1. 考试是什么环境?
考试是在 centos7 环境下考试的。
- 不同的题库会有不同的试题,但大致都需要3-4个独立的集群环境。
- 有的集群1-2个节点
- 有的集群3-4个节点
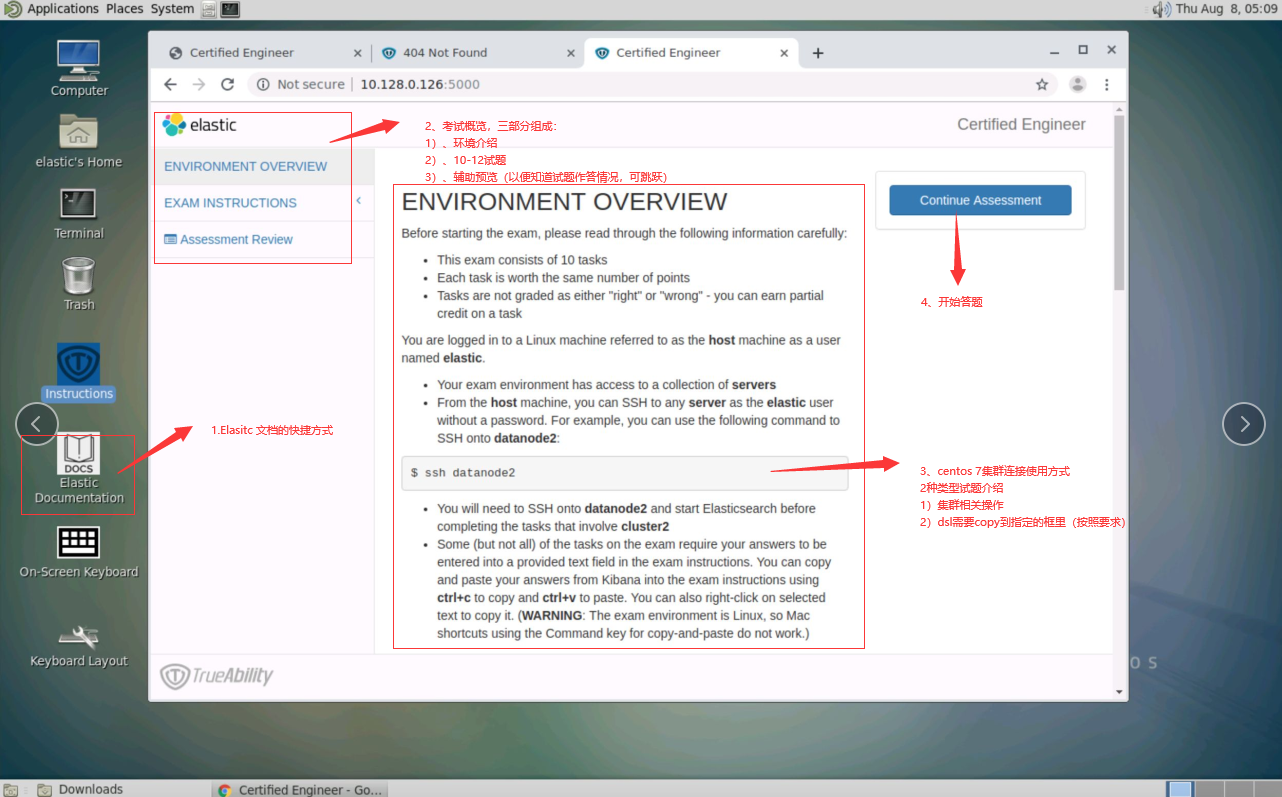
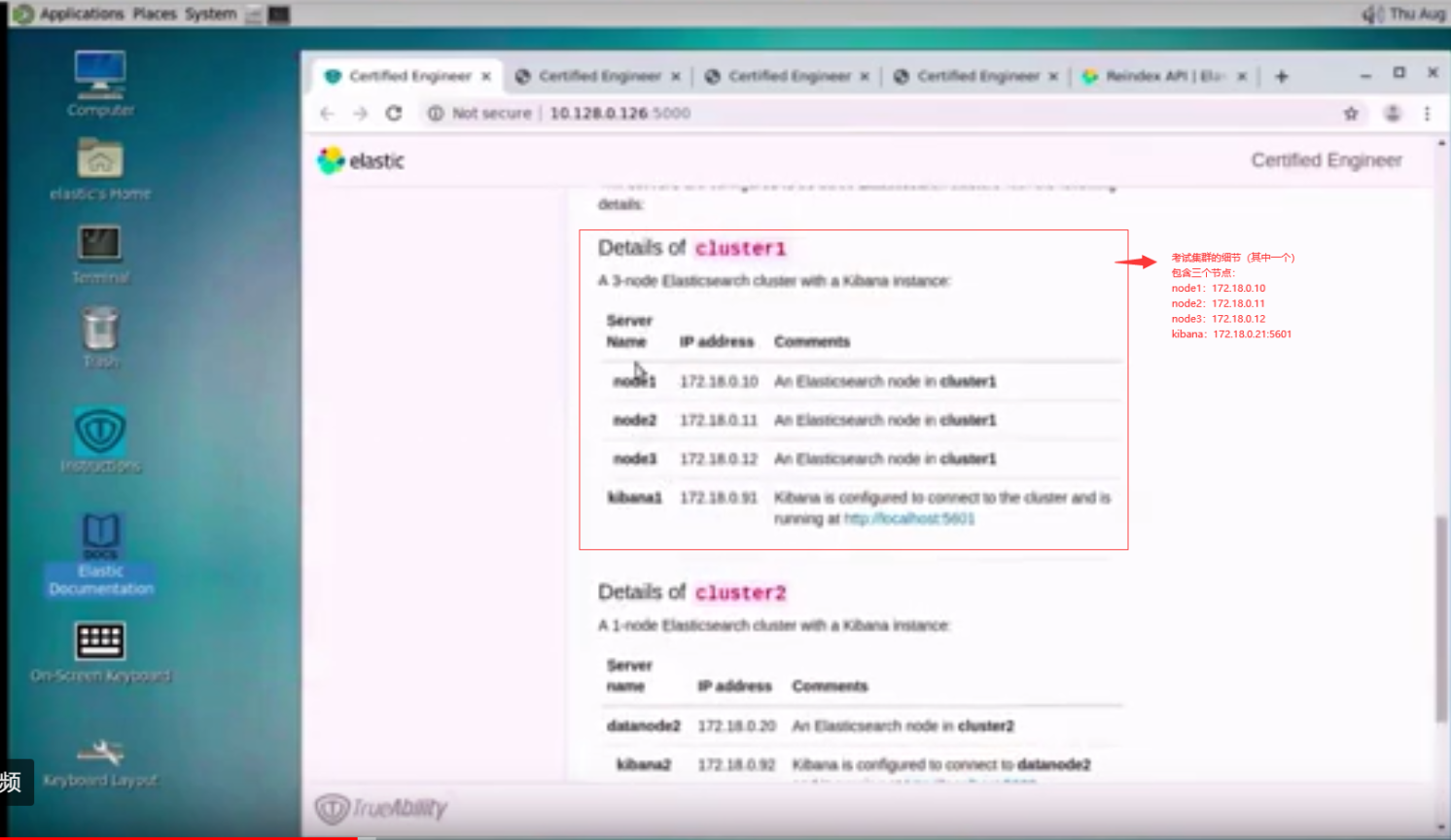
考虑到很多同学没有参加过类似的psi的在线考试,所以多看几遍:心里有数,考试才不紧张。 - Elastic文档的位置,考试不允许google、bing等搜索,文档是唯一的参考方式。常见的操作建议烂熟于心,稍微复杂点的建议对文档烂熟于心,直接o(1)时间锁定文档。
- 考试环境介绍,包含:主机节点访问方式,集群介绍等。
2. 我们该如何准备环境?
2.1 自己本机windows搭建虚拟机环境
注意:虚拟机选型:centos 7,其他不考虑。
2.2 自己本机部署docker
借助:docker compose实现。
2.3 购买云服务器。
建议:最小2核CPU,4GB内存。
能搭建两个节点的集群。
可以用来模拟:
- 1个集群两个节点。
常见考题:分片分配感知、集群主/副本分片异常等故障诊断等。 - 2个独立节点的集群。
常见考题:跨集群检索、机架awareness分片分配等。
其他相关DSL(增、删、改、查、聚合、Mapping/template/analyzer、xpack安全等)一个节点的集群就能搞定。
3. Elasticsearch单节点集群环境tar部署
3.1 Elasticsearch 7.2.0 版本下载地址
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
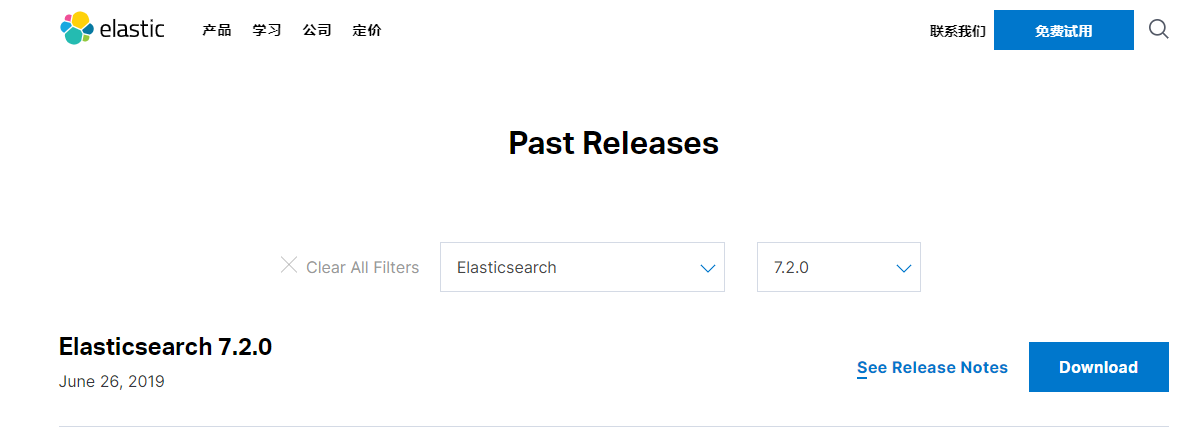
选择 Linux版本,就可以完成下载。tar包或rpm包
3.2 将压缩包导入Centos7 机器环境。
3.3 基础配置准备(非考试重点)
3.3.1 新建elastic账号和用户组。
• Elasticsearch不支持root账户运行。
• 考试的时候,账号名和用户组是elastic。
centos 7 执行命令:
useradd elastic
3.3.2 解压压缩包得elasticsearch-7.2.0文件
- 将elasticsearch-7.2.0文件拷贝到指定路径,路径自己定义即可。
- 为文件指定用户和用户组权限
进入elasticsearch-7.2.0路径,执行命令:
chown -R elastic:elastic ./*
3.3.3 修改文件描述符数目
为什么要修改?
- 原因1: Elasticsearch 在节点和 HTTP 客户端之间进行通信也使用了大量的套接字(注:sockets)。 所有这一切都需要足够的文件描述符。
- 原因2:许多现代的 Linux 发行版本,每个进程默认允许一个微不足道的 1024 文件描述符。这对一个小的 Elasticsearch 节点来说实在是太低了,更不用说一个处理数以百计索引的节点。
步骤1: 设置环境变量。
vim /etc/profile
ulimit -n 65535
用以设定同一时间打开的文件数的最大值为65535。
source /etc/profile
使得命令生效。
步骤2: 修改limits.conf配置文件。
- 用来限制打开文件数65535
- 用来限制打开最大的进程数32000
- 弹性搜索用户添加了无限内存锁
$ vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 32000
* hard nproc 32000
* hard memlock unlimited
* soft memlock unlimited
$ vim /etc/systemd/system.conf
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
$ systemctl daemon-reload
步骤3: 验证是否成功。
切换到elastic用户,使用ulit -a 查看是否修改成功。
ulimit -a
3.3.4 修改 最大映射数量 MMP
Elasticsearch 对各种文件混合使用了 NioFs( 非阻塞文件系统)和 MMapFs ( 内存映射文件系统)。
请确保你配置的最大映射数量,以便有足够的虚拟内存可用于 mmapped 文件。这可以暂时设置:
sysctl -w vm.max_map_count=262144
或者你可以在 /etc/sysctl.conf 通过修改 vm.max_map_count 永久设置它。
[root@4ad config]# tail -f /etc/sysctl.conf`在这里插入代码片`
vm.max_map_count=262144
3.3.5 禁用swapping
$ swapoff -a
$ vim /etc/sysctl.conf
vm.swappiness = 1
进行修改确认:
$ sysctl -p
vm.swappiness = 1
3.4 elasticsearch.yml 配置(考试会考)
cluster.name: cluster1 #核心配置
node.name: node1 #核心配置
node.master: true #核心配置
node.data: true #核心配置
cluster.remote.connect: false #核心配置
network.host: 172.17.0.17 #核心配置
http.port: 9200 #核心配置
transport.port:9300 #核心配置
discovery.seed_hosts: ["172.17.0.17:9300"] #核心配置
cluster.initial_master_nodes: ["172.17.0.17:9300"] #核心配置
path.data: /var/lib/elasticsearch #优化配置,非必须
path.logs: /var/log/elasticsearch #优化配置,非必须
bootstrap.memory_lock: true #优化内存配置,非必须
注意:考试的时候就基本如上所示,没有任何注释。
• cluster.name: 集群名称,唯一确定一个集群。
• node.name:节点名称,一个集群中的节点名称是唯一固定的,不同节点不能同名。
• node.master: 主节点属性值
• node.data: 数据节点属性值
• network.host: 本节点的ip
• http.port: 本节点的http端口
• transport.port:9300——集群之间通信的端口,若不指定默认:9300
• discovery.seed_hosts:节点发现需要配置一些种子节点,与7.X之前老版本:disvoery.zen.ping.unicast.hosts类似,一般配置集群中的全部节点
• cluster.initial_master_nodes:指定集群初次选举中用到的具有主节点资格的节点,称为集群引导,只在第一次形成集群时需要。
path.data: /var/lib/elasticsearch 配置数据存储路径
path.logs: /var/log/elasticsearch 配置日志存储路径
bootstrap.memory_lock: true 为弹性搜索用户添加了无限内存锁
3.4 章节的考点包含但不限于:
- 集群节点配置
区分并会配置:master,data,coordinate,ingest等节点 - xpack安全配置
设置Elasticsearch安全属性开关 - 节点自定义属性(冷、热等)冷热架构集群部署配置
3.5 jvm.option的设置
$ grep '^-Xm[sx]' /etc/elasticsearch/jvm.options
-Xms1g
-Xmx1g
这里针对4GB内存的机器环境,预留分配2个节点,所以堆内存大小:设置了1GB。
- 实际生产环境中计算公式:min(机器内存的一半,32GB内存)。也就是说:取机器环境内存的一半和32GB内存之间的小值。
- 实战中经常会遇到堆内存设置不合理的问题,
- 具体原理推荐阅读:https://blog.csdn.net/laoyang360/article/details/79998974
3.6 启动节点
实际考试中,一般kibana会启动,elasticsearch集群可能不启动。
需要你:
• 第一步: ssh 登录到对应节点。
ssh node1
• 第二步:启动 对应节点的Elasticsearch。
启动方法1:后台启动
./elasticsearch -d
启动方法2:非后台启动
能看到启动日志
./elasticsearch
4. Elasticsearch 双节点或多节点集群环境tar包部署
仅说明两个节点的配置,多节点雷同,不再赘述。
多节点elasticsearch.yml
4.1 节点1的配置如下:
$ vim /elasticsearch-7.2.0/config/elasticsearch.yaml
cluster.name: cluster1
node.name: node1
node.master: true
node.data: true
node.ingest: true
network.host: 172.17.0.17
http.port: 9200
transport.port:9300
discovery.seed_hosts: ["172.17.0.17:9300","172.17.0.17:9301"]
cluster.initial_master_nodes: ["172.17.0.17:9300","172.17.0.17:9301"]
path.data: /var/lib/elasticsearch #优化配置,非必须
path.logs: /var/log/elasticsearch #优化配置,非必须
bootstrap.memory_lock: true #优化配置,非必须
启动服务
$ /elasticsearch-7.2.0/bin/elasticsearch -d
4.2 节点2的配置如下:(伪节点,其实还是在节点1)
cp -pr /elasticsearch-7.2.0 /elasticsearch-7.2.0_2
vim /elasticsearch-7.2.0_2/config/elasticsearch.yaml
cluster.name: cluster1
node.name: node2
node.master: true
node.data: true
node.ingest: true
network.host: 172.17.0.17
http.port: 9201
transport.port:9301
discovery.seed_hosts: ["172.17.0.17:9300","172.17.0.17:9301"]
cluster.initial_master_nodes: ["172.17.0.17:9300","172.17.0.17:9301"]
path.data: /var/lib/elasticsearch #优化配置,非必须
path.logs: /var/log/elasticsearch #优化配置,非必须
bootstrap.memory_lock: true #优化配置,非必须
启动服务
$ /elasticsearch-7.2.0_2/bin/elasticsearch -d
核心点:
机器资源有限,1台机器部署2-3甚至更多节点,如何通信?
- 设置相同ip
- 设置不同的http和tcp端口以区分不同节点
- 本质是伪集群
注意切记:实际业务线上环境,建议所有Elasticsearch节点都是独立节点,不要部署其他程序、其他后台进程,以提高性能。如果内存足够大,比如:128GB、256GB,单节点是浪费,建议通过虚拟化方式切分开。
5. kibana环境部署
5.1 下载安装包
https://www.elastic.co/cn/downloads/past-releases#kibana
如图所示:
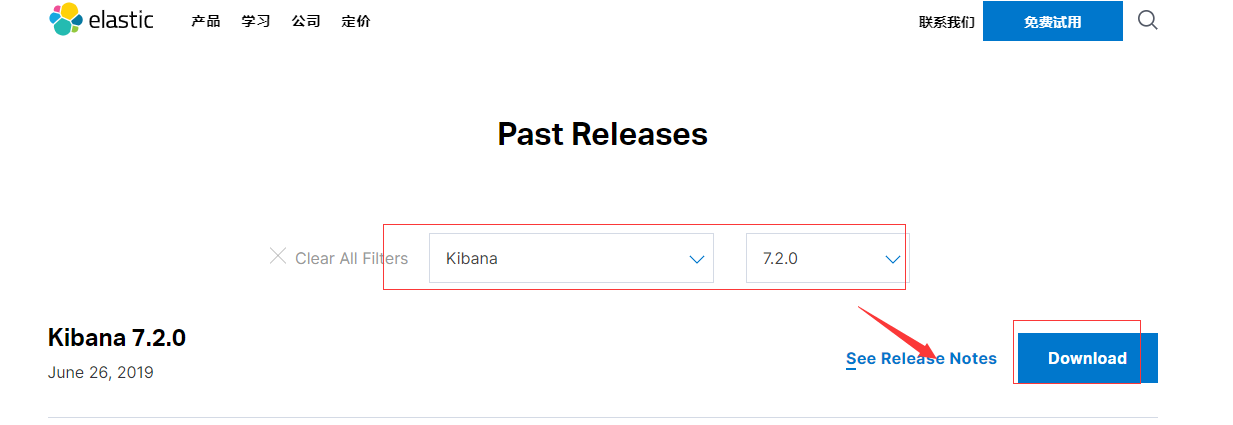
5.2 解压安装包
5.3 修改kibana.yml配置
- 设定kibana端口
- 设定所在主机ip
- 指定Elasticsearch连接地址
$ vim /kibana-7.2.0-linux-x86_64/config/kibana.yml
server.port: 5601
server.host: "172.17.0.17"
elasticsearch.hosts: ["http://172.17.0.17:9200"]
5.4 启动kibana(基本不考)
注意:不需要修改kibana的用户或者用户组权限。
nohup ./bin/kibana --allow-root & > /dev/null 2>&1
访问http://1172.17.0.17:5601/
6. 注意事项
6.1 我上面讲的都是考试实际考试的环境。
6.2 启动 + 参数的方式 也可以启动集群,考试没有明确指定启动方式。
如下 也可以启动集群。
bin/elasticsearch -E node.name=cluster0node -E cluster.name=cluster0 -E path.data=cluster0_data -E discovery.type=single-node -E http.port=9200 -E transport.port=9300
参考连接:
Exception in thread “main” java.nio.file.AccessDeniedException:
Elasticsearch进程内存锁定失败
吃透Elasticsearch 堆内存
更多Elastic认证细节内容,请报名@毅铭天下

最后
以上就是花痴斑马最近收集整理的关于Elastic认证集群环境tar包安装准备的全部内容,更多相关Elastic认证集群环境tar包安装准备内容请搜索靠谱客的其他文章。








发表评论 取消回复