从理论到现实,分析特斯拉全自动驾驶的演变

在之前的文章中,我们讨论了特斯拉视觉方案的整个架构。
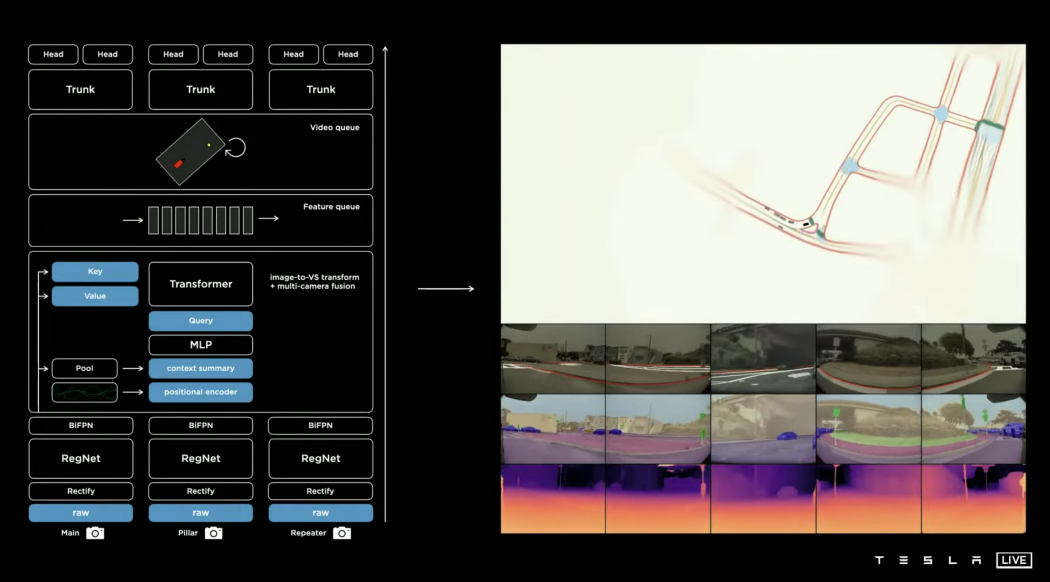
在这篇文章中,我们将讨论:计划与控制。
计划与控制
这部分由特斯拉自动驾驶软件总监Ashok Elluswamy介绍。
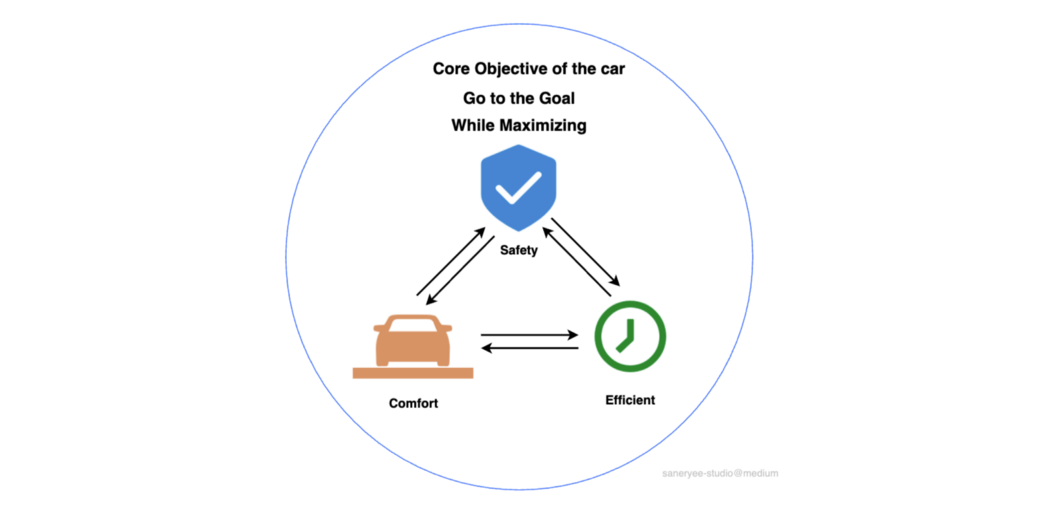
视觉网络将密集的视频压缩成3D向量空间,现在规划模块的角色是使用这个向量空间,使汽车到达目的地,同时最大限度地提高汽车的安全性、舒适性和效率。不得不说,作为一个拥有十几年驾驶经验的人类司机,我的驾驶风格就是追求这三点的完美结合。
特斯拉Autopilot的早期版本,在还不叫FSD(Full Self Driving)的时候,已经在大多数高速公路驾驶场景中表现良好,能够保持车道,必要时进行换道,并离开高速公路。(我记得在2016年,Youtube上有一段视频显示,“自动驾驶特斯拉驱动车主工作并找到停车位”,你可以在本文结尾观看。)特斯拉FSD要求规划师在城市街道驾驶时具有同样出色的性能。
在城市里驾驶要复杂得多。规划中的关键问题是行动空间既是一个非凸问题又是一个高维问题。
非凸问题
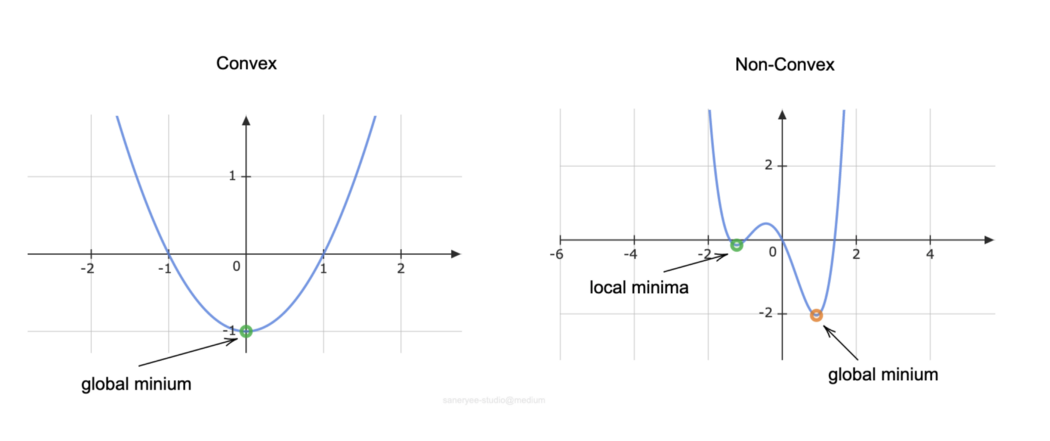
非凸意味着可能有多个独立的好解。但要得到一个全球一致的解决方案是相当棘手的。规划可能会陷入局部极小值的口袋中。
高维问题
高维是因为汽车需要计划接下来的10到15秒,需要产生整个窗口的位置,速度和加速度,这是运行时需要产生的很多参数。
解决上述问题常用的方法有两类:离散搜索法和连续函数优化法。
离散搜索方法在解决非凸问题时非常有效因为它们不会陷入局部极小值。但它在解决高维问题时表现不佳,因为它是离散的。它不使用任何梯度信息。所以必须去探索每一个点,知道它有多好。这是非常低效的。
连续函数优化很擅长解决高维问题,因为它们使用基于梯度的方法,可以非常快速地得到一个好的解。但对于非凸问题,它们很容易陷入局部极小值,并产生糟糕的解决方案。

特斯拉人工智能团队的解决方案是将其分层次分解。首先,利用粗搜索方法对非凸性进行压缩,得到凸走廊,然后利用连续优化技术使最终轨迹平滑。
以下两个经典场景介绍了特斯拉混合动力规划系统的处理流程
规划换道

在这种情况下,汽车需要做两个背靠背的车道变换,使左转弯在前面。它搜索的第一个计划是附近的一个变道,但汽车刹车很厉害,所以很不舒服。
它尝试的第二种策略是变道有点晚,所以它加速,跑到另一辆车的后面,跑到其他车的前面,在变道时发现它,但现在它有错过左转的风险。
而计划器会在很短的时间内完成数千次这样的搜索。在1.5毫秒内完成2500次搜索。这种搜索速度非常快。想象一下,如果你使用60km/h, 1.5ms只会前进2.5cm,而你已经有2500条行驶路线。
最后,规划人员根据安全、舒适、易转弯等最优条件进行转弯选择。
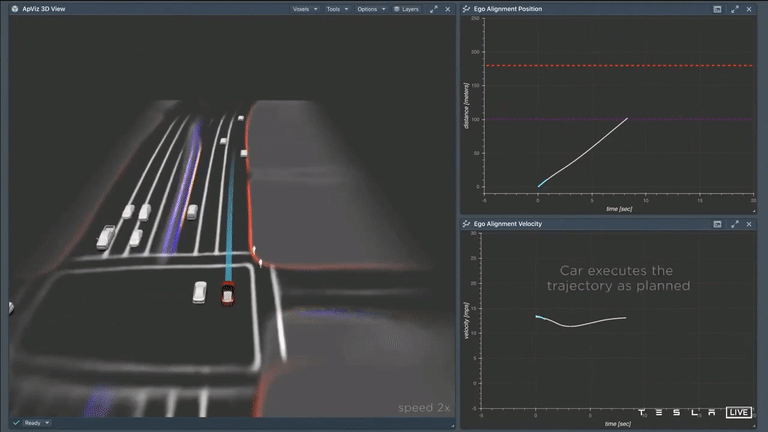
现在汽车选择了这条路。你可以看到,当赛车执行这个轨迹时,它和我们的计划非常吻合。上面的图片显示,右边青色的图,这是汽车的实际速度,下面的白线是计划。所以我们可以在这里计划10秒,当你事后看到的时候,可以匹配它。所以这是个精心设计的计划。我不禁想到,特斯拉的人工智能似乎能在未来10秒内预测汽车的行动。
AI Day只给我们展示了Planner的最终执行过程,并没有具体介绍算法的细节。但是我们知道,在处理自动驾驶的规划和控制时,我们一般会使用强化学习相关的知识。如果您感兴趣,可以参考其他公司的类似算法论文,如百度Apollo EM Motion Planner。(本文使用的是高清地图。)
汽车在狭窄的道路上相遇
当我们在城市的街道(狭窄的道路)上行驶时,重要的不是只为我们自己规划,而是要为每个人共同规划,优化整个场景的交通流。为了做到这一点,特斯拉AI团队在场景中的每一个相关对象上运行自动驾驶计划。

在上述的例子中:
- 迎面而来的1号车先到,自动驾驶仪慢了一点。但随后,它意识到它无法主动避开迎面而来的汽车,因为它的一侧没有空间。但另一辆车可以让给我们。因此,自动驾驶仪并没有盲目地在这里刹车,而是认为汽车的速度足够低,他们可以靠边停车,让我们下车。因此,自动驾驶仪果断地取得了进展。
- 第二辆迎面而来的2号车现在到了,这辆车的速度更快了。在这个场景中,特斯拉AI团队为另一个对象运行自动驾驶仪计划。迎面而来车辆预测结果: -高概率:绕过其他停放的车辆(红色路径) -低概率:收益率(绿色路径) 根据对迎面而来车辆的预测,自动驾驶仪决定靠边停车。
- 因此,当自动驾驶仪停车时,我们注意到汽车选择了屈服基于他们的偏航率和加速度。自动驾驶仪立即改变了他的想法,并继续取得进展。
因为我们无法在自动驾驶过程中确定其他参与者(主要是车辆)的行为,所以我们需要为每个对象制定计划。最后,优化走廊内安全、顺畅、快速的路径。
作为一名司机,在遇到上述情况时,我的决策过程与自动驾驶几乎完全相同。
玩具的停车问题
我们将讨论一个简单得多的玩具停车问题,但仍然说明了问题的核心。
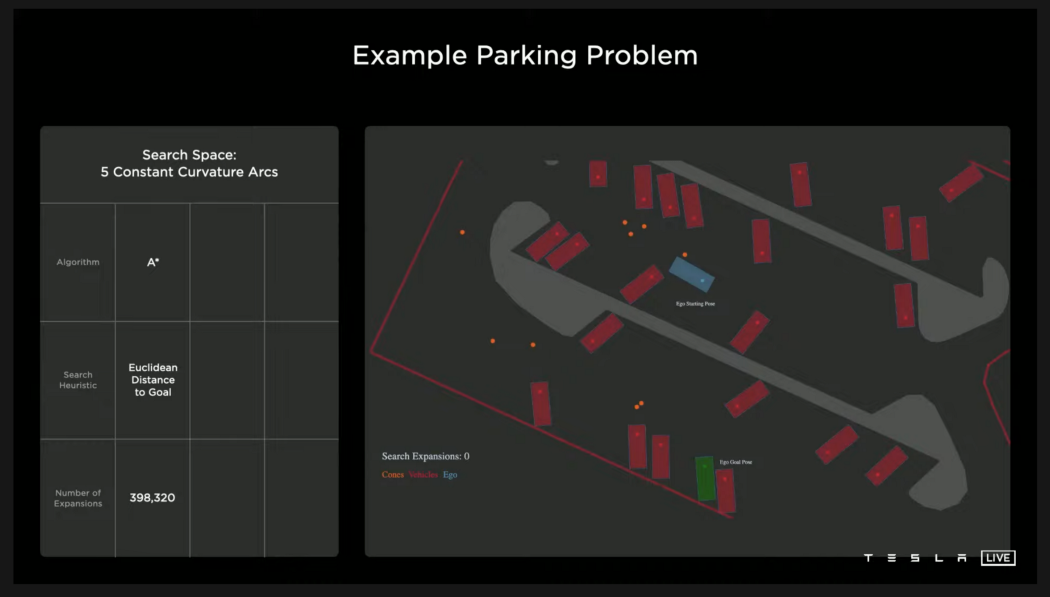
目标是自我车(蓝色)需要停在绿色的停车位上,绕过路边、停着的车和圆锥体(橙色)。
Baseline
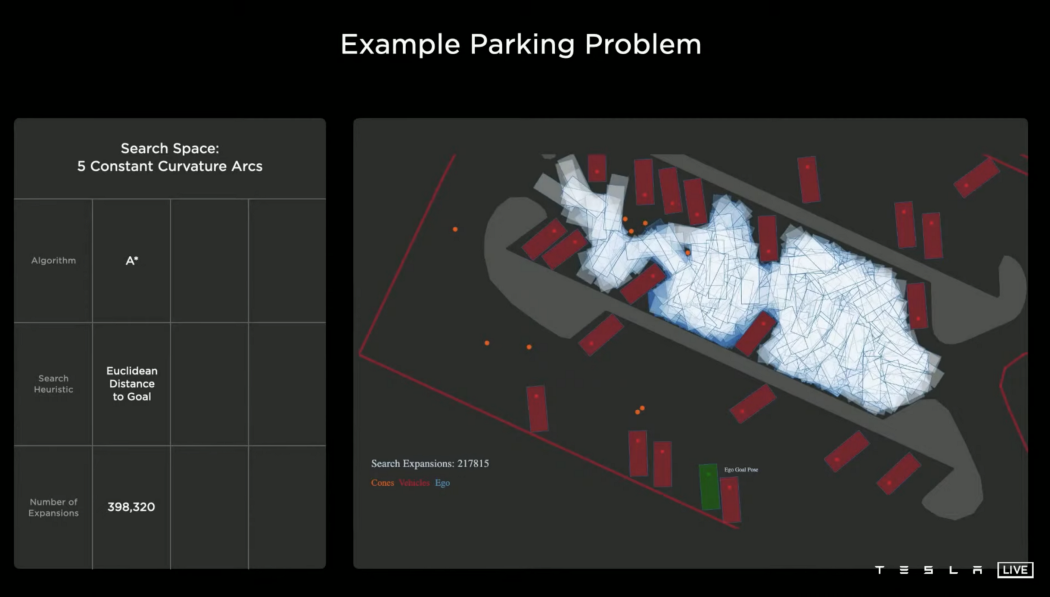
简单基线采用A算法。A的启发式函数是欧几里德距离。正如你从上面的图片中看到的那样,它很快就陷入了局部极小值。最终,它取得进展并到达本地,但最终使用了近400,000个节点来完成此操作。
使用导航
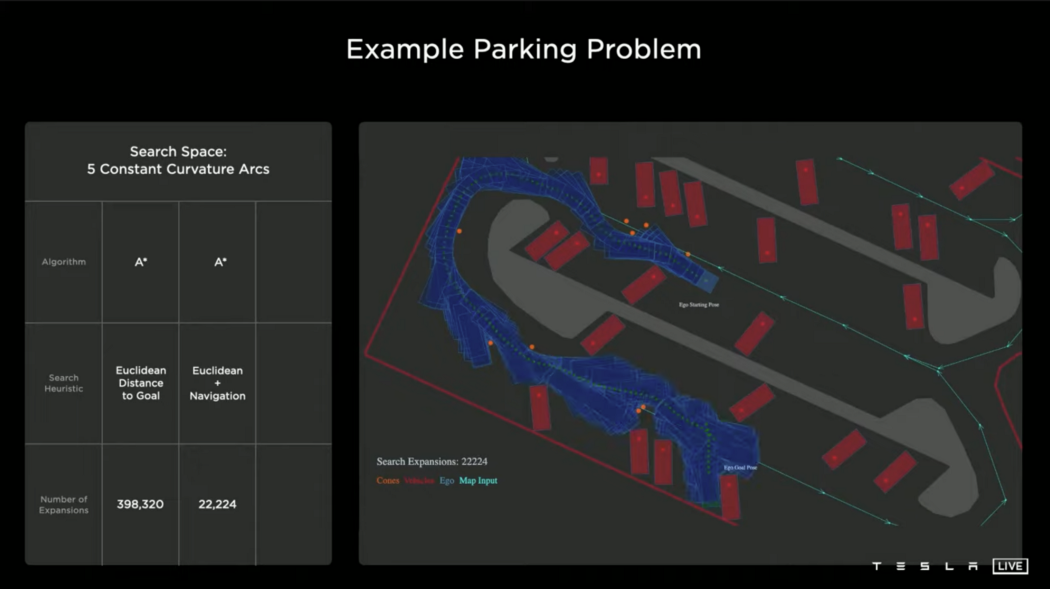
如果您在基线上添加了一个导航路线,它会立即帮助您。但当遇到障碍时,它基本上会做和之前一样的事情,回溯,然后搜索全新的路径,最终,它仍然需要22000个节点。
蒙特卡洛树搜索
有没有更有效的解决办法?又到了“第一原理思考”的时候了。目前,决策过程的最佳实践是使用启发式搜索算法,而启发式搜索算法的最佳实践是蒙特卡罗搜索树(MCTS)。到2021年为止,基于MCTS的最好、最新的型号是DeepMind的MuZero。(安德烈·卡帕西(Andrej Karpathy)曾在这里实习。)
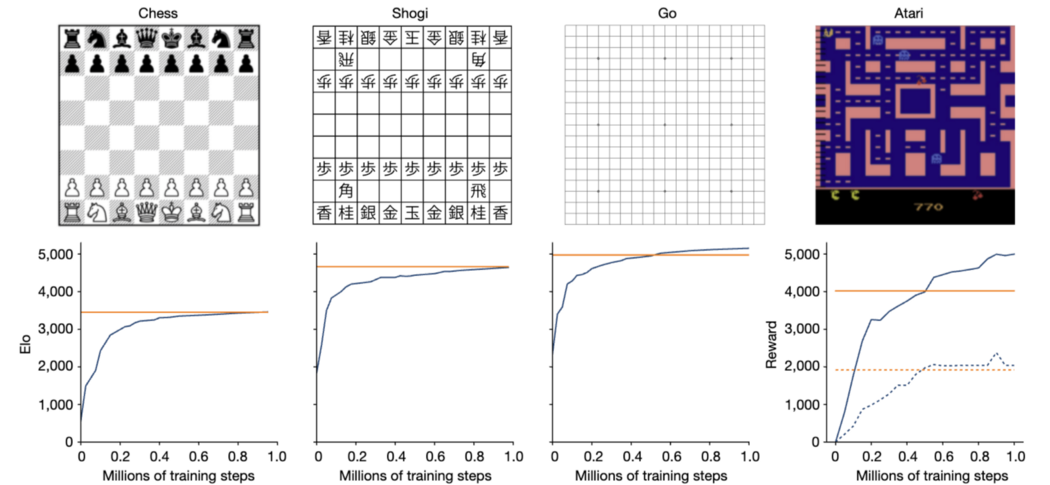
MuZero在无需告知规则的情况下就精通围棋、国际象棋、shogi和Atari。它有能力在未知的环境中制定制胜策略。这似乎是解决特斯拉停车问题的完美模式。把我们的问题变成"停车游戏"就行了。幸运的是,在特斯拉的Vector Space中,停车问题就像玩《吃豆人》的雅达利游戏。
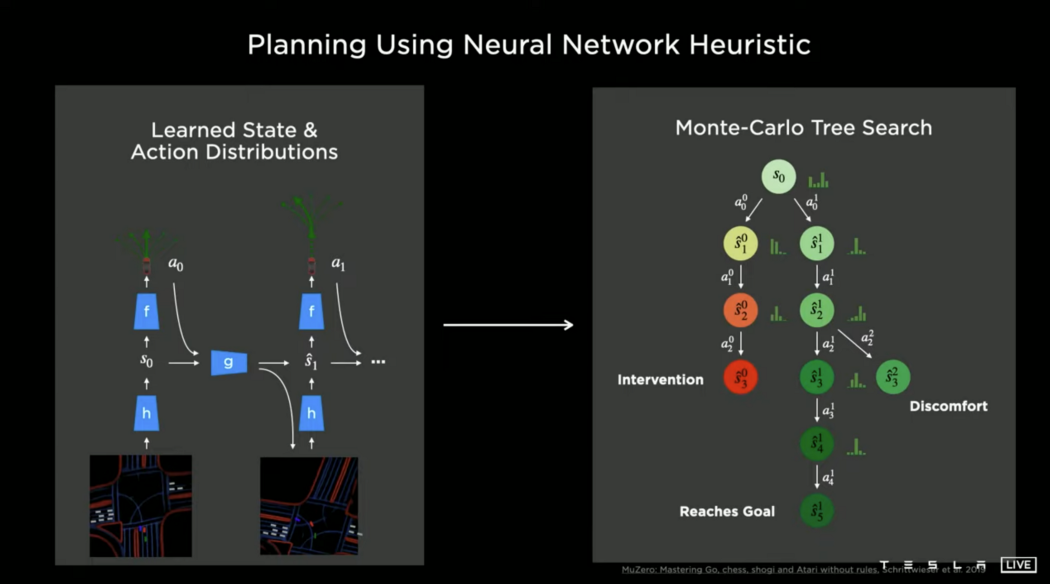
MuZero是一个基于模型的规划系统,也是一个基于模型的强化学习系统,旨在通过学习环境动态的精确模型,然后使用它来进行规划来解决这个问题。

因此,特斯拉人工智能团队正在研究可以产生状态和行动分布的神经网络,然后可以插入蒙特卡罗树搜索与各种成本函数。一些成本函数可以是明确的成本函数,如距离、碰撞、舒适度、穿越时间和实际手动驾驶事件的干预。
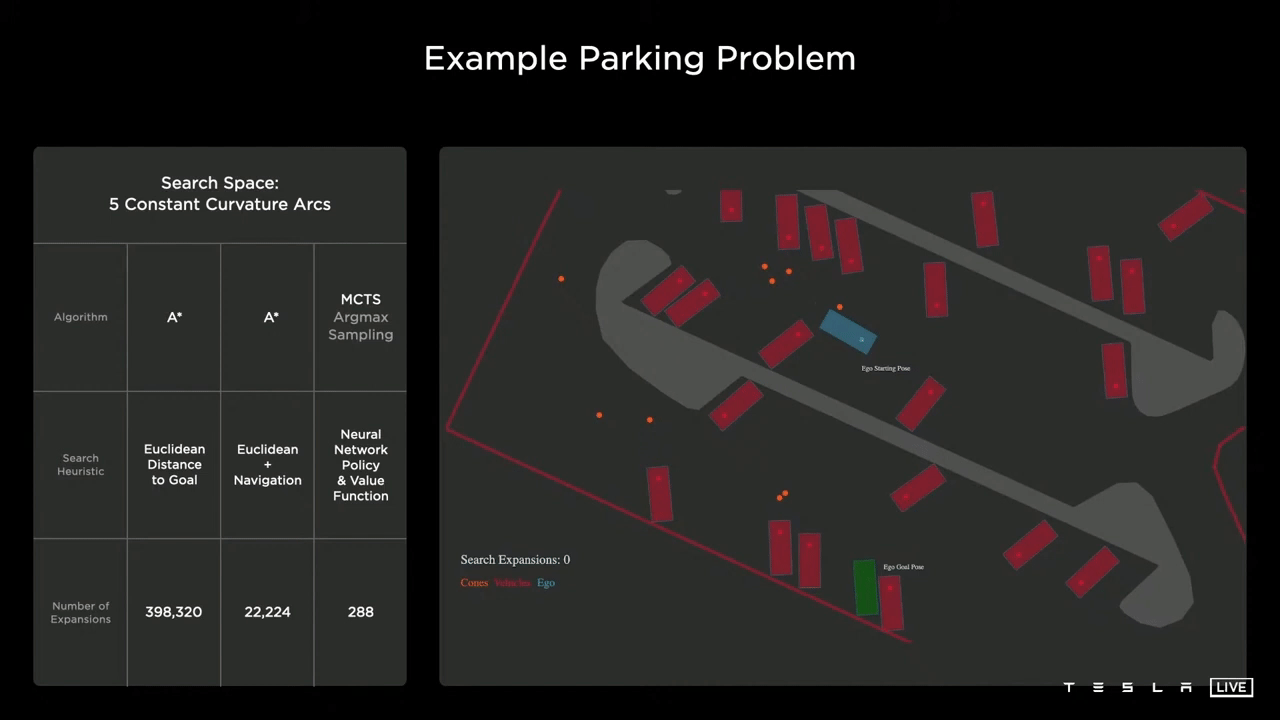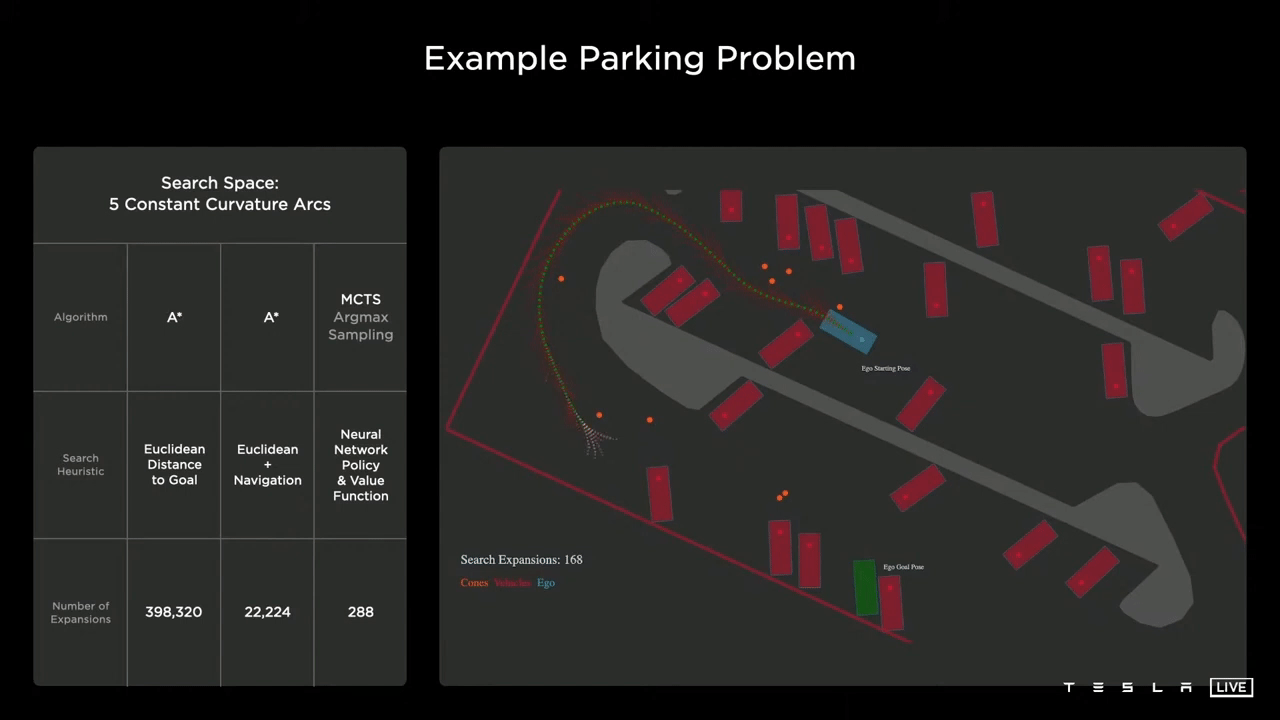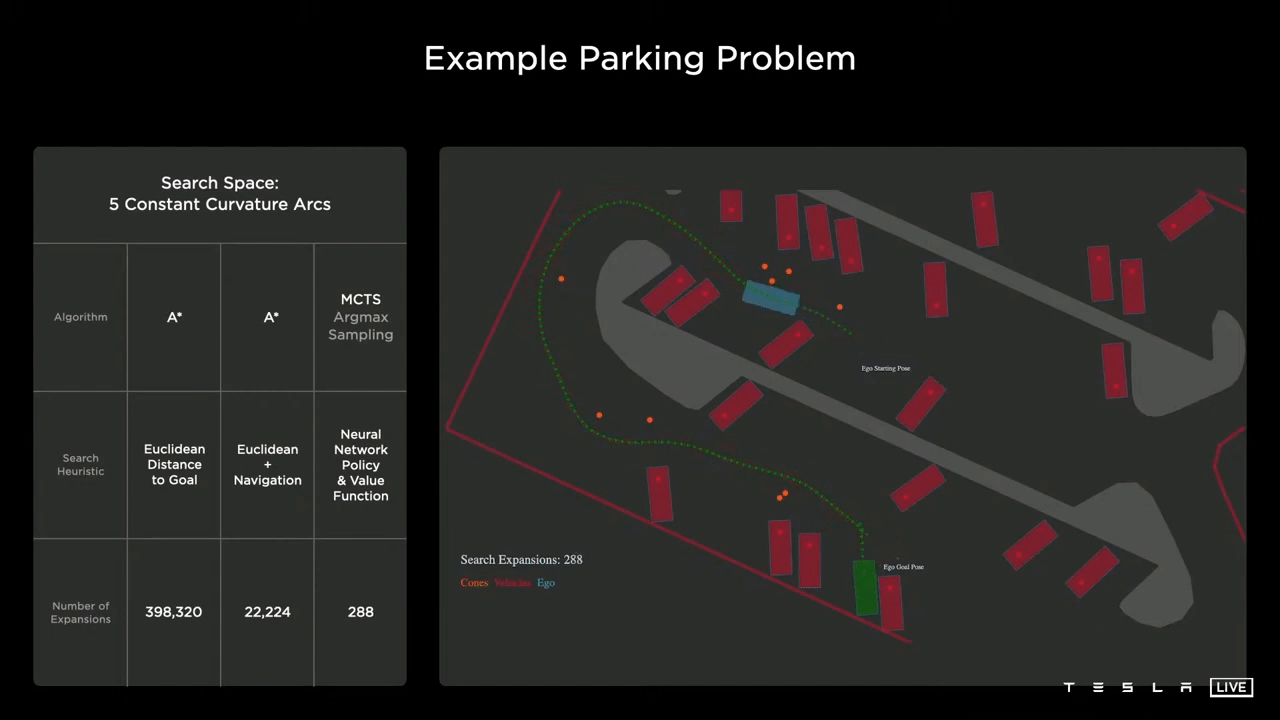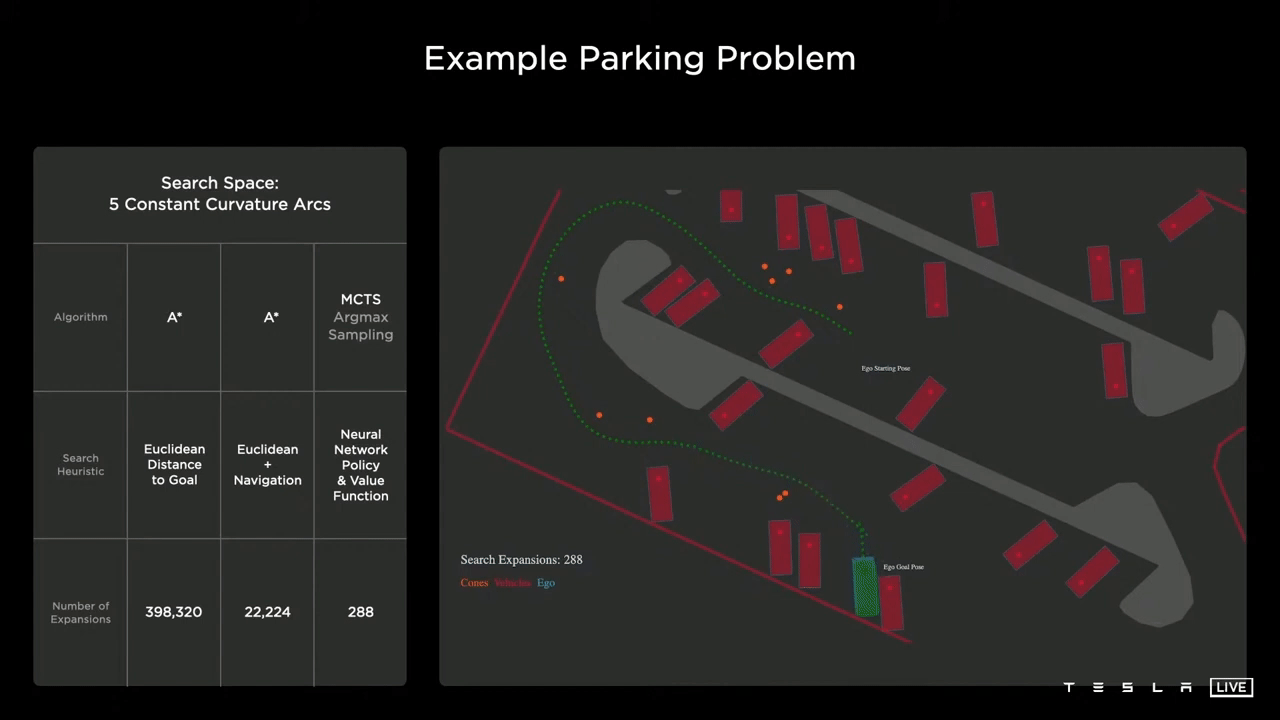
结果如上图所示,规划器基本上能够一次朝着目标前进,注意到这甚至没有使用导航启发式,只是给定场景,规划器能够直接朝着目标前进。神经网络能够吸收场景的全局上下文,然后产生一个值函数,有效地引导它走向全局最小值,而不是陷入任何局部最小值。这只需要288个节点。
我再次感叹特斯拉的工程能力。虽然我们还在讨论AlphoZero和MuZero除了玩游戏还能做什么,但特斯拉已经将其应用到自动驾驶系统中。
欲了解更多AlphaZero, MuZero,请阅读:
Paper: Mastering Atari, Go, chess and shogi by planning with a learned model
AlphaZero: Shedding new light on chess, shogi, and Go
MuZero: Mastering Go, chess, shogi and Atari without rules
最终架构
随着计划和控制模块的添加,最终的架构将如下图所示。
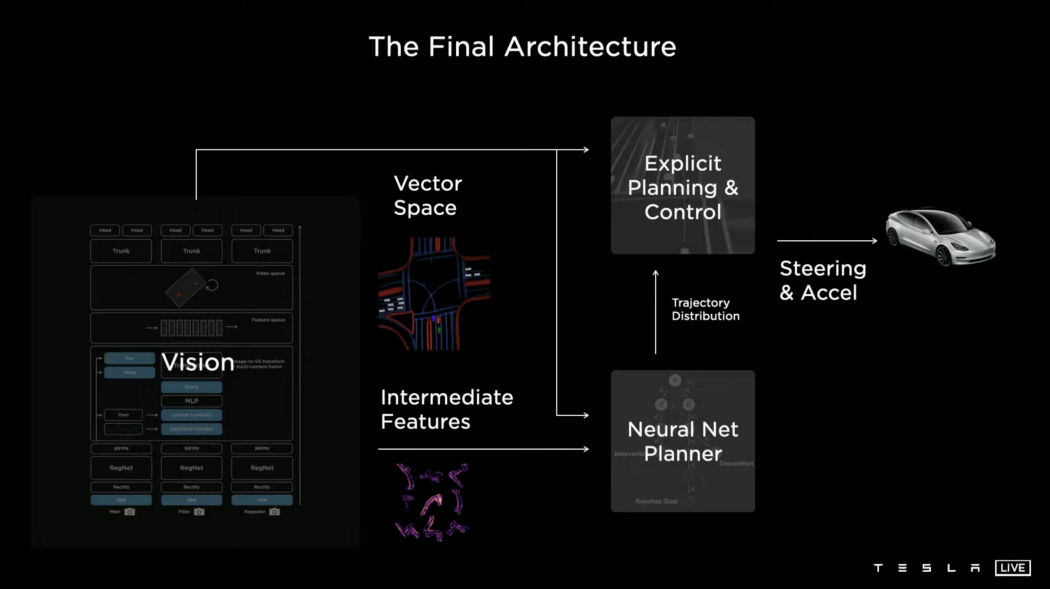
视觉系统将把密集的视频数据压缩成一个矢量空间。它将同时被显式规划器和神经网络规划器所消耗。除此之外,网络规划器还可以使用网络的中间特性。这就产生了一个轨迹分布,它可以通过明确的成本函数、人工干预和其他模拟数据进行端到端的优化。这是一个明确的计划函数,它可以做任何简单的事情,并为汽车生成最终的转向和加速指令。
完美的网络需要完美的数据。特斯拉如何生成培训数据?我将在下一篇文章中继续探讨这个问题。
感谢阅读,下一篇文章见。
最后
以上就是呆萌便当最近收集整理的关于深度理解特斯拉自动驾驶解决方案 3:规划与控制的全部内容,更多相关深度理解特斯拉自动驾驶解决方案内容请搜索靠谱客的其他文章。








发表评论 取消回复