先占个坑,立志于写一个简单易懂又符合逻辑的深度强化学习教程吧。这篇文章适合知道Reinforcement Learning是啥,稍稍有些理解,最好是对DQN有些理解的小伙伴们阅读。如果你还不知道强化学习的基本概念,Q Learning是什么,DQN是什么的话,那可以先去有个了解再回来哦。然后的话这篇文章里面部分数学方面的推导将直接给结论,因为有点太复杂了,感兴趣的朋友可以去原paper里去找。
强化学习这一块主要分为两个大的部分,一个是value-based,其中以 Q-Learning,SARSA,DQN为代表,这一类的话网上教程比较多,也比较详细,也比较简单,效果也相对比较差,就不写这一块了;另一个部分是policy-based,以A3C(Asynchronous Advantage Actor-Critic)(也可以被认为是value-based和policy-based的结合),DDPG(Deep Deterministic Policy Gradient) , TRPO(Trust Region Policy Optimization),PPO(Proximal Policy Optimization)为代表, 这一部分的话理解起来会稍微难一些,但是是现在的主流方法,尤其是PPO,DeepMind 和 OpenAI 最近都以它作为默认使用的最有方法了。那我们接下来就开始吧!
首先的话在整个教程开始之前,在这里先把所需要用的一些基本元素和概念简单罗列介绍一下。一般来说,policy-based 强化学习的目的就是建立一个policy π,这个policy可以被认为是一个神经网络(neural network),它的输入是State s,输出是Action a。可以想象一下,当这个policy或者说是network训练成功以后,把任意一个state(s可以是这一时刻的图片,或agent所处的位置等等)输入到policy中,都可以得到一个应该采取的action(a在policy中一般被设定为某一行为,比如说向上走,被采用的概率),从而使agent得到最多的Reward r。这里就把强化学习中重要的要素policy π,State s,Action a,Reward r解释了一下,当然,使用强化学习的最终目的,就是要构建一个非常棒的策略,也就是policy π, 从而使得在agent在任意state情况下,可以做出最优action,然后得到尽可能多的reward。
这一切的一切都要从这篇 Policy Gradient Methods for Reinforcement Learning with Function Approximation 说起,这一篇论文可以被认为是如今这方面方法的奠基之作,非常的经典。首先要关注的是这一个公式:
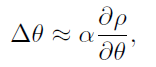
在这里,ρ可以被认为是performance,也就是这个policy的表现;而θ则是policy中的参数,现在常用做法是把policy用神经网络表示出来,那么这里的参数就是要学习的神经元之间的连接参数啦,w,b什么的;α的话则是梯度更新时步子的大小,几乎可以被认定为learning rate。根据这个公式,policy也就是神经网络的参数更新梯度就可以被计算出来了,也就是说整个神经网络将会朝着ρ的最大化的方向更新。好了,现在我们只需要找出方程右边那一块怎么算,那么就可以不断的优化policy了。
这时候,文章中给出了一个定理:
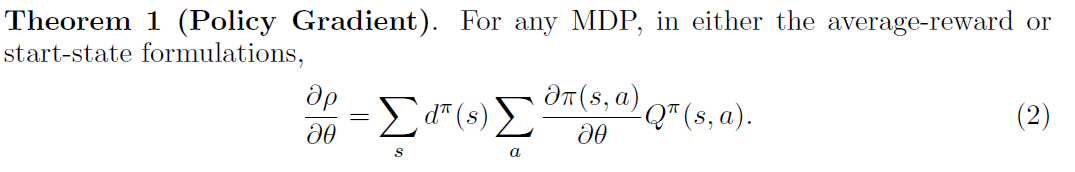
这个公式给出了梯度的计算方法。一项一项来看,首先这里的d被看作是在policy π下的state的稳态分布,文章中提到这个分布可以被假定为对于所有不同的policy来说,独立于初始状态s0;然后再来看第二项π,这里的话毫无疑问指的就是这个policy,也就是在DRL里的神经网络了;再来看第三项Q,它指的是每一对state-action所对应的value,这里与Q-Learning中的Q value是几乎一样的概念,这个值越大的话,就说明在这个特定state的情况下这个特定的action越好。
那么到了这里之后,文章中又证明了我们可以用一个方程f(s,a)去近似代替Q(s,a),从而达到求解梯度的目的,详细的推到和证明这里就不给出了。之后文章中又提到:
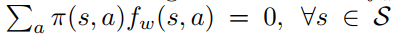
这样的话,那么这个function approximator f(s,a)实际上就可以认为是advantage function的近似了。那么advantage function一般可以认为是这个东西:
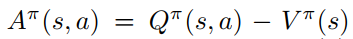
这里Q的意义和前文一样,而V指的是当前state的value,也就是评价当前state的好坏(比如说能获得reward的state所对应的V一般来说就会大一些)。
到了这里,我们就可以得到梯度的计算方式了:
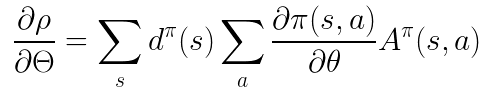
这时候我们对这个方程进行进一步的操作,可以得到:
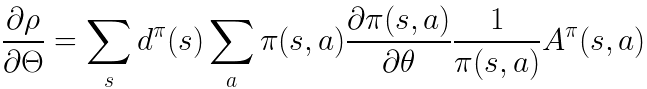
然后就可以得到:
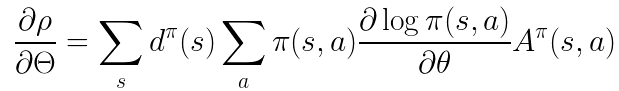
最后前两项的话实际上就可以被认为是在一些有限的采样后得到的期望,这里不知道怎么具体解释,可以参考PPO的论文。最终的话我们就可以得到policy gradient的究极形态了:
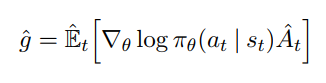
这个公式出自于PPO(Proximal Policy Optimization),g表示的就是梯度。个人感觉这个表达方式十分清晰易懂,于是就放在这里。到这里,policy gradient的思路已经介绍完了。下一篇文章将从这里继续,讲解A3C算法。
最后
以上就是欣慰裙子最近收集整理的关于Policy-based Deep Reinforcement Learning: From 0 To 1 -- Policy Gradient的全部内容,更多相关Policy-based内容请搜索靠谱客的其他文章。








发表评论 取消回复