今日CS.CV 计算机视觉论文速览
Mon, 20 May 2019
Totally 25 papers
?上期速览✈更多精彩请移步主页

Interesting:
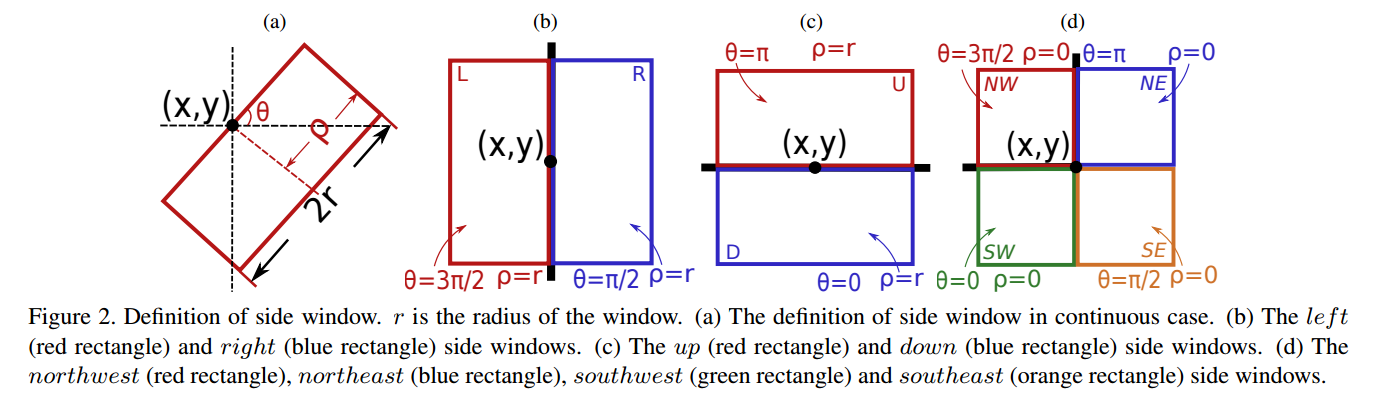
?边窗滤波Side Window Filtering,SWF, 中心的滤波框是造成边缘模糊的基本原因,研究人员提出了将框的边缘或者角点而不是中心用于待处理的像素位置。这种简单但有效的方法具有广泛的拓展性,并用于多种早期视觉任务中去。(from 深圳大学)
目标像素不会处于边缘的中心,而是一边。所以将目标像素作为潜在边缘处理,并将某个窗的边缘或者角点与目标像素对齐,输出则是一系列边窗的叠加。
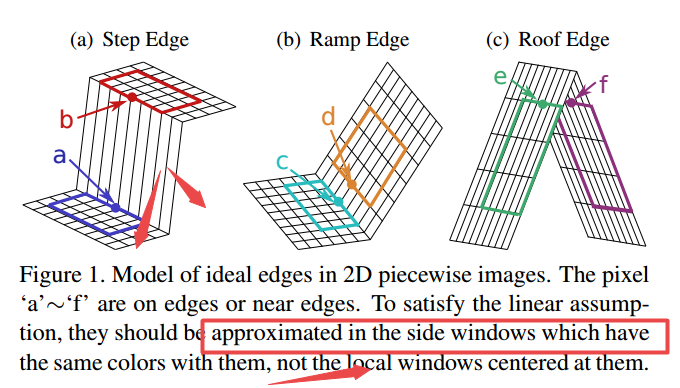
边窗滤波器的构造,分为了旋转,左右,上下和四角,可以看到待处理的像素都位于某个小边框的角点或者边缘上。
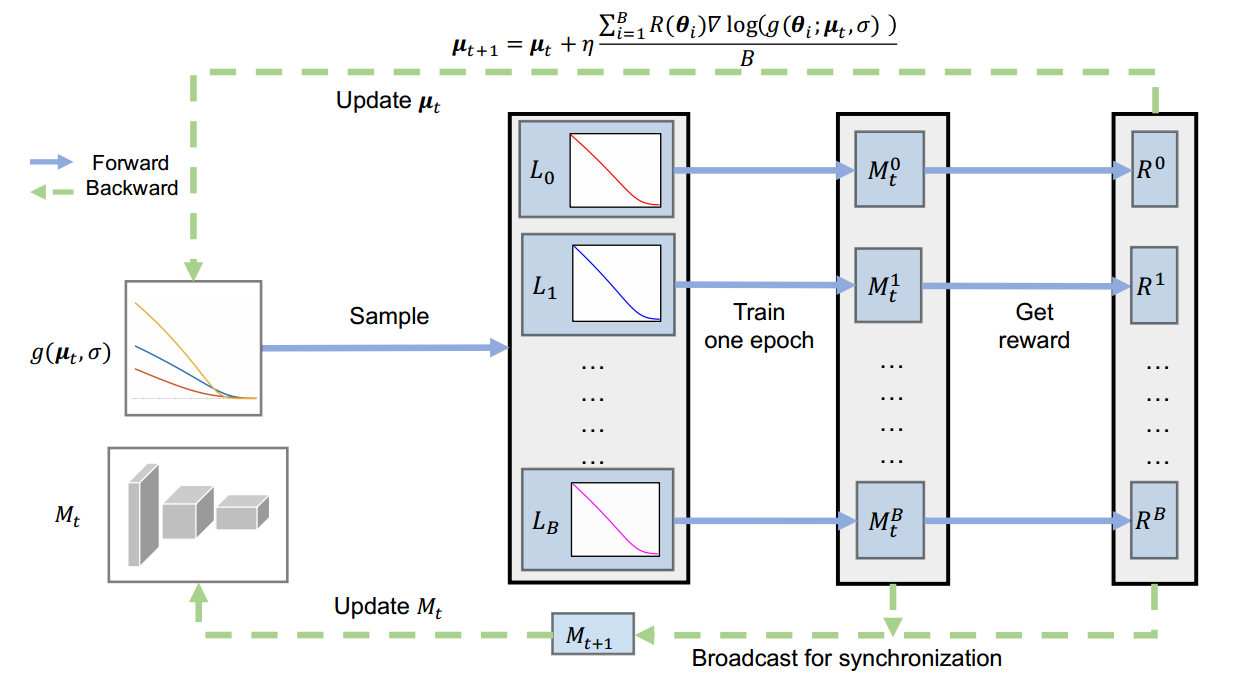
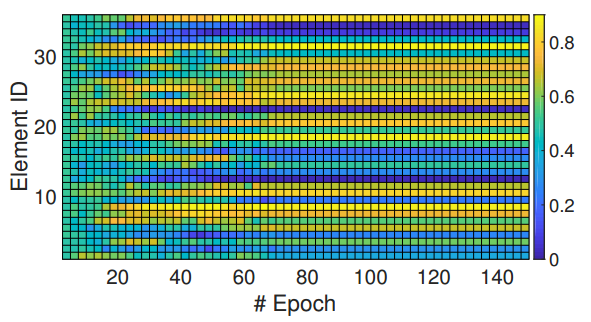
?AM-LFS用于损失函数搜索的自动机器学习, 损失函数的设计对于模型训练至关重要,这篇文章提出了一种用于损失函数搜索的自动机器学习方法,将强化学习用于了损失函数搜索。关键的贡献在于对于搜索空间的设计可以保证在不同版本任务上的泛化性和迁移性。同时提出了高效的优化方法在训练过程中高效的优化损失函数的参数分布。(from 商汤)
内部最小化样本损失,外部最大化网络的奖励:
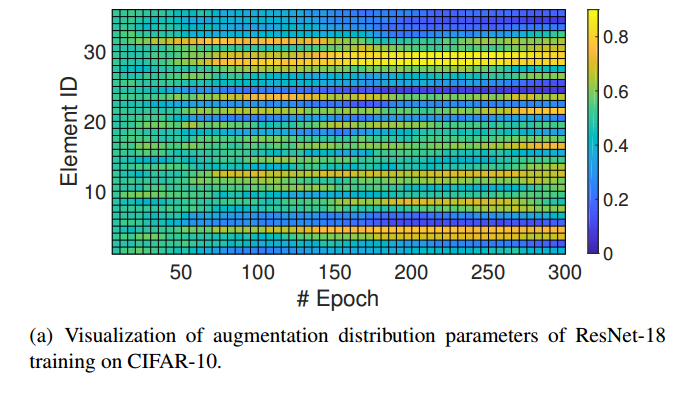
?OHL-Auto-Aug在线超参数学习用于自动增强策略, 一种经济的方法来学习数据增强策略,基于参数化的概率分布,使得参数可以与网络共同优化,消除了充分训练和全局搜索的繁杂。(from 商汤 香港中文)
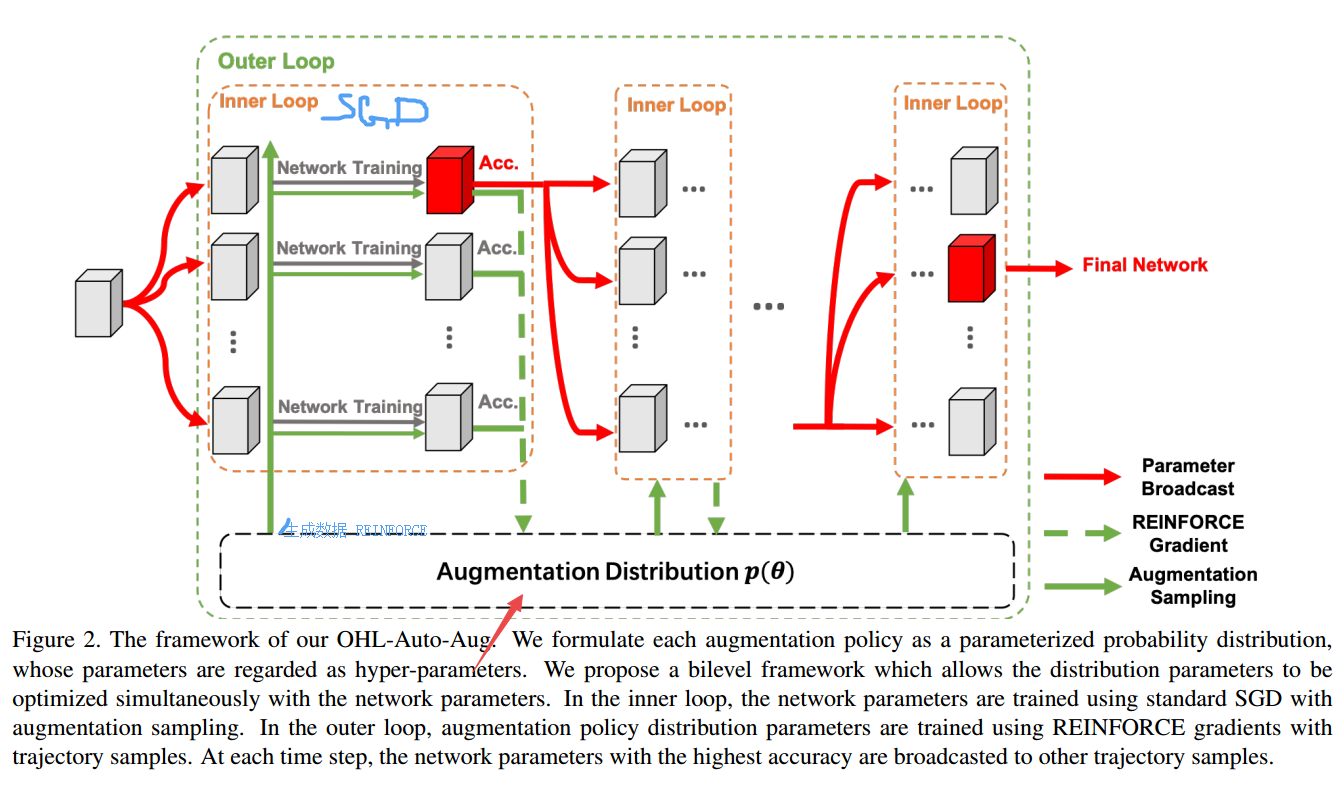
在训练过程中,数据增强分布逐渐收敛:
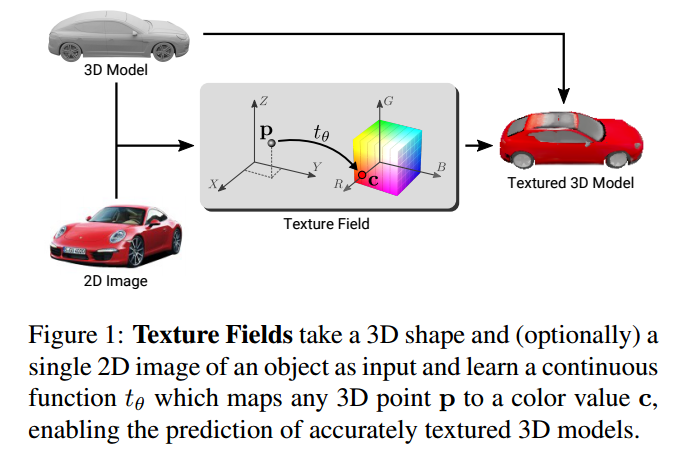
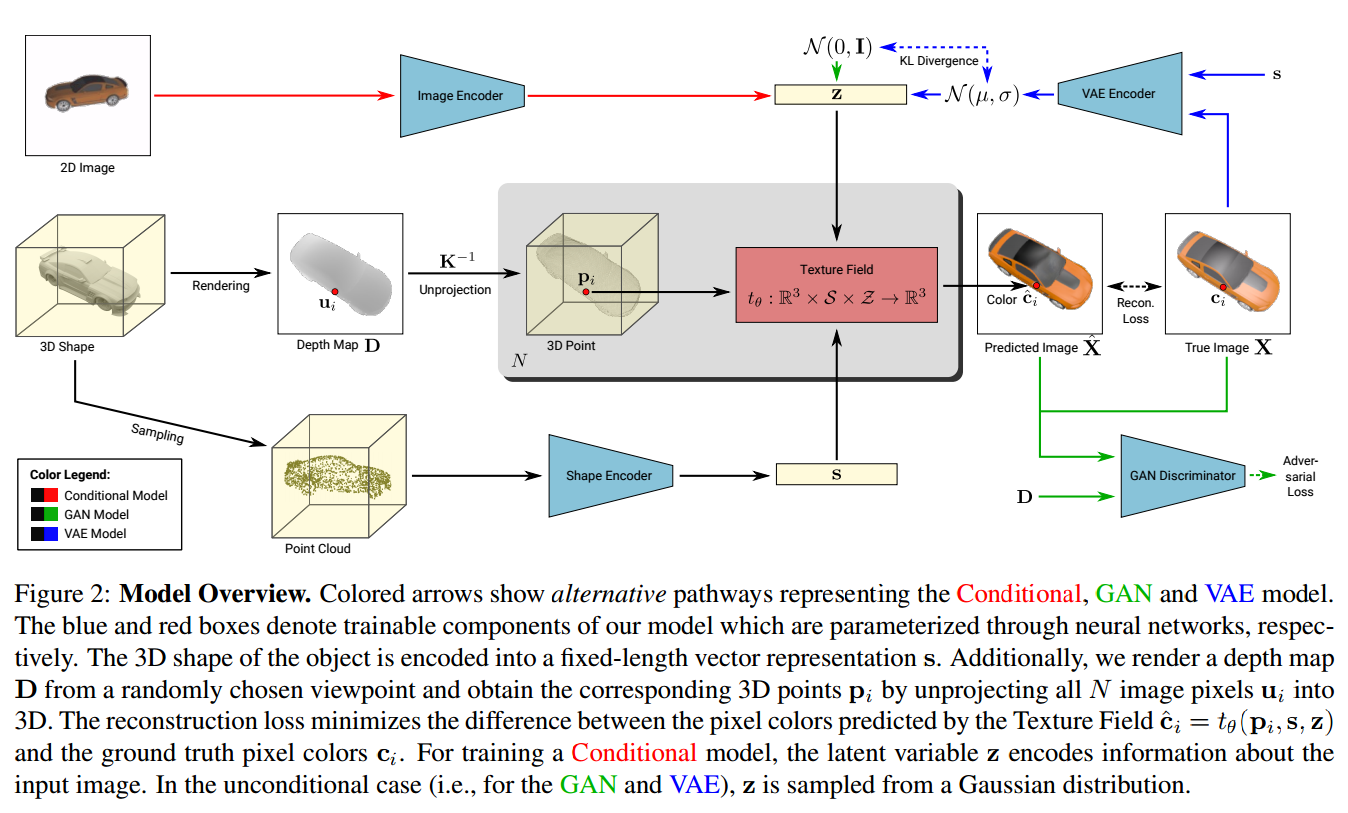
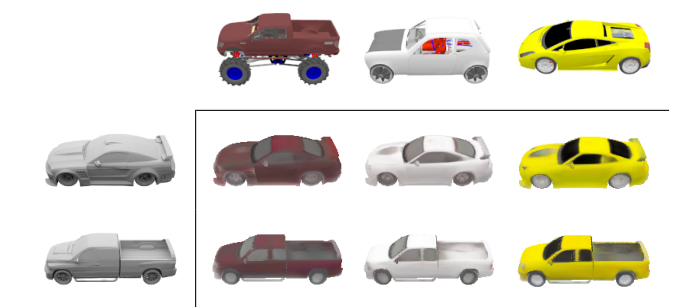
?Texture Fields在函数空间中学习纹理表示, 点云的纹理映射问题,研究人员提出了纹理场的概念,在连续的3D函数参数化网络上实现新颖的纹理表示。绕开了形状离散和参数化,用独立于形状的纹理表示方法来进行映射。(from 图宾根大学 & MPI)
纹理场的表示能力:

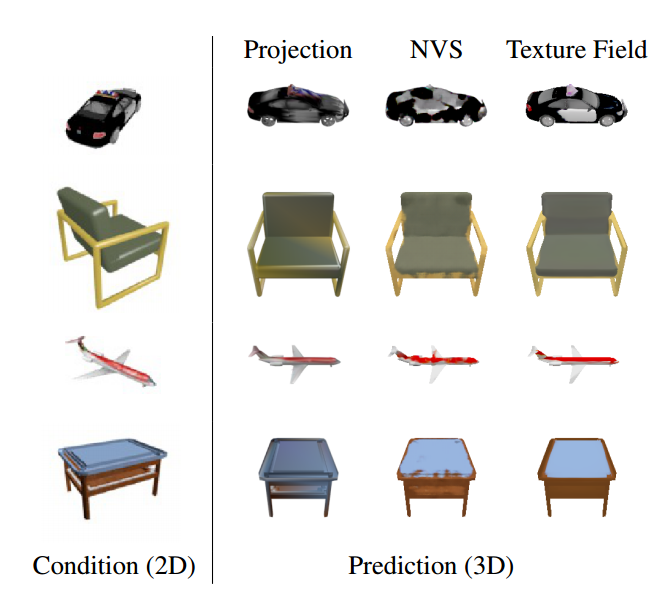
隐空间插值和纹理迁移:

ref:https://github.com/syb7573330/im2avatar
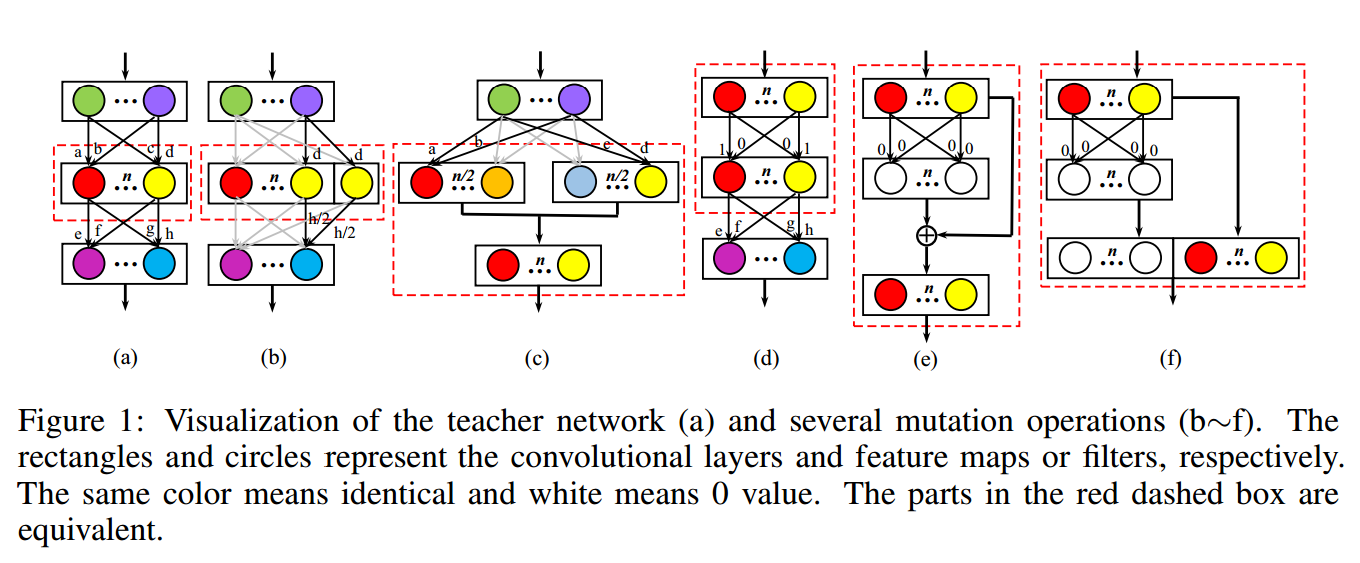
?EENA神经网络的高效进化, 自动神经架构搜索近年来取得了很大的成就但在搜索时的无方向性造成了计算量庞大。为了解决这一问题,这篇文章提出了名为EENA的进化方法,基于变异和交叉操作,将已经学习到的信息作为引导来为后续学习提供方向。在CIFAR-10上仅仅利用0.65GPU日就实现了8.47M参数的2.56%测试误差的架构,并可以方便地迁移到CIFAR-100。(from 中科院大学)
一些变异操作:
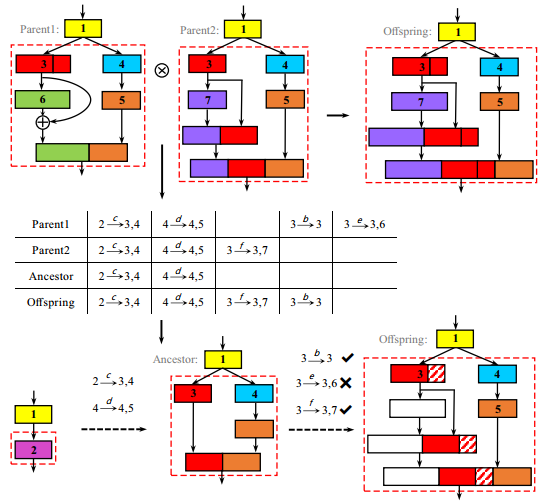
模型搜索过程中的树结构:
?单图像深度估计的理解, 研究了网络如何从rgb中学习到深度的过程,以MonoDepth为例探索了网络用于深度估计的视觉信息,发现了网络会忽略清晰尺寸而比较倾向利用垂直位置,但同时也需要已知相机位姿,在滚转和俯仰的情况下深度估计将变得不准。从垂直图像位置来估计深度但需要较强的边缘特征。 (from 代尔夫特理工)

?激光雷达传感器建模和数据增强, 利用图像迁移的方法从非配对数据中利用CycleGan建立传感器模型,并利用仿真环境sim2real得到逼真的激光雷达数据。还利用real2real从低分辨率数据得到了高分辨的激光雷达数据,激光雷达数据在鸟瞰视角(• Bird-eye View ,2D BEV)和2D极视角下(• Polar-Grid Map, 2D PGM)进行表示。(from 法雷奥Valeo)
真实数据与合成数据:


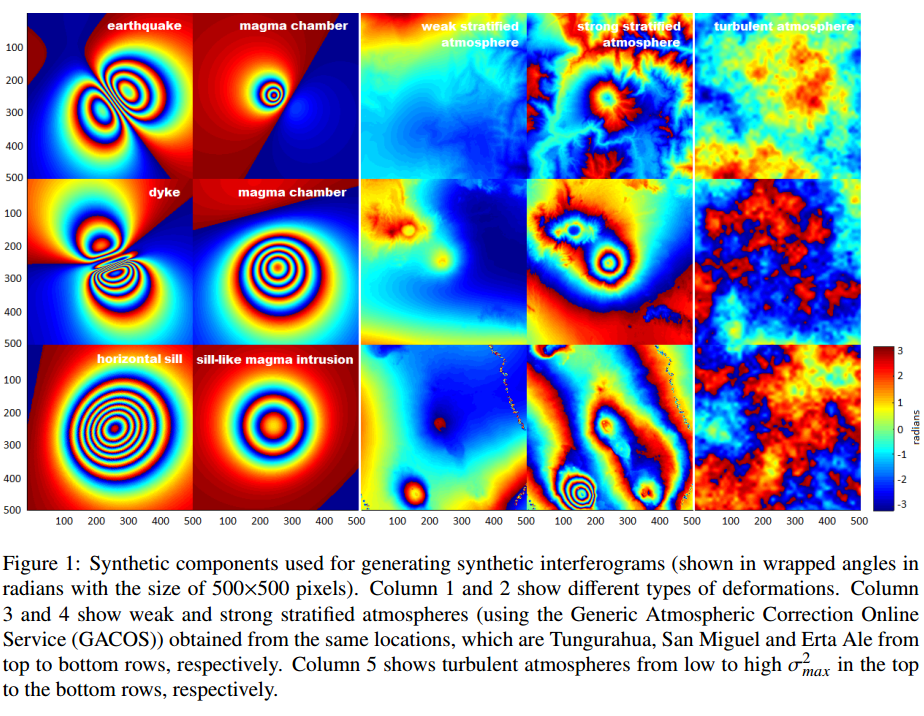
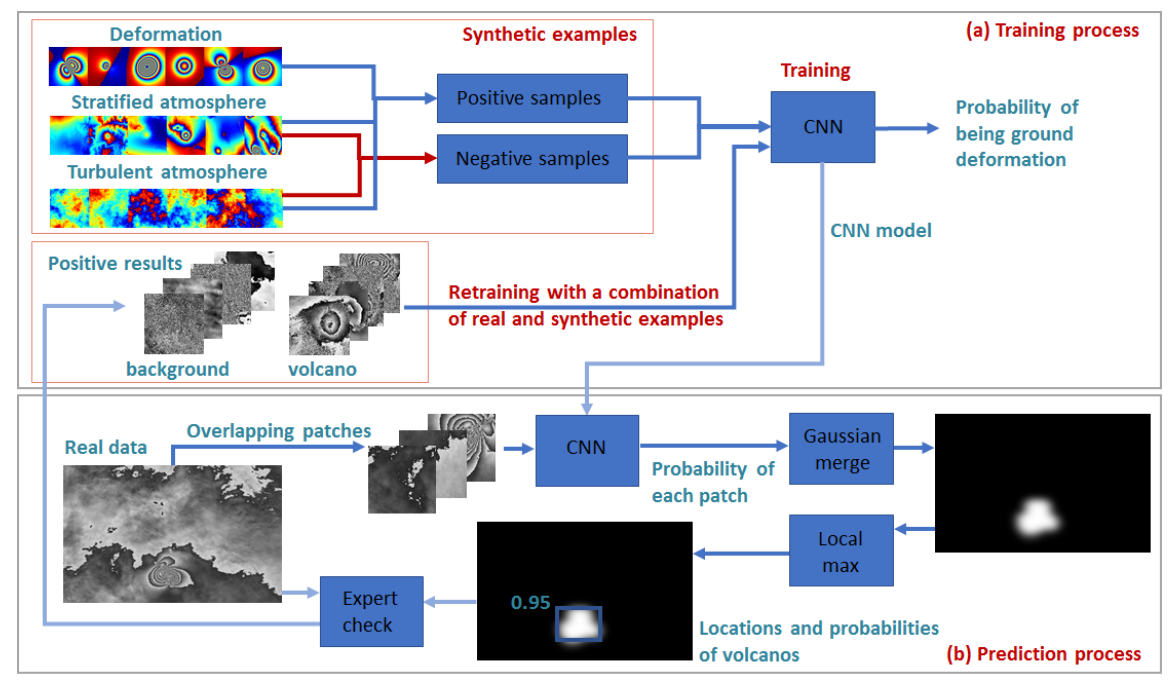
?火山形变过程检测, 基于卫星合成孔径干涉仪得到的大气模式来进行火山形变过程检测。(from 英国布里斯托大学)
基于合成数据生成的形变模式和对应的大气分层图像:
合成数据训练及预测过程:
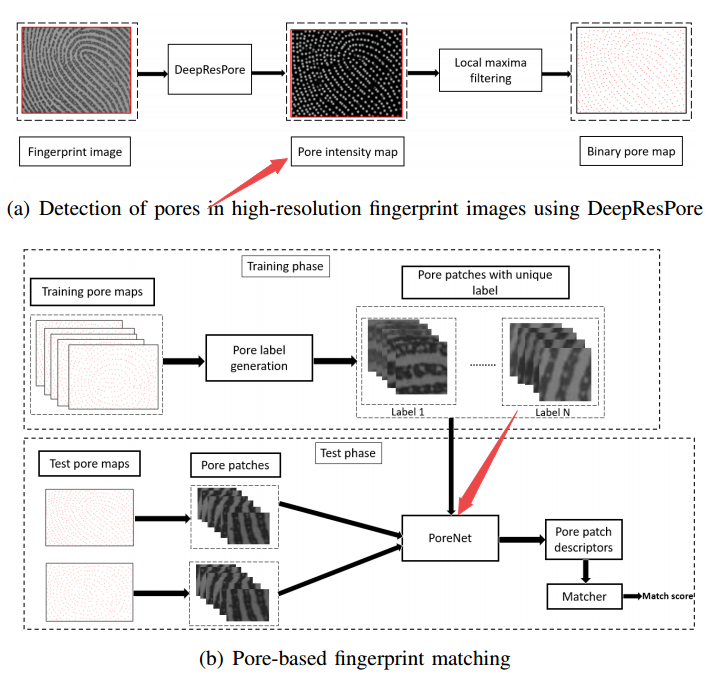
?PoreNet基于毛孔的高分辨率指纹识别系统, (from IIT Indore)
基于毛孔的指纹识别过程:
Daily Computer Vision Papers
| Neural Message Passing on Hybrid Spatio-Temporal Visual and Symbolic Graphs for Video Understanding Authors Effrosyni Mavroudi, Benjam n B jar Haro, Ren Vidal 视频理解中的许多问题需要标记在视频的不同部分同时发生的多个活动,包括参与这些活动的对象和参与者。然而,计算机视觉中的现有技术方法主要关注诸如动作分类,动作检测或动作分割之类的任务,其中通常仅需要预测一个动作标签。在这项工作中,我们提出了一种通用方法,用于对基于视频中的空间定位语义实体(例如演员和对象)的时空图的一个或多个节点进行分类。特别地,我们将基于语义标签空间的归因符号图与捕获视觉上下文和交互的属性时空视觉图组合,后者捕获多个标签之间的关系。我们进一步提出了一种神经消息传递框架,用于联合细化混合视觉符号图的节点和边缘的表示。我们的框架具有节点类型和边缘类型条件滤波器和自适应图形连接,用于将视觉节点连接到符号节点的软分配模块,反之亦然,用于强制语义一致性的ca符号图推理模块和用于聚合精细节点的da pooling模块和下游分类任务的边缘表示。我们展示了我们的方法在各种任务上的一般性,例如CAD 120数据集上的时间子活动分类和对象可供性分类以及大规模Charades数据集上的多标签时间动作定位,其中我们仅使用原始方法优于现有的深度学习方法RGB帧。 |
| AM-LFS: AutoML for Loss Function Search Authors Chuming Li, Chen Lin, Minghao Guo, Wei Wu, Wanli Ouyang, Junjie Yan 设计有效的损失函数在视觉分析中起着重要作用。大多数现有的损失函数设计依赖于手工制作的启发式方法,这需要领域专家来探索大型设计空间,这通常是次优和耗时的。在本文中,我们提出了用于损失函数搜索AM LFS的AutoML,它利用REINFORCE在训练过程中搜索损失函数。这项工作的关键贡献是搜索空间的设计,通过在一个统一的公式中包含一堆现有的主要损失函数,可以保证不同视觉任务的泛化和可转移性。我们还提出了一种有效的优化框架,可以在训练过程中动态优化损失函数分布的参数。四个基准数据集的广泛实验结果表明,在没有任何技巧的情况下,我们的方法在各种计算机视觉任务中优于现有的手工制作的损失函数。 |
| Online Hyper-parameter Learning for Auto-Augmentation Strategy Authors Chen Lin, Minghao Guo, Chuming Li, Wei Wu, Dahua Lin, Wanli Ouyang, Junjie Yan 数据增强对现代深度学习技术的成功至关重要。在本文中,我们提出了用于自动增强的在线超参数学习OHL Auto Aug,这是一种经济的解决方案,可以学习增强策略分布以及网络训练。与以前以离线方式搜索增强策略的自动增强方法不同,我们的方法将增强策略表示为参数化概率分布,从而允许其参数与网络参数一起优化。我们提出的OHL Auto Aug消除了重新训练的需要,并大大降低了整体搜索过程的成本,同时建立了比基线模型显着的准确性改进。在CIFAR 10和ImageNet上,我们的方法在搜索精度方面取得了显着的成绩,在CIFAR 10上速度提高了60倍,在ImageNet上提高了24倍,同时保持了竞争力的准确性。 |
| Semantic Analysis of Traffic Camera Data: Topic Signal Extraction and Anomalous Event Detection Authors Jeffrey Liu, Andrew Weinert, Saurabh Amin 交通管理中心TMC经常使用交通摄像头提供有关交通,道路和天气状况的态势感知。相机镜头对于各种诊断目的非常有用,但大多数镜头只保留了几天,如果有的话。这主要是因为目前通过人工操作员的人工审查来识别显着的镜头是一个费力且低效的过程。在本文中,我们提出了一种面向语义的方法来分析顺序图像数据,并展示其在自然检测现实世界,天气和交通状况异常事件中的应用。我们的方法从文本标签构建图像内容的语义矢量表示,这可以从现成的,预训练的图像标记软件中容易地获得。这些语义标签向量用于使用Latent Dirichlet Allocation LDA主题模型构建语义主题信号物理过程的时间序列表示。通过检测主题信号中的异常,我们识别出与冬季风暴和异常交通拥堵相对应的显着镜头。在针对现实世界事件的验证中,使用语义主题信号的异常检测明显优于使用任何单独标签信号的检测。 |
| LiDAR Sensor modeling and Data augmentation with GANs for Autonomous driving Authors Ahmad El Sallab, Ibrahim Sobh, Mohamed Zahran, Nader Essam 在自动驾驶领域,来自真实车辆的数据收集和注释是昂贵的并且有时是不安全的。模拟器通常用于数据增强,这需要现实的传感器模型,这些传感器模型难以配制并以封闭形式建模。相反,可以从真实数据中学习传感器模型。主要挑战是缺少配对数据集,这使得传统的监督学习技术不适合。在这项工作中,我们将问题表述为来自不成对数据的图像转换,并采用CycleGAN来解决LiDAR的传感器建模问题,从模拟的LiDAR sim2real中生成逼真的LiDAR。此外,我们从较低分辨率的real2real生成高分辨率,逼真的LiDAR。 LiDAR 3D点云在Bird eye View和Polar 2D表示中处理。实验结果表明该方法具有很高的潜力。 |
| CNN-based Cost Volume Analysis as Confidence Measure for Dense Matching Authors Max Mehltretter, Christian Heipke 由于其能够识别密集立体匹配中的错误视差分配,因此置信度估计对于广泛的应用是有益的,例如,自动驾驶,需要一定程度的信心作为强制性先决条件。特别是,基于深度学习的方法的引入导致近年来该领域的日益普及,这是由于显着提高的准确性引起的。尽管有这种显着的发展,但这些方法中的大多数仅依赖于从视差图中学习的特征,而没有考虑相应的三维成本量。然而,已经证明,使用基于手工制作特征的传统方法,可以使用该附加信息来进一步提高准确度。为了结合深度学习和基于成本量的特征的优势,本文提出了一种新颖的卷积神经网络CNN架构,可直接学习体积三维数据的置信度估计特征。使用三种常见的密集立体匹配技术对三个数据集进行广泛评估,证明了所提出方法的一般性和现有技术的准确性。 |
| A deep learning approach to detecting volcano deformation from satellite imagery using synthetic datasets Authors Nantheera Anantrasirichai, Juliet Biggs, Fabien Albino, David Bull 卫星可以对火山进行广泛的,区域的或全球的监视,并可以提供火山爆发或火山爆发的第一个迹象。在这里,我们考虑干涉合成孔径雷达InSAR,它可用于检测表面变形与强烈的喷发统计链接。已经证明了机器学习在这些大型InSAR数据集中自动识别感兴趣信号的能力,但是数据驱动技术,例如卷积中性网络CNN需要平衡的正负信号训练数据集,以有效地区分真实变形和噪声。由于只有一小部分火山正在变形,大气噪声无处不在,因此利用机器学习来探测火山爆发更具挑战性。在本文中,我们使用合成干涉图来训练AlexNet来解决这个问题。合成干涉图由3部分1变形模式组成,基于蒙特卡罗选择的分析正演模型参数,2个分层大气效应源自天气模型和3个湍流大气效应基于相关噪声的统计模拟。基于分类准确度和阳性预测值PPV,使用合成数据训练的AlexNet体系结构优于仅使用真实干涉图训练的结构。然而,用于生成合成信号的模型是自然过程的简化,因此我们使用由合成模型和选定的实例组成的组合数据集重新训练CNN,实现最终PPV为82。尽管对整个数据集应用大气校正在计算上是昂贵的,但将它们应用于小的阳性结果子集相对简单。这进一步改善了检测性能,而没有显着增加计算负担。 |
| Texture Fields: Learning Texture Representations in Function Space Authors Michael Oechsle, Lars Mescheder, Michael Niemeyer, Thilo Strauss, Andreas Geiger 近年来,在基于学习的3D对象重建方面取得了实质性进展。同时,提出了可以生成高度逼真图像的生成模型。然而,尽管在这些密切相关的任务中取得了成功,但3D对象的纹理重建几乎没有受到研究界的关注,并且现有技术方法要么限于相对较低的分辨率,要么受限于实验设置。这些局限性的一个主要原因是纹理的常见表示对于现代深度学习技术而言效率低或难以界面。在本文中,我们提出了纹理场,这是一种新颖的纹理表示,它基于回归一个用神经网络参数化的连续三维函数。我们的方法绕过了形状离散化和参数化等限制因素,因为所提出的纹理表示独立于3D对象的形状表示。我们展示了Texture Fields能够代表高频纹理,并自然地融入现代深度学习技术。在实验上,我们发现纹理场比较有利于用于3D对象的条件纹理重建的现有技术方法,并且能够学习用于纹理化看不见的3D模型的概率生成模型。我们相信Texture Fields将成为下一代生成3D模型的重要组成部分。 |
| Neither Global Nor Local: A Hierarchical Robust Subspace Clustering For Image Data Authors Maryam Abdolali, Mohammad Rahmati 在本文中,我们考虑存在连续噪声,遮挡和伪装的子空间聚类问题。我们认为,在现有技术方法中数据的自我表达表示对遮挡和复杂的现实世界噪声非常敏感。为了缓解这个问题,我们提出了一个分层框架,它将基于局部补丁的表示和全局表示的判别属性的稳健性结合在一起。该方法包括1个自上而下的阶段,其中输入数据经历重复划分为较小的补丁,2个为自下而上的阶段,其中本地补丁的低等级嵌入在上层中的相应补丁的视野中在Grassmann流形上合并。这个汇总信息提供了上层相应补丁的两个关键信息,不能链接和推荐链接。该信息用于使用加权稀疏组套索优化问题来计算上层的每个补丁的自表达表示。几个真实数据集的数值结果证实了我们的方法的效率。 |
| Transfer Learning based Detection of Diabetic Retinopathy from Small Dataset Authors Misgina Tsighe Hagos, Shri Kant 注释训练数据不足仍然是在医学数据分类问题中应用深度学习的挑战之一。从已经训练过的深度卷积网络中进行转移学习可用于从头开始降低培训成本,并通过小型培训数据进行深度学习培训。这提出了一个问题,即我们是否可以使用转移学习来克服基于深度学习的医学数据分类中的训练数据不足问题。深度卷积网络已经在ImageNet大规模视觉识别竞赛ILSVRC图像分类挑战中取得了高性能结果。一个例子是Inception V3模型,它是ILSVRC 2015挑战赛的第一个参赛者。有助于在一个卷积级别中提取输入图像的不同大小特征的初始模块是Inception V3的独特功能。在这项工作中,我们使用了预训练的Inception V3模型来利用其用于糖尿病视网膜病变检测的Inception模块。为了解决标记的数据不足问题,我们对用于模型训练的较小版本的Kaggle Diabetic Retinopathy分类挑战数据集进行了子样本测试,并在先前未见过的数据子集上测试了模型的准确性。我们的技术可用于其他基于深度学习的医学图像分类问题,面临标记训练数据不足的挑战。 |
| Side Window Filtering Authors Hui Yin, Yuanhao Gong, Guoping Qiu 局部窗口通常用于计算机视觉,几乎无一例外,窗口的中心与正在处理的像素对齐。我们表明,这种传统智慧并非普遍适用。当像素位于边缘上时,将窗口的中心放置在像素上是导致许多滤波算法模糊边缘的基本原因之一。基于这种见解,我们提出了一种新的侧窗滤波SWF技术,该技术将窗口侧或角与正在处理的像素对齐。 SWF技术令人惊讶地简单但理论上根深蒂固且在实践中非常有效。我们展示了许多传统的线性和非线性滤波器可以在SWF框架下轻松实现。广泛的分析和实验表明,实现SWF原理可以显着提高其边缘保持能力,并在诸如图像平滑,去噪,增强,结构保持纹理去除,相互结构提取和HDR色调映射等应用中实现最先进的性能。除了图像过滤,我们进一步表明SWF原理可以扩展到涉及使用本地窗口的其他应用程序。通过优化着色作为示例,我们证明了实现SWF原理可以有效地防止诸如与传统实现相关的颜色泄漏之类的伪像。鉴于计算机视觉中基于窗口的操作无处不在,新的SWF技术可能会使更多应用受益。 |
| Group Re-Identification with Multi-grained Matching and Integration Authors Weiyao Lin, Yuxi Li, Hao Xiao, John See, Junni Zou, Hongkai Xiong, Jingdong Wang, Tao Mei 重新识别不同摄像机视图的人群的任务是一个重要但研究较少的问题。组识别Re ID是一项非常具有挑战性的任务,因为它不仅受到传统单个对象的ID问题的不利影响,例如视点和人体姿势变化,但它也受到组布局和组成员身份变化的影响。在本文中,我们提出了一种新的群体粒度概念,通过多粒度对象的个体人物和一组内的两个和三个人的子群来表征群体图像。为了实现健壮的组Re ID,我们首先引入多粒度表示,这些表示可以通过开发两个单独的方案来提取,即一个用手工制作的描述符,另一个用深度神经网络。所提出的表示旨在表征多粒度对象的空间和空间关系,并进一步配备重要性权重,其捕获组内动态的变化。通过多阶匹配过程促进最优群组匹配,进而以迭代方式动态更新重要性权重。我们对包含复杂场景和大动态的三个多摄像机组数据集进行了评估,实验结果证明了我们的方法的有效性。 |
| Non-Parametric Priors For Generative Adversarial Networks Authors Rajhans Singh 1 , Pavan Turaga 1 , Suren Jayasuriya 1 , Ravi Garg 2 , Martin W. Braun 2 1 Arizona State University, 2 Intel Corporation 生成对抗网络GAN的出现使得迄今为止认为非常具有挑战性的综合,插值和数据增强方面的新功能成为可能。然而,大多数GAN架构中的一个常见假设是假设简单的参数潜在空间分布。虽然易于实现,但简单的潜在空间分布对于诸如插值的用途可能是有问题的。这是由于在潜在空间中插入样本时的分布不匹配。我们使用概率论和现成的优化工具的基本结果提出了这个问题的直接形式化,我们开发了达到适当的非参数先验的方法。所获得的先验在其形状方面表现出不寻常的定性特性,并且在其中点分布的较低发散方面具有定量益处。我们证明了我们设计的先验有助于在插值期间沿着任何欧几里德直线改善图像生成,无论是定性还是定量,无需任何额外的培训或架构修改。拟议的表述非常灵活,为潜在的空间统计施加更新的限制铺平了道路。 |
| How do neural networks see depth in single images? Authors Tom van Dijk, Guido C.H.E. de Croon 深度神经网络已经导致单个图像的深度估计的突破。最近的工作通常侧重于深度图的准确性,其中对公开可用的测试集(例如KITTI视觉基准)的评估通常是本文的主要结果。虽然这样的评估显示神经网络可以很好地估计深度,但它并没有显示它们是如何做到这一点的。据我们所知,目前还没有任何工作可以分析这些网络学到了什么。 |
| PoreNet: CNN-based Pore Descriptor for High-resolution Fingerprint Recognition Authors Vijay Anand, Vivek Kanhangad 随着高分辨率指纹扫描仪的发展,基于高分辨率指纹的生物识别技术近年来受到越来越多的关注。这封信提出了一种基于毛孔特征的生物识别方法。我们的方法采用卷积神经网络CNN模型DeepResPore来检测输入指纹图像中的毛孔。此后,针对每个检测到的孔周围的补片计算基于CNN的描述符。具体来说,我们设计了一个基于剩余学习的CNN,称为PoreNet,它从孔隙补丁中学习独特的特征表示。为了验证,通过使用欧几里德距离以双向方式比较从一对指纹图像获得的孔描述符来生成匹配分数。所提出的高分辨率指纹识别方法在部分DBI和基准PolyU HRF数据集的完整DBII指纹上实现了2.56和0.57相等的错误率EER。最重要的是,它在两个数据集上实现了比当前最先进方法更低的FMR1000和FMR10000值。 |
| POPQORN: Quantifying Robustness of Recurrent Neural Networks Authors Ching Yun Ko, Zhaoyang Lyu, Tsui Wei Weng, Luca Daniel, Ngai Wong, Dahua Lin 对抗性攻击的脆弱性一直是深度神经网络的关键问题。解决此问题需要一种可靠的方法来评估网络的健壮性。最近,已经开发了几种方法来计算神经网络的纹理稳健性量化,即最小对抗扰动的经认证的下界。然而,这些方法被设计用于前馈网络,例如,多层感知器或卷积网络。量化循环网络的稳健性仍然是一个悬而未决的问题,特别是LSTM和GRU。对于这样的网络,在计算鲁棒性量化方面存在额外的挑战,例如在多个步骤处理输入以及门和状态之间的交互。在这项工作中,我们提出textit文本POPQORN textbf P ropagated textbf o ut textbf p ut textbf Q uantified R textbf o bustness for textbf RN Ns,这是一种量化RNN稳健性的通用算法,包括vanilla RNN,LSTM和GRU。我们在不同的网络架构上展示了它的有效性,并表明各个步骤的稳健性量化可以带来新的见解。 |
| Integer Discrete Flows and Lossless Compression Authors Emiel Hoogeboom, Jorn W.T. Peters, Rianne van den Berg, Max Welling 无损压缩方法使用统计模型缩短了数据的预期表示大小而不丢失信息。基于流的模型在此设置中很有吸引力,因为它们允许精确的似然优化,这相当于最小化每条消息的预期比特数。然而,传统流程假设连续数据,这可能在量化压缩时导致重建错误。出于这个原因,我们引入了一个称为整数离散流IDF的序数离散数据的生成流,这是一种双向整数映射,可以学习高维数据的丰富变换。作为IDF的构建模块,我们引入了称为整数离散耦合和下三角耦合的灵活变换层。我们的实验表明,IDF与其他基于流动的生成模型竞争。此外,我们证明基于IDF的压缩在CIFAR10,ImageNet32和ImageNet64上实现了最先进的无损压缩率。 |
| EENA: Efficient Evolution of Neural Architecture Authors Hui Zhu, Zhulin An, Chuanguang Yang, Kaiqiang Xu, Yongjun Xu 用于自动神经结构搜索的最新算法在搜索空间中表现显着但基本上没有方向性,并且在每个中间架构的训练中计算成本高。在本文中,我们提出了一种有效的架构搜索方法,称为EENA神经架构的高效演化,已经学习了由信息引导的突变和交叉操作,以加速这一过程,并通过减少冗余搜索和训练来减少计算工作量。在CIFAR 10分类中,使用最小计算资源0.65 GPU天的EENA可以设计高效的神经结构,其在8.47M参数下实现2.56测试误差。此外,发现的最佳架构也可转换为CIFAR 100。 |
| Finding Rats in Cats: Detecting Stealthy Attacks using Group Anomaly Detection Authors Aditya Kuppa, Slawomir Grzonkowski, Muhammad Rizwan Asghar, Nhien An Le Khac 高级攻击活动跨越多个阶段并长时间保持隐身状态。越来越多的攻击者使用现成的工具和预安装的系统应用程序(如emph powershell和emph wmic)来逃避检测,因为系统管理员和安全分析师也使用相同的工具来执行日常任务的合法目的。要开始调查,可以从操作系统收集事件日志,但是,这些日志非常通用,并且通常无法将潜在攻击归因于特定攻击组。文献中最近的方法使用异常检测技术,其旨在区分计算机或网络系统的恶意和正常行为。遗憾的是,基于点异常的异常检测系统在某种意义上过于严格,以至于它们可能会错过恶意活动并对攻击进行分类,而不是异常值。因此,对于更好地检测恶意活动存在研究挑战。为了应对这一挑战,在本文中,我们利用Group Anomaly Detection GAD,它可以检测各个数据点的异常集合。 |
| Training Object Detectors With Noisy Data Authors Simon Chadwick, Paul Newman 大量标记的训练数据的可用性对于现代物体探测器的训练是至关重要的。手动标记训练数据是耗时且昂贵的,而自动标记方法不可避免地会给标签添加不需要的噪音。我们研究了不同类型的标签噪声对物体探测器性能的影响。然后,我们展示了如何改进协同教学,一种用于处理噪声标签和之前在分类问题上演示的方法,以减轻物体检测设置中标签噪声的影响。我们使用KITTI数据集上的模拟噪声和使用自动标记数据的车辆检测任务来说明我们的结果。 |
| Mechanically Powered Motion Imaging Phantoms: Proof of Concept Authors Alberto Gomez, Cornelia Schmitz, Markus Henningsson, James Housden, Yohan Noh, Veronika A. Zimmer, James R. Clough, Ilkay Oksuz, Nicolas Toussaint, Andrew P. King, Julia A. Schnabel 运动成像模型昂贵,笨重且难以运输和设置。本文的目的是演示一种设计多模态运动成像模型的简单方法,该模型使用机械存储的能量来产生运动。我们提出两种幻影设计,使用主发条和弹性带来储存能量。在每个模型的传动链的端部处将矩形件连接到轴上,并且在释放机械马达时进行旋转运动。用MRI和US对模体进行成像,并将图像序列嵌入一维非线性流形拉普拉斯特征图中,并使用嵌入的光谱图来推导随时间的角速度。导出的速度在一个小误差内是一致的和可重复的。提出的运动模型概念显示了构建简单且价格合理的运动模型的巨大潜力 |
| Deep Unified Multimodal Embeddings for Understanding both Content and Users in Social Media Networks Authors Karan Sikka, Lucas Van Bramer, Ajay Divakaran 在过去几年中,社交媒体网络上产生的多模式内容爆炸式增长,这使得必须更深入地了解社交媒体内容和用户行为。我们为社交多媒体内容分析提出了一种新颖的内容独立内容用户反应模型与通常单独处理语义内容理解和用户行为建模的先前工作相比,我们在统一框架内提出了对这些问题的通用解决方案。我们将用户,图像和文本从开放的社交媒体中嵌入到一个共同的多模式几何空间中,使用一种新的损失函数来设计应对远程和不同的模态,从而实现无缝的三向检索。我们的模型不仅优于基于单峰嵌入的交叉模态检索任务方法,而且还显示了联合解决Twitter数据上的两个任务所带来的改进。我们还表明,与在Instagram数据上使用单峰内容学习的用户相比,在我们的联合多模式嵌入模型中学习的用户嵌入更能预测用户兴趣。因此,我们的框架超越了使用显式领导者关注者链接信息通过从孤立用户中提取隐含内容中心关联来建立从属关系的先前实践。我们提供定性结果,以表明从学习嵌入中出现的用户群具有一致的语义和我们的模型从嘈杂和非结构化数据中发现细粒度语义的能力。我们的工作表明,社交多模态内容本质上是多模式的,并且具有一致的结构,因为在社交网络中,意义是通过用户和内容之间的交互来创建的。 |
| Dream Distillation: A Data-Independent Model Compression Framework Authors Kartikeya Bhardwaj, Naveen Suda, Radu Marculescu 模型压缩非常适合在物联网设备上部署深度学习。但是,现有的模型压缩技术依赖于对原始数据集或某些备用数据集的访问。在本文中,我们解决了当没有可用的实际数据时的模型压缩问题,例如,当数据是私有的时。为此,我们提出了Dream Distillation,一种独立于数据的模型压缩框架。我们的实验表明,Dream Distillation可以在CIFAR 10测试集上达到88.5的准确度,而无需对原始数据进行实际训练 |
| GlidarCo: gait recognition by 3D skeleton estimation and biometric feature correction of flash lidar data Authors Nasrin Sadeghzadehyazdi, Tamal Batabyal, Nibir K. Dhar, B. O. Familoni, K. M. Iftekharuddin, Scott T. Acton 使用非侵入性获取数据的步态识别在过去十年中引起了越来越多的关注。在各种数据源模式中,通过实验发现,涉及骨架表示的数据适用于可靠的特征压缩和快速处理。利用来自拟合模型(如骨架)的特征的基于模型的步态识别方法因其视图和尺度不变属性而被识别。我们提出了一种基于模型的步态识别方法,使用由单个闪光激光雷达记录的序列。利用Kinect和Mocap收集的高质量骨架数据的现有最先进模型方法仅限于受控实验室环境。传统研究工作的表现受到数据质量差的负面影响。我们解决了在具有挑战性的情况下的步态识别问题,例如激光雷达的低质量和嘈杂的成像过程,这降低了现有技术骨架系统的性能。我们提出GlidarCo以在所描述的条件下获得高度准确的步态识别。过滤机制校正有缺陷的骨架关节测量,并且将稳健的统计数据集成到传统特征矩以编码运动的动态。作为比较,研究从噪声骨架中提取的基于长度和基于矢量的特征以用于异常值去除。实验结果说明了在噪声低分辨率激光雷达数据的情况下,所提出的方法在改善步态识别方面的功效。 |
| Semi-supervised learning based on generative adversarial network: a comparison between good GAN and bad GAN approach Authors Wenyuan Li, Zichen Wang, Jiayun Li, Jennifer Polson, William Speier, Corey Arnold 最近,基于生成对抗网络GAN的半监督学习方法受到了很多关注。其中,两种不同的方法在各种基准数据集上取得了竞争性结果。 Bad GAN学习分类器,其中分布在输入数据支持的补充上的不切实际的样本。相反,Triple GAN包含一个三人游戏,试图利用良好生成的样本来提升分类结果。在本文中,我们在不同的基准数据集上对这两种方法进行了全面的比较。我们展示了它们在图像生成方面的不同属性,以及对提供的标记数据量的敏感性。通过综合比较这两种方法,我们希望能够揭示基于GAN的半监督学习的未来。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com
最后
以上就是糊涂鸡最近收集整理的关于【今日CV 计算机视觉论文速览 第117期】Mon, 20 May 2019的全部内容,更多相关【今日CV内容请搜索靠谱客的其他文章。








发表评论 取消回复