前端和框架
1.谈谈你对http协议的认识
浏览器本质,socket客户端遵循Http协议 HTTP协议本质:通过rn分割的规范,请求响应之后断开链接 ==> 短连接、无状态 具体: Http协议是建立在tcp/ip之上的,是一种规范,它规范定了发送的数据的数据格式, 然而这个数据格式是通过rn进行分割的,请求头与请求体也是通过2个rn分割的,响应的时候, 响应头与响应体也是通过rn分割,并且还规定已请求已响应就会断开链接,即-->短连接、无状态
2.谈谈你对websocket协议的认识
websocket是给浏览器新建的一套(类似于http)协议,协议规定:浏览器和服务器连接之后不断开,以达到服务端向客户端主动推送消息。
本质: 创建一个连接后不断开的socket 当连接成功之后: 客户端(浏览器)会自动向服务端发送消息,包含:Sec-WebSocket-Key: iyRe1KMHi4S4QXzcoboMmw== 服务端接收之后,会对于该数据进行加密:base64(sha1(swk + magic_string)) 构造响应头: HTTP/1.1 101 Switching Protocolsrn Upgrade:websocketrn Connection: Upgradern Sec-WebSocket-Accept: 加密后的值rn WebSocket-Location: ws://127.0.0.1:8002rnrn 发给客户端(浏览器) 建立:双工通道,接下来就可以进行收发数据 发送数据是加密,解密,根据payload_len的值进行处理 payload_len <= 125 payload_len == 126 payload_len == 127 获取内容: mask_key 数据 根据mask_key和数据进行位运算,就可以把值解析出来。
3.什么是magic string?
客户端向服务端发送消息时,会有一个'sec-websocket-key'和'magic string'的随机字符串(魔法字符串), 服务端接收到消息后会把他们连接成一个新的key串,进行编码、加密,确保信息的安全性。
4.如何创建响应式布局?


响应式布局是通过@media实现的 @media (min-width:768px){ .pg-header{ background-color:green; } } @media (min-width:992px){ .pg-header{ background-color:pink; } } 代码 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> <style> body{ margin: 0; } .pg-header{ background-color: red; height: 48px; } @media (min-width: 768px) { .pg-header{ background-color: aqua; } } @media (min-width: 992px) { .pg-header{ background-color: blueviolet; } } </style> </head> <body> <div class="pg-header"></div> </body> </html>
5.你曾经使用过哪些前端框架?
- jQuery - Bootstrap - Vue.js(与vue齐名的前端框架React和Angular)
6.什么是ajax请求?并使用jQuery和XMLHttpRequest对象实现一个ajax请求
https://www.cnblogs.com/wcwnina/p/10316919.html
7.如何在前端实现轮询?
轮询:通过定时器让程序每隔n秒执行一次操作。
<!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> </head> <body> <h1>请选出最帅的男人</h1> <ul> {% for k,v in gg.items() %} <li>ID:{{ k }}, 姓名:{{ v.name }} ,票数:{{ v.count }}</li> {% endfor %} </ul> <script> setInterval(function () { location.reload(); },2000) </script> </body> </html>
8.如何在前端实现长轮询?
客户端向服务器发送请求,服务器接到请求后hang住连接,等待30秒,直到有新消息,才返回响应信息并关闭连接,客户端处理完响应信息后再向服务器发送新的请求。
<!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> </head> <body> <h1>请选出最帅的男人</h1> <ul> {% for k,v in gg.items() %} <li style="cursor: pointer" id="user_{{ k }}" ondblclick="vote({{ k }});">ID:{{ k }}, 姓名:{{ v.name }} ,票数:<span>{{ v.count }}</span></li> {% endfor %} </ul> <script src="/static/jquery-3.3.1.min.js"></script> <script> $(function () { get_new_count(); }); function get_new_count() { $.ajax({ url: '/get_new_count', type:'GET', dataType:'JSON', success:function (arg) { if (arg.status){ // 更新票数 var gid = "#user_" + arg.data.gid; $(gid).find('span').text(arg.data.count); }else{ // 10s内没有人投票 } get_new_count(); } }) } function vote(gid) { $.ajax({ url: '/vote', type:'POST', data:{gid:gid}, dataType:"JSON", success:function (arg) { } }) } </script> </body> </html>
9.vuex的作用?
多组件之间共享:vuex 补充luffyvue 1:router-link / router-view 2:双向绑定,用户绑定v-model 3:循环展示课程:v-for 4:路由系统,添加动态参数 5:cookie操作:vue-cookies 6:多组件之间共享:vuex 7:发送ajax请求:axios (js模块)
10.vue中的路由的拦截器的作用?
vue-resource的interceptors拦截器的作用正是解决此需求的妙方。
在每次http的请求响应之后,如果设置了拦截器如下,会优先执行拦截器函数,获取响应体,然后才会决定是否把response返回给then进行接收
11.axios的作用?
发送ajax请求:axios (js模块)
12.列举vue的常见指令
1、v-show指令:条件渲染指令,无论返回的布尔值是true还是false,元素都会存在在html中,只是false的元素会隐藏在html中,并不会删除.
2、v-if指令:判断指令,根据表达式值得真假来插入或删除相应的值。
3、v-else指令:配合v-if或v-else使用。
4、v-for指令:循环指令,相当于遍历。
5、v-bind:给DOM绑定元素属性。
6、v-on指令:监听DOM事件。
13.简述jsonp及实现原理?
JSONP 是json用来跨域的一个东西。原理是通过script标签的跨域特性来绕过同源策略。 JSONP的简单实现:创建一个回调函数,然后在远程服务上调用这个函数并且将JSON数据作为参数传递,完成回调。
14.什么是cors ?
CORS:跨域资源共享(CORS,Cross-Origin Resource Sharing),随着技术的发展,现在的浏览器可以支持主动设置从而允许跨域请求,其本质是设置响应头,使得浏览器允许跨域请求。
浏览器将CORS请求分成两类:简单请求和复杂请求 简单请求(同时满足以下两大条件) (1)请求方法是以下三种方法之一: HEAD GET POST (2)HTTP的头信息不超出以下几种字段: Accept Accept-Language Content-Language Last-Event-ID Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain 凡是不同时满足上面两个条件,就属于非简单请求
15.列举Http请求中常见的请求方式?
GET、POST、PUT、DELETE
PATCH(修改数据) HEAD(类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头)
16.列举Http请求中的状态码?
分类: 1** 信息,服务器收到请求,需要请求者继续执行操作 2** 成功,操作被成功接收并处理 3** 重定向,需要进一步的操作以完成请求 4** 客户端错误,请求包含语法错误或无法完成请求 5** 服务器错误,服务器在处理请求的过程中发生了错误 常见的状态码 200 - 请求成功
202 - 已接受请求,尚未处理
204 - 请求成功,且不需返回内容 301 - 资源(网页等)被永久转移到其他url
400 - 请求的语义或是参数有错
403 - 服务器拒绝请求 404 - 请求资源(网页)不存在 500 - 内部服务器错误
502 - 网关错误,一般是服务器压力过大导致连接超时
503 - 由于超载或系统维护,服务器暂时的无法处理客户端的请求
17.列举Http请求中常见的请求头?
- user-agent (代理) - host - referer - cookie - content-type
18.看图写结果(js):

李杰
看图写结果(js):
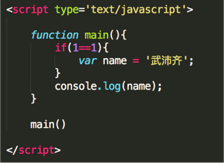
武沛奇
看图写结果:(js)
老男孩
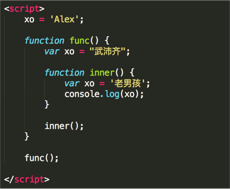
看图写结果:(js)

undefined
看图写结果:(js)
武沛奇
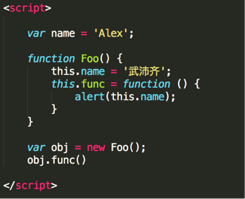
看图写结果:(js)

Alex
19.django、flask、tornado框架的比较?
- django,大而全的框架,它的内部组件比较多,内部提供:ORM、Admin、中间件、Form、ModelForm、Session、缓存、信号、CSRF;功能也相当完善。 - flask,微型框架,内部组件就比较少了,但是有很多第三方组件来扩展它,定制化程度高。
比如说有那个wtform(与django的modelform类似,表单验证)、flask-sqlalchemy(操作数据库的)、flask-session、flask-migrate、flask-script、blinker可扩展强,第三方组件丰富。所以对他本身来说有那种短小精悍的感觉
- tornado,异步非阻塞。 django和flask的共同点就是,他们2个框架都没有写socket,所以他们都是利用第三方模块wsgi。 但是内部使用的wsgi也是有些不同的:django本身运行起来使用wsgiref,而flask使用werkzeug wsgi 还有一个区别就是他们的请求管理不太一样:django是通过将请求封装成request对象,再通过参数传递,而flask是通过上下文管理机制。
Tornado:
是一个轻量级的Web框架,异步非阻塞+内置WebSocket功能。
目标:通过一个线程处理N个并发请求(处理IO)。
内部组件
#内部自己实现socket
#路由系统
#视图
#模板
#cookie
#csrf
20.什么是wsgi?
是web服务网关接口,是一套协议。 是通过以下模块实现了wsgi协议: - wsgiref - werkzurg - uwsgi 关于部署 以上模块本质:编写socket服务端,用于监听请求,当有请求到来,则将请求数据进行封装,然后交给web框架处理。
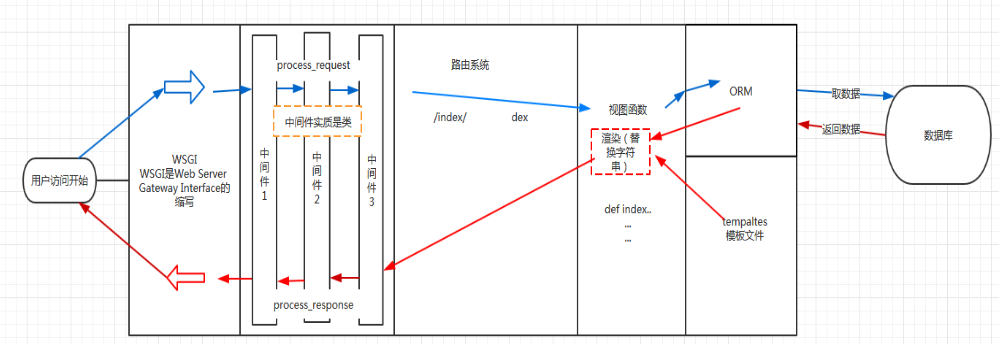
21.django请求的生命周期?
用户请求 --> wsgi --> jango的中间件(方法process_request) --> url路由匹配 --> 视图 --> orm数据库操作 --> 模板渲染
--> 中间件(方法process_response) --> wsgi -->用户
22.列举django的内置组件?
表单form:
- 对用户请求的数据进行校验 - 生成HTML标签 PS: - form对象是一个可迭代对象。 - 问题:如何实现choice的数据实时更新?(动态数据,而不是写死) - 解决:给该字段定义成ModelChoiceField的时候利用好"queryset"参数
class UserForm(Form): ut_id = ModelChoiceField(queryset=models.UserType.objects.all()) # 从另一张依赖表中提取数据 依赖表: class UserType(models.Model): title = models.CharField(max_length=32)
信号signal:
django的信号其实就是django内部为开发者预留的一些自定制功能的钩子。 只要在某个信号中注册了函数,那么django内部执行的过程中就会自动触发注册在信号中的函数。 如:
- pre_save & post_save 在ORM模型的save()方法调用之前或之后发送信号
- pre_delete & post_delete 在ORM模型或查询集的delete()方法调用之前或之后发送信号
- request_started & request_finished 当接收和关闭HTTP请求时发送信号
- m2m_changed 当多对多字段被修改时发送信号
场景: 在数据库某些表中添加数据时,可以进行日志记录。
中间件middleware:
对所有的【请求】进行【批量】处理,说得直白一点中间件是帮助我们在视图函数执行之前和执行之后都可以做一些额外的操作,它本质上就是一个自定义类。其影响的是全局,需谨慎使用。
应用:用户登录校验
问题:为甚么不使用装饰器?
如果不使用中间件,就需要给每个视图函数添加装饰器,太繁琐。
权限:
用户登录后,将权限放到session中,然后再每次请求进来在中间件里,根据当前的url去session中匹配,
判断当前用户是否有权限访问当前url,有权限就继续访问,没有就返回, 检查的东西就可以放到中间件中进行统一处理,在process_request方法里面做的, 我们的中间件是放在session后面,因为中间件需要到session里面取数据。
会话session:
cookie与session区别 (a)cookie是保存在浏览器端的键值对,而session是保存的服务器端的键值对,但是依赖cookie。(也可以不依赖cookie,可以放在url,或请求头但是cookie比较方便) (b)以登录为例,cookie为通过登录成功后,设置明文的键值对,并将键值对发送客户端存,明文信息可能存在泄漏,不安全;
session则是生成随机字符串,发给用户,并写到浏览器的cookie中,同时服务器自己也会保存一份。 (c)在登录验证时,cookie:根据浏览器发送请求时附带的cookie的键值对进行判断,如果存在,则验证通过;
session:在请求用户的cookie中获取随机字符串,根据随机字符串在session中获取其对应的值进行验证
跨域请求cors(场景:前后端分离时,本地测试开发时使用):
如果网站之间存在跨域,域名不同,端口不同会导致出现跨域,但凡出现跨域,浏览器就会出现同源策略的限制。 解决:在我们的服务端给我们响应数据,加上响应头 --> 在中间件加的。
缓存cache:
常用的数据放在缓存里面,就不用走视图函数,请求进来通过所有的process_request,会到缓存里面查数据,有就直接拿,没有就走视图函数。
关键点:1:执行完所有的process_request才去缓存取数据
2:执行完所有的process_response才将数据放到缓存
关于缓存问题 1:为什么放在最后一个process_request才去缓存? 因为需要验证完用户的请求,才能返回数据 2:什么时候将数据放到缓存中? 第一次走中间件,缓存没有数据,会走视图函数,取数据库里面取数据, 当走完process_response,才将数据放到缓存里,因为,走process_response的时候可能给我们的响应加处理。
3:为什么使用缓存?
将常用且不太频繁修改的数据放入缓存。
以后用户再来访问,先去缓存查看是否存在,如果有就返回
否则,去数据库中获取并返回给用户(再加入到缓存,以便下次访问)
CSRF-TOKEN:
目标:防止用户直接向服务端发起POST请求。
对所有的post请求做验证,将jango生成的一串字符串发送给后台,一种是从请求体发过来,一种是放在隐藏的标签里面。
方案:先发送GET请求时,将token保存到:cookie、Form表单中(隐藏的input标签),
以后再发送请求时只要携带过来即可。
23.列举django中间件的5个方法?以及django中间件的应用场景?
# 这些方法中的参数都是与视图函数参数对应的
process_request(self, request) 主要方法。请求刚进来时,执行视图函数之前调用。(无return) process_view(self, request, callback, callback_args, callback_kwargs) URL路由匹配成功后,执行视图函数之前调用,拿到视图函数对象,及其所有参数。(无return) process_exception(self, request, exception) 执行视图函数中遇到异常时调用。(无return) process_template_response(self, request, response) 很少用。执行了render()渲染方法后调用。(有return) process_response(self, request, response) 主要方法。执行视图函数结束之后有响应时调用。(有return)
执行流程
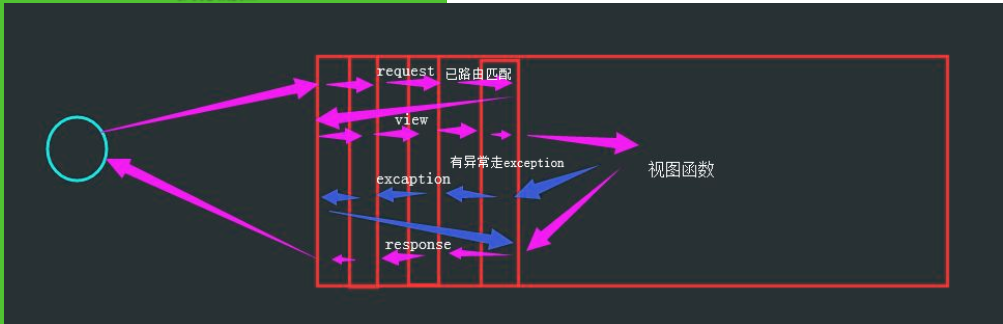
24.简述什么是FBV和CBV?
FBV 函数视图
# FBV 写法
# urls.py
url(r'^login/$',views.login, name="login"),
# views.py
def login(request):
if request.method == "POST":
print(request.POST)
return render(request,"login.html")
CBV 类视图
# urls.py
url(r'^login/$',views.Login.as_view(), name="login"),
# views.py
from django.views import View
class Login(View):
# 类首字母大写
def get(self,request):
return render(request, "login.html")
def post(self,request):
print(request.POST)
return HttpResponse("OK")
25.FBV与CBV的区别
- 没什么区别,因为他们的本质都是函数。CBV的.as_view()返回的view函数,view函数中调用类的dispatch方法, 在dispatch方法中通过反射执行get/post/delete/put等方法。 - 非要说区别的话: CBV比较简洁,GET/POST等业务功能分别放在不同get/post函数中。FBV自己做判断进行区分。
26.Django的request对象是在什么时候创建的?
当请求一个页面时, Django会建立一个包含请求元数据的HttpRequest对象。
当Django加载对应的视图时, HttpRequest对象将作为视图函数的第一个参数,另外每个视图会返回一个HttpResponse对象。
27.如何给CBV的程序添加装饰器?
利用方法装饰器"method_decorator":
def auth(func): def inner(*args,**kwargs): return func(*args,**kwargs) return inner class UserView(View): @method_decorator(auth) def get(self,request,*args,**kwargs): return HttpResponse('...')
28.列举Django ORM中的方法(QuerySet对象的方法)
1.返回QuerySet对象的方法: all() filter() exclude() order_by() reverse() distinct()
select_related()
prefetch_related()
only()
defer()
using() 特殊的QuerySet: values() (返回一个字典序列) values_list() (返回一个元组序列)
2.不返回QuerySet,而返回具体对象的方法: get() first() last()
earliest()
latest()
update()
delete() 返回布尔值的方法有: exists() 返回数字的方法有: count()
29.only()和defer()的区别?
only()查询指定的字段,defer()查询排除指定的字段。
30.select_related('外键字段[__外键字段]') 和 prefetch_related('外键字段[__外键字段]')的区别?
# 相同点:它俩都用于连表查询,缓存查询结果,减少SQL查询次数。
# 不同点: select_related 主要针对一对一和一对多关系进行优化。通过多表join关联查询,一次性获得所有数据,缓存在内存中,但如果关联的表太多,会严重影响数据库性能。 prefetch_related 主要针对多对多关系进行优化。通过分表,先获取各个表的数据,缓存在内存中,然后通过Python处理他们之间的关联。
31.filter()和exclude()的区别?
filter(self, *args, **kwargs) # 条件查询(符合条件) # 查出符合条件 # 条件可以是:参数,字典,Q exclude(self, *args, **kwargs) # 条件查询(排除条件) # 排除不想要的 # 条件可以是:参数,字典,Q
32.列举Django ORM中2种能写SQL语句的方法
靠近原生SQL --> extra()、raw()
- extra
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(10,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(10,), order_by=['-nid'])
- raw
def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo')
# 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid,name as title
from 表')
# 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,])
# 将获取的到列名转换为指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map)
# 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default")
33.Django ORM中如何设置读写分离?
步骤一:写配置文件 class Router1: # 指定到某个数据库读数据 def db_for_read(self, model, **hints): if model._meta.model_name == 'usertype': return 'db1' else: return 'default'
# 指定到某个数据库写数据 def db_for_write(self, model, **hints): return 'default'
再写到配置 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), }, 'db1': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } DATABASE_ROUTERS = ['db_router.Router1',]
步骤二:手动使用queryset的using方法
def index(request):
models.UserType.objects.using('db1').create(title='普通用户')
# 手动指定去某个数据库取数据
result = models.UserType.objects.all().using('db1')
return HttpResponse('...')
34.F和Q表达式的作用?
F:主要用来对字段的值进行四则计算。
Goods.objects.update(price=F("price")+10) # 对于goods表中每件商品的价格都在原价格的基础上增加10元
Q:用来进行复杂查询,实现"与"、"或"、"非"查询。
Q(条件1) | Q(条件2) # 或
Q(条件1) & Q(条件2) # 且
~ Q(条件) # 非
35.values()和values_list()的区别?
def values(self, *fields): # 返回每行数据为字典格式 def values_list(self, *fields, **kwargs): # 返回每行数据为元组格式
36.如何使用Django ORM批量创建数据?
# bulk_create(objs, batch_size=None):批量插入 # batch_size表示一次插入的个数 objs = [ models.DDD(name='r11'), models.DDD(name='r22') ] models.DDD.objects.bulk_create(objs, 10)
37.Django的Form和ModeForm的作用?
- 作用: - 对用户请求数据格式进行校验 - 自动生成HTML标签 - 区别: - Form,字段需要自己手写。 class Form(Form): xx = fields.IntegerField(.) xx = fields.CharField(.) xx = fields.EmailField(.) xx = fields.ImageField(.)
- ModelForm,可以通过Meta进行定义 class MForm(ModelForm): class Meta:
model = UserInfo fields = "__all__" - 应用:只要是客户端向服务端发送表单数据时,都可以进行使用,如:用户登录注册
38.Django的Form组件中,如果字段中包含choices参数,请使用两种方式实现数据源实时更新(动态数据,而不是写死)
方式一:重写初始化方法,在构造方法中重新去数据库获取值 class UserForm(Form): ut_id = fields.ChoiceField(choices=())
def __init__(self, *args, **kwargs): super(UserForm, self).__init__(*args, **kwargs) self.fields['ut_id'].choices = models.UserType.objects.all().values_list('id', 'title')
方式二: ModelChoiceField字段 class UserForm(Form): ut_id = ModelChoiceField(queryset=models.UserType.objects.all()) # 从另一张依赖表中提取数据 依赖表: class UserType(models.Model): title = models.CharField(max_length=32)
39.Django的Model中的ForeignKey字段中的on_delete参数有什么作用?
在django2.0后,定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题,不然会报错: user=models.OneToOneField(User,on_delete=models.CASCADE) --在老版本这个参数(models.CASCADE)是默认值 owner=models.ForeignKey(UserProfile,on_delete=models.CASCADE) --在老版本这个参数(models.CASCADE)是默认值
参数说明: on_delete有CASCADE、PROTECT、SET_NULL、SET_DEFAULT、SET()五个可选择的值 CASCADE:级联删除。 PROTECT:报完整性错误。 SET_NULL:把外键设置为null,前提是允许为null。 SET_DEFAULT:把设置为外键的默认值。 SET():调用外面的值,可以是一个函数。 一般情况下使用CASCADE就可以了。
40.Django中csrf的实现机制?
目的:防止用户直接向服务端发起POST请求
- 用户先发送GET获取令牌csrf token: Form表单中一个隐藏的标签 + token;
- 发起POST请求时,需要携带这个令牌csrf token;
- 在中间件的process_view方法中进行令牌校验。
在html中添加{%csrf_token%}标签。
41.Django如何实现websocket?
django中可以通过channel实现websocket。
42.基于Django使用ajax发送post请求时,都可以使用哪种方法携带csrf token?
https://www.cnblogs.com/wcwnina/p/9099561.html
43.Django中如何实现ORM表中添加数据时创建一条日志记录
# 使用Django的信号机制,可以在添加、删除数据前后设置日志记录: pre_init # Django中的model对象执行其构造方法前,自动触发 post_init # Django中的model对象执行其构造方法后,自动触发 pre_save # Django中的model对象保存前,自动触发 post_save # Django中的model对象保存后,自动触发 pre_delete # Django中的model对象删除前,自动触发 post_delete # Django中的model对象删除后,自动触发
# 使用
@receiver(post_save, sender=Myclass) # 信号接收装饰器。由于内置信号,所以直接接收
def signal_handler(sender, **kwargs): # 接收到信号后,在此处理
logger = logging.getLogger()
logger.success('保存成功')
44.Django缓存如何设置?
Django中提供了6种缓存方式: 开发调试(默认缓存) 内存 文件 数据库 Memcache缓存 第三方库支持redis:django-redis
设置缓存: # 全站缓存(中间件) MIDDLEWARE = [ ‘django.middleware.cache.UpdateCacheMiddleware’, #第一个位置 'django.middleware.common.CommonMiddleware', ‘django.middleware.cache.FetchFromCacheMiddleware’, #最后位置 ]
CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', # 取决于您选择的Memcached绑定 'LOCATION': ['127.0.0.1:11211', ], # 缓存后端服务器位置,支持分布式,可多个 'TIMEOUT': 5 * 60, # 缓存超时,默认300s } }
# 视图缓存 @cache_page(15) #超时时间为15秒 def index(request): t=time.time() #获取当前时间 return render(request,"index.html",locals())
# 模板缓存 {% load cache %}
{% cache 2 'name' %} # 存的key <h3>缓存:{{ t }}</h3> {% endcache %}
45.Django的缓存能使用redis吗?如果可以的话,如何配置?
# 在setting添加配置文件
# 配置中间件同上。 CACHES = { "default": { "BACKEND": "django_redis.cache.RedisCache", # 缓存类型 "LOCATION": "127.0.0.1:6379", # 缓存服务器IP和端口 "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", "CONNECTION_POOL_KWARGS": {"max_connections": 100} # 连接池最大连接数 # "PASSWORD": "123456", } } } # 使用 def index(request): conn = get_redis_connection("default") # 根据名字去连接池中获取连接 conn.hset('n1','k1','v1') # 存数据 return HttpResponse('...')
46.Django路由系统中name的作用?
反向解析路由字符串.
url(r'^home', views.home, name='home')
在模板中使用:{ % url 'home' %}
在视图中使用:reverse('home')
47.Django的模板中filter和simple_tag的区别?
filter: 过滤器,只能接受两个参数,第一个参数是|前的数据。 用于操作变量。 simple_tag: 标签(简单标签)。 用于操作模板模块。
48.Django-debug-toolbar的作用?
一、查看访问的速度、数据库的行为、cache命中等信息。 二、尤其在Mysql访问等的分析上大有用处(sql查询速度).
49.Django中如何实现单元测试unittest?
单元测试是class类(继承TestCase),每一个测试方法必须以"test"开头。你可以重写setUp()(测试开始之前的操作)和tearDown()(测试结束之后的操作)方法。
常用的断言方法:assertEqual()。 会单独新建一个测试数据库来进行数据库的操作方面的测试,垃圾数据默认在测试完成后销毁。 Django单元测试时为了模拟生产环境,会修改settings中的变量,例如, 把DEBUG变量修改为True, 把ALLOWED_HOSTS修改为[*]。
50.解释ORM中 db first 和 code first的含义?
db first: 先创建库,再更新表 code first:先创建表,再更新库
51.Django中如何根据数据库表生成model中的类?
1、修改seting文件,在setting里面设置要连接的数据库类型和名称、地址
2、运行下面代码可以自动生成models模型文件
- python manage.py inspectdb > app/models.py # inspectdb 监测数据库的意思
52.使用ORM和原生SQL的优缺点?
SQL: # 优点: 执行速度快 # 缺点: 编写复杂,开发效率不高 ---------------------------------------------------- ORM: # 优点: 让用户不再写SQL语句,提高开发效率 可以很方便地引入数据缓存之类的附加功能 # 缺点: 在处理多表联查、where条件复杂查询时,ORM的语法会变得复杂。 没有原生SQL速度快
53.简述MVC和MTV
MVC:model、view(显示)、controller(视图) MTV:model、tempalte、view
二者本质没有区别。
54.Django的contenttype组件的作用?
contenttype是Django的一个组件(app),它可以将django下所有app下的表记录下来。 可以使用他再加上表中的两个字段,实现一张表和N张表动态创建FK关系。 - 字段:表名称 - 字段:数据行ID
55.谈谈你对Restfull规范的认识?
Restful其实就是一套编写接口的'风格规范',规定如何编写以及如何设置返回值、状态码等信息。 最显著的特点: # 用Restful: 给用户一个url,再根据不同的method在后端做不同的处理 比如:post创建数据、get获取数据、put和patch修改数据、delete删除数据。 # 不用Restful: 给调用者很多url,每个url代表一个功能,比如:add_user/delte_user/edit_user/ # 当然,还有其他的,比如: '版本' 来控制让程序有多个版本共存的情况,版本可以放在 url、请求头(accept/自定义)、GET参数 '状态码' 200/300/400/500 'url中尽量使用名词' restful也可以称为“面向资源编程” 'api标示' api.luffycity.com www.luffycity.com/api/
56.接口的幂等性是什么意思?
第一次访问一个接口后,再对该接口进行N次相同的访问时,对资源不造影响,就认为接口具有幂等性。 GET, #第一次获取结果、第二次也是获取结果对资源都不会造成影响,幂等。 POST, #第一次新增数据,第二次也会再次新增,非幂等。 PUT, #第一次更新数据,第二次不会再次更新,幂等。 PATCH,#第一次更新数据,第二次不会再次更新,非幂等。 DELTE,#第一次删除数据,第二次不在再删除,幂等。
57.什么是RPC?
'远程过程调用协议'。 是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。 进化的顺序: 现有的RPC,然后有的RESTful规范
58.Http和Https的区别?
#Http: 80端口 #https: 443端口 #http信息是明文传输,https则是具有安全性的ssl加密传输协议。 #- 自定义证书 - 服务端:创建一对证书 - 客户端:必须携带证书 #- 购买证书 - 服务端: 创建一对证书,。。。。 - 客户端: 去机构获取证书,数据加密后发给咱们的服务单 - 证书机构:公钥给改机构
59.为什么要使用Django Rest Framework框架?
# 在编写接口时可以不使用django rest framework框。 # 不使用:也可以做,可以用django的CBV来实现,开发者编写的代码会更多一些。 # 使用:内部帮助我们提供了很多方便的组件,我们通过配置就可以完成相应操作,如: '序列化'可以做用户请求数据校验+queryset对象的序列化称为json '解析器'获取用户请求数据request.data,会自动根据content-type请求头的不能对数据进行解析 '分页'将从数据库获取到的数据在页面进行分页显示 #还有其他组件:'认证'、'权限'、'访问频率控制'
60.Django Rest Framework框架中都有那些组件?
#- 路由,自动帮助开发者快速为一个视图创建4个url www.oldboyedu.com/api/v1/student/$ www.oldboyedu.com/api/v1/student(?P<format>w+)$ www.oldboyedu.com/api/v1/student/(?P<pk>d+)/$ www.oldboyedu.com/api/v1/student/(?P<pk>d+)(?P<format>w+)$ #- 版本处理 - 问题:版本都可以放在那里? - url - GET - 请求头 #- 认证 - 问题:认证流程? #- 权限 - 权限是否可以放在中间件中?以及为什么? #- 访问频率的控制 匿名用户可以真正的防止?无法做到真正的访问频率控制,只能把小白拒之门外。 如果要封IP,使用防火墙来做。 登录用户可以通过用户名作为唯一标示进行控制,如果有人注册很多账号,则无法防止。 #- 视图 #- 解析器 ,根据Content-Type请求头对请求体中的数据格式进行处理。request.data #- 分页 #- 序列化 - 序列化 - source - 定义方法 - 请求数据格式校验 #- 渲染器
61.Django Rest Framework框架中的视图都可以继承哪些类?
a. 继承APIView(最原始)但定制性比较强 这个类属于rest framework中的顶层类,内部帮助我们实现了只是基本功能:认证、权限、频率控制, 但凡是数据库、分页等操作都需要手动去完成,比较原始。 class GenericAPIView(APIView) def post(...): pass b.继承GenericViewSet(ViewSetMixin,generics.GenericAPIView) 首先他的路由就发生变化 如果继承它之后,路由中的as_view需要填写对应关系 在内部也帮助我们提供了一些方便的方法: get_queryset get_object get_serializer get_serializer_class get_serializer_context filter_queryset 注意:要设置queryset字段,否则会抛出断言的异常。 代码 只提供增加功能 只继承GenericViewSet class TestView(GenericViewSet): serialazer_class = xxx def creat(self,*args,**kwargs): pass # 获取数据并对数据 c. 继承 modelviewset --> 快速快发 -ModelViewSet(增删改查全有+数据库操作) -mixins.CreateModelMixin(只有增),GenericViewSet -mixins.CreateModelMixin,DestroyModelMixin,GenericViewSet 对数据库和分页等操作不用我们在编写,只需要继承相关类即可。 示例:只提供增加功能 class TestView(mixins.CreateModelMixin,GenericViewSet): serializer_class = XXXXXXX *** modelviewset --> 快速开发,复杂点的genericview、apiview
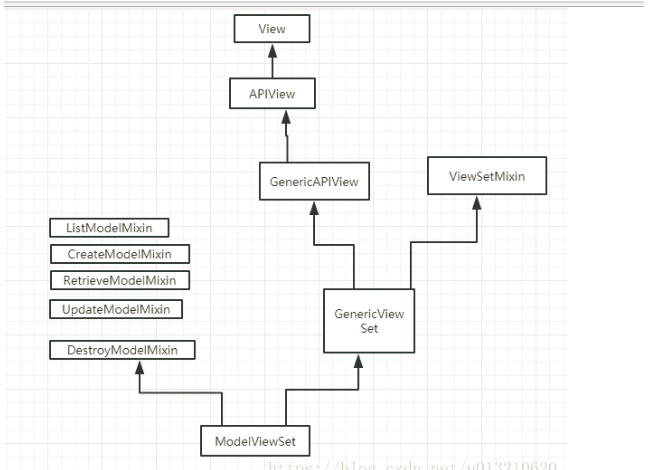
62.简述 Django Rest Framework框架的认证流程
- 如何编写?写类并实现authenticators 请求进来认证需要编写一个类,类里面有一个authenticators方法,我们可以自定义这个方法,可以定制3类返回值。 成功返回元组,返回none为匿名用户,抛出异常为认证失败。 源码流程:请求进来先走dispatch方法,然后封装的request对象会执行user方法,由user触发authenticators认证流程 - 方法中可以定义三种返回值: - (user,auth),认证成功 - None , 匿名用户 - 异常 ,认证失败 - 流程: - dispatch - 再去request中进行认证处理
63.Django Rest Framework如何实现的用户访问频率控制?
# 对匿名用户,根据用户IP或代理IP作为标识进行记录,为每个用户在redis中建一个列表
{
throttle_10.1.1.1:[1526868876.497521, 152686885.497521, ...],
throttle_10.1.1.2:[1526868876.497521, 152686885.497521, ...],
throttle_10.1.1.3:[1526868876.497521, 152686885.497521, ...],
}
每个用户再来访问时,先去记录中剔除过期记录,再根据列表的长度判断是否可以继续访问。
'如何封IP':在防火墙中进行设置
--------------------------------------------------------------------------
# 对注册用户,根据用户名或邮箱进行判断。
{
throttle_xxxx1:[1526868876.497521, 152686885.497521, ...],
throttle_xxxx2:[1526868876.497521, 152686885.497521, ...],
throttle_xxxx3:[1526868876.497521, 152686885.497521, ...],
}
每个用户再来访问时,先去记录中剔除过期记录,再根据列表的长度判断是否可以继续访问。
如1分钟:40次,列表长度限制在40,超过40则不可访问
64.Flask框架的优势?
Flask自由、灵活,可扩展性强,透明可控,第三方库的选择面广。
65.Flask框架依赖组件
# 依赖jinja2模板引擎 # 依赖werkzurg协议
66.Flask蓝图的作用
# blueprint把实现不同功能的module分开.也就是把一个大的App分割成各自实现不同功能的module. # 在一个blueprint中可以调用另一个blueprint的视图函数, 但要加相应的blueprint名.
67.列举使用的Flask第三方组件?
# Flask组件 flask-session session放在redis flask-SQLAlchemy 如django里的ORM操作 flask-migrate 数据库迁移 flask-script 自定义命令 blinker 信号-触发信号 # 第三方组件 Wtforms 快速创建前端标签、文本校验 dbutile 创建数据库连接池 gevnet-websocket 实现websocket # 自定义Flask组件 自定义auth认证 参考flask-login组件
68.简述Flask上下文管理流程?
# a、简单来说,falsk上下文管理可以分为三个阶段: 1、'请求进来时':将请求相关的数据放入上下问管理中 2、'在视图函数中':要去上下文管理中取值 3、'请求响应':要将上下文管理中的数据清除 # b、详细点来说: 1、'请求刚进来': 将request,session封装在RequestContext类中 app,g封装在AppContext类中 并通过LocalStack将requestcontext和appcontext放入Local类中 2、'视图函数中': 通过localproxy--->偏函数--->localstack--->local取值 3、'请求响应时': 先执行save.session()再各自执行pop(),将local中的数据清除
69.Flask中的g的作用?
# g是贯穿于一次请求的全局变量,当请求进来将g和current_app封装为一个APPContext类; # 再通过LocalStack将Appcontext放入Local中,取值时通过偏函数在LocalStack、local中取值; # 响应时将local中的g数据删除;
70.Flask中上下文管理主要涉及到了那些相关的类?并描述类主要作用?
RequestContext #封装进来的请求(赋值给ctx) AppContext #封装app_ctx LocalStack #将local对象中的数据维护成一个栈(先进后出) Local #保存请求上下文对象和app上下文对象
71.为什么要Flask把Local对象中的的值stack维护成一个列表?
# 因为通过维护成列表,可以实现一个栈的数据结构,进栈出栈时只取一个数据,巧妙的简化了问题。 # 还有,在多app应用时,可以实现数据隔离;列表里不会加数据,而是会生成一个新的列表 # local是一个字典,字典里key(stack)是唯一标识,value是一个列表
72.Flask中多app应用是怎么完成?
请求进来时,可以根据URL的不同,交给不同的APP处理。蓝图也可以实现。
#app1 = Flask('app01')
#app2 = Flask('app02')
#@app1.route('/index')
#@app2.route('/index2')
源码中在DispatcherMiddleware类里调用app2.__call__,
原理其实就是URL分割,然后将请求分发给指定的app。
之后app也按单app的流程走。就是从app.__call__走。
73.在Flask中实现WebSocket需要什么组件?
gevent-websocket
74.wtforms组件的作用?
#快速创建前端标签、文本校验;如django的ModelForm
75.Flask框架默认session处理机制?
# 前提: 不熟的话:记不太清了,应该是……分两个阶段吧 # 创建: 当请求刚进来的时候,会将request和session封装成一个RequestContext()对象, 接下来把这个对象通过LocalStack()放入内部的一个Local()对象中; 因为刚开始 Local 的ctx中session是空的; 所以,接着执行open_session,将cookie 里面的值拿过来,重新赋值到ctx中 (Local实现对数据隔离,类似threading.local) # 销毁: 最后返回时执行 save_session() 将ctx 中的session读出来进行序列化,写到cookie 然后给用户,接着把 ctx pop掉
76.解释Flask框架中的Local对象和threading.local对象的区别?
# a.threading.local
作用:为每个线程开辟一块空间进行数据存储(数据隔离)。
问题:自己通过字典创建一个类似于threading.local的东西。
storage = {
4740: {val: 0},
4732: {val: 1},
4731: {val: 3},
}
# b.自定义Local对象
作用:为每个线程(协程)开辟一块空间进行数据存储(数据隔离)。
class Local(object):
def __init__(self):
object.__setattr__(self, 'storage', {})
def __setattr__(self, k, v):
ident = get_ident()
if ident in self.storage:
self.storage[ident][k] = v
else:
self.storage[ident] = {k: v}
def __getattr__(self, k):
ident = get_ident()
return self.storage[ident][k]
obj = Local()
def task(arg):
obj.val = arg
obj.xxx = arg
print(obj.val)
for i in range(10):
t = Thread(target=task, args=(i,))
t.start()
77.Flask中 blinker 是什么?
# flask中的信号blinker 信号主要是让开发者可是在flask请求过程中定制一些行为。 或者说flask在列表里面预留了几个空列表,在里面存东西。 简言之,信号允许某个'发送者'通知'接收者'有事情发生了
@before_request有返回值,blinker没有返回值
# 10个信号
request_started = _signals.signal('request-started') #请求到来前执行
request_finished = _signals.signal('request-finished') #请求结束后执行
before_render_template = _signals.signal('before-render-template') #模板渲染前执行
template_rendered = _signals.signal('template-rendered') #模板渲染后执行
got_request_exception = _signals.signal('got-request-exception') #请求执行出现异常时执行
request_tearing_down = _signals.signal('request-tearing-down') #请求执行完毕后自动执行(无论成功与否)
appcontext_tearing_down = _signals.signal('appcontext-tearing-down') #请求上下文执行完毕后自动执行(无论成功与否)
appcontext_pushed = _signals.signal('appcontext-pushed') #请求app上下文push时执行
appcontext_popped = _signals.signal('appcontext-popped') #请求上下文pop时执行
message_flashed = _signals.signal('message-flashed')#调用flask在其中添加数据时,自动触发
78.SQLAlchemy中的 session和scoped_session 的区别?
# Session: 由于无法提供线程共享功能,开发时要给每个线程都创建自己的session 打印sesion可知他是sqlalchemy.orm.session.Session的对象 # scoped_session: 为每个线程都创建一个session,实现支持线程安全 在整个程序运行的过程当中,只存在唯一的一个session对象。 创建方式: 通过本地线程Threading.Local() # session=scoped_session(Session) 创建唯一标识的方法(参考flask请求源码)
79.SQLAlchemy如何执行原生SQL?
# 使用execute方法直接操作SQL语句(导入create_engin、sessionmaker) engine = create_engine('mysql://root:*****@127.0.0.1/database?charset=utf8') DB_Session = sessionmaker(bind=engine) session = DB_Session() session.execute('alter table mytablename drop column mycolumn ;')
80.ORM的实现原理?
# ORM的实现基于一下三点 映射类:描述数据库表结构, 映射文件:指定数据库表和映射类之间的关系 数据库配置文件:指定与数据库连接时需要的连接信息(数据库、登录用户名、密码or连接字符串)
81.DBUtils模块的作用?
# 数据库连接池 使用模式: 1、为每个线程创建一个连接,连接不可控,需要控制线程数 2、创建指定数量的连接在连接池,当线程访问的时候去取,不够了线程排队,直到有人释放(推荐) --------------------------------------------------------------------------- 两种写法: 1、用静态方法装饰器,通过直接执行类的方法来连接使用数据库 2、通过实例化对象,通过对象来调用方法执行语句 https://www.cnblogs.com/ArmoredTitan/p/Flask.html
以下SQLAlchemy的字段是否正确?如果不正确请更正:
from datetime import datetime from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, DateTime Base = declarative_base() class UserInfo(Base): __tablename__ = 'userinfo' id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(64), unique=True) ctime = Column(DateTime, default=datetime.now()) ----------------------------------------------------------------------- 更正: ctime 字段中参数应为’default=datetime.now’,now后面不应该加括号,加了的话,字段不会实时更新。
82.SQLAchemy中如何为引擎和表设置字符编码?
1. 设置引擎编码方式为utf8。
engine = create_engine("mysql+pymysql://user:password@127.0.0.1:3306/db01?charset=utf8")
2. 设置数据库表编码方式为utf8
class UserType(Base):
__tablename__ = 'usertype'
id = Column(Integer, primary_key=True)
caption = Column(String(50), default='管理员')
# 添加配置
__table_args__ = {
'mysql_charset': 'utf8'
}
这样生成的SQL语句就自动设置数据表编码为utf8了,__table_args__还可设置存储引擎、外键约束等等信息。
83.SQLAchemy中如何设置联合唯一索引?
通过'UniqueConstraint'字段来设置联合唯一索引
__table_args__ = {
UniqueConstraint('hid', 'username', name='hid_username_i')
}
#hid和username组成联合唯一约束。
84.简述Tornado框架的特点
异步非阻塞+websocket
85.简述Tornado框架中Future对象的作用?
# 实现异步非阻塞 视图函数yield一个future对象,future对象默认: self._done = False ,请求未完成 self._result = None ,请求完成后返回值,用于传递给回调函数使用。 tornado就会一直去检测future对象的_done是否已经变成True。 如果IO请求执行完毕,自动会调用future的set_result方法: self._result = result self._done = True 参考:http://www.cnblogs.com/wupeiqi/p/6536518.html(自定义异步非阻塞web框架)
86.Tornado框架中如何编写WebSocket程序?
Tornado在websocket模块中提供了一个WebSocketHandler类。 这个类提供了和已连接的客户端通信的WebSocket事件和方法的钩子。 当一个新的WebSocket连接打开时,open方法被调用, 而on_message和on_close方法,分别在连接、接收到新的消息和客户端关闭时被调用。 此外,WebSocketHandler类还提供了write_message方法用于向客户端发送消息,close方法用于关闭连接。
87.Tornado中静态文件是如何处理的? 如: <link href="{{static_url("commons.css")}}" rel="stylesheet" />
# settings.py
settings = {
"static_path": os.path.join(os.path.dirname(__file__), "static"),
# 指定了静态文件的位置在当前目录中的"static"目录下
"cookie_secret": "61oETzKXQAGaYdkL5gEmGeJJFuYh7EQnp2XdTP1o/Vo=",
"login_url": "/login",
"xsrf_cookies": True,
}
经上面配置后
static_url()自动去配置的路径下找'commons.css'文件
88.Tornado操作MySQL使用的模块?
torndb torndb是基于mysqldb的再封装,所以使用时要先安装myqldb
89.Tornado操作redis使用的模块?
tornado-redis
90.简述Tornado框架的适用场景?
web聊天室,在线投票
91.git常见命令和作用
- git init //初始化本地git环境
- git clone XXX //克隆一份代码到本地仓库
- git pull //把远程库的代码更新到工作台
- git pull --rebase origin master //强制把远程库的代码跟新到当前分支上面
- git fetch //把远程库的代码更新到本地库
- git add . //把本地的修改加到stage中
- git commit -m 'comments here' //把stage中的修改提交到本地库
- git push //把本地库的修改提交到远程库中
- git branch -r/-a //查看远程分支/全部分支
- git checkout master/branch //切换到某个分支
- git checkout -b test //新建test分支
- git checkout -d test //删除test分支
- git merge master //假设当前在test分支上面,把master分支上的修改同步到test分支上
- git merge tool //调用merge工具
- git stash //把未完成的修改缓存到栈容器中
- git stash list //查看所有的缓存
- git stash pop //恢复本地分支到缓存状态
- git blame someFile //查看某个文件的每一行的修改记录()谁在什么时候修改的)
- git status //查看当前分支有哪些修改
- git log //查看当前分支上面的日志信息
- git diff //查看当前没有add的内容
- git diff --cache //查看已经add但是没有commit的内容
- git diff HEAD //上面两个内容的合并
- git reset --hard HEAD //撤销本地修改,版本回滚
92.简述以下git中stash命令作用以及相关其他命令
'git stash':将当前工作区所有修改过的内容存储到“某个地方”,将工作区还原到当前版本未修改过的状态 'git stash list':查看“某个地方”存储的所有记录 'git stash clear':清空“某个地方” 'git stash pop':将第一个记录从“某个地方”重新拿到工作区(可能有冲突) 'git stash apply':编号, 将指定编号记录从“某个地方”重新拿到工作区(可能有冲突) 'git stash drop':编号,删除指定编号的记录
93.git 中 merge 和 rebase命令 的区别
merge: 会将不同分支的提交合并成一个新的节点,之前的提交分开显示, 注重历史信息、可以看出每个分支信息,基于时间点,遇到冲突,手动解决,再次提交 rebase: 将两个分支的提交结果融合成线性,不会产生新的节点; 注重开发过程,遇到冲突,手动解决,继续操作
94.公司如何基于git做的协同开发?
1、你们公司的代码review分支怎么做?谁来做? 答:组长创建review分支,我们小功能开发完之后,合并到review分支交给老大(小组长)来看。 1.1、你组长不开发代码吗? 他开发代码,但是它只开发核心的东西,任务比较少 或者抽出时间,我们一起做这个事情。 2、你们公司协同开发是怎么协同开发的? 每个人都有自己的分支,阶段性代码完成之后,合并到review,然后交给老大看。 -------------------------------------------------------------------------- # 大致工作流程: 在公司: 下载代码 git clone https://gitee.com/wupeiqi/xianglong.git 或创建目录 cd 目录 git init git remote add origin https://gitee.com/wupeiqi/xianglong.git git pull origin maste 创建dev分支
git checkout -b dev git checkout dev git pull origin dev 继续写代码 git add . git commit -m '提交记录' git push origin dev 回到家中: 拉代码: git pull origin dev 继续写: 继续写代码 git add . git commit -m '提交记录' git push origin dev
95.如何基于git实现代码review?
https://blog.csdn.net/june_y/article/details/50817993
96.git如何实现v1.0、v2.0等版本的管理?
在命令行中,使用git tag –a tagname –m 'comment'可以快速创建一个标签。 需要注意,命令行创建的标签只存在本地Git库中,还需要使用Git push –tags指令发布到服务器的Git库中。
97.什么是gitlab
gitlab是公司自己搭建的项目代码托管平台。
98.github和gitlab的区别?
1、gitHub是一个面向开源及私有软件项目的托管平台(创建私有的话,需要购买,最低级的付费为每月7刀,支持5个私有项目) 2、gitlab是公司自己搭建的项目托管平台
99.如何为github上牛逼的开源项目贡献代码?
1、fork需要协作项目 2、克隆/关联fork的项目到本地 3、新建分支(branch)并检出(checkout)新分支 4、在新分支上完成代码开发 5、开发完成后将你的代码合并到master分支 6、添加原作者的仓库地址作为一个新的仓库地址 7、合并原作者的master分支到你自己的master分支,用于和作者仓库代码同步 8、push你的本地仓库到GitHub 9、在Github上提交 pull requests 10、等待管理员(你需要贡献的开源项目管理员)处理
100.git中 .gitignore文件的作用
一般来说每个Git项目中都需要一个“.gitignore”文件, 这个文件的作用就是告诉Git哪些文件不需要添加到版本管理中。 实际项目中,很多文件都是不需要版本管理的,比如Python的.pyc文件和一些包含密码的配置文件等等。
101.什么是敏捷开发?
'敏捷开发':是一种以人为核心、迭代、循序渐进的开发方式。 它并不是一门技术,而是一种开发方式,也就是一种软件开发的流程。 它会指导我们用规定的环节去一步一步完成项目的开发。 因为它采用的是迭代式开发,所以这种开发方式的主要驱动核心是人
102.简述 jenkins 工具的作用?
'Jenkins'是一个可扩展的持续集成引擎。 主要用于: 持续、自动地构建/测试软件项目。 监控一些定时执行的任务。
103.公司如何实现代码发布?
nginx+uwsgi+django 、
https://www.cnblogs.com/wcwnina/p/9906081.html
104.简述 RabbitMQ、Kafka、ZeroMQ的区别?
https://blog.csdn.net/zhailihua/article/details/7899006
105.RabbitMQ如何在消费者获取任务后未处理完前就挂掉时,保证数据不丢失?
为了预防消息丢失,rabbitmq提供了ack 即工作进程在收到消息并处理后,发送ack给rabbitmq,告知rabbitmq这时候可以把该消息从队列中删除了。 如果工作进程挂掉 了,rabbitmq没有收到ack,那么会把该消息 重新分发给其他工作进程。 不需要设置timeout,即使该任务需要很长时间也可以处理。 ack默认是开启的,工作进程显示指定了no_ack=True
106.RabbitMQ如何对消息做持久化?
1、创建队列和发送消息时将设置durable=Ture,如果在接收到消息还没有存储时,消息也有可能丢失,就必须配置publisher confirm channel.queue_declare(queue='task_queue', durable=True) 2、返回一个ack,进程收到消息并处理完任务后,发给rabbitmq一个ack表示任务已经完成,可以删除该任务 3、镜像队列:将queue镜像到cluster中其他的节点之上。 在该实现下,如果集群中的一个节点失效了,queue能自动地切换到镜像中的另一个节点以保证服务的可用性
107.RabbitMQ如何控制消息被消费的顺序?
默认消息队列里的数据是按照顺序被消费者拿走, 例如:消费者1 去队列中获取奇数序列的任务,消费者2去队列中获取偶数序列的任务。 channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列(同时也保证了公平的消费分发)
108.以下RabbitMQ的exchange type分别代表什么意思?如:fanout、direct、topic
amqp协议中的核心思想就是生产者和消费者隔离,生产者从不直接将消息发送给队列。 生产者通常不知道是否一个消息会被发送到队列中,只是将消息发送到一个交换机。 先由Exchange来接收,然后Exchange按照特定的策略转发到Queue进行存储。 同理,消费者也是如此。Exchange 就类似于一个交换机,转发各个消息分发到相应的队列中。 -------------------------------------------------- type=fanout 类似发布者订阅者模式,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中 type=direct 队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。 type=topic 队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,
则将数据发送到指定队列。 --------------------------------------------------- 发送者路由值 队列中 old.boy.python old.* -- 不匹配 *表示匹配一个 old.boy.python old.# -- 匹配 #表示匹配0个或多个
109.简述 celery 是什么以及应用场景?
# Celery是由Python开发的一个简单、灵活、可靠的处理大量任务的分发系统, # 它不仅支持实时处理也支持任务调度。 # http://www.cnblogs.com/wupeiqi/articles/8796552.html
110.简述celery运行机制
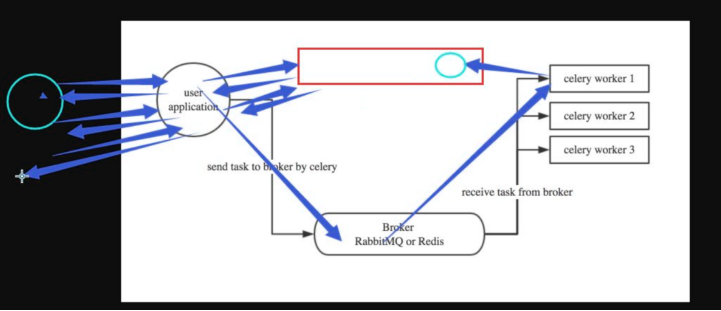
111.celery如何实现定时任务?
# celery实现定时任务
启用Celery的定时任务需要设置CELERYBEAT_SCHEDULE 。
CELERYBEAT_SCHEDULE='djcelery.schedulers.DatabaseScheduler'#定时任务
'创建定时任务'
# 通过配置CELERYBEAT_SCHEDULE:
#每30秒调用task.add
from datetime import timedelta
CELERYBEAT_SCHEDULE = {
'add-every-30-seconds': {
'task': 'tasks.add',
'schedule': timedelta(seconds=30),
'args': (16, 16)
},
}
112.简述 celery多任务结构目录
pro_cel ├── celery_tasks # celery相关文件夹 │ ├── celery.py # celery连接和配置相关文件 │ └── tasks.py # 所有任务函数 ├── check_result.py # 检查结果 └── send_task.py # 触发任务
113.celery中装饰器 @app.task 和 @shared_task的区别?
# 一般情况使用的是从celeryapp中引入的app作为的装饰器:@app.task # django那种在app中定义的task则需要使用@shared_task
114.简述 requests模块的作用及基本使用?
# 作用: 使用requests可以模拟浏览器的请求 # 常用参数: url、headers、cookies、data json、params、proxy # 常用返回值: content iter_content text encoding="utf-8" cookie.get_dict()
115.简述 Beautifulsoup模块的作用及基本使用?
#BeautifulSoup 用于从HTML或XML文件中提取、过滤想要的数据形式 #常用方法 解析:html.parser 或者 lxml(需要下载安装) find、find_all、text、attrs、get
https://www.cnblogs.com/wcwnina/p/8093987.html
116.简述 seleninu模块的作用及基本使用?
Selenium是一个用于Web应用程序测试的工具, 他的测试直接运行在浏览器上,模拟真实用户,按照代码做出点击、输入、打开等操作 爬虫中使用他是为了解决requests无法解决javascript动态问题
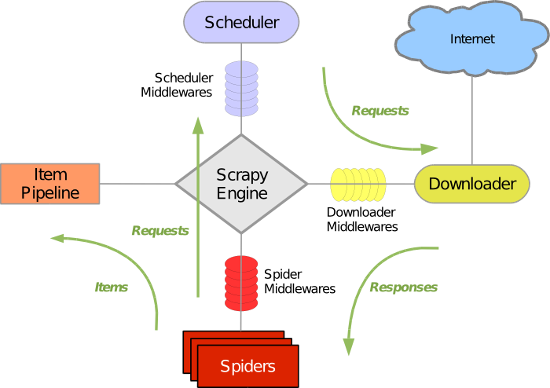
117.Scrapy框架中各组件的工作流程?
Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向):
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
介于Scrapy引擎和下载器之间的中间件,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的中间件,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
1.引擎:Hi!Spider, 你要处理哪一个网站? 2.Spider:老大要我处理xxxx.com(初始URL)。 3.引擎:你把第一个需要处理的URL给我吧。 4.Spider:给你,第一个URL是xxxxxxx.com。 5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。 6.调度器:好的,正在处理你等一下。 7.引擎:Hi!调度器,把你处理好的request请求给我。 8.调度器:给你,这是我处理好的request 9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。 10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载) 11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的) 12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。 13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。 14.管道、调度器:好的,现在就做!
https://blog.csdn.net/qq_37143745/article/details/80996707
118.在scrapy框架中如何设置代理(两种方法)?
方式一:内置添加代理功能
# -*- coding: utf-8 -*-
import os
import scrapy
from scrapy.http import Request
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
start_urls = ['https://dig.chouti.com/']
def start_requests(self):
os.environ['HTTP_PROXY'] = "http://192.168.11.11"
for url in self.start_urls:
yield Request(url=url,callback=self.parse)
def parse(self, response):
print(response)
方式二:自定义下载中间件
import random
import base64
import six
def to_bytes(text, encoding=None, errors='strict'):
"""Return the binary representation of `text`. If `text`
is already a bytes object, return it as-is."""
if isinstance(text, bytes):
return text
if not isinstance(text, six.string_types):
raise TypeError('to_bytes must receive a unicode, str or bytes '
'object, got %s' % type(text).__name__)
if encoding is None:
encoding = 'utf-8'
return text.encode(encoding, errors)
class MyProxyDownloaderMiddleware(object):
def process_request(self, request, spider):
proxy_list = [
{'ip_port': '111.11.228.75:80', 'user_pass': 'xxx:123'},
{'ip_port': '120.198.243.22:80', 'user_pass': ''},
{'ip_port': '111.8.60.9:8123', 'user_pass': ''},
{'ip_port': '101.71.27.120:80', 'user_pass': ''},
{'ip_port': '122.96.59.104:80', 'user_pass': ''},
{'ip_port': '122.224.249.122:8088', 'user_pass': ''},
]
proxy = random.choice(proxy_list)
if proxy['user_pass'] is not None:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass']))
request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass)
else:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
配置:
DOWNLOADER_MIDDLEWARES = {
# 'xiaohan.middlewares.MyProxyDownloaderMiddleware': 543,
}
119.scrapy框架中如何实现大文件的下载?
from twisted.web.client import Agent, getPage, ResponseDone, PotentialDataLoss from twisted.internet import defer, reactor, protocol from twisted.web._newclient import Response from io import BytesIO class _ResponseReader(protocol.Protocol): def __init__(self, finished, txresponse, file_name): self._finished = finished self._txresponse = txresponse self._bytes_received = 0 self.f = open(file_name, mode='wb') def dataReceived(self, bodyBytes): self._bytes_received += len(bodyBytes) # 一点一点的下载 self.f.write(bodyBytes) self.f.flush() def connectionLost(self, reason): if self._finished.called: return if reason.check(ResponseDone): # 下载完成 self._finished.callback((self._txresponse, 'success')) elif reason.check(PotentialDataLoss): # 下载部分 self._finished.callback((self._txresponse, 'partial')) else: # 下载异常 self._finished.errback(reason) self.f.close()
120.scrapy中如何实现限速?
http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/autothrottle.html
121.scrapy中如何实现暂停爬虫?
# 有些情况下,例如爬取大的站点,我们希望能暂停爬取,之后再恢复运行。 # Scrapy通过如下工具支持这个功能: 一个把调度请求保存在磁盘的调度器 一个把访问请求保存在磁盘的副本过滤器[duplicates filter] 一个能持续保持爬虫状态(键/值对)的扩展 Job 路径 要启用持久化支持,你只需要通过 JOBDIR 设置 job directory 选项。 这个路径将会存储所有的请求数据来保持一个单独任务的状态(例如:一次spider爬取(a spider run))。 必须要注意的是,这个目录不允许被不同的spider共享,甚至是同一个spider的不同jobs/runs也不行。 也就是说,这个目录就是存储一个单独 job的状态信息。
122.scrapy中如何进行自定制命令?
在spiders同级创建任意目录,如:commands 在其中创建'crawlall.py'文件(此处文件名就是自定义的命令) from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self): return '[options]' def short_desc(self): return 'Runs all of the spiders' def run(self, args, opts): spider_list = self.crawler_process.spiders.list() for name in spider_list: self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start() 在'settings.py'中添加配置'COMMANDS_MODULE = '项目名称.目录名称'' 在项目目录执行命令:'scrapy crawlall'
123.scrapy中如何实现的记录爬虫的深度?
'DepthMiddleware'是一个用于追踪每个Request在被爬取的网站的深度的中间件。 其可以用来限制爬取深度的最大深度或类似的事情。 'DepthMiddleware'可以通过下列设置进行配置(更多内容请参考设置文档): 'DEPTH_LIMIT':爬取所允许的最大深度,如果为0,则没有限制。 'DEPTH_STATS':是否收集爬取状态。 'DEPTH_PRIORITY':是否根据其深度对requet安排优先
124.scrapy中的pipelines工作原理?
Scrapy 提供了 pipeline 模块来执行保存数据的操作。 在创建的 Scrapy 项目中自动创建了一个 pipeline.py 文件,同时创建了一个默认的 Pipeline 类。 我们可以根据需要自定义 Pipeline 类,然后在 settings.py 文件中进行配置即可
125.scrapy的pipelines如何丢弃一个item对象?
通过raise DropItem()方法
126.简述scrapy中爬虫中间件和下载中间件的作用?
http://www.cnblogs.com/wupeiqi/articles/6229292.html
127.scrapy-redis组件的作用?
实现了分布式爬虫,url去重、调度器、数据持久化 'scheduler'调度器 'dupefilter'URL去重规则(被调度器使用) 'pipeline'数据持久化
128.scrapy-redis组件中如何实现的任务的去重?
a. 内部进行配置,连接Redis
b.去重规则通过redis的集合完成,集合的Key为:
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
默认配置:
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
c.去重规则中将url转换成唯一标示,然后在redis中检查是否已经在集合中存在
from scrapy.utils import request
from scrapy.http import Request
req = Request(url='http://www.cnblogs.com/wupeiqi.html')
result = request.request_fingerprint(req)
print(result) # 8ea4fd67887449313ccc12e5b6b92510cc53675c
scrapy和scrapy-redis的去重规则(源码)
1. scrapy中去重规则是如何实现?
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
def __init__(self, path=None, debug=False):
self.fingerprints = set()
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
def request_seen(self, request):
# 将request对象转换成唯一标识。
fp = self.request_fingerprint(request)
# 判断在集合中是否存在,如果存在则返回True,表示已经访问过。
if fp in self.fingerprints:
return True
# 之前未访问过,将url添加到访问记录中。
self.fingerprints.add(fp)
def request_fingerprint(self, request):
return request_fingerprint(request)
2. scrapy-redis中去重规则是如何实现?
class RFPDupeFilter(BaseDupeFilter):
"""Redis-based request duplicates filter.
This class can also be used with default Scrapy's scheduler.
"""
logger = logger
def __init__(self, server, key, debug=False):
# self.server = redis连接
self.server = server
# self.key = dupefilter:123912873234
self.key = key
@classmethod
def from_settings(cls, settings):
# 读取配置,连接redis
server = get_redis_from_settings(settings)
#
key = dupefilter:123912873234
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
@classmethod
def from_crawler(cls, crawler):
return cls.from_settings(crawler.settings)
def request_seen(self, request):
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
# self.server=redis连接
# 添加到redis集合中:1,添加工程;0,已经存在
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
return request_fingerprint(request)
def close(self, reason=''):
self.clear()
def clear(self):
"""Clears fingerprints data."""
self.server.delete(self.key)
129.简述 vitualenv 及应用场景?
'vitualenv'是一个独立的python虚拟环境。 如: 当前项目依赖的是一个版本,但是另一个项目依赖的是另一个版本,这样就会造成依赖冲突, 而virtualenv就是解决这种情况的,virtualenv通过创建一个虚拟化的python运行环境, 将我们所需的依赖安装进去的,不同项目之间相互不干扰。
130.简述 pipreqs 及应用场景?
可以通过对项目目录扫描,自动发现使用了那些类库,并且自动生成依赖清单。 pipreqs ./ 生成requirements.txt
131.在Python中使用过什么代码检查工具?
1)PyFlakes:静态检查Python代码逻辑错误的工具。 2)Pep8: 静态检查PEP8编码风格的工具。 3)NedBatchelder’s McCabe script:静态分析Python代码复杂度的工具。 Python代码分析工具:PyChecker、Pylint
132.B Tree和B+ Tree的区别?
1.B树中同一键值不会出现多次,并且有可能出现在叶结点,也有可能出现在非叶结点中。 而B+树的键一定会出现在叶结点中,并有可能在非叶结点中重复出现,以维持B+树的平衡。 2.因为B树键位置不定,且在整个树结构中只出现一次,
133.请列举你熟悉的设计模式?
工厂模式/单例模式等。
134.有没有刷过leetcode?
leetcode是个题库,里面有多很编程题目,可以在线编译运行。 https://leetcode-cn.com/problemset/all/
135.列举熟悉的的Linux命令。
1创建目录 mkdir /data cd / mkdir data 2查看目录 ls ls -l 显示详细信息
136.公司线上服务器是什么系统?
Linux/Centos
137.解释 PV、UV 的含义?
PV访问量(Page View),即页面访问量,每打开一次页面PV计数+1,刷新页面也是。 UV访客量(Unique Visitor)指独立访客访问数,一台电脑终端为一个访客。
138.解释 QPS的含义?
'QPS(Query Per Second)' 每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准
139.uwsgi和wsgi的区别?
wsgi是一种通用的接口标准或者接口协议,实现了python web程序与服务器之间交互的通用性。 uwsgi:同WSGI一样是一种通信协议 uwsgi协议是一个'uWSGI服务器'自有的协议,它用于定义传输信息的类型, 'uWSGI'是实现了uwsgi和WSGI两种协议的Web服务器,负责响应python的web请求。
140.supervisor的作用?
# Supervisor: 是一款基于Python的进程管理工具,可以很方便的管理服务器上部署的应用程序。 是C/S模型的程序,其服务端是supervisord服务,客户端是supervisorctl命令 # 主要功能: 1 启动、重启、关闭包括但不限于python进程。 2 查看进程的运行状态。 3 批量维护多个进程。
141.什么是反向代理?
正向代理代理客户端(客户端找一个代理去访问服务器,服务器不知道你的真实IP) 反向代理代理服务器(服务器找一个代理给你响应,你不知道服务器的真实IP)
142.简述SSH的整个过程。
SSH 为 'Secure Shell' 的缩写,是建立在应用层基础上的安全协议。 SSH 是目前较可靠,为远程登录会话和其他网络服务提供的安全性协议。 利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。
143.有问题都去那些找解决方案?
起初是百度,发现搜到的答案不精准,净广告 转战谷歌,但墙了;捣鼓怎么FQ 还会去知乎、stackoverfloow、必应、思否(segmentfault)
144.是否有关注什么技术类的公众号?
python之禅(主要专注Python相关知识,作者:刘志军) 码农翻身(主要是Java的,但不光是java,涵盖面很广,作者:刘欣) 实验楼(在线练项目) and so on
145.最近在研究什么新技术?
Numpy pandas(金融量化分析、聚宽) 百度AI 图灵API 智能玩具
来自转载,有较大改动。

转载于:https://www.cnblogs.com/wcwnina/p/10295350.html
最后
以上就是愤怒可乐最近收集整理的关于Python 经典面试题汇总之框架篇前端和框架的全部内容,更多相关Python内容请搜索靠谱客的其他文章。








发表评论 取消回复