http://arxiv.org/abs/1507.04296
Introduction
Existing work on distributed deep learning has focused exclusively on supervised and unsupervised learning. In this paper we develop a new architecture for the reinforcement learning paradigm, which we called Gorila (General Reinforcement Learning Architecture), aiming to solve a single-agent problem more efficiently by exploiting parallel computation.
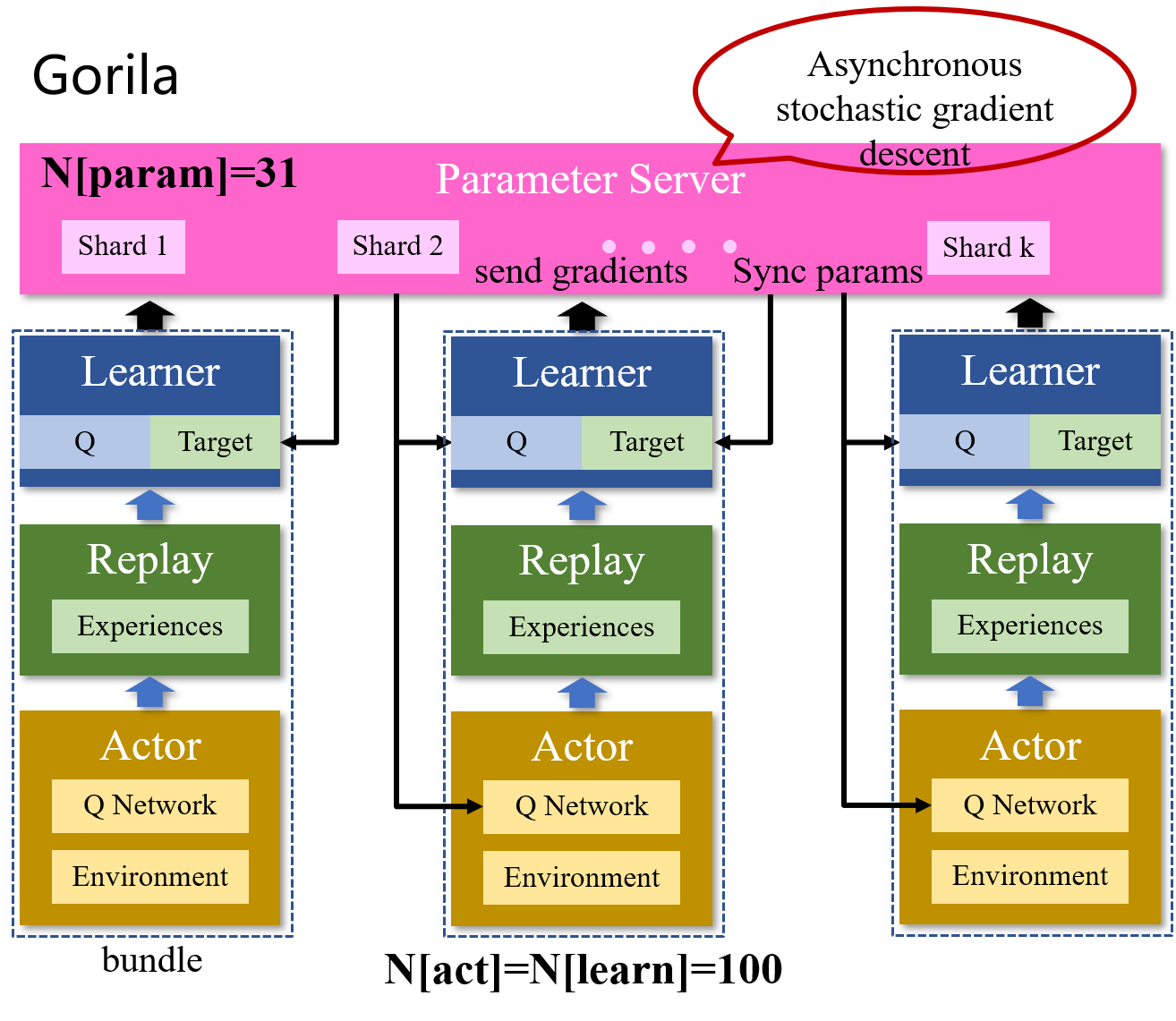
Distributed Architecture

4 components.
- Actor - Generate experiences.
- Replay Memory
- First, a local replay memory stores each actor’s experience locally on that actor’s machine.
- Second, a global replay memory aggregates the experience into a distributed database.
- Learner
- Generate gradients and send them to the parameter server.
- Receive the the parameters of the Q-network periodically from the parameter server.
- Parameter server - Applies these gradients to modify the parameters, using an asynchronous stochastic gradient descent algorithm.
Bundled mode. The simplest overall instantiation of Gorila, in which there is a one-to-one correspondence between actors, replay memory, and learners. The only communication between bundles is via parameters: the learners communicate their gradients to the parameter server; and the Q-networks in the actors and learners are periodically synchronized to the parameter server.
Gorila DQN. The DQN algorithm is extended to the distributed implementation in Gorila as follows. The parameter server maintains the current parameters θ + theta+ θ+ and the actors and learners contain replicas of the current Q-network Q ( s , a ; θ ) Q(s, a; theta) Q(s,a;θ) that are synchronized from the parameter server before every acting step. The learner additionally maintains the target Q-network Q ( s , a ; θ − ) Q(s, a; theta−) Q(s,a;θ−). The learner’s target network is updated from the parameter server θ + theta+ θ+ after every N N N gradient updates in the central parameter server.
Stability. While the DQN training algorithm was designed to ensure stability of training neural networks with reinforcement learning, training using a large cluster of machines running multiple other tasks poses additional challenges. The Gorila DQN implementation uses additional safeguards to ensure stability in the presence of disappearing nodes, slowdowns in network traffic, and slowdowns of individual machines. One such safeguard is a parameter that determines the maximum time delay between the local parameters and the parameters in the parameter server. All gradients older than the threshold are discarded by the parameter server. Additionally, each actor/learner keeps a running average and standard deviation of the absolute DQN loss for the data it sees and discards gradients with absolute loss higher than the mean plus several standard deviations. Finally, we used the AdaGrad update rule.
Experiments
We evaluated Gorila by conducting experiments on 49 Atari 2600 games using the Arcade Learning Environment.
In all experiments, Gorila DQN used: N p a r a m = 31 N_{param} = 31 Nparam=31 and N l e a r n = N a c t = 100 N_{learn} = N_{act} = 100 Nlearn=Nact=100. We use the bundled mode. Replay memory size D D D = 1 million frames and used ϵ epsilon ϵ-greedy as the behaviour policy with ϵ epsilon ϵ annealed from 1 to 0.1 over the first one million global updates. Each learner syncs the parameters θ − theta− θ− of its target network after every 60K parameter updates performed in the parameter server.
最后
以上就是直率大象最近收集整理的关于[ICML 2015] Massively Parallel Methods for Deep Reinforcement LearningIntroductionDistributed ArchitectureExperiments的全部内容,更多相关[ICML内容请搜索靠谱客的其他文章。




![[ICML 2015] Massively Parallel Methods for Deep Reinforcement LearningIntroductionDistributed ArchitectureExperiments](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)



发表评论 取消回复