
1. 绪论
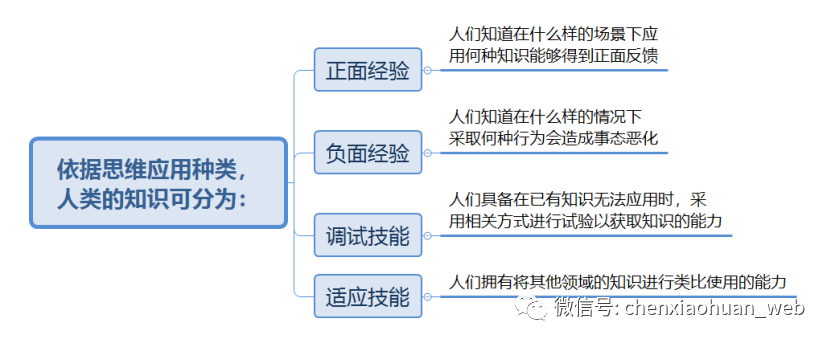
机器若要帮助人类摆脱繁杂的无价值事务,前提条件之一就是理解人类的意图。语言是人类最重要的信息传达方式,所以机器理解人类语言的能力就显得极为重要了。人机对话作为这个方向下的具体落地业务,必然将在人工智能发展周期中扮演极为重要的角色。
当下正在发生的人工智能技术革命正尝试迈出消除人机理解障碍的关键一步:致力于将人机交互方式发展为与人人交互相同的以视觉加自然语言为主的方式。这一步将使得人机交互发生由人服从机器到机器服从人的变化。其主要难度在于,过去人们在使用程序设计语言时,所有表达方式都需要服从机器的要求,程序设计语言是一种有限集;而人类自身语言的抽象性极高,任何一种意图的可行表述方式都接近于无限,想要做到使机器服从人,就需要完成从语言的有限集到无限集的推演过程。
依照马斯洛人类需求层次理论的描述,人类需求由低到高分为五层,分别为生理需求、安全需求、社交需求、尊重需求和自我实现需求。互联网和移动互联网技术的发展并没有创造新需求,只是既有需求有了新的解决方案而已,需求可以被激活,但并不能被凭空创造。人工智能技术也是这样的,它不会创造新的需求,但却有潜力改变相当大比例人类需求的现有解决方案。
2. 产品经理与系统设计
2.1 产品经理与技术

不论是用户型、商业型还是平台型产品经理,都需要经历一个将抽象转换为具体的过程,用户型产品经理从用户行为中抽象用户需求,商业型产品经理从客户诉求中抽象客户需求,平台型产品经理从用户需求和客户需求中二次抽象出平台化解决方案所需要求解的问题。技术人员最终得到的是由产品经理给出的具体而明确的需要求解的问题。

产品经理提出问题的质量决定了产品的质量,产品经理看得多远、多深,决定了产品未来的发展有多远。提出问题的质量通常可以从两个角度来衡量:深度与全面性。
2.2 系统设计的基本问题
1)为解决当下业务需求所属的一类通用问题,都需要哪些模块的协同工作?在这些模块中,哪些模块是现有系统中已经存在的,哪些模块是需要新增的?
2)业务需求的解决所涉及的每个模块,其定位或单一职责是什么?它们在系统中扮演什么样的角色、起到什么样的作用?已有模块的职责是否满足业务的要求、新模块的职责定义是否清晰明确?是否存在同一个模块承担多个职责,导致相互耦合的情况?
3)每个模块的输入和输出分别是什么?每个模块是否得到了使其足以完成其职责的信息输入,既不存在信息缺失,也不存在会导致耦合的信息冗余?
4)系统整体的模块调用顺序是什么?是否拥有合理的信息通路?模块间的上下位关系是否明确?是否保证了模块上下位关系的一致性?是否存在下位模块僭越上位模块进行跨层级调用的情况?
5)整个系统的行为及输出信息是否稳定并符合业务需求?
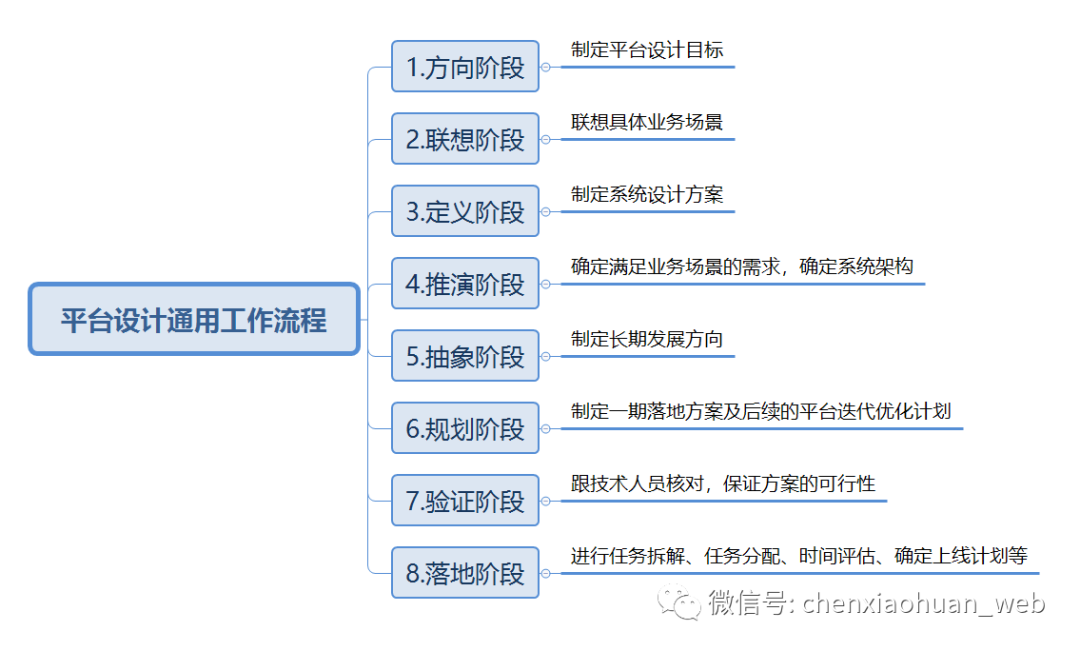
2.3 平台设计通用工作流程
3. 人工智能技术
3.1 机器学习
Arthur Samuel曾非正式地定义过,机器学习是在不直接针对问题进行编程的情况下,赋予计算机学习能力的一个研究领域。
在传统算法设计中,由人来分析问题得到模型,并将模型编码输入机器,机器只负责根据人编写好的算法模型将输入转换为输出;而在机器学习算法中,人并不直接编写处理问题的算法模型,而是把利用数据进行学习的方法教给机器,机器自己根据输入与输出的对应关系抽象出问题处理模型。
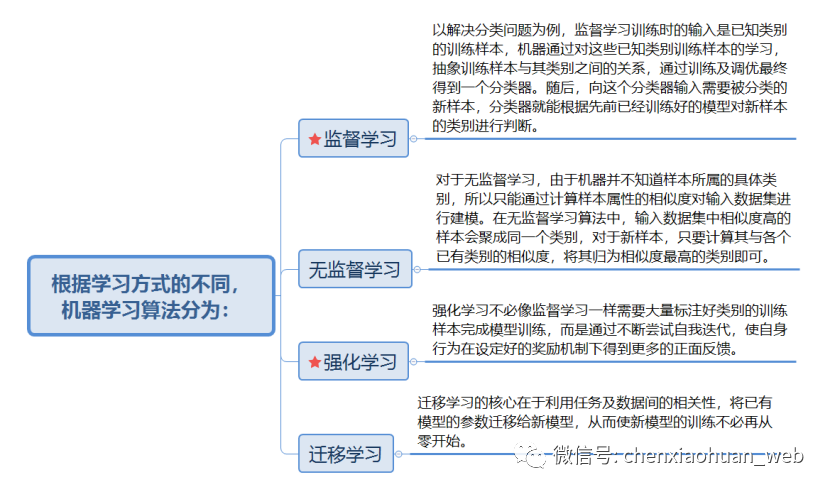
监督学习和强化学习是目前应用范围最广且效果最好的机器学习方式。监督学习和强化学习的主要区别在于,监督学习需要标注好类别的训练样本,而强化学习需要能判断行为好坏的奖励机制。
监督学习的优点在于见效快,适用于有大量已标注训练样本的业务场景,能够快速得到一个表现出色的模型。而强化学习的优点在于成本低、通用性强,奖励机制的设计成本通常比训练样本的标注成本低,且同一个奖励机制还可能适用于多类问题,而监督学习通过学习训练样本所得到模型通常只能处理一类问题。另外,与监督学习的模仿比起来,强化学习更容易创新,创造出之前从未有过的问题解决方法。
1)k-近邻(kNN)算法(监督学习)
kNN算法要求输入标注好类别的训练样本集,且每个训练样本都由若干个用于分类的特征来表示。随后,使用一个维数与训练样本特征数相同的坐标系来表示各个训练样本,每一维代表一个特征,训练样本在这个坐标系下被映射成一个个点。映射结束后,便得到了一个坐标系及该坐标系表示下的所有训练样本点。
当需要对新样本进行分类时,同样将其映射到该坐标系中,然后计算新样本所对应的坐标点与其他所有训练样本点的欧氏距离(由两点间距离计算公式得到),找到距其欧氏距离最短的k个训练样本点,并将k个训练样本中占比最大的类别定为这个新样本点所属的类别。
kNN的缺点是计算的时间和空间复杂度都太高,内存中需要存储所有训练样本点,而且每需要对一个新样本进行分类,就需要计算一遍这个新样本点到所有训练样本点的欧氏距离。
2)ID3决策树算法(监督学习)
ID3决策树算法要求输入标注好类别的训练样本集,每个训练样本由若干个用于分类的特征来表示。决策树算法的训练目的在于构建决策树,希望能够得到一棵可以将训练样本按其类别进行划分的决策树。
决策树算法经过训练构建出决策树之后,就不再需要将训练样本保留在内存中了,这颗决策树就是根据训练样本所抽象出来的分类模型
3)朴素贝叶斯分类算法(监督学习)
朴素贝叶斯分类算法中的“朴素”一词源于这样一个假设:在文档中,每个单词(特征)出现的可能性是完全独立的,与其他单词是否出现、出现在哪无关。同时,朴素贝叶斯分类算法还假定每个单词(特征)对判定文档类别同等重要。
朴素贝叶斯分类算法的核心是贝叶斯公式:p(c|x) = p(x|c) * p(c) / p(x)
式子中的c、x分别指某个事件;p(c)、p(x)被称作边缘概率,分别指事件c与事件x的发生概率;p(x|c)、p(c|x)被称作条件概率,分别指事件c发生的前提下事件x发生的概率和事件x发生的前提下事件c发生的概率。
kNN及ID3决策树算法属于判别方法,其模型属于判别模型,而朴素贝叶斯分类算法属于生成方法,其模型属于生成模型。判别模型和生成模型的本质区别在于模型输入和输出的决定关系,判别模型假定输入决定输出,而生成模型假定输出决定输入。
4)逻辑回归算法(监督学习)
逻辑回归属于监督学习下的一种二分类算法,同时属于判别方法,只能处理线性可分问题。其核心是一个线性函数模型,用其判断新样本是否属于某个类别时,需要将这个样本的特征值代入线性函数模型中,并将该模型的输出结果代入到一个名为Sigmoid的阶跃函数中。
由于Sigmoid函数不论输入值如何,其输出都在0~1之间,所以在逻辑回归算法中,取Sigmoid函数输出值大于0.5的为一类,输出值小于0.5的为另一类。
5)支持向量机(SVM)(监督学习)
支持向量机是一种监督学习下的二分类算法,同时属于判别方法,只能处理线性可分问题。其核心任务是构建一个N-1维的分隔超平面来实现对N维样本数据的划分,认定的分隔超平面两侧的样本点分属两个不同类别。
支持向量机在对样本进行分类时,不必再保留所有的训练样本,而是只保留有限的几个支持向量,大大减少了内存的占用,但效果却没有变差。
6)Ada Boost元算法
Ada Boost是一种元算法,通过组合多个弱分类器来构建一个强分类器。单一的分类算法各有优缺点,可以采用元算法(Meta Algorithm)或叫作集成方法(Ensemble Method)的方式集成不同算法、同一个算法的不同设置或不同数据集上训练过的算法等来尝试获得更好的表现。
7)线性回归及树回归算法
最小二乘法是最简单的线性回归算法。假定二维平面中存在一些样本点,最小二乘法希望能够画出一条直线,根据直线的方程(回归方程)能够以较小的误差预测样本点所在的位置。
最小二乘法这种纯粹的线性回归方式可能会欠拟合,即出现拟合程度不够的现象。局部加权线性回归(Locally Weighted Linear Regression,LWLR)可以在一定程度上解决这个问题。
树回归的思想在于,有些数据集较为复杂,并不能建立全局的回归方程,所以树回归希望结合树的思想,先将数据集进行分类,将数据集分成很多份易建模回归的数据,再采用其他回归方法求得回归方程。
8)K均值聚类算法(无监督学习)
假定存在一些需要被聚类的样本点,应用K均值聚类算法,首先随机选择k个点作为初始质心,计算所有样本点到每个质心的距离,找到每个样本点距其最近的质心,然后将该样本点分配给该质心所对应的簇。随后,将每个簇的质心更新为该簇中所有样本点坐标的均值,并根据新的质心重新划分样本点所在的簇。如此不断迭代,直到所有样本点所属的簇都不再改变,算法收敛,最终将样本点划分为k个类别。
聚类效果可以采用误差平方和来度量:计算每个簇中的点到其质心距离的平方和,平方和越大说明点距其质心越远、聚类效果越差;反之亦然。
K均值聚类算法可以与TF-IDF算法结合进行简单的文本分类。TF-IDF(Term Frequency-Inverse Document Frequency)是度量一个词对所处文档重要程度的算法。TF指词频,IDF指逆文档频率,TF-IDF算法采用TF值与IDF值相乘后的结果代指一个词对所处文档的重要程度。
9)Apriori及FP-growth算法
Apriori是一种进行元素项关联分析的算法,关联分析包括发现频繁项集和关联规则。频繁项集是经常出现在一起的元素的集合,关联规则暗示了两种元素之间的相关关系,且这种相关关系具有方向性。
FP-growth算法通常被专门用来发现频繁项集,其速度要快于Apriori算法,常被用于输入联想功能中。
由于Apriori算法对于每个潜在的频繁项集都需要扫描一遍数据集来判定其支持度是否达到阈值,所以在处理大量数据时效率并不高。而FP-growth算法仅扫描数据集两次就可以挖掘出频繁项集,其性能通常要比Apriori算法好两个数量级以上。
FP-growth算法的基本思想是:首先,扫描一遍数据集并构建一棵FP树,FP树是一种极为紧凑的数据结构,它对原始数据集进行了压缩,但仍然存储着查找频繁项集所需要的全部信息;然后,进行第二次扫描,利用FP树这个数据结构,挖掘出原数据集中包含的所有频繁项集。
10)PCA与SVD
PCA(Principal Component Analysis,主成分分析)是一种将原始数据进行降维处理的统计方法。它可以将N维原始数据降维到最能代表数据集真实结构的K个正交维度上。
SVD(Singular Value Decomposition,奇异值分解)同样是一种数据降维与压缩方法,它可以从原始噪声数据中抽取核心特征。其核心原理是:任意一个矩阵都可以被拆分为一个正交矩阵、一个对角矩阵和一个正交矩阵的乘积。其中,对角矩阵就是原矩阵的奇异值矩阵。
SVD的应用非常广,比如在自然语言处理中,SVD可以抽取文档和词的“概念”,即可以识别拥有同一个主题的文章,以及语义相近的同义词。另外,SVD还可以被用在推荐系统中。
11)主题模型LDA
LDA(Latent Dirichlet Allocation)模型由LSA、p LSA这两类主题模型演化而来。LDA模型构建的基本思想是:一篇文档中的每个词,都是以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词得到的。
LDA模型的训练是通过期望最大化算法(Expectation Maximization Algorithm, EM算法)实现的,利用训练语料,最终使得LDA模型收敛到一个合理的分布上。
LDA在个性化推荐、社交网络、广告预测等各个领域的应用都非常广泛。
3.2 深度学习
机器学习的本质在于寻找最优模型,深度学习是机器学习的一个重要分支,深度学习的概念起源于对人工神经网络的研究,其基本学习模型是深度神经网络。
深度学习与传统机器学习的一个重要区别就在于原始数据可以被直接作为深度神经网络模型的输入,也就不再需要预先利用人类的各领域知识对原始数据进行抽象来提供样本的关键特征。
1)感知机模型与前馈神经网络
感知机抽象于生物神经细胞,神经细胞大致可分为四部分:细胞体、树突、轴突和突触。单个神经细胞可被视为一种有且仅有两种状态的机器,兴奋时为“是”,安静时为“否”。神经细胞的状态取决于这个细胞从其他神经细胞处所收到的输入信号量及突触的强度(抑制或加强)。当信号量总和超过了某个阈值后,神经细胞兴奋,产生电脉冲,电脉冲会沿着轴突,并通过轴突—树突—突触传递到其他神经细胞。为了模拟神经细胞的行为,感知机模型被提出了,其中的权重概念对应突触、偏置概念对应阈值、激活函数对应细胞体。
感知机模型只能处理线性可分问题,无法处理异或关系,而多层神经网络解决了这个问题。
前馈神经网络是最简单的一类神经网络,多层感知机网络属于其中的一种。前馈神经网络通常包含输入层、隐层和输出层。网络第一层为输入层,最后一层为输出层,中间为隐层。隐层可以是一层,也可以是多层。各神经元之间分层排列,每一层包含若干个神经元,同一层的神经元之间无连接。每个神经元只与上一层的神经元相连,接收上一层的输出,并输出给下一层,参数由输入层向输出层单向传播。
反向传播算法(Back Propagation Algorithm,也称作BP算法)通常被用来进行多层神经网络模型的学习,采用了反向传播算法训练的前馈神经网络也被称作BP神经网络。
2)深度神经网络(DNN)
深度神经网络(Deep Neural Networks,DNN)可以简单地理解为拥有多隐层的感知机模型,其基本结构并不复杂,但为了在具体任务中取得优异成果,通常需要从两个角度进行考虑:一是使神经网络在训练集上具备良好的表现,二是使其能在测试集中拥有与在训练集中同样良好的表现。
为了优化神经网络在训练集中的表现,通常可以从损失函数、训练方法、激活函数、学习速率、突破局部最优等多个方向进行尝试。
3)卷积神经网络(CNN)
神经认知机将一个视觉模式分解为若干子特征,然后进入分层递阶相连的特征平面进行处理,即使物体有轻微变形或位移,也能保证识别的正确性。
卷积神经网络由卷积层(Convolutions Layer)、池化层(Pooling Layer)和全连接层构成。全连接层通常作为网络的最后几层,其中的每个神经元都与上层中的所有神经元相连,所以称之为全连接层。全连接层之前是若干对卷积层与池化层,卷积层与池化层一一对应,且卷积层在前,池化层在后。本质上,对于卷积神经网络而言,卷积层和池化层所起的作用是将原始数据中的特征进行抽象,而最后的全连接层则利用这些抽象出的特征对样本数据进行分类,并为样本打上标签。
4)递归神经网络(RNN)与LSTM
递归神经网络是两种人工神经网络的总称,一种是时间递归神经网络(Recurrent Neural Network),另一种是结构递归神经网络(Recursive Neural Network)。目前所说的递归神经网络(RNN)通常指时间递归神经网络。
相较于普通前馈神经网络,递归神经网络的优势在于对序列数据的处理。
由于单纯的递归神经网络无法处理由于不断递归所导致的梯度消失问题,也难以捕捉更长时间的时间关联,所以有人提出了一种更加优秀的递归神经网络结构即长短期记忆(Long-Short Term Memory,LSTM)神经网络来解决这个问题。
LSTM的神经元由四部分组成,分别是输入门、输出门、遗忘门和记忆细胞。每个神经元接收四种输入,提供一种输出。输入门、输出门、遗忘门各接收一种控制信号输入,输入门额外接收上一个神经元的输入,输出门额外给出到下一个神经元的输出。
3.3 自然语言处理
美国计算机学家Bill Manaris曾经给出过定义:自然语言处理是研究人与人交际中及人与计算机交际中的语言问题的一门学科。自然语言处理要研制表示语言能力和语言应用的模型,建立计算框架来实现这样的语言模型,提出相应的方法来不断完善这样的语言模型,根据这样的语言模型设计各种实用系统,并探讨这些实用系统的评测技术。
1)熵
熵H(X),又称自信息,被用来描述一个随机变量不确定性的大小。熵越大,不确定性/混乱程度越大;反之亦然。不确定性越大的随机变量,就需要越多的信息量来消除这种不确定性。
2)形式语言
文法是形式语言中一个极为重要的概念。文法由四部分组成,分别为开始符号、终结符号、非终结符号与产生式规则。开始符号必然是非终结符号,终结符号与非终结符号之间不存在交集,产生式规则左侧必然包含非终结符号。
文法可以被用来产生语言。在乔姆斯基的文法理论中,包含四类文法:3型文法(正则文法,RG)、2型文法(上下文无关文法,CFG)、1型文法(上下文相关文法,CSG)和0型文法(短语结构文法,PSG)。
3)语言模型
语言模型(Language Model,LM)广泛应用于基于统计模型的语音识别、机器翻译、分词及句法分析中,N元文法模型(N-gram Model)是一种经典的语言模型。
一元文法模型(Unigram)意味着,出现在第k个位置的词独立于历史而存在。朴素贝叶斯算法中的朴素性假设本质上就是一种一元文法模型。
二元文法模型(Bigram)是指,出现在第k个位置的词只与它前面最近的一个历史词有关,独立于更早的历史词。二元文法模型又被称作一阶马尔可夫模型。
三元文法模型被称作二阶马尔可夫模型,记作Trigram。
用于构建语言模型的文本被称作训练语料(Training Corpus)。训练语料的规模通常在上百万个词以上。
4)马尔科夫模型(MM)
如果一个系统中包含n个有限状态,随着时间推移,该系统将随机从某一个状态转换到另一个状态。如果在特殊条件下,系统在t时刻的状态只与在t-1时刻的状态i相关,则该系统构成了一个一阶马尔可夫链(Markov Chain,MC)。同理,如果t时刻的状态与之前n个时刻的状态均相关,则该系统就构成了一个n阶马尔可夫链。另外,如果上文中描述的随机过程独立于时刻t,则该随机过程可被称为马尔可夫模型(Markov Model,MM)。
5)隐马尔科夫模型(HMM)
隐马尔可夫模型(Hidden Markov Model,HMM)被广泛应用在语音识别、词性标注、音字转换、概率文法等各个自然语言处理领域,是应用最广泛的概率图模型(Probabilistic Graphical Model,PGM)之一,也是一种经典的生成模型。
隐马尔可夫模型可被用来解决三类基本问题:
(1)估计问题:给定一个观察序列和隐马尔可夫模型,可快速地计算出这个观察序列由给定模型输出的概率;
(2)解码问题:给定一个观察序列和隐马尔可夫模型,求解最优状态序列,使得该状态序列能够最好地解释观察序列;
(3)训练问题:只给定一个观察序列,可求解使这个观察序列输出概率最大的隐马尔可夫模型。
6)最大熵模型(MEM)
最大熵模型(Maximum-Entropy Model)的思想是:在只掌握关于未知分布的部分信息的前提下,契合已知信息的概率分布可能会有多个,其中使熵值最大的概率分布真实反映了事件的分布情况。最大熵模型的构建属于判别方法,其目的就是构建一个符合已知条件且熵最大的概率判别模型。
7)最大熵马尔科夫模型(MEMM)与条件随机场(CRF)
最大熵马尔可夫模型(Maximum-Entropy Markov Model,MEMM)又称条件马尔可夫模型(Conditional Markov Model,CMM),它同时结合了隐马尔可夫模型和最大熵模型的特点。
最大熵马尔可夫模型认为某个时刻的系统状态同时取决于前一个状态与当前时刻的输出符号,并利用最大熵模型来学习这个条件概率。相较于隐马尔可夫模型,最大熵马尔可夫模型有能力描述观察符号之间的关联关系。
条件随机场(Conditional Random Field,CRF)在最大熵马尔可夫模型舍弃输出独立性假设的基础上,一并舍弃了有限历史性假设。
条件随机场不再像隐马尔可夫模型那样,在输出独立性假设和有限历史性假设的基础上对各类条件概率进行建模,而是整体地去做函数拟合,采用期望最大化的方法得到拟合程度最高的判别模型。条件随机场有能力描述更复杂的系统状态关联关系,也被广泛用于处理序列标注问题。
8)词法分析
自动分词、命名实体识别(Named Entity Recognition,NER,指识别文本中具有特定意义的实体)与词性标注是汉语词法分析中所面临的三个基本问题。
9)句法分析
句法分析的主要目的是明确句子的语法结构或词之间的依存关系。
句法分析的任务通常有三个:(1)判断句子是否属于某种语言;(2)消除句子中词法及结构等方面的歧义;(3)分析句子的内部结构,如成分构成、上下文关系等,生成句法分析树。
10)语义分析
对于不同语言单位,语义分析的主要任务也各不相同。在词层次上,语义分析的主要任务是进行词义消歧;在句层次上,语义分析的主要任务是语义角色标注;而在文档层次上,语义分析的主要任务是共指消解,又称指代消歧。
4. 智能交互技术
4.1 智能搜索
第一代搜索引擎一般基于文本信息检索模型,比如布尔模型、向量空间模型和概率模型等,能够检索出那些包含用户问句查询词的文档,并根据关键词匹配程度做初步排序后展示给用户。
第二代搜索引擎充分利用了网页之间的链接关系,具有代表性的是Google公司的Page Rank链接分析算法。这一代搜索引擎可以同时结合内容相关性与网页流行性来为用户提供搜索结果。
第三代搜索引擎尝试在搜索中引入用户信息,比如根据用户过往的行为偏好和当前所在的位置等信息,给用户提供与当前场景更加相关的搜索结果。
现代搜索引擎面临着两个新的挑战:一个是更好地建模搜索结果与用户需求的语义相关性,而不只是简单的关键词搜索;另一个是更直截了当地回答用户问题,而不是给出一堆相关文档或网页的集合,同时具备一定的推理能力。可利用DNN优化搜索结果,利用CNN计算语义相关性,利用RNN构建语言模型。
知识推理是智能搜索技术发展的另一个重要方向,将知识引入搜索中,可以结合推理能力,更直接地回答用户的问题,而不是给出一堆文档/网页的集合,让用户自己做筛选。甚至进一步提供与用户查询实体相关的其他内容,比如一些基本属性及与其他实体的关系,并以知识卡片的形式展示出来。
实现知识推理的基础是知识图谱。相对于传统数据库而言,知识图谱是一种结构化的语义知识库,它以符号形式描述真实世界中的概念及其相互关系,也是真正智能化语义检索的基础和桥梁。
知识图谱的逻辑结构分为两个层次:数据层和模式层。数据层一般存在两种三元组作为事实的基本表达方式:“实体—关系—实体”和“实体—属性—值”。而模式层通常采用本体库来管理,存储的是提炼后的知识,本体库相当于知识的模具。
知识图谱的构建通常分为三个步骤:信息抽取、知识融合和知识加工。
信息抽取涉及的关键技术包含命名实体识别、关系抽取、属性抽取,分别与数据层中的实体、关系、属性相对应。
知识融合负责对数据进行清理和整合,主要包括实体链接和知识合并。实体链接所涉及的主要技术为共指消解和实体消歧。知识合并主要指从第三方知识库产品或已有结构化数据库中获取知识。
知识加工主要负责构建模式层的本体库,主要包括本体构建、知识推理和质量评估。
除知识图谱外,类似文本自动摘要、情感分析这样的自然语言处理技术同样有助于提高搜索质量。
4.2 对话交互
就目前而言,对话交互/人机对话所解决的典型问题的类型有三种,分别为任务型(Task)、问答型(QA)和闲聊型(Chat)。
任务型的主要目的是依照用户意图收集必要信息以协助用户完成任务或操作;问答型的主要目的是检索并提供给用户所需的信息;而闲聊型的主要目的是满足用户的情感需求,在产品设计中客观上能够起到拉近距离、建立信任关系和提高用户黏性的作用。
从产品角度看,对话系统执行任务的过程其实可以大致分为三个阶段:理解阶段、思考阶段和执行阶段。理解阶段,即理解人类的需求,常用技术有语音识别、图像识别、自然语言理解等。思考阶段,即寻找需求的解决方案,常用技术有搜索引擎、推荐系统、知识图谱等。执行阶段,即完成人类的需求,常用的技术有自然语言生成、智能家居/物联网和目前被用来满足需求的其他技术。
4.3 问答匹配技术的发展
问答匹配的核心任务是找到库中与用户当前问句语义最相关的标准问句。问答匹配技术经历了由基于规则到基于统计的方法,再到深度学习方法的发展,被广泛应用于智能客服等简单问答型人机对话问题的解决中。
5. Bot Framework设计探究
5.1 对话系统的组成
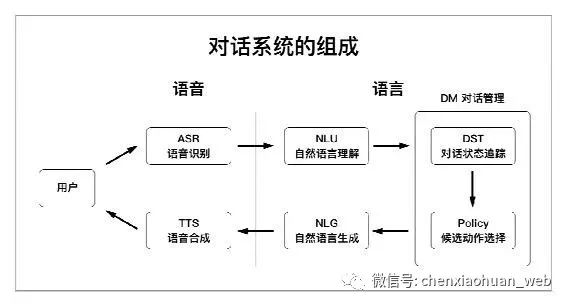
1)语音识别(ASR):将原始的语音信号转换成文本信息;
2)自然语言理解(NLU):将识别出来的文本信息转换成机器可以理解的语义表示;
3)对话管理(DM):根据NLU模块输出的语义表示执行对话状态的更新和追踪,并根据一定策略选择相应的候选动作;
4)自然语言生成(NLG):负责生成需要回复给用户的自然语言文本;
5)语音合成(TTS):将自然语言文本转换成语音输出给用户。
5.2 对话交互框架
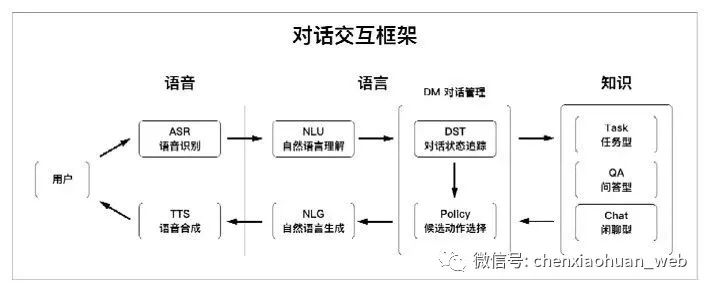
对话任务的完成离不开知识,不论是任务型中的意图及参数、问答型中的知识库,还是闲聊型中的语料都属于知识。
自然语言理解(NLU)的作用在于将识别到的文本信息转换成机器可以理解的语义表示,而语义表示主要有三种方式:1)分布语义(Distributional Semantics);2)框架语义(Frame Semantics);3)模型论语义(Model-theoretic Semantics)。
5.3 国内外开放的Bot Framework
1)Dialogflow
Dialogflow是一个基于自然语言对话的人机交互开发平台,它的前身是Api.ai, Api.ai于2016年9月被Google公司收购,后更名为Dialogflow。
2)wit.ai
wit.ai是Facebook公司的用于将自然语言转换为可处理指令的API平台,其目的是为了帮助开发者便捷地打造类似Siri语音对话应用或设备。
3)Alexa Skills Kit
Alexa技能工具包(ASK)是一套自助服务的API、工具、文档和代码示例,使开发者能够快速、轻松地为Alexa添加技能。
4)Luis.ai
Luis.ai是微软公司推出的基于机器学习的服务平台,其目的是为了将自然语言嵌入到应用程序、机器人和物联网设备中。
5)Chat Flow
Chat Flow是KITT.AI公司推出的一个致力于提供对话理解服务的平台。KITT.AI公司于2017年7月被百度公司收购。
6)Duer OS开放平台
Duer OS开放平台是百度公司推出的、为企业及开发者提供一整套对话式人工智能解决方案的开放平台。
7)UNIT
百度公司推出的UNIT(Understandingand Interaction Technology),即理解与交互技术,是建立在百度公司多年积累的自然语言处理与对话技术及大数据的基础上,面向第三方开发者提供的对话系统开发平台。
8)云小蜜
阿里巴巴公司于2017年10月在云栖大会上推出的云小蜜是一款面向开发者的会话机器人,支持在不同的消息端实现基于自然语言处理(NLP)的智能会话,如网站、App及实体机器人等。
9)Dui.ai
Dui.ai是思必驰公司推出的全链路智能对话开放平台。
5.4 Bot Framework的组成
在主流Bot Framework的设计中,最重要的组成部分有三个,分别是意图(Intent)、实体(Entity)和训练(Training)。
意图表示用户希望执行的任务或操作,它是用户在输入中所表达的目的或目标。意图部分包含以下主要组成模块:语境(Contexts)、用户表述(Usersays)、动作/澄清(Action)和回应(Response)。
实体是进行参数抽取的基础,约定了参数的取值范围。除一些特殊实体外,绝大多数实体都以词集的形式存在。对实体的管理很大程度上等同于对词的管理。
Bot Framework中模型训练的主要目的是持续提高意图识别、排序及参数识别的准确率。正确地识别框架(Frame)及参数(Argument),是得到用户问句合理框架语义表示的前提。训练部分的核心模块有两个:在线服务模块和离线标注模块。
最后
以上就是老迟到烧鹅最近收集整理的关于人工智能产品经理:人机对话系统设计逻辑探究(笔记)的全部内容,更多相关人工智能产品经理内容请搜索靠谱客的其他文章。








发表评论 取消回复