现在ros都可以与MATLAB进行通信了。
https://github.com/talregev/ROS_Matlab
看了大神的github
真的太有收获了
https://github.com/kintzhao?page=2&tab=repositories
matlab安装教程:
https://jingyan.baidu.com/article/456c463b22527e0a58314402.html
顺便自己打算把一些好的作图的东西也粘的这个里面。
如何批量导入dat信息。
参考博客:
http://blog.csdn.net/txlsddd/article/details/52601011?locationNum=1&fps=1
在matlab当中,我们用ls来导入文件的名字,
filename=ls('C:UsersAdministratorDesktopgene_info*.dat');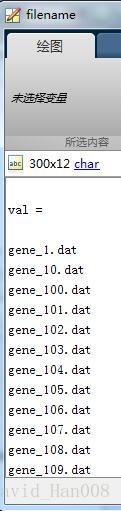
然后我们这个里面的所有的文件进行循环
在matlab当中importdata和load的区别在于:load一般只针对于matlab特有的格式。例如.mat文件。importdata支持的格式一般是针对于文本文件。
这条语句是用来进行导入文件的名字,将文件名做成一个字符串数组方便调用
str=['C:UsersAdministratorDesktopgene_info',filename(i,:)];然后将文件名str 进行importdata(str),随后给了data_cell这个一个元祖
matlab当中的元胞数组是什么概念?

matlab当中的元胞数组http://blog.163.com/zmbetty7891@126/blog/static/162476718201092524859556/
https://jingyan.baidu.com/article/20095761997932cb0721b485.html
将所有的文件都放到一个元祖当中当中,就是上面的这个图。
(将来不管是什么数据,首先要想到的就是把这些数据导入到一个元素当中)
这个就是在第一行表示行数,就是给每个元祖进行了一下编号
data=[1:length(data_cell)]; 这里data是2是因为他们从第2个开始。
for j=1:length(data_cell)
data(2,j)=length(data_cell{1,j});
for k=1:length(data_cell{1,j})
numstr=regexprep(data_cell{1,j}(k,1),'rs','');
data(k+2,j)=str2num(numstr{1,1});
end
end把字符转出相应的数字 将2翻译成two->to
str2num把数字转出成相应的数据
num2str regexprep 用于对字符串进行查找并且替换相比于其他:regexp和regexpi。regexp用于对字符进行查找,大小写敏感。regexpi大小写不敏感。
{}我们用这个括号来表示元祖()用这个来对元素进行地进行定位data(k+2)这里+2因为在上面的得到的这些数组
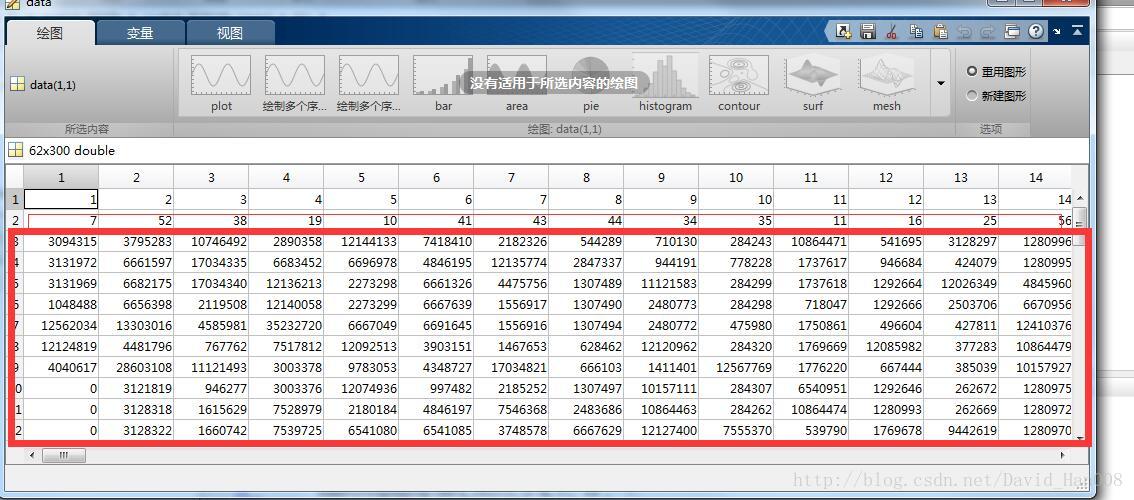
第一行表示的序列
第二行表示的长度
从第三行后面的表示数组的长度,我觉得应该吧这个好的模板记住,以后有类型的事情,就用这个套路进行处理。
filename=ls('C:UsersAdministratorDesktopgene_info*.dat');
for i=1:length(filename)
str=['C:UsersAdministratorDesktopgene_info',filename(i,:)];
data_cell{1,i}=importdata(str);
end
data=[1:length(data_cell)];
for j=1:length(data_cell)
data(2,j)=length(data_cell{1,j});
for k=1:length(data_cell{1,j})
numstr=regexprep(data_cell{1,j}(k,1),'rs','');
data(k+2,j)=str2num(numstr{1,1});
end
endmatlab单步调试就是 F10
matlab注释就是%,以及按ctrl+R
如果是大量的数据就用importdata(‘文件的目录’)
str2=['C:UsersAdministratorDesktop2016试题BB题附件genotype.dat'];
data_cell2=importdata(str2);
numstr=regexprep(data_cell2(1,1),'rs','');这个后面的地方data_cell2(1,1)是提取出第一个细胞元组当中所有的数据

细胞数组是 matlab当中的一类特殊的数组
http://www.fx114.net/qa-111-87603.aspx

cell生成细胞数组
cellplot用图形方式显示细胞数组
细胞数组的生成,先用cell函数预分配数组,然后再对每个元素赋值。
B=cell(3,4) 创建一个3*4的细胞矩阵。
MATLAB取消多行注释
所以说用strcmp函数去比较两个字符是可取的,就是当检测到第一个字符不对,就走了
导致的结果就是整个data里面有很多
百度了一下还是用正则表达式去做。

存储矩阵用()
存储cell用{}
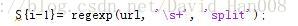

在data_num当中产生200-1000个43个随机数
for i=1:43
data_num(i)=rand(1)*(1000-200)+200;
endmatlab当中关于点除的东西。其实 就不是矩阵的乘法运算。
产生一列数据
x_i(1,[1:43])=0;新建一个矩阵,这个矩阵是一列,然后我们分号进行分开。
data=[x_i;data_ai;data_bi;data_num];然后通过提取第i个数组进行赋值
x0=data(:,i);并且进行转置
x0=x0';将最后的结果的数据进行存储
result(i)=fval;采用模拟算法
[x fval] = simulannealbnd(@fun1,x0,Aeq, beq);一些比较基础但是很有用函数
floor函数是进行向下取整floor(1.5)=1
ceil函数是进行向上取整ceil(1.5)=2
round函数,是取最接近的整数 可以理解为四舍五入函数
对于细胞数组cell使用的是{ }
同样,也可以对一个cell进行转置。
matlab如何进行读写操作。fopen()用来读入数据 fprintf()用来写入数据按照某种特定的格式。
使用doc命令进行查找某个函数的功能,例如doc fopen
利用fopen打开文件 也可以选择默认的按时,默认方式就是只读的方式进行打开。fileID=fopen('test.txt')等效于:fileID=fopen('test.txt','r');
在matlab当中进行查找和替换的的strrep函数
在 str1 中找到str2 ,替换成str3
str1 = 'This is a good example.';
str2 = 'good';
str3 = 'great';
str = strrep(str1, str2,str3)
str =
This is a great example.从论文算法的角度来看的话,感觉需要用的卡方检测,卡方检测就是统计样本实际的观测量与理论推断之间的偏离程度。实际观测与理论推断之间的偏离程度决定了卡方值的大小,卡方值越小,说明偏差越小,越符合。如果两个数值完全相等,卡方值位0,表明理论值与实际值完全符合。在这里说一个查专业资料,尽量去维基百科,英语查。哪里的资料要把百度更多一些。matlab当中的关于卡方检测的两个函数有crosstab和chi2gof函数。大神博客的链接:个人认为还是很详细的http://blog.sina.com.cn/s/blog_7054a1960102wizu.html。
由于对matlab当中的统计分析的工具箱不太熟悉,现在想测试一下
1、概率分布
随机变量的统计行为,就是他的概率分布。分别是
概率密度函数 pdf 表示的连续分布,每个点在这个范围的可能性。
累积分布函数(cdf)是概率密度函数的积分。
逆累积分布函数 (icdf))
随机数产生器
均值和方差函数
一般的概率密度函数
x=[-1:0.1:1];
f=normpdf(x,0,1);
plot(x,f)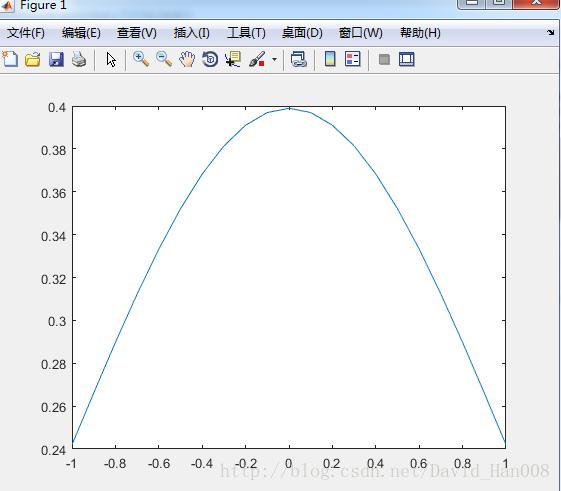
但是感觉不是太靠谱。这个为什么产生的一条直线。
产生标准正态分布
x=[-1:0.01:9];
f=pdf('Normal',x,1,1);
plot(x,f)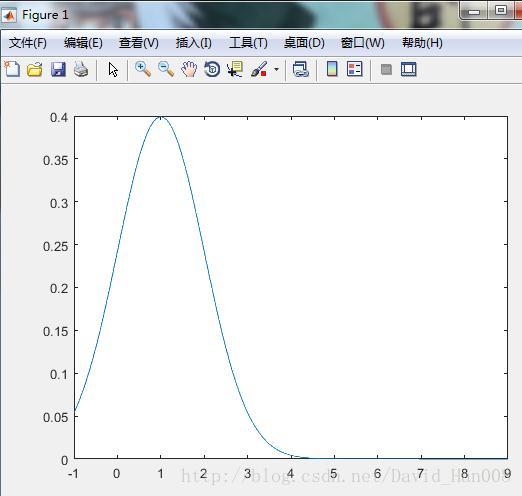
关于pdf(‘name’,x,a1,a2);
当表示的一个二维的随机变量的时候。name表示分布的类型,例如normal.x表示取值的范围。a1表示的均值,a2表示的方差。a3如果有高纬的分布的话,反正就是以此表示他们的参数。例如
x=[-1:0.1:1];
f=pdf('Poisson',x,1);
plot(x,f)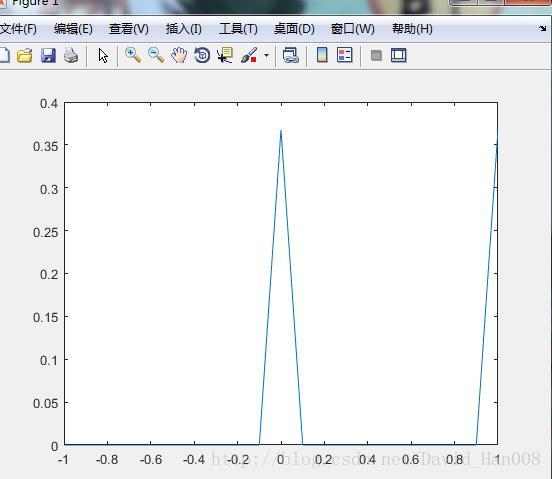
累积分布函数
x=[-1:0.1:5];
f=cdf('Normal',x,0,1);%f=icdf('Normal',x,0,1);
plot(x,f);这是cdf函数
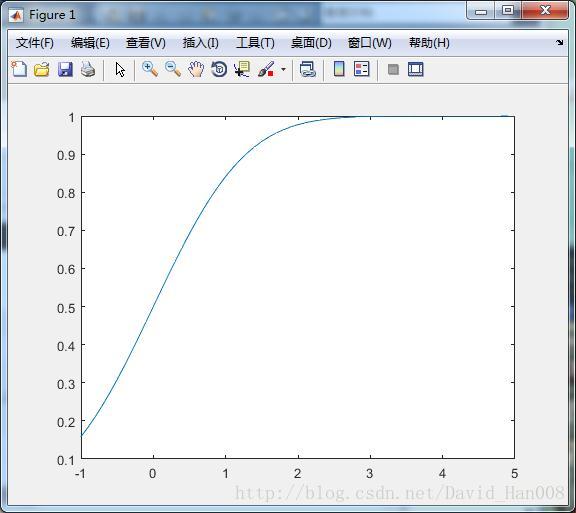
这是icdf函数
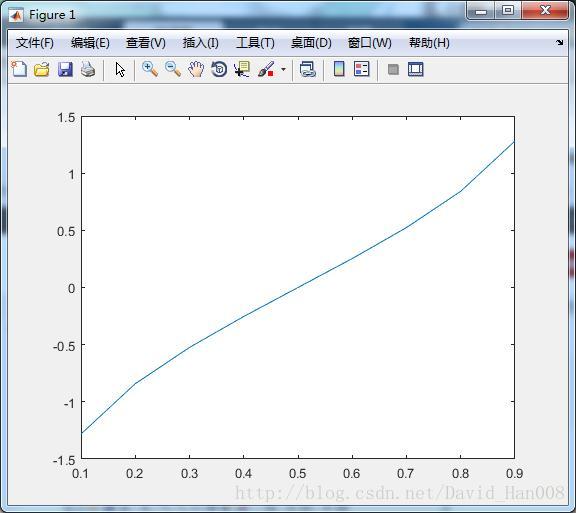
随机数产生器
random函数
y=random('Normal',0,1);输出的结果是是一个随机数。
计算均值和方差
[m,n]=normstat(0,0.3)返回的m,n分别是均值和方差 输入的两个参数 分别是 mu和 sigma
举例说明:数学公式如何和matlab相互对应起来

计算某个值得概率密度用normcdf ,使用cdf函数能够快速的计算PDF。这就是累积概率分布的作用。
normcdf(2,1,3)如果要求p(x>2)
那么就是1减去上面这个数
如果去要某个一个区间范围p(2<x<4)
mcdf(4,1,3)-normcdf(2,1,3)
描述下性统计
中心位置度量,数据样本的中心度量的目的在于,对数据向本的数据分布线上的中心位置予以定位。
均值是对位置的简单和通常的估计量。但是野值(就会出奇的大或者出奇的小)
对于平均值进行定义
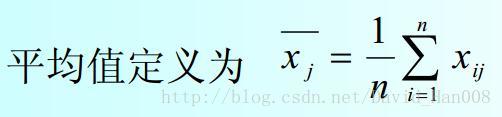
利用随机产生器,产生在0,1,然后100行5列的二维矩阵
x=normrnd(0,1,1000,5);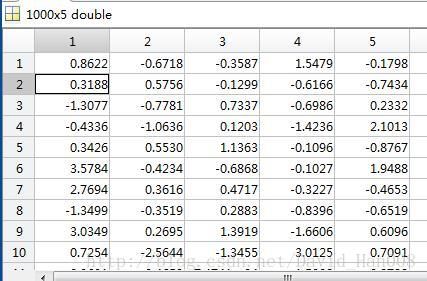
xbar=mean(x);输出的是 ,也即是mean函数只能在一个方向上进行求取平均数。
,也即是mean函数只能在一个方向上进行求取平均数。
几何平均数
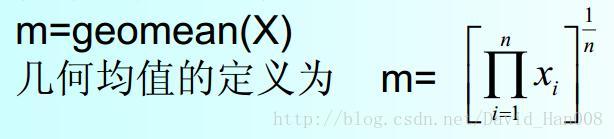
如果X是一个向量,那么返回的是这个向量的几何平均,如果是一个矩阵,那么返回的是一个行向量,这个跟mean函数是一样的。
exprnd(mu,m,n)产生 均值mu m*n的矩阵的 指数分布的的随机数。使用geomean(x)来求几何中心
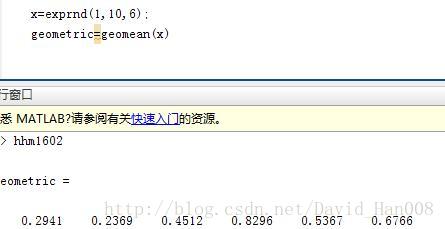
中位数的野值的抗干扰性强
使用median(x)
对离散分布的度量
离散分布的度量,就是样本的数据偏离其数值中心的程度,也叫作离差
极差:最大的观测量与最小的观测量之间的差
标准差和方差:常常用散布度量来衡量
四分位数间距为随机变量的上四分位数和下四分位数之差。
计算样本的内的四分位数间距使用的是iqr(x);
计算极差range(x)
计算样本的方差 var(x)
计算标准差 std(x)
计算协方差矩阵 cov(x)
计算数据的平均绝对偏差 mad(x)
中心矩
是表示数学期望的矩

样本矩即是平均数;中心距就是 所有的x-x的平均数,然后平方,然后在求和。原点矩,就是x^2再求和。
这个的r表示的r阶的中心距。
moment(x,order);使用order来表示阶数
相关系数
相关系数表示的是两个随机变量之间线性相依的程度
可以使用corrcoef函数来计算
R=corrcoef(x)在这个x当中,x的行元素表示的观测值,列元素表示变量。
统计作图
box plots(box图)
distribution plots(概率图)
scatter plots(散点图)
x=[normrnd(4,1,1,100) normrnd(6,0.5,1,200)];
boxplot(x)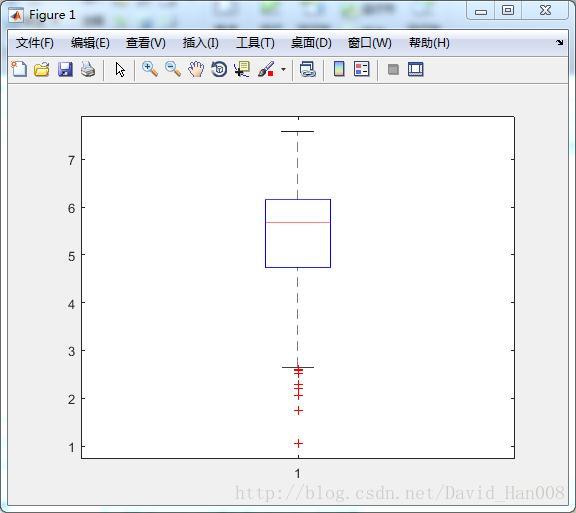
矩形框中红色的表示的是中位数,中位数正好在数据正中间,说明数据有一半大于这个中位数,目前明显是不是。红色的格子上下两边称为上下四分数点,:他的意思是,数据中有四分之一的数据大于上四分位数。
盒子上下有一条纵向的线,表示的触须线。上面的截止横线表示的变量值本体的最大值。下横线表示的变量值本体最小的值。异常的点用*来表示。
(如果将来要用到这种图的,还是要会分析这种图的)
分布图
卡方分布
x=0:0.1:15;
y=chi2pdf(x,8);%第一个参数表示自变量,第二个参数表示的是自由度V
plot(x,y)自由度v,和自变量x,以及因变量Y之间的关系式
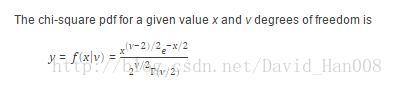
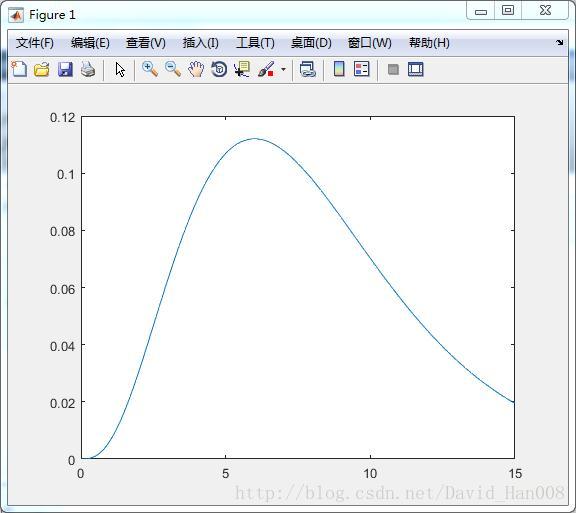
f分布
V1和V2的自由度
y=fpdf(x,5,3);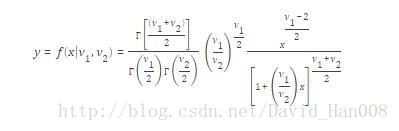
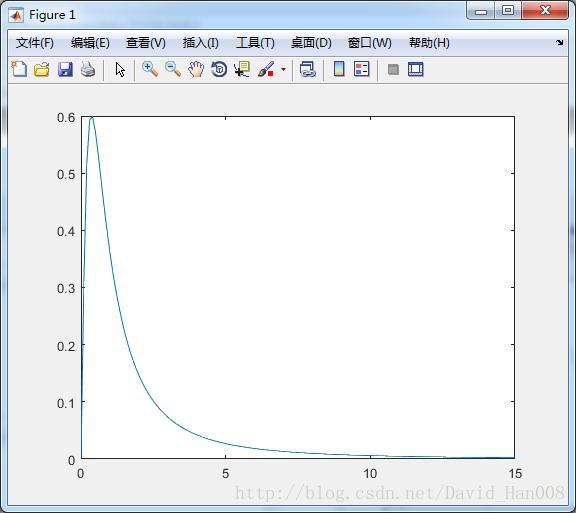
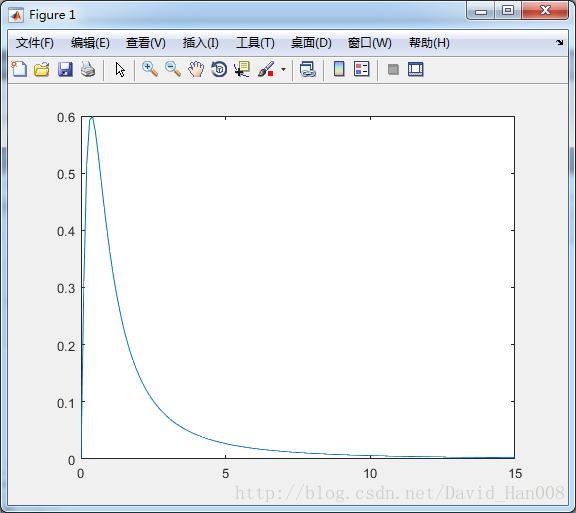
t分布
也是用tpdf();就可以了

假设检测
假设检验,利用得到的少量的信息,来判断整体是否达到某个标准。
他们的步骤:
1、假设H 0假设
2、得到一组观测值
3、给定显著型水平
4、应用子样的某些统计量特征
使用ranklsum函数
[p,h]=ranksum(x,y,alpha)
p返回的x,y的一致性水平水平,h为假设检验的返回值
x,y为两组观测值,alpha为显著性水平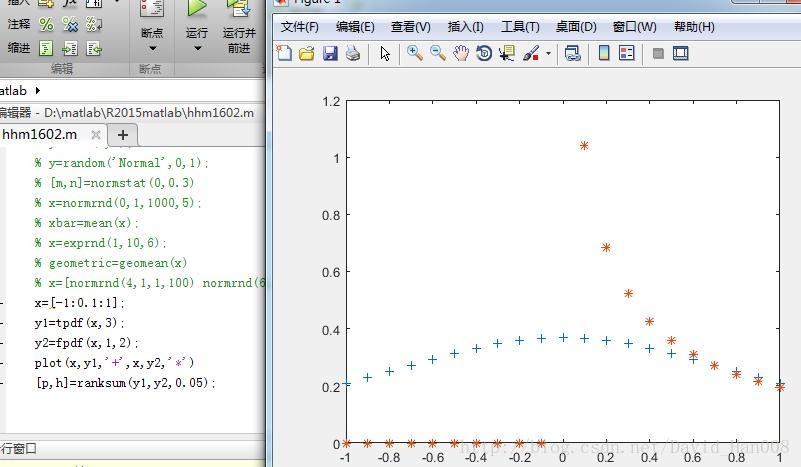
x=[-1:0.1:1];
y1=tpdf(x,3);
y2=fpdf(x,1,2);
plot(x,y1,'+',x,y2,'*')
[p,h]=ranksum(y1,y2,0.05);h为0表示,y1和y2显著相关 h为1表示不相关,p为表示他们的相关的水平。
说明改假设成立
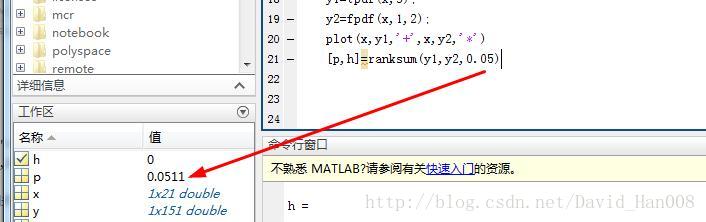
如果我再这个改了这个alpha的数值,那么
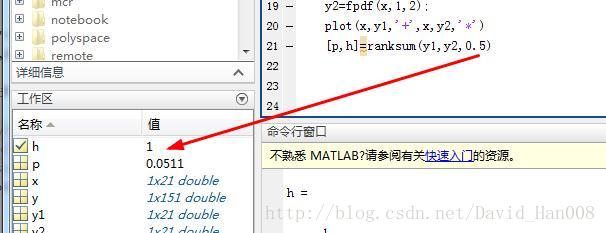
这个h的方就变成了1
t检验
[h,sig,ci]=ttest(x,m,alpha);h为假设检测返回值,sig与 ,m为假设的样本的均值。
,m为假设的样本的均值。
利用matlab生成world文档
%创建一个Microsoft word的服务器
try
word=actxGetRunningServer(‘Word.Application’);
catch
word=actxserver(‘Word.Application’);
end
%设置服务器可见
set(word,’Visible’,1);
%可以通过word.get查看对象的所有属性
%通过invoke可以看见所有的可能的命令,其实我们常用的就是几个
%word.Documents.invoke;
%利用add方法建立一个空白的文档
document=word.document.Add;
利用matlab读取excel文档
遇到的问题:
xlsread('D:matlabR2015matlabbindaoru.xls')
错误使用 xlsread (line 251)问题的原因:excel 里面有com的插件
解决方法:
https://zhidao.baidu.com/question/536815299.html
勾选掉:
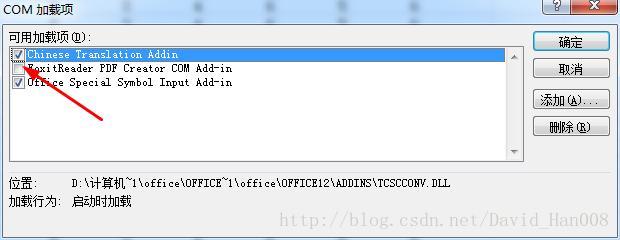
然后就好了

xlsread 的参数说明
num = xlsread(filename)
num = xlsread(filename,sheet)
num = xlsread(filename,xlRange) reads from the specified range of the first worksheet in the workbook. Use Excel range syntax, such as 'A1:C3'.
num = xlsread(filename,sheet,xlRange) reads from the specified worksheet and range.第二个参数就是 excel 里面的sheet
使用matlab 写入excel数据

从这个图说明,也可以用cell进行读写,那就是偶很好用
如果是数据量很大的话,就像是数学建模的B题,数据量太大的,是没有办法用excel进行存储的。
xlswrite('C:UsersAdministrator.WIN7-20161129QODesktopdaoru.xls',A);用法也一样的
xlswrite(filename,A) writes matrix A to the first worksheet in the Microsoft® Excel® spreadsheet workbook filename starting at cell A1.
xlswrite(filename,A,sheet) writes to the specified worksheet.
xlswrite(filename,A,xlRange) writes to the rectangular region specified by xlRange in the first worksheet of the workbook. Use Excel range syntax, such as 'A1:C3'.但是你也可以选择读取一部分
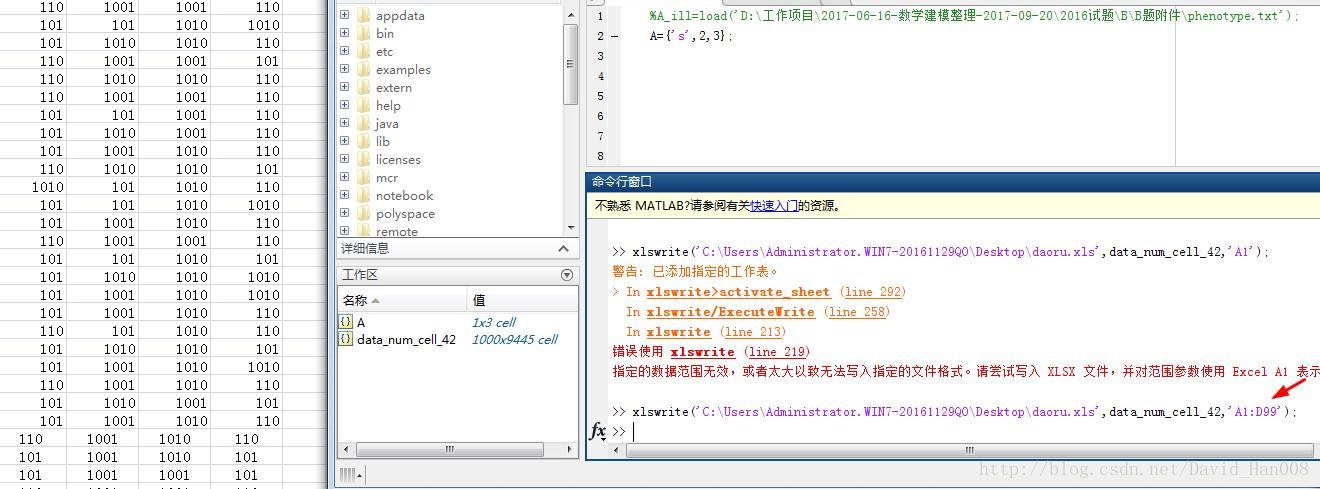
其实我感觉数学建模朝着大数据量的方向发展。
我尝试了 一下,将原来的矩阵转置之后 excel的行数是可以承受9445这个数,但是列是没有办法承受1000这个数字的
仔细看了一下报错,是因为我的是xls 如果换成xlsx就可以存储啦,哈哈,原来这么easy
目前有了excel我觉得就可以用spss进行分析了。
其实本质上就没那么多的事,虚惊一场,哈哈
txt导入matlab
使用load命令
load('C:UsersAdministrator.WIN7-20161129QODesktoptest.txt')或者你有的时候直接将这个txt拖入到matlab的工作空间中就可以了
maltab导入txt
我感觉 用的几率不是很大
http://jingyan.baidu.com/article/e6c8503c609ea8e54f1a189d.html
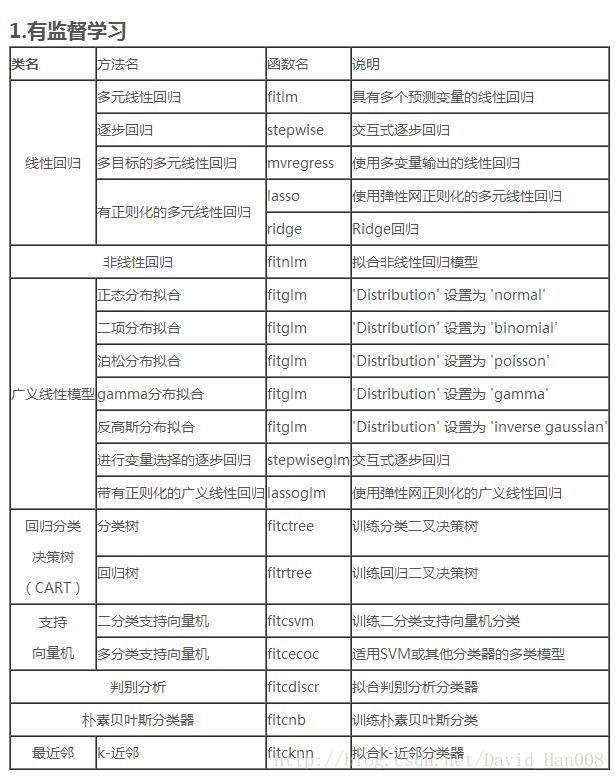
matlab用于训练机器学习的模型的函数主要分成三类
1、有监督的学习(有label)
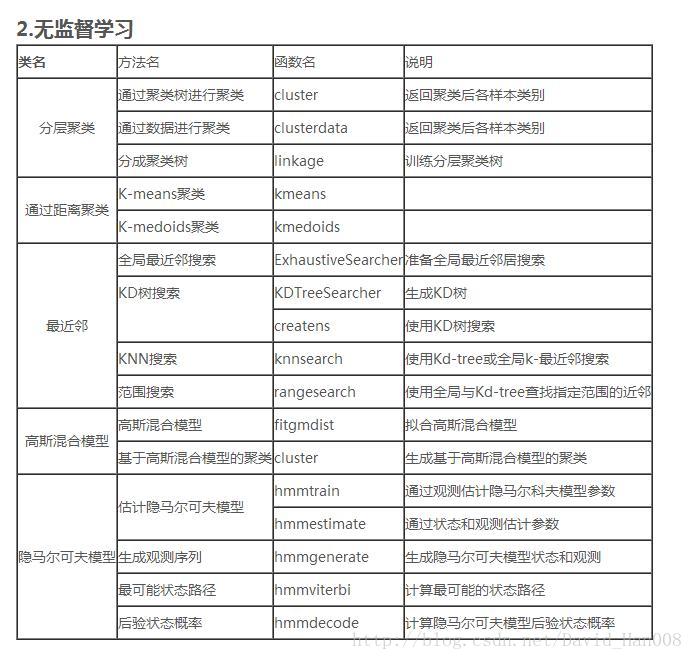
2、无监督的学习(没有label)—聚类
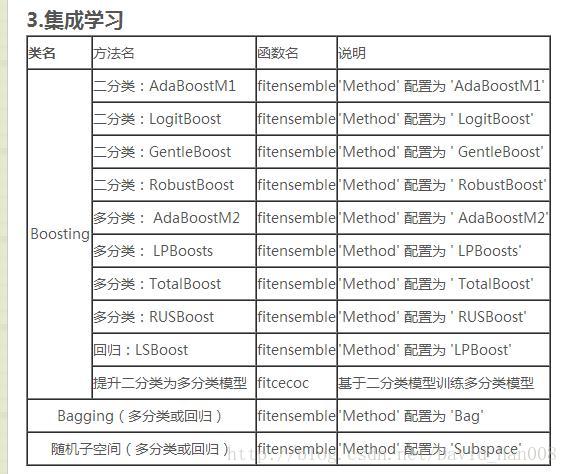
3、集成学习
当你需要训练模型对进行预测(例如股市将会涨还是落)或者分类()
当要选择采用何种算法的时候
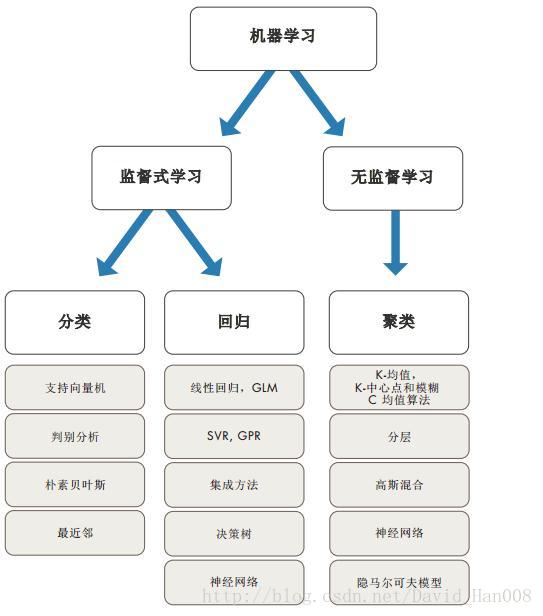
分类就选择用 判别分析,支持向量机、朴素贝叶斯、最近邻
回归:线性回归GLM SVR GPR 集成方法,决策树 神经网路
聚类:K-means 高斯混合 神经网络 HMM
一般的解决问题的思路:
1、加载数据
2、对数据进行预处理
3、预处理后的数据提取特征
4、根据特征训练模型
5、通过迭代抓住最佳的训练模型
通常我们把数据分成两组,一组从来进行测试,另外一种进行训练,这种方法叫作保留法,是一种有用的交叉验证技术。
matlab的混淆矩阵:
在人工智能中,混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。
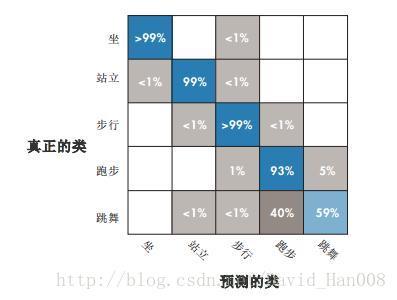
KNN(K-近邻算法)将新点和训练数据进行比较,然后返回最近的k个多数类别。
简化方法
减少特征的技术:
相关矩阵:可显示变量之间的关系,因此可以删除非高度相关的变量或特征
主成分分析(PCA)-可消除冗余
序列特征减少-采用迭代的方式减少模型的特征,直到无法改进模型的性能为止。
无监督学习
在聚类分析中,根据某些相似性度量吧数据划分成组。采用聚类的组正形式,同一类(或者同一簇)中的对象非常相似,不同类中的对象决然不同。
聚类算法分成两大类:
1、硬聚类:其中每个数据点只属于一类
2、软聚类:其中每个数据点可属于多类
k-均值
工作原理:
将数据分割成k个相互排斥的类,一个点在多个程度上适合划入哪一个类,由该点到类中心的距离决定。

k-中心点
要求:与数据契合的的聚类中心。

层次聚类:
工作原理:
通过分析点之间的想相似度,将对象分组成一二进制的层次结构树,产生聚类嵌套集
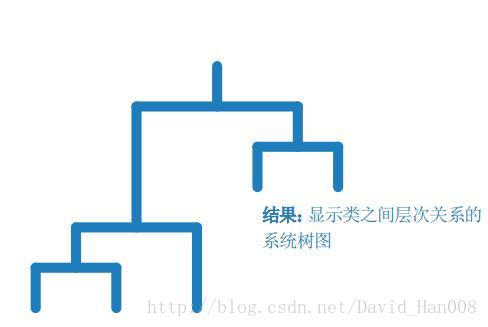
自组织映射
工作原理是:
基于神经网络的聚类,将数据集变成保留拓扑结构的2D图

软聚类算法
模糊 C-均值
工作原理:
当数据点可能属于多个类进行基于分割的聚类

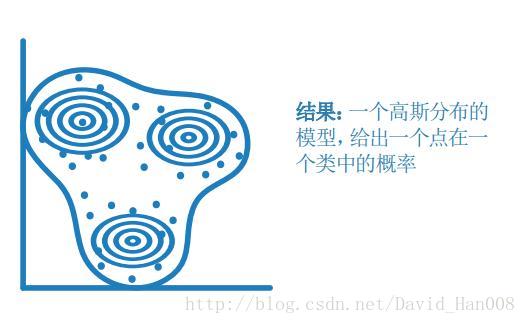
高斯混合模型
工作原理:
数据点具有一定概率的不同的多元正态分布。
常见的降维度方法
主成分分析:

因子分析
识别数据集当中个变量之间潜在相关性

非负矩阵分解
当模型只能非负数的时候
监督式学习
如果你想预测先有数据的输出,应该使用监督式学习。监督学习就是已知输入数据集,和一直对数据集合的输出,然后训练一个模型,为新的输入数据和相应作出合理的预测。
监督式学习分成,分类和回归两种形式
分类:预测离散相应
回归:预测连续相应
在处理分类问题的时候,一开始就是确定你这个问题是二分类,还是多分类。对于二分类,有病,没病就是一个二分类。某些算法(例如逻辑回归)专门为二分类问题设计的。
逻辑回归
K最近邻
KNN,假定相互靠近的对象都是相似的,因此有很多距离来查找最近邻

支持向量机
通过搜索能将全部数据点分割开的判别便捷,对数据尽心分类。

神经网络
朴素贝叶斯
假设勒种的某一具体的特征的存在于其他任何特征的存在都是不相关的。

判别分析
决策树
总结
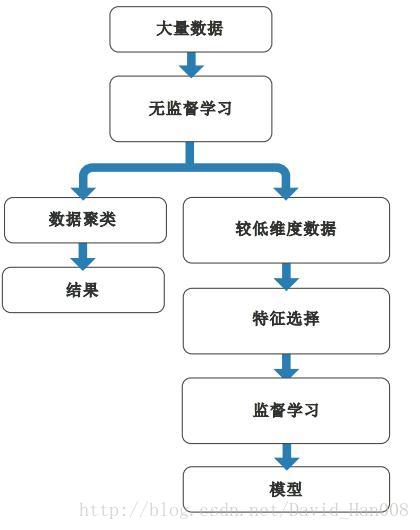
将一个很大额数据量通过监督学习,成为较低维度,然后进行特征选取,和监督学习。
使用HOG特征对数字进行分类
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。HOG特征通过计算和统计图像局部区域的梯度方向直方图来构成特征。
这个地方更新的是谢中华的matlab统计分析的与应用40个案例分析的笔记
第一个例子的输出
clc
clear all
data=[15.14,14.81,15.11,15.26,15.08,15.17,15.12,14.95,15.06,14.87];
[muhat,sigmahat,muci,sigmaci] = normfit(data,0.1)
90%的置信区间:
[14.9760 15.1380]
正态总体参数的检验
总体的标准差未知,单个正态分布的 利用均值的t检验—–ttest()
总体的标准差未知,两个正态分布的 利用均值比较t检验——— ttest2()
总体的均值未知,单个正态总体 利用卡方检测—-vartest()—-方差检测
总体的均值未知,两个正态利用方差 F检验—-vartest2()
在某些统计推断中,通常假定总体服从一定的分布,例如正态分布,然后再这个分布的基础上,构造相应的统计量,通过统计量的分布做出一些统计判断
在描述统计量上面,我们有:均值,方差,标准差,最大最小值,极差,中位数,众数,变异系数,峰度,偏度。
变异系数是衡量数据资料中观测值变异程度的一个统计量。
当进行两个或者多个变量的比较的之后,均值相同,我们使用标准差进行比较,如果均值不同,就不能使用标准差进行比较了。需要采用标准差和均值的比值,也就是变异系数来进行比较。
data=xlsread(‘D:a.xls’);
data_mean=mean(data(:,6));
data_std=std(data(:,6));
data_score=data_std/data_mean;
箱线图
箱子图当中™
data=xlsread(‘D:a.xls’);
boxlabel={课程A’,’课程B’,‘课程C’};
boxplot(data(:,6)’,boxlabel,’notch’,’on’,’orientation’,’horizontal’)
boxplot(data(:,3:5))
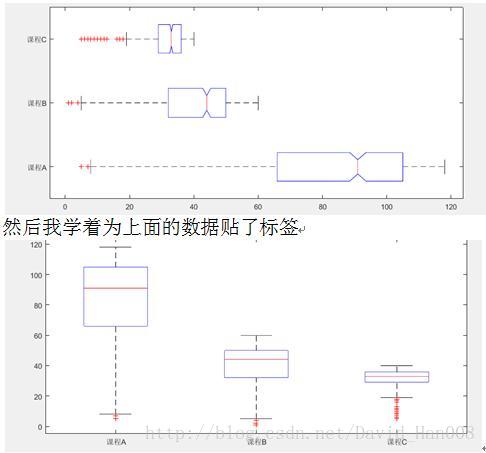
左边的这个线,或者是下面的这个线,表示的样本1/4分数线的位置,+的位置表示的出现异常的点
右侧,或者上侧的线表示样本0.75的分数线的位置。在样本的中位数上画一条线,也就是盒子的中间,这个箱子包含了50%的样本数据,1/4的位置是样本的最小值,3/4的位置,表示的是样本的最大值。箱线图可以十分直观的反应样本数据的分散程度以及总体的对称分布。虚线的长度近似,那么表示总体是对称分布嘚
画出频率直方图
在matlab当中就是利用ecdf函数和ecdfhist函数,进行绘制
data=xlsread(‘D:a.xls’);
[f,xc]=ecdf(data(:,6));
ecdfhist(f,xc,8)
hold on
%下面是用来做对比曲线的
x=1:0.1:1000;
y=normpdf(x,mean(data(:,6)),std(data(:,6)));
plot(x,y)

经验分布函数
经验分布函数使用的cdfplot 和ecdf函数
[h.state]=cdfplot(data(:,6));
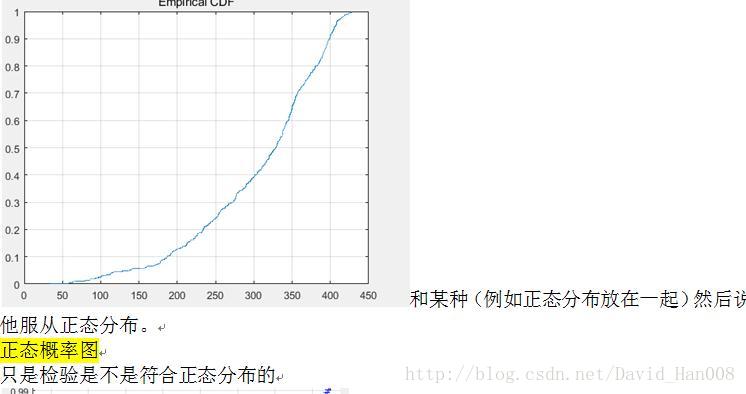
分布检验
chi2gof函数用来做卡方拟合优度检测,检验样本是否服从指定分布。卡方检测的原理:利用若干个小区间吧样本观测观测数据进行分组,是的理论上每组包含5个以上的观测,如果不满足这个要求,那么久通过合并相邻组来达到这个要求。根据分组结果计算X2检验统计量
h=chi2gof(data);
如果h为0d的话,则表示在显著水平0.05下接受该原则
通过控制一些参数,来是改变
‘nbin’控制分组数量
通过ctrs 指定各个区间的的中点数
Jbtest函数用来做Jarque-Bera检验,检验样本是否服从正态分布,调用这个函数不许需要指定分布的方差和均值,由于正态分布的偏度为0,峰度为3 基于Jarque-Bera检验,利用样本的偏度和峰度构造检验统计量
[h,p]=jbtest(data(:,6))
返回的是检验的p值
K-test函数
用作单个样本Kolmogorov-Smirnov函数,它可以作双侧检验,判断样本是否服从指定的分布。也可以作单侧检验,验证样本的分布函数是否在指定的分布函数之上。kstest函数根据样本的经验分布函数 和指定的分布函数 构造检验统计量
默认的是正态分布
[h,p]=kstest(data(:,6))
如果你想用的cdf定义的连续分布的话
data=xlsread(‘D:a.xls’);
cdf=[data(:,6),normcdf(data(:,6),315,80)];
[h,p]=kstest(data(:,6),cdf)
使用kstest2函数,检验样本x1和x2是否具有相同的分布。
h=kstest2(data(:,5),data(:,4))
当H=1 则说明拒绝这一个假设
cdfplot(data(:,5))
hold on
cdfplot(data(:,4))
利用hold on能够将这个图在同一个图当中显示
lillietest函数
当总体的均值和方差未知的时候,Lilliefor(1967)提出了样本均值 和标准差s代替总体的样本均值 和标准差 ,然后 使用Kolmogorov-Smirnov函数检验,这就是所谓的Lilliefors检验 lillietest函数用于Lillietest检验,检验样本是否服从指定分布,lillietest函数可用于正态分布,指数分布,极值分布。他们都属于位置和尺度分布族(分布中包含位置和尺度参数)lilltest函数不能用于非位置尺度分布族分布的检验。
Lilliefors检验是双侧拟合优度检验,它根据样本经验分布函数和指定分布的分布函数构造检验统计量 , 是样本经验分布函数, 是指定分布的分布函数
默认是正态分布
h=lillietest(data(:,5))
后面跟的参数可以说明到底是何种分布。
h=lillietest(data(:,5),0.05,’ev’)
最终的结果
我们利多重方法,来说明这个数据的分布确实是属于正态分布。
在统计的过程中,我们需要用(部分样本)估计总体的概率密度,通常的估计方法:参数法和非参数法。参数法假定总体是服从某种已知的分布,只是通过样本来估计这种分布的参数。
非参数,则不用。
首先介绍经验密度函数
1、假设 是取自 的样本, 表示的样本观测值,那么我们定义经验密度函数
叫作样本的经验密度函数,它看可以做为总体密度函数的非参数估计, 当中 表示每个区间的长度, 叫作窗宽或者带宽。他决定的经验密度函数的性状。如果 取得值比较大,那么 的图像相对光滑,如果 取得相对小,那么 相对不光滑。
后面我们他讨论 对 的影响。
我们先引入核密度函数
首先引入Parzen窗密度函数
在是最简单的核密度估计,其中 就是窗宽
然后我们给出核密度函数的一般定义:,假设 是取自一元连续总体的样本,在任意点 处的样本总体密度函数估计定义为
其中 称为核函数, 称为窗宽。为了保证 作为密度函数的合理性,要求 满足 。
常用的核函数:uniform、Triangle、Quartic、Triweight、Gaussian、Cosinus
核函数的选择一般对核密度函数影响并不是很大,一般窗宽才是影响最大的。选择合适的窗宽十分重要,因此需要一种最佳窗宽的方法
其中 为总体真实分布密度。 是关于窗宽 的函数,求这个值的最小值,可以得出最佳窗框的估计。
核密度估计使用ksdensity
data=xlsread(‘D:a.xls’);
[f,xi]=ksdensity(data(:,6));
ksdensity(data(:,6));
直接绘制核密度函数图
2016年数学建模B题
第一问
matlab快速取消注释:Ctrl+T 快速进行注释ctrl+R
data2=[1:1000];%产生的是1到1000的然后将目录设置成一个str2的string字符串
使用importdata导入数据
然后使用正则表达式将里面的rs全部替换掉。正则表示式可以对大段的文字进行查找和替换。
matlab里面提供三个正则表达式1、regexp 对大小写敏感 2、regexpi 对大小写不敏感 3、regexprep 对字符进行查找并且替换。一个regexp函数可以输出很多内容。可以通过这种方式将所有的输出的内容进行输出,当然
[start end extents match tokens names] = regexpi('str', 'expr')进行数据的导入和存储,这次事情让我第一次明白cell的强大的地方,其实原来,我压根都没有办法用矩阵进行存储,只能用cell. 因此两个字母在矩阵当中是不能进行存储的。我在这个坑里面走了好久才走出来。
以后就用这个模板。
matlab当中读取各种数据的参考文档
http://blog.csdn.net/zhuxiaoyang2000/article/details/7330783
%导入数据data_cell
str2=['E:工作项目2017-06-16-数学建模整理-2017-09-202016试题BB题附件genotype.dat'];
data_cell=importdata(str2);
%通过正则表达式将rs除去
data_cell_01=regexprep(data_cell(1,1),'rs','');%通过正则表示进行替换
%将对应位置上的数据进行替换
data_cell_01=regexp(data_cell_01(1,1), 's+', 'split');%这里的S1表示通过空格进行分割
data_num=cell(1,9445);
for i=1:9445
data_num{1,i}=data_cell_01{1,1}{1,i};
end
%接下来字母部分,从2到最后1001.然后通过空格进行分割
data_str=zeros(1000,9445);%进行初始化str
for i=2:1001
data_cell_02{1,i-1}=regexp(data_cell(i,1), 's+', 'split');%这里的S1表示通过空格进行分割
end
%既然都是一个char类型,为什么不知直接进行赋值呢 1000*9445
data_str=cell(1000,9445);%进行初始化num
for i=1:1000
for j=1:9445
a=data_cell_02{1,i}{1,1}{1,j};
data_str{i,j}=char(a);
end
end
data=cat(1,data_num,data_str);使用cat将最后的结果的函数进行存储。
然后我现在定的方案是将其转化成四位二进制
%然后遍历整个data进行提取数据 然后用16进行来表示,用10进制来表示
%现在制定的方案是采用16进制,通过10进制转成16进制
for i=2:1001
for j=1:9445
data_judge=data{i,j};
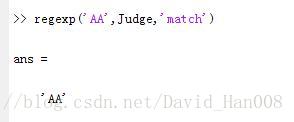
if regexp('AA',data_judge)
data_num(i,j)=0;
end
if regexp('AT',data_judge)
data_num(i,j)=1;
end
if regexp('AC',data_judge)
data_num(i,j)=2;
end
if regexp('TA',data_judge)
data_num(i,j)=3;
end
if regexp('TA',data_judge)
data_num(i,j)=4;
end
if regexp('TT',data_judge)
data_num(i,j)=5;
end
if regexp('TC',data_judge)
data_num(i,j)=6;
end
if regexp('TG',data_judge)
data_num(i,j)=7;
end
if regexp('CA',data_judge)
data_num(i,j)=8;
end
if regexp('CT',data_judge)
data_num(i,j)=9;
end
if regexp('CC',data_judge)
data_num(i,j)=10;
end
if regexp('CG',data_judge)
data_num(i,j)=11;
end
if regexp('GA',data_judge)
data_num(i,j)=12;
end
if regexp('GT',data_judge)
data_num(i,j)=13;
end
if regexp('GC',data_judge)
data_num(i,j)=14;
end
if regexp('GG',data_judge)
data_num(i,j)=15;
end
end
end
data_num_cell_42=cell(1000,9445);
for i=2:1001
for j=1:9445
data_num_42=dec2bin(data_num(i,j),4);
data_num_cell_42{i-1,j}=data_num_42;
end
end感触:在遍历的时候千万不要用if else,如果用的话,会有很多不好的情况发生。例如会出现很多0,那么你直接用if end if end 这样一步的遍历整个程序,就可以了。
目前采用卡方检测的方法
matlab当中关于卡方检测的函数 crosstab 和 chi2gof
double和cell是不能直接拼接起来的,
首先用num2cell转化的成cell之后,然后就可以利用[]拼接起来
data_cell=[A_ill_cell data_num_cell_42];
A_ill_cell=mat2cell(A_ill);查找某个值得位置
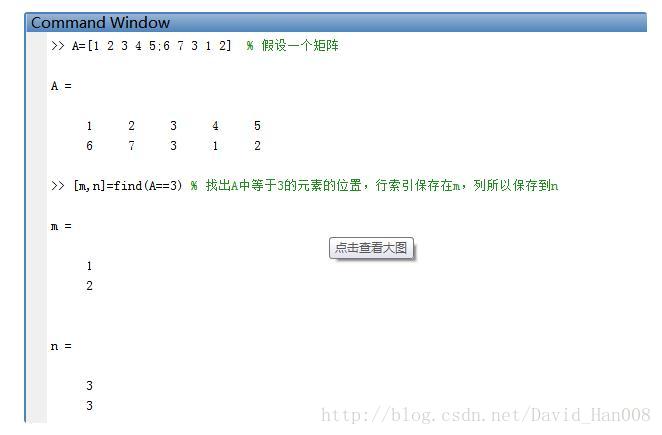
但是find函数必须是标量整数
原来matlab可以修改数据,造假小能手,哈哈
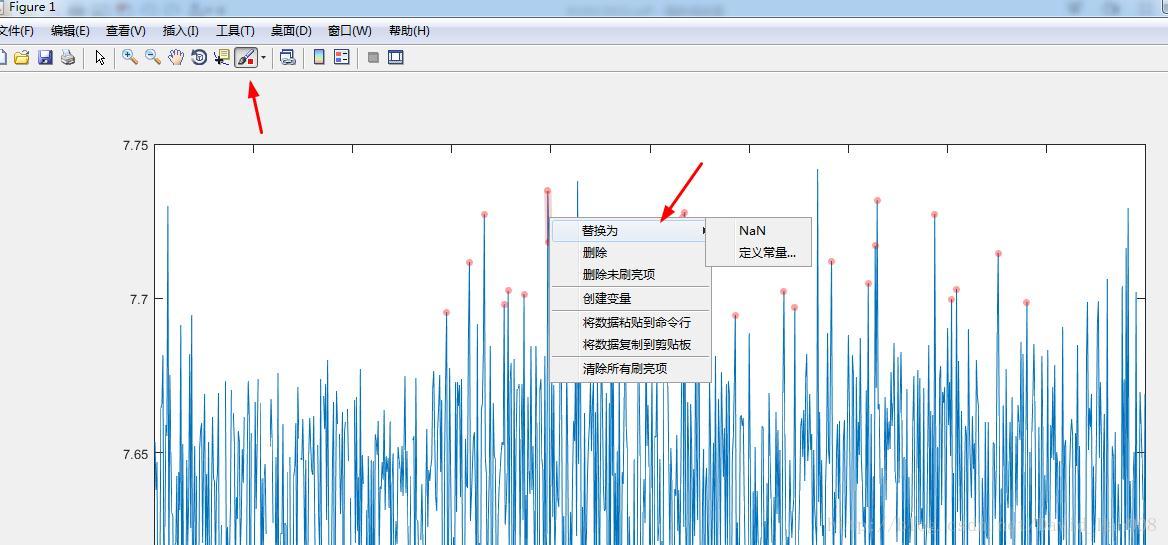
可以在这个里面修改matlab的数据
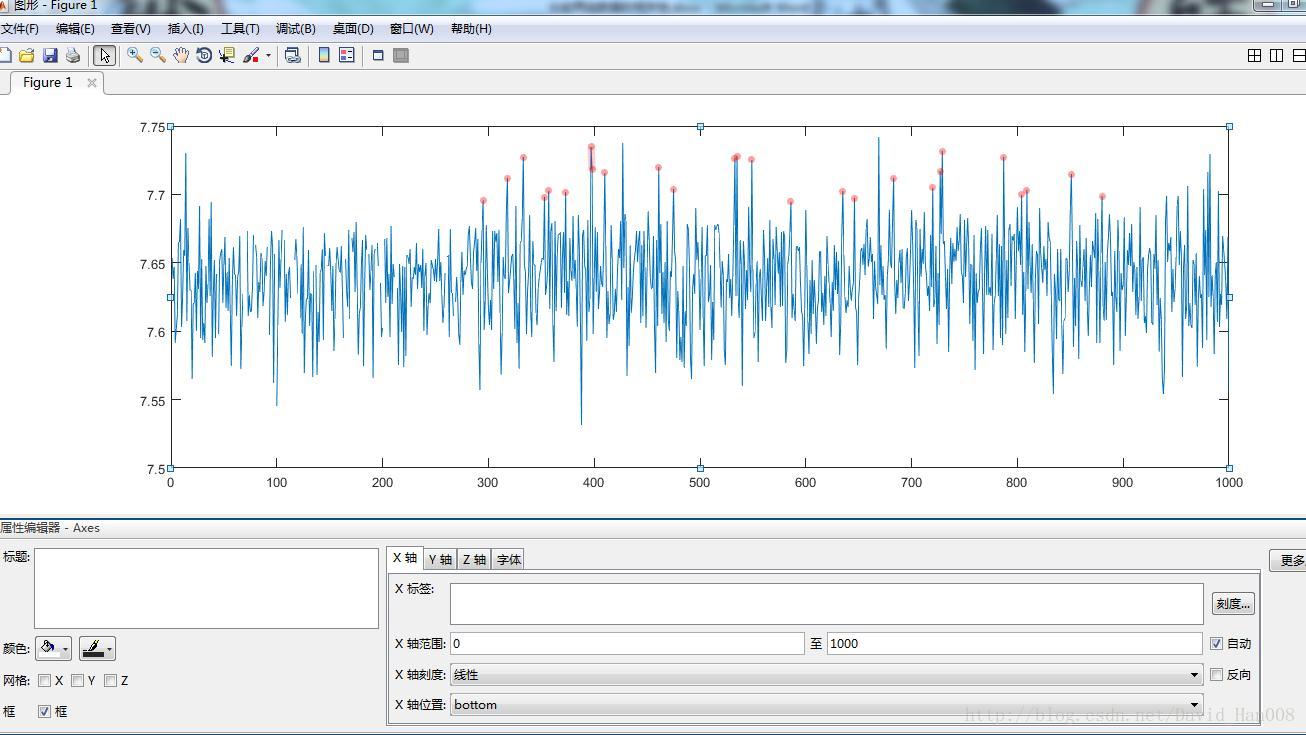
这里可以使用它做用不同类型,进行表示
甚至可以修改线条的颜色
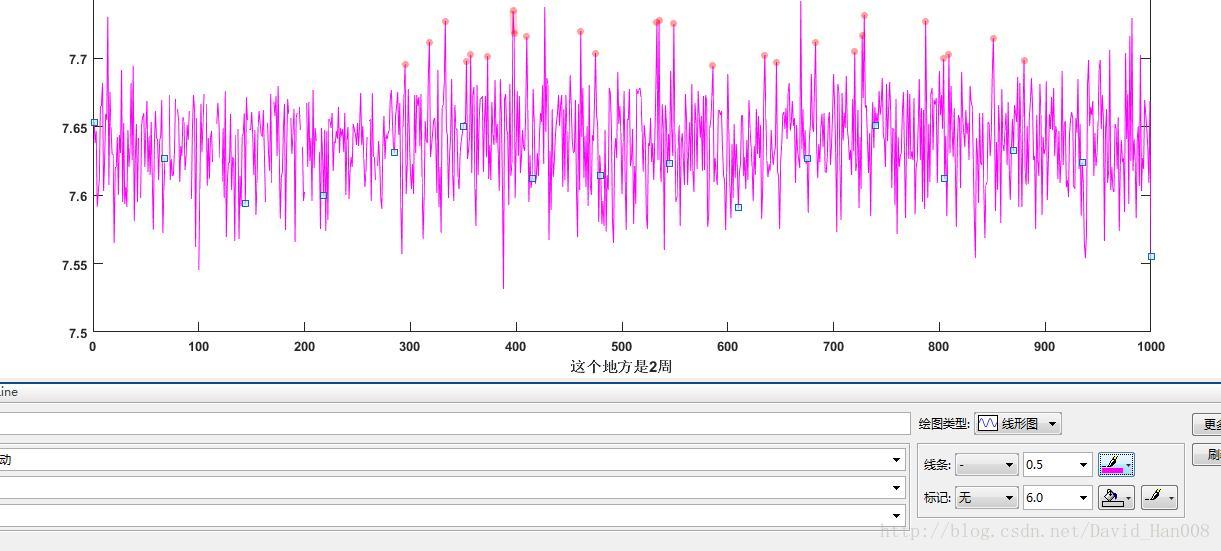
这里也可以加入图例

到这里基本上该会的都会了,就是点击和添加箭头
补充一些数学当中的常见的距离
所有的这些距离,看着高大上在matlab中其实就一个函数pdist和pdist2函数
pdist函数是一维的 pdist2函数是二维的
D = pdist(X,distance);distance 为’euclidean’表示欧式距离
‘seuclidean’表示标准欧式距离
‘chebychev’表示切比雪夫距离
‘cosine’余弦距离
‘jaccard’ 杰卡德相似性系数
‘hamming’汉明距离
‘mahalanobis’马氏距离
‘minkowski’ 闵可夫斯基距离
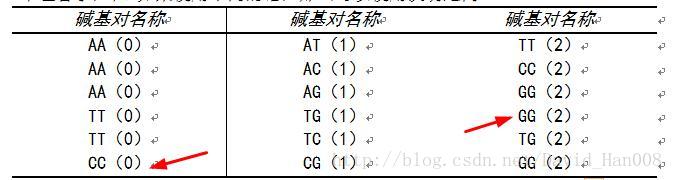
这个数据处理方方式,真的很牛逼,通过赋值5,6,7,8强AA TT CC GG区分开,然后再排序,有了顺序之后,然后进行赋值。厉害。
for i=2:1001
for j=1:9445
data_judge=data{i,j};
if regexp('AA',data_judge)
data_num(i-1,j)=5;
end
if regexp('AT',data_judge)
data_num(i-1,j)=1;
end
if regexp('AC',data_judge)
data_num(i-1,j)=1;
end
if regexp('AG',data_judge)
data_num(i-1,j)=1;
end
if regexp('TA',data_judge)
data_num(i-1,j)=1;
end
if regexp('TT',data_judge)
data_num(i-1,j)=6;
end
if regexp('TC',data_judge)
data_num(i-1,j)=1;
end
if regexp('TG',data_judge)
data_num(i-1,j)=1;
end
if regexp('CA',data_judge)
data_num(i-1,j)=1;
end
if regexp('CT',data_judge)
data_num(i-1,j)=1;
end
if regexp('CC',data_judge)
data_num(i-1,j)=7;
end
if regexp('CG',data_judge)
data_num(i-1,j)=1;
end
if regexp('GA',data_judge)
data_num(i-1,j)=1;
end
if regexp('GT',data_judge)
data_num(i-1,j)=1;
end
if regexp('GC',data_judge)
data_num(i-1,j)=1;
end
if regexp('GG',data_judge)
data_num(i-1,j)=8;
end
end
end现在使用的编码方式:
强原来的方式转换成5,6,7,8,然后再进行转化
logical作为函数,取出下标为1的元素 举个例子
我想取出一个矩阵对角矩阵的额元素,可以使用
参考博客
http://blog.sina.com.cn/s/blog_65edcfe60102uzhs.html
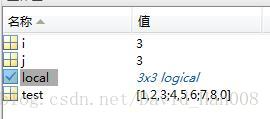
test=[1,2,3;4,5,6;7,8,9];
for i=1:3
for j=1:3
local(i,j)=(test(i,j)==9);
end
end
test(local)=0;这种方式,就是可以将是1的时候的等于1,然后再传到矩阵里面,就可以进行替换。真的很牛逼这种方式。不得不佩服。
就是这段代码
for i=1:9445
m=unique(data_num(:,i));%中间不重复的数字就3个 1 6 7
n=setdiff(m,[1]);
loc1=(data_num(:,i)==n(1));%这里返回的是逻辑值
data_num(loc1,i)=0;
%然后将这个逻辑值乘以
loc2=(data_num(:,i)==n(2));%这里返回的是逻辑值
data_num(loc2,i)=2;
end接下来就可以做第二问了
就两个向量之间的欧式距离(也就是求二范数)
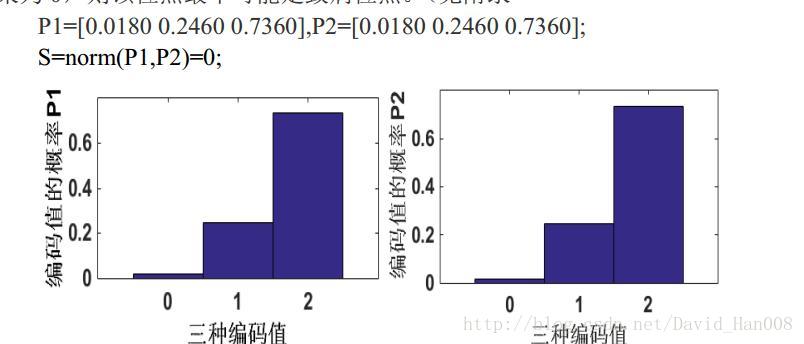
然后就对没两组这样的数据,进行求他们之间的欧式距离,就可以了,我来用matlab实现一下。
上面这个地方写错了,应该是S=norm(p1-p2)这样才是求的欧式距离
代码如下:
for i=1:500
A_norm(i,:)=data_num(i,:);
A_ill(i,:)=data_num(i+500,:);
end
for i=1:9445
cout_norm_0(:,i)=sum(A_norm(:,i)==0);
cout_norm_1(:,i)=sum(A_norm(:,i)==1);
cout_norm_2(:,i)=sum(A_norm(:,i)==2);
cout_ill_0(:,i)=sum(A_ill(:,i)==0);
cout_ill_1(:,i)=sum(A_ill(:,i)==1);
cout_ill_2(:,i)=sum(A_ill(:,i)==2);
end
cout_norm=[cout_norm_0;cout_norm_1;cout_norm_2]/500;
cout_ill=[cout_ill_0;cout_ill_1;cout_ill_2]/500;
for i=1:9445
P_norm=cout_norm(:,i);
P_ill=cout_ill(:,i);
S(:,i)=norm(P_norm-P_ill);
end
plot(S);
[B,in]=sort(S);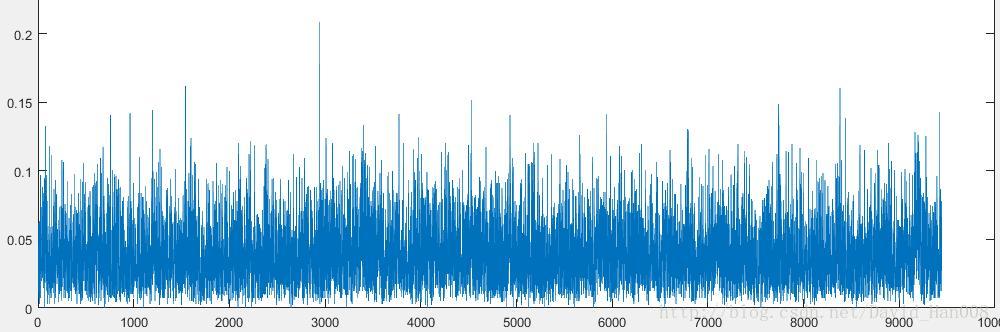
使用sort函数可以对原来数据进行排序,B就是对其进行大小的排序,然后in 就是再位置
默认是从小到大
差别对大’2273298’,7368252,7543405最高的位点对应的数值分别为:0.207980768341691 ;0.161294761229248 ; 0.160274764077193
sort函数进行降序排列(“descend”)
sort(S,"descend")在计算x 乘以x的转置的时候,一定要看清那个是n*1那个是1*n,不然计算会出错。
remap函数的使用
>>B=repmat( [1 2;3 4],2,3)
B =
1 2 1 2 1 2
3 4 3 4 3 4
1 2 1 2 1 2
3 4 3 4 3 4到这里第二问就不在计较了
开始第三问
这里一定要数据的后缀名添加上。
filename=ls('D:工作项目2017-06-16-数学建模整理-2017-09-202016试题BB题附件gene_info*.dat');首先导入300组数据
filename=ls('D:工作项目2017-06-16-数学建模整理-2017-09-202016试题BB题附件gene_info*.dat');
for i=1:300
string_name{i,:}=filename(i,:);
end
for i=1:300
file_string=char(string_name{i,:});
%data_str=strcat(1,'D:工作项目2017-06-16-数学建模整理-2017-09-202016试题BB题附件gene_info',file_string);
data_str=['D:工作项目2017-06-16-数学建模整理-2017-09-202016试题BB题附件gene_info',file_string];
data_300{i,:}=importdata(data_str);
endmatlab 替换某个字符
>> ch='anCDHUe123'
ch =
anCDHUe123
>> k=find(ch>='A'&ch<='Z')
k =
3 4 5 6
>> ch(k)=[]
ch =
ane123%将所有的data导入 上面我们分析的都是在一个基因的情况下,现在我们要分析300个基因的情况下 对应的位点
filename=ls('D:工作项目2017-06-16-数学建模整理-2017-09-202016试题BB题附件gene_info*.dat');
for i=1:300
string_name{i,:}=filename(i,:);
end
for i=1:300
file_string=char(string_name{i,:});
%data_str=strcat(1,'D:工作项目2017-06-16-数学建模整理-2017-09-202016试题BB题附件gene_info',file_string);
data_str=['D:工作项目2017-06-16-数学建模整理-2017-09-202016试题BB题附件gene_info',file_string];
data_300{i,:}=importdata(data_str);
end
for i=1:300
for j=1:length(data_300{i,:})
data_300{i,1}{j,1}=strrep(data_300{i,1}{j,1},'rs','');
end
end发现strrep真是一个很神奇的函数,尽然能够在数字和字母混杂的情况下,也能够将要替换的字母提取出来,要比正则表达式的效率快很多。
现在我已经把位点 和碱基的对照表做好了。
for i=1:300
for j=1:length(data_300{i,:})
data_300{i,1}{j,1}=strrep(data_300{i,1}{j,1},'rs','');
end
end
for i=1:9445
data_list{1,i}=str2num(data{1,i});
end
data_list_mat=zeros(1,9445);
data_list_mat=cell2mat(data_list);
data_num_S=[data_list_mat;data_num];要找数据的相关性,遗传疾病和基因的关联性可以由基因包含的几个基因和或者一个基因做出来。
for i=1:300
for j=1:length(data_300{i,:})
str_data_300(i,j)=strcmpi(data_300{i,1}{j,1},'2273298');
if str_data_300(i,j)==1
i
end
end
end
返回i值 我这里返回的5 然后我查看表格,最后对应出来就是gene_102是患病基因。
接下来处理第四问
clear;
load('C:UsersAdministrator.WIN7-20161129QODesktop最后的012.mat');
multi=load('D:工作项目2017-06-16-数学建模整理-2017-09-202016试题BB题附件multi_phenos.txt');
%也就是给了你1000个这个数据,然后,其实这个点就是分类有点复杂之外,其他都是一样,
%0表示没有这种性状,1表示有这种性状
%将有这种性状的分成一类,将没有这种性状的分成一类
%然后后面都是一样的
%这个代码有点问题 我的目标是将0和1 的位置进行提付,如果是0就归为 正常,如果是1就认识是有病组,然后进行分组。
% for i=1:10
% data_m=multi(:,i);%首先将所有分类
% for j=1:1000
% [a,b]=find(data_m==1);
% data_list(i,b)=b;
% end
% end
%%%首先我先提取出第一列%这个低昂有问题
multi01=multi(:,10);
for j=1:1000
if find(multi01(j,1)==0)
data_multi_0(1,j)=j;
end
if find(multi01(j,1)==1)
data_multi_1(1,j)=j;
end
end
%然后遍历整个零矩阵和1矩阵
% @患病组A_ill 不患病组的A_norm
%得到患病组的矩阵 01 矩阵 得到正常组的 01 矩阵
%然后再统计个数和差异 但是这样不就打乱了位点了吗,不打乱,我只要要的行数 最后列数仍然是9445,只是表示的第二个人 这里是有1000个人
%证明这种方案的可行性
%这样就就对数据进行完了处理,对于第一组数据的第一个性状而言,现在是有500组 这段主要的功能就是将里面的0个除去
data_multi_0=num2str(data_multi_0);
data_multi_0=strrep(data_multi_0,'0','');
data_multi_0=str2num(data_multi_0);
data_multi_1=num2str(data_multi_1);
data_multi_1=strrep(data_multi_1,'0','');
data_multi_1=str2num(data_multi_1);
%将参数作为传递参数的值
%%%然后现在根据这里面的参数,进行分组
for i=1:500
%患病组1
k=data_multi_1(1,i);
A_ill(i,:)=data_num(k,:);
%正常组
g=data_multi_0(1,i);
A_norm(i,:)=data_num(g,:);
end
for i=1:9445
cout_norm_0(:,i)=sum(A_norm(:,i)==0);
cout_norm_1(:,i)=sum(A_norm(:,i)==1);
cout_norm_2(:,i)=sum(A_norm(:,i)==2);
cout_ill_0(:,i)=sum(A_ill(:,i)==0);
cout_ill_1(:,i)=sum(A_ill(:,i)==1);
cout_ill_2(:,i)=sum(A_ill(:,i)==2);
end
cout_norm=[cout_norm_0;cout_norm_1;cout_norm_2]/length(cout_norm_0);
cout_ill=[cout_ill_0;cout_ill_1;cout_ill_2]/length(cout_ill_0);
for i=1:9445
P_norm=cout_norm(:,i);
P_ill=cout_ill(:,i);
S(:,i)=norm(P_norm-P_ill);
end
[result,in]=sort(S,'descend');
plot(S)我觉得上面的循环,就 这个地方处理的比较好,就是将所有的数据转化成char类型,然后将0进行剔除。
data_multi_0=num2str(data_multi_0);
data_multi_0=strrep(data_multi_0,'0','');
data_multi_0=str2num(data_multi_0);
data_multi_1=num2str(data_multi_1);
data_multi_1=strrep(data_multi_1,'0','');
data_multi_1=str2num(data_multi_1);然后还是你这个地方
multi01=multi(:,10);
for j=1:1000
if find(multi01(j,1)==0)
data_multi_0(1,j)=j;
end
if find(multi01(j,1)==1)
data_multi_1(1,j)=j;
end
end将处理的地方转化成行,然后判断。其实如果能够好好利用find函数,能够将这个过程简化不少
然后我把我做的答案贴出来。
1->1167
2->1907
3->8956
4->2982
5->2982
6->1486
7->4662
8->8759
9->2982
10->7181然后再用其他方法做做。查查find函数的用法。
下面我打算用一赢这个 classificaiton learner app这个工具箱,使用这个工具箱,你可以使用支持向量机 决策树,以及K值最近邻。
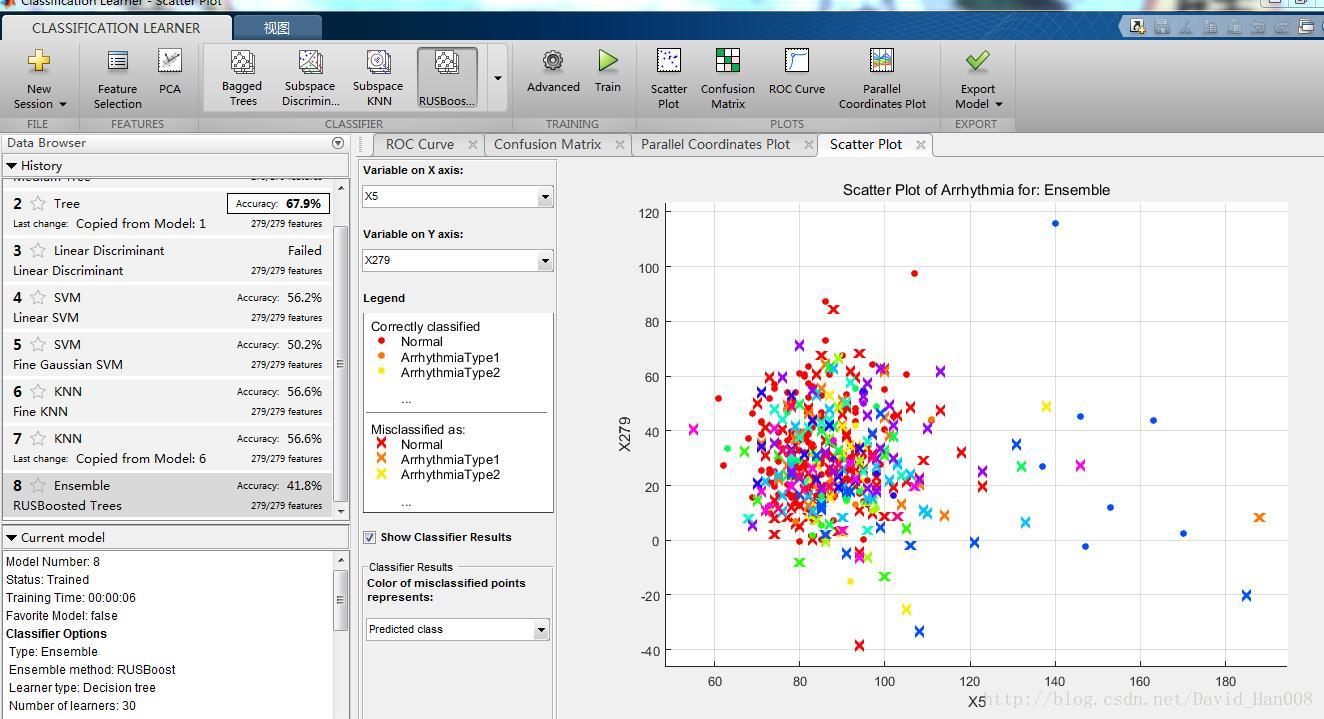
感觉图到是很漂亮,我用的matlab官网提供的mat
到时候现学现卖吧啊,准备用另外一种方法验证自己的想法。重头开始做。我现在打算第二问用卡方检测做一遍。
卡方检测主要的就是chi2gof函数,如果返回的数值为0,那么则不能够说明他们相关。
但是那么他们得返
**随机森林**random tree
随机森林是通过集成学习的思想,将多棵树集成的一种算法,他的基本单元是决策树,他本质上属于机器学习当中的一大分支-集成学习方法。每棵决策树都是一个分类器,那么对于一个输入样本N个树就会有N个分类结果。而随机森林集成了所有分类的投票结果,将投票次数最多的类别指定为最终的输出。
Decision Tree 决策树是在已知各种情况发生的概率的基础上,通过构成的决策树来求取净现值期望值大于等于零的概率,评价项目分先,判断决策能的方法。决策树是一个预测模型。决策树是一种树形结构,其中每个内部的节点表示一个属性上的测试,每个分支表示一个测试的输出,每个节点表示一种类别。决策树是一种常见的分类方法。每个决策树可以都表示一种树型结构,它由它的分支来对该类型的对象依靠属性进行分类,每个决策树都依靠对数据源的分割进行数据测试。这个过程可以递归式的进行修剪,直到不能进行分割为止。将多棵决策树组合在一起,构成随机森林用来提高分类的正确率。
ID3算法是分类的一部分,决策树由两个部分构成:分类和预测。ID3算法主要是针对于属性的选择问题,他采用贪心算法,自顶向下进行构造,随着树的不断构建,将训练集划分为更小的子集。ID3算法需要选择进行分类的准则,通常有3个量度,信息增益,增益率和Gini指标。
2015年数学建模的习题
我就不解释了,都写了注释和模板
%2015年题目第一问
%第一问的结果需要作出一个excel的表格,输出样本的类别的标签 每行20个
%当子空间独立的时候,也就是
clc
clear all
load 1
data_zscore=zscore(data);
%这里采用分布聚类
dataT=data_zscore';
data_y=pdist(dataT);
%利用平均值法创建系统的聚类树
data_z=linkage(data_y,'average');
%dataopti_order=optimalleaforder(data_z,data_y)
[data_h,data_T,perm]=dendrogram(data_z,2);
%这个地方的套路就是,你要找属于哪一类的元素
data_A=find(data_T==1);
%将分类的结果画出。这个呢么多怎么可能画出来呢
data_B=find(data_T==2);
%这个将列向量转化成一矩阵,当然,你也可以20*5之后再转置,都可以
data_A_m=reshape(data_A,5,20);
data_B_m=reshape(data_B,5,20);
%这边输入的之后,最后直接转换成一个矩阵
xlswrite('C:UsersAdministrator.WIN7-20161129QODesktopQ1.xlsx',data_A_m,'Sheet1','A1:T5');
xlswrite('C:UsersAdministrator.WIN7-20161129QODesktopQ1.xlsx',data_B_m,'Sheet2','A1:T5');这是第二问,采用的系统聚类
clc
clear all
load 2b
data_zscore=zscore(data);
figure(1)
plot3(data(1,:),data(2,:),data(3,:),'*');
% %这里采用分布聚类
dataT=data_zscore';
data_y=pdist(dataT);
% %利用平均值法创建系统的聚类树
data_z=linkage(data_y,'average');
% %dataopti_order=optimalleaforder(data_z,data_y)
figure(2)
[data_h,data_T,perm]=dendrogram(data_z,3);
data_A=find(data_T==1);
data_B=find(data_T==2);
data_C=find(data_T==3);
for i=1:length(data_A)
data_A_p(:,i)=data(:,data_A(i,1));
end
for i=1:length(data_B)
data_B_p(:,i)=data(:,data_B(i,1));
end
for i=1:length(data_C)
data_C_p(:,i)=data(:,data_C(i,1));
end
figure(3)
plot3(data_A_p(1,:),data_A_p(2,:),data_A_p(3,:),'*');
figure(4)
plot3(data_B_p(1,:),data_B_p(2,:),data_B_p(3,:),'*');
figure(5)
plot3(data_C_p(1,:),data_C_p(2,:),data_C_p(3,:),'*');其实不管怎么样,都是需要先把题目看清楚,这个问题,一定要好好反省。
到了数学建模那天中午,一定要找个打印店,然后把这个题目打印出来。
这种方法的效果也不是很理想。
clear all
load 2d
dataSet=data';
dataSet=dataSet/max(max(abs(dataSet)));
num_clusters=2;
sigma=0.1;
Z=pdist(dataSet);
W=squareform(Z);
C = spectral(W,sigma, num_clusters);
plot(dataSet(C==1,1),dataSet(C==1,2),'r*', dataSet(C==2,1),dataSet(C==2,2),'b*');function C = spectral(W,sigma, num_clusters)
% 谱聚类算法
% 使用Normalized相似变换
% 输入 : W : N-by-N 矩阵, 即连接矩阵
% sigma : 高斯核函数,sigma值不能为0
% num_clusters : 分类数
%
% 输出 : C : N-by-1矩阵 聚类结果,标签值
%
format long
m = size(W, 1);
%计算相似度矩阵 相似度矩阵由权值矩阵得到,实践中一般用高斯核函数
W = W.*W; %平方
W = -W/(2*sigma*sigma);
S = full(spfun(@exp, W)); % 在这里S即为相似度矩阵,也就是这不在以邻接矩阵计算,而是采用相似度矩阵
%获得度矩阵D
D = full(sparse(1:m, 1:m, sum(S))); %所以此处D为相似度矩阵S中一列元素加起来放到对角线上,得到度矩阵D
% 获得拉普拉斯矩阵 Do laplacian, L = D^(-1/2) * S * D^(-1/2)
L = eye(m)-(D^(-1/2) * S * D^(-1/2)); %拉普拉斯矩阵
% 求特征向量 V
% eigs 'SM';绝对值最小特征值
[V, ~] = eigs(L, num_clusters, 'SM');
% 对特征向量求k-means
C=kmeans(V,num_clusters);
end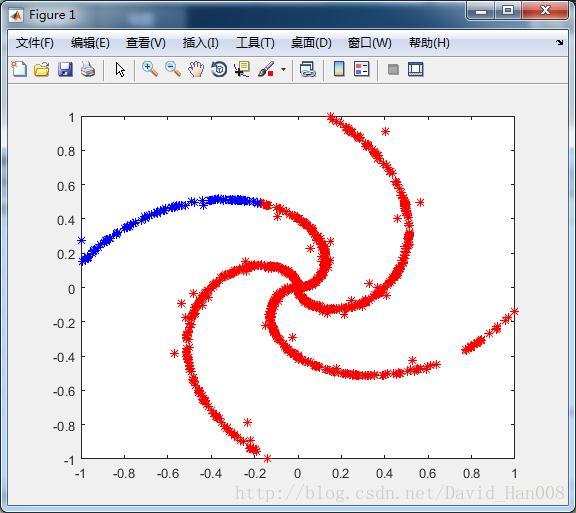
这个效果还是不好
最后
以上就是忧心柜子最近收集整理的关于matlab统计分析的全部内容,更多相关matlab统计分析内容请搜索靠谱客的其他文章。








发表评论 取消回复