从互联网的服务描述来看,我们说互联网由分布式的应用进程和为分布式应用进程提供服务的基础设施组成。通常情况下,我们在任意两个端系统间通信,都希望我们给对方发送信息时,对方能够立刻收到信息。或者是客户机在访问服务器时,服务器能够立刻应答。然而,这是理想情况。事实上,计算机网络必定要限制在端系统之间的吞吐量(每秒能够传送的数据量),在端系统之间引入时延,而且实际上也可能丢失分组。这一节,我们就来学习计算机网络中的时延,丢包,吞吐量等问题。
在介绍时延,丢包,吞吐量等问题前,我们来看这样一个问题:考虑一条高速公路,并假设这条高速公路中每隔100km的距离会有一个收费站。假定有一列车队(10辆车)要从起点收费站上高速而在终点收费站下高速。此车队的顺序永远保持不变,并均保持100km/h的速度行驶。这个车队是一个团队,他们约定第一辆车(1号车)及后面的车到达下一个收费站时,不能立刻出发,你必须等待该车队的最后一辆车(10号车)到达收费站时,第一辆车(1号车)才开始驶出收费站。假定收费站给予每辆车1min的服务,然后就向下一收费站驶去。并且收费员只有看到10号车到达收费站,才开始给1号车提供服务。
先分析第一个问题,从第一辆车获得服务开始计时,第一辆车到达B收费站的时间是61min,但是因为尾车还没到来,所以它要等待。第二个车是62min,第三个车是63min..........最后一辆车70min到达B收费站。此时,收费员才开始给1号车办理服务,花费1min,才向C收费站驶去。也就是说1号车在B收费站等待了10min(包括其收费时间),而10号车在A收费站等待10min时间(包括其收费时间)。(在此,注意一个细节,车队通过收费站用时10min,而每辆车在路上行驶时间60min,也就是说1号车到达B收费站时,10号车已经出发行驶在路上。)
现假设车队每辆车速度是1000km/h,其它条件保持不变。
分析这个问题,路上时间6min,1号车在第七分钟的时候到达B收费站,然而10还没开始得到服务,仍在A收费站等待。
时延
我们知道,分组交换具有存储转发机制。前面我们计算过从源开始发送分组到目的地收到整个分组所用的时间。在那里,我们忽略了传播时延,节点处理时延,排队时延等,而是把它看作简单理想的情况。事实上,分组从一台主机(源)出发,通过一系列的路由器,在另一台主机(目的地)结束历程。当分组从一个节点(主机或路由器)沿着这条路径到后继节点(主机或路由器),该分组在沿途的每个节点经受几种不同类型的时延。这些时延最重要的是节点处理时延,排队时延,传输时延,传播时延。这些时延总体累加起来就是节点总时延。
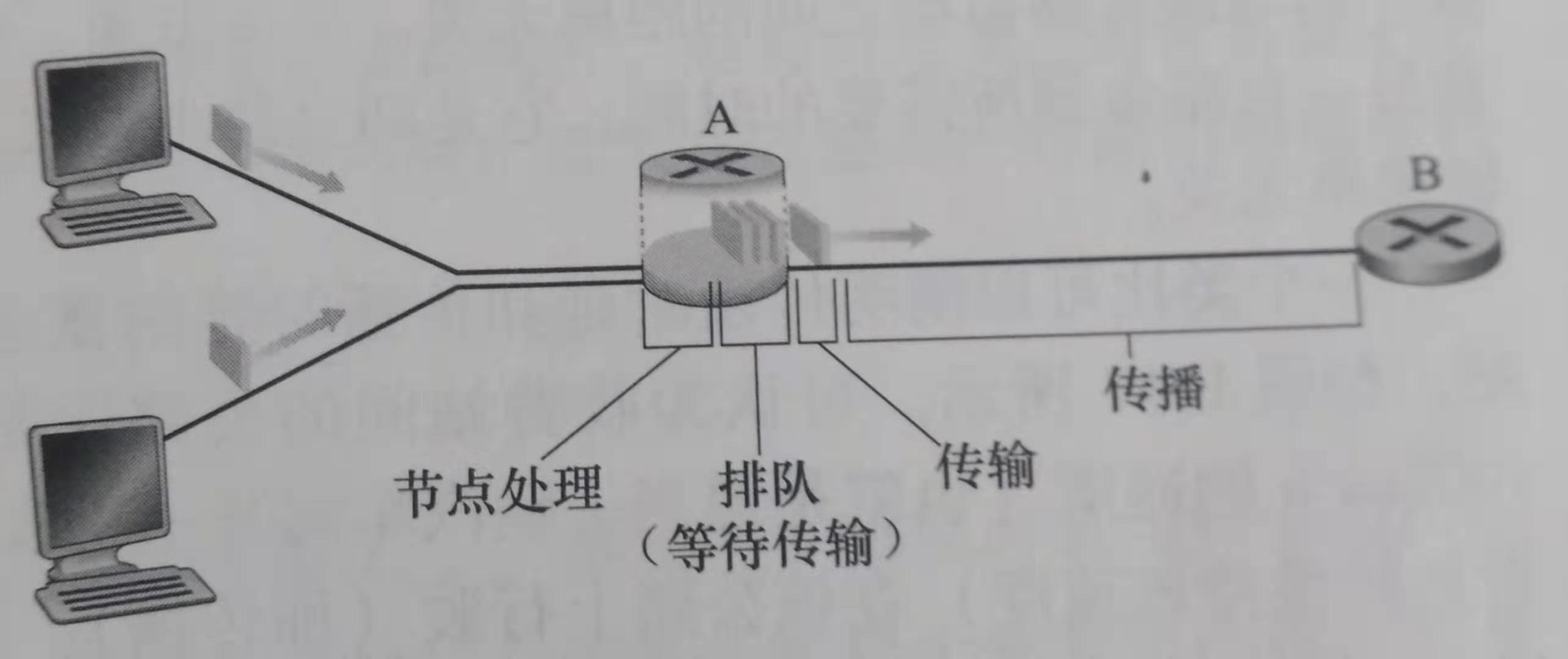
上图,一个分组从上游节点通过路由器A向路由器B发送。我们的目标是在路由器A刻画出节点时延。值得注意的是,路由器A具有通向路由器B的出链路。该链路的前面有一个队列,当分组从上游节点到达路由器A时,路由器A检查该分组的首部以决定它的适当出链路,并将分组导向该链路。
(1)处理时延:包括检查分组首部和决定将分组导向哪条链路所花费的时间。
(2)排队时延:一个分组从输入链路过来,路由器将分组导向出链路。但是,如果该输出链路有其它分组在传输,则它必须要排队。在队列中,分组在链路上等待传输所花费的时间叫做排队时延。时延长度取决前面排队导向该链路的分组的数量。
(3)传输时延:前面其实已经介绍过传输时延。在此,再次概括。假定分组以先到先服务的方式传输,仅当所有已经到达的分组中所有比特被传输后,才能传输刚到达的分组。L比特表示该分组的长度,R bps表示从路由器A到路由器B的链路传输速率。传输时延是L/R。这是将所有的分组的比特推向链路所需时间。
(4)传播时延:在介质上传播所需时间。
辨析传播时延和传输时延:传输时延是路由器推出分组中所有比特所花费的时间,它是分组的长度和链路的传输速率的函数。回到文章开始的那个例子,车队可以比喻成一个分组,而每一辆车可以比喻成每一个比特。传输时延相当于车队的每辆车完成收费驶入高速所花费的时间,当然该时间等于车辆数乘以每辆车得到服务所需时间。那么也就是说传输时延与比特数量和每秒传输的比特数量有关。
传播时延指一个比特从一台路由器传播到另外一个路由器所需要的时间,它是两台路由器之间距离的函数,而与分组长度或链路的传输速率无关。就好比每辆车从A收费站到B收费站所花费的时间。
如果令d(proc), d(queue), d(trans), d(prop)分别表示处理时延,排队时延,传输时延和传播时延,则节点的总时延由以下公式给定:
d(nodal) = d(proc)+d(queue)+d(trans)+d(prop).
排队时延
排队时延是不确定的。就好比我们去坐公交车。如果人多的话,相对排队的时间就要久一点。也可能跟具体的位置有关,例如如果你排前面,那么相对来说你排队的时间就要短一些,如果你在队伍的后面,那么你排队的时间就要久一些。同样的,排队时延对不同的分组可能也不一样,假如有10个分组同时到达空对列,传输第一个分组没有排队时延,而传输最后一个分组将经受相对大的排队时延(它要等待其它9个分组被传输)。
什么时候排队时延大,什么时候又不大呢?该问题的答案很大程度上取决于流量到达该队列的速率,链路的传输速率和到达流量的性质,即流量是突发性到达还是周期性到达。
假设a表示分组到达队列的平均速率(单位:分组/s, pkt/s),假设1s到达1个分组,那么a就等于1pkt/s。R是传输速率,即从队列中推出比特的速率(单位:bps)。为了简单起见,假定所有分组由L比特组成。则比特到达的平均速率为La bps。R是比特推出的平均速率,我们比特到达的平均速率与比特输出的平均速率的比值叫做流量强度。即流量强度 = La/R。
如果流量强度大于1,则比特到达队列的平均速率大于该队列中比特输出的平均速率,队列会越来越长(流量强度不能大于1)。如果流量强度等于1,说明比特到达队列的平均速率等于该队列中比特输出的平均速率(流量强度不能等于1)。如果流量强度小于1,则比特到达队列的平均速率小于该队列中比特输出的平均速率。
现在考虑流量强度小于等于1的情况。这时,到达流量的性质影响排队时延。如分组周期性到达,即每L/R秒到达一个分组,则每个分组将到达空队列,则无排队时延。如分组以突发性形式到达而不是周期性到达,则可能会有很大的平均排队时延。
丢包
想象一下这样的场景:我们11:30到银行办理业务,发现前面还有好些人排队,于是你只好排队。快到12:00了,你发现前面还有3个人排队,马上就能轮到你了。但是银行工作人员突然说,我们到下班时间了,你们几个人下午再来吧。于是你们几个人只好回家了,而没有办成业务。计算机网络中也有排队,一条链路对的队列往往是有限的容量。因为该排队容量是有限的,随着流量强度接近1,排队时延并不真正趋于无穷大。相反,到达的分组会发现一个满的队列。由于没有地方存储这些分组,路由器将丢弃这些分组。分组也叫包,所以叫丢包。
从端系统的角度看,丢包看起来是一个分组已经传输到网络核心,但它绝不会从网络发送到目的地。分组丢失的比例随着流量强度的增大而增加。
端到端的时延
前面讨论一直聚焦在节点时延上,即在单台路由器上的时延。我们现在来考虑端到端的时延,什么叫端到端的时延呢?所谓端到端,就是指源主机到目的主机。时延端到端的时延就是从源到目的地的总时延。为了理解这个概念,我们假定在源主机到目的主机之间有N-1个路由器,并且此网络此时是不堵塞的(排队时延是微不足道的)。在每台路由器和源主机上的处理时延是d(proc),每台路由器和源主机的输出是Rbps,每条链路的传播时延是d(prop)。节点时延累加起来,得到端到端的总时延:
d(end-end) = N(d(proc) + d(trans) + d(prop)), 其中d(trans) = L/R.
回忆一下,以前学习过的一个公式:通过N条速率均为R的链路组成的路径,从源到目的地发送一个分组。应用如上相同的逻辑,我们看到端到端的时延是:
d(端到端) = NL/R.
L/R就是d(trans). 所以上式是在忽略处理时延,传播时延下的特殊形式。
吞吐量
除了时延和丢包,计算机网络中另一个性能指标是端到端的吞吐量。假设主机A到主机B跨越计算机网络传送一个大文件。例如,也是从一个P2P文件共享系统的一个对等方向另外一个对等方传送一个视频。在任何时间瞬间的瞬时吞吐量是主机B接收到该文件的速率(以bps计)。(许多应用程序包括许多P2P文件共享系统,其用户界面显示了下载期间的瞬时吞吐量)。如果该文件由F比特组成,主机B接收到所有F比特用去T秒,则文件传送的平均吞吐量是F/Tbps。
最后
以上就是结实八宝粥最近收集整理的关于分组交换中的时延,丢包和吞吐量的全部内容,更多相关分组交换中内容请搜索靠谱客的其他文章。








发表评论 取消回复