多喝热水
问题背景
这篇讲一下最近的一个工作场景,需要统计用户登录时长,两个指标:每日平均单次登录时长、每日平均用户登录时长。 有的数据字段长下面这样子(这边不考虑根据不同app版本分类啊之类的 实际也做不了因为大部分是空的orz 有把一些干扰字段也列出来了):
| 字段名 | 解释 |
|---|---|
| id | 事件记录id |
| userid | 用户id |
| ip | 设备ip |
| triggertime | 事件触发时间戳 |
| tiggertimestr | 事件触发时间(yyyy-mm-dd) |
| createtime | 记录创建时间戳 |
| eventtype | 事件类型1,2,3,4 |
| eventname | 事件名称 对应上面类型 启动app、关闭app、打开服务、关闭服务 |
在实际场景中,有以下几个问题:
- 当用户打开app时是未登录状态的话,这条记录的userid为空
- 有userid的记录不一定有ip, 没userid的也不一定有,就很难顶
- 能有一个完整开启关闭记录的情况只有两种行动路径:
- 启动App->退回到首页->关闭App
- 启动App->打开服务->关闭服务->退回到首页->关闭App
也就是说,我们拿到的数据集大概是11112122111222这样子,而我们要从其中找出12组合
- 数据源出现同一用户同一行为同一事件触发时间但是有多条记录的情况(除了createtime以外其他都一毛一样的重复数据)
数据预处理
PART1:思路
- 先将数据源表提取出eventtype=1或2的数据,根据userid进行分区,对triggertime进行排序处理。这边只关注有userid的记录。
- 假设分区中每一条记录的下一条与这一条能够形成闭环,即假设这两条记录能刚好形成12组合。
PART2 代码
create table if not exists t1 as
select userid,
triggertimestr as start_time_str,
triggertime as start_time,
lead(triggertime) over(partition by userid order by triggertime) as end_time,
eventtype as start_type,
lead(eventtype) over(partition by userid order by triggertime) as end_type
from table_a
where (eventtype = '1'
or eventtype = '2')
order by userid, triggertime;
这边利用到函数lead(key, n),它输出key(要展示的字段)根据一定的规则处理后该条记录下的第n条记录,默认n=1。在该代码示例中,解释为根据userid分区且分区中根据triggertime进行上升排序,选取该条记录的下一条的trigggertime作为新字段对应的值。
输出示例如下(可以无视那个detail_time没有用的哈只是想看一下是哪个时间点的
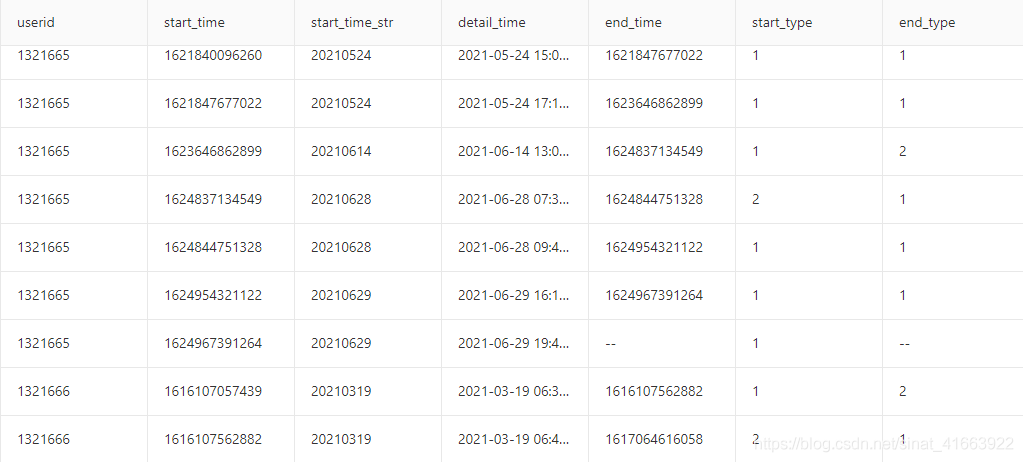
计算结果
PART1:代码
-- avg_single_duration平均每日单次登录时长
-- avg_user_duration 平均每日用户登录时长
select start_time_str, sum(duration)/count(1)/1000 as avg_single_duration,
sum(duration)/count(distinct(userid))/1000 as avg_user_duration
from
(select *, end_time-start_time as duration
from t1
where start_type = '1'
and end_type = '2') t2
where duration <= 7200000
group by start_time_str
order by start_time_str;
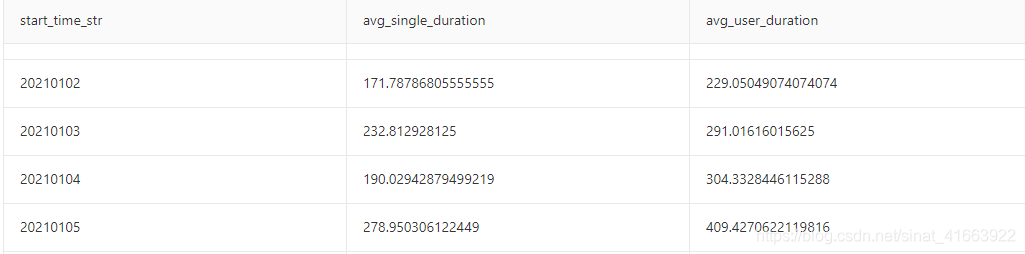
PART2: 注意
虽然这一步很简单,只要选取我们假设的闭环记录中起始事件=1和结束事件=2的记录,再做加减乘除就可以了。另外,会发现在数据集分析中的问题4在这环节也得到了解决。但是,要注意的是,我们的匹配对的时间差可能会出现异常值(一定会出现的其实),在第一轮结果计算中发现,有的日期当日平均单次登录时长竟然达到7天,这是不可能的事情,在这边是假定计算出的登录时长超过2小时的记录我们就将其过滤掉。这个过滤界限可根据app的实际情况,不同性质的app可能不一样。
最后
使用时长是数据分析中一个蛮常见的指标,但具体还要结合实际的业务场景来分析。有的app如sns、游戏、视频,肯定是希望使用时间越长越好了。那像有的app如工具、服务预约这类型的就比较复杂,我们希望用户在使用时不需要太多学习成本,以达成更便捷的效果,又希望用户会多次使用。这时候可能要将次数、日均单次访问时长、日均用户访问时长、留存率、具体功能这些相结合来进行分析。啊就很复杂orz
另外说一点工作半年来的心得吧,不要轻易相信数据商提供的字段值含义,不要直接根据字段名上手写脚本。大部分情况下一些字段会和实际业务有关联,要考虑场景才能更好的进行分析,有的甚至数据源的设计就很有问题,于是沟通成本真的很大哈哈哈哈哈哈哈哈哈哈哈,每天卑微提问(bushi
最后
以上就是大方猎豹最近收集整理的关于Hive SQL 实际场景下计算使用时长的全部内容,更多相关Hive内容请搜索靠谱客的其他文章。








发表评论 取消回复