hive的使用
- 简单操作
- 修改表
- 修改列名
- 添加新列,和替换列
- 导入导出
- 导入导出表:
- 导入导出数据:
- 创建表
- truncate、delete和drop的区别
- 创建类型复杂表(案例)
- 创建分区表
- 单分区
- 多个分区:
简单操作
在mysql中可以,在hive中不可以
show databases like '%da%'
删除数据库
drop database database_name;
修改数据库属性
alter database my_2 set location 'hdfs://jh/mr/my_2';
查看我在哪个数据库
select current_database() ;
创建表–简单的
create table psn_2
(
id int comment '这是id',
name string comment '这是名字',
age tinyint ,
score double ,
createTime timestamp
)
comment '这是表的注释';
# 查看所有表
show tables;
# 查看单张表
desc psn_1 ;
# 查看表结构
desc formatted psn_1 ;
修改表
修改表名
alter table psn_1 rename to psn_11 ;
修改列名
修改表的列
alter table psn_11 change age age_1 int ;
添加新列,和替换列
alter table psn_11 add columns
(
sex smallint,
updateTime timestamp
);
删除表
drop table psn_11 ;
导入导出
Hive需要往hdfs中写数据;最好先关闭hadoop
进入node1中
cd /data/hadoop/hadoop/etc/hadoop/
配置hadoop,core-site.xml(追加内容,要注意格式哦)
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
然后分发给其他机器
scp core-site.xml node2:`pwd`
...node3...
...node4...
然后启动hadoop,执行如下命令
导入导出表:
导出hive中的表到hdfs
export table psn_1 to '/hw/psn_1' ;
删除hive中的表psn_1
drop table psn_1;
再从hdfs上导入
import table psn_1 from '/hw/psn_1' ;
导入导出数据:
导入数据:
hdfs导入的数据文件会被挪走(不复存在),
load data inpath '/hw/data.txt' into table psn_4 ;
内部表把hdfs上的文件夹也给删除了;而外部表不会删除hdfs上的
drop table psn_4 ;
如果表的格式为textFile,直接将txt上传到表指定的目录中,就可以直接查询出来;
创建表
创建表(并指定创建hdfs存储位置)
– 建议将最后一级目录的名字和表名一样;最好是空目录,否则会把文件夹下面的所有内容删除;可选,可不选
like 创建一个和某个表结构一样的表(不包含数据)
create table psn_8
like psn_1
location '/mr/psn_8';
as
创建一张表,是根据sql语句来的;
创建表的类型默认是内部表;
创建的表的格式默认是textFilie;
创建表中的列类型和sql语句查询出来的类型是一样一样的;
create table psn_7
as select id,name,age from psn_6 ;
truncate、delete和drop的区别
truncate和 delete只删除数据不删除表的结构(定义)
drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger),索引(index);
当你不再需要该表时, 用 drop;
当你仍要保留该表,但要删除所有记录时, 用 truncate;
当你要删除部分记录时(always with a WHERE clause), 用 delete
创建类型复杂表(案例)
create table psn_9
(
id int ,
name string,
age smallint,
scroe double,
-- 地址;容器,泛型
address array<string>,
-- map爱好;容器,泛型
hobby map<string,string>,
createTime string
)
-- 记录行的分隔符
row format delimited
-- 列的分隔符
fields terminated by ','
-- 数组的拆分
collection items terminated by '-'
-- map
map keys terminated by ':'
-- 存储文件的格式;textfile是默认的,写与不写都是一样的
stored as textfile ;
数组的拆分和map的拆分,并木有指定是哪一列,是所有的数组都是用-拆分,所有的map都是用:拆分
Map:键值对,使用:隔开,多个键值对使用集合-
准备一个数据文件;(multi_data.txt)
1,aa,20,80,北京-郑州-上海,音乐:王杰-运动:wegame-学习:码代码,2019-01-17 15:45:00
2,bb,21,90,郑州-上海,音乐:梁家辉-运动:篮球-学习:玩游戏,2019-01-17 15:45:00
3,cc,24,70,荥阳-上街,音乐:王杰-运动:wegame-学习:码代码,2019-01-18 15:45:00
4,dd,20,82,,音乐:轻音乐-运动:驱车-学习:大数据,2019-01-10 15:45:00
5,ee,22,81,,,2019-01-20 15:45:00
6,测试,29,80,郑州-荥阳,音乐:王杰-运动:wegame-学习:码代码,2019-01-11 15:45:00
表的默认格式是textFile,也不用使用load_data命令,直接将数据的文件上传到表的目录下面;
查询数组中的内容和map中的内容;
select id,address[1],hobby['音乐'] from psn_9 ;
创建分区表
单分区

create table psn_10
(
id int ,
name string,
age smallint,
scroe double,
-- 地址;容器,泛型
address array<string>,
-- map爱好;容器,泛型
hobby map<string,string>,
createTime string
)
-- 分区,分区的规则,指定列进行分区,分区的列不允许出现在小括号中;(分区可以有多个)
partitioned by (sex string)
-- 记录行的分隔符
row format delimited
-- 列的分隔符
fields terminated by ','
-- 数组的拆分
collection items terminated by '-'
-- map
map keys terminated by ':'
-- 存储文件的格式;textfile是默认的,写与不写都是一样的
stored as textfile ;
数据文件multi_data.txt
1,aa,20,80,北京-郑州-上海,音乐:王杰-运动:wegame-学习:码代码,2019-01-17 15:45:00
2,bb,21,90,郑州-上海,音乐:梁家辉-运动:篮球-学习:玩游戏,2019-01-17 15:45:00
3,cc,24,70,荥阳-上街,音乐:王杰-运动:wegame-学习:码代码,2019-01-18 15:45:00
4,dd,20,82,,音乐:轻音乐-运动:驱车-学习:大数据,2019-01-10 15:45:00
5,ee,22,81,,,2019-01-20 15:45:00
6,测试,29,80,郑州-荥阳,音乐:王杰-运动:wegame-学习:码代码,2019-01-11 15:45:00
导入数据
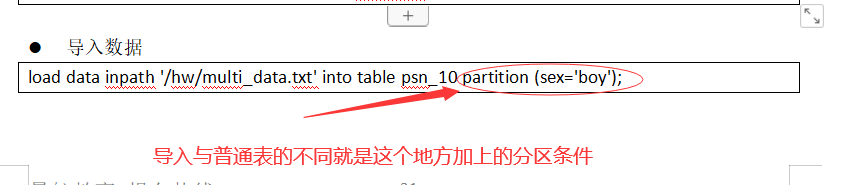
load data inpath '/hw/multi_data.txt' into table psn_10 partition (sex='boy');
分区在上hdfs上就是一个目录,不能手动在hdfs上直接创建;
多个分区:

最后
以上就是直率星月最近收集整理的关于hive的使用(实战)的全部内容,更多相关hive内容请搜索靠谱客的其他文章。








发表评论 取消回复