的超大音量只能通过频繁调节设备播放音量按键来解决。在直播间 / 短视频之间切换时,也难免会遇到类似问题。
(2)环境中的嘈杂人声被过度放大的问题
在办公室、卖场等开放环境,主讲人开麦但是未发言时,周围的嘈杂人声很可能会被当做主讲人声音,传统的自适应方案会触发增益补偿,导致整个过程中嘈杂声非常明显,严重影响会议、直播的体验。
(3)直播连麦等娱乐场景,背景音乐音量起伏的问题
直播连麦等娱乐场景中播放背景音乐是极为常见的,很多主播都会使用声卡,一般业务层都选择关闭 AGC,将调音量的权利交给主播,宏观上看并不能解决(1)中不同直播间音量差异较大的问题,主播甚至都难以察觉爆音和音量小的情况,因此在这类场景中开启 AGC 是必要的。但传统的增益补偿策略不会区分人声和背景音乐,必然会带来音乐音量的起伏问题,对于观众来说这是不可接受的,控制好存在音乐的场景是 AGC 面临的最大挑战。
由此可见,鲁棒的自适应模拟 / 数字增益是非常基础的,仅能解决(1)中音量不统一的问题,我们还需要通过新增其他的方法或模块去应对具体场景中的音量问题。
AliAGC 算法优化方向
阿里云视频云音频技术团队为了追求极致的音视频通话体验,AGC 作为音频 3A 算法中最后一环,我们提出了如下要求:
① 增益补偿以及自适应调节策略响应迅速,做到秒级收敛;
② 增益范围大,能覆盖绝大多数移动端和 PC 端设备;
③ 在嘈杂、音乐等复杂场景,稳定性好,不触发误调;
④ 功耗低,音质无损;
为了实现上述目标,我们基于 WebRTC 中 AGC 框架(具体细节可以查看《详解 WebRTC 高音质低延时的背后 — AGC(自动增益控制)》)做了如下主要优化:
① 数字增益自适应方案:新增了 VAD/ 包络检测模块用于实时计算音频信号音量,用于快速确定最大的增益上限,从而指导当前数字增益调节;
② 模拟增益自适应方案:基于检测到的人声 / 底噪音量,用于指导模拟增益调节,从而控制采集底噪和人声音量处于目标范围;
③ 场景自适应方案:新增语音 / 嘈杂 / 音乐等多任务检测模块,动态估计当前嘈杂声水平、音乐等状态,用于激活相应的调节策略,使算法适应当前绝大多数应用场景。
④ 音频统计数据建设:新增了人声 / 噪声音量统计等数据和事件检测,为其他模块提供准确的数据支持同时,也通过数据上报通道完善埋点,丰富后台仪表盘。
AliAGC 算法效果
基于以上难点问题,下面来看看优化后 AliAGC 的效果:
(1)收敛速度快
采集音量极小的情况下:-30dB → -3db 需要 5s - 8s;常规情况下 : -20dB → -3db 仅需要 3s - 5s。
反过来,当采集音量较大,数字增益严重过剩时,下调的收敛速度同样很快。绝大多数场景基本是说一句的时间,就收敛了。
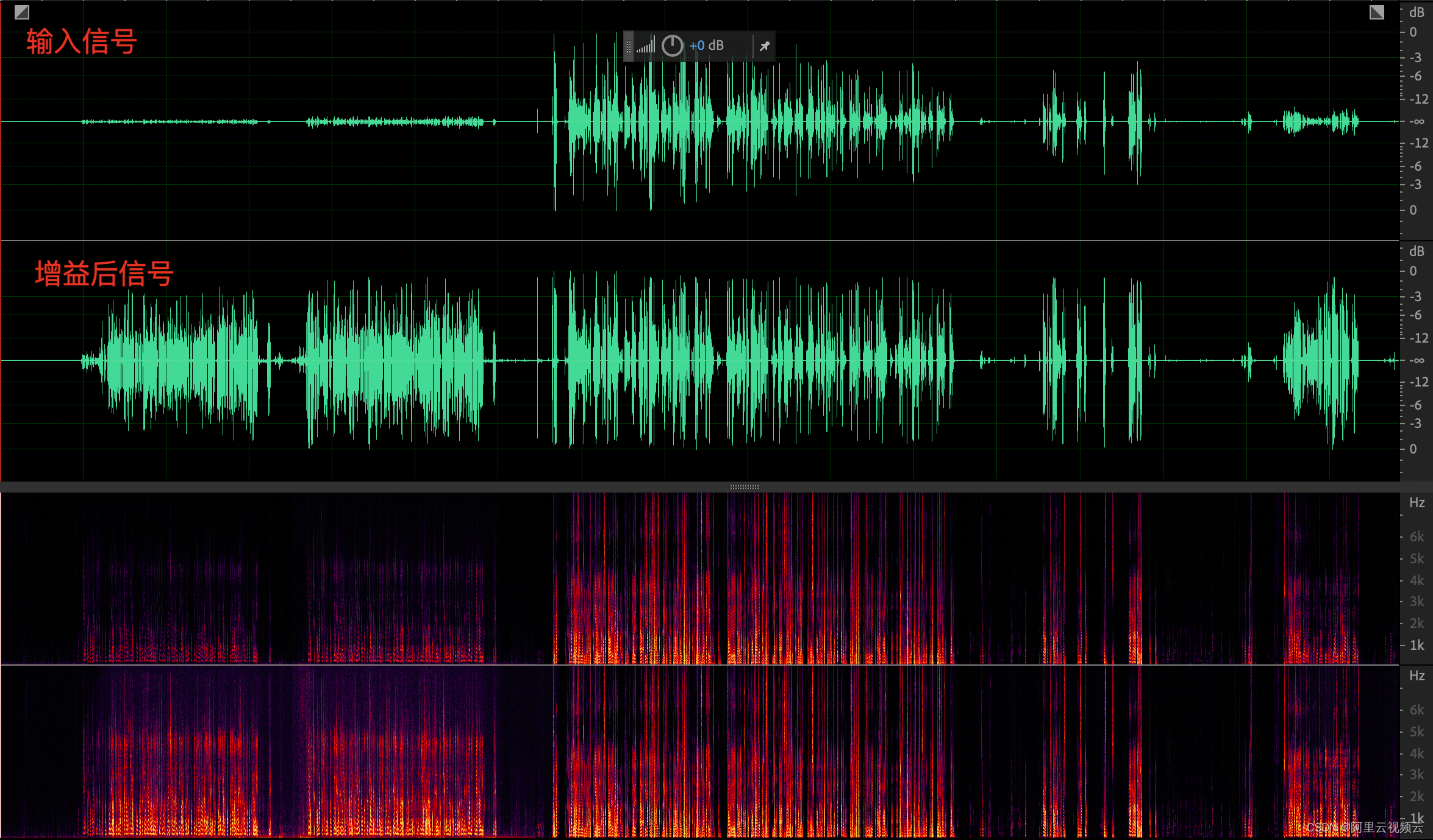
(2)数字增益自适应更新能力
前面的 case 中已经可以看出,初段是极小的音量(<-34dB),中后段的音频音量比较大,从输出结果可见,最终输出音量基本处于 [-1dB, -3dB] 的目标区间,听感上已经没有差异。
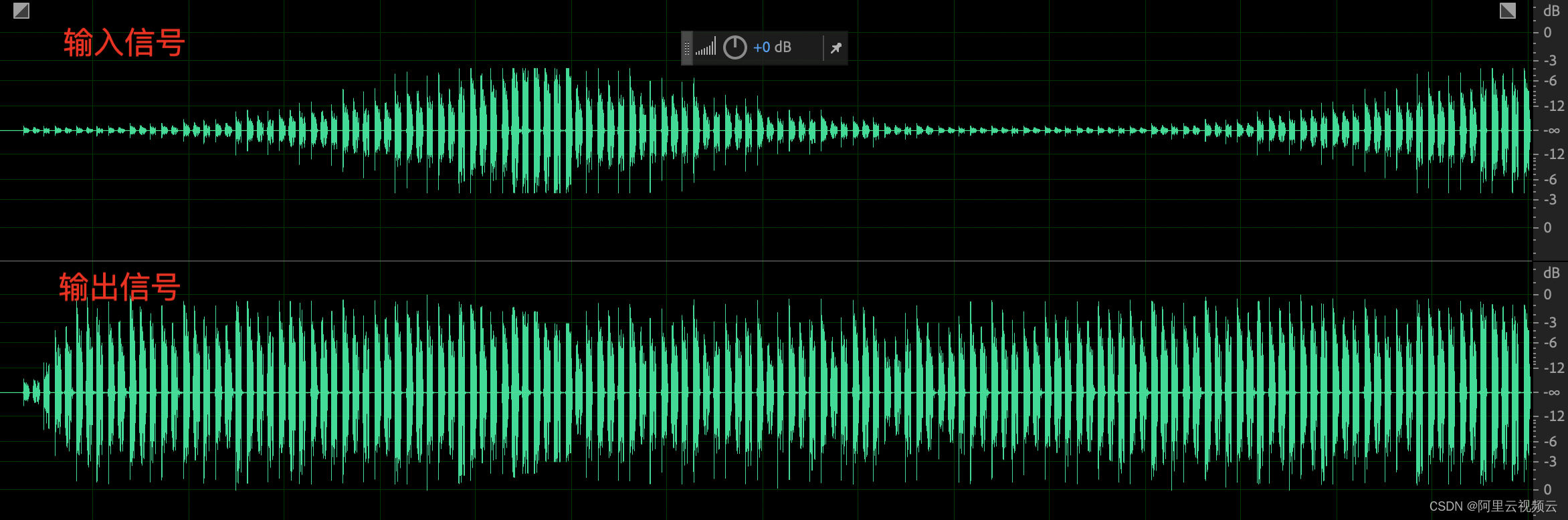
下面来看一个比较极端 case:人声由大到小交替变化,如果增益自适应调节不及时我们会看到波峰被压限器削平的情况,以及小音量提升不及时的问题(可以在深入浅出那篇文章中查看)。优化之后可见,整体输出音量平稳,且波形保持完好。
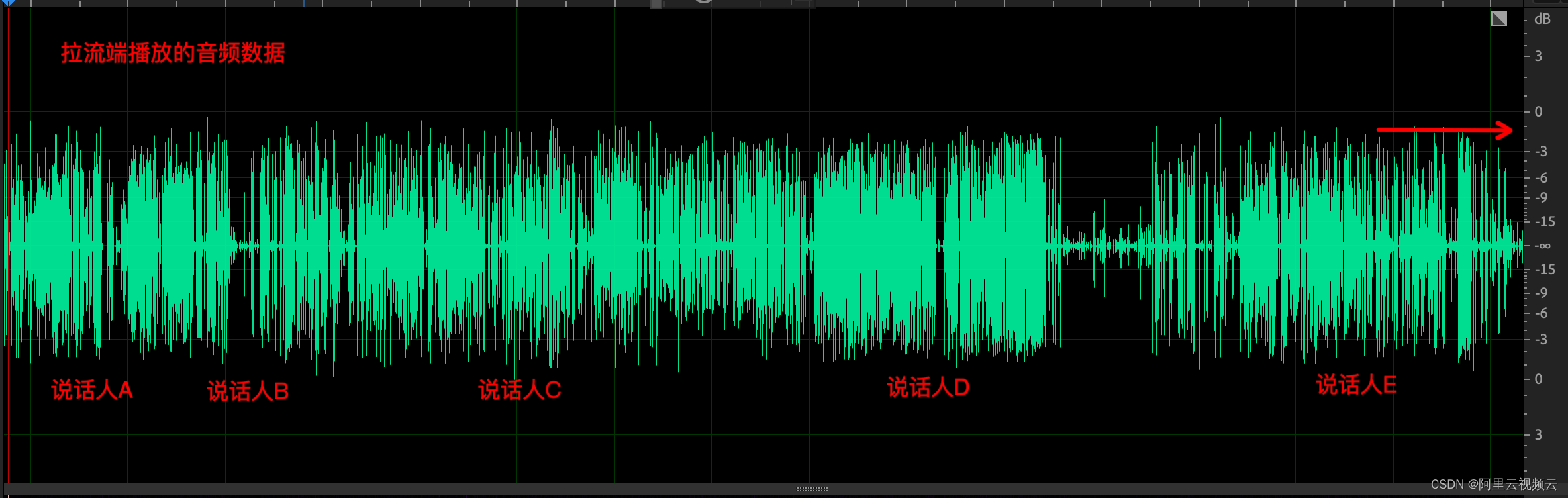
同时,我们录制了一次多人会议中参会人 F 本地播放音频数据,参会人 A ~ E 最终推流音量基本都被均衡到-3dB 附近,对于参会人 F 而言,他主观听感上基本是一致的。
(3)嘈杂环境下的增益控制
同样地,我们选取了一段真实会议中录制的推流音频数据。主讲人发言之前,环境中有其他同事正在开会,传统自适应方案中由于缺乏对嘈杂环境监测,导致其他同事声音也得到了大幅度的增益,优化后的方案避免了这类情况,仅当主讲人开始发言时才激活了自适应逻辑,避免了过度增益周围嘈杂人声的问题。
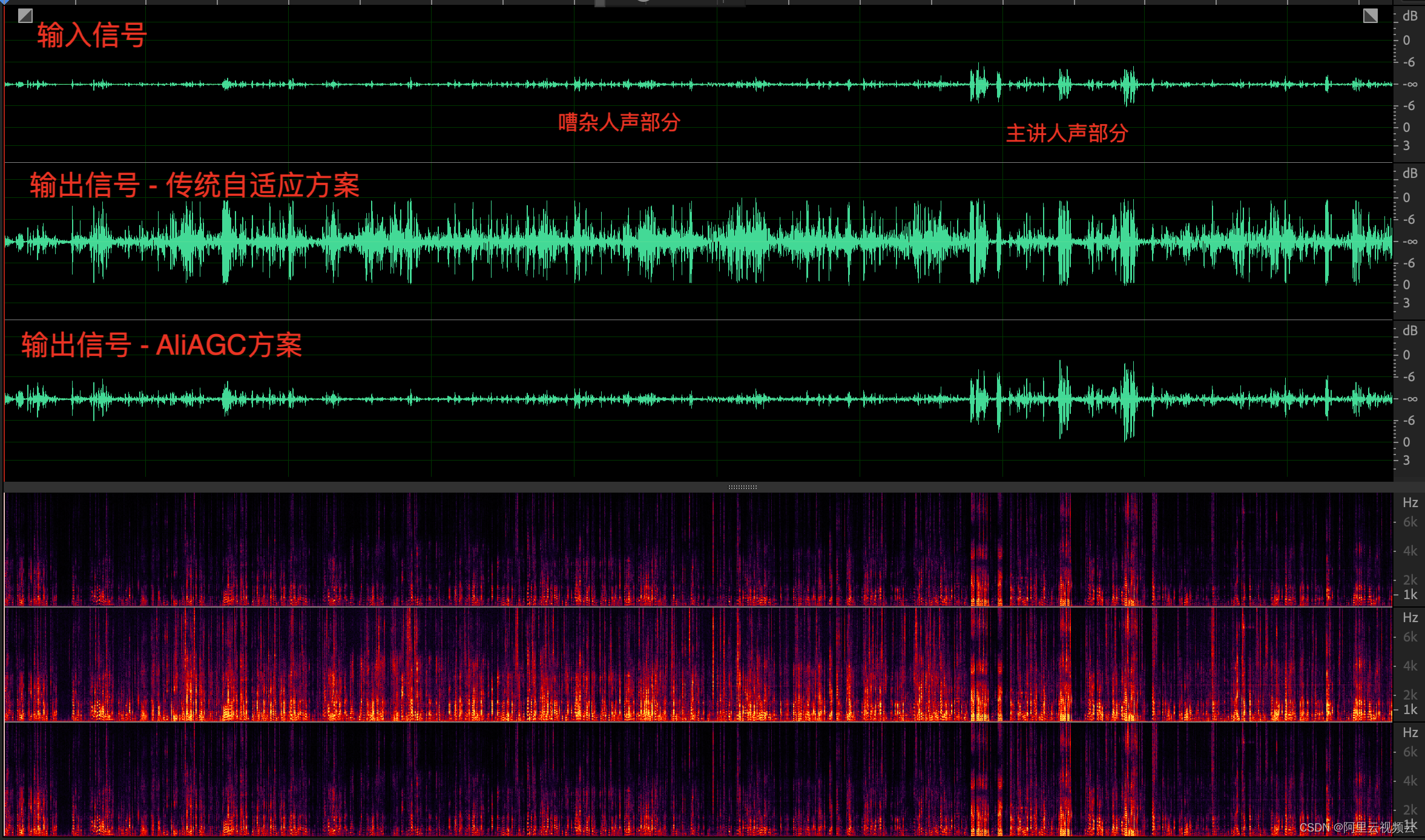
同时,对于原始采集底噪大,且存在嘈杂人声的情况,主讲人发言之前增益保持比较好,并没有因为 AGC 的增益而带来底噪被大幅放大的问题。当主讲人开始发言时,触发增益自适应调节,最终被增益到合适位置。

(4)娱乐直播场景下的增益控制
我们选取了一段主播与背景音乐交替出现的素材,传统增益补偿方案中人声和音乐是一视同仁的,最终都得到了提升,听感上会发现背景音乐音乐起伏不定。优化后的方案中,由于音乐检测模块较好的表现,会指导 AGC 对音乐部分增益的控制,输出结果符合预期,整体看增益仅仅是按照了主播人声的部分在自适应。
全场景自适应,AliAGC 算法的后续优化目标
阿里云视频云音频技术团队提供的音频 3A 算法(不局限于 3A),是 AliRTC 推流端音频质量的保障,各项音频指标不能有明显短板,在复杂的应用场景中三者缺一不可,共同影响着音频质量与主观体验。我们并不能把某一个算法割裂地去优化,比如 AGC 增益过大,不仅会过度增益噪声,还会造成对端采集到的回声非线性成分增多,影响回声消除的效果。另外,降噪能力太差,也会限制 AGC 可以达到的最大增益上限。同时,在嘈杂声较大的环境中,也不能单纯依赖 AGC 对嘈杂人声的控制,毕竟检测都存在误检的可能,如果智能降噪默认使用的话,这类场景中 AGC 的压力会大幅减小。
在后续的优化中,会逐步按照场景细化 3A 的配置,整体看 3A 的最终效果。对于单一算法的优化,各大厂家之间的差距不断缩小,个性化差异化的创新显得尤为重要。一方面,AliAGC 算法需要主动发掘线上 badcase,持续加强稳定性建设;另一方面,需要加深机器学习、阵列等技术上的探索与运用,丰富产品亮点。
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云产品技术交流群,和业内大咖一起探讨音视频技术,获取更多行业最新信息。
最后
以上就是微笑黄蜂最近收集整理的关于AliAGC 自动增益控制算法:解决复杂场景下的音量问题现有 WebRTC AGC 算法存在什么问题?AliAGC 算法优化方向AliAGC 算法效果全场景自适应,AliAGC 算法的后续优化目标的全部内容,更多相关AliAGC内容请搜索靠谱客的其他文章。








发表评论 取消回复