1 背 景
1.1 3D目标检测
3D目标检测是通过输入传感器数据,预测3D目标的属性信息的任务。如何表示3D目标的属性信息是关键,因为后续的预测和规划需要这些信息。在大部分情况下,3D目标被定义为一个立方体,(x,y,z)是立方体的中心坐标,l,w,h是长宽高信息,delta是航向角,比如立方体在地平面的偏航角,class是3D目标的类别。vx、vy描述3D目标在地面上沿x轴和y轴方向的速度。在工业应用中,一个3D目标的参数可以进一步简化为BEV上一个长方体的4个角位置。
如今在自动驾驶应用场景中,3D目标检测一般基于摄像机、LiDAR或者两者融合来进行,LiDAR传感器更贵,但是通过LiDAR能获得实时的深度图像和点云。
与2D检测相比,基于点云的3D目标检测需要处理不规则的点数据,而且同时基于点云和图像的检测需要特殊的融合机制;3D目标检测是多视角的,如BEV、点视图、圆柱形视图等;3D目标检测需要更加精准的定位信息,它不像2D检测中几像素的位置偏差仍然能够获取非常不错的IoU,驾驶场景中,几像素的偏差很有可能在检测行人时出现致命错误。
1.2 数据集
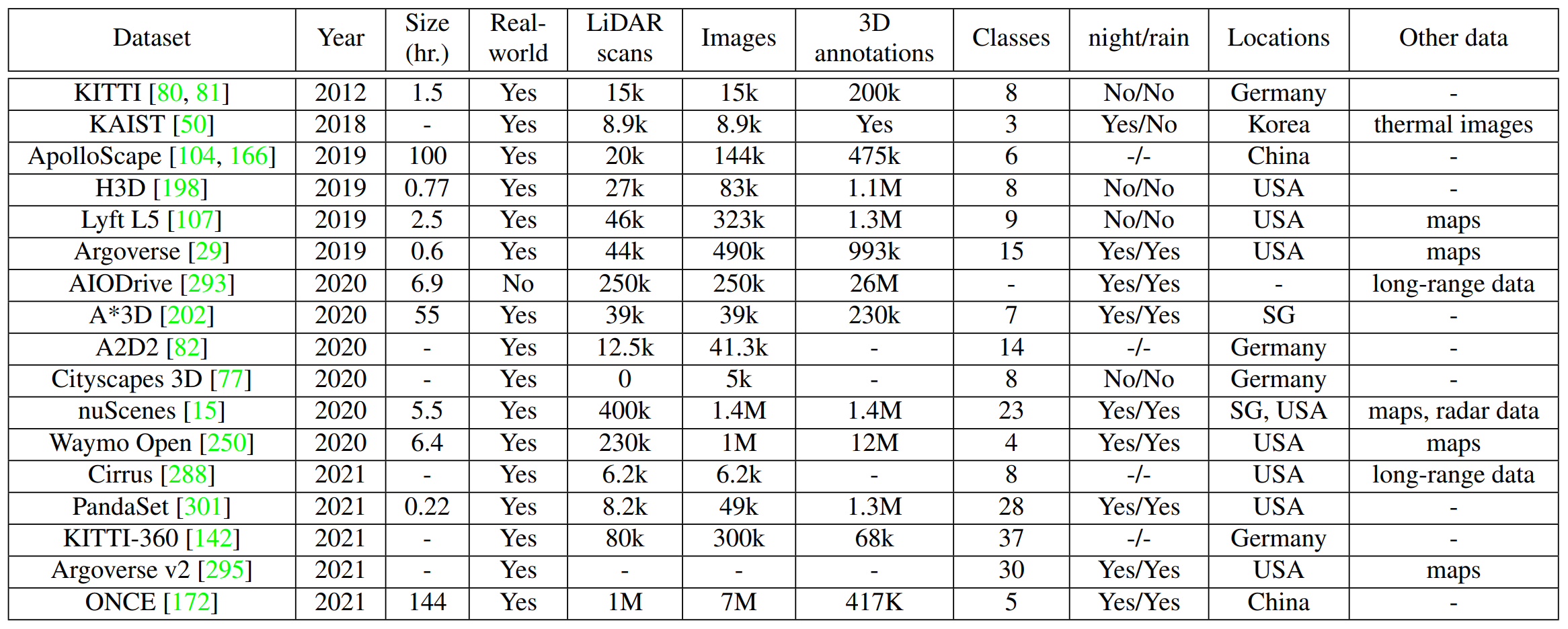
1.3 评估指标
在3D目标检测中,一般有两类评估指标,一类是将2D检测中的AP挪用到3D检测中,如KITTI,包含3D和BEV两个AP,分别代表3D上的IoU和BEV上的IoU,另一类评估指标则是基于下游任务的,如PKL、SDE等,比如在驾驶场景中,相同的IoU随着离驾驶人越近,权重增加,因为更能危及到驾驶人的安全问题,这就是AP指标未能考虑的点。但是PKL、SDE也不是完美的,PKL是需要预训练的运动规划器的,但是预训练的过程并非能保证不出错,而SDE需要重构物体边界,这通常是很复杂的。
2 基于LiDAR的3D目标检测
通过LiDAR,传感器能输出深度图像和点云,但是简单的将2D目标检测中的诸如卷积等操作应用过来,可能会丧失像素中包含的3D信息,同时在自动驾驶场景中,要实时且准确的描述信息是一个巨大的挑战。
2.1 Data Representations
2.1.1 Point-based 3D目标检测
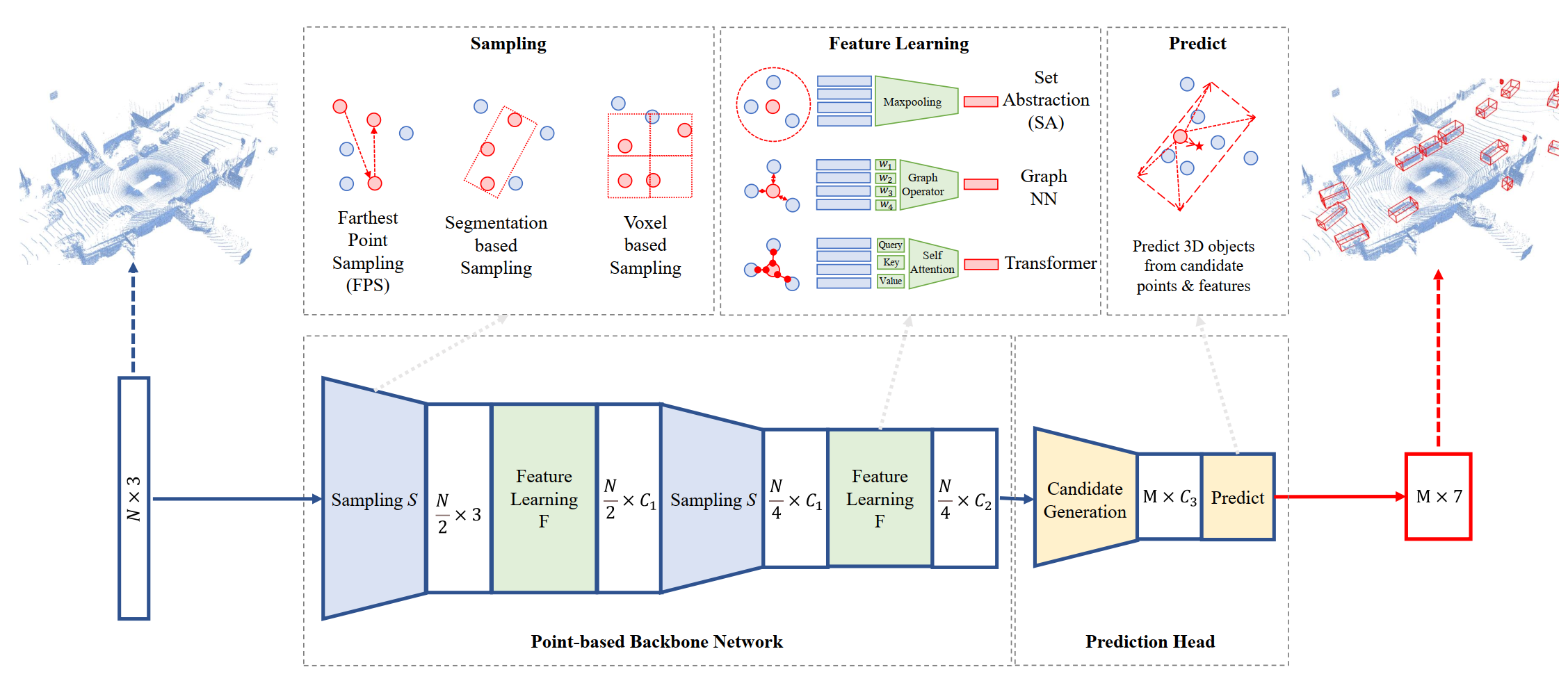
点云下采样
在 PointNet++ 中用到了FPS(Farthest Point Sampling) 最远点采样法,该方法比随机采样的优势在于它可以尽可能的覆盖空间中的所有点。
实现步骤
假设一共有n个点,整个点集为N = {f1, f2,…,fn}, 目标是选取n1个起始点做为下一步的中心点:
①随机选取一个点fi为起始点,并写入起始点集 B = {fi};
②选取剩余n-1个点计算和fi点的距离,选择最远点fj写入起始点集B={fi,fj};
③选取剩余n-2个点分别计算和点集B中每个点的距离, 将最短的那个距离作为该点到点集的距离, 这样得到n-2个到点集的距离,选取最远的那个点写入起始点B = {fi, fj ,fk},同时剩下n-3个点, 如果n1=3 则到此选择完毕;
④如果n1 > 3则重复上面步骤直到选取。
其他的下采样有 segmentation guided filtering、feature space sampling、random sampling、voxel-based sampling、coordinate refinemen等。
点云特征学习
set abstraction(SA)首先点云通过预先定义好半径的ball query收集,然后通过mlp和max pooling抽取特征。
其他方法还有graph operators、attentional operators、Transformer。
分析
模型的表征能力主要基于两种因素:点的数量和ball query的半径。
通过LiDAR采样的点并不是均匀分布的,随机采样往往导致过度采样那些高密度区域,而忽略掉分散的点,所以随机采样较fps表现不佳。fps是一连串的算法不可能高并行化,所以不太合适做实时检测。
2.1.2 Grid-based 3D目标检测
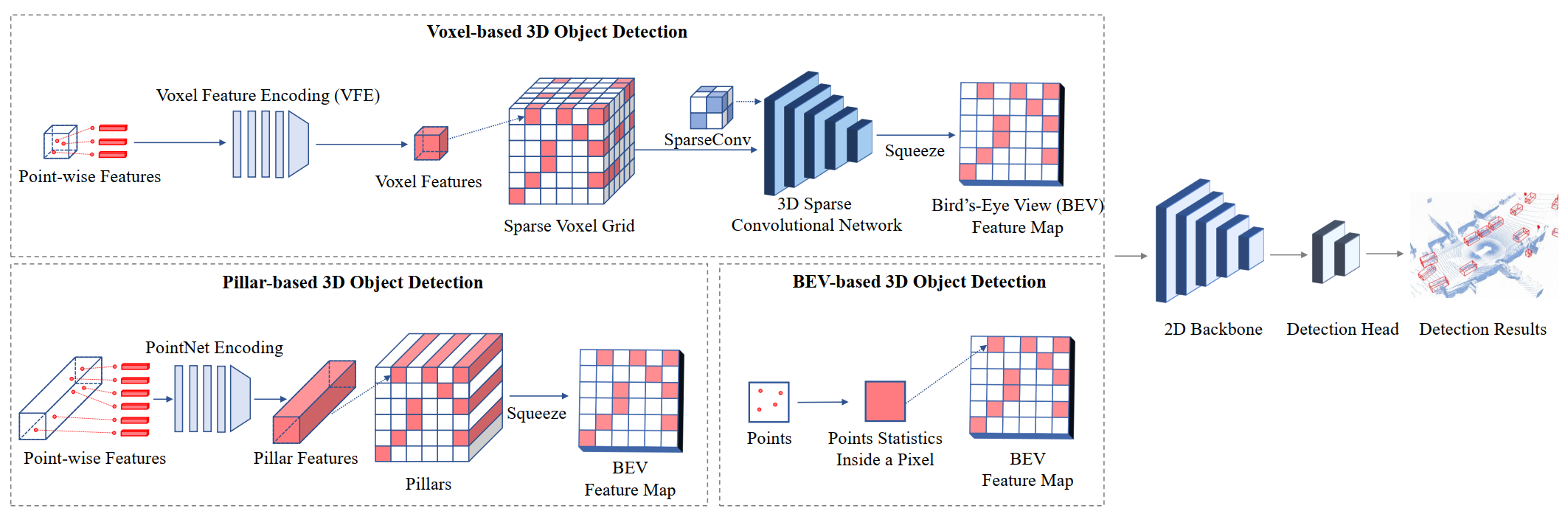
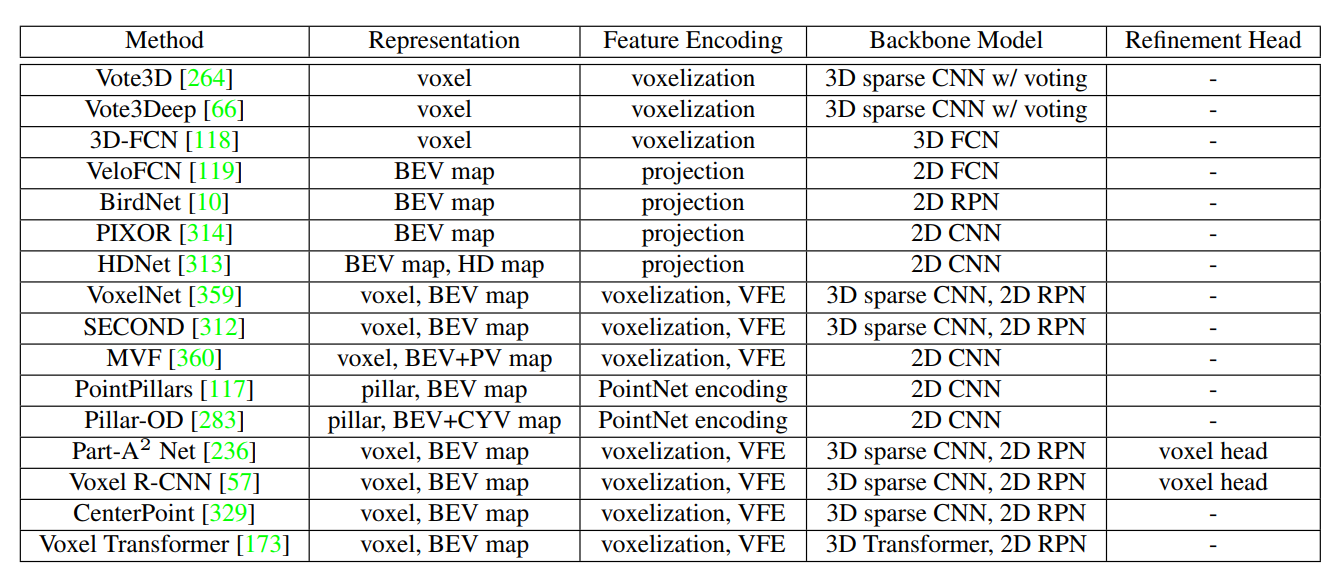
Grid-based表示
有三种类型:voxel体素、pillars、BEV特征图
voxel:在实际应用场景中,只有那些非空的voxel被利用于特征提取,VoxelNet就是一项先驱性工作,提出了VFE用于提取在voxel cell中的点的特征。除此以外还有Muti-view voxels(一种从多角度表征3D目标且能融合的方法)和Multi-scale voxels。
pillars:可以看作特殊的voxel,它在垂直尺度上是不受限制的。该表征方法由PointPillars提出。
BEV feature maps:每个像素相当于一块特定的区域的编码,BEV特征图能够直接通过summary point statistics获取,或者通过投影3D特征(从voxel或pillars获取)到鸟瞰图。
Grid-based神经网络
一般有两类:2D卷积神经网络(pillars、BEV特征图)和3D稀疏神经网络(voxel)。
2D卷积神经网络:有很多经典的,像resnet、rpn、fpn
3D稀疏卷积神经网络:
①稀疏卷积:卷积的输入为一个矩阵M和一个哈希表H。矩阵M为输入feature map上不为空的部分的特征,大小为 a × n, a代表不为空的位置个数,n代表特征维度C。哈希表H, key代表输入feature map中不为空的位置的坐标,value代表这个坐标对应的特征是M中的哪一行特征。
计算流程:
1.(CPU上)。对H中的key进行遍历,确定卷积输出feature map上不为空的位置的坐标与个数,组成Hout 。同时确定rule book, rule book的每一行对应计算卷积输出feature map上不为空的某个位置所需要输入feature map上的位置,通过这个位置得到输入哈希表中该位置对应的key,填充到rule book中
2. (GPU上)。对rule book的每一行进行并行计算,得到每个不为空的输出位置的输出。
②submanifold卷积
在稀疏卷积的基础上提出了子流形稀疏卷积。submanifold指稀疏卷积指 输出feature map上不为空的位置与输入feature map上不为空的位置相同。稀疏卷积会使得数据的稀疏性指数下降,而submanifold会保持一样的稀疏性,但是如果只用submanifold稀疏卷积,卷积核的感受野会限制在一定范围内,所以要和 maxpooling 或 stride=2 的卷积一起使用,在保持稀疏性的同时增大感受野。
具体的实现流程类似,直接把Hin复制到Hout,其他一致。
分析
voxel较pillar和BEV特征图能包含更多的3D信息,然而,一个3D的神经网络会消耗更多的时间和空间。BEV特征图是最有效的grid表示(高效且实时的推理速度),它直接将点云投影到2D平面上,而常见的2D目标检测操作也能无缝地迁移过来,但是这样简易的操作势必会丢失很多3D信息。Pillars则能在两者之间平衡。
grid-based最重要的就是cell的尺寸。网格表示本质上是点云的离散格式,通过将连续的点坐标转换为离散的网格索引。更小的cell精度也会越高,但也会消耗更多的memory。
2.1.3 Point-voxel based 3D目标检测
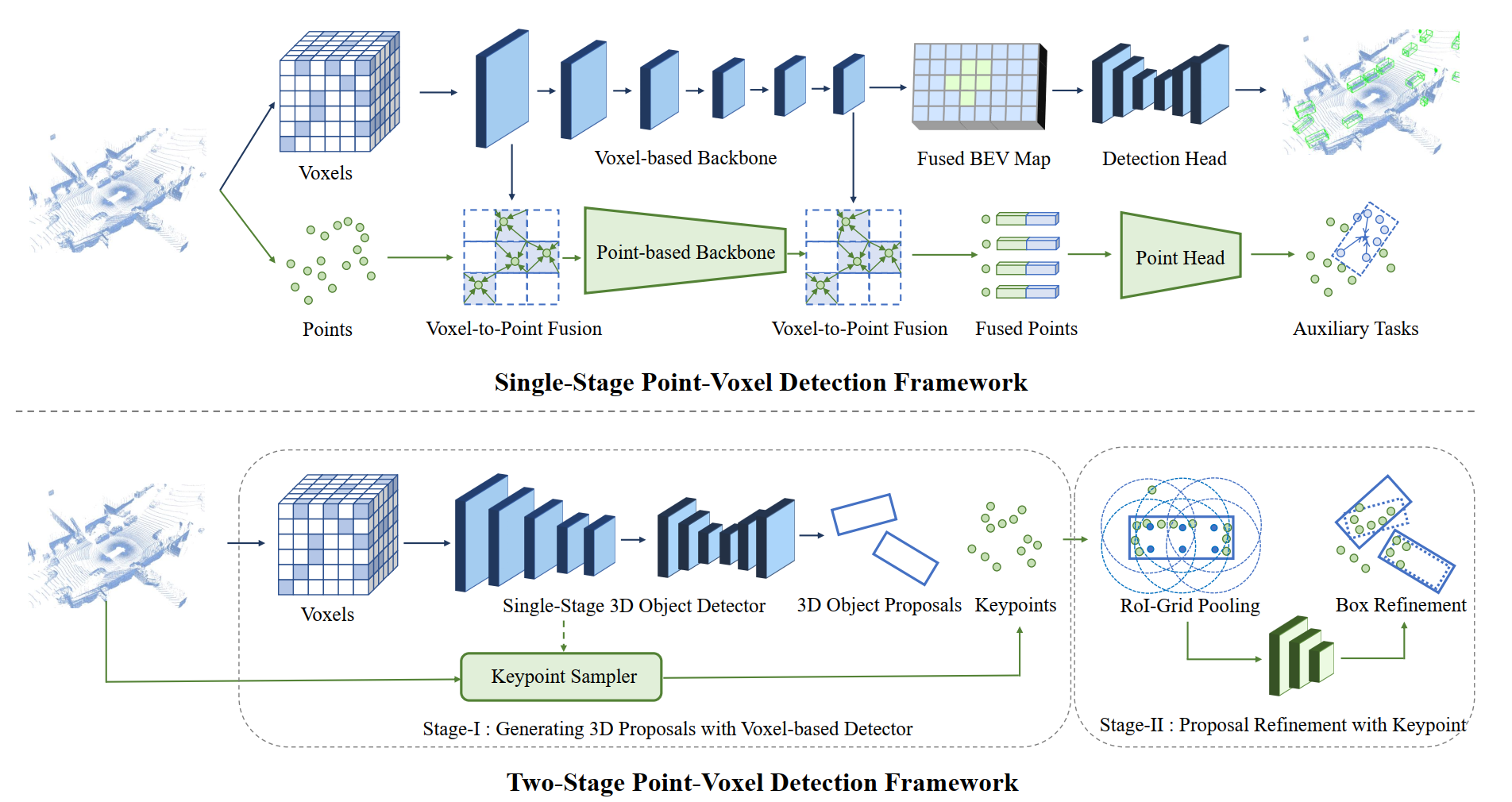
Single-stage point-voxel 检测框架
point包含高精度的位置信息,voxel在推理计算上又很有效率,所以在backbone中,两者通过 point-to-voxel 和 voxel-to-point进行转换。比如point-voxel convolutions、auxiliary point-based networks、multi-scale feature fusion
Two-stage point-voxel 检测框架
第一阶段:通过voxel-based检测框架来输出3D目标的候选集;代表工作:PV-RCNN
第二阶段:结合第一阶段的检测器以及点云采样得到keypoints,然后从keypionts进一步细化3D候选框,如RoI-grid pooling
分析
Point-voxel based方法虽然能结合两者的优点,但是在融合上有很耗时。对于Two-stage框架,如何有效地在3D候选框上综合点的特征,是一个挑战。
2.1.4 Range-based 3D目标检测
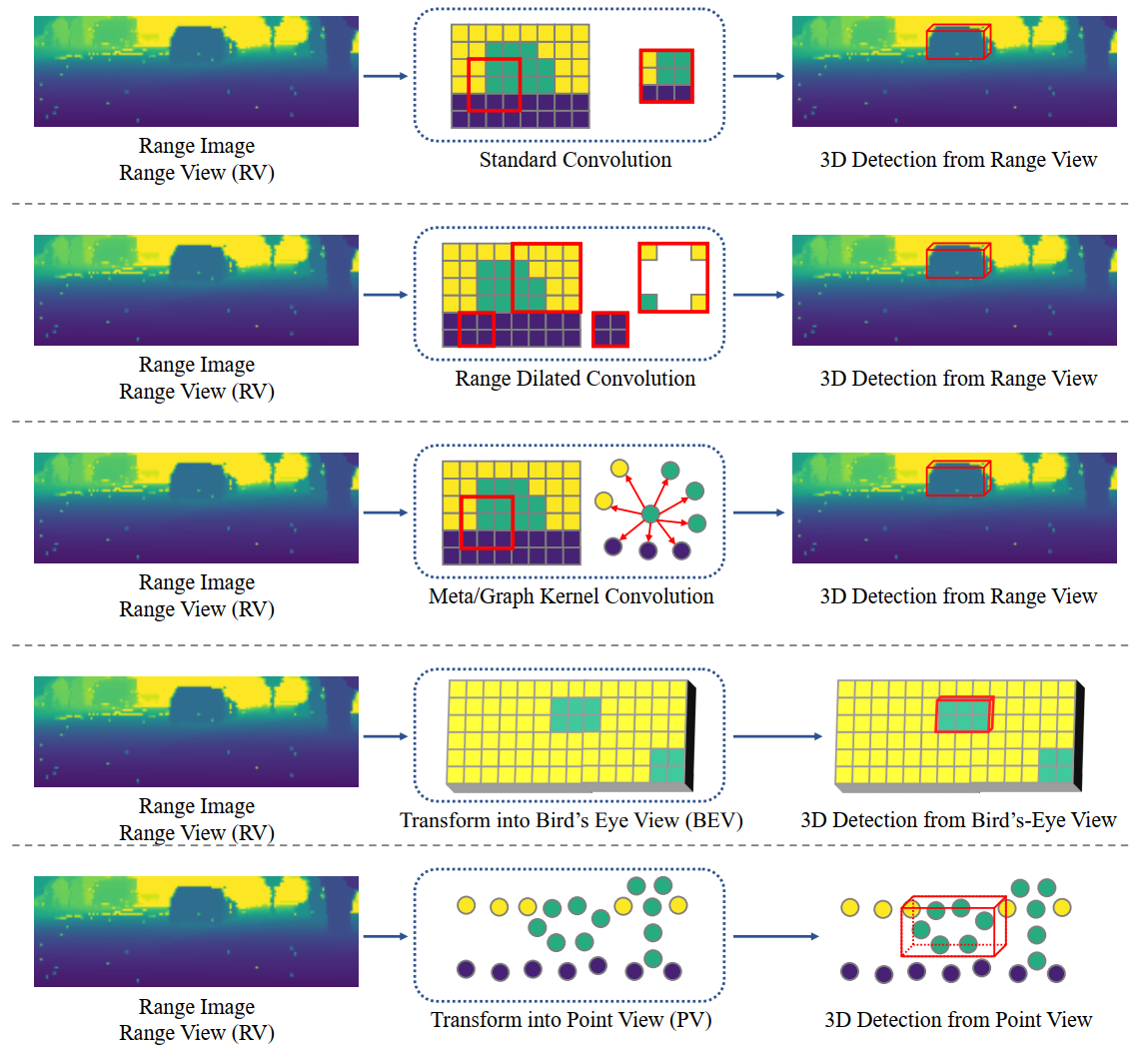
深度图像虽然是2D的,但是,每一个像素点都包含3D距离信息。
Range-based 检测模型
正因为深度图像是2D的,所以能将2D目标检测的模型迁移过来,LaserNet就是一个代表性的工作。
Range-based 算子
虽然是2D图像,但是一个滑动窗口中的像素在3D空间里可能离得很远。像 range dilated convolutions 等有效的解决了这个问题。
Range-based 视角
从range view检测势必会受到球面投影带来的遮挡和尺度变化问题的影响。
分析
从range view中提取特征,从BEV中检测物体,是Range-based的3D物体检测最实用的解决方案。
2.2 Learning Objectives
该节讲述准确估计3D目标的中心点和尺寸的方法。
2.2.1 anchor-based
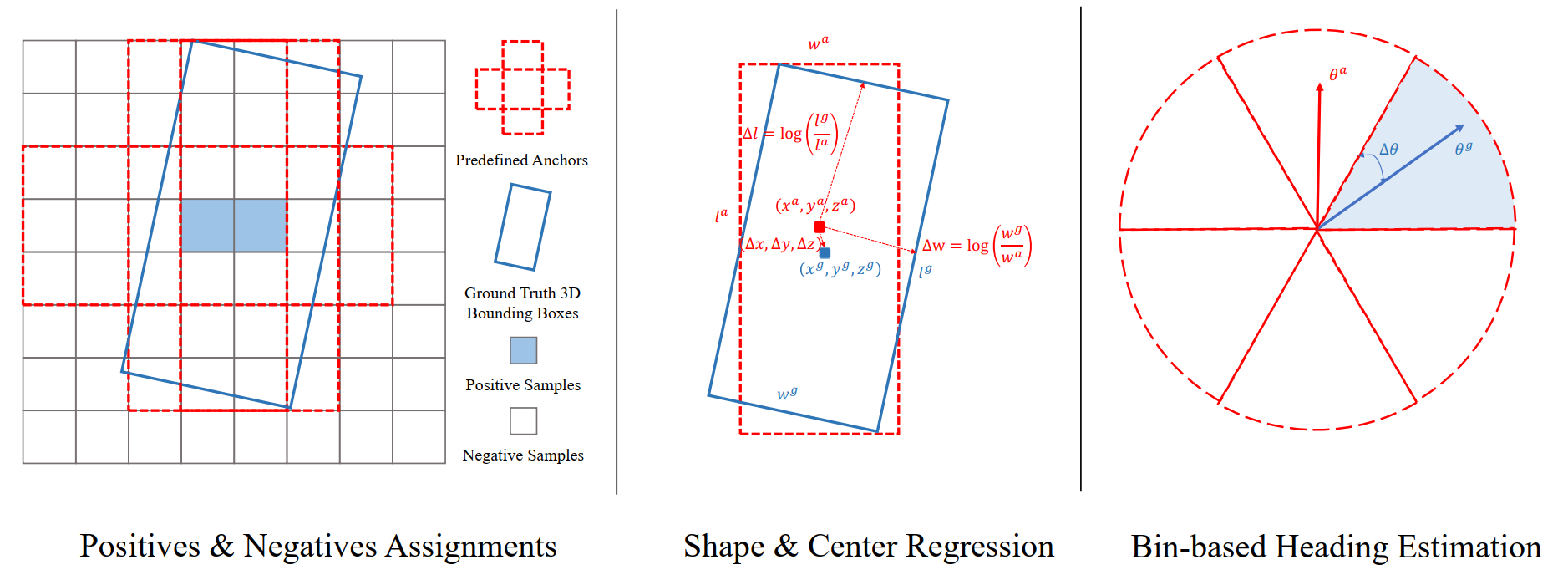
通常3D目标的预测是基于标注好的anchor,相同的类别有相同的size,并且整个检测过程的视角是BEV。
如下所示,整个损失函数包含类别、尺寸位置、方向角三个部分。
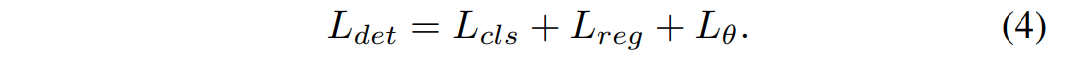
在类别损失中,通常采用 bce loss 和 focal loss(针对样本不均衡问题)。
在尺寸位置、方向角损失中,通常采用SmoothL1。
除了上述三种分别处理的损失,还有IoU损失、corner loss等等。
分析:第一,3D目标相较于检测范围来说是相对小的,第二,对于行人等小目标检测不是很准确。通常anchor都是放置在每个cell的中央,如果cell很大,cell中的目标很小的话,就会导致较低的IoU。
2.2.2 anchor-free
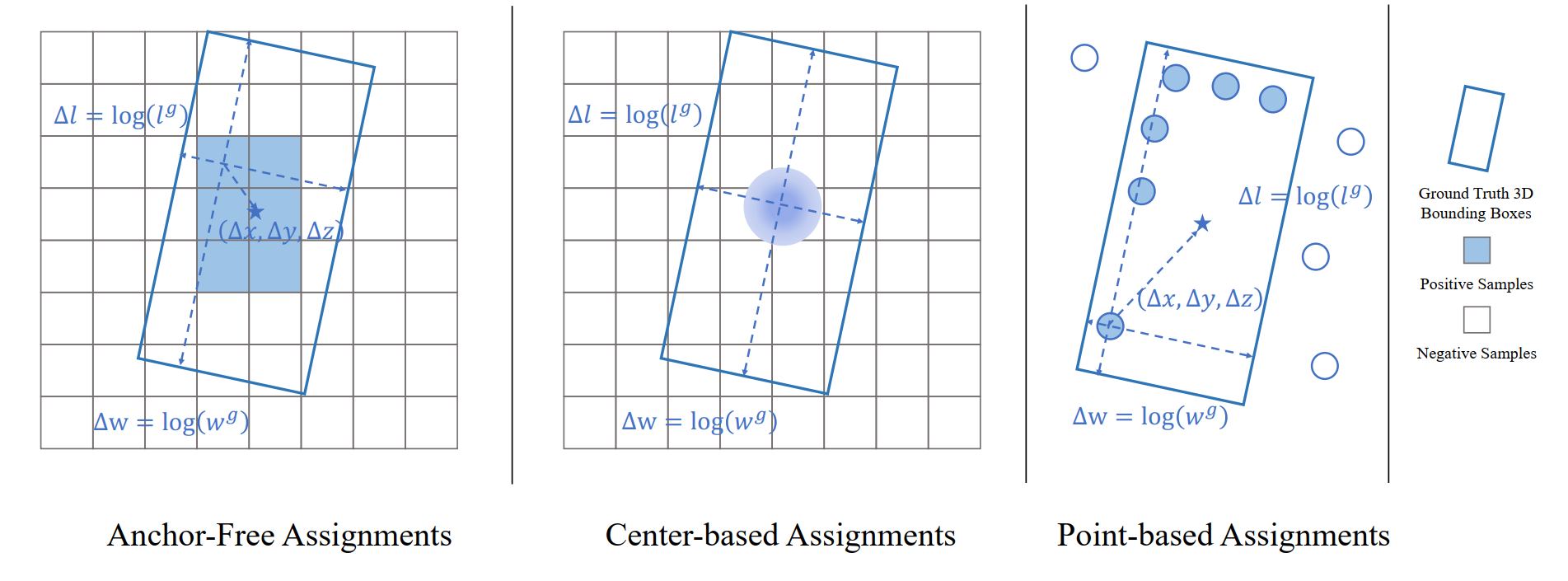
(1)针对point-based:首先对点进行分割,选择那些在三维物体内部或附近的前景点作为正样本,最后从这些前景点中学习3D bounding box。
(2)针对range-based:选择三维物体内部的范围像素作为正样本,与其他基于全局三维坐标系的回归目标的方法不同,基于范围的方法借助于以物体为中心的坐标系进行回归。
(3)set-to-set:如2D目标检测中的DETR采用的匈牙利匹配算法。
缺点:bad positive samples
2.2.3 3D object detection with auxiliary tasks
(1)语义分割
语义分割可以在三个方面帮助三维物体检测:(1)前景分割可以提供物体位置的隐含信息。(2) 空间特征可以通过分割得到增强。(3) 可以作为预处理步骤来利用,以过滤掉背景样本,使三维物体检测更加有效。
(2)IoU rectification
IoU可以作为一个有用的监督信号来纠正物体的置信度分数。可以为每个检测到的三维物体预测一个IoU分数:SIoU。在推理过程中,原始置信度分数Sconf = Scls被SIoU进一步rectify。
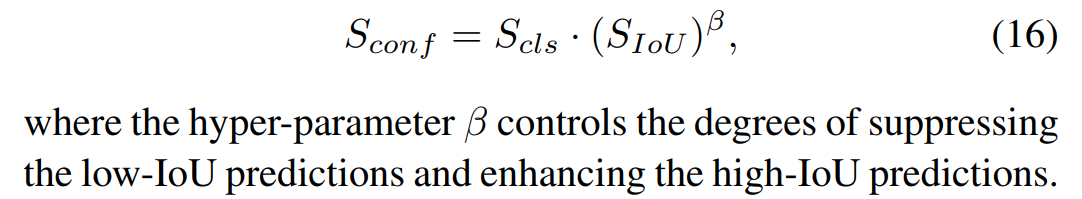
通过IoU rectification,高质量的三维物体更容易被选为最终预测。
(3)Object shape completion
由于LiDAR的性质,远处的物体一般只收到其表面的几个点,所以三维物体一般是稀疏的、不完整的。提高检测性能的一个直接的方法是从稀疏的点云中完成物体形状。完整的形状可以为准确和稳健的检测提供更多有用的信息。
(4)Object part estimation
识别物体内部的部分信息对三维物体检测很有帮助,因为它揭示了一个物体更精细的三维结构信息。
3 基于Camera的3D目标检测
略
4 多模态融合的3D目标检测
略
最后
以上就是虚幻魔镜最近收集整理的关于自动驾驶中3D目标检测综述的全部内容,更多相关自动驾驶中3D目标检测综述内容请搜索靠谱客的其他文章。








发表评论 取消回复