开源代码: https://github.com/megvii-research/OccDepth
论文链接:https://arxiv.org/abs/2302.13540

一、背景
在 2022 年的 Tesla AI Day 上, Tesla 将 Bev(鸟瞰图) 感知进⼀步升级,提出了基于 Occupancy Network 的感知⽅法。这种基于 Occupancy Grid Mapping 的表示⽅法,⼜叫体素(Voxel)占据,在 3D 重建任务中已经是一个“老熟人”了。它将世界划分成为⼀系列 3D ⽹格单元,然后定义哪个单元被占⽤,哪个单元是空闲的,并且每个占据单元同时也包含分类信息,⽐如路⾯、⻋辆、建筑物、树⽊等。在⾃动驾驶感知中,相⽐普通的 3D 检测⽅法,这种基于体素的表示可以帮助预测更精细的异形物体。如下图 Tesla Demo 中所展示的那样,对于空间感知更精细。
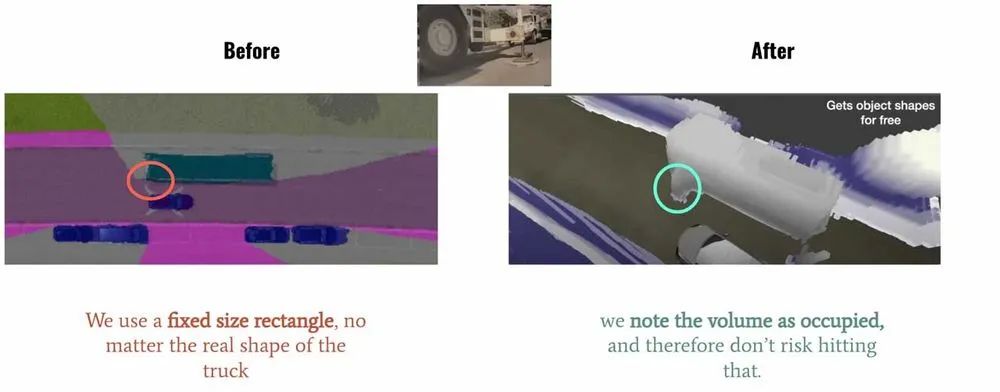
左图:使用固定的矩形框标记车辆;右图:使用体素占据来精细表示车辆
图片出处:https://www.youtube.com/watch?v=jPCV4GKX9Dw
在这种在线重建的⽅法中,⼀般使⽤ SSC ( Semantic Scene Completion)任务评判预测的准确性,即利⽤图像、点云或者其他 3D 数据作为输⼊,预测空间中的体素占据和类别信息,并与 GT 标注相⽐较。在权威的⾃动驾驶 Semantic-Kitti SSC 任务中,可以根据输⼊分成纯图像和基于 3D (点云、 TSDF、体素等)的两类不同的⽅法。使⽤纯图像⽅案恢复 3D 结构是⼀个⽐较困难的问题,旷视研究院提出了 OccDepth 的⽅法,将纯图像输⼊⽅法的精度⼤幅提升,获得了视觉⽅法的 SOTA,其中 SC IOU 从 34.2 增⻓为 45.1, mIOU 从 11.1 增⻓为15.9。同时可视化结果表明 OccDepth 可以更好地重建出近处和远处的⼏何结构。下⾯将带⼤家介绍 OccDepth 具体的⽅法。

二、任务困难和解决动机
仅从视觉图像估计场景中完整的⼏何结构和语义信息,这是⼀项具有挑战性的任务,其中准确的深度信息对于恢复 3D⼏何结构是⾄关重要的。之前的很多⼯作,都是利⽤点云、 RGBD 、TSDF[1]等其他 2.5D 、3D 形式[2-8]作为输⼊,来预测体素占据,这也需要较昂贵的设备来采集 3D 信息。基于纯图像的⽅案更便宜,同时也可以提供更为丰富且稠密场景表示, MonoScene[9]提出了纯视觉的 Baseline。但相较于上述的 3D ⽅法,在⼏何结构恢复⽅⾯,表现有⼀定的差距。
本项工作借鉴了“人类使用双眼能比单眼更好地感知3D世界中的深度信息”的思想,提出了名为 OccDepth 的语义场景补全⽅法。它分别显式和隐式地利⽤图像中含有的深度信息,以帮助恢复良好的 3D ⼏何结构。在 SemanticKITTI 和 NYUv2 等数据集上的⼤量实验表明,与当前基于纯视觉的 SSC ⽅法相⽐,我们提出的 OccDepth ⽅法均达到了 SOTA,在 SemanticKITTI 上整体实现了+4.82% mIoU 的提升,其中+2.49% mIoU 的提升来⾃隐式的深度优化,+2.33% mIoU 提升来⾃于显式的深度蒸馏。 在NYUv2 数据集上,与当前基于纯视觉的 SSC ⽅法相⽐, OccDepth 实现了+4.40% mIoU 的提升。 甚⾄相⽐于所有 2.5D 、3D 的⽅法, OccDepth 仍然实现了 +1.70% mIoU 的提升。
三、具体方法
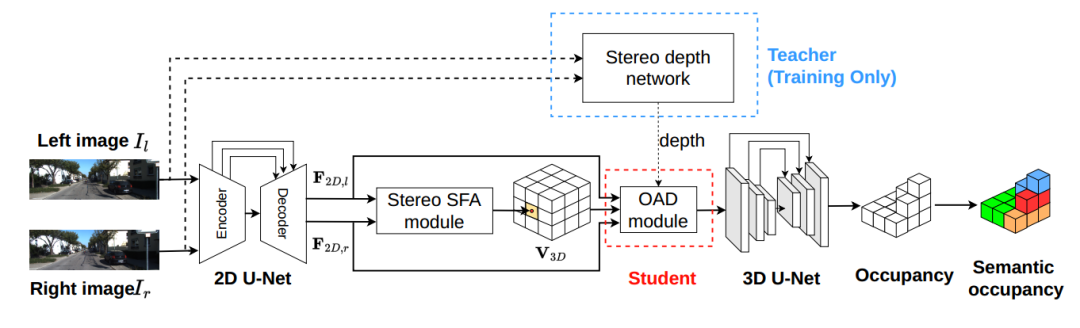
上图是 OccDepth 的主要流程。3D 场景语义补全可以根据输⼊的双⽬图像所推理出来,其中连接了⼀个双⽬特征软融合(Stereo-SFA )模块⽤于隐式地将特征提升到 3D 空间,⼀个占⽤深度感知(OAD) 模块⽤于显式地增强深度预测,后续接上 3D U-Net ⽤于提取⼏何和语义信息。其中双⽬深度⽹络仅在训练的时候使⽤,⽤蒸馏的⽅法帮助 OAD 模块提升深度预测能⼒。
双目特征软融合模块
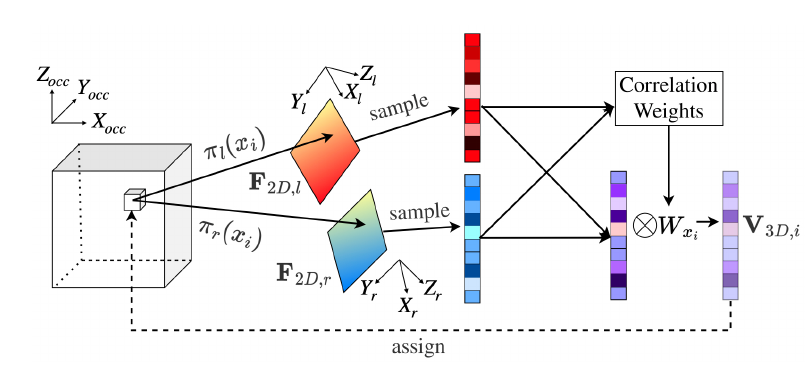
上图显示了 Stereo-SFA 模块的处理过程。为了计算有界 3D 场景中每个体素的特征表示,需要建⽴起 2D 图像特征和 3D 体素特征之间的特征映射。与将 2D 特征反投影到 3D 空间的 LSS[14] 不同,我们选择将每个体素投影到相应图像像素的映射⽅法,后者能够为有界空间内的所有体素建⽴起完整的特征映射。此外,我们通过计算同⼀空间体素对应左右图像上 2D 特征之间的相关性可以隐式地将深度信息编码为 3D 体素特征的权重。这⾥假设双⽬相机已经经过了校准并且输⼊图像经过了去畸变处理,那么双⽬相机的内外参数都是已知的,3D 到 2D 的投影关系也是已知的。对于给定 个体素,他们的中心坐标表示为 ,那么 3D 到 2D 的投影可以表示为 。然后,3D 体素特征 可以从相应的 2D 特征图 中采样获得,表示为: 。之后用 和 分别表示为从左 2D 特征图和右 2D 特征图获取的 3D 特征,那么加权的 3D 特征 可以写为
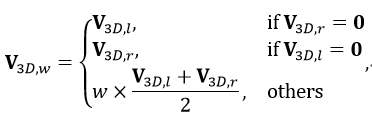
其中 表示根据 和 之间相关性计算得到的权重。在本工作中实际实现的时候采用余弦相似度来衡量特征的相关性。
占用感知的深度蒸馏模块
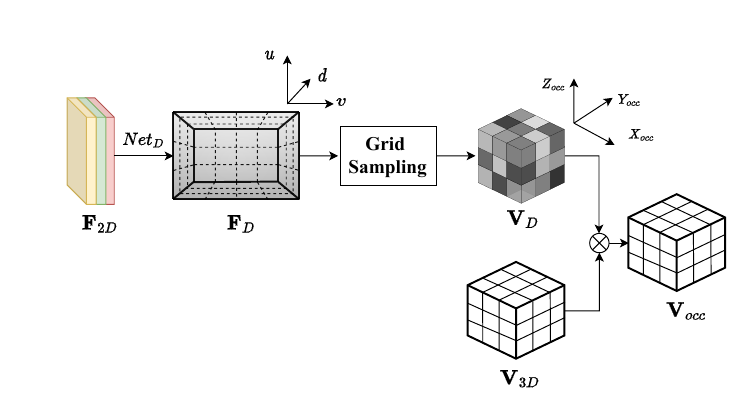
为了在将 2D 图像特征转换为 3D 体素特征时引入空间占用的先验信息,本项工作提出了占用深度感知(OAD)模块,通过预测的深度信息显式地引入到空间占用先验信息。上图为占用感知深度模块的示意图,为了简单起见,图中仅展示了单图像 的处理流程。
受到优秀的 3D 物体检测工作[15-16]的启发,OAD 模块使用预测的深度信息来估计体素特征空间中物体存在的先验概率。然后使用此概率信息来改善体素特征的空间信息。根据上述的 Stereo-SFA 模块可以得到体素空间 中对应的特征图。将具有下采样尺度 的单尺度图像特征 送到 OAD 模块,首先,使用一个深度分布网络 来预测多视图输入图像的深度特征 ;其次,使用 softmax 算子将 变换为截锥体的深度分布 其中 是离散深度块的个数。之后,截锥体深度分布 通过使用相机标定矩阵 和可微网格采样过程被转换为体素空间深度分布表示 最后可以获得占用感知体素特征
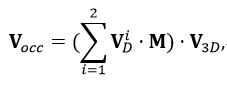
其中 是对双目图像输入之间可视重叠区域的体素像素进行平均的掩码,重叠区域的值为 0.5,其他为 1.0。 可以被理解成体素空间中的先验占用概率。
残差设计
OccDepth 通过优化几何损失函数、语义损失函数、深度损失函数和 MonoScene 中提出的 损失函数进行训练:
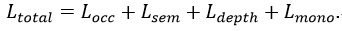
其中 可以帮助更好地提取语义信息, 可以帮助提高语义和几何结构精度的提升,而 则是用于提升模型的补全能力。
四、实验
指标对比
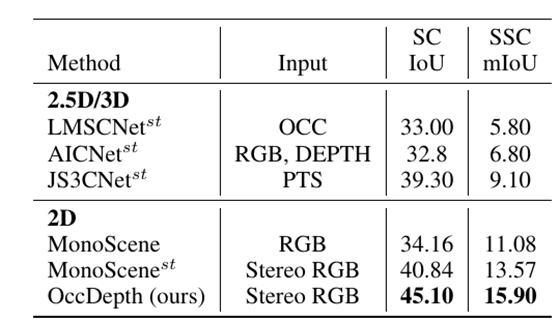
上表是在 SemanticKITTI 数据集的测试集上的表现结果表,所有 2.5D/3D 的方法都修改为基于双目图像推理的版本,并标有上标“st”。双目图像用于为 2.5D/3D 方法生成 occupancy、TSDF、点云和深度图。对于基于单目的 MonoScene,我们从双目输入获取的特征中平均融合成 3D 体素特征,并将其命名为 。在表中,最佳的结果以粗体显示。场景补全的IoU 和语义场景补全的 mIoU 作为指标被用于评价方法的性能。在相同双目输入情况下,本工作提出的 OccDepth 具有最好的结果。
OccDepth 在 SemanticKITTI 数据集的测试集上的测试结果报告在上表中。上表的实验结果表明,在相同双目图像作为输入的情况下,我们的 OccDepth 优于其他方法。与作为 2D 基础方法的 MonoScene 相比,OccDepth 在 SemanticKITTI 上提高了 +4.82 mIoU/+10.94 IoU(表 ref{mainResults0}。同时,在 SemanticKITTI 上, 与 相比,我们的 OccDepth 也取得了相当大的改进([+2.33 mIoU,+4.26 IoU])。这意味着 OccDepth 可以提供比 更精细的几何结构。
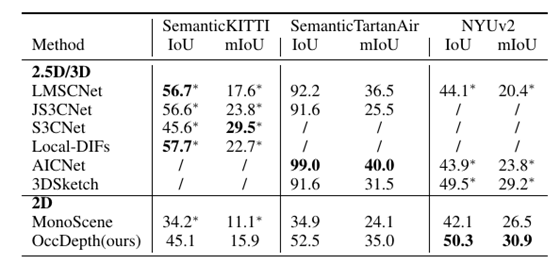
在不同数据集上和 2.5D/3D 数据作为输入的方法的对比表。OccDepth 的结果在一些室内场景上和 2.5D/3D 的方法接近甚至有所超越,在室外场景上和某些 2.5D/3D 方法相媲美。"*" 表示结果引用自 MonoScene。“/”表示缺失结果。
我们还将 OccDepth 与原始 2.5D/3D 作为输入的基础方法进行了比较,结果列在上表中。在 SemanticKITTI 数据集的隐藏测试集中,虽然 OccDepth 只使用水平视野比激光雷达( 82°vs. 180°)小得多的双目图像,但 OccDepth 取得了和使用 2.5D/3D 基础方法可比的结果 。这个结果表明 OccDepth 具有相对较好的补全能力。在 NYUv2 的测试集中,因为没有双目图像,我们的 OccDepth 将 RGB 图像和深度图生成虚拟双目图像作为输入。结果显示, OccDepth 取得了比所有 2.5D/3D 方法更好的 mIoU 和 IoU([+0.8 IoU,+1.7 mIoU])。在提出的仿真数据集 SemanticTartanAir 的测试集中,我们在这里使用深度真值作为这些 2.5D/3D 方法的输入,所以 2.5D/3D 方法的准确率非常高。另一方面,与 2.5D/3D 输入方法相比, OccDepth 具有较为接近的 mIoU 结果,并且 OccDepth 没有使用深度真值。与 纯视觉推理的方法相比,OccDepth 具有更高的 IoU 和 mIoU ([+17.6 IoU, +10.9 mIoU])。
定性对比
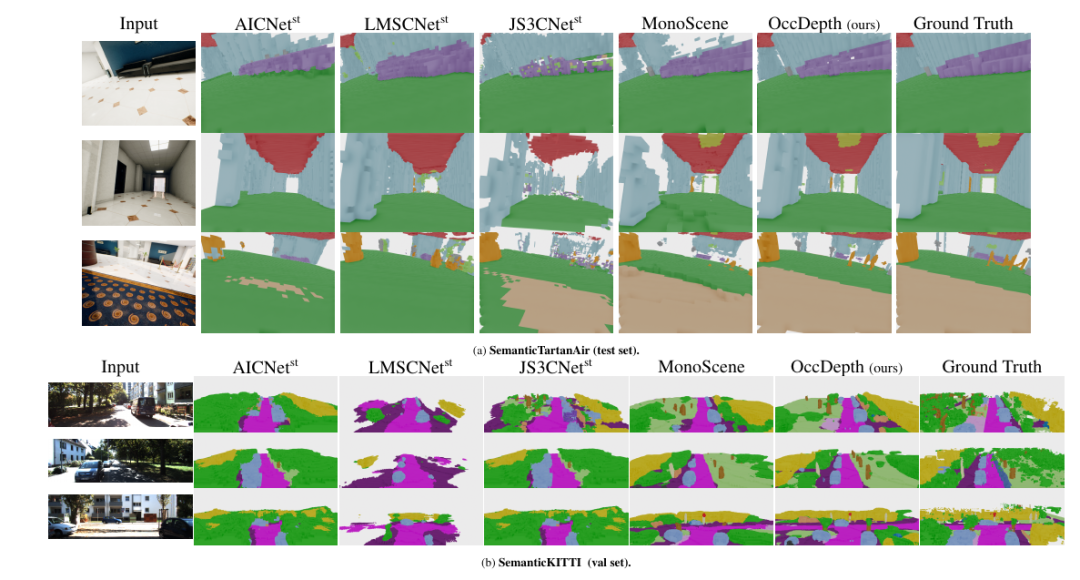
在 SemanticTartanAir 和SemanticKITTI 上的可视化结果。最左侧是输入的图像,最右侧是语义体素真值,中间为各种方法的可视化结果。这里显示了 OccDepth 在两个数据集中有较好结果场景。
在室内场景 SemanticTartanAir 数据集上,虽然所有方法都正确获得了正确的场景表示,但 OccDepth 对物体边缘具有更好的还原效果,例如沙发(图(a)的第 1 行)和天花板灯(图(a)的第 2 行) 和地毯(图(a)的第 3 行)。而在室外场景的 SemanticKITTI 数据集上,与基础方法相比,OccDepth 的空间和语义预测结果明显更好。例如,通过 OccDepth 可以实现路标(图(b)的第 1 行)、树干(图(b)的第 2 行)、车辆(图(b)的第 2 行)和道路(图(b)的第 3 行)的准确识别。
消融实验

对提出的模块进行消融实验。(a) Stereo-SFA 模块的消融实验。(b) OAD 模块中深度蒸馏数据源的消融实验。(c)OAD 模块中深度蒸馏数据源的消融实验。“w/o Depth”表示不使用深度蒸馏,Lidar depth 是指激光雷达点云生成的深度图,Stereo Depth 是指 LEAStereo 模型生成的深度图。以上实验都在 SemanticKITTI 的 08 号轨迹上进行测试。(a),(b),(c)的消融实验结果证明了提出的每个模块的有效性。
五、总结
在这项工作中,我们提出了一种有效利用深度信息的 3D 语义场景补全方法,我们将其命名为 OccDepth 。我们在 SemanticKITTI(室外场景)和 NYUv2(室内场景)数据集等公共数据集上训练了 OccDepth, 实验结果表明,本工作提出的 OccDepth 在室内场景和室外场景上都可与某些以 2.5D/3D 数据作为输入的方法相媲美。特别地是,OccDepth 在所有场景体素类别分类上都优于当前基于纯视觉推理的方法。
引用
[1] Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 165–174, 2019.
[2] Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Manolis Savva, and Thomas Funkhouser. Semantic scene completion from a single depth image. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1746–1754, 2017.
[3] Jiaxiang Tang, Xiaokang Chen, Jingbo Wang, and Gang Zeng. Not all voxels are equal: Semantic scene completion from the point-voxel perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 2352–2360, 2022
[4] Shun-Cheng Wu, Keisuke Tateno, Nassir Navab, and Federico Tombari. Scfusion: Real-time incremental scene reconstruction with semantic completion. In 2020 International Conference on 3D Vision (3DV), pages 801–810. IEEE, 2020.
[5] Ran Cheng, Christopher Agia, Yuan Ren, Xinhai Li, and Liu Bingbing. S3cnet: A sparse semantic scene completion network for lidar point clouds. In Conference on Robot Learning, pages 2148–2161. PMLR, 2021
[6] Xu Yan, Jiantao Gao, Jie Li, Ruimao Zhang, Zhen Li, Rui Huang, and Shuguang Cui. Sparse single sweep lidar point cloud segmentation via learning contextual shape priors from scene completion. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 3101–3109, 2021
[7] Xuemeng Yang, Hao Zou, Xin Kong, Tianxin Huang, Yong Liu, Wanlong Li, Feng Wen, and Hongbo Zhang. Semantic segmentation-assisted scene completion for lidar point clouds. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3555–3562. IEEE, 2021
[8] Christoph Rist, David Emmerichs, Markus Enzweiler, and Dariu Gavrila. Semantic scene completion using local deep implicit functions on lidar data. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
[9] Anh-Quan Cao and Raoul de Charette. Monoscene: Monocular 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3991–4001, June 2022

最后
以上就是大方猎豹最近收集整理的关于OccDepth:对标 Tesla Occupancy 的开源 3D 语义场景补全⽅法的全部内容,更多相关OccDepth:对标内容请搜索靠谱客的其他文章。








发表评论 取消回复