这里是2019年遥感图像稀疏表征与智能分析竞赛初期代码,后期魔改这个代码拿到了分类赛道榜一,这里以AID数据集为例,演示一下拿到遥感数据集后对数据集进行分析,和初步的模型训练以及对结果的分析。如果对场景分类和变化检测有兴趣的同学,可以移步 https://github.com/carryHJR/remote-sense-quickstart,本文代码也在这个仓库里,求star.
对于已有基础的同学,可以直接移步本文后记部分
load module
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import os
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
%load_ext autoreload
%autoreload 2
load dataset
这里我们定义数据集的位置和制作一个字典来确定类别名字和对应id
data_dir = '/home/yons/data/AID/AID'
import glob
image_path_list = glob.glob(os.path.join(data_dir, '*', '*'))
image_path_list.sort()
print(len(image_path_list))
categories = [d.name for d in os.scandir(data_dir) if d.is_dir()]
categories.sort()
print(len(categories))
class_to_idx = {categories[i]: i for i in range(len(categories))}
idx_to_class = {idx: class_ for class_, idx in class_to_idx.items()}
print(class_to_idx)
可以得到
{'Airport': 0, 'BareLand': 1, 'BaseballField': 2, 'Beach': 3, 'Bridge': 4, 'Center': 5, 'Church': 6, 'Commercial': 7, 'DenseResidential': 8, 'Desert': 9, 'Farmland': 10, 'Forest': 11, 'Industrial': 12, 'Meadow': 13, 'MediumResidential': 14, 'Mountain': 15, 'Park': 16, 'Parking': 17, 'Playground': 18, 'Pond': 19, 'Port': 20, 'RailwayStation': 21, 'Resort': 22, 'River': 23, 'School': 24, 'SparseResidential': 25, 'Square': 26, 'Stadium': 27, 'StorageTanks': 28, 'Viaduct': 29}
view numbers
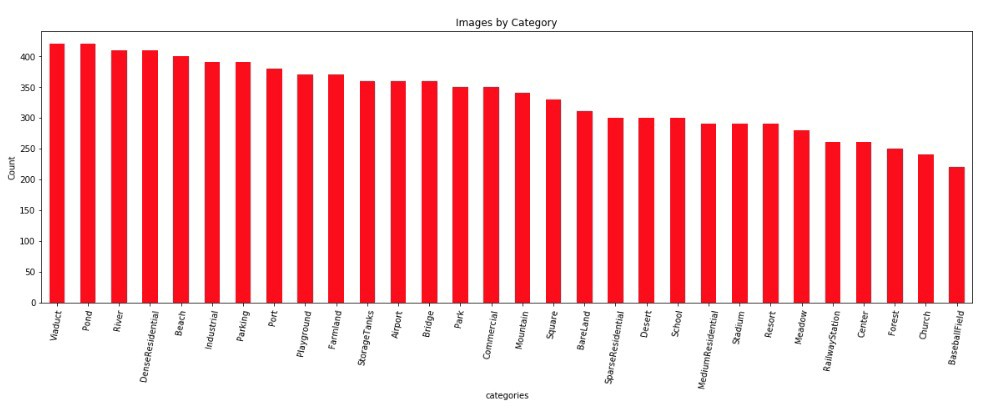
看看数量关于类别的分布
n_categories = []
for category in categories:
n_categories.append(len(os.listdir(os.path.join(data_dir, category))))
print(n_categories)
import pandas as pd
cat_df = pd.DataFrame({'categories':categories, 'number':n_categories})
cat_df.sort_values('number', ascending=False, inplace=True)
cat_df.head()
cat_df.tail()
_ = plt.figure()
cat_df.set_index('categories')['number'].plot.bar(color='r', figsize=(20, 6))
_ = plt.xticks(rotation=80)
_ = plt.ylabel('Count')
_ = plt.title('Images by Category')
view heights and widths
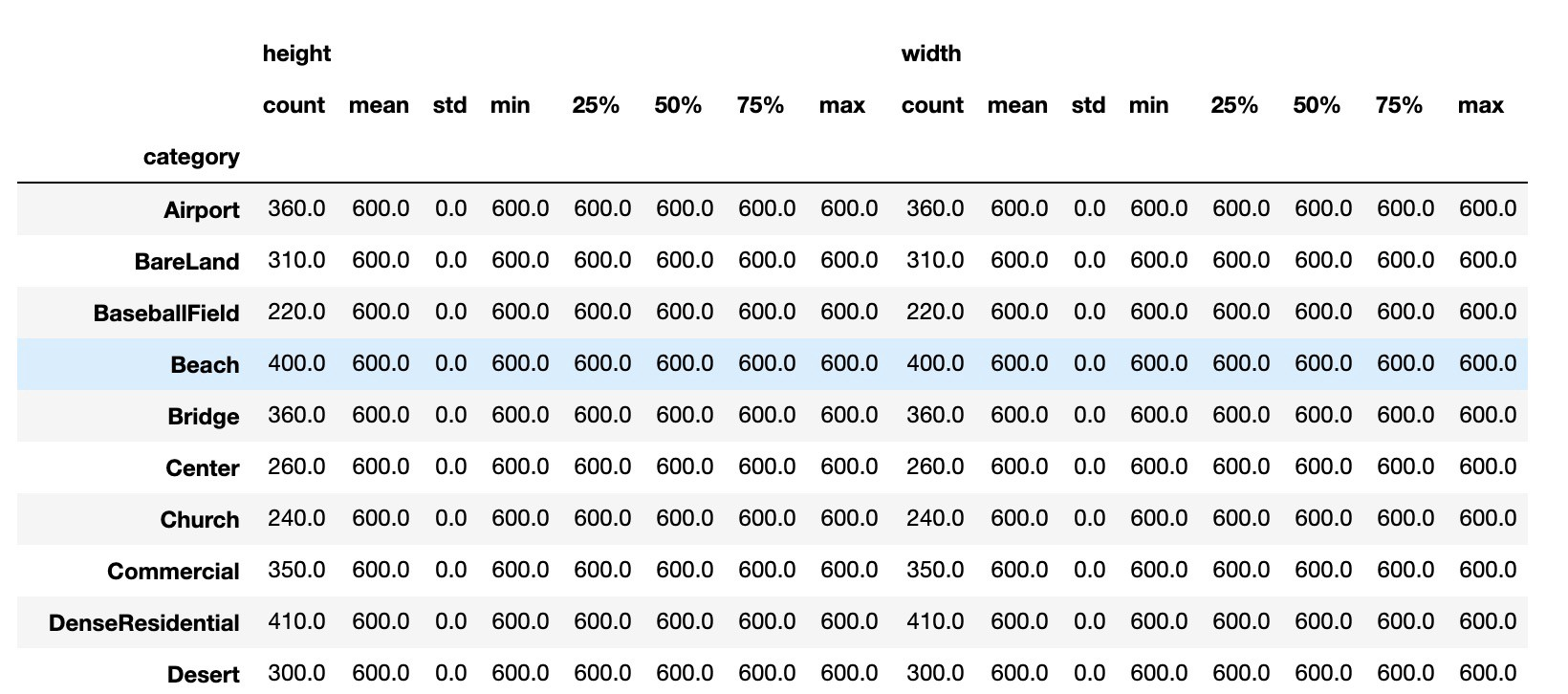
这里AID数据集统一是600*600,为了适应广泛的数据集,还是算一下
import cv2
def multiprocess_run(process, obj_list, notebook=False):
if notebook is True:
from tqdm import tqdm_notebook as tqdm
else:
from tqdm import tqdm
from multiprocessing import Pool
import multiprocessing
import time
import sys
cpus = multiprocessing.cpu_count()
pool = Pool(processes=cpus)
result_list = []
tic = time.time()
for result in tqdm(pool.imap(process, obj_list)):
result_list.append(result)
sys.stdout.flush()
toc = time.time()
print('time waste', toc - tic)
return result_list
def process(image_path):
category = os.path.dirname(image_path).split('/')[-1]
try:
h, w, _ = cv2.imread(image_path).shape
except Exception as e:
print(image_path)
return None
return {'category':category, 'height':h, 'width': w}
result_list = multiprocess_run(process, image_path_list, notebook=True)
img_category_list = []
img_height_list = []
img_width_list = []
for d in result_list:
if d is not None:
img_category_list.append(d['category'])
img_height_list.append(d['height'])
img_width_list.append(d['width'])
image_df = pd.DataFrame({
'category': img_category_list,
'height': img_height_list,
'width': img_width_list
})
import seaborn as sns
img_dsc = image_df.groupby('category').describe()
img_dsc
## all of the dataset are 600*600
split datasets
AID 对应paper 给的是20% — 86.86 | 50% — 89.53,这里我用50%
import random
random.shuffle(image_path_list)
image_path_list_train = image_path_list[:5000]
image_path_list_val = image_path_list[5000:]
print('train:', len(image_path_list_train))
print('val:', len(image_path_list_val))
define datasets
from torch.utils.data import Dataset
from PIL import Image
class SceneDataset(Dataset):
def __init__(self, samples, transform, notebook=False):
self.transform = transform
self.samples = samples
self.get_item = self.get_item_from_path
print(len(self.samples))
def get_item_from_path(self, index):
path, target = self.samples[index]
with open(path, 'rb') as f:
img = Image.open(f).convert('RGB')
return img, target
def __getitem__(self, index):
sample, target = self.get_item(index)
sample = self.transform(sample)
return sample, target
def __len__(self):
return len(self.samples)
# test
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([transforms.Resize(224),
transforms.ToTensor()])
batch_size = 128
data = {
'train':
SceneDataset([(x, class_to_idx[x.split('/')[-2]]) for x in image_path_list_train], transform=transform),
'val':
SceneDataset([(x, class_to_idx[x.split('/')[-2]]) for x in image_path_list_val], transform=transform),
}
dataloaders = {
'train': DataLoader(data['train'], batch_size=batch_size, shuffle=False),
'val': DataLoader(data['val'], batch_size=batch_size, shuffle=False),
}
test_iter = iter(dataloaders['train'])
inputs, targets = next(test_iter)
inputs.shape, targets.shape
可以得到
(torch.Size([128, 3, 224, 224]), torch.Size([128]))
可视化一下

cat the mean and the std
计算均值和方差,后面定义transform要用
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([transforms.Resize(224),
transforms.ToTensor()])
dataset = SceneDataset(samples=[(x, class_to_idx[x.split('/')[-2]]) for x in image_path_list_train], transform=transform)
loader = DataLoader(
dataset,
batch_size=128,
num_workers=32,
shuffle=False
)
print(len(loader))
mean = 0.
std = 0.
nb_samples = 0.
from tqdm import tqdm_notebook as tqdm
for step, data in tqdm(enumerate(loader)):
inputs, targets = data
batch_samples = inputs.size(0)
inputs = inputs.view(batch_samples, inputs.size(1), -1)
mean += inputs.mean(2).sum(0)
std += inputs.std(2).sum(0)
nb_samples += batch_samples
mean /= nb_samples
std /= nb_samples
mean = mean.numpy()
std = std.numpy()
print(mean)
print(std)
得到
[0.3993387 0.4099782 0.36849037]
[0.14586602 0.1325128 0.12770559]
define transfrom
from torchvision import transforms
# Image transformations
image_transforms = {
# Train uses data augmentation
'train':
transforms.Compose([
transforms.RandomResizedCrop(size=224, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.ColorJitter(),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std) # Imagenet standards
]),
# Validation does not use augmentation
'val':
transforms.Compose([
transforms.Resize(size=256),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
}
可视化一下

define model
使用经典的resnext50
import torchvision
import torch.nn as nn
model = torchvision.models.resnext50_32x4d(pretrained=True)
for i, layer in enumerate(model.children()):
if i < 6:
for param in layer.parameters():
param.requires_grad = False
n_inputs = model.fc.in_features
model.fc = nn.Sequential(
nn.Linear(n_inputs, 256), nn.ReLU(), nn.Dropout(0.3),
nn.Linear(256, 30))
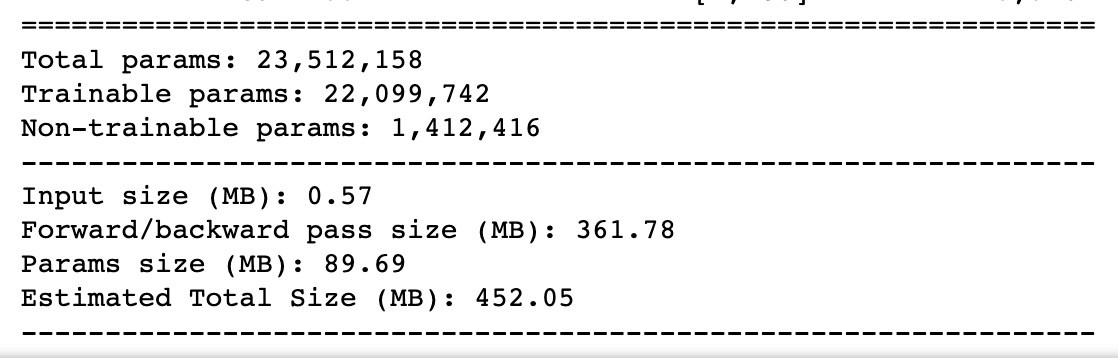
看看参数有多少
train
定义一个train_val函数
def train_val(net, criterion, optimizer, train_loader, val_loader):
from tqdm.autonotebook import tqdm
_ = net.train()
train_loss = 0
train_acc = 0
for step, (inputs, targets) in tqdm(enumerate(train_loader)):
inputs, targets = inputs.cuda(), targets.cuda()
outputs = net(inputs)
optimizer.zero_grad()
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, pred = torch.max(outputs, dim=1)
correct_tensor = pred.eq(targets.data.view_as(pred))
accuracy = torch.mean(correct_tensor.type(torch.FloatTensor))
train_acc += accuracy.item()
train_loss, train_acc = train_loss / len(train_loader), train_acc / len(train_loader)
_ = net.eval()
with torch.no_grad():
val_loss = 0
val_acc = 0
for step, (inputs, targets) in enumerate(val_loader):
inputs, targets = inputs.cuda(), targets.cuda()
outputs = net(inputs)
loss = criterion(outputs, targets)
val_loss += loss.item()
_, pred = torch.max(outputs, dim=1)
correct_tensor = pred.eq(targets.data.view_as(pred))
accuracy = torch.mean(correct_tensor.type(torch.FloatTensor))
val_acc += accuracy.item()
val_loss, val_acc = val_loss / len(val_loader), val_acc / len(val_loader)
return train_loss, train_acc, val_loss, val_acc
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
正式训练
batch_size = 128
dataloaders = {
'train': DataLoader(data['train'], batch_size=batch_size, shuffle=True),
'val': DataLoader(data['val'], batch_size=batch_size, shuffle=False),
}
print('train batch:%s' % len(dataloaders['train']))
print('val batch:%s' % len(dataloaders['val']))
# loss
criterion = nn.CrossEntropyLoss()
import torch
net = model.cuda()
net = nn.DataParallel(net)
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[2, 8, 15, 20], gamma=0.1)
version = '0.1'
log_dir = 'AID-quickstart.log'
save_dir = os.path.join(log_dir, version)
import shutil
import os
if not os.path.exists(save_dir):
os.makedirs(save_dir)
else:
shutil.rmtree(save_dir)
os.makedirs(save_dir)
best_acc = 0
for epoch in range(25):
scheduler.step()
print('n Version: %s Epoch: %d | learning rate:%f' % (version, epoch, get_lr(optimizer)))
train_loss, train_acc, val_loss, val_acc = train_val(net, criterion, optimizer, dataloaders['train'], dataloaders['val'])
print(epoch, train_loss, train_acc, val_loss, val_acc)
if val_acc > best_acc:
best_acc = val_acc
save_path = os.path.join(save_dir, 'best_acc.pth')
state = {
'net': net.state_dict(),
'epoch': epoch,
'loss': val_loss,
'acc': val_acc
}
torch.save(state, save_path)
evaluate
save_path = os.path.join(save_dir, 'best_acc.pth')
checkpoint = torch.load(save_path)
net.load_state_dict(checkpoint['net'])
print(checkpoint['epoch'], checkpoint['loss'], checkpoint['acc'])
得到
13 0.3272677581757307 0.92421875
说明最好的是epoch=13,网络不给力,收敛太早了,不过精度已经超过了官方的baseline
view top1 and top5
计算top1 和 top5 得到
top1 : 0.9224
top5 : 0.9694
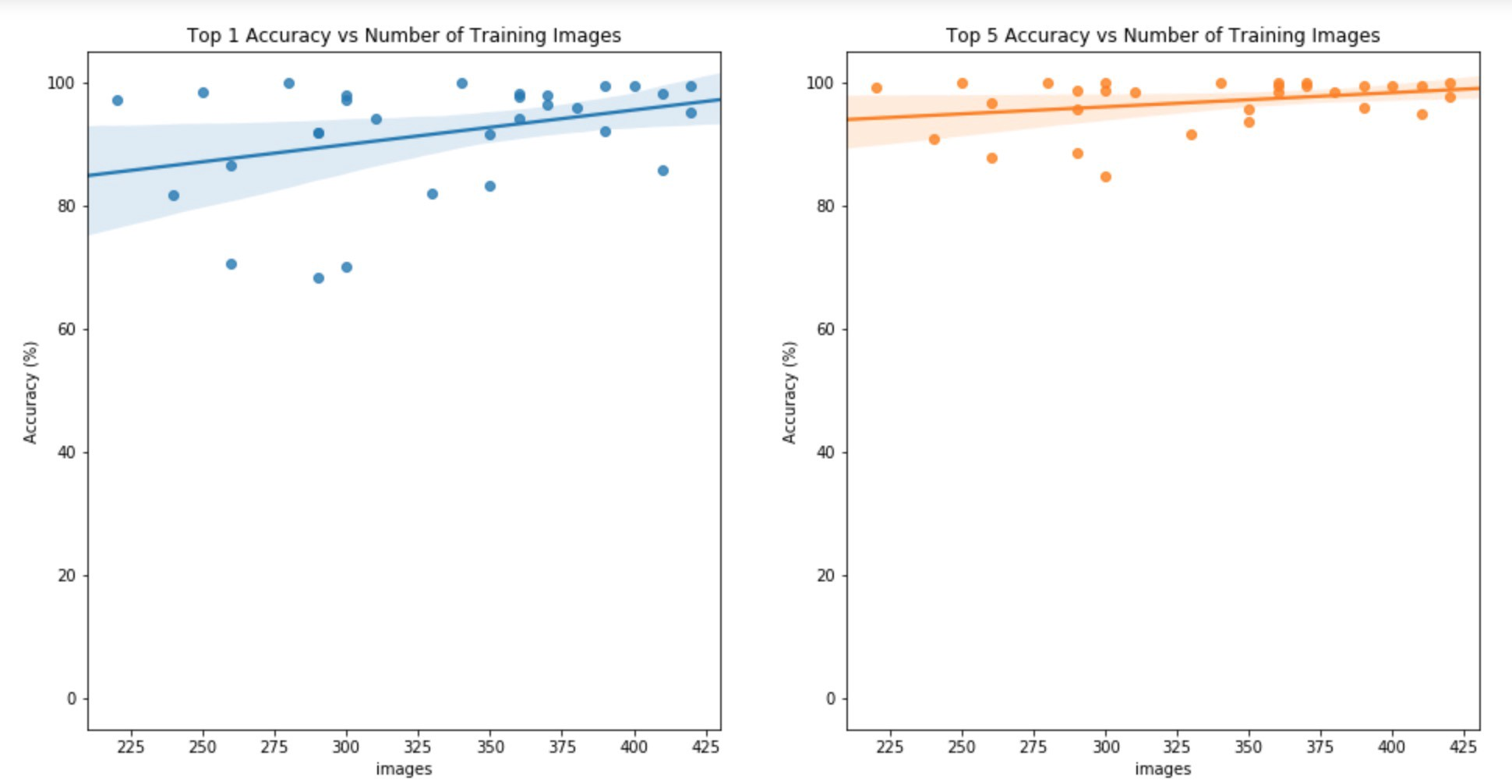
看看正确率关于类别的分布以及数量
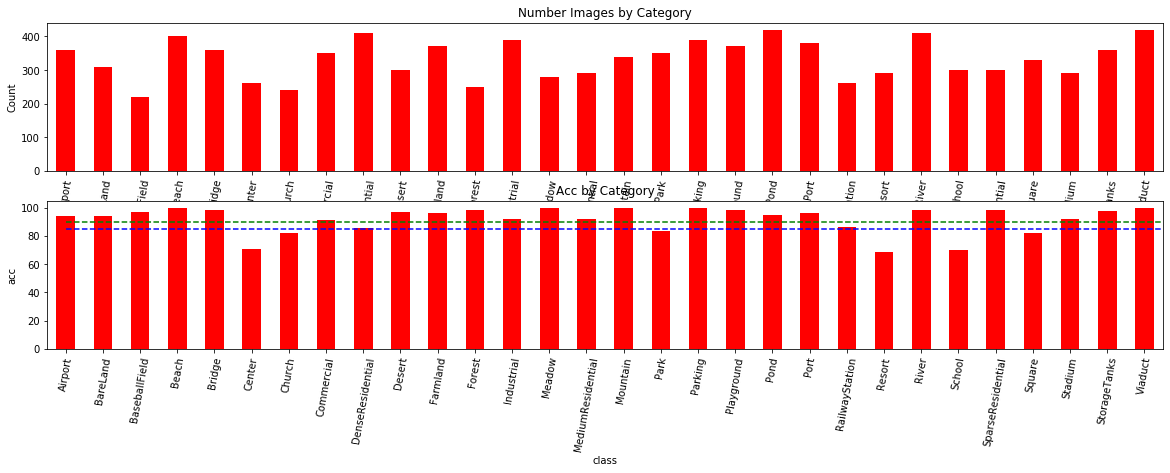
绘制混淆矩阵

看起来有些类别之间的混淆影响了最终结果,这个也是很多论文在尝试提高的地方
后记
心血来潮把变换检测和场景分类的代码整理了一下 https://github.com/carryHJR/remote-sense-quickstart,如果大家对这个仓库有一定兴趣的话或者觉得有帮助的话,给个star呗
手头还有个场景分类的进阶版,主要是在线测试数据增广和半监督训练和更复杂的增广,可以对acc有较大提升,如果大家感兴趣的话在点赞和评论区扣1,我整理好后会挨个私信
最后
以上就是飘逸帆布鞋最近收集整理的关于场景分类quick-start的全部内容,更多相关场景分类quick-start内容请搜索靠谱客的其他文章。








发表评论 取消回复