参考代码:D2Det
1. 概述
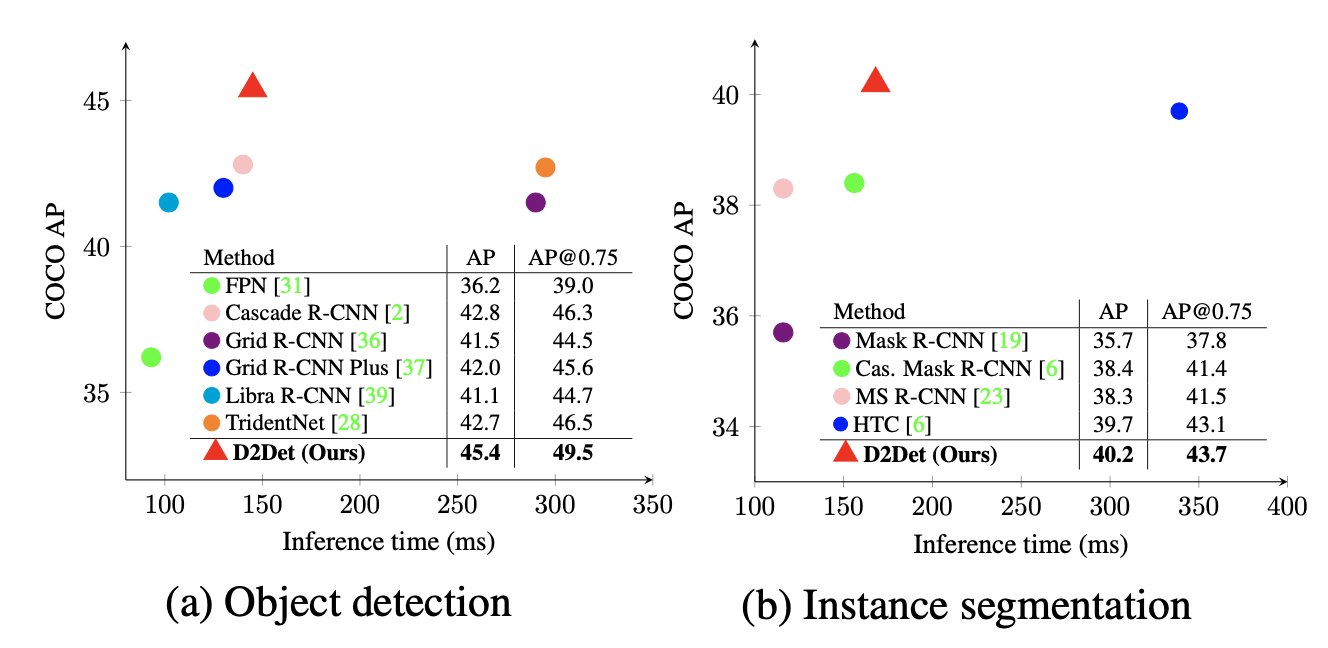
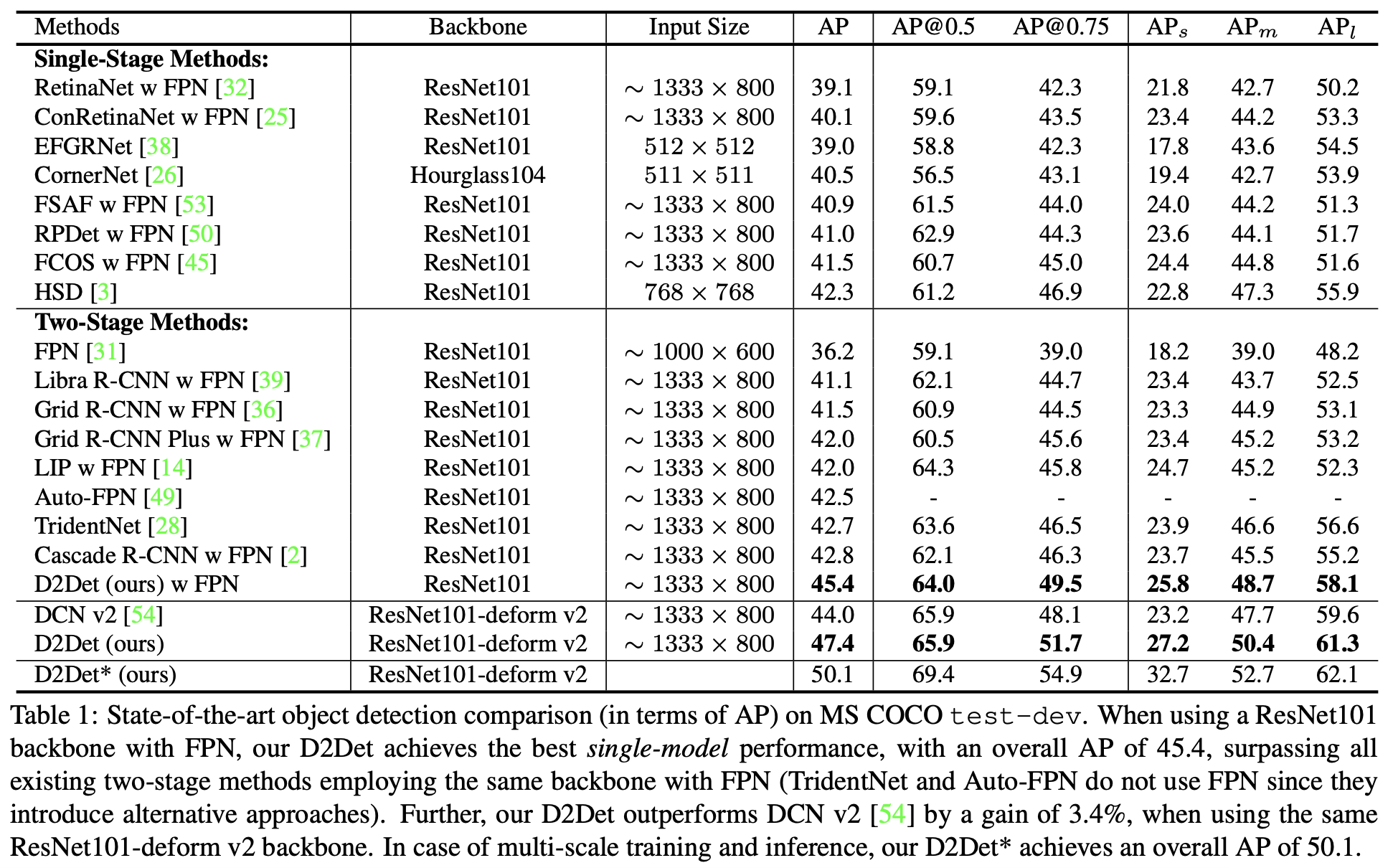
导读:这篇文章提出了一种新的两阶段检测算法,主要的改进点集中在RPN网络之后,从而带来目标定位和目标分类更加准确。对于定位部分的优化这里是使用的是类似Grid RCNN之类的检测框预测方法,因而就可以对一个proposal进行密集预测(dense box),文中提到这样的回归方式会带来更为精确的预测结果,在此基础上引入了二值掩膜重叠预测(GT为对应GT框的内部区域,看作另外一种形式的分割)用以更近一步排除由proposal进行预测得到结果为背景的情况。对于精确的分类结果,文章将原有的RoI-Pooling操作做了具有discriminative属性的判别形式(也就是不同采样区域设置不同的采样权重),从而得到更加具有判别能力的特征。文章的算法在COCO数据集上使用ResNet101作为backbone获得了45.1的AP。
下图是文章的算法与一些检测算法的对比,见下图所示:
2. 方法设计
2.1 网络结构
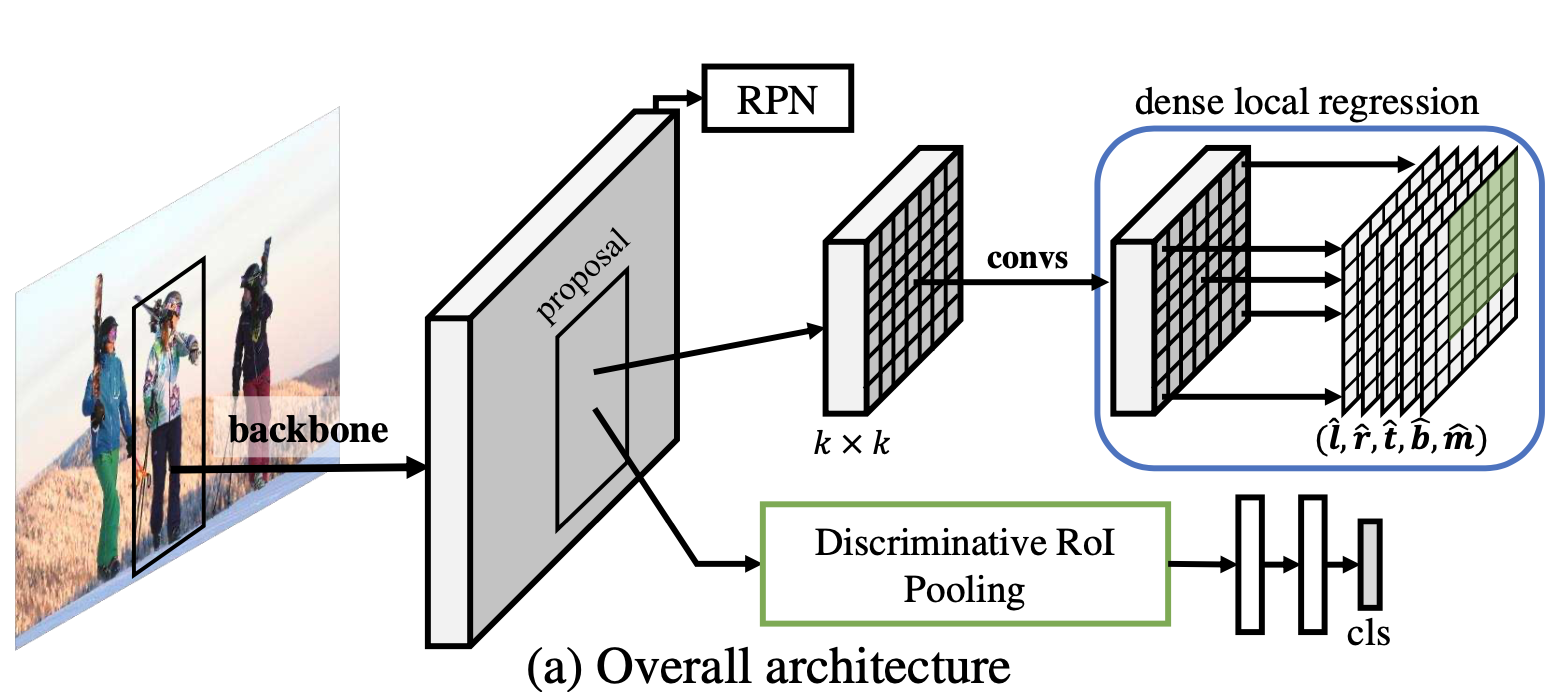
文章的算法是来来自于Faster-RCNN的,主要的改进在最后的预测头部分,下图展示的就是文章的主要网络部分:
2.2 密集的目标回归机制
在Faster RCNN系列的算法中,设RPN网络提取的proposal表示为
P
(
x
P
,
y
P
,
w
P
,
h
P
)
P(x_P,y_P,w_P,h_P)
P(xP,yP,wP,hP),对应的GT表示为
G
(
x
G
,
y
G
,
w
G
,
h
G
)
G(x_G,y_G,w_G,h_G)
G(xG,yG,wG,hG),那么对应的RCNN头部分需要的回归量表示为:
δ
x
=
(
x
G
−
x
P
)
/
w
P
,
δ
y
=
(
y
G
−
y
P
)
/
h
P
delta_x=(x_G-x_P)/w_P, delta_y=(y_G-y_P)/h_P
δx=(xG−xP)/wP, δy=(yG−yP)/hP
δ
w
=
l
o
g
(
w
G
/
w
p
)
,
δ
h
=
l
o
g
(
h
G
/
h
P
)
delta_w=log(w_G/w_p), delta_h=log(h_G/h_P)
δw=log(wG/wp), δh=log(hG/hP)
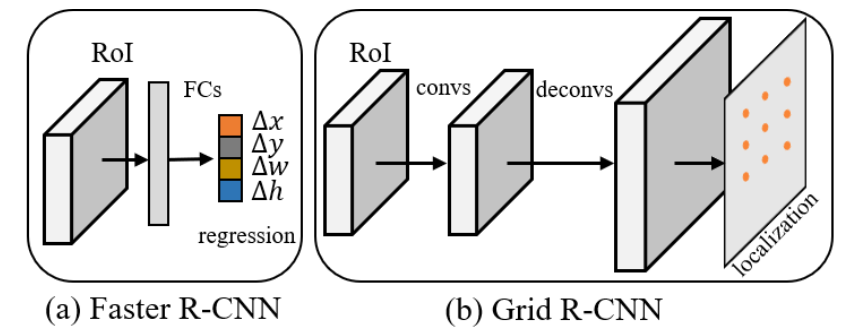
出了使用这种预测数量比较限定的坐标回归方式之外,前面的一些工作提供了一种卷积的预测方式,如Grid RCNN,它是在特征图里面采用了逐像素的预测机制(预测左上和右下的坐标点),同时还引入grid多点监督的方式使得坐标回归更加稳定。这里使用
(
x
l
,
y
t
,
x
r
,
y
b
)
(x_l,y_t,x_r,y_b)
(xl,yt,xr,yb)表示GT目标框,则网络在特征图上的点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)预测的目标偏移量表示为
l
i
^
,
t
i
^
,
r
i
^
,
b
i
^
hat{l_i},hat{t_i},hat{r_i},hat{b_i}
li^,ti^,ri^,bi^,对应的GT描述为:
l
i
=
(
x
i
−
x
l
)
/
w
P
,
t
i
=
(
y
i
−
y
t
)
/
h
P
l_i=(x_i-x_l)/w_P, t_i=(y_i-y_t)/h_P
li=(xi−xl)/wP, ti=(yi−yt)/hP
r
i
=
(
x
r
−
x
i
)
/
w
P
,
b
i
=
(
y
b
−
y
i
)
/
h
P
r_i=(x_r-x_i)/w_P, b_i=(y_b-y_i)/h_P
ri=(xr−xi)/wP, bi=(yb−yi)/hP
这两种检测框预测机制其结构见下面的(a)(b)图所示:
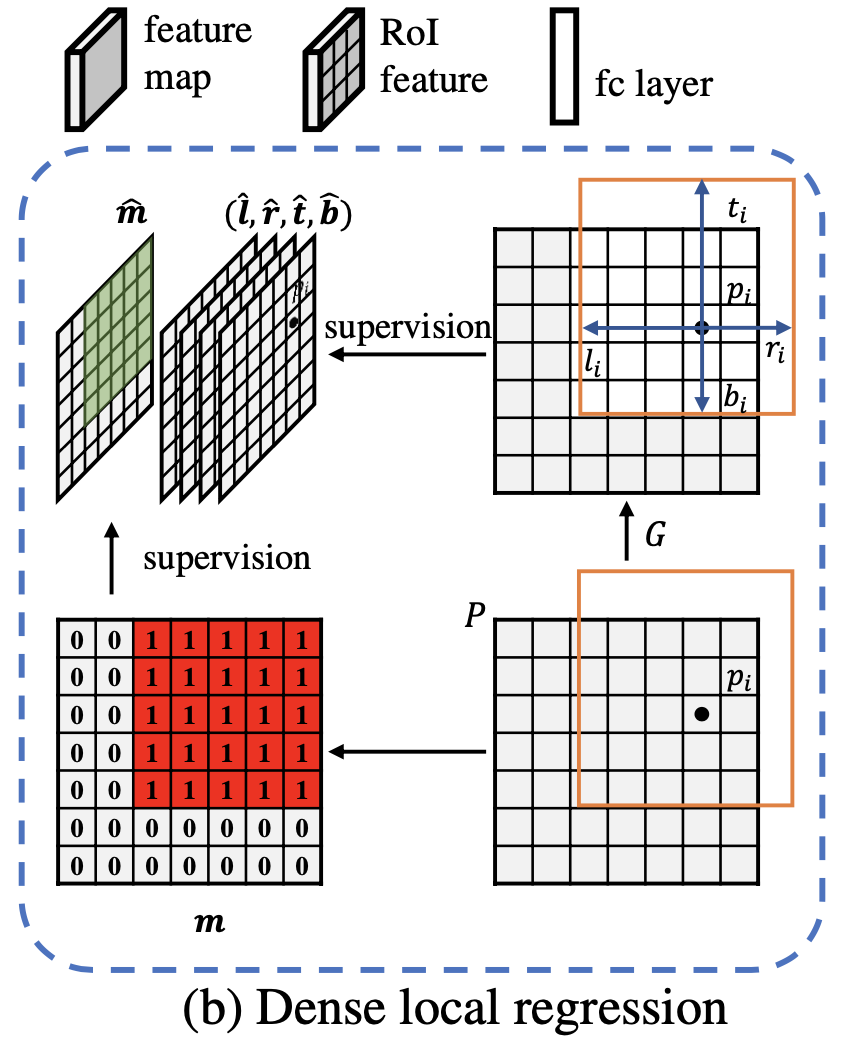
文章的检测框回归方式采用的是与Grid RCNN类似的回归方式,使得回归头可以实现dense prediction,文章在此基础上通过添加一个二值掩膜预测从而更好去区分前景和背景区域。这里对于二值掩膜GT的定义为:
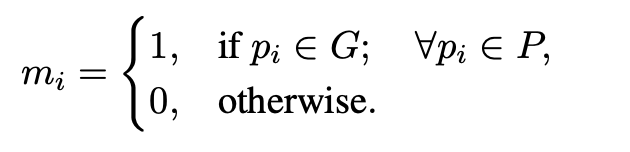
也就是RPN提出的proposal与GT重叠的部分被设置为1,其它区域是0(代表是背景区域)。结合二值掩膜之后整体网络预测为5个分量
(
l
i
^
,
t
i
^
,
r
i
^
,
b
i
^
,
m
i
^
)
(hat{l_i},hat{t_i},hat{r_i},hat{b_i},hat{m_i})
(li^,ti^,ri^,bi^,mi^),之后经过sigmoid进行输出
σ
(
m
i
^
)
>
0.5
sigma (hat{m_i})gt 0.5
σ(mi^)>0.5从而进行损失计算。其结构见下图所示:
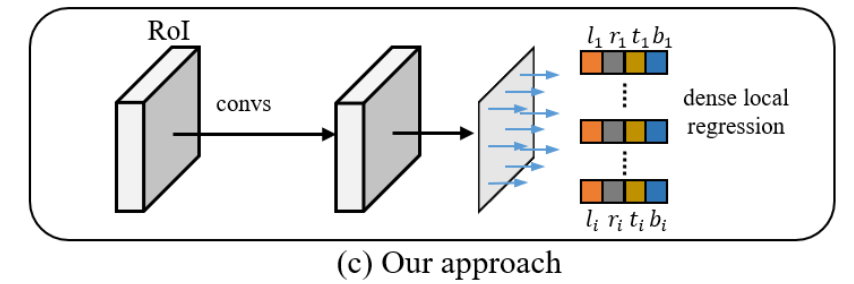
上面的提到的几个部分他们之间的关系见下图所示:
2.3 Discriminative RoI Pooling
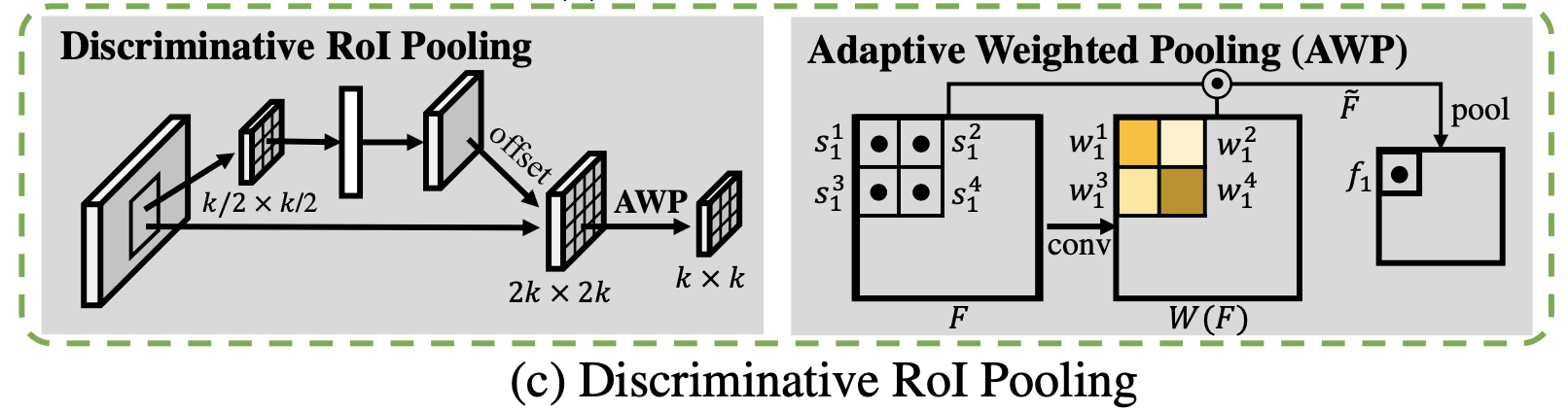
由于目标分类任务需要更加具有判别能力的特征,因而文章借鉴deformable RoI Pooling操作,但是也有一些改进地方:
- 1)对于offset预测的地方使用更小的特征图 ( k 2 , k 2 ) (frac{k}{2},frac{k}{2}) (2k,2k)进行预测,从而减少计算量;
- 2)deformable RoI Pooling中对于特征 F ∈ R 2 k ∗ 2 k Fin R^{2k*2k} F∈R2k∗2ksampling过程中的权值是平均处理的,这里通过一个权值矩阵 W ( F ) ∈ R 2 k ∗ 2 k W(F)in R^{2k*2k} W(F)∈R2k∗2k进行加权实现的,其过程描述为: F ^ = W ( F ) ⊙ F hat{F}=W(F)odot F F^=W(F)⊙F;
下图便是其结构与数据流程:
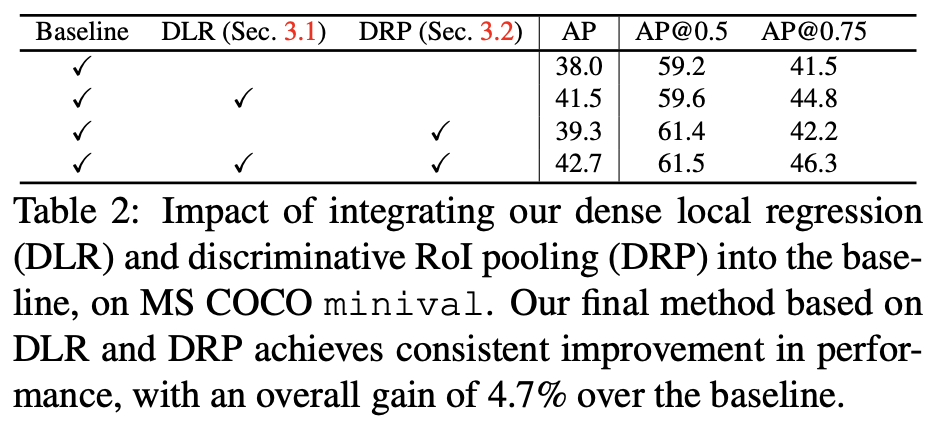
下面表2展示的是文章的dense box和discriminative RoI pooling对性能的影响:
3. 实验结果
最后
以上就是强健八宝粥最近收集整理的关于《D2Det:Towards High Quality Object Detection and Instance Segmentation》论文笔记1. 概述2. 方法设计3. 实验结果的全部内容,更多相关《D2Det:Towards内容请搜索靠谱客的其他文章。








发表评论 取消回复