自动驾驶四大核心技术,分别是环境感知、精确定位、路径规划、线控执行。环境感知是其中被研究最多的部分,不过基于视觉的环境感知是无法满足无人驾驶要求的。
环境感知主要包括三个方面,路面、静态物体和动态物体。对于动态物体,不仅要检测还要对其轨迹进行追踪,并根据追踪结果,预测该物体下一步的轨迹(位置)。这在市区,尤其中国市区必不可少,最典型场景就是北京五道口:如果你见到行人就停,那你就永远无法通过五道口,行人几乎是从不停歇地从车前走过。人类驾驶员会根据行人的移动轨迹大概评估其下一步的位置,然后根据车速,计算出安全空间(路径规划),公交司机最擅长此道。无人车同样要能做到。 要注意这是多个移动物体的轨迹的追踪与预测,难度比单一物体要高得多。这就是MODAT(Moving Object Detection and Tracking)。也是无人车最具难度的技术。
图:无人车环境感知框架
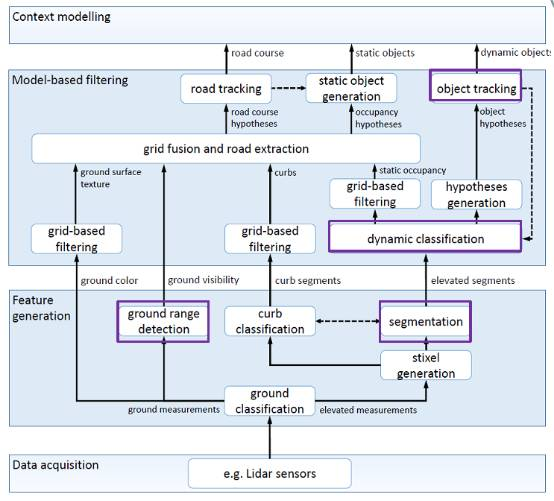
这是基于激光雷达的环境感知模型,搞视觉环境感知模型研究的人远多于激光雷达。不过很遗憾地讲,在无人车这件事上,视觉不够靠谱。
让我们来看计算机视觉的发展历程,神经网络的历史可追述到上世纪四十年代,曾经在八九十年代流行。神经网络试图通过模拟大脑认知的机理,解决各种机器学习的问题。1986 年Rumelhart,Hinton 和Williams 在《自然》发表了著名的反向传播算法用于训练神经网络,直到今天仍被广泛应用。
不过深度学习自80年代后沉寂了许久。神经网络有大量的参数,经常发生过拟合问题,即往往在训练集上准确率很高,而在测试集上效果差。这部分归因于当时的训练数据集规模都较小,而且计算资源有限,即便是训练一个较小的网络也需要很长的时间。神经网络与其它模型相比并未在识别的准确率上体现出明显的优势,而且难于训练。
因此更多的学者开始采用诸如支持向量机(SVM)、Boosting、最近邻等分类器。这些分类器可以用具有一个或两个隐含层的神经网络模拟,因此被称作浅层机器学习模型。它们不再模拟大脑的认知机理;相反,针对不同的任务设计不同的系统,并采用不同的手工设计的特征。例如语音识别采用高斯混合模型和隐马尔可夫模型,物体识别采用SIFT 特征,人脸识别采用LBP 特征,行人检测采用HOG特征。
2006年以后,得益于电脑游戏爱好者对性能的追求,GPU性能飞速增长。同时,互联网很容易获得海量训练数据。两者结合,深度学习或者说神经网络焕发了第二春。2012 年,Hinton 的研究小组采用深度学习赢得了ImageNet 图像分类的比赛。从此深度学习开始席卷全球,到今天,你不说深度学习都不好出街了。
深度学习与传统模式识别方法的最大不同在于它是从大数据中自动学习特征,而非采用手工设计的特征。好的特征可以极大提高模式识别系统的性能。在过去几十年模式识别的各种应用中,手工设计的特征处于统治地位。它主要依靠设计者的先验知识,很难利用大数据的优势。由于依赖手工调参数,特征的设计中只允许出现少量的参数。深度学习可以从大数据中自动学习特征的表示,其中可以包含成千上万的参数。手工设计出有效的特征是一个相当漫长的过程。回顾计算机视觉发展的历史,往往需要五到十年才能出现一个受到广泛认可的好的特征。而深度学习可以针对新的应用从训练数据中很快学习得到新的有效的特征表示。
一个模式识别系统包括特征和分类器两个主要的组成部分,二者关系密切,而在传统的方法中它们的优化是分开的。在神经网络的框架下,特征表示和分类器是联合优化的。两者密不可分。深度学习的检测和识别是一体的,很难割裂,从一开始训练数据即是如此,语义级标注是训练数据的最明显特征。绝对的非监督深度学习是不存在的,即便弱监督深度学习都是很少的。因此视觉识别和检测障碍物很难做到实时。而激光雷达云点则擅长探测检测障碍物3D轮廓,算法相对深度学习要简单的多,很容易做到实时。激光雷达拥有强度扫描成像,换句话说激光雷达可以知道障碍物的密度,因此可以轻易分辨出草地,树木,建筑物,树叶,树干,路灯,混凝土,车辆。这种语义识别非常简单,只需要根据强度频谱图即可。而视觉来说要准确的识别,非常耗时且可靠性不高。
视觉深度学习最致命的缺点是对视频分析能力极弱,而无人车面对的视频,不是静态图像。而视频分析正是激光雷达的特长。视觉深度学习在视频分析上处于最初的起步阶段,描述视频的静态图像特征, 可以采用从ImageNet 上学习得到的深度模型;难点是如何描述动态特征。以往的视觉方法中,对动态特征的描述往往依赖于光流估计,对关键点的跟踪,和动态纹理。如何将这些信息体现在深度模型中是个难点。最直接的做法是将视频视为三维图像,直接应用卷积网络,在每一层学习三维滤波器。但是这一思路显然没有考虑到时间维和空间维的差异性。另外一种简单但更加有效的思路是通过预处理计算光流场,作为卷积网络的一个输入通道。也有研究工作利用深度编码器(deep autoencoder)以非线性的方式提取动态纹理,而传统的方法大多采用线性动态系统建模。
光流只计算相邻两帧的运动情况,时间信息也表述不充分。two-stream只能算是个过渡方法。目前CNN搞空域,RNN搞时域已经成共识,尤其是LSTM和GRU结构的引入。RNN在动作识别上效果不彰,某些单帧就可识别动作。除了大的结构之外,一些辅助的模型,比如visual hard/soft attention model,以及ICLR2016上的压缩神经网络都会对未来的深度学习视频处理产生影响。
目前深度学习对视频分析还不如手工特征,而手工特征的缺点,前面已经说过,准确率很低,误报率很高。未来恐怕也难以提升。太多的坑要填。
MODAT首先要对视频分析,实时计算出地平面,这对点云为主的激光雷达来说易如反掌,对视觉来说难比登天。
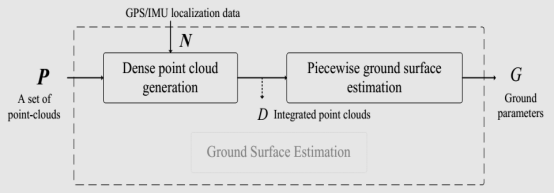
用分段平面拟合和RANSAC算法计算出真实地平面。实际单靠激光雷达的强度扫描成像,一样可以得出准确的地平面,这也是激光雷达用于遥感的主要原因,可以排除植被的干扰,获得准确的地形图,大地基准面。
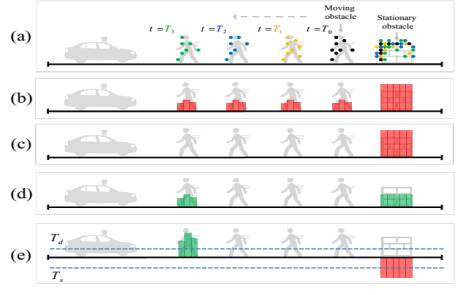
用VOXEL GRID滤波器将动静物体分开,黑棕蓝绿是激光雷达发射到行人身上的每个时间段的假设,与动态物体比,静态物体捕获的点云数自然要多。
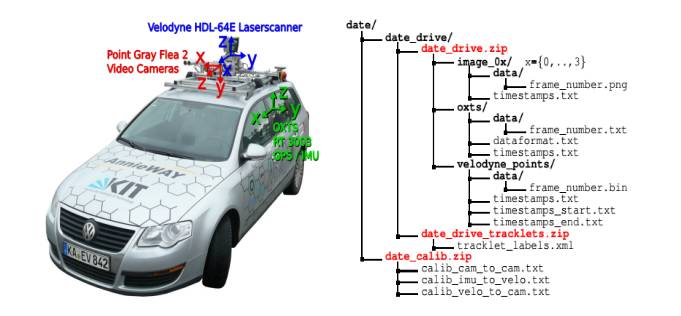
左边是深度学习领域人尽皆知的权威Kitti数据集的采集车,右边是数据集的数据格式和内容。Kitti对其Ground Truth有一段描述,To generate 3D object ground-truth we hired a set of annotators, and asked them to assign tracklets in the form of 3D bounding boxes to objects such as cars, vans, trucks,trams, pedestrians and cyclists. Unlike most existing benchmarks, we do not rely on online crowd-sourcing to perform the labeling. Towards this goal, we create a special purpose labeling tool, which displays 3D laser points as well as the camera images to increase the quality of the annotations.这里Kitti说的很明确,其训练数据的标签加注不是人工众包,而是打造了一个自动标签软件,这个软件把3D激光云点像光学图像一样显示出来,以此来提高标注的质量。很简单,激光雷达是3D Object Detection的标准,即使视觉深度学习再强大,与激光雷达始终有差距。
再来说一下Stixel(sticks above the ground in the image),中文一般叫棒状像素,这是2008年由奔驰和法兰克福大学Hern′an Badino教授推出的一种快速实时检测障碍物的方法,尤其适合检测行人,每秒可做到150甚至200帧,这也是奔驰和宝马双目的由来。Hern′an Badino后来被卡梅隆大学的机器人实验室挖走了,Uber的无人车主要就是基于卡梅隆大学机器人实验室开发的。Stixel的核心是计算棒状物的上下边缘和双目视差,构建一个Stixel,可以准确快速地检测障碍物,特别是行人。这是奔驰宝马大规模使用双目的主要原因,相对单目的行人识别,双目Stixel拥有碾压性优势。
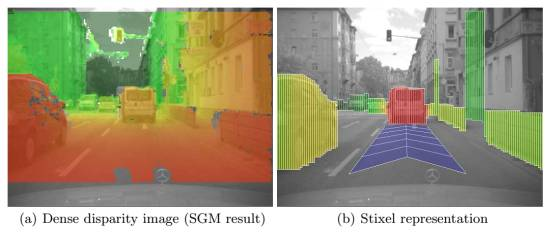
激光雷达的3D距离信息更容易获得,也更准确,因此建立Steixel更加快捷准确。
现在该说Tracking了,现在不少人把跟踪(tracking)和计算机视觉中的目标跟踪搞混了。前者更偏向数学,是对状态空间在时间上的变化进行建模,并对下一时刻的状态进行预测的算法。例如卡尔曼滤波,粒子滤波等。后者则偏向应用,给定视频中第一帧的某个物体的框,由算法给出后续帧中该物体的位置。最初是为了解决检测算法速度较慢的问题,后来慢慢自成一系。因为变成了应用问题,所以算法更加复杂,通常由好几个模块组成,其中也包括数学上的tracking算法,还有提取特征,在线分类器等步骤。
在自成一系之后,目标跟踪实际上就变成了利用之前几帧的物体状态(旋转角度,尺度),对下一帧的物体检测进行约束(剪枝)的问题了。它又变回物体检测算法了,但却人为地把首帧得到目标框的那步剥离出来。在各界都在努力建立end-to-end系统的时候,目标跟踪却只去研究一个子问题,选择性无视’第一帧的框是怎么来的’的问题。
激光雷达的Tracking则很容易做到,以IBEO为例,IBEO每一款激光雷达都会附送一个叫IBEO Object Tracking的软件,这是一个基于开曼滤波器的技术,最多可实时跟踪65个目标,是实时哟,这可是视觉类根本不敢想的事。Quanergy也有类似的软件,叫3D Perception。
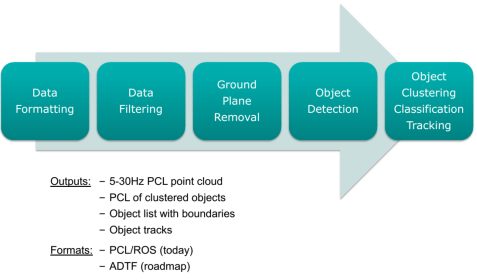
感知、决策(路径规划)、定位都是基于传感器或软件系统的,这也是科技类厂家的强项,不过线控执行系统则是传统汽车产业(不一定是整车厂)的绝对强项,这也是科技类厂家注定无法独立造车的主要原因,无论是谷歌还是百度,都必须要与传统汽车产业联合,才能进军无人车领域。下一节,我们就说说线控执行。
最后
以上就是诚心龙猫最近收集整理的关于自动驾驶核心技术之三:环境感知的全部内容,更多相关自动驾驶核心技术之三内容请搜索靠谱客的其他文章。








发表评论 取消回复