论文标题:Collaborative Automated Driving: A Machine Learning-based Method to Enhance the Accuracy of Shared Information
发表期刊/会议:2018 21st International Conference on Intelligent Transportation Systems (ITSC)
问题:在基于后期融合的协同目标跟踪应用中,装有车载传感器的车辆检测周围的移动物体(如车辆、自行车),并与其他车辆共享检测到的物体的位置(纬度、经度和高度)、尺寸(长和宽)和motion信息(如,速度、加速度、行驶方向)。
假设ego车辆EV,与其协作的其他无人车AV,被检测的目标车辆TV:
> TV1-TV3都不在协作车辆AV的视野内,EV检测并提取TVs的信息,然后与AV共享。然而,为了让配备了十字路口移动辅助系统(IMA) 的AV利用收到的信息执行十字路口防撞应用,除了motion信息外,还必须接收TV的尺寸和中心位置。IMA和其他安全应用需要接收这些信息以进行避免碰撞的计算。
但是,V2V SAE(汽车工程师学会)标准要求共享信息提供物体中心点的位置;由于车载传感器(如摄像头、激光雷达)有其自身的局限性,不能连续不断的提供所需的信息,并且通常从不同的角度观测移动的object,要获得准确的尺寸和物体中心位置信息具有挑战性。
TV在同一车道上领先于EV:
> 这种情况下,EV的车载传感器看不到TV的长度,除了长度和宽度,还需要计算TV的中心点的位置。
1 目标尺寸和位置计算方法
由于,车载传感器提供了车辆与被检测物体最近点之间的距离,本文考虑通过采用机器学习的方法,获得被检测车辆的尺寸,从而计算出其中心位置。
1.1 车辆分类及尺寸提取
为了获得TV的尺寸,采用机器学习方法根据车辆的品牌和型号进行检测和分类:
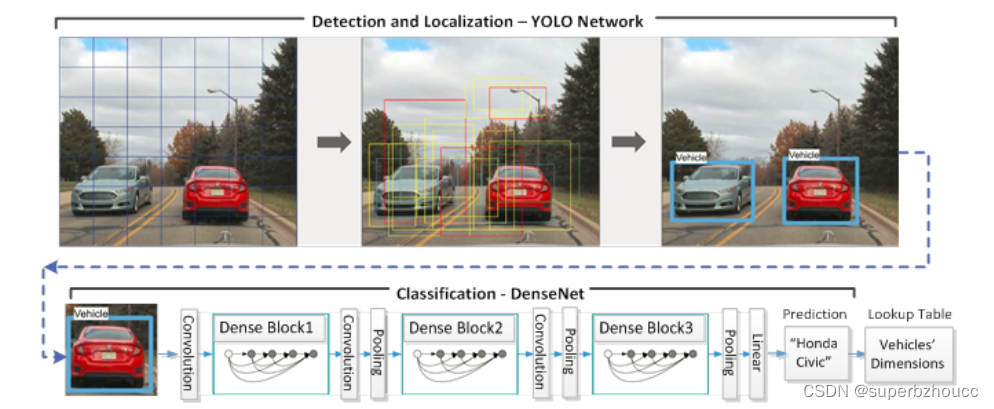
1. YOLO Network
以视频作为输入,其每一帧经过一个具有28个卷积层的YOLO 网络模型进行检测和定位,检测每一帧图像中是否有车辆并对其进行定位。
1)将图像划分为多个区域,并预测每个区域的存在目标车辆的概率;
2)通过将每个区域的预测概率进行加权以获得检测到的车辆的边界框;
3)根据边界框裁剪出检测到的车辆,并将其传给DenseNet以进行分类。
2. DenseNet(密集卷积网络)
采用一个40层的DenseNet,根据车辆的品牌和型号对其进行分类(如轿车、掀背车等),然后基于车辆的类型计算出一个近似的尺寸。
提取的尺寸信息将与目标跟踪系统的输出一起被用来计算被跟踪物体的中心位置。
1.2 目标跟踪模型
为了在ego车辆的坐标系下估计每个被跟踪的目标的状态,采用了无迹卡尔曼滤波(UKF)多目标跟踪算法 结合恒定加速度(CA)车辆运动模型:
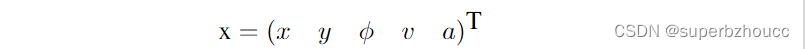
预测状态向量中每个元素的期望值和标准偏差,其中,包括位置坐标x、y,纵向和横向速度v、航向角(行驶方向)
ϕ
phi
ϕ,纵向和横向加速度a。
1.3 中心位置计算
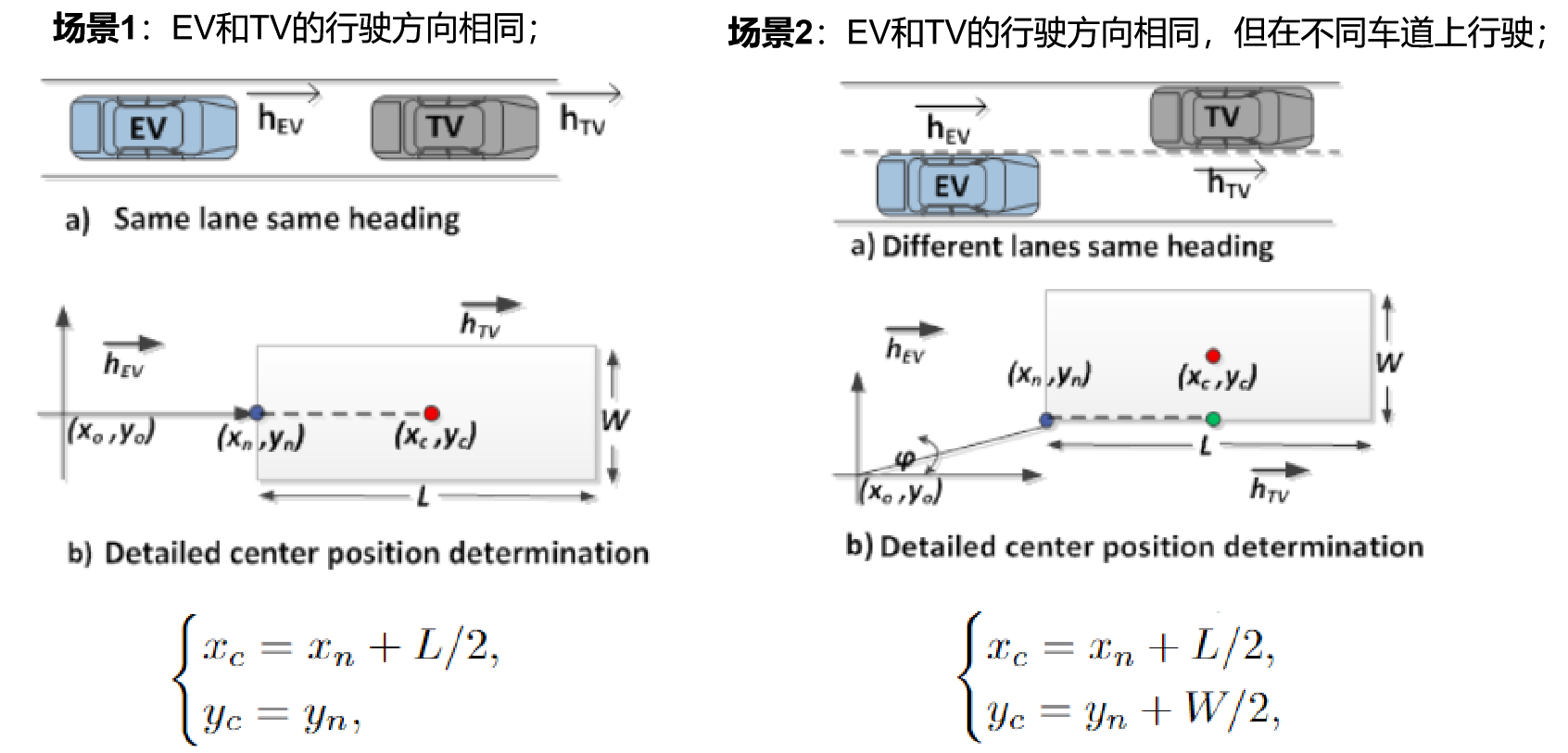
使用EV的目标跟踪系统和机器学习模型分别确定了TV的状态和尺寸之后,可获得TV离EV最近的点(xn,yn) ,TV的航向角φ以及长L和宽W,就可以计算TV的中心位置(xc, yc)。
本文考虑EV从TV的正后方和后侧角度观测的三种场景(hEV和hTV分别表示EV和TV的行驶方向,(xo, yo)为EV目标跟踪系统的坐标系的原点),根据TV所处的象限,采用不同的中心点位置计算方法:

2 与目标跟踪系统结合
所提出的深度学习方法将整合在目标跟踪系统中:
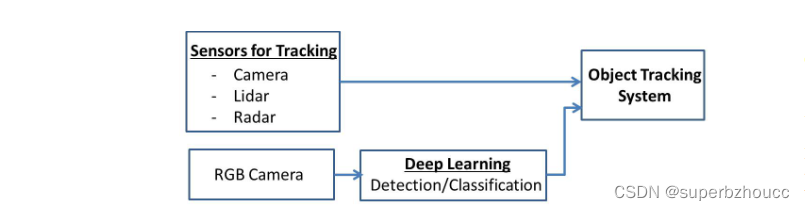
最终,需要共享的信息,除了目标跟踪系统估计的状态变量外,还包括所提出的深度学习模型生成的目标物体的尺寸和中心点位置。
3 实验
3.1 物体分类和维度提取
由于,车辆分类是根据品牌和型号进行的,需要为每个车型收集大量的数据。首先,采用了Stanford数据集和CIFAR-10数据集,其中包括车辆的正面、背面和侧面图像。另外,手动拍摄了13个不同品牌和型号的车辆图片数据,且都为后视图,其中每个品牌和车型都收集了850多张图片。利用这3个数据集对分类模型DenseNet(密集卷积网络)进行多阶段训练:
1)用CIFAR-10数据集进行训练,得到网络的初始权重。
2)使用得出的初始权重,在包含196个类型车辆的Stanford数据集上训练网络。
3)在手动收集的包含13个常见车辆类型的数据集上对网络进行微调。
3.2 中心位置计算
为评估中心位置计算的准确性,对EV和TV进行以下设置:
1) 车辆配置
该评估仅针对轿车类型的车辆进行。使用两辆DENSO的原型车进行实验,EV配备了高精度的OXFORD XT GPS,GPS提供的定位信息为车辆的中心位置,并以10Hz的速度记录。TV是2015年的特斯拉Model-S,安装了UBlox GPS,因此TV的GPS定位信息也为车辆的中心位置。两辆车的GPS数据用于计算EV和TV中心之间的距离,被用作评估的参考距离。
2) 驾驶场景
场景1,EV和TV在同一条车道上同向行驶,且TV一直在EV前面行驶。
场景2,EV和TV在两个相邻的车道上同向行驶,且TV一直在前面。
场景3,EV和TV在两条车道上行驶,两辆车都改变车道以产生不同的方向。
3) 与TV中心位置的接近程度
这个指标显示了当提出的方法被整合到跟踪系统中时,TV的估计中心位置与它的真实值(用GPS测量)之间的我偏差。并将其与跟踪系统运行时不包括所提出的方法的情况进行比较。
4 总结
提出了一种基于机器学习的方法,与目标跟踪系统相结合,以提高协同自动驾驶应用的共享信息的准确性。使用两个YoLo网络和DenseNet分别进行目标检测和分类,通过分类来协助提取目标物体的尺寸,而提取的尺寸信息用于估计物体中心点位置。该方法提供了V2V协同多目标追踪 所需的被追踪物体目标的尺寸和中心点的位置。
本文重点只放在感知方面,未考虑实际的数据共享和将共享数据纳入V2V无线信息的细节。
仅考虑两辆车之间的协作。
最后
以上就是寒冷日记本最近收集整理的关于V2V协同多目标跟踪——目标尺寸和位置估计1 目标尺寸和位置计算方法3 实验4 总结的全部内容,更多相关V2V协同多目标跟踪——目标尺寸和位置估计1内容请搜索靠谱客的其他文章。








发表评论 取消回复