Image generation(synthesis) is the task of generating new images from an existing dataset.
图像生成(合成)是从现有数据集生成新图像的任务。
- Unconditional generation refers to generating samples unconditionally from the dataset,i.e.
无条件生成式指从数据集中无条件的生成样本。即p(y)
- Conditional image generation(subtask) refers to generating samples conditionally from the dataset, based on a label, i.e. p(y|x)
条件图像生成是指基于标签有条件的从数据集生成样本,即p(y|x)
Image-to-Image Translation
Image-to-image translation is the task of taking images from one domain and transforming them so they have the style(or characteristics) of images from another domain.
图像到图像的转换,是从一个域中提取图像并对其进行转换,使其具有另一个域图像的风格(或特征)。
Unsupervised Image-to-Image Translation
Unsupervised image-to-image translation is the task of doing image-to-image translation without ground truth image-to-image pairings.
无监督图像到图像的转换时在没有真实图像到生成图像的匹配的情况下进行图像到图像的转换。
One Shot Image to Image Translation
源域到目标域仅由单个样本组成的图像到图像的转换。
- One-Shot Unsupervised Cross Domain Translation
**abstraction:**Given a single image x from domain A and a set ot images from domain B, our task is to generate the analogous of x in B. We argue that this task could be a key AI capability that underlines the ability of cognitive agents to act in the work and present empirical evidence that the existing unsupervised domain translation methods fail on this task. Our method follows a two step process. First, a variational autoencoder for domain B is trained. Then, given the new sample x, we create a variational autoencoder for domain A by adapting the layers that are close to the image in order to directly fit x, and only indirectly adapt the other layers. Our experiments indicate that the new method does as well, when trained on one sample x, as the existing domain transfer methods, when these enjoy a multitude of training samples from domain A.
给定一幅来自A域的x图像和一组来自B域的图像。我们的任务是生成B域中x类似物。我们认为该任务可能是一项关键的AI能力,突显了认知主体在其中起作用的能力。强调认知主体在世界上的能力,目前的经验证据表明,现有的无监督与转换方法无法完成此任务。我们的方法遵循两步过程。首先,训练B域的变体自动编码器。然后,给定新样本x,他们通过调整接近图像的图层以直接适合x,而间接调整其他图层,为A域创建变体自动编码器。实验表明,新方法在一个样本x上进行训练,与现有的对A域中的大量样本训练的域转移方法一样有效。

- Bidirectional One-Shot Unsupervised Domain Mapping(2019)
We study the problem of mapping between a domain A, in which there is a single training sample and a domain B, for which we have a richer training set. The method we present is able to perform this mapping in both directions. For example, we can transer all MNIST images to the visual domain captured by a single SVHN image and transform autoencoder of the single sample domain is trained to match both this sample and the latent space of domain B. Our results demonstrate convincing mapping between domains, where either the source or the target domain are defined by a single sample, far surpassing existing solutions.
我们研究了一个域A到域B的转换问题,域A只有一个训练样本,域B拥有更丰富的训练集。我们提出的方法能够在两个方向上执行此映射。例如,我们可以将所有的MNIST图像转换到由单个SVHN图像所捕获的视觉域,也可以将SVHN图像变换到MNIST图像的域中。我们的方法是基于每一个域使用一个编码器和一个解码器,而不使用权重共享。训练单个样本域的自动编码器,使该样本和B域的潜在空间相匹配。我们的结果证明域的映射是可行的,远远超过现有的解决方案,不管源域或目标域由单个样本定义。





Sensor Modeling(传感器建模)
- LiDAR Sensor modeling and Data augmentation with GANs for Autonomous driving
利用GAN进行LiDAR传感器建模和数据增强以实现自动驾驶。
In the autonomous driving domain, data collection and annotation from real vehicles are expensive and sometimes unsafe. Simulators are often used for data augmentation, which requires realistic sensor models that are hard to fomulate and model in closed forms. Instead, sensors models can be learned from real data. The main challenge is the absence of paired data set, which makes traditional supervised learning techniques not suitable. In this work, we formulate the problem as image translation from unpaired data and employ CycleGANs to solve the sensor modeling problem for LiDAR, to produce realistic LiDAR from simulated LiDAR(sim2real). Further, we generate high-resolution, realistic LiDAR from lower resolutiion one(real2real). The LiDAR 3D point cloud is processed in Bird-eye View and Polar 2D representations. The experimental results show a high potential of the proposed approach.
在自动驾驶领域,从真实车辆收集和注释数据非常昂贵,有时甚至是不安全的。 模拟器通常用于数据扩充,这需要现实的传感器模型,这些模型很难以封闭形式进行公式化和建模。 相反,可以从真实数据中学习传感器模型。 主要挑战是缺少成对的数据集,这使得传统的监督学习技术不合适。 在这项工作中,我们将问题描述为来自未配对数据的图像转换,并使用CycleGAN解决LiDAR的传感器建模问题,从而从模拟LiDAR(sim2real)生成逼真的LiDAR。 此外,我们从较低的分辨率逼真的LiDAR(real2real)生成高分辨率逼真的LiDAR。 LiDAR 3D点云以鸟瞰图和Polar 2D表示形式进行处理。 实验结果表明该方法具有很高的潜力。

Synthesic-to-Real Translation
合成到真实的转换
Synthetic-to-real translation is the task of domain adaptation from synthetic (or virtual) data to real data.
合成到真实的转换主要是从合成(或虚拟)数据到真实数据的领域适应的任务。
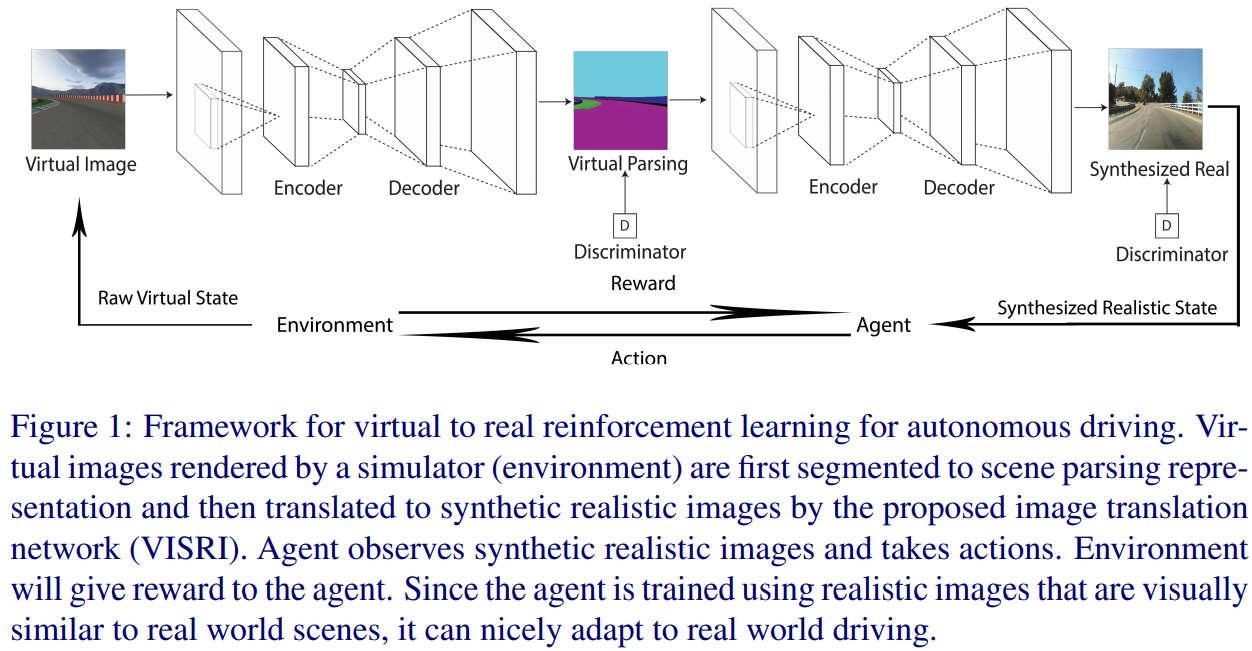
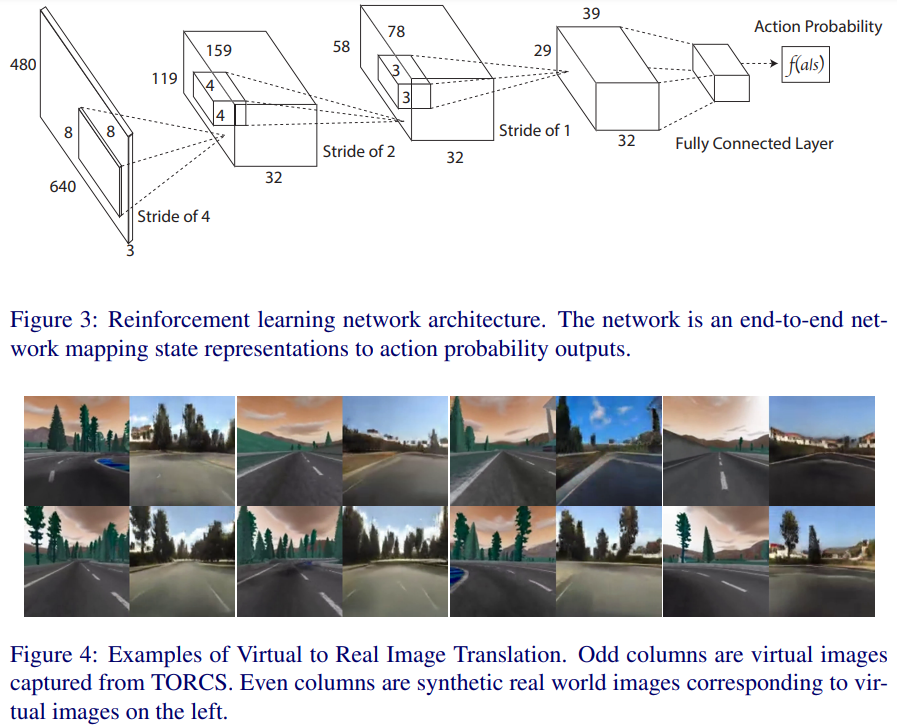
- Virtual to Real Reinforcement Learning for Autonomous Driving(2017)
自主驾驶的虚-实强化学习
Reinforcement learning is considered as a promising direction for driving policy learning. However, training autonomous driving vehicle with reinforcement learning in ral environment involves non-affordable trial-adn-error. It is more desirable to first train in a virtual environment and then transfer to the real environment. In this paper, we propose a novel realistic translation network to make model trained in virtual environment be workable in real world. The proposed network can convert non-realistic virtual image input into a realistic one with similar scene structure. Given realistic frames as input, driving policy trained by reinforcement learing can nicely adapt to real world driving. Experiments show that our proposed virtual to real (VR) reinforcement learning (RL) works pretty well. To our knowledge, this is the first successful case of drving policy trained by reinforcement learning that can adapt to real world driving data.
强化学习被认为是推动策略学习的一个很有前途的方向。然而,在真实环境中,用强化学习训练自主驾驶汽车,涉及到不可承受的试错。更可取的做法是先在虚拟环境中进行训练,然后转移到真实环境中。本文提出了一种新的真实感翻译网络,使在虚拟环境中训练的模型在现实世界中可行。该网络可以将输入的非真实感虚拟图像转换为具有相似场景结构的真实感虚拟图像。以真实框架为输入,强化学习训练出的驾驶策略能够很好地适应现实驾驶。实验结果表明,本文提出的虚拟现实强化学习方法效果良好。据我们所知,这是第一个成功的案例,驾驶政策培训的强化学习,可以适应现实世界的驾驶数据。

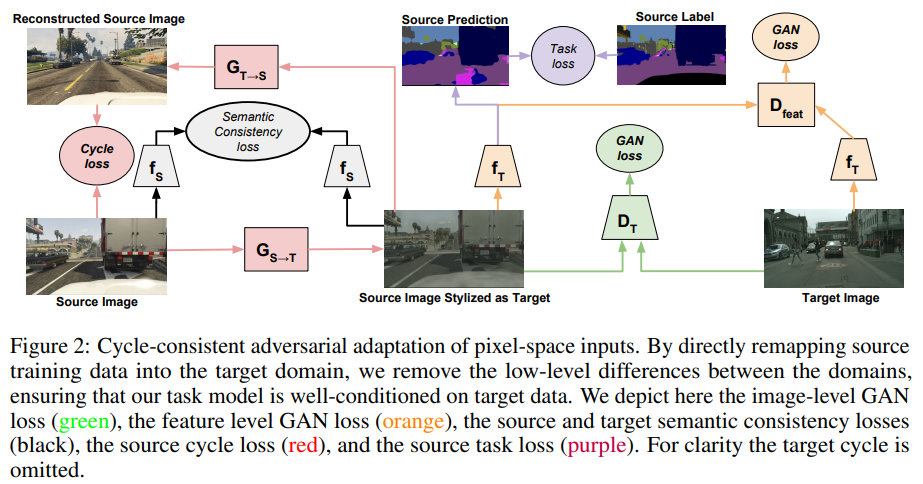
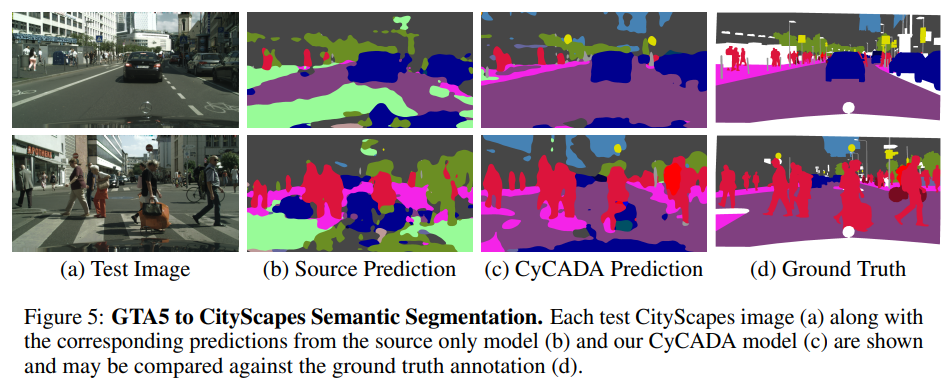
- CyCADA: Cycle-Consistent Adversarial Domain Adaptation(2018)
CyCADA:周期一致的对抗域自适应
Domain adaptation is critical for success in new, unseen environments. Adversarial adaptation models applied in feature spaces discover domain invariant representations, but are difficult to visualize and sometimes fail to capture pixel-level and low-level domain shifts. Recent work has shown that generative adversarial networks combined with cycle-consistency constraints are surprisingly effective at mapping images between domains, even without the use of aligned image pairs. We propose a novel discriminatively-trained Cycle-Consistent Adversarial Domain Adaptation model. CyCADA adapts representations at both the pixel-level and feature-level, enforces cycle-consistency while leveraging a task loss, and does not require aligned pairs. Our model can be applied in a variety of visual recognition and prediction settings. We show new state-of-the-art results across multiple adaptation tasks, including digit classification and semantic segmentation of road scenes demonstrating transfer from synthetic to real world domains.
域适应对于在新的看不见的环境中取得成功至关重要。在特征空间中应用的对抗性适应模型会发现域不变表示,但是难以可视化,有时候无法捕获像素级和低级域移位。最近的工作表明,生成对抗网络与循环一致性约束相结合,即使在不使用对齐的图像对的情况下,也可以有效的在域之间映射图像。我们提出了一个新的判别训练周期一致性的对抗域适应模型。CyCADA在像素级和功能级都适应了表示形式,在利用任务损失的同时增强了循环一致性,并且不需要对齐的对。我们的模型可以应用于各种视觉识别和预测设置。我们展示了跨多个适应任务的最新技术成果,包括道路场景的数字分类和语义分割,以说明从合成域到真实域的转移。



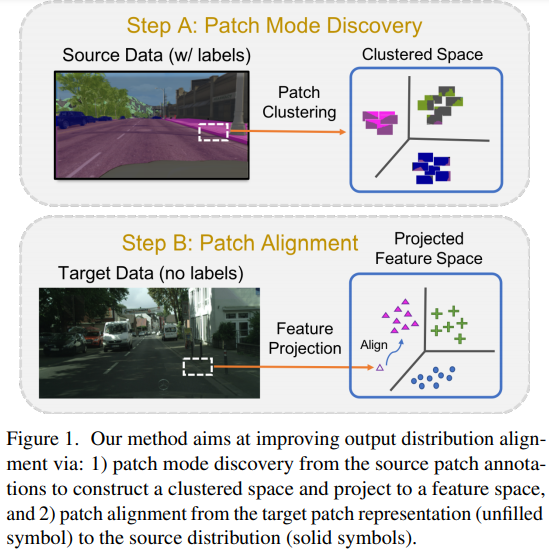
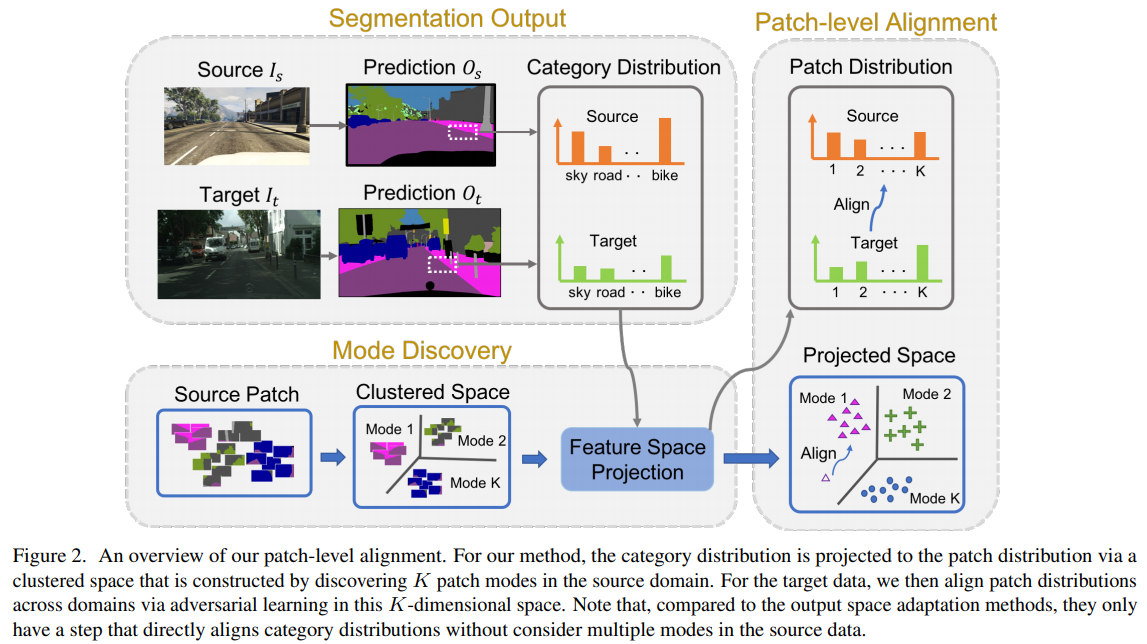
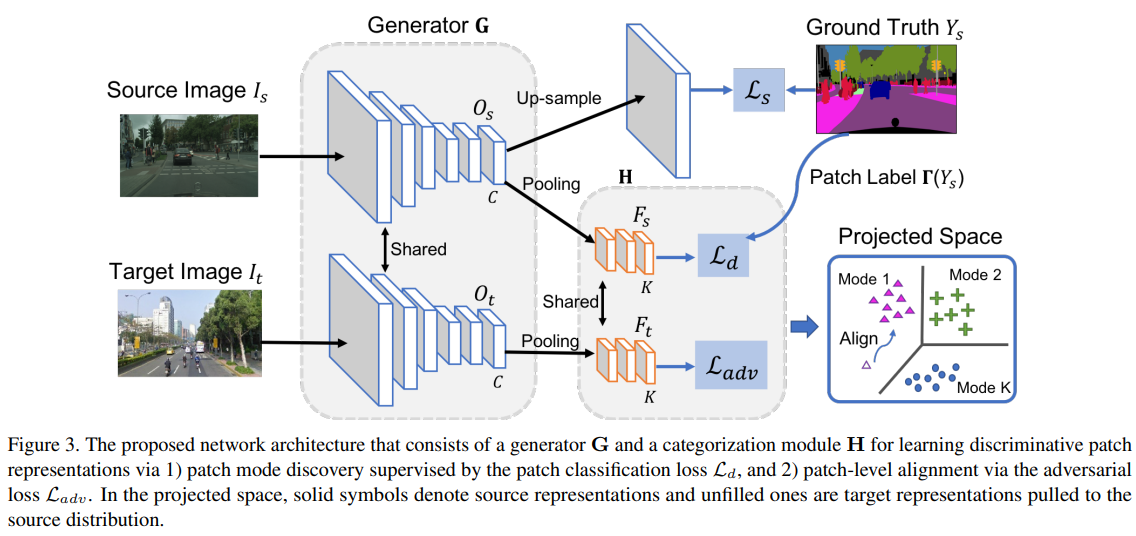
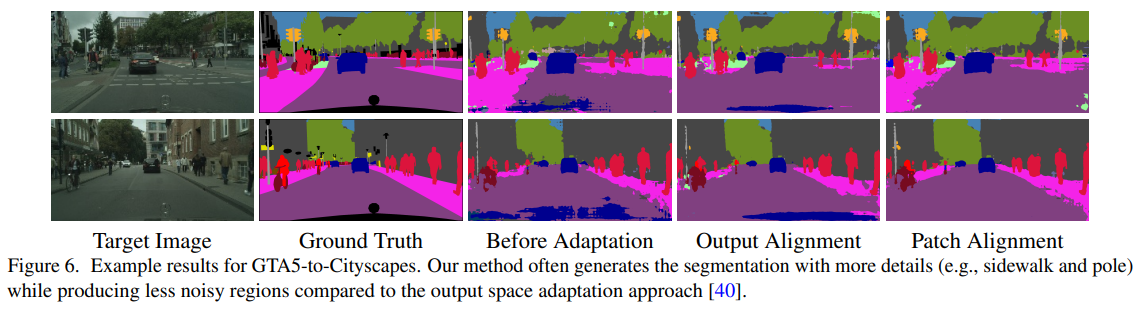
- Domain Adaptation for Structured Output via Discriminative Patch Representations(2019)
通过对区分性补丁表示对结构化输出进行域自适应
predicting structured outputs such as semantic segmentation relies on expensive per-pixel annotations to learn supervised models like convolutional neural networks. However, models trained on one data domain may not generalize well to other domains without annotations for model finetuning. To avoid the labor-intensive process of annotation, we develop a domain adaptation method to adap the source data to the unlabeled target domain. We propose to learn discriminative feature representations of patches in the source domain by discovering multiple modes of patch-wise output distribution through the construction of a clustered space. With such repesentations as guidance, we use an adversarial learning scheme to push the feature representations of target patches in the clustered space closer to the distributions of source patches. In addition, we show that our framework is complementary to existing domain adaptation techniques and achieves consistent improvements on semantic segmentation. Extensive ablations and results are demonstrated on numerous benchmark datasets with various settings, such as synthetic-to-real and cross-city scenarios.
预测结构化输出(例如语义分割)依赖于昂贵的每像素注释来学习诸如卷积神经网络之类的监督模型。 但是,在一个数据域上训练的模型可能无法在没有模型微调注释的情况下很好地推广到其他域。 为了避免注释的劳动密集型过程,我们开发了一种域自适应方法,以使源数据适应未标记的目标域。 我们建议通过构建聚类空间来发现补丁方向输出分布的多种模式,从而在源域中学习补丁的判别特征表示。 以这种表示为指导,我们使用对抗学习方案将聚类空间中目标补丁的特征表示推向更接近源补丁的分布。 此外,我们证明了我们的框架是对现有领域适应技术的补充,并且在语义分割方面实现了一致的改进。 在具有各种设置的大量基准数据集上展示了广泛的消融和结果,例如从合成到真实和跨城市的场景。
- Learning to Adapt Structured Outpu Space for Semantic Segmentatiion(2018)
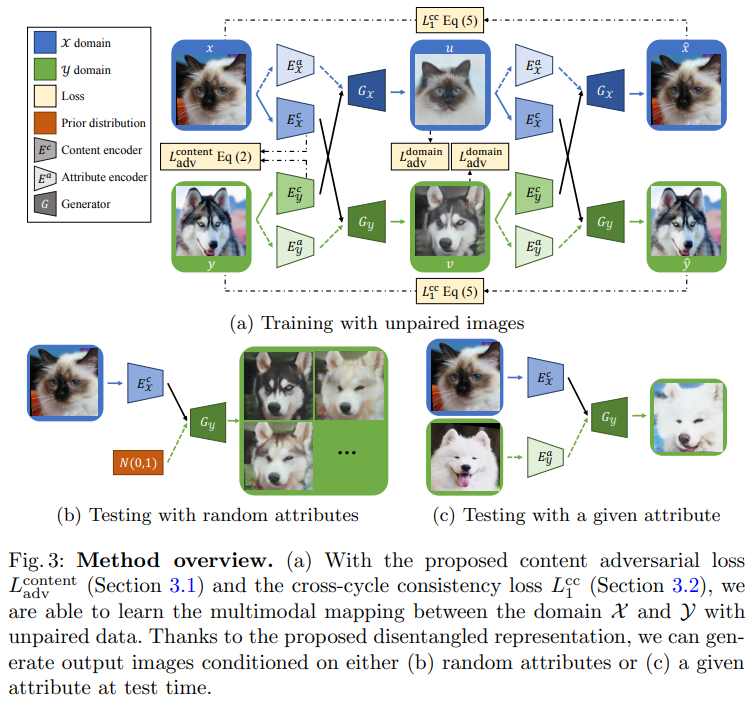
- Diverse Image-to-Image Translation via Disentangled Representations(2018)
Image-to-image translation aims to learn the mapping between visual domains. There are two main challenges for many applications:1) the lack of aligned training pairs and 2) multiple possible outputs from a single input image. In this work, we present an approach based on disentangled representation for producing diverse outputs without paired training images. To achive diversity, we propose to embed images onto two spaces: a domain-invariant content space capturing shared information across domains and a domain-specific attribute space. Our model takes the encoded content features extracted from a given input and the attribute vectors sampled from the attribute space to produce diverse outputs at test time. To handle unpaired training data, we introduce a novel cross-cycle consistency loss based on disentangled representations. Qualitative with user study and diversity with a perceptual distance metric. We apply the proposed model to domain adaption and show competitive performance when compared to the state-of-the-art on the MNIST-M and the LineMod datasets.
图像到图像的翻译旨在学习两个视觉域之间的映射。许多应用程序面临两个主要挑战:1)缺少对齐的训练对;2)单个输入图像的多个可能输出。在这项工作中,我们提出了一种基于非纠缠表示的方法来产生不同的输出,而不需要成对的训练图像。为了实现图像的多样性,我们提出将图像嵌入到两个空间中:一个是捕获跨域共享信息的域不变内容空间,另一个是特定于域的属性空间。该模型利用从给定输入中提取的编码内容特征和从属性空间中提取的属性向量在测试时产生不同的输出。为了处理不成对的训练数据,我们引入了一种新的基于非纠缠表示的交叉循环一致性损失。定性结果表明,我们的模型可以在不需要配对训练数据的情况下,在大范围的任务上生成多样化和真实的图像。对于定量比较,我们用用户研究来衡量现实性,用感知距离度量来衡量多样性。我们将所提出的模型应用于域自适应,并与MNIST-M和LineMod数据集上的最新技术进行了比较。






-
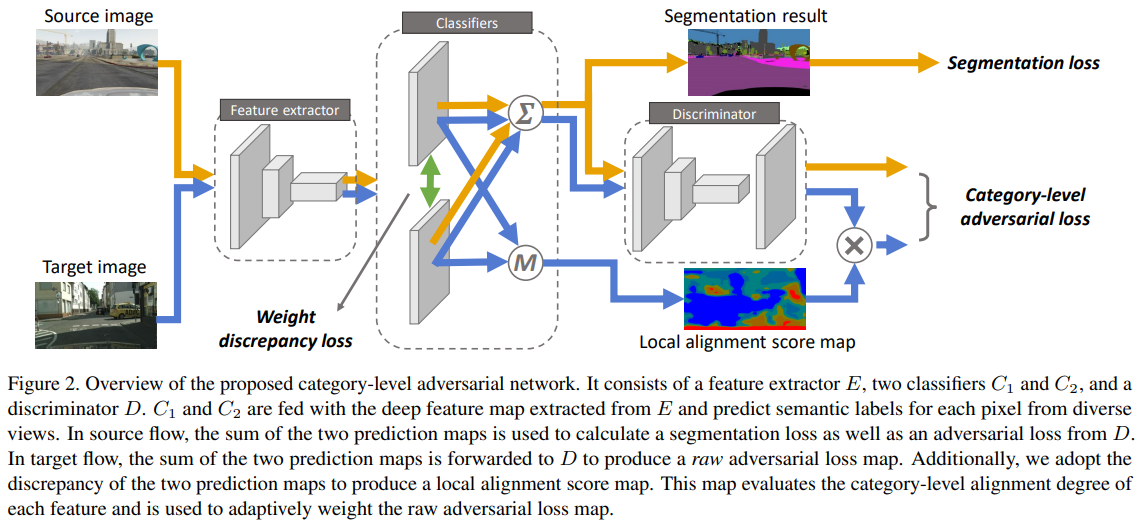
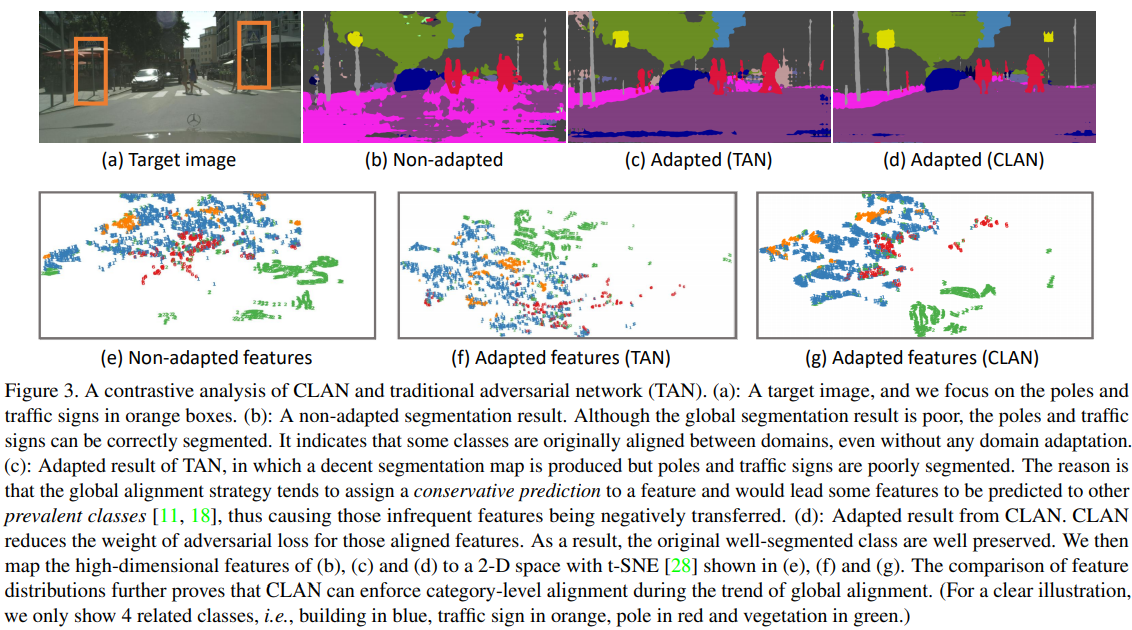
Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation(2019)

-
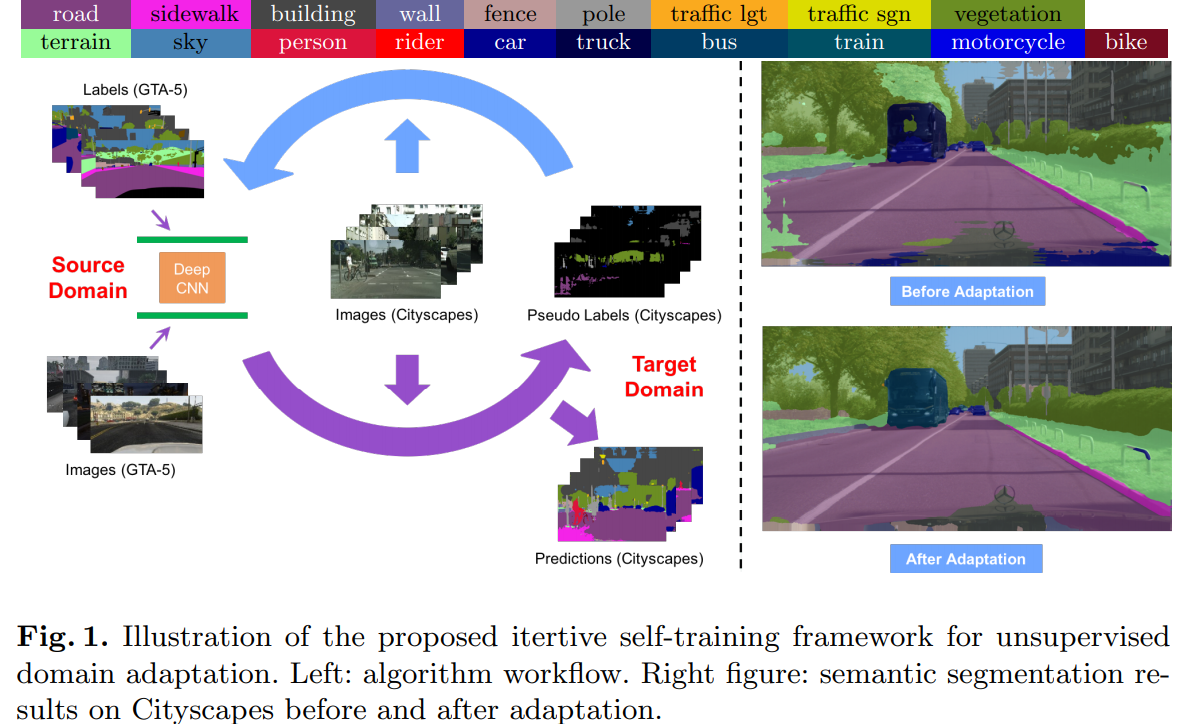
Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training(2018)


-
All about Structure: Adapting Structural Information across Domains for Boosting Semantic Segmentation(2019)
关于结构:跨越调整结构信息以促进语义分割
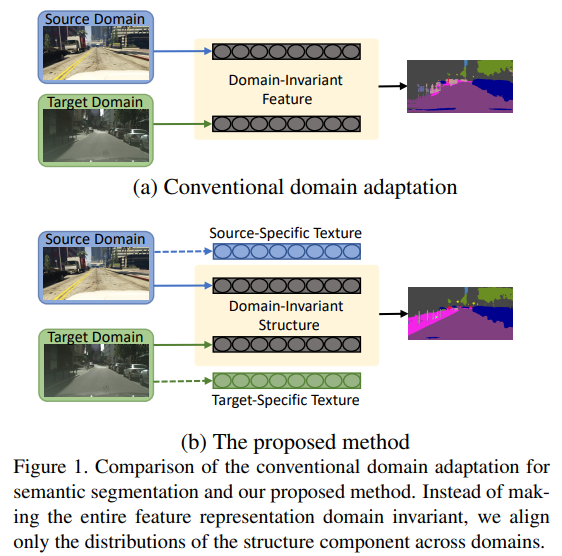
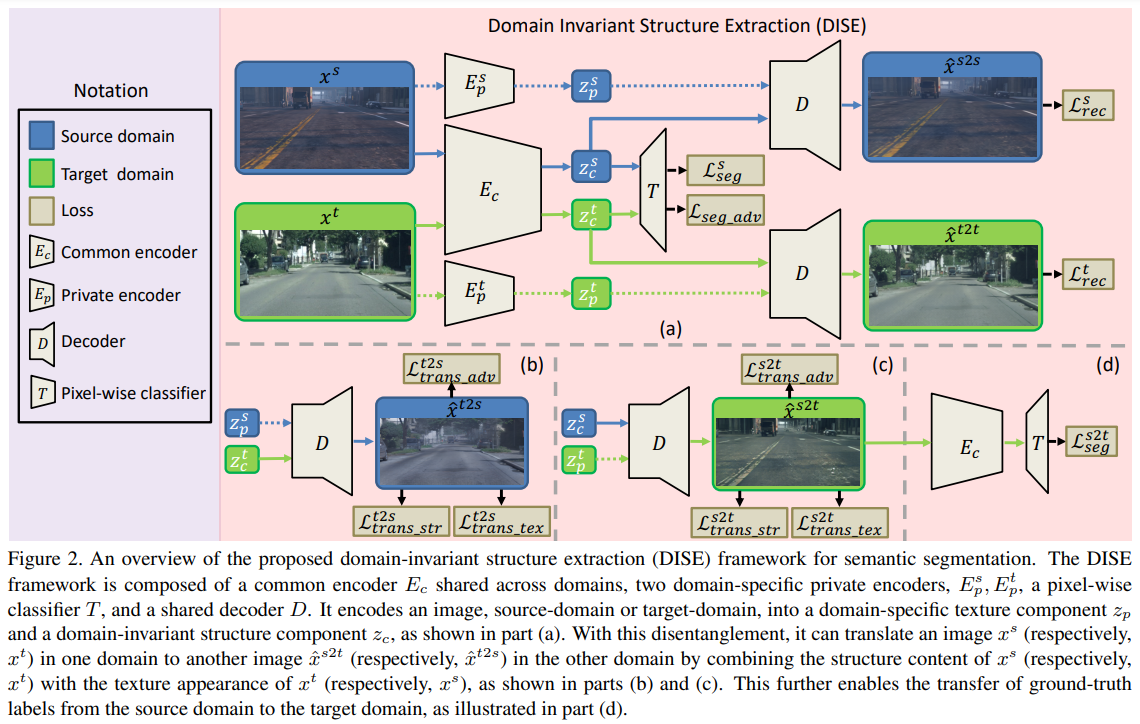
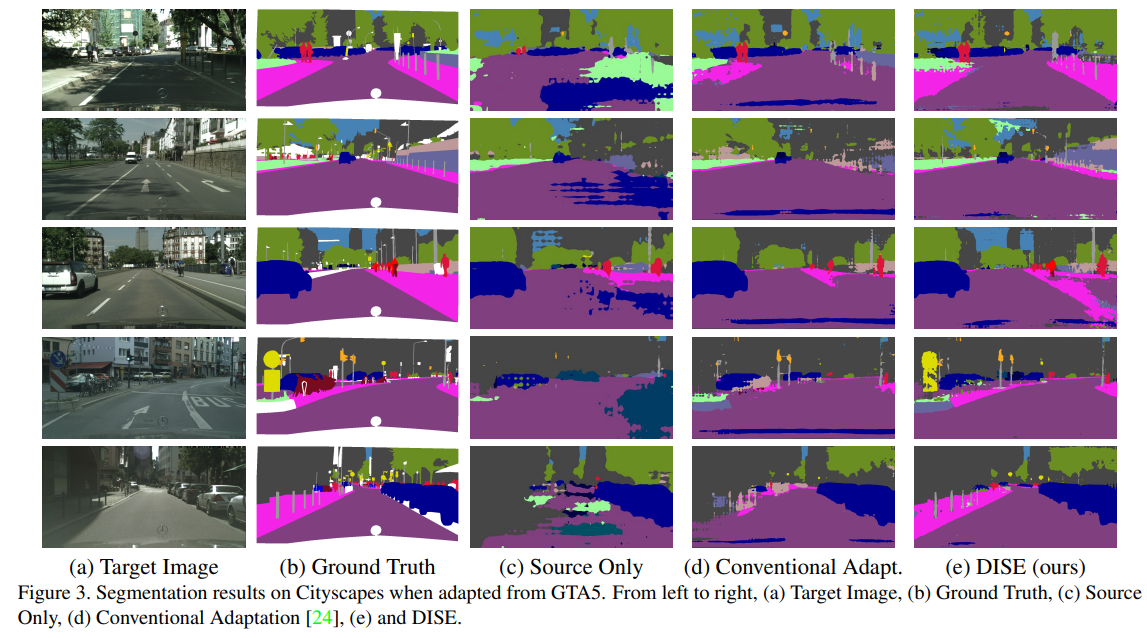

-
A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes(2018)
-
Curriculum Domain Adaptaioin for Semantic Segmentation of Urban Scenes(2017)
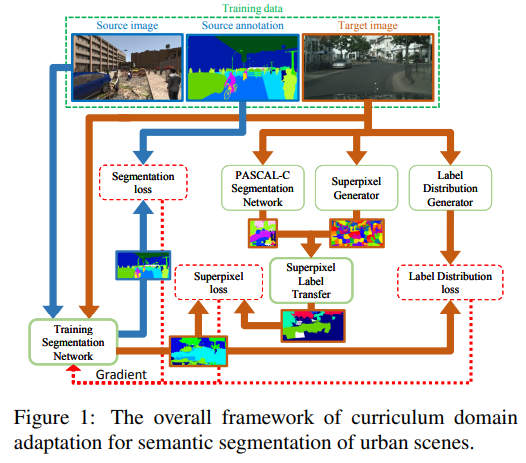

-
Class Matter: A Fine-grained Adversarial Approach to Cross-domain Semantic Segmentation(2020)
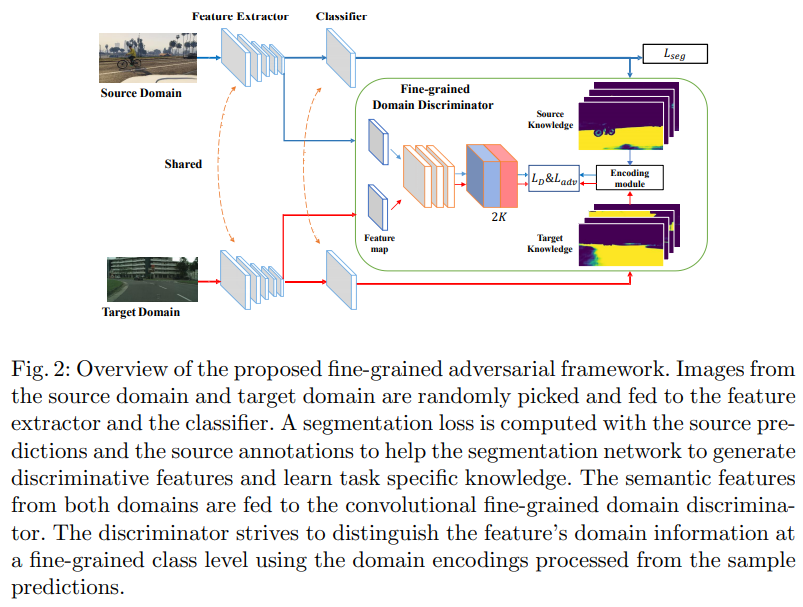

-
Content-Consistent Matching for Domain Apdaptive Semantic Segmentation(2020)
This paper considers the adaptation of semantic segmentation from the synthetic source domain to the real target domain. Different from most previous explorations that often aim at developing adversarial-based domain alignment solutions, we tackle this challenging task from a new perspective, mph{i.e.}, content-consistent matching (CCM). The target of CCM is to acquire those synthetic images that share similar distribution with the real ones in the target domain, so that the domain gap can be naturally alleviated by employing the content-consistent synthetic images for training. To be specific, we facilitate the CCM from two aspects, mph{i.e.}, semantic layout matching and pixel-wise similarity matching. First, we use all the synthetic images from the source domain to train an initial segmentation model, which is then employed to produce coarse pixel-level labels for the unlabeled images in the target domain. With the coarse/accurate label maps for real/synthetic images, we construct their semantic layout matrixes from both horizontal and vertical directions and perform the matrixes matching to find out the synthetic images with similar semantic layout to real images. Second, we choose those predicted labels with high confidence to generate feature embeddings for all classes in the target domain, and further perform the pixel-wise matching on the mined layout-consistent synthetic images to harvest the appearance-consistent pixels. With the proposed CCM, only those content-consistent synthetic images are taken into account for learning the segmentation model, which can effectively alleviate the domain bias caused by those content-irrelevant synthetic images. Extensive experiments are conducted on two popular domain adaptation tasks, mph{i.e.}, GTA5
Cityscapes and SYNTHIA Cityscapes. Our CCM yields consistent improvements over the baselines and performs favorably against previous state-of-the-arts.
本文研究了从合成源域到真实目标域的语义切分的自适应问题。与以往大多数旨在开发基于对抗的域对齐解决方案的探索不同,我们从一个新的角度,即内容一致性匹配(CCM)来处理这一具有挑战性的任务。CCM的目标是获取与目标域中真实图像具有相似分布的合成图像,从而利用内容一致的合成图像进行训练,自然地减少了域间的差距。具体来说,我们从语义布局匹配和像素相似性匹配两个方面对CCM进行了改进。首先,我们使用所有来自源域的合成图像来训练初始分割模型,然后利用该模型为目标域中的未标记图像生成粗像素级的标签。利用粗糙/精确的真实/合成图像标签映射,从水平和垂直两个方向构造其语义布局矩阵,并进行矩阵匹配,找出语义布局与真实图像相似的合成图像。第二,选择置信度高的预测标签,对目标域中的所有类别生成特征嵌入,并对挖掘出的布局一致的合成图像进行像素级匹配,得到外观一致的像素。提出的CCM算法只考虑那些内容一致的合成图像来学习分割模型,有效地缓解了那些内容无关的合成图像所带来的领域偏差。在两个流行的领域适应任务,即mph{i.e.},GTA5 Cityscapes和SYNTHIA Cityscapes上进行了广泛的实验。我们的CCM在基线上产生了一致的改进,并且与以前的技术状态相比表现良好。

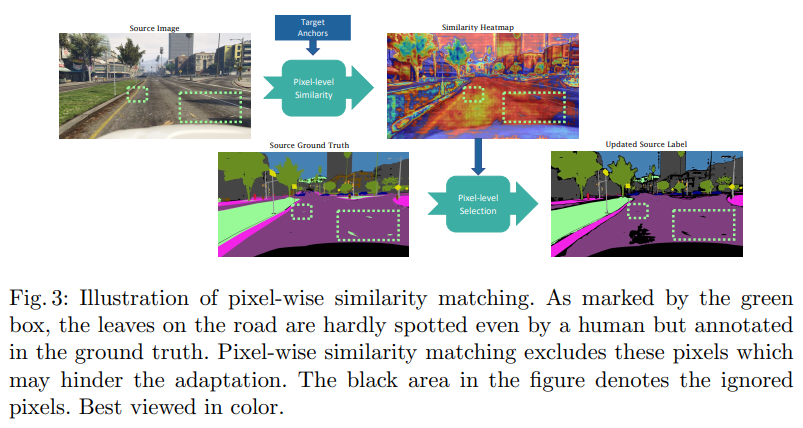
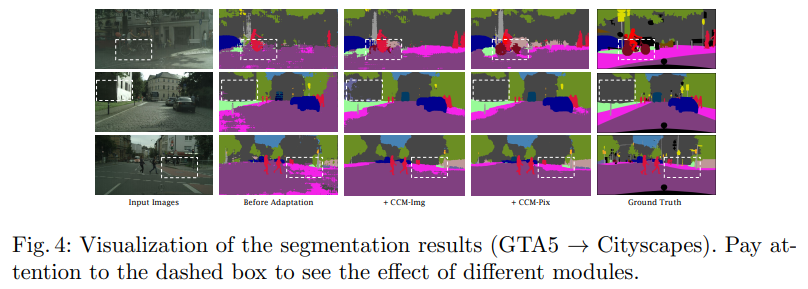

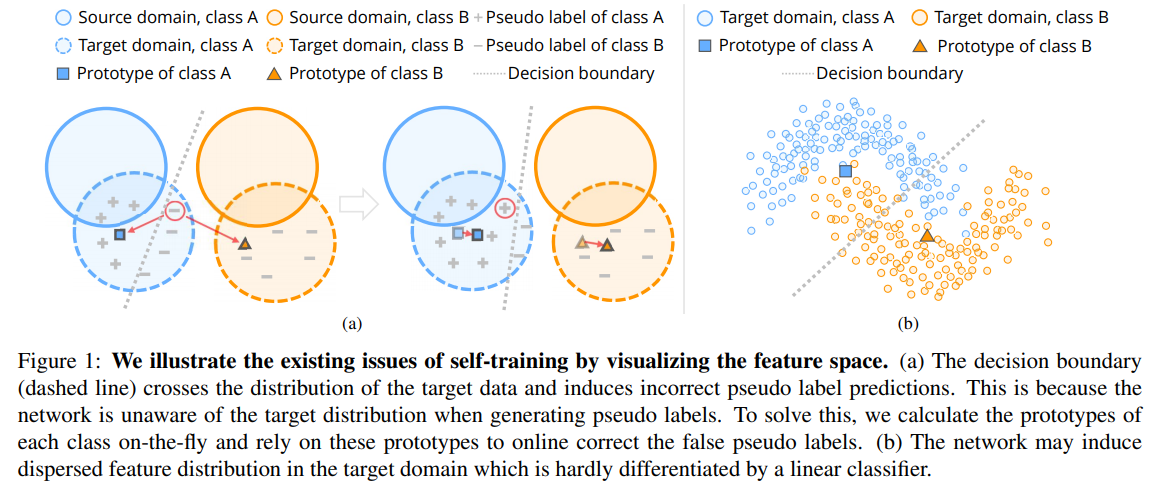
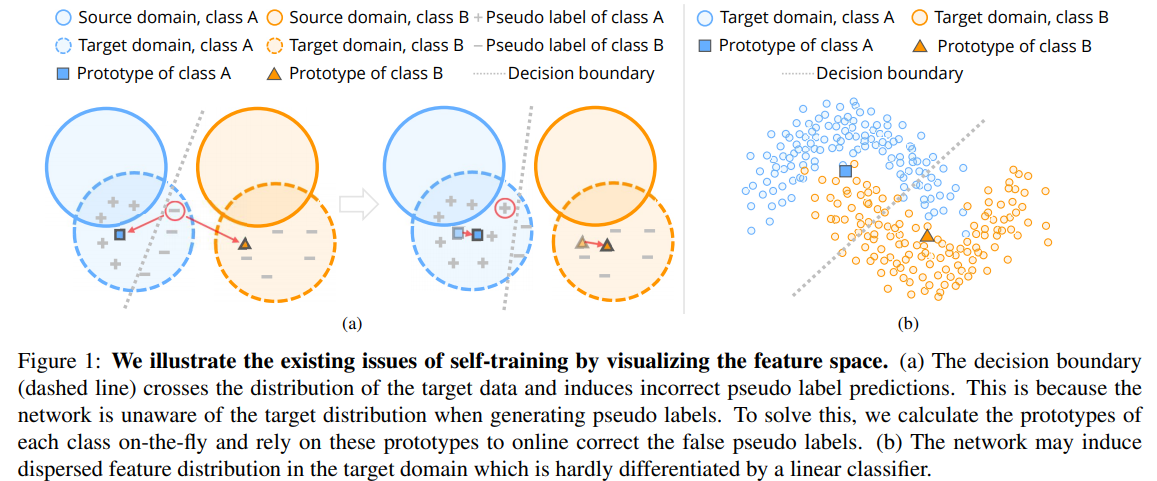
- Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation(2021)
Self-training is a competitive approach in domain adaptive segmentation, which trains the network with the pseudo labels on the target domain. However inevitably, the pseudo labels are noisy and the target features are dispersed due to the discrepancy between source and target domains. In this paper, we rely on representative prototypes, the feature centroids of classes, to address the two issues for unsupervised domain adaptation. In particular, we take one step further and exploit the feature distances from prototypes that provide richer information than mere prototypes. Specifically, we use it to estimate the likelihood of pseudo labels to facilitate online correction in the course of training. Meanwhile, we align the prototypical assignments based on relative feature distances for two different views of the same target, producing a more compact target feature space. Moreover, we find that distilling the already learned knowledge to a self-supervised pretrained model further boosts the performance. Our method shows tremendous performance advantage over state-of-the-art methods. We will make the code publicly available.
自训练是一种竞争性的领域自适应分割方法,它在目标域上训练带有伪标记的网络。然而,由于源域和目标域之间的差异,不可避免地会产生伪标签噪声和目标特征的离散化。在本文中,我们依靠具有代表性的原型,类的特征质心,来解决无监督域自适应的两个问题。特别是,我们更进一步,利用原型的特征距离,提供比单纯的原型更丰富的信息。具体来说,我们使用它来估计伪标签的可能性,以便在训练过程中进行在线校正。同时,针对同一目标的两个不同视图,基于相对特征距离对原型赋值进行对齐,得到更为紧凑的目标特征空间。此外,我们发现,将已学习的知识提取到一个自我监督的预训练模型中,可以进一步提高性能。与最先进的方法相比,我们的方法显示出巨大的性能优势。我们将公开代码。
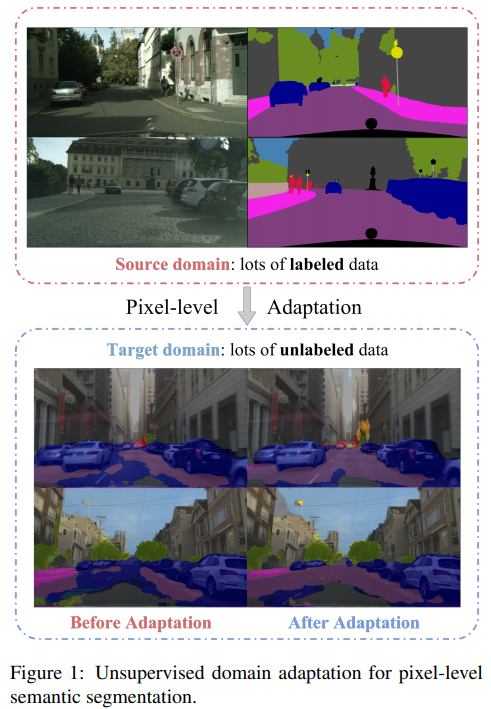
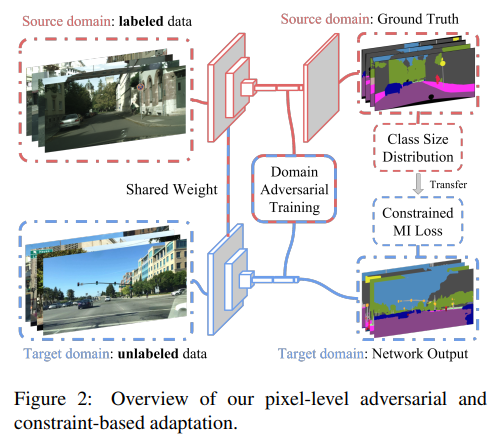
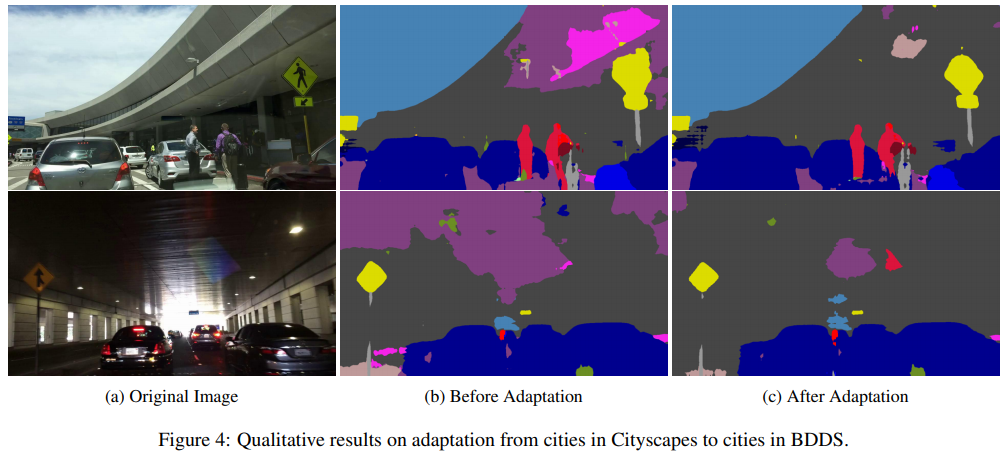
- FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation(2016)
用于密集预测的完全卷积模型已被证明在广泛的视觉任务中是成功的。这类模型在有监督的环境中表现良好,但在人类观察者看来温和的领域转移下,性能可能会出人意料地差。例如,在不同地理区域和/或天气条件下在一个城市进行培训和在另一个城市进行测试可能会由于像素级分布偏移而导致性能显著降低。在本文中,我们介绍了第一种领域自适应语义分割方法,提出了一种无监督对抗性的像素预测方法。我们的方法包括全局和特定类别的适应技术。全局域对齐是使用一种新的语义分割网络与完全卷积域对抗学习。这种初始的适应空间通过约束弱学习的泛化实现了特定类别的适应,并将空间布局从源域显式地转移到目标域。我们的方法在多个大规模数据集的不同设置上优于基线,包括在不同的真实城市环境、不同的合成子域、从模拟到真实的环境以及一个新的大规模行车记录仪数据集上进行自适应。

- Instance Adaptive Self-Training for Unsupervised Domain Adaptation(2020)
标记训练数据和未标记测试数据之间的差异是当前深度学习模型面临的一个重大挑战。无监督域自适应(UDA)试图解决这样一个问题。最近的研究表明,自我训练是一种有效的方法。然而,现有的方法很难平衡可伸缩性和性能。本文提出了一种基于实例自适应的语义切分自学习框架。为了有效地提高伪标签的质量,我们提出了一种基于实例自适应选择器的伪标签生成策略。此外,我们还提出了区域引导正则化方法来平滑伪标记区域和锐化非伪标记区域。该方法简洁有效,易于推广到其它无监督域自适应方法。在“GTA5到城市景观”和“SYNTHIA到城市景观”上的实验表明,与最先进的方法相比,我们的方法具有优越的性能。

- Permuted AdaIN: Reducing the Bias Towards Global Statistics in Image Classification(2020)
最近的研究表明,卷积神经网络分类器过度依赖于纹理而牺牲了形状线索。一方面,我们对形状和局部图像线索以及全局图像统计进行了相似但不同的区分。我们的方法称为置换自适应实例归一化(pAdaIN),减少了图像分类器隐藏层中全局统计信息的表示。pAdaIN样本一种随机排列,在给定的批次中重新排列样本。然后在每个(非置换)样本的激活和样本的相应激活之间应用自适应实例规范化(AdaIN),从而在批处理的样本之间交换统计信息。由于全局图像统计信息被扭曲,这种交换过程导致网络依赖于诸如形状或纹理之类的线索。通过概率选择随机排列,反之选择同一排列,可以控制效果的强弱。在正确的选择,所有实验的固定先验和不考虑测试数据的情况下,我们的方法在多种情况下都优于基线。在图像分类方面,我们的方法在CIFAR100和ImageNet的基础上进行了改进,采用了多种结构。在鲁棒性方面,我们的方法对ImageNet-C和Cifar-100-C进行了改进。在领域自适应和领域泛化的背景下,我们的方法在从GTAV到Cityscapes的迁移学习任务和PACS基准上取得了最新的成果。

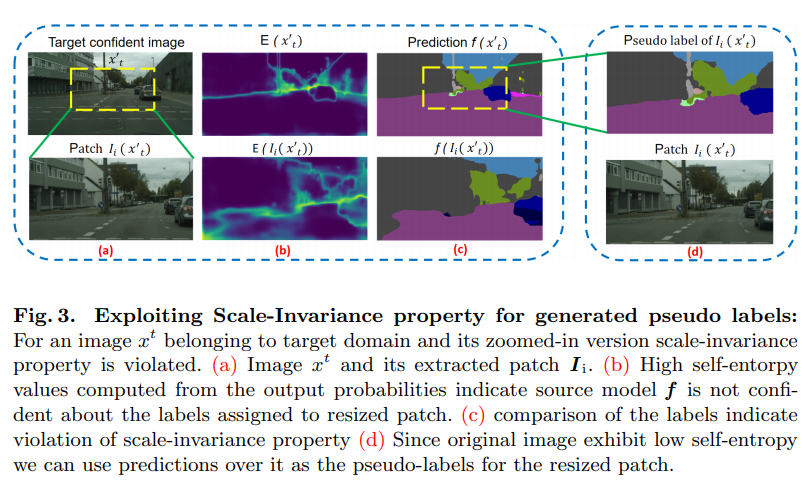
- Learning from Scale-Invariant Examples for Domain Adaptation in Semantic Segmentation(2020)
用于语义切分模型的无监督域自适应(UDA)的自监督学习方法面临着预测和选择合理的高质量伪标签的挑战。本文提出了一种利用语义分割模型的尺度不变性进行自监督域自适应的新方法。我们的算法基于一个合理的假设,即一般来说,不管对象和内容的大小(给定上下文),语义标签都应该保持不变。我们表明,这个约束是违反了图像的目标领域,因此可以用来转移标签之间的不同比例的补丁。具体地说,我们表明,语义分割模型产生高熵的输出时,提出了扩大补丁的目标领域,相比之下,当提出原始大小的图像。这些尺度不变的例子是从目标域的最可靠的图像中提取的。为了滤除不可靠的伪标签,提出了动态类特定熵阈值机制。此外,我们还结合焦点损失来解决自我监督学习中的班级不平衡问题。大量的实验结果表明,利用尺度不变性标记,我们的性能优于现有的基于自监督的领域自适应方法。具体而言,我们通过VGG16-FCN8基线网络实现了GTA5到城市景观和SYNTHIA到城市景观的1.3%和3.8%的铅含量。



Multimodal Unsupervised Image-to-Image Translation
Multimodal unsupervised image-to-image translation is the task of producing multiple translations to one domain from a single image in another domain.
多模态无监督图像到图像的翻译是指从一幅图像到另一幅图像的多幅翻译。
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks(2017)
- Multimodal Unsupervised Image-to-Image Translation(2018)
- Unsupervised Image-to-Image Translation Networks(2017)
- StarGAN v2: Diverse Image Synthesis for Multiple Domains(2020)
- Diverse Image-to-Image Translation via Disentangled Representations(2018)
- High-Resolution Daytime Translation Without Domain Labels(2020)
- Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis(2019)
- Lifespan Age Transformation Synthesis(2020)
- Breaking the Cycle - Colleagues Are All You Need(2020)
- Breaking the cycle – Colleagues are all you need(2019)
- Image-to-image Translation via Hierarchical Style Disentanglement(2021)
- In2I : Unsupervised Multi-Image-to-Image Translation Using Generative Adversarial Networks(2017)
Fundus to Angiography Generation
Generating Retinal Fluorescein Angiography from Retinal Fundus Image using Generative Adversarial Networks.
利用生成对抗网络从视网膜眼底图像生成视网膜荧光素血管造影。
- Image-to-Image Translation with Conditional Adversarial Networks(2017)
- U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation(2020)
- High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs(2018)
- StarGAN v2: Diverse Image Synthesis for Multiple Domains(2020)
- 0-Step Capturability, Motion Decomposition and Global Feedback Control of the 3D Variable Height-Inverted Pendulum(2019)
- Attention2AngioGAN: Synthesizing Fluorescein Angiography from Retinal Fundus Images using Generative Adversarial Networks(2020)
- Fundus2Angio: A Conditional GAN Architecture for Generating Fluorescein Angiography Images from Retinal Fundus Photography(2020)
- VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers(2021)
Cross-View Image-to-Image Translation
跨视图图像到图像的转换
- Image-to-Image Translation with Conditional Adversarial Networks(2017)
- Multi-Channel Attention Selection GAN with Cascaded Semantic Guidance for Cross-View Image Translation(2019)
- A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird’s Eye View(2020)
- Cross-view image synthesis using geometry-guided conditional GANs(2018)
- Cross-View Image Synthesis using Conditional GANs(2018)
- Cross-View Image Matching for Geo-localization in Urban Environments(2017)
- Predicting Ground-Level Scene Layout from Aerial Imagery(2017)
Image Inpainting
Image Inpainting is a task of reconstructing missing regions in an image. It is an important problem in computer vision and an essential functionality in many imaging and graphics applications, e.g. object removal, image restoration, manipulation, re-targeting, compositing, and image-based rendering.
图像修复是一项重建图像中缺失区域的任务。它是计算机视觉中的一个重要问题,也是许多图像和图形应用中的一个重要功能,例如对象移除、图像恢复、操作、重定位、合成和基于图像的绘制。
Facial Inpainting
Facial inpainting (or face completion) is the task of generating plausible facial structures for missing pixels in a face image.
面部修复(或面部完成)是为面部图像中缺失的像素生成合理的面部结构的任务。
- SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color(2019)
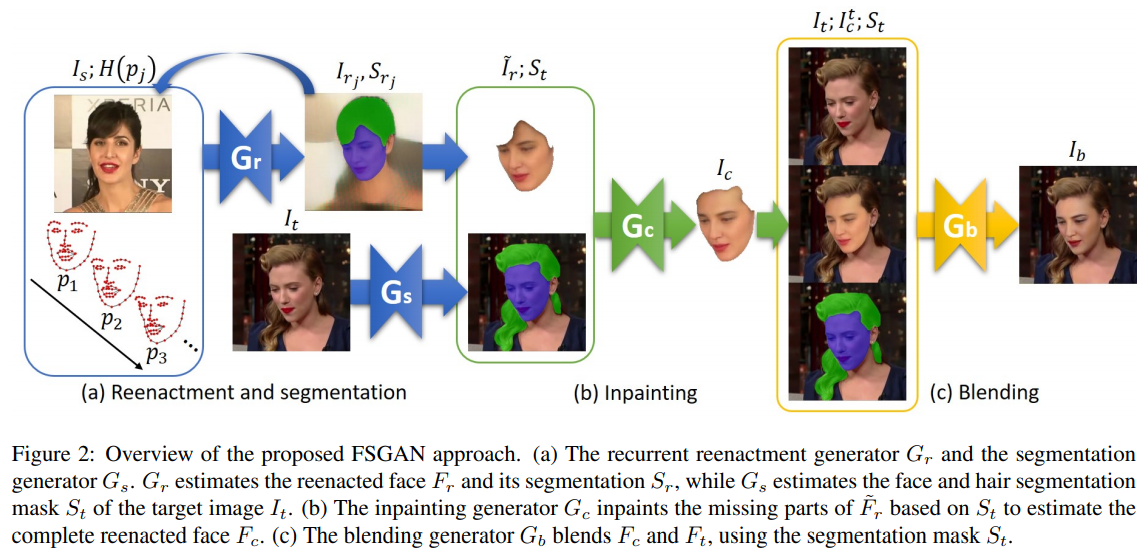
- FSGAN: Subject Agnostic Face Swapping and Reenactment(2019)
我们提出了人脸交换GAN(FSGAN)来实现人脸交换和再现。与以前的工作不同,FSGAN是不可知主体的,可以应用于成对的人脸,而不需要对这些人脸进行训练。为此,我们介绍了一些技术贡献。我们提出了一种新的基于递归神经网络(RNN)的人脸重构方法,该方法可以调整姿态和表情的变化,并且可以应用于单个图像或视频序列。对于视频序列,我们引入了基于重影、Delaunay三角剖分和重心坐标的连续人脸视图插值。遮挡的人脸区域由人脸完成网络处理。最后,我们使用一个人脸融合网络,在保持目标肤色和光照条件的前提下,对两个人脸进行无缝融合。该网络采用了一种新的泊松混合损失,它将泊松优化与感知损失相结合。我们将我们的方法与现有的最先进的系统进行了比较,结果表明我们的结果在质量和数量上都是优越的。
FSGAN: Subject Agnostic Face Swapping and Reenactment
fsgan


- LaFIn: Generative Landmark Guided Face Inpainting(2019)
- FCSR-GAN: Joint Face Completion and Super-resolution via Multi-task Learning(2019)
- Learning Symmetry Consistent Deep CNNs for Face Completion(2018)
- Does Generative Face Completion Help Face Recognition?(2018)
- Generative Face Completion(2017)
- Detecting Overfitting of Deep Generative Networks via Latent Recovery(2019)
Image Outpainting
Predicting the visual context of an image beyond its boundary.
预测图像边界以外的视觉背景。
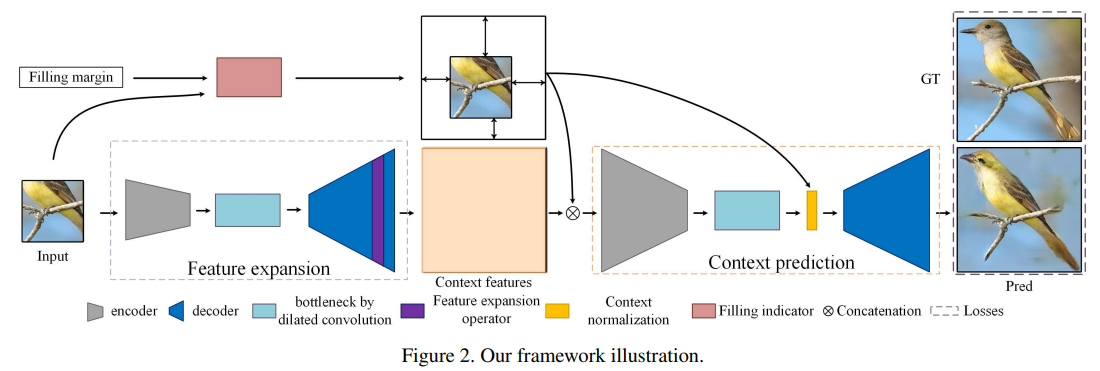
- Wide-Context Semantic Image Extrapolation(2019)
本文研究了利用深层生成模型外推视觉语境的基本问题,即用合理的结构和细节扩展图像边界。这项看似简单的任务实际上面临许多关键的技术挑战,并且有其独特的特性。两大问题是规模扩张和单边约束。我们提出了一个具有多个特殊贡献的语义再生网络,并利用多个空间相关损失来解决这些问题。我们的结果包含了一致的结构和高质量的纹理。对各种可能的替代方案和相关方法进行了广泛的实验。我们还探讨了我们的方法对于各种有趣的应用的潜力,这些应用可以有益于各个领域的研究。
Wide-Context Semantic Image Extrapolation
outpainting_srn



- Painting Outside the Box: Image Outpainting with GANs(2018)
- Very Long Natural Scenery Image Prediction by Outpainting(2019)
- SiENet: Siamese Expansion Network for Image Extrapolation(2020)
- Multimodal Image Outpainting With Regularized Normalized Diversification(2019)
- Image Outpainting and Harmonization using Generative Adversarial Networks(2019)
- Enhanced Residual Networks for Context-based Image Outpainting(2020)
Cloud Removal
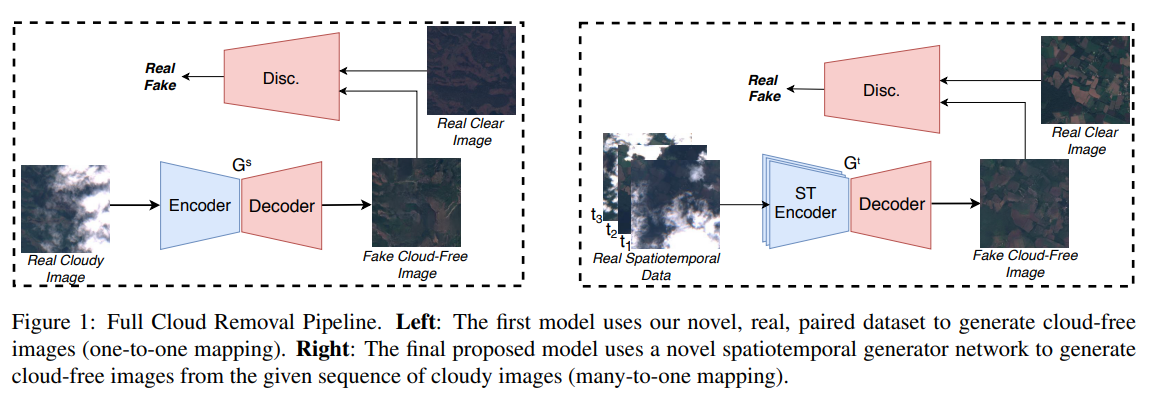
- A Remote Sensing Image Dataset for Cloud Removal(2019)
光学遥感图像中经常存在云覆盖,限制了采集数据的应用。去云是遥感图像分析中不可缺少的预处理步骤。近年来,深度学习在遥感领域取得了巨大的成功,包括场景分类和变化检测。然而,深度学习在遥感图像去云中的应用却很少。原因是缺乏训练神经网络的数据集。为了解决这一问题,本文首先提出了遥感图像去云数据集(RICE)。该数据集由两部分组成:RICE1包含500对图像,每对图像都有云和无云大小为512×512的图像;RICE2包含450组图像,每组包含三个512*512大小的图像。分别是无云的参考图、云的图片和云的遮罩。
A Remote Sensing Image Dataset for Cloud Removal
RICE_DATASET


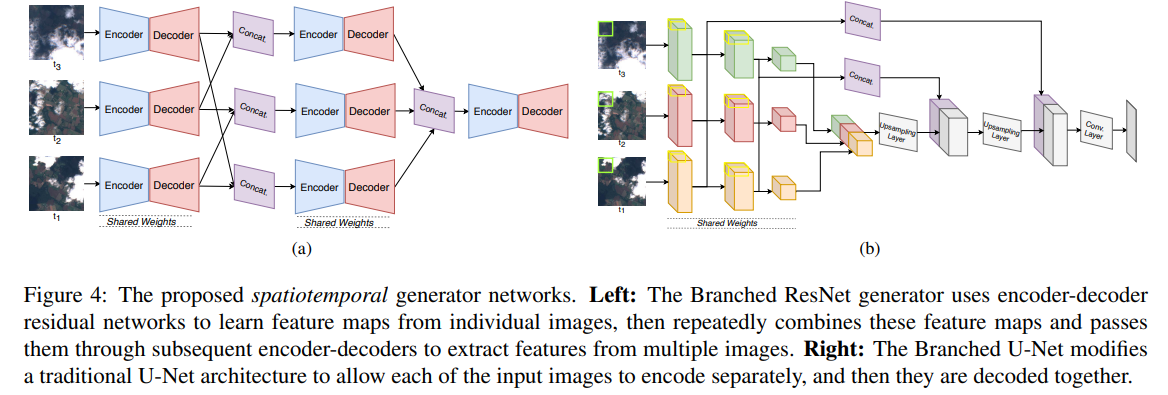
- Cloud Removal in Satellite Images Using Spatiotemporal Generative Networks(2019)
卫星图像在环境连续监测和地球观测方面具有巨大的应用前景。然而,云层造成的遮挡会严重限制覆盖范围,使得地面信息提取更加困难。现有的管道通常使用简单的时间合成和手工制作的过滤器来执行云移除。与此相反,我们将去云问题视为条件图像合成的挑战,并提出一个可训练的时空发生器网络(STGAN)去云。我们在一个新的大规模时空数据集上训练我们的模型,这个数据集包含了覆盖所有大陆的97640个图像对。实验结果表明,所提出的STGAN模型的性能优于标准模型,能够在各种大气条件下生成具有高PSNR和SSIM值的真实无云图像,从而提高了下游任务(如土地覆盖分类)的性能。
Cloud Removal in Satellite Images Using Spatiotemporal Generative Networks
stgan


Fine-Grained Image Inpainting
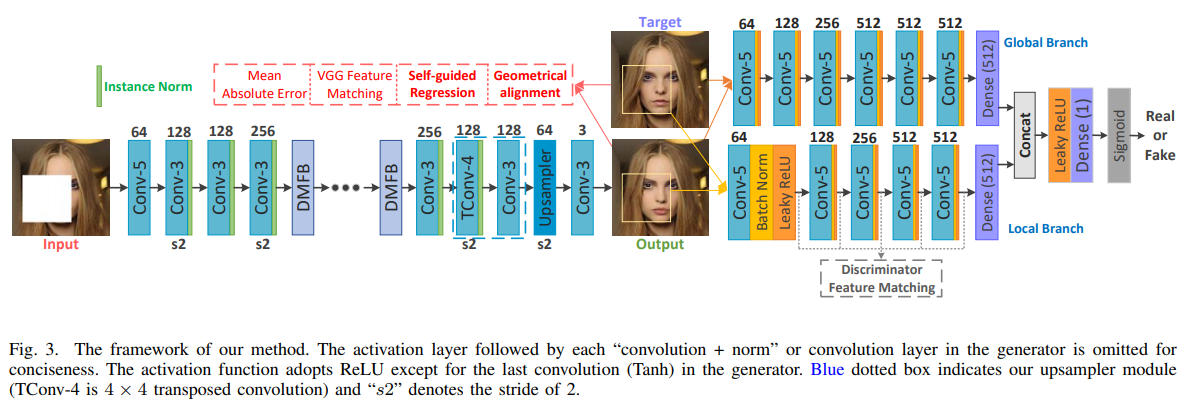
- Image Fine-grained Inpainting(2020)
近年来,在生成性对抗网络的帮助下,图像修复技术有了很大的发展。然而,它们大多存在着结构不合理、结果模糊等问题。为了缓解这个问题,在本文中,我们提出了一个单阶段模型,利用密集的扩张卷积组合,以获得更大和更有效的感受野。得益于这种网络的特性,我们可以更容易地恢复不完整图像中的大区域。为了更好地训练这种高效的生成器,除了常用的VGG特征匹配损失外,我们还设计了一种新的自引导回归损失,用于集中不确定区域和增强语义细节。此外,我们设计了一个几何对齐约束项来补偿基于像素的预测特征和地面真实特征之间的距离。我们还采用了具有本地和全局分支的鉴别器来确保本地和全局内容的一致性。为了进一步提高生成图像的质量,引入了基于局部分支的鉴别器特征匹配,动态地最小化了合成真面片和地面真面片中间特征的相似度。在几个公共数据集上的大量实验表明,我们的方法优于目前最先进的方法。
Fine-Grained Image Inpainting
DMFN



Conditional Image Generation
Conditional image generation is the task of generating new images from a dataset conditional on their class.
条件图像生成的任务是根据类的条件从数据集中生成新图像。
Face Generation
Face generation is the task of generating (or interpolating) new faces from an existing dataset.
The state-of-the-art results for this task are located in the Image Generation parent.
人脸生成是从现有数据集生成(或插值)新人脸的任务。 此任务的最新结果位于图像生成父级中。
Talking Head Generation
Talking head generation is the task of generating a talking face from a set of images of a person.
会说话的头生成是从一组人的图像中生成会说话的脸的任务。
Talking Face Generation
Face Age Editing
Text-to-Image Generation
参考资料
One-Shot Unsupervised Cross Domain Translation
OneShotTranslation
Bidirectional One-Shot Unsupervised Domain Mapping
BiOST
Virtual to Real Reinforcement Learning for
Autonomous Driving
Autopilot-TensorFlow
CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION
cycada_release
Domain Adaptation for Structured Output via
Discriminative Patch Representations
AdaptSegNet
Learning to Adapt Structured Output Space for Semantic Segmentation
Diverse Image-to-Image Translation via Disentangled Representations
DRIT
Taking A Closer Look at Domain Shift:
Category-level Adversaries for Semantics Consistent Domain Adaptation
CLAN
Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
CBST
All about Structure: Adapting Structural Information across Domains for Boosting Semantic Segmentation
DISE-Domain-Invariant-Structure-Extraction
Curriculum Domain Adaptation for Semantic Segmentation of Urban Scenes
A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
AdaptationSeg
Classes Matter: A Fine-grained Adversarial Approach to Cross-domain Semantic Segmentation
FADA
Content-Consistent Matching for Domain Adaptive Semantic Segmentation
CCM
Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation
ProDA
FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation
Domain-adaptation-on-segmentation
Instance Adaptive Self-Training for Unsupervised Domain Adaptation
IAST
Permuted AdaIN: Reducing the Bias Towards Global Statistics in Image Classification
PermutedAdaIN
Learning from Scale-Invariant Examples for Domain Adaptation in Semantic Segmentation
LSE
最后
以上就是超帅滑板最近收集整理的关于Image GenerationImage-to-Image TranslationImage InpaintingConditional Image GenerationFace GenerationText-to-Image Generation的全部内容,更多相关Image内容请搜索靠谱客的其他文章。








发表评论 取消回复