论文链接:https://arxiv.org/pdf/2007.08988.pdf
代码:https://github.com/rpautrat/LISRD
文章主要内容
本文指出当前特征描述子的局限性在于通用性和区分性的取舍:如果一种描述子有很好的不变形,这也意味着它包含更较少的特征信息。论文通过分解局部描述子中的不变性并在给定上下文的情况下,在线选择最合适不变性的方式来克服此限制。
文章主要贡献
1、使用一个网络,通过多任务学习的方式学习出适应多种变化组合的描述子。
2、提出一种轻量级的meta descriptor方法,根据当前情况,自动选择拥有最好不变性特征的描述子。
3、提出的meta descriptor和不变性选择方法可以轻易地移植到大多数的特征点提取器和描述器中,也可以运用到传统的方法中,通用性好。
算法分析
总体流程分两步。第一步:设计一个网络学习几类稠密的描述子,每一类都有不同的不变性特征;第二步:在匹配本地描述子时,决定最好的不变性特征并使用。
文中选择了旋转(rotation)和光照(illumination)两种影响因素,相比之前希望通过一个描述子同时适应所有情况的方法,本文生成了四种组合的描述子按照这两种影响因素的排列组合分别对应如下四种变化:
1、rotation variance+illumination variance
2、rotation invariance+illumination variance
3、rotation variance+illumination invariance
4、rotation invariance+illumination invariance
网络结构如下图所示:
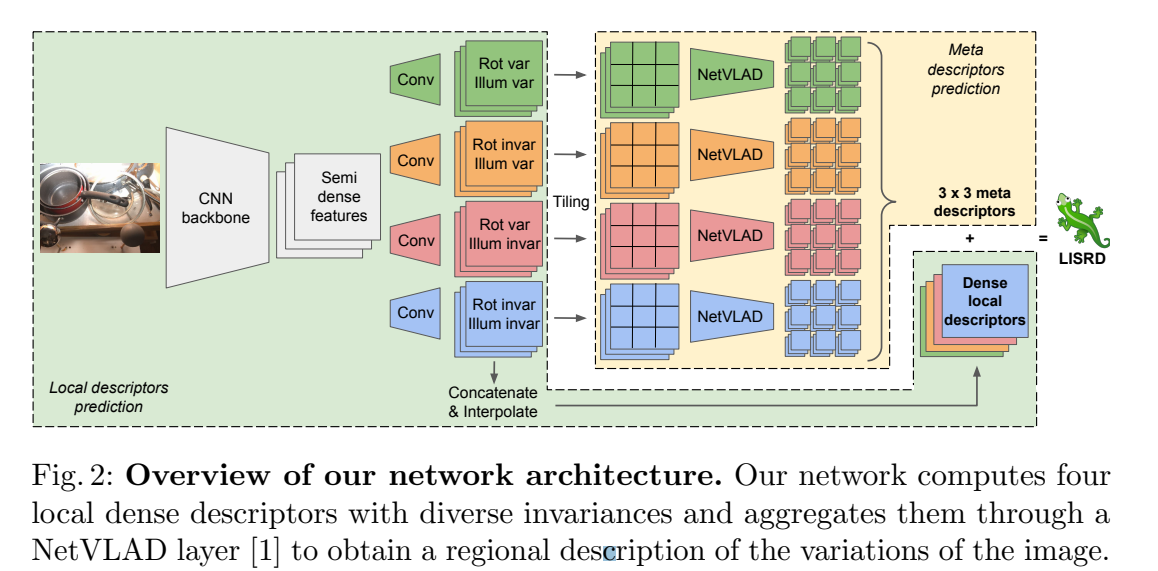
网络受Superpoint启发,以RGB图像为输入,通过卷积神经网络计算半稠密特征图,然后将其分为四块,预测各自的半稠密描述子(针对上述四种组合的一种)。同时,共享的卷积神经网络,即图中的CNN backbone,通过共享计算,可以简化图中Conv(四个子网络)的规模,进而简化计算,从而保准网络的速度。
数据库准备:
训练数据库由三部分组成:
1、anchor image
I
A
I^A
IA:来自真实图片的数据库(原图)
2、variant image
I
V
I^V
IV:包含无旋转的 Homography,亮度变化与原图相同
3、invariant image
I
I
I^I
II:包含与原图不同的旋转和亮度变化
训练损失:
本文使用SIFT特征点,记两幅待匹配图像分别为
I
a
I^a
Ia和
I
b
I^b
Ib,两幅图像通过单应矩阵
H
H
H关联,
I
a
I^a
Ia中的n个特征点记为
x
1..
n
a
x^a_{1..n}
x1..na,通过单应矩阵
H
H
H得到
I
b
I^b
Ib对应的特征点
x
1..
n
b
x^b_{1..n}
x1..nb。。我们将通过下面的描述定义一种通用的 triplet loss 表达方式。
从
x
1..
n
a
x^a_{1..n}
x1..na中提取的描述子记为
d
1..
n
a
d^a_{1..n}
d1..na,从
x
1..
n
b
x^b_{1..n}
x1..nb中提取的描述子记为
d
1..
n
b
d^b_{1..n}
d1..nb,通过
L
2
L_2
L2归一化定义距离,二者距离定义为:
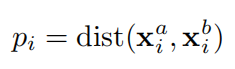
除此之外,triplet loss增加了负距离
n
i
n_i
ni,定义为
x
i
a
x_i^a
xia到
I
b
I^b
Ib中负样本点
x
n
b
(
i
)
b
x_{n_b(i)}^b
xnb(i)b的距离,对
x
i
b
x_i^b
xib同理,于是这一部分可以定义为:
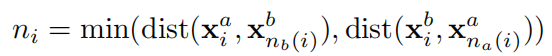
其中,
n
b
(
i
)
=
a
r
g
m
i
n
j
∈
[
1
,
n
]
(
d
i
s
t
(
x
i
a
,
x
j
b
)
)
s
.
t
.
∣
∣
x
i
a
−
x
j
b
∣
∣
2
>
T
n_b(i)=arg min_{jin[1,n]}(dist(x_i^a,x_j^b)) s.t. ||x_i^a-x_j^b||_2 >T
nb(i)=argminj∈[1,n](dist(xia,xjb))s.t.∣∣xia−xjb∣∣2>T,
n
a
(
i
)
n_a(i)
na(i)同理。
给定 margin M 则典型的 triplet margin loss 定义为:
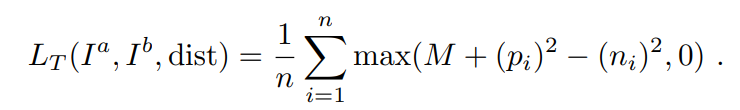
invariant descriptor 的 loss
L
I
L_I
LI是上式的一个特例,对应于anchor image
I
A
I^A
IA和invariant image
I
I
I^I
II,利用
L
2
L_2
L2归一化,可以表示为:
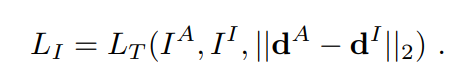
针对variant descriptors的损失
L
V
L_V
LV是基于
I
A
I^A
IA、
I
I
I^I
II和
I
V
I^V
IV三个变量的,它在保证
I
V
I^V
IV和
I
A
I^A
IA、
I
I
I^I
II不同的同时,希望保留
I
V
I^V
IV和
I
A
I^A
IA的相似性,具体表示为:
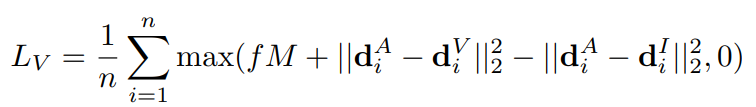
其中,
f
f
f是控制
I
A
I^A
IA和
I
I
I^I
II不同程度的参数。对于旋转变换,
f
=
m
i
n
(
1
,
θ
I
θ
m
a
x
)
f=min(1,frac{theta_I}{theta_{max}})
f=min(1,θmaxθI),
θ
I
theta_I
θI是
I
A
I^A
IA和
I
I
I^I
II之间的绝对旋转角,
θ
I
theta_I
θI是代表阈值的超参数,当超过该阈值的时候,两张图片被认为不同。该阈值确保了只有大的旋转会被损失函数惩罚。由于两张图片的光照区别很难比较,光照针对
I
A
I^A
IA和
I
I
I^I
II的
f
f
f函数设置为1。
对于变化和不变的描述子分别使用
L
V
L_V
LV或者
L
I
L_I
LI,定义
L
I
/
V
(
d
)
L_{I/V}(d)
LI/V(d)为选择的损失,针对局部描述子的总损失可以定义为:
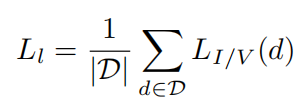
在线选择最佳不变性特征点
有了这些描述子之后,如何获得匹配图片最相关的不变性特征点呢?由于重计算和比较每一对匹配图片变化特征点的代价太大,论文提出只用描述子信息实现选择的方法。一种通俗的方法就是分别计算不同局部描述子的相似性,然后选择最相似的。然而,不变性特征点可以通过更多的上下文信息获得,并且这些不变性特征点应该和附近的描述子一致。因此,论文建议从局部描述子中提取区域描述子,并使用它们来指导不变性选择。
因此,本地描述子通过NetVLAD层收集在相邻区域中,以获取与本地描述子的子集共享相同类型不变性的meta descriptor,但是上下文比单个本地描述子更多。 因此,具有相似的meta descriptor意味着共享相同级别的变化。 通过将图像平铺为c×c网格并为每个图块计算一个meta descriptor来创建相邻区域。 因此,我们获得每个图块四个meta descriptor,然后对其进行
L
2
L_2
L2归一化。
当匹配图块的局部描述子时,meta descriptor之间的四个相似度是用标量积计算的,我们可以根据这些相似度对四个局部描述子进行排序。 我们不使用仅采用最接近的本地描述子的方法来做出艰难的选择,而是使用软分配。 将softmax操作应用于这四个相似度,以获得四个权重之和。 然后将这些权重用于计算局部描述子之间的距离,如下图所示:
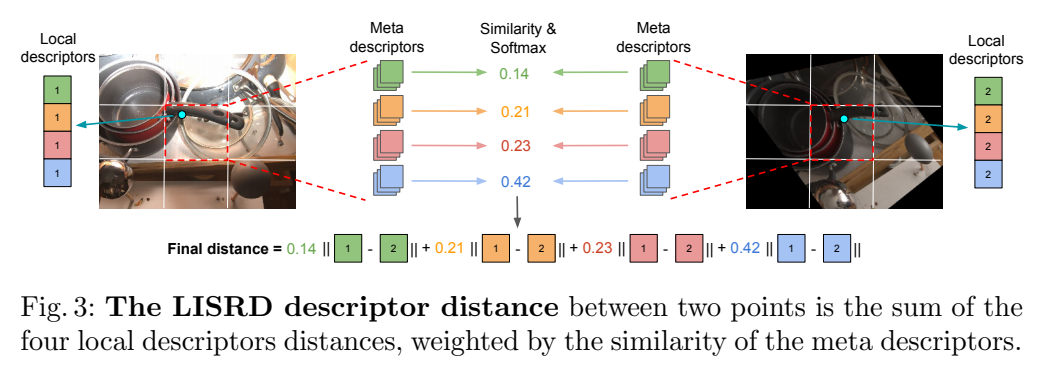
假设需要计算
I
A
I^A
IA中的点
x
a
x^a
xa和
I
B
I^B
IB中的点
x
b
x^b
xb点,
x
a
x^a
xa和4个本地描述子
d
1..4
a
d^a_{1..4}
d1..4a相关联,并对应4个meta descriptor
m
1..4
a
m^a_{1..4}
m1..4a,
x
b
x^b
xb同理。最终,
x
a
x^a
xa和
x
b
x^b
xb的最终描述子距离为:
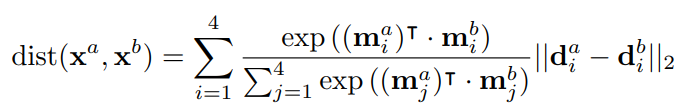
对于 4 个 NetVLAD 层的训练只需使用 weakly supervised 方法即可,不需要监督。同样使用上面提到的 triplet loss,只不过这里的 descriptor 换成了 meta descriptors:
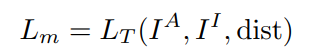
最终两部分总的 Loss 为加权和:
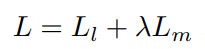
训练细节
为了训练在旋转和照度方面具有不同方差水平的描述符,需要提供所有可能的变化组合的数据集。主要依靠了四个数据集,分别是:MS COCO、 Multi-Illumination Images in the Wild、 Aachen dataset和Virtual Image Dataset for Illumination Transfer (VIDIT)。
受VGG16启发的骨干网由连续的3×3卷积层组成,通道大小为64-64-64-64-128-128-256-256。 每个conv层后均进行ReLU激活和批量归一化。 每隔两层,应用步幅为2的2×2平均池将空间分辨率降低2。对于大小为H×W×3的图像,输出特征图的大小将为H/8×W/8×256。本地描述符头全部由以下操作组成:通道大小256的3×3转换-ReLU-Batch Norm-通道大小128的1×1转换。因此,每个本地描述符的最终尺寸为H/8 × W/8×128,每个串联的描述符为512维。
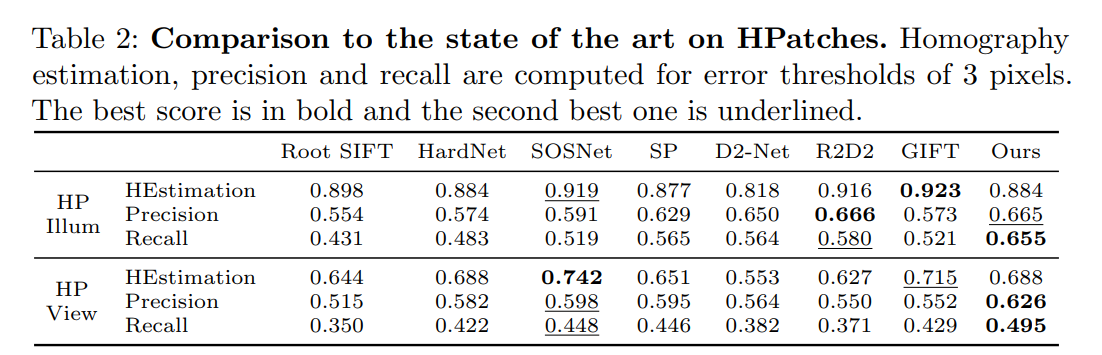
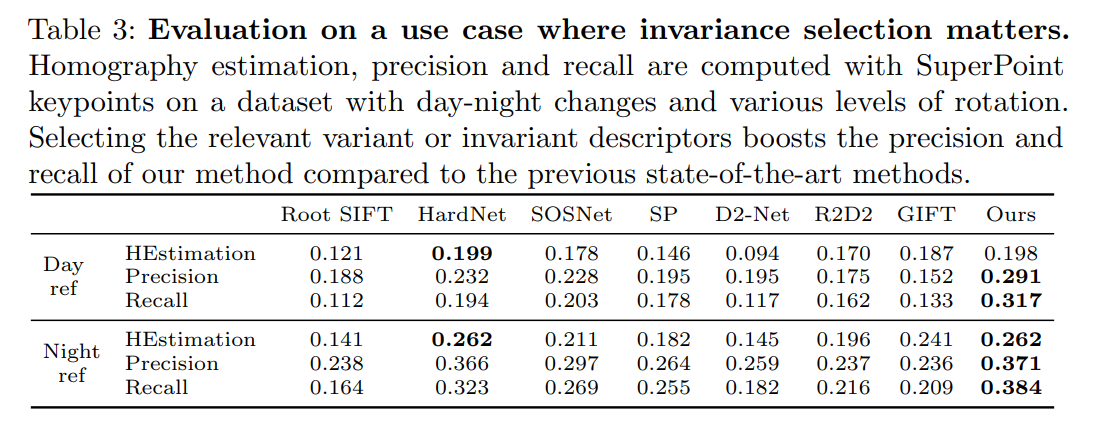
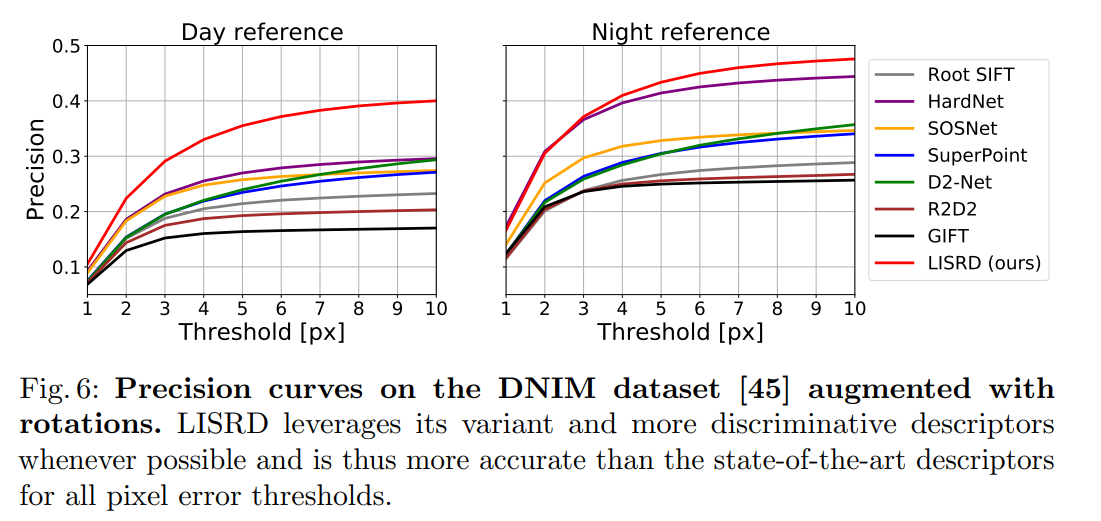
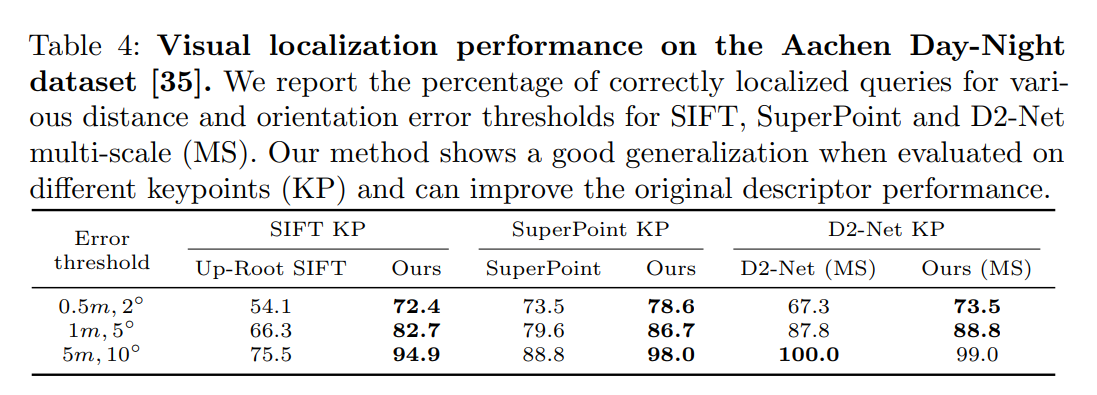
实验结果
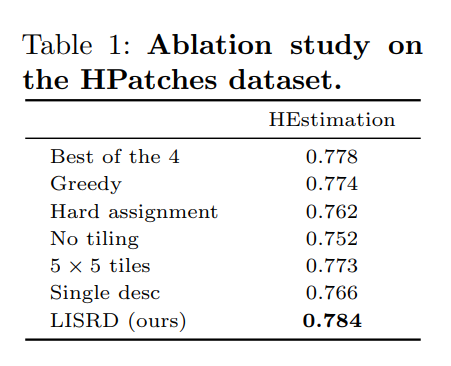
其中:
Best of the 4 是对 4 种 descriptors 都进行匹配,然后就选距离最小的一类;
Greedy 是每个 keypoint 都分别对 4 种 descriptor 进行匹配然后每个都找距离最近的;
Hard assignment 是不使用权重,直接通过 meta descriptor 选择固定的一类。
No tiling 和 5x5 是表示划分网格的多少。
Single desc 表示仍然采用这个网络进行训练得到 4个 descriptor 但将4个 concat 成1个并对所有光照和旋转进行训练。
最终可以看出本文中提出的策略的有效性,每个步骤都起了一定的涨点作用。
最后
以上就是幸福帆布鞋最近收集整理的关于Online Invariance Selection for Local Feature Descriptors论文笔记文章主要内容文章主要贡献算法分析实验结果的全部内容,更多相关Online内容请搜索靠谱客的其他文章。





![[ECCV2018]Person Search via A Mask-Guided Two-Stream CNN ModelContribution](https://www.shuijiaxian.com/files_image/reation/bcimg10.png)


发表评论 取消回复