概述
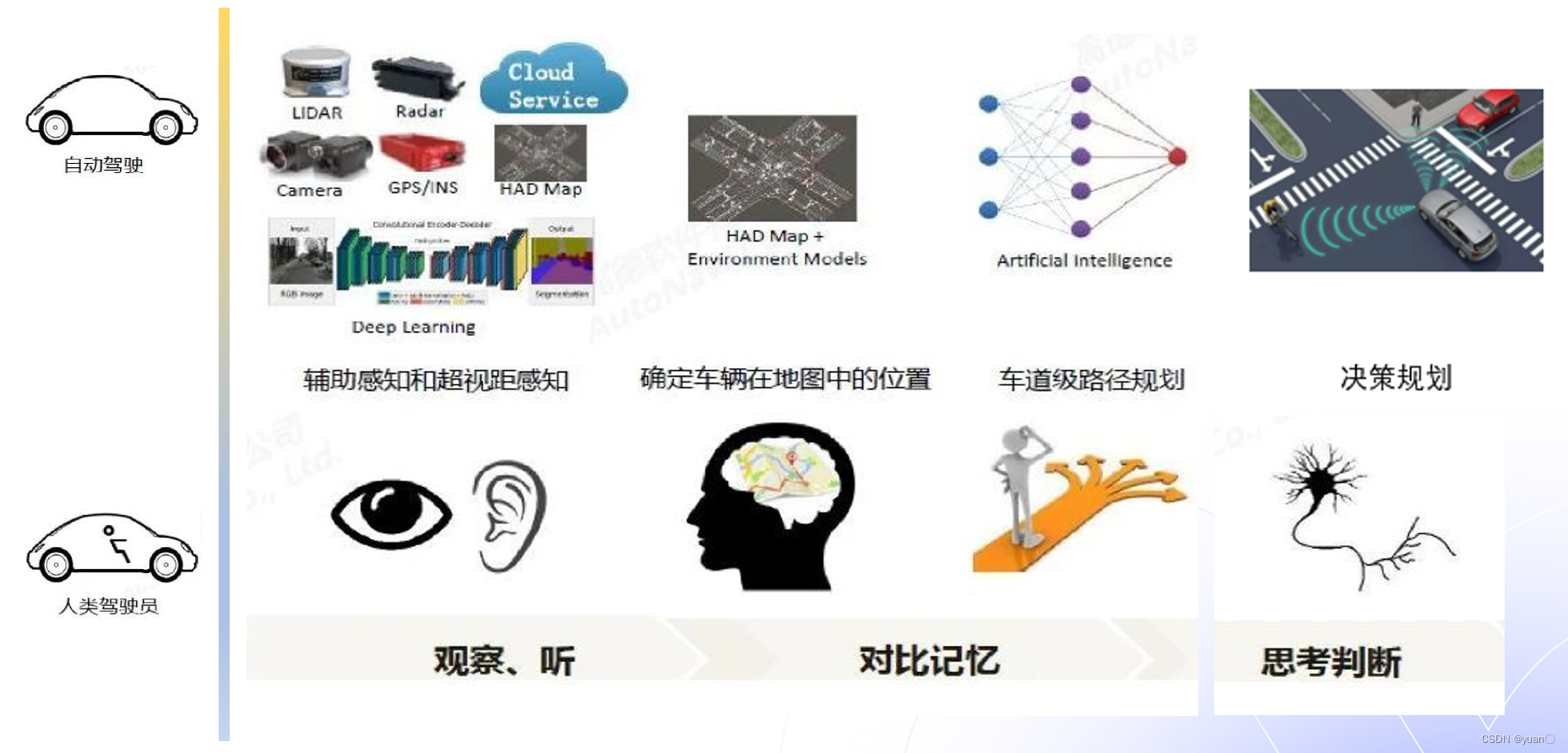
- 在自动驾驶系统中,与人类驾驶员对比,感知模块相当于人类眼和耳朵;
- 地图搜索路径和车道级别的路径规划,相当于人脑对道路的记忆和搜索;
- 最后决策规划功能,相当于人类对道路环境和客观世界的反应和判断。
规划技术就是包括地图搜索路径,以及道路决策和规划这部分重要的功能。
规划模块的作用相当于理解传感器以及高精地图模块等上游的“感知系统”获得的感知信息,并且在当前周期内进行思考并做出判断,然后把计算好的轨迹信息传递给下游模块进行控制指令的分解以及控制信号的计算。
作用
规划的作用:在遵循道路交通规则的前提下,将自动驾驶车辆从当前位置导航到目的地。
从专业术语上来说,路径规划是在遵循道路交通规则的前提下,计算出具体运动指令,将车辆从当前位置导航到目的地。它在自动驾驶技术中起到承上启下的重要作用。
在开放道路上,自动驾驶要处理的信息非常复杂,需要根据已知周围环境信息,如行人,红绿灯等交通信号,计算出安全、舒适的轨迹,完成自动驾驶任务。

主要功能
从功能上说,规划主要实现了三个功能:路由寻径,行为决策和轨迹规划。
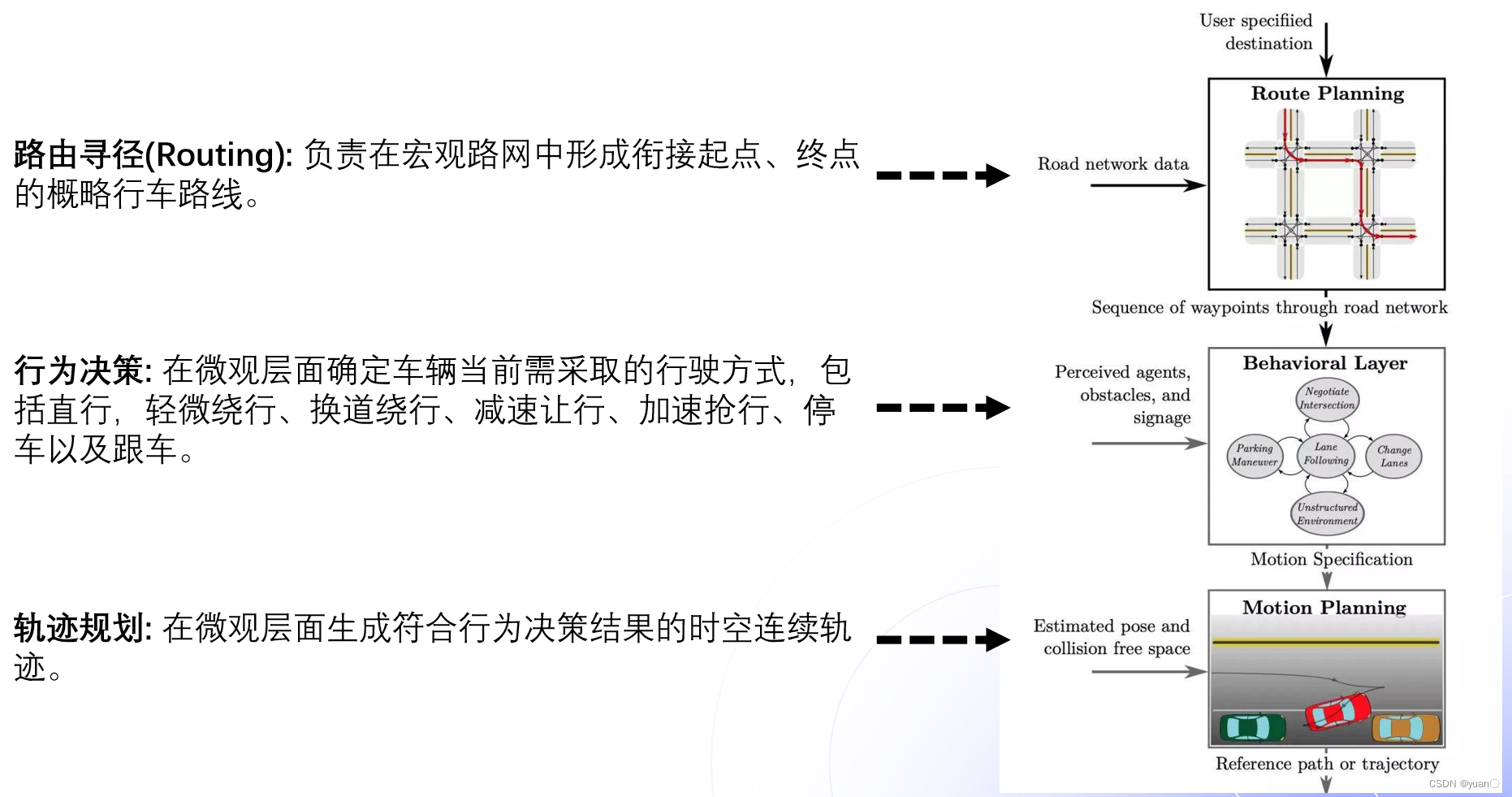
- 路由寻径(routing),在接收到一个给定的行驶目的地之后,结合地图信息,生成一条全局的路径,作为为后续具体 路径 规划 的参考;
- 行为决策层(Behavioral Layer)
- 行为决策层在接收到全局路径后,结合从 感知模块得到的环境信息(包括其他车辆与行人,障碍物,以及道路上的交通规则信息),作出具体的行为决策(决策车辆是否跟车、在遇到交通灯和行人时的等待避让、以及路口和其他车辆的交互通过;);
- 它主要提供一些描述性的策略,比如向左转还是向右转,亦或加速减速,它并不提供具体的像Motion级别车的state描述。
- 运动 规划 (Motion Planning)
- 是局部路径规划。它会根据具体的行为决策, 规划生成一条满足特定约束条件(例如车辆本身的动力学约束、避免碰撞、乘客舒适性等)的轨迹,该轨迹作为控制模块的输入决定车辆最终行驶路径。
- 即提供的是车当前的状态序列,比如车在t刻要以速度v和加速度a到达s位置,最后,Planning生成的动作序列发给Control模块,Control再对Planning的序列进行跟踪。
全局路径规划(Routing)
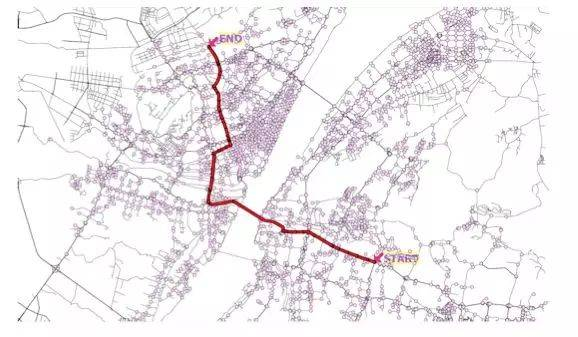
目的:
- Routing,可以翻译成“路由寻径”,正如其名称所示,其主要作用就是根据请求在地图上搜索出最优的全局路径
- 请求:给定车辆的当前位置与终止目标
- 地图:用的是高精地图
- 搜索:常用的搜索算法包括Dijkstra和A Star算法,以及在这两种算法基础上的多种改进算法。
- 最优:这里的“最优”包括路径最短,或者到达时间最快等条件。
- 全局路径:
- Routing输出的全局路径是一种静态路径,与时间无关。
- 目前的导航软件一样,主要提供全局路由的规划,属于路级别的规划信息,可简单的理解为传统地图导航+高精地图(包含车道信息和交通规则等);
模块输入:
- 地图数据
- 请求,包括:开始和结束位置
模块输出:
- 从起点到终点的路由线路
Dijkstra算法
- Dijkstra算法是由计算机科学家Edsger W. Dijkstra在1956年提出,用来寻找图形中节点之间的最短路径。在Dijkstra算法中,需要计算每一个节点距离起点的总移动代价。同时,还需要一个优先队列结构。对于所有待遍历的节点,放入优先队列中会按照代价进行排序。在算法运行的过程中,每次都从优先队列中选出代价最小的作为下一个遍历的节点。直到到达终点为止。
- Dijkstra算法的优点是:给出的路径是最优的;缺点是计算 时间复杂度比较高(O(N2)),因为是向周围进行探索,没有明确的方向。
A*算法
-
为了解决Dijkstra算法的搜索效率问题,1968年,A算法由Stanford研究院的Peter Hart, Nils Nilsson以及Bertram Raphael发表,其主要改进是借助一个启发函数来引导搜索的过程。具体来说,A算法通过下面这个函数来计算每个节点的优先级:
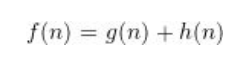
其中: -
f(n) 是节点n的综合优先级。当我们选择下一个要遍历的节点时,我们总会选取综合优先级最高(值最小)的节点。
-
g(n)是节点n距离起点的代价。
-
h(n) 是节点n距离终点的预计代价,这也就是A*算法的启发函数。
行为决策(Behavioral Layer)
在确定全局路径之后,自动驾驶车辆需要根据具体的道路状况、交通规则、其他车辆与行人等情况作出合适的行为决策。目的:
- 保障无人车的行车安全并遵守交通规则
- 为路径和速度的平滑优化提供限制信息
它的输入除了Routing输出路由结果信息外,主要是周围路况的实时信息
- 第一个路况信息是道路结构信息,如当前车道,相邻车道,汇入车道,路口等;
- 第二个是交通信号和标识,如红绿灯、人行横道、停车标志等;
- 第三个是障碍物信息,包括障碍物类型、位置、大小、速度、未来的可能运动轨迹。
它的输出有
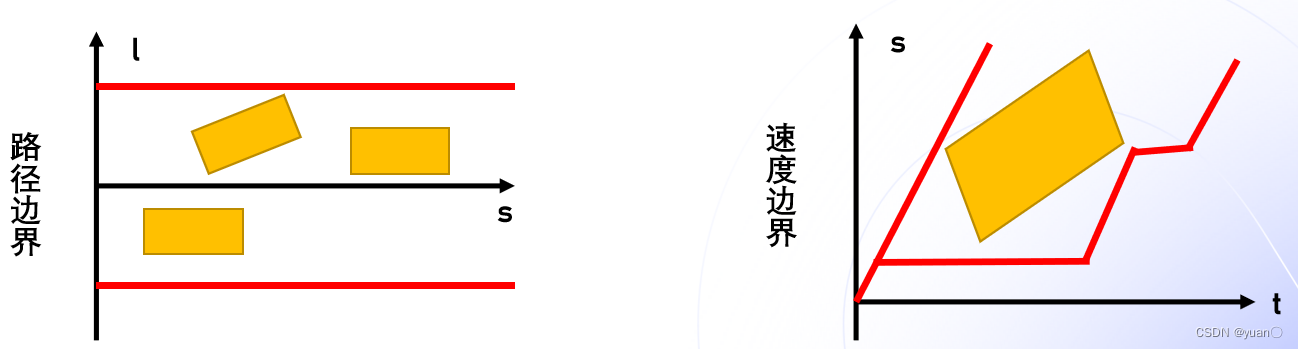
- 路径信息,包括路径长度以及左右限制边界;
- 路径上的速度限制边界
- 时间上的位置限制边界.
这一过程面临三个主要问题:
- 首先,真实的驾驶场景千变万化,如何覆盖?
- 其次,真实的驾驶场景是一个多智能体决策环境,包括主车在内的每一个参与者所做出的行为,都会对环境中的其他参与者带来影响,因此我们需要对环境中其他参与者的行为进行预测;
- 最后,自动驾驶车辆对于环境信息不可能做到100%的 感知,例如存在许多被障碍物遮挡的可能危险情形。
综合以上几点,在自动驾驶行为决策层,我们需要解决的是在多智能体决策的复杂环境中,存在 感知不确定性情况的 规划问题。可以说这一难题是真正实现L4、L5级别 自动驾驶技术的核心瓶颈之一,近年来随着 深度强化学习等领域的快速发展,为解决这一问题带来了新的思路和曙光。
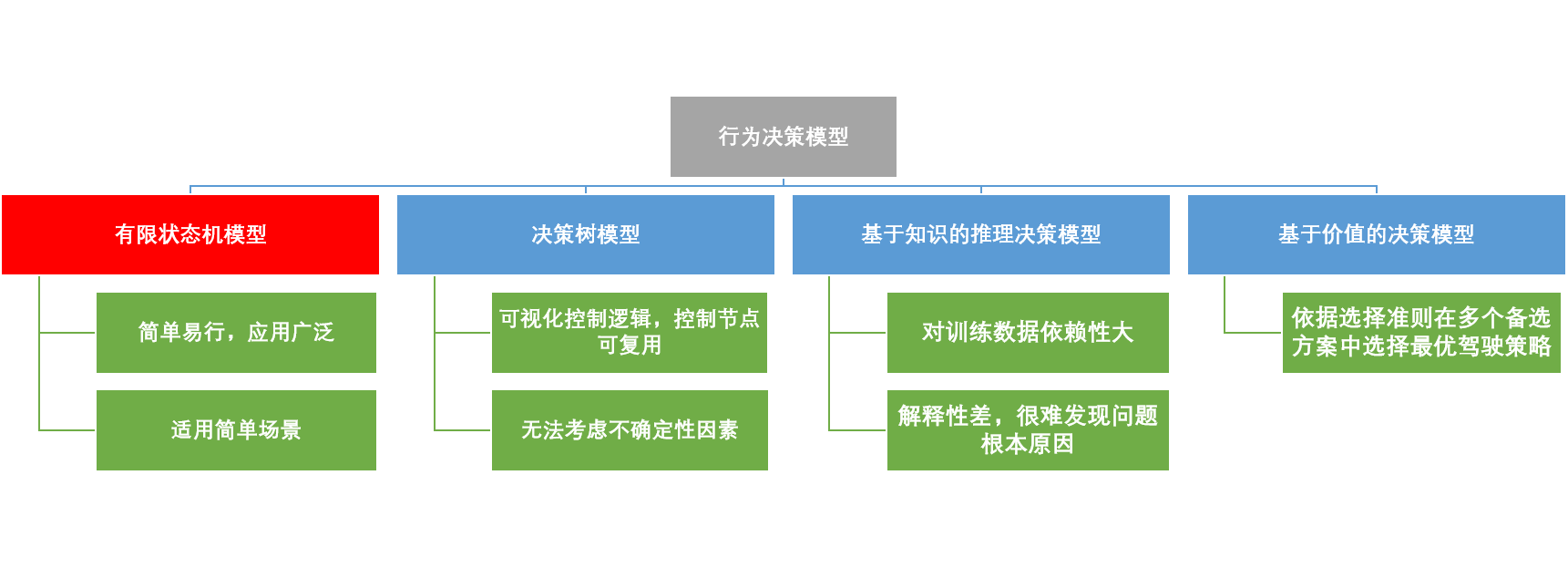
行为决策模型
行为决策模型分为四类:其中有限状态机模型简单易行,应用也比较广泛,Apollo中的场景决策就是采用这种模型。
有限状态机模型
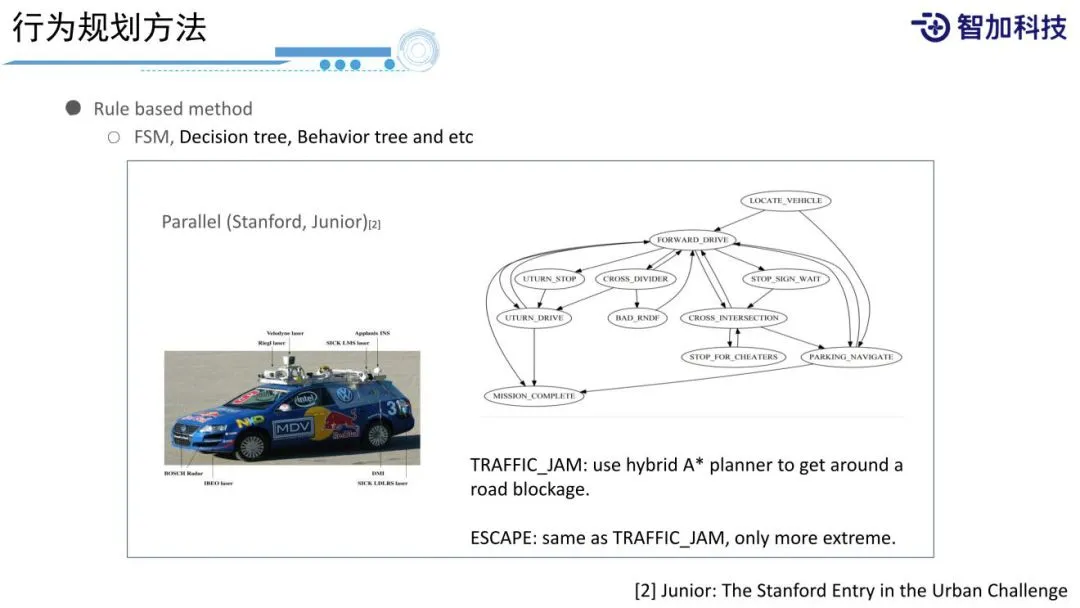
- 自动驾驶车辆最开始的决策模型为 有限状态机模型
- 车辆根据当前环境选择合适的驾驶行为,如停车、换道、超车、避让、缓慢行驶等模式,
- 状态机模型通过构建有限的有向连通图来描述不同的驾驶状态以及状态之间的转移关系
- 从而根据驾驶状态的迁移反应式地生成驾驶动作。
- 有限状态机模型是无人驾驶领域目前最广泛的行为决策模型,它为什么是最常用的呢?
- 因为其简单、有效、明确,主要通过定义一些状态,以及定义一些状态之间的转移条件和状态之间相互约束的条件,最后,通过有限状态的模型来处理我们面对的未知的复杂的环境,可以使机器人在没有遇到过的环境中做出比较正确的决策。
- 在Apollo代码中,也通过有限的scenario以及stage之间的transform来实现在道路上不同的运动之间的决策。
- 这种方法的好处是简单明确。缺点是很难通过定义有限的状态来处理一个很复杂的事情。因为实际道路上,可能会遇到很多很复杂的情况,很多都没有遇到过,只是采用有限的状态和有限的行为,很难把它处理的很好。
基于知识的推理决策模型
基于知识的推理决策模型由“场景特征-驾驶动作”的 映射关系来模仿人类驾驶员的行为决策过程,该类模型将驾驶知识存储在 知识库或者 神经网络中,这里的驾驶知识主要表现为规则、案例或场景特征到驾驶动作的 映射关系。进而,通过“ 查询”机制从 知识库或者训练过的网络结构中推理出驾驶动作。
该类模型主要包括:基于规则的推理系统[8]、基于案例的推理系统[9]和基于 神经网络的 映射模型[10]。
该类模型对先验驾驶知识、训练数据的依赖性较大,需要对驾驶知识进行精心整理、管理和更新,虽然基于 神经网络的 映射模型可以省去数据标注和知识整合的过程,但是仍然存在以下缺点:
- 其“数据”驱动机制使得其对训练数据的依赖性较大,训练数据需要足够充分[11];
- 将 映射关系固化到网络结构中,其解释性较差;
- 存在“黑箱”问题,透明性差,对于实际系统中出现的问题可追溯性较差,很难发现问题的根本原因。
POMDP
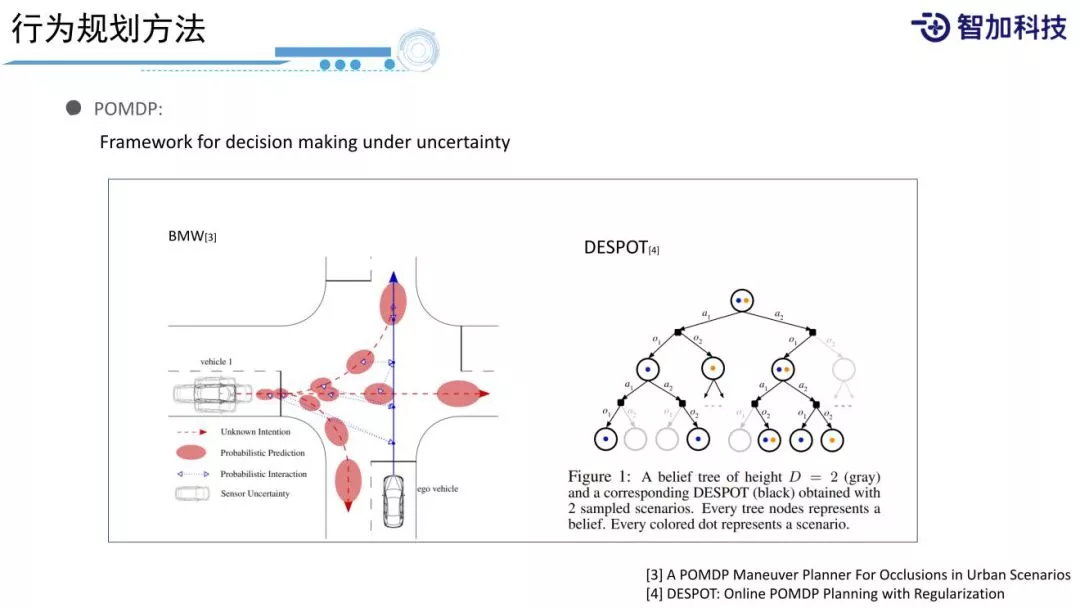
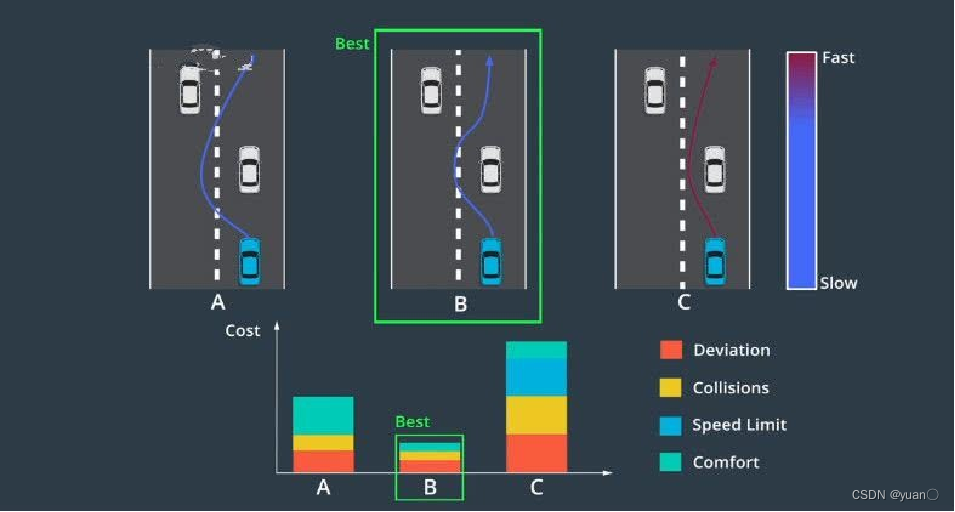
另一个比较常用的方法是POMDP,是一个将uncertainty考虑到decision making过程中的框架。所谓uncertainty,对于有规划经验的人,经常会抱怨,因为我们的上游是感知组,感知可不可以准点,不要有那么多噪音,感知的同学又说到,传感器能不能给准点,大家都有抱怨。但实际情况是,世界肯定是不确定的,所有感知的结果,包括感知的类型、位置,(如左图,可以看到左边的来车,它的位置在这个区域内是服从一定的概率分布的,并不是一个确定的结果,包括它未来的行为,有可能左转、右转或者直行,它的intention和轨迹都是不确定的。我们在规划时,怎样把这种不确定性考虑到规划中?
对于左图的场景,一个典型人类驾驶员的行为,会边开边看,边看边动,然后再根据当前情况再去行动。POMDP也采用了同样的方法,POMDP将每个状态表示成一个belief,然后通过观察来update belief,最终通过一些方法来求得一个在当前belief下的最优的Policy。[3][4]是一些Online/Offline POMDP求解方法,POMDP很好地解决了uncertainty问题,但是它主要的问题是计算量比较大,实际应用过程中需要很多的工程优化,才能取得比较好的成果。
基于价值的决策模型
根据最大效用理论,基于效用/价值的决策模型的基本思想是依据选择准则在多个备选方案中选择出最优的驾驶策略/动作[12]。
为了评估每个驾驶动作的好坏程度,该类模型定义了效用(utility)或价值(value)函数,根据某些准则属性定量地评估驾驶策略符合驾驶任务目标的程度,对于无人驾驶任务而言,这些准则属性可以是安全性、舒适度、行车效率等,效用和价值可以是由其中单个属性决定也可以是由多个属性决定。
Learning based methods
Learning based methods,包括Deep Learning、Deep Q-Learning、MCTS这些方法,这里不在详细介绍。这里提一点,Deep Learning的效果非常好,比前面两种方法效果都好,它的问题是Data Collection和Pipeline要求非常高。首先要有足够多的数据,然后整个Pipeline上要有足够完善的工具,包括仿真工具的完善程度,对系统的依赖程度比较高,并不是简单的写几行代码,制定一个规则就可以快速应用的。当然你可以得到一个很初步的版本,但是实际效果Input,背后训练的代价还是很大的。所以需要有很多的车辆配合来获取数据,得到数据的过程和处理数据的过程比写一套代码的工作量还是要大很多的。
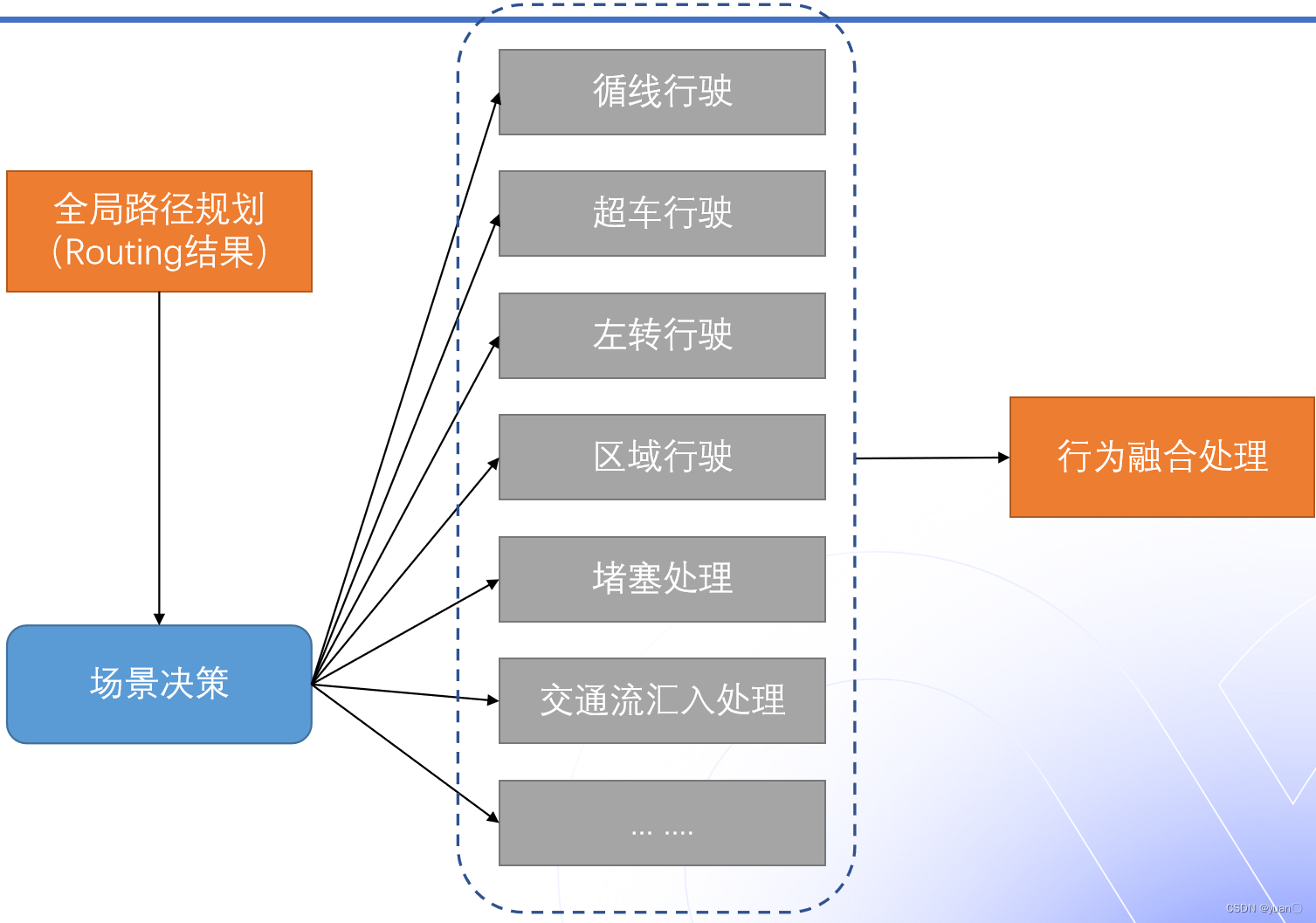
行为决策类型
行为决策主要做的的决策类型有:循线行驶,超车行驶,左转行驶,区域行驶,堵塞处理,交通流汇入处理等,最后再将这些决策进行融合,得到最终的决策结果。并作为轨迹规划的目标参考和限制。
轨迹规划(Motion Planning)
在确定具体的驾驶行为之后,我们需要做的是将“行为”转化成一条更加具体的行驶“轨迹”,从而能够最终生成对车辆的一系列具体控制信号,实现车辆按照 规划目标的行驶。这一过程称为 运动 规划 (Motion Planning)。
motion planning会结合导航给的全局路径进行局部路径规划;
- 导航给的地图路线只是规划过程中的一部分,我们仍需要构建沿这条路线前进的局部轨迹。
- 这意味着要处理一些不属于地图的物体:如其他车辆、自行车或行人。例如,我们可能需要与试图在我们前面掉头的汽车互动,或者我们可能希望超过一辆在公路上行驶的慢车。这些场景需要更低 级别、更高精确度的规划。我们将这一级别的规划称为轨迹规划。
- 轨迹规划的核心就是要解决车辆该怎么走的问题。轨迹规划的输入包括拓扑地图,障碍物及障碍物的预测轨迹,交通信号灯的状态,还有定位导航、车辆状态等其他信息。而轨迹规划的输出就是一个轨迹,轨迹是一个时间到位置的函数,就是在特定的时刻车辆在特定的位置上。
注意,注意块输出的路径是局部路径而非全局路径。举个简单示例加以说明,假如无人车需从长沙智能驾驶研究院行驶至长沙高铁南站,首先需借助Routing(路由寻径)模块输出全局导航路径,接下来才是规划模块基于全局导航路径进行一小段、一小段具体行驶路径的规划。
规划的目标主要是为了合适的轨迹供无人驾驶车辆完成行驶任务。对其要求有三:
- 在合理的时间到达规划的目标或终点
- 避免与障碍物碰撞
- 更好的乘坐体验,加速和减速过程尽量平滑
规划的输入与决策类似,除了决策的输出信息外,同样也有周围路况的实时信息,即道路结构信息,交通信号和标识和障碍物信息。
- 决策输出信息
- 道路结构信息
- 交通信号和标识
- 障碍物信息
输出:
- 稳定平滑的轨迹点,其中包含了每个点的位姿和时间信息。
运动 规划 的概念在机器人领域已经有较长时间的研究历史,我们可以从数学的角度将它看做如下的一个优化问题:

在以机器人为代表的许多场景中,我们可以认为周围的环境是确定的。在这种情况下,所谓的 路径 规划 ,是指在给定的一个状态空间Χ,寻找一个满足一定约束条件的 映射σ:[0,1]➞Χ,这些约束包括:
- 确定的起始状态以及目标点所在的区域
- 避免碰撞
- 对路径的微分约束(例如在实际问题中路径曲率不能太小,对应于其二阶 导数的约束)
该优化问题的目标泛函定义为J(σ),其具体意义可以表示为路径长度、控制复杂度等衡量标准。
然而在自动驾驶问题中,车辆周围的环境是持续动态变化的,因此单纯的 路径 规划 不能给出在行驶过程中一直有效的解,因此我们需要增加一个维度——时间T,相应的 规划问题通常被称为轨迹 规划。

时间维度的增加为 规划问题带来了巨大的挑战。例如,对于一个在2D环境中移动一个抽象为单点的机器人,环境中的障碍物近似为多边形的问题。 路径 规划 问题可以在多项式时间内求解,而加入时间维度的轨迹 规划问题已经被证明是NP-hard问题。
在自动驾驶的实际场景中,无论是对车辆本身还是对周围环境,建立更为精确的模型意味着对优化问题更为复杂的约束,同时也意味着求解的更加困难。因此实际采用的算法都是建立在对实际场景的近似前提下,在模型精确性和求解效率二者之间寻求一个最佳的平衡点。
下文对自动驾驶领域目前常见的几类 运动 规划 算法分别进行介绍,在实际中,往往是其中几类思想的结合才能最终达到比较好的 规划结果,并满足更多的不同场景。
基于搜索的规划算法
- 其基本思想是将状态空间通过确定的方式离散成一个图(即将规划问题建立成图),然后利用各种启发式搜索算法在图中寻找一个从起点到终点的最优路径。
- 在将状态空间离散化的过程中,需要注意的是确保最终形成的栅格具有最大的覆盖面积,同时不会重复。如图5所示,左边的栅格是由直行、左转90°、右转90°这三种行为生成;而如果选择直行、左转89°、右转89°三种行为,最后就无法生成一个覆盖全部区域的栅格结构。
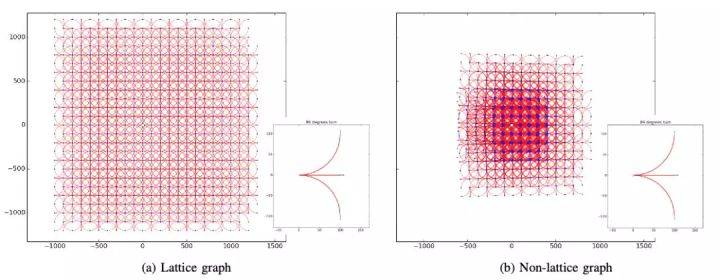
- 在将状态空间栅格化之后,我们就可以使用Dijkstra、 A*搜索算法,完成最终的 规划。
- Dijkstra算法的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。迪杰斯特拉算法的成功率是最高的,因为它每次必能搜索到最优路径。但迪杰斯特拉算法的搜索速度是最慢的:随着图维度的增大,其计算效率会明显变低。
- 然而在实际复杂环境中,栅格数目众多,并且环境随时间动态变化,会导致搜索结点过多,因此发展出了多种改进算法,用以处理不同的具体场景:
- Hybrid A* 算法,在A*算法的基础上考虑了车的最大转向问题,例如限定计算的路径上车最大转向不超过5°。该算法目前的应用场景有车掉头(Stanford 参加DARPA 挑战赛使用的Junior车采用了该算法进行uturn),泊车等等对方向盘控制要求较高的场景。
- D*、D*Lite算法,事先由终点向起点进行搜索,使用Dijkstra算法,存储路网中目标点到每个点的最短路径长度k, 和该节点到目标点的实际长度值h,开始情况下 k==h, 并且存储每个节点的上一个节点,保证能够沿着链接走下去。
- 计算结束后,获取了一条当时最优路径。当车行驶到某个节点时,通过传感器发现该节点已经无法通行(有障碍物),则对已存储的路网信息一些相关点的h值进行修改(变大),选择一个邻居点满足仍然h==k的,即仍然是最优路径上的点,作为下一个点。
- 然后走到终点。该类算法适用于在未知环境中的导航以及 路径 规划 ,广泛用于目前各种 移动机器人和自主车辆载具,例如“机遇号”和“勇气号”火星车。
优缺点:
- Search based的好处是可以得到一个全局层面的最优解,只要将规划问题建立成图,图上就存在着唯一的最优解
- 它的问题是只适用于比较低维数的规划问题,当规划问题state的维数比较高之后,search起来就比较耗时,面临着指数爆炸的问题。对于我们正常的纵向规划,需要同时规划车辆的位置、速度、加速度以及时间,一般在4~5维以上就用不了这种search method。
基于采样的规划算法
通过对连续的状态空间进行采样,从而将原问题近似成一个离散序列的优化问题,这一思路也是在计算机科学中应用最为广泛的算法。在 运动 规划 问题中,基于采样的基本算法包括概率路线图(PRM)和快速搜索随机树(RRT)算法。

面对高维的运动规划问题,我们一般采用sample based方法:
- 先在state space进行sample
- 然后对这些sample的点进行cost等连接方法
Sample based的优点是可以同时处理比较高维数的运动规划,然后可以将dynamic model也放在规划过程中;缺点是只能得到一个概率层面上的最优,只要有足够多的求解时间,就会得到一个接近于概率1的最优解,显然实际过程中不可能给出足够多的时间,或者一会儿就要重新规划了。在有限时间内,得到的就不是一个最优解,导致规划之后的结果可能比较粗糙,还需要一些后优化的方法和后处理的方法。
Optimization based
对于自动驾驶车辆,optimization based会将规划的结果通过曲线的形式来表示,比如Polynomial、Bezier、Spline,通过多段的具有解析解的曲线形式来表示,从而将规划问题转化成求解曲线的参数问题,这样比较好处理加一些想要的约束,转化成优化问题,对于优化问题,我们有很多的求解方法,比如NLP、QP等。optimization based方法的好处是可以有很多不同的function,可以满足不同的目标,并且很直观求解速度也很快;它的问题是多个目标的权重如何加?求解的最优解一般都比较贴近约束的边界,如何来处理这些问题?而且并不能把所有的问题都很好地转化成一个优化问题,也不是所有的优化问题都有解,比如非线性优化求解起来比较麻烦,是不是凸的、非凸的,这都是一些问题。
最后
以上就是知性海燕最近收集整理的关于Apollo:规划技术功能概述概述作用主要功能的全部内容,更多相关Apollo内容请搜索靠谱客的其他文章。








发表评论 取消回复