大众对沉浸体验的追求,不再仅局限于“视觉”。声之切,境尤升。
随着硬件技术的升级、软件内容的丰富以及5G网络环境的优化,推动几经浮沉的VR产业走向正循环。
就在去年,「Roblox上市」、「Facebook更名为Meta」、「微软收购暴雪」等将元宇宙相关产业推向风口,而Oculus Quest 2(VR一体机)出货量破千万台的成绩,更是一件将沉浸式VR从概念落地场景实践的标志性事件。
在本次云栖大会阿里云视频云的8K VR视频技术展台,体验者通过佩戴Pico VR头显,感受清晰度高达8K的360度VR视频,实时捕捉超高清细节。
不仅如此,体验者还能以“声”临其境,感受令人惊艳的全景声技术带来的沉浸式视听体验。


01“视”之外的沉浸之“声”
「沉浸式视听体验」一词已多次出现在大众视野,究竟什么是沉浸式视听体验呢?
“沉浸式视听体验”是指通过视频、音频及特效系统,构建大视角、高画质、三维声特性,从而具备画面包围和声音环绕的主观感受特征,观众在所处位置就能获得周围多方位的视觉、听觉信息,带来身临其境之感。
听觉作为仅次于视觉的重要感官通道,对沉浸式的视听体验至关重要。随着用户对视听体验的极致追求,在“视”之外,沉浸之“声”技术应运而生。
「沉浸式音频」是指能够呈现空间的还音系统的声辐射,至少能覆盖观众的前、后、左、右、上五个方位。除此之外,还能真实地营造出声场的水平纵深和垂直高度,即从听者角度能精准地定位声音的方向和位置。
从技术角度是如何实现呢?
其实,真实世界的声音来自环境的四面八方,人耳往往可以通过声波的时间差、强度差、相位差、频率差等辨别声音的方位。
但现有的立体声和5.1环绕声只能呈现部分方向传来的声音信息,若想获得声音带来的沉浸感,需要尽可能全方位再现真实世界的声音,也需要一种沉浸式音频技术来实现。

图片来源于网络
02一个「球面」的声场?
沉浸式音频主要技术有三大类: 基于声道 Channel Based Audio(CBA)、基于对象Object Based Audio (OBA)、基于场景 Scene Based Audio(SBA)。
❖ 基于声道技术(CBA):在传统 5.1 环绕声的基础上,增加了 4 个顶部声道,通过增加声道的方式来补充空间中的声音信息,但只能呈现部分方向来的声音信息。
❖ 基于对象的技术(OBA):是目前主流技术,并在电影领域已广泛应用,如 Dolby Atmos 全景声。该技术会产生大量的数据和运算,除了声道的音频外,还有关于声源的元数据Metadata,即:声源(位置/大小/速度/形状等属性)、声源所在的环境(混响Reverb/回声Reflection/衰减Attenuate/几何形态等),该技术在VR领域只适合主机VR上的大型游戏,对于普通移动端的硬件设备来讲,算力及带宽承载具有较大压力。
❖ 基于场景的技术(SBA):用来描述场景的声场,其核心的底层算法是Ambisonics 技术,可被映射到任意扬声器布局中。Ambisonics技术的特点是:声源贴在提前渲染好的全景球上,即所有声源将被压缩在了这个球上。
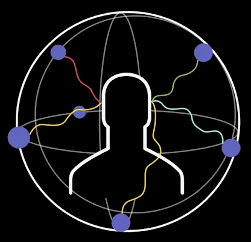
图片来源于网络
本文的音频体验展示便采用了Ambisonics的录制格式(文末体验DEMO)。
Ambisonics作为全景声的一种录取格式,在上世纪70年代就已经问世,但一直没有获得商业上的成功。
随着近几年VR,AR等相关领域的兴起,Ambisonics开始逐渐被讨论。与其它多声道环绕声格式不同,Ambisonics传输通道不带扬声器信号,允许音频工作者根据声源方向而不是扬声器的位置来思考设计,并且为听众提供了用于播放扬声器的布局和数量,因此,大大增加了灵活性。
Ambisonics音频格式可以解码任何扬声器阵列,并且可以完整地、不间断地还原音源而不受任何特定编解码播放系统的限制。
下图是一个一阶的Ambisonics结构,4个MIC垂直部署在一个四面体上,播放效果与Dolby Atmos类似,但和Dolby Atmos不同的地方是:Dolby Atmos 只解决了半球的声场。
而Ambisonics除了水平环绕声音,还可以支持拾音位置或者听众上下的声源,即整个球面的声场。
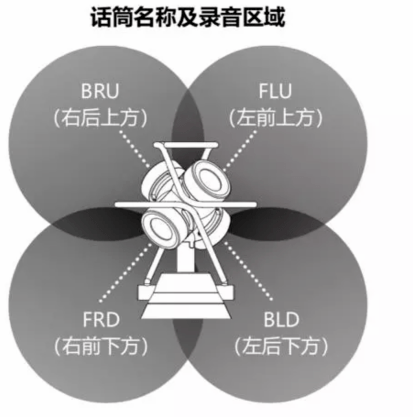

图片来源于网络
03实现声声入耳的引擎:AliBiAudio
全景声不仅仅是增加几个声道那么简单,而是把整个声音系统架构都颠覆了,从之前基于声道来混音的技术上升为基于对象的音频处理技术,使人在环境中的听觉感受与现场实际声音一致。
将全景声音频重建成用户可测听的形式有两种途径,一种是多扬声器重建,即电影院或家庭影院中的音响系统,其本质是将全景声音频转换到5.1.4或7.1.4格式;另一种是耳机重建,即将全景声音频通过双耳渲染技术转换为双声道音频,并保留其全部空间信息。
相对于多扬声器重建,耳机重建成本低、易部署、效果好。
不言而喻,耳机重建全景声音频,需要一个双耳渲染的过程,以此来通过两个立体声通道创建空间和维度的听觉感知效果。

AliBiAudio 就是一个阿里自研的双耳实时渲染引擎,结合头部跟踪坐标,可以达到人转动,声源位置不动的效果。当前双耳渲染引擎,具有支持全平台、多场景、易部署等特性。该引擎既可以部署在移动端,也可以部署在云端,并支持三大场景的渲染。
❖ 单声道输入:用于虚拟会议场景,可将不同位置的人,渲染在不同的角度发声,通常部署在服务端。
❖ 5.1/7.1 输入:用于影视剧渲染,得到更逼真的环绕声,类似优酷中的“帧享”音效。既可以部署在端上(如:Apple Music 空间音频),也可以部署在服务器上(如:作为媒体处理,将多声道数据下混成2路数据)。
❖ Ambisonics输入:对Ambisonics格式进行渲染,用于VR直播,VR点播,当前部署在Aliplay中。
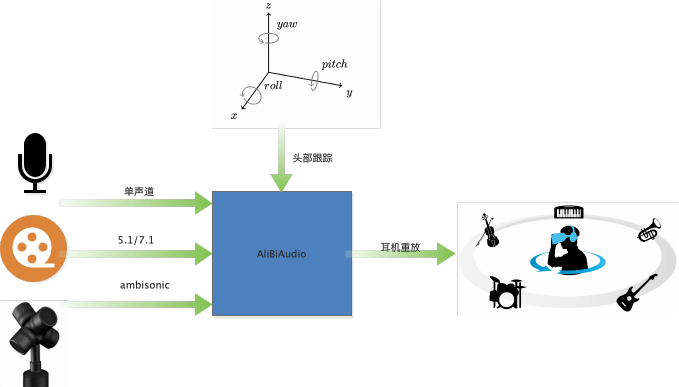
04如何让声音跟随脑袋一起摇摆
❖ HRTF
双耳渲染引擎的核心模块是人头传递函数HRTF( Head-related Transfer Function )。
每一方向都有两个HRTF,分别代表音源到左右耳的房间冲击响应,通过720度扫描可以得到一个球形的HRTF库,如下图是一个ARI HRTF 数据库的分布。
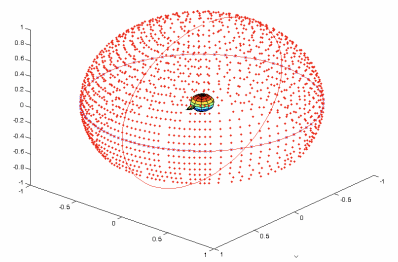
ARI HRTF 数据库
在渲染时,通过输入的角度信息,先从数据库中选出当前角度的HRTF对。然后再将输入数据分别和HRTF对进行卷积得到左右耳信号。为了得到更逼真效果,还可以添加一定量的房间混响如下图所示:
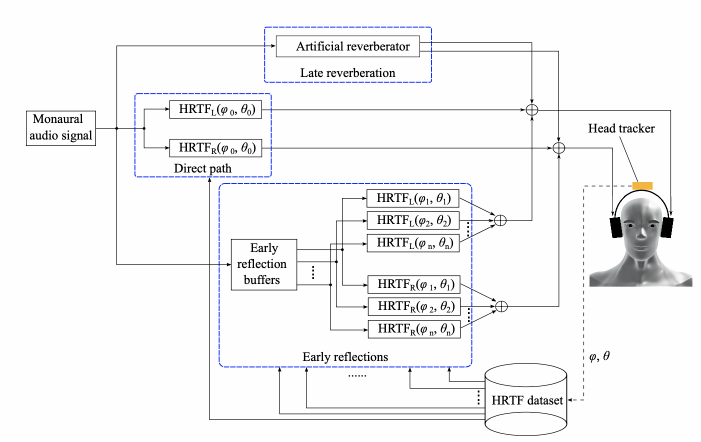
本项目对大量HRTF库进行筛选,获取到一个最优的数据库。
❖ Ambisonics数据格式
Ambisonics 的基础功能是让来自不同方向点声源,作为360度的球面来处理,这个中心点,就是麦克风放的位置。当前广泛用于VR 和 360 度全景视频的Ambisonics 格式,是一个叫做Ambisonics B-format的4声道(还有另一种格式叫A-format)。由W, X, Y and Z组成。对应着360度球面的,中心,左右,前后,上下。
- W 是一个全向
- X 是一个双极 8 字指向,代表前后
- Y 是一个双极 8 字指向,代表左右
- Z 是一个双极 8 字指向,代表上下
B-format 有两种格式分别是ambix 和fuma(它们只是排列顺序不同),而A-format 代表4个mic 采集的原始数据。B-format和A-format的关系如下:
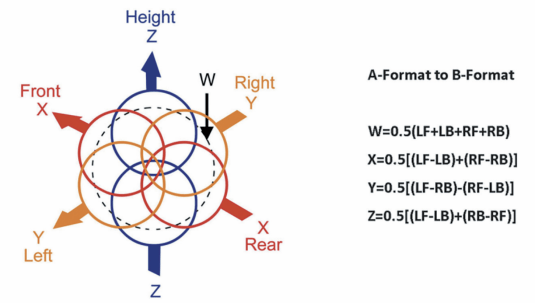
图片来源于网络
❖ 头部跟踪
该技术利用了某些特定款式耳机中的传感器信息,如:加速度计和陀螺仪,从而更好地跟踪头部运动,并做出相应的音频调整。
Apple已经从 iOS 15 开始通过兼容耳机带来支持头部跟踪的空间音频功能,目前Android 13的发布预览版已完全支持在兼容设备上使用头部跟踪的空间音频。本次云栖大会的展台体验便主要利用了Pico头显设备中陀螺仪的信息。
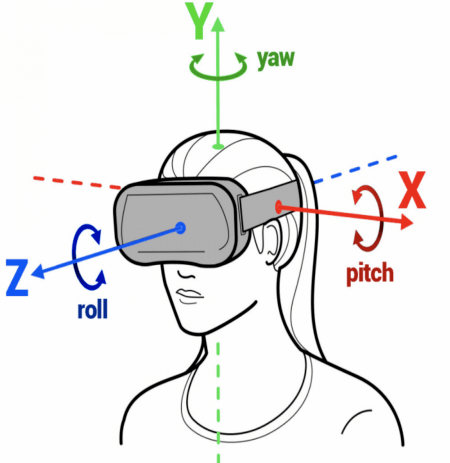
图片来源于网络
05一起「声」临其境
「佩戴耳机」体验全景声,效果更好哦!
现场体验中,声音的变化会随着头部的转动而转动,本次线上DEMO体验将依靠手动界面移动来模拟头部转动。
01听:无人机掠过头顶
无人机逐渐升起从头顶掠过,当视角跟随(模拟)无人机时,声音相应地实时变化。
02听:滴答滴答
聆听水滴的同时,发现左方有无人机的声音,视角随声而转,一路跟随,感受无人机由近及远的变化。
03听:沉浸游园
主持人在介绍园区时,用户向四周左右观看(模拟),在此过程中,主持人的声音呈现与他在你视角的位置始终保持对应。
04听:PING PANG之声
沉浸式场景怎能少了运动!一转头,乒乓之声已被“抛之脑后”。
06音频的未来,炫到无法想象
除此之外,全景声双耳渲染技术还可运用于多个场景,带来沉浸视听的无限想象力。
❖ VR演唱会
现场混合360度视频和全景声音频, 同时将数据传输到相应的移动平台,并进行实时直播。让观众可以达到“不在现场,胜似现场”的感觉。

❖ 沉浸式影院
也可以称之为沉浸式投影,是一种成熟的高度沉浸式虚拟现实系统。它将高分辨率的立体投影技术、三维计算机图形技术和音响技术等有机地结合在一起,产生一个完全沉浸式的虚拟环境,大大增加观影的沉浸感。
❖ 智慧教育
沉浸式教学模式逐渐受到教育界的关注。例如,IBM研究院和伦斯勒理工学院联合开发的“认知沉浸室 ”,它能让学生置身于中国的餐馆、商场、园林等虚拟场景,与AI机器人练习汉语对话,大大提升了学生的学习兴趣和专注力。
❖ 虚拟会议
以Facebook基于VR开发的虚拟会议为例。而为了更贴近现实,Workrooms还加入了沉浸音频功能,让用户交谈时,声音的发出的方向跟他们所处的房间位置一致,从而进一步增加参会者的沉浸感。

图片来源于网络
未来的沉浸音频技术将如何发展?
以双耳渲染引擎的核心模块HRTF为例来说,当前的HRTF模型,是一个固定模型,无法适应不同人的声音感知差异,尤其在正前方的外化能力还不够好。若想得到更逼真的声音效果,需对HRTF进行进一步优化,使其适应每个人的个体差异性。
比如:根据每个人的人头大小,耳廓信息以及肩膀的形状独立建模。在国外HRTF的建模与个性化发展已经成为趋势:
3月开始,杜比支持个性化HRTF的定制。

图片来源于网络
9月开始,iPhone升级了ios16,通过人脸扫描,可以定制自己的HRTF。
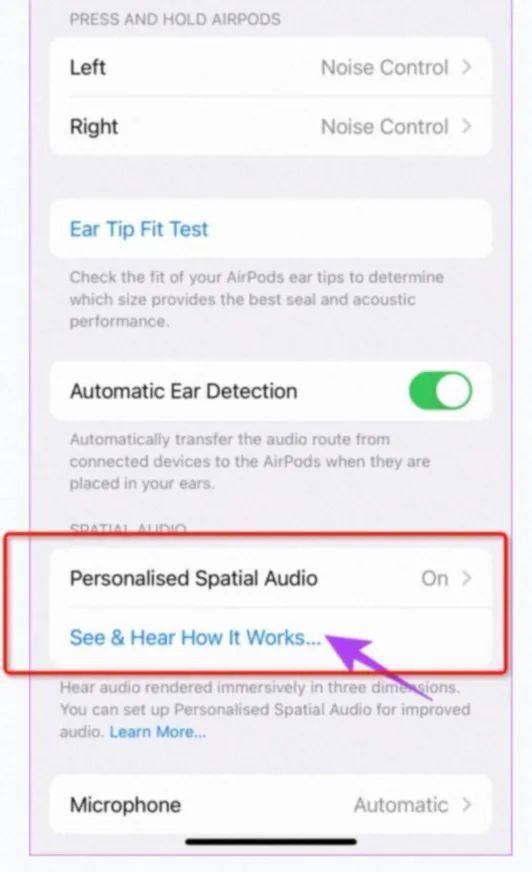
图片来源于网络
此外,用机器学习的方法,将面部,耳部图片,转化成HRTF也在火热研究中。
未来,阿里云视频云将继续探索基于深度学习与信号处理的的音频技术,为VR超高清视频直播带来以「声」临其境的超沉浸之感。
参考文献:
[1] 5G 高新视频—沉浸式视频技术白皮书
[2] https://m.fx361.com/news/2018/0326/3298705.html
[3] https://3g.163.com/dy/article/ELBCI2OG053290QL.html?clickfrom=subscribe
[4] https://www.birtv.com/Magazine/content/?246.html
[5] https://m.midifan.com/article_body.php?id=6201
[6] https://sound.media.mit.edu/resources/KEMAR.html
[7] https://juiwang.com/assets/projects/hrtf_nn_bem/hrtf_nn_bem.pdf
[8] https://www.tvoao.com/a/208656.aspx
最后
以上就是文艺跳跳糖最近收集整理的关于沉浸式视听体验:全景声技术是如何实现的?01“视”之外的沉浸之“声”02一个「球面」的声场?03实现声声入耳的引擎:AliBiAudio04如何让声音跟随脑袋一起摇摆05一起「声」临其境06音频的未来,炫到无法想象的全部内容,更多相关沉浸式视听体验:全景声技术是如何实现内容请搜索靠谱客的其他文章。








发表评论 取消回复