龙芯3A4000处理器简介
- 1.龙芯 3号功能特征
- 龙芯 3A4000
- 2. 龙芯 3号处理器核
- (一)通用寄存器
- (二) CP0 寄存器
- (三)指令集
- 3. 龙芯电脑基本结构
- 参考链接
- A.1 内存屏障
- (一)优化屏障
- (二)内存屏障
- 侵删
1.龙芯 3号功能特征
本书的重点是计算机类应用,因此主要关注龙芯 3号。目前已经得到大规模应用的龙芯 3号处理器包括四核 3A1000 、八核 3B1500 、四核3A2000 、四核 3A3000 和四核 3A4000 共5款。龙芯 3号的整体架构基于两级互联实现,以四核处理器为例,其结构如图所示。
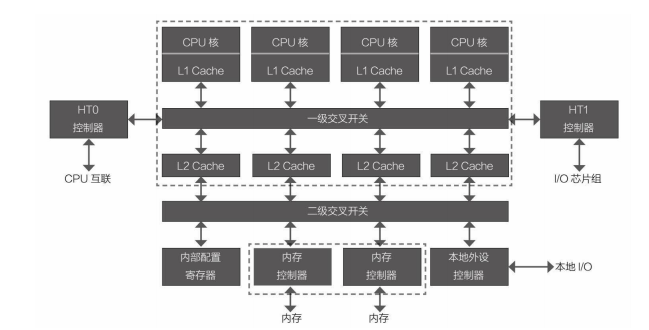
龙芯处理器支持通过 HT 控制器实现多路互联,多路互联意味着一台计算机上有多个处理器芯片(多个物理 CPU )。处理器芯片内部集成内存控制器,这就意味着每个物理 CPU 有自己的 “本地内存 ”,同时又能通过 HT 控制器互联总线访问其他物理 CPU 的“远程内存 ”。这种组织架构就是非均匀内存访问( Non-Uniform Memory Access ,NUMA ),即每个自带内存控制器的独立单元(传统上就是一个物理 CPU )就是一个NUMA 节点。如果硬件负责维护节点间的高速缓存一致性,就叫高速缓
存一致的非均匀内存访问架构( Cache-Coherent Non-Uniform MemoryAccess ,CCNUMA )。龙芯 3号的 NUMA 是一种 CC-NUMA ,每个NUMA 节点由 4个CPU 核组成,四核处理器(龙芯 3A )包含 1个NUMA节点,八核处理器(龙芯 3B )包含 2个NUMA 节点。龙芯 3号每个NUMA 节点包含 4个CPU 核,每个 CPU 核有自己的本地 Cache (一级Cache ,L1 Cache ),节点内的 4个CPU 核共享二级 Cache (分体式共享,分为 4个模块但作为整体被 CPU 核共享)。
NUMA 虽然在内存访问上存在不均匀性,但在运行过程中每个处理器的地位是对等的,因此依旧属于对称多处理器( Symmetric Multi-Processor ,SMP )。或者说,广义的 SMP 系统既包括均匀内存访问的对称多处理器( UMA-SMP ),也包括非均匀内存访问的对称多处理器(NUMA-SMP )。与 SMP 系统相对的是单处理器( Uni-Processor ,UP )系统。
龙芯 3号每个节点的第一级互联采用 6×6 的交叉开关,用于连接 4个CPU 核(作为主设备)、 4个二级 Cache 模块(作为从设备)以及 2个I/O端口(每个端口使用一个 Master 主设备和一个 Slave 从设备)。一级互联开关连接的每个 I/O 端口连接一个 16 位的 HT 控制器,每个 16 位的 HT 端口还可以作为两个 8位的 HT 端口使用。 HT 控制器通过一个 DMA 控制器和一级交叉开关相连, DMA 控制器负责 I/O 端口的 DMA 控制并负责片间一致性的维护。龙芯 3号的 DMA 控制器还可以通过配置实现预取和矩阵转置或搬移。
龙芯 3号每个节点的第二级互联采用 5×4 的交叉开关,连接 4个二级Cache 模块(作为主设备)。从设备一方则包括两个 DDR2/3 内存控制器、本地的低速或高速 I/O 控制器(包括 PCI 、LPC 、SPI 、UART 等)以及芯片内部的配置寄存器模块。在交叉开关上面,所谓主设备,就是主动发起访问请求的主控方;所谓从设备,就是被动接受访问请求并给出响应的受控方。龙芯 3号的两级交叉开关都采用读写分离的数据通道,数据通道宽度为 128 位,工作在与处理器核相同的频率,用以提供高速的片上数据传输。由于基于龙芯 3号可扩展互联架构,因此在组建 NUMA 时,四核龙芯3A 可以通过 HT 端口连接构成 2芯片八核的 SMP 结构或者 4芯片 16 核的SMP 结构。同样,八核龙芯 3B 也可以通过 HT 端口连接构成 2芯片 16 核的SMP 结构。
龙芯 3A4000
龙芯 3A4000 是一款四核龙芯处理器,采用 28 nm 工艺制造,稳定工作主频为 1.8 ~2.0 GHz ,主要技术特征如下。
○ 片内集成 4个64 位的四发射超标量 GS464V 高性能处理器核,支持向量运算扩展指令。
○ 每个核的私有一级 Cache 包含 64 KB 指令 Cache 、64 KB 数据 Cache和256 KB 牺牲 Cache 。片内集成 8 MB 的分体共享二级 Cache (由 4个体模块组成,每个体
模块容量为 2 MB )。
○ 通过目录协议维护多核及 I/O DMA 访问的 Cache 一致性。
○ 片内集成 2个64 位带 ECC 、800 MHz 的DDR3/4 控制器。
○ 片内集成 2个16 位1.6 GHz 的HyperTransport 控制器。
○ 每个 16 位的 HT 端口拆分成两个 8路的 HT 端口使用。
○ 片内集成 2个I2C 、1个UART 、1个SPI 、16 路GPIO 接口。龙芯 3A4000 的顶层结构设计在龙芯 3A2000 和3A3000 的基础上进行了较大幅度的优化,其主要改进如下。
○ 继续采用双 TLB 设计, VTLB 保持 64 项, FTLB 从1024 项增加到2048 项。
○ 调整了片上互联结构,简化了地址路由, I/O 模块间互联采用RING 结构。
○ 优化了 HT 控制器的带宽利用率与跨片延时。
○ 优化了内存控制器结构,增加了 DDR4 内存的支持,并支持内存槽连接加速卡。
○ 规范了配置寄存器空间与访问方式,引入了 CSR 配置寄存器访问机制。
○ 优化了中断控制器结构,支持向量中断分发机制。
○ 增加了 8路互联支持。
○ 全芯片的性能优化提升,在主频不变的情况下性能提高约 50% 。
2. 龙芯 3号处理器核
在逻辑上,一个龙芯 3号处理器核包括主处理器、协处理器 0、协处理器 1、协处理器 2、一级 Cache 、SFB 和TLB 等多个组成部分。
主处理器: 实现整数运算、逻辑运算、流程控制等功能的部件,包括32 个通用寄存器( General Purpose Registers ,GPR )以及 Hi/Lo 两个辅助寄存器。
协处理器 0(CP0 ): 名称是系统控制协处理器,负责一些跟特权级以及内存管理单元( Memory Management Unit ,MMU )有关的功能,至少包括 32 个CP0 寄存器。
协处理器 1(CP1 ): 名称是浮点运算协处理器( FPU ),负责单精度 /双精度浮点运算,包括 32 个浮点运算寄存器( FPR )和若干个浮点控制与状态寄存器( FCSR )。
协处理器 2(CP2 ): 名称是多媒体指令协处理器,负责多媒体指令( MMI 指令)的运算,共享 FPU 的运算寄存器。
一级 Cache (L1 Cache ): 包括 64 KB 指令 Cache (I-Cache )、 64KB 数据 Cache (D-Cache ),从龙芯 3B1500 开始还包括 256 KB 牺牲Cache (V-Cache )。注意,二级 Cache 不属于处理器核的组成部分,而是被多个处理器核共享的。 I-Cache 和D-Cache 采用 VIPT 组织方式, 4路组相联; V-Cache 采用 PIPT 组织方式, 16 路组相联。
SFB :全称 Store Fill Buffer ,是从龙芯 3A2000 开始引入的功能部件,可以大幅优化访存性能。 SFB 位于寄存器和一级 Cache 之间,在功能上可以把 SFB 理解为零级 Cache (L0 Cache ),但是只有数据访问会经过SFB ,取指令直接访问一级 Cache 。
TLB :全称 Translation Lookaside Buffer ,即快速翻译查找表,是为了加速页表访问而引入的一种高速缓存(专属于页表的 Cache )。龙芯 3号的主 TLB 不分指令和数据,因此统称为 JTLB (另有软件透明的uTLB ,分为指令 ITLB 和数据 DTLB ,整个 uTLB 是JTLB 的子集,类似于一级 Cache 和二级 Cache 的关系)。龙芯 3A1000 ~3B1500 每个核有 64 项JTLB (页大小可变因此也叫 VTLB );龙芯 3A2000 、3A3000 除64 项VTLB 以外还有 1024 项页大小固定的 FTLB ;龙芯 3A4000 除64 项VTLB 以外还有 2048 项页大小固定的 FTLB 。VTLB 和FTLB 同属于 JTLB ,前者采用全相联方式,后者采用 8路组相联方式。
根据 MIPS 处理器规范,一个处理器核总共可以有 4个协处理器,但是龙芯 3号只设计了 3个,因此没有 CP3 。
MIPS 处理器核的字节序格式既可以使用大尾端( Big-Endian )也可以使用小尾端( LittleEndian ),但龙芯只支持小尾端格式。
(一)通用寄存器
龙芯处理器核有 32 个通用寄存器( GPR ),在 64 位模式下, GPR 字长均为 64 位;在 32 位兼容模式下, GPR 只有低 32 位可用。所谓通用寄存器,就是可以用作任意用途,不过 0号GPR 是一个特殊的通用寄存器,其值永远为 0。虽然在硬件设计上 GPR 的用途没有特意规定( GPR0 除外),但是在软件使用上遵循一定的约定,这种约定就是应用二进制接口( Application Binary Interface ,ABI )。 MIPS 处理器有 3种常用的ABI :O32 、N32 和N64 (O代表 Old ,旧的; N代表 New ,新的),其主要特征如下。
O32 :只能用 32 位操作数指令和 32 位GPR ,C语言数据类型的 char 、short 、int 、long 和指针分别为 8位、 16 位、 32 位、 32 位和 32 位。
N32 :可以用 64 位操作数指令和 64 位GPR ,C语言数据类型的 char 、short 、int 、long 和指针分别为 8位、 16 位、 32 位、 32 位和 32 位。
N64 :可以用 64 位操作数指令和 64 位GPR ,C语言数据类型的 char 、short 、int 、long 和指针分别为 8位、 16 位、 32 位、 64 位和 64 位。
除了上述数据格式的差别, 3种ABI 的另一个重要区别是 32 个通用寄存器的使用约定不一样,具体如表所示。在内核代码中寄存器编号采用 $n 的形式来表示第 n个通用寄存器,即 GPRn ;寄存器名称也叫助记符,用于表征其功能,在内核代码里面通常使用小写字母,但在文档资料介绍中通常使用大写字母。
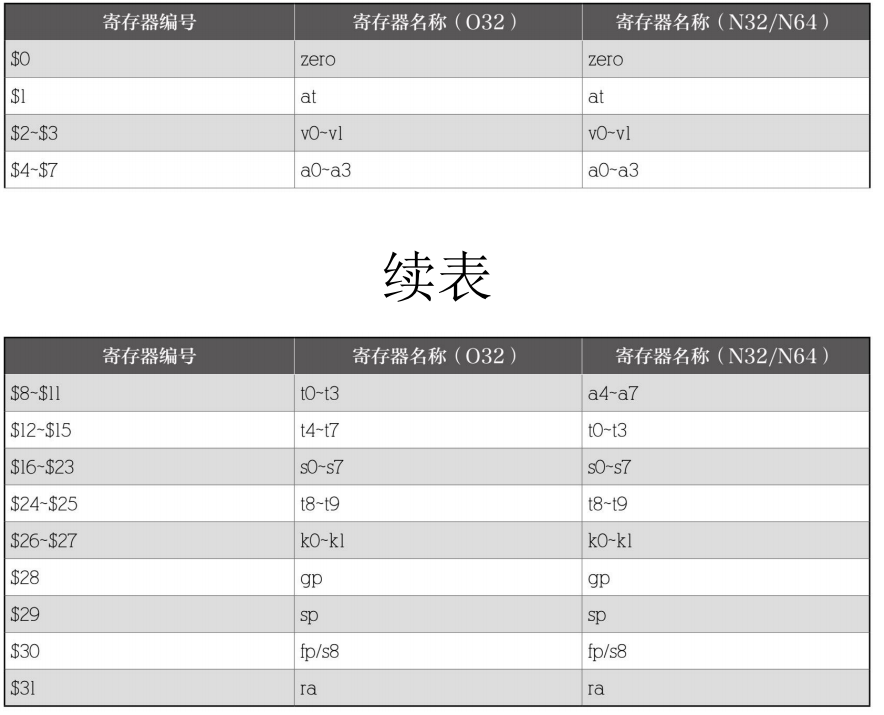
GPR0 :ZERO ,它的值永远为 0,之所以要设置这个寄存器,是因为RISC 使用定长指令( MIPS 的标准指令字长度为 32 位),如果没有零值寄存器,就无法把 32 位/64 位的零操作数编码到指令中。
GPR1 :AT ,是保留给汇编器使用的,用于合成宏指令。宏指令是那些处理器实际上不提供,而由汇编器利用多条指令合成的伪指令,比如加载任意立即数的 li 指令。
GPR31 :RA ,通常用来保存函数返回的地址。
V系列寄存器: 用于保存函数的返回值。
A系列寄存器: 用于传递函数的参数。 N32/N64 与O32 相比有更多的A系列寄存器,因此更有利于使用寄存器而不是堆栈来传递参数。
S系列寄存器: 函数调用时需要保存的寄存器。
T系列寄存器: 可以随意使用的临时寄存器。更确切地说, S寄存器由被调用者负责保存 /恢复, T寄存器由调用者负责保存 /恢复(如果需要的话)。 N32/N64 与O32 相比 T系列寄存器更少,因为它们被用于 A系列寄存器了。
K系列寄存器: 保留给内核在异常处理时使用的,应用程序不应当使用。
GPR28 :GP ,是 Global Pointer (全局指针)的缩写。由于存在大量的进程间共享,应用程序和动态链接库一般被设计成位置无关代码(Position Independent Code ,PIC )。因此,全局变量(更一般地说是全局符号,包括全局函数和全局变量)往往不能通过一个确定的地址直接访问。为了解决这个问题,需要在每个链接单元中引入一个GOT (Global Offset Table ),然后通过 GP 寄存器指向 GOT 表来间接访问这些全局变量。相比之下,内核通常链接在固定的地址(地址有关代码),因此不需要 GOT 表。新版的 Linux 内核也支持重定位,但一台电脑上只运行一个内核,没有共享问题,所以重定位内核可以使用地址修正法而不需要 GOT 表。内核的模块使用了位置无关代码,但内核模块同样没有共享问题;所以在加载模块的时候地址即可唯一确定,因而即便是跨模块的全局符号访问也可以通过 EXPORT_SYMBOL() 等方法来解决。总而言之,内核里对全局函数和全局变量的访问不需要使用 GP ,因此在内核中 GP 通常用来指向当前进程的 thread_info 地址,这样可以优化对当前进程本地数据结构的访问性能。
GPR29 :SP ,是 Stack Pointer (栈指针)的缩写,主要用于访问局部变量(以及栈里面的其他数据)。
GPR30 :FP ,是 Frame Pointer (帧指针)的缩写,用来辅助访问局部变量。 FP 不是必需的,在不需要 FP 的代码里面,可以当 S8 使用。为了理解 SP 和FP ,我们简单介绍一下龙芯 3号( MIPS 通用)的栈结构[3] ,如图所示。
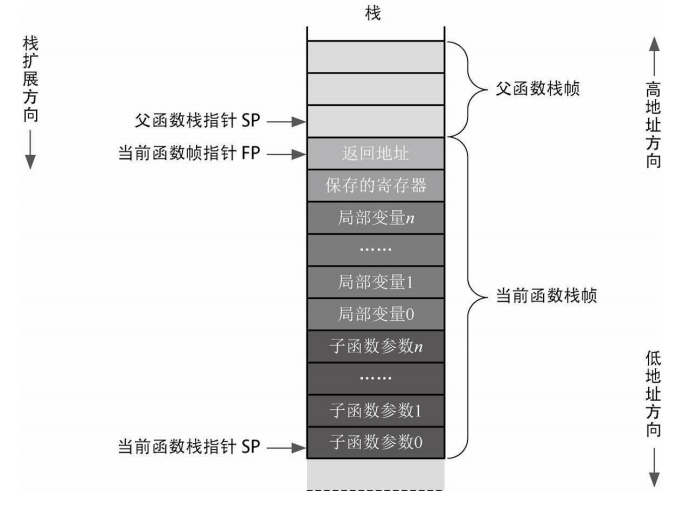
在大多数体系结构的设计中,堆是从低地址往高地址扩展,而栈是从高地址往低地址扩展。龙芯平台的栈设计也是从高地址往低地址扩展,其栈的起始点称为栈底(最高地址),在使用过程中动态浮动的结束点称为栈顶(最低地址)。除了保存局部变量以外,栈的最大作用是保存函数调用过程中的寄存器状态。因此,在函数逐级调用时,栈里面的内容是一段一段的,每一段称为一个栈帧。从高地址往低地址看,首先是父函数(当前函数的调用者)的栈帧,然后是当前函数的栈帧,再然后是子函数的栈帧,依此类推。每一个栈帧的内容是类似的:首先是函数返回地址,然后是需要保存的寄存器,再然后是当前函数用到的局部变量,最后是调用的子函数参数(最下层的叶子函数不需要参数空间)。在大多数情况下,函数调用时子函数的第一步就是调整栈指针SP (从父函数栈帧的最低地址调整到子函数栈帧的最低地址),然后在整个子函数活动时间内 SP 保持不变,因此引用局部变量时有一个固定不变的基地址。但是 C语言运行时库里面可能会提供 alloca() 等函数用于在栈里面分配内存空间,这会导致活动期间 SP 发生变化。在这种情况下,为了方便引用局部变量就会引入 FP ;FP 指向当前栈帧的最高地址并且在函数活动期间不发生变化。注意: MIPS 的ABI 约定优先使用寄存器传递参数,寄存器不够用时才会使用栈传递。但即便如此,栈帧结构里面依旧会给每个参数预留空间,栈帧里面这些不会被使用的参数空间称为影子空间(不管哪种 ABI ,前 4个参数一定会通过 A0 ~A3 寄存器传递,所以栈帧参数空间里面前 4个一定是影子空间)。
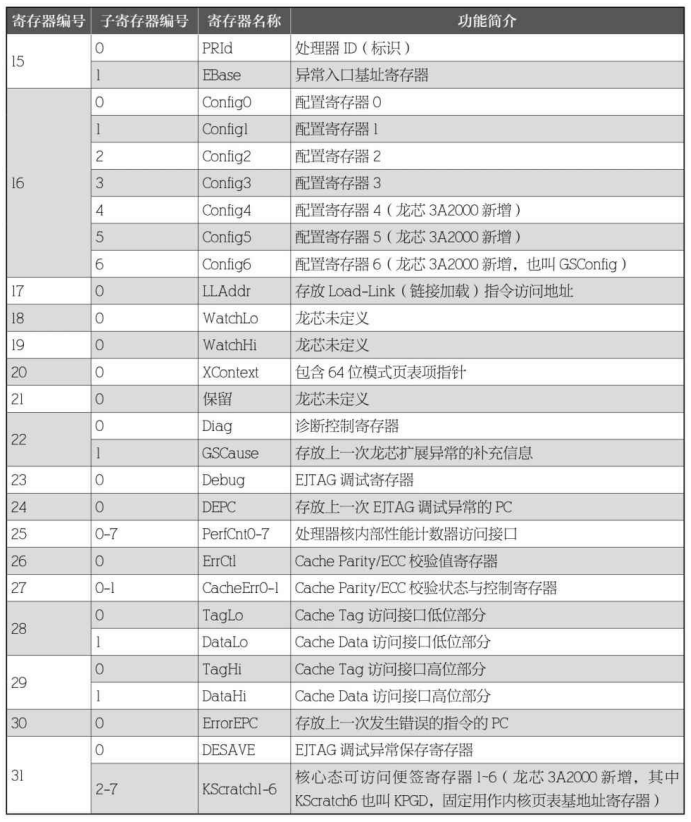
(二) CP0 寄存器
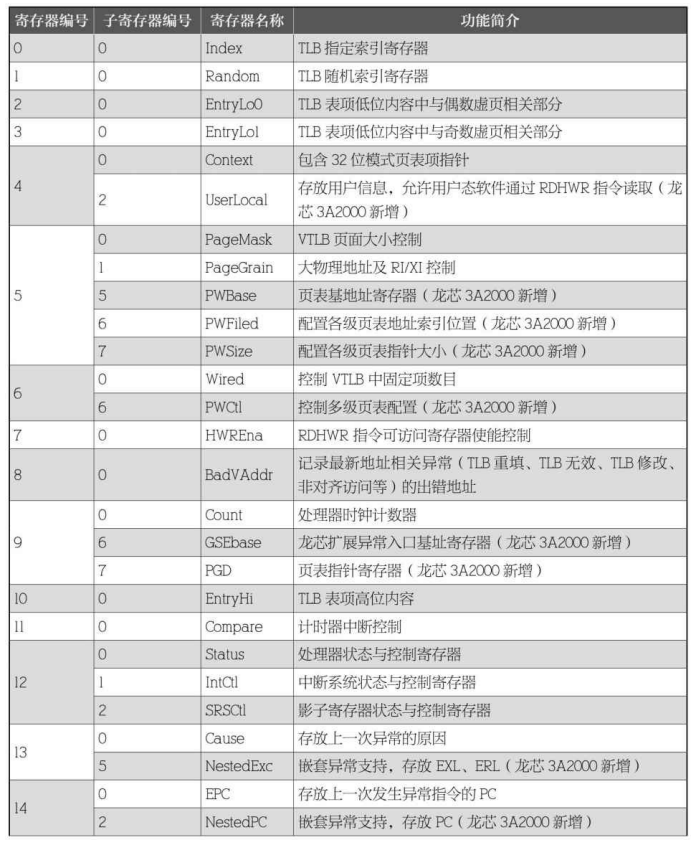
系统控制协处理器( CP0 )拥有至少 32 个寄存器。之所以说 “至少”,是因为某些编号寄存器包含扩展的子寄存器。龙芯 3A2000 (以及更新的处理器)比龙芯 3A1000 、3B1000 、3B1500 拥有更多的扩展,其概述如表所示。
(三)指令集
MIPS 作为一种 RISC 指令集,相对来说是比较精简的,指令名(助
记符)也很有规律。下面分类介绍常用指令。
访存指令: LB 、LBU 、LH 、LHU 、LW 、LWU 、LD 、SB 、SH 、
SW 、SD 、LUI 、LI 、DLI 、LA 、DLA 。
访存指令分为加载指令和存储指令两类,前者是将内存内容读到寄存器,后者是将寄存器内容写入内存。指令名的含义基本上遵循 “操作类型 —操作位宽 —后缀 ”的规律。操作类型是 L(Load ,即加载)或S(Store ,即存储);操作位宽为 B、H、W或D,分别代表 Byte (字节, 8位)、 Half-Word (半字, 16 位)、 Word (字, 32 位)、 Double-Word (双字, 64 位);后缀 U表示加载的数是无符号整数,会对高位进行零扩展而不是符号扩展。例如, LHU 表示加载一个 16 位无符号整数到寄存器,对高位部分进行零扩展。
但是, LUI 、LI/DLI 、LA/DLA 不符合上述规律。 LUI 表示加载高半字立即数,即加载一个无符号 16 位立即数并左移 16 位。 LI/DLI 是宏指令,作用是加载一个任意 32 位/64 位立即数到寄存器。 LA/DLA 也是宏指令,作用是加载一个符号(变量名或函数名)的 32 位/64 位地址到寄存器。
计算指令: ADDI 、ADDIU 、DADDI 、DADDIU 、ADD 、ADDU 、DADD 、DADDU 、SUB 、SUBU 、DSUB 、DSUBU 、MULT 、DMULT 、MULTU 、DMULTU 、DIV 、DDIV 、DIVU 、DDIVU 、MFHI 、MTHI 、MFLO 、MTLO 。
计算指令指整数的加减乘除四则运算,指令名的含义基本上遵循“操作位宽一计算类型一后缀 ”的规律。操作位宽无 D的表示 32 位操作数,有 D的表示 64 位操作数;计算类型分加( ADD )、减( SUB )、乘(MULT )、除( DIV )4种;无后缀的表示两个源操作数都来自寄存器,后缀为 I的表示一个源操作数来自寄存器而另一个源操作数是立即数,后缀为 U的表示无符号操作数(实际含义是溢出时不产生异常),后缀 IU 则是 I后缀和 U后缀的组合。例如, DADDIU 表示 64 位加法指令,一个加数来自寄存器而另一个加数为立即数,运算溢出时不产生异常。两个标准字长的操作数做乘法往往会产生双倍字长的结果,比如 32位操作数乘 32 位操作数的结果可能是 64 位操作数。因此,MIPS 在32 个通用寄存器之外专门设置了 Hi 寄存器和 Lo 寄存器,分别用来保存乘法运算结果的高位字和低位字。在进行除法运算时, Lo 寄存器保存商, Hi 寄存器保存余数。 MFHI/MTHI/MFLO/MTLO 用于在通用寄存器和 Hi/Lo 两个辅助寄存器之间传递数据, MF 指的是 Move From ,MT 指的是 Move
To 。顾名思义, MFHI 就是将 Hi 寄存器中的数据传递到通用寄存器。逻辑指令: AND 、OR 、XOR 、NOR 、ANDI 、ORI 、XORI 。
4种基本运算: AND 是逻辑与, OR 是逻辑或, XOR 是逻辑异或,NOR 是逻辑或非。无后缀 I的指令表示两个源操作数都来自寄存器,有后缀 I的表示一个源操作数来自寄存器而另一个源操作数是立即数。
移位指令: SLL 、SRL 、SRA 、ROTR 、SLLV 、SRLV 、SRAV 、ROTRV 、DSLL 、DSRL 、DSRA 、DROTR 、DSLLV 、DSRLV 、DSRAV 、DROTRV 。
4种32 位基本操作: SLL 是逻辑左移(低位补充零), SRL 是逻辑右移(高位补充零), SRA 是算术右移(高位补充符号位), ROTR 是循环右移(高位补充从低位移出的部分)。其他的可以以此类推,带 D前缀的指令是 64 位操作数,无 V后缀的是固定移位(移位的位数由立即数给出),有 V后缀的是可变移位(移位的位数由寄存器给出)。
跳转指令: J、JR 、JAL 、JALR 、B、BAL 、BEQ 、BEQAL 、BNE 、BNEAL 、BLTZ 、BLTZAL 、BGTZ 、BGTZAL 、BLEZ 、BLEZAL 、BGEZ 、BGEZAL 。
前缀为 J的指令表示绝对跳转(无条件跳转),跳转目标地址是相对PC 所在地址段的 256 MB 边界的偏移;前缀为 B的是相对跳转(有条件跳转,也叫分支指令),跳转目标地址是相对 PC 的偏移。 J类跳转指令里面:无后缀 R表示目标地址为立即数,有后缀 R表示跳转目标为寄存器的值;无后缀 AL 表示普通跳转,有后缀 AL 表示链接跳转(自动保存返回地址到 RA 寄存器,用于函数调用)。 B类分支指令里面: EQ 表示跳转条件为相等( Equal ), NE 表示跳转条件为不相等( Not Equal ),LT 表示跳转条件为小于( Less Than ), GT 表示跳转条件为大于(Greater Than ), LE 表示跳转条件为小于或等于( Less Than or Equal ), GE 表示跳转条件为大于或等于( Greater Than or Equal ), AL后缀表示链接跳转。 B类分支指令里面有一部分是宏指令。例如,BGEZAL 表示若源操作数大于或等于零,就执行相对链接跳转。
协处理器指令: MFC0 、MTC0 、DMFC0 、DMTC0 、MFC1 、MTC1 、DMFC1 、DMTC1 、MFC2 、MTC2 、DMFC2 、DMTC2 。
协处理器指令用于在通用寄存器和协处理器寄存器之间传送数据。MF 表示 Move From ,MT 表示 Move To ;无前缀 D的指令表示操作 32 位协处理器寄存器,有前缀 D的表示操作 64 位协处理器寄存器;后缀 C0 表示协处理器 0,C1 表示协处理器 1,C2 表示协处理器 2。例如, DMFC0 表示从协处理器 0的64 位寄存器传递一个数据到通用寄存器。
MMU 相关指令: CACHE (高速缓存维护)、 TLBP (TLB 查询)、 TLBR (读 TLB 项)、 TLBWI (写 TLB 指定项)、 TLBWR (写TLB 随机项)。
特殊指令: SYNC (内存屏障)、 SYSCALL (系统调用)、ERET (异常返回)、 BREAK (断点)、 EI (开中断)、 DI (关中断)、 NOP (空操作)、 WAIT (暂停等待)。
浮点运算指令和龙芯扩展指令在内核中极少使用,此处不予介绍。
有关寄存器和指令集的更多信息请参阅 MIPS 架构文档、龙芯处理器手册以及《 MIPS 体系结构透视》 [1] 。
3. 龙芯电脑基本结构
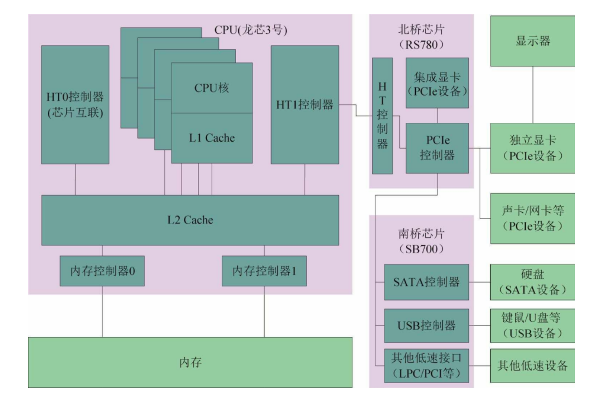
传统的处理器仅仅指的是 CPU 核,而现代的处理器通常包括更多的功能。从处理器结构图可以看出,除 4个CPU 核以外,龙芯处理器还包括本地私有一级 Cache 、共享二级 Cache 、两个内存控制
器和两个 HT 控制器等重要结构。其中内存控制器用于连接内存, HT0 控制器用于多个处理器芯片互联以构建 CC-NUMA 系统, HT1 控制器用于连接芯片组进而挂接各种外围设备。
龙芯 3号处理器可以跟多种芯片组搭配,比如 RS690 (北桥)+SB600 (南桥)、 RS780 (北桥) +SB700 (南桥)、 RS880 (北桥)+SB800 (南桥)、 SR5690 (北桥) +SP5100 (南桥)。以上芯片组都是由美国 AMD 公司出品,互相之间基本保持兼容,故以 RS780 为代表将它们统称为 RS780 机型。除了使用 AMD 芯片组之外,龙芯电脑还可以使用南北桥合一(合在一起称为桥片)的 LS2H 或LS7A ,这两种芯片组都是龙芯中科自产。
在RS780 机型中,龙芯的外围总线总体上是基于 PCI-Express (以下简称 PCI-E 或PCIe )的, PCIe 的根节点位于北桥芯片,下面可以挂接PCIe 显卡(包括北桥内部的集成显卡)、 PCIe 声卡、 PCIe 网卡等高速设备。南桥芯片内部包含各种低速控制器,如 SATA 控制器、 USB 控制器、 PCI 控制器等,这些低速控制器本身是 PCIe 设备,其下挂接的则是各种相应的低速设备。使用 RS780 机型的龙芯电脑基本结构如图所示。
LS2H 是第一款可以用于龙芯 3号处理器的国产桥片,内含 CPU 核,因此也可以当 SoC 用(即龙芯 2H )。 LS7A 则可以视为 LS2H 的升级改进版本,是第一款专门针对龙芯 3号处理器设计的国产桥片(去掉了 CPU核),在功能和性能上有了全面的提升,也是现在使用的主流型号。LS2H/LS7A 机型与 RS780 机型相比没有太大的区别,仅仅是南桥芯片和北桥芯片集成在一起而已。使用 LS2H/LS7A 芯片组的龙芯电脑基本结构如图所示。

从两个架构图的对比可以看出,除了将南北桥芯片集成在一起之外, LS2H/LS7A 机型允许一些低速设备控制器不通过 PCIe 根,而是直接与HT 控制器的内部总线相连接。比如在 LS7A 桥片中, RTC 和I2C 设备直接使用内部总线连接,而 LPC 、SPI 等控制器则通过 PCIe 连接。在 Linux内核中,直接通过内部总线连接的设备叫平台设备( platform device ),因此内部总线也叫平台总线( platform bus )。也就是说,在LS2H/LS7A 机型中,外围设备有 PCIe 总线设备(简称 PCIe 设备)和平台总线设备(简称平台设备)两大类。
根据 PCIe 总线规范, PCIe 设备运行时是可探测的,因此同一套软件可以不做任何变化地应用于不同外设配置的机器上。然而,平台设备运行时却不可以探测,传统上这类设备只能在内核里面静态声明,因而影响可移植性。为了解决这个问题,现在比较常用的方法是设备树(DeviceTree )。设备树是对一台机器上所有平台设备信息的描述(实际上也可以描述其他类型的设备),集成在 BIOS 中并以启动参数的方式传递给 Linux 内核。如果 BIOS 没有传递设备树信息,则内核可以使用默认的设备树描述。在龙芯平台上, LS2H 、LS7A 和RS780 这3种机型的默认设备树描述文件分别是
arch/mips/boot/dts/loongson/loongson3_ls2h.dts、
arch/mips/boot/dts/loongson/loongson3_ls7a.dts和
arch/mips/boot/dts/loongson/loongson3_rs780.dts
从龙芯电脑结构框架图中还可以看出, 4个CPU 核的一级 Cache 与2个HT 控制器一样,都是二级 Cache 的主设备。龙芯处理器在硬件上可以通过目录协议 [4] 来维护 CPU 核间 Cache 一致性,以及 CPU 核与外设 DMA 之间的 Cache 一致性。这种不需要软件处理一致性问题的设计,大大方便了 Linux 内核的开发者。然而,为了满足一些特殊场合的要求,龙芯平台的 Linux 内核既支持一致性 DMA (由硬件维护CPU 核与 DMA 之间的一致性),也支持非一致性 DMA (由软件维护CPU 核与 DMA 之间的一致性)。注意:这里涉及的一致性是指空间一致性( coherency )而不是时序一致性( consistancy )。空间一致性指多个Cache 副本之间的一致性,由龙芯 CPU 硬件负责维护;而时序一致性指多个处理器之间访存操作的顺序问题,通常需要软件和硬件协同解决(参考本书附录 A.1 内存屏障一节)。
参考链接
[1] 仅高配版支持通过 HTO 进行芯片间互联,高配版亦称龙芯 3B2000 。
[2] 仅高配版支持通过 HTO 进行芯片间互联,高配版亦称龙芯 3B3000 。
[3] 在操作系统里面,堆( Heap )和栈( Stack )有着严格的区分,但在有些文献里面把栈称为堆栈。
[4] 硬件维护一致性的协议主要有两大类:侦听协议和目录协议。其基本方法都是本地 Cache (如一级 Cache )与共享 Cache (如二级 Cache )之间通过消息传递来维护每个 Cache 行的状态机。侦听协议要求每个 CPU核都随时侦听总线上的消息,通信代价较大。目录协议则让每个 CPU 核负责一个 Cache 目录,每个 Cache 目录对应整个 Cache 里面的一个子集;CPU 核是 Cache 目录的宿主,本地 Cache 传递消息的时候直接发往宿主而不是广播到总线。龙芯使用的目录协议中, Cache 行的状态分三种:INV (无效,表示没有缓存任何数据)、 SHD (共享,表示多个本地Cache 里面都有相同的数据副本,只能读不能写)和 EXC (独占,表示有一个本地 Cache 要写数据,因此其他本地 Cache 中的数据副本都要无效化)。
A.1 内存屏障
高性能是计算机所追求的一个永恒目标。编译器在优化过程中会对指令重新排序,高性能处理器在执行指令的时候也会引入乱序执行。这些重新排序理论上都是不应该改变源代码行为的,但实际上编译器和处理器只能保证显式的控制依赖和数据依赖没有问题。而源代码中往往存在各种隐式的依赖,这些依赖性如果被破坏就会产生逻辑错误。举个简单的生产者 —消费者案例,生产者和消费者是两个进程,运行在不同的 CPU 上,它们通过一个缓冲区 buffer 交换共享数据,另有一个变量 flag 来标识缓冲区是否准备好。源代码顺序如下。
int flag = 0;
char buffer[64] = {0};
void producer()
{
memset(buffer, 1, 64);
flag = 1;
}
void consumer()
{
char x;
while (!flag) ;
x = buffer[0];
}
按源代码的字面顺序, consumer() 进程应该得到 x=1 的结果,实际上却未必。
原因有以下两点:一是 producer() 中buffer 和flag 本身没有任何显式的控制依赖和数据依赖,因此 flag 的赋值可能先于 memset() 执行;
二是 consumer() 中buffer 和flag 本身也没有任何显式的控制依赖和数据依赖,因此 x的赋值可能先于 while() 循环执行。
很显然,在应用逻辑上 buffer 和flag 是存在依赖的,但这种依赖无法被编译器和处理器识别。因此,我们必须人工加上屏障来保证顺序,以对抗指令重排和乱序执行(尤其是访存指令的乱序),得到正确的结果。
对抗编译器指令重排的屏障叫优化屏障,对抗处理器乱序执行的屏障叫内存屏障。屏障就像一条界线,禁止屏障前的操作和屏障后的操作乱序。
内存屏障包含了优化屏障的功能,优化屏障也可视为一种弱化的内存屏障。
(一)优化屏障
优化屏障定义如下。
#define barrier() __asm__ __volatile__("": : :"memory")
优化屏障 barrier() 是一个 __asm__ 内嵌汇编语句,本身并不产生任何额外的指令。但是,内嵌汇编中的 __volatile__ 关键字可以禁止该__asm__语句与其他指令重新组合;而 memory 关键字强制让编译器假定该__asm__ 语句修改了内存单元,让该语句前后的访存操作生成真实的访存指令而不会通过寄存器来进行优化。优化屏障可以防止编译器对前后的访存指令重新排序,但并不能防止处理器的乱序执行。在生产者 —消费者示例中,如果处理器是顺序执行的,那么插入优化屏障即可保证逻辑正确。
int flag = 0;
char buffer[64] = {0};
void producer()
{
memset(buffer, 1, 64);
barrier();
flag = 1;
}
void consumer()
{
char x;
while (!flag) ;
barrier();
x = buffer[0];
}
为了方便对抗单个变量读写的编译器优化, barrier() 还有 3个变种:READ_ONCE() 、WRITE_ONCE() 和ACCESS_ONCE() ,使用方法如下。
○ a = READ_ONCE(x) :功能上等同于 a = x ,但保证对 x生成真实的读指令而不被优化;
○ WRITE_ONCE(x, b) :功能上等同于 x = b ,但保证对 x生成真实的写指令而不被优化。
○ ACCESS_ONCE() :a = ACCESS_ONCE(x) 等价于 a =READ_ONCE(x) ,ACCESS_ONCE(x) = b 等价于 WRITE_ONCE(x, b) ,READ_ONCE() 和WRITE_ONCE() 是从 Linux-3.19 版本开始才引入的,在那之前只能用 ACCESS_ONCE() 。
ACCESS_ONCE() 有缺陷,只能针对不超过处理器字长的数据类型,否则无法保证原子性。 READ_ONCE() 和WRITE_ONCE() 没有这样的缺陷,它们在超过处理器字长的数据类型(比如大结构体和大联合体)上会退化成使用 memcpy() 来读写。自从 READ_ONCE() 和WRITE_ONCE() 被引入, ACCESS_ONCE() 就属于计划淘汰的 API (已从Linux-4.15 版本开始正式淘汰)。
(二)内存屏障
内存屏障用于解决内存时序一致性(即内存有序性)问题。 CPU 的内存时序一致性模型有严格一致性、顺序一致性、处理器一致性、松散一致性(弱一致性)等模型,此处不予展开。现代高性能 CPU ,包括龙芯在内,大多使用松散一致性模型,访存指令会存在乱序执行的情况。
对抗访存指令在处理器上乱序执行的内存屏障有很多种,主要列举如
下。
mb() :全屏障,可以对抗读内存操作( Load )和写内存操作(Store )的乱序执行。
rmb() :读屏障,可以对抗读内存操作( Load )乱序执行,不干预写内存操作( Store )。
wmb() :写屏障,可以对抗写内存操作( Store )乱序执行,不干预写内存操作( Load )。
**smp_mb() **:多处理器版全屏障,在多处理器系统上等价于 mb() ,可以对抗读内存操作( Load )和写内存操作( Store )的乱序执行;在单处理器上等价于优化屏障 barrier() 。
smp_rmb() :多处理器版读屏障,在多处理器系统上等价于 rmb() ,可以对抗读内存操作( Load )乱序执行,不干预写内存操作( Store );在单处理器上等价于优化屏障 barrier() 。
smp_wmb() :多处理器版写屏障,在多处理器系统上等价于wmb() ,可以对抗写内存操作( Store )乱序执行,不干预写内存操作(Load );在单处理器上等价于优化屏障 barrier() 。
一般来说,单处理器虽然也存在乱序执行,但对于同一个处理器来说是符合内部完全自洽的。也就是说运行在同一个处理器上的两个进程(或者更一般地说,两个内核执行路径)所看到的内存时序应当是一致的,乱序执行也不会导致逻辑问题。正因为如此,多处理器版的内存屏障smp_mb()/smp_rmb()/smp_wmb() 在单处理器配置上等价于一个优化屏障barrier() 。
然而,除了多处理器之间存在内存一致性问题,处理器与外设之间(主要是 DMA 控制器)也存在内存一致性问题,因此我们需要强制性内存屏障 mb()/rmb()/wmb() 来解决。
读屏障和写屏障应当成对使用,写端 CPU 上必须用写屏障,读端CPU 上必须用读屏障。也就是说在生产者 —消费者示例中,如果处理器是乱序执行的,那么生产者(写端 CPU )插入写屏障,消费者(读端CPU )插入读屏障才可以保证逻辑正确(缺一不可,用错也不行)。
int flag = 0;
char buffer[64] = {0};
void producer()
{
memset(buffer, 1, 64);
smp_wmb();
flag = 1;
}
void consumer()
{
char x;
while (!flag) ;
smp_rmb();
x = buffer[0];
}
当然,强屏障总是可以代替弱屏障。比如全屏障可以代替读屏障和写屏障,而强制性屏障可以代替多处理器版屏障,内存屏障可以代替优化屏障。只不过强屏障一般会比弱屏障更慢,性能损失更多。在龙芯上,读屏障、写屏障和全屏障都是一条 sync 指令,但在语义上,不同的屏障其功能要求是不一样的。
一般来说,内存屏障仅仅是一条界线,能够保证界线前后的访存指令不会交错执行。比如:读屏障可以保证屏障后 Load 指令执行之前,所有屏障前的 Load 指令已经执行完成;写屏障可以保证屏障后 Store 指令执行之前,所有屏障前的 Store 指令已经执行完成;全屏障可以保证屏障后Load/Store 指令执行之前,所有屏障前的 Load/Store 指令已经执行完成。但是,在语义上,内存屏障并不保证在屏障本身执行完成的时候,屏障前的有关访存指令已经执行完成。 尽管处理器可以设计成屏障指令
保证访存完成(比如龙芯用于实现内存屏障的 sync 指令就具有保证访存完成的功能),但内存屏障的语义要求并不需要这样。
多处理器版屏障还有一些变种,比如 smp_mb__before_atomic() 和 smp_mb__after_atomic(),分别用在原子操作的前后,在实现上大都等价于smp_mb() 。
在一些内存一致性非常弱的体系结构上,比如 Alpha 或者国产申威处理器上,需要一种叫数据依赖屏障的特殊内存屏障。 Linux 内核对数据依赖屏障的定义有两个,分别是强制性屏障read_barrier_depends() 和多处理器版屏障 smp_read_barrier_depends() ,其实现相当于一个弱化版
的读屏障(因而也可以用读屏障来代替)。 X86 、龙芯等大多数架构不需要数据依赖屏障。
另外有一些内存屏障是用来解决 CPU 与外设之间内存一致性问题的,举例如下。
**dma_rmb() **:DMA 读屏障。在设备 →CPU 方向( From Device )的DMA 中,设备是写端, CPU 是读端, CPU 在读取标识变量和读取数据之间,必须插入 DMA 读屏障。
dma_wmb() :DMA 写屏障。在 CPU→ 设备方向( To Device )的DMA 中, CPU 是写端,设备是读端, CPU 在写入数据和写入标识变量之间,必须插入 DMA 读屏障。
mmiowb() :MMIO 寄存器写屏障。对于设备的 MMIO 寄存器的写操作有时候是不允许乱序的,在这些场景下需要用 MMIO 寄存器写屏障。
以上提到的所有内存屏障都是双向的,也就是说,内存屏障既要关注屏障前的访存操作,也要关注屏障后的访存操作。但是内核也提供一些隐式的单向屏障功能,比如 ACQUIRE 操作和 RELEASE 操作。ACQUIRE 的语义是 ACQUIRE 操作后面的访存必须在 ACQUIRE 操作之后完成,但并不关注 ACQUIRE 操作前面的访存; RELEASE 的语义是RELEASE 操作前面的访存必须在 RELEASE 操作之前完成,但并不关注RELEASE 操作后面的访存。后面提到的原子操作变种就有带 ACQUIRE 和RELEASE 语义的版本。另外,加锁操作通常意味着 ACQUIRE 操作,而解锁操作通常意味着 RELEASE 操作。
关于内存屏障的更多信息可参阅内核文档 Documentation/memory-barriers.txt。
侵删
最后
以上就是紧张苗条最近收集整理的关于龙芯3A4000处理器简介的全部内容,更多相关龙芯3A4000处理器简介内容请搜索靠谱客的其他文章。








发表评论 取消回复