加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
写在文前:
【清明追思,家国永念】今天是国家公祭日,全国深切哀悼抗疫烈士和逝世同胞,愿花飨逝者、春暖斯人。
------
本文介绍了训练分类网络的各个阶段可以用来提升性能的Trick,也就是俗称的调参术。结果顶级调参术的调教,ResNet- 50的top-1验证精度在ImageNet上从75.3%提高到79.29%。这个结果比直接设计全新的网络效果都要好。
1.Baseline
现有的深度学习分类网络,其主要整体框架如下图所示:首先对数据进行预处理,并利用小批量随机梯度下降的训练模板,在每次迭代中,通过随机抽取batch大小的预处理后图像计算梯度并更新网络参数,并经过K个epoch之后停止迭代。

2.预处理阶段
训练阶段:
◎对于每幅图像,将其解码成32位浮点原始像素值[0,255]。
◎利用0.5的概率进行随机翻转。
◎在色调,饱和度和亮度三个方面进行均匀增强。
◎为输入图像加入正态分布的白噪声,用于提升分类网络的鲁棒性。
◎将RGB通道归一化,分别减去123.68、116.779、103.939,再除以58.393、57.12、57.375。
◎对图像进行随机裁剪,裁剪后的长宽比范围为[3/ 4,4 /3]和面积大小范围为[8%,100%]的矩形区域,然后将裁剪后的区域调整为224 * 224的正方形图像,分类网络多用正方形输入是为了使得网络能够对目标比例具有更强的泛化能力。
测试验证阶段:
将每个图像的短边调整为256像素,同时保持其高宽比。接下来,在中心裁剪出224×224的区域,并对类似于训练的RGB通道进行归一化处理。且不执行任何随机扩展。
权值初始化:
卷积层和全连接层:Xavier算法进行初始化,所有的偏置初始化为0。对于BN层,伽马参数都初始化为1,β参数初始化为0。
3.训练初始阶段
利用大batch进行模型的训练,会增加模型的并行性且降低通信成本,在训练过程中,炼丹师的直观感受更多的是大batch训练的网络会更加的稳定,主要原因是batch越大整个随机梯度的方差就越小,噪声越小,因为batch越大越能表征样本空间。因此若是你使用大batch就可以按比例的增加学习率。然而有很多论文证明直接增大batch会导致训练的收敛变慢,并且最终网络的性能也会下降,table4中的第一行实验结果也验证了这一点。为了提升大batch的训练性能,提出了以下三个训练trick。 LR warmup 若你的训练并没有预训练权重,而是使用随机初始化权重的方式,那么在训练的开始阶段,由于初始化权重的随机性若直接使用过大的学习率可能导致训练前期的震荡,因此我们可以使用warmup的方式,直白来说就是刚开始不要太剧烈,让学习率在初始的N个epoch中通过预热的方式缓慢上升到预先设定的初始值。 Zero γ BN层的可学习参数初始化。BN层的两个科学系参数γ和β。最终经过BN层的输出会在归一化之后通过γ*x+β的方式重新学习到原始分布。而在初始化这两个参数时,通常将γ初始化为1,β初始化为0。而如下图所示是Resnet中常见的一个跳跃连接的子模块,该子模块的输出分别为block(x)+x,分别来自于输入的跳跃和block的输出。而通常情况下每个block的最后一层都是BN层,用于归一化。在这个过程中,我们将该BN层的γ参数也初始化为0,此时整个跳跃链接在初始阶段就变成了恒等连接,这将使得网络的初始深度变浅,收敛更快更稳定。 No bias decay 不要对bias参数利用衰减系数。通常在训练网络时会对每个可学习参数设置一个权重衰减系数,用于抑制过拟合。然而我们只对卷积权重和全连接层的参数进行衰减,对bias和BN层中的可学习参数不进行衰减。 所有Trick的消融研究如下表所示。仅通过线性扩展学习率将批量大小从256个增加到1024个,导致前1名的准确率下降0.9%,而将上述3个Trick算法叠加在一起则弥补了这一差距。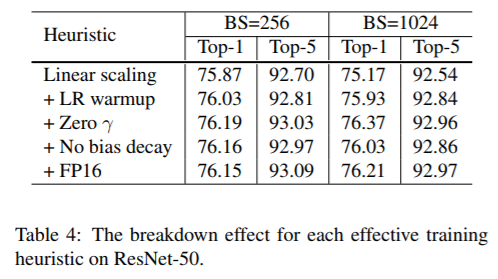
4.网络结构阶段
模型调整是对网络架构的一个小调整,比如改变特定卷积层的步长。这样的调整通常几乎不会改变计算复杂度,但可能会对模型精度产生不可忽视的影响。在本节中,我们将以ResNet为例研究模型调整的影响。 ResNet基础结构: ResNet网络由一个输入主干、四个stage阶段和一个最终输出层组成,如图所示。在输入主干中,通过一个stride为2的卷积和stride为2的pooling将输入图降采样四倍,并将通道增加到64个。从stage2开始每个stage都包含有stride为2的降采样模块,每个stage是由一个降采样模块和N个残差块构成。降采样模块如图所示,由两条并行的通道构成,实现了跳跃链接。残差块和降采样模型的结构一样,只是没有stride为2的卷积。不同的resnet网络结构上是相似的,就是每个stage中的残差块的个数不同。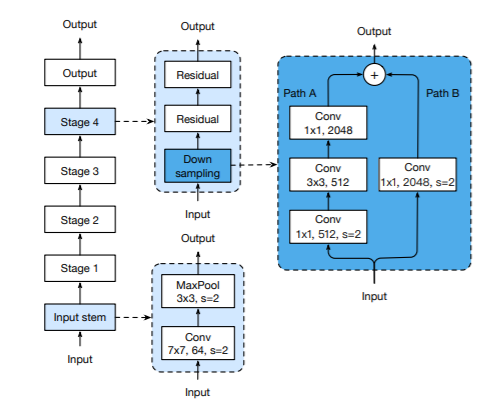 然而残差块和降采样块在构建的时候存在一些小问题,本文提出了三种改进策略,有效提升了resnet网络的性能。分别称为resnet-B,resnet-C,resnet-D。
ResNet-B
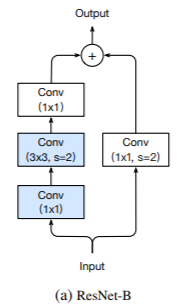
它改变了ResNet的降采样块。观察发现,在降采样模块中,pathA中的卷积忽略了输入特征图的四分之三,因为它使用的核尺寸为1*1,步长为2。ResNet-B在pathA中切换前两个卷积的步长大小,如下图所示,因此没有信息被忽略。由于第二次卷积的核大小为3*3,所以pathA的输出形状保持不变。
然而残差块和降采样块在构建的时候存在一些小问题,本文提出了三种改进策略,有效提升了resnet网络的性能。分别称为resnet-B,resnet-C,resnet-D。
ResNet-B
它改变了ResNet的降采样块。观察发现,在降采样模块中,pathA中的卷积忽略了输入特征图的四分之三,因为它使用的核尺寸为1*1,步长为2。ResNet-B在pathA中切换前两个卷积的步长大小,如下图所示,因此没有信息被忽略。由于第二次卷积的核大小为3*3,所以pathA的输出形状保持不变。
 ResNet-C
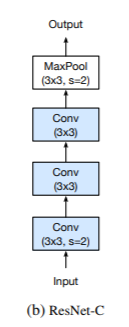
结果表明,卷积的计算成本是核的宽,高的乘积。一个7*7卷积比一个3*3卷积贵5.4倍。因此,这个微调将输入主干中的7*7卷积替换为3个3*3卷积,如下图所示,第一个和第二个卷积的输出通道为32,步长为2,而最后一个卷积的输出通道为64。
ResNet-C
结果表明,卷积的计算成本是核的宽,高的乘积。一个7*7卷积比一个3*3卷积贵5.4倍。因此,这个微调将输入主干中的7*7卷积替换为3个3*3卷积,如下图所示,第一个和第二个卷积的输出通道为32,步长为2,而最后一个卷积的输出通道为64。
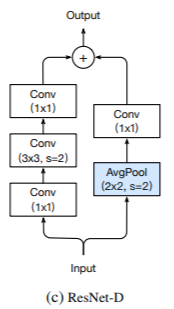
 ResNet-D
受ResNet-B的启发,我们注意到降采样块pathB中的1*1个卷积也忽略了输入特征图的3/4,我们想对它进行修改,这样就不会忽略任何信息。根据经验,我们发现在卷积之前添加一个步长为2的平均池化层,使其步长变为1,在实践中效果良好,对计算成本的影响很小。这个调整在如下图所示。
ResNet-D
受ResNet-B的启发,我们注意到降采样块pathB中的1*1个卷积也忽略了输入特征图的3/4,我们想对它进行修改,这样就不会忽略任何信息。根据经验,我们发现在卷积之前添加一个步长为2的平均池化层,使其步长变为1,在实践中效果良好,对计算成本的影响很小。这个调整在如下图所示。
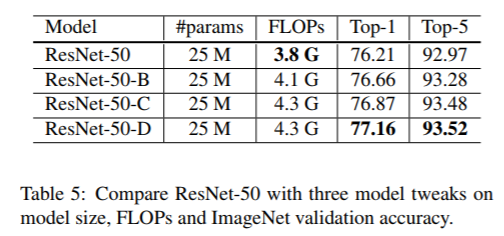
 下表展示了上述提到的ResNet-BCD结构堆叠在一起后的性能,我们发现一些小的结构调整,能够有1个点左右的提升。
下表展示了上述提到的ResNet-BCD结构堆叠在一起后的性能,我们发现一些小的结构调整,能够有1个点左右的提升。
5.训练阶段
余弦学习速率衰减(Cosine Learning Rate Decay) 如下图所示,展示了利用余弦学习速率和阶跃衰减速率在验证集上的性能比对。余弦衰减在开始时缓慢降低学习速度,然后在中间几乎呈线性下降,到最后再次下降。与阶跃衰减相比,余弦衰减从一开始就对学习进行衰减,但在阶跃衰减使学习速率降低10倍之前,余弦衰减仍然很大,这可能会提高训练的精度。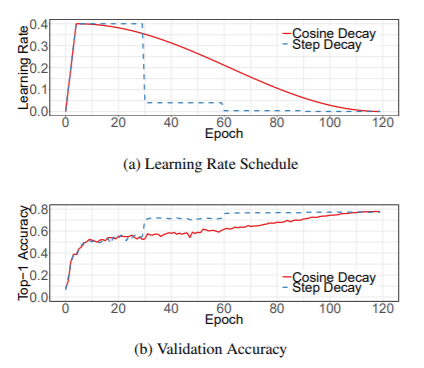 标签平滑(label smooth)
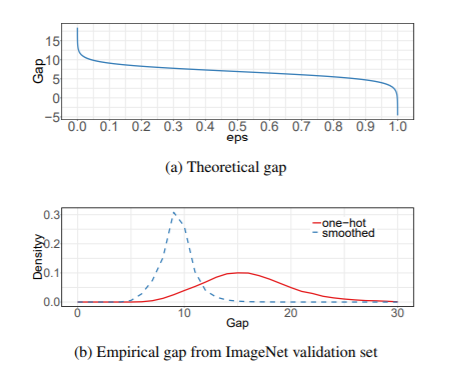
这是一种抑制网络过拟合现象的策略,如下图所示,它主要通过软化标签,加入噪声的方式,实现过拟合抑制。具体我之前写过一篇文章。
标签平滑(label smooth)
这是一种抑制网络过拟合现象的策略,如下图所示,它主要通过软化标签,加入噪声的方式,实现过拟合抑制。具体我之前写过一篇文章。
 混合训练(Mixup Training)
这其实是一种数据增强方法,称为mixup。在mixup中,每次我们随机抽取两个例子(xi, yi)和(xj, yj)。然后通过这两个实例样本的加权线性插值得到一个新的实例样本,实现数据增强。
混合训练(Mixup Training)
这其实是一种数据增强方法,称为mixup。在mixup中,每次我们随机抽取两个例子(xi, yi)和(xj, yj)。然后通过这两个实例样本的加权线性插值得到一个新的实例样本,实现数据增强。
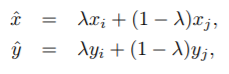 知识蒸馏(Knowledge Distillation)
在知识蒸馏中,我们使用教师模型来帮助训练当前的模型,即学生模型。教师模型通常是预训练的模型,具有较高的准确性,因此通过模仿,学生模型可以在保持模型复杂性不变的情况下提高自身的准确性。
-END
-
知识蒸馏(Knowledge Distillation)
在知识蒸馏中,我们使用教师模型来帮助训练当前的模型,即学生模型。教师模型通常是预训练的模型,具有较高的准确性,因此通过模仿,学生模型可以在保持模型复杂性不变的情况下提高自身的准确性。
-END
-
*延伸阅读
算法岗面试:Deep Learning 27类常见问题+解析汇总
神经网络结构优化:这篇论文让你无惧梯度消失或爆炸,轻松训练万层神经网络
亚马逊团队调参秘籍:用CNN进行图像分类的高实用Tricks合集

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ 
最后
以上就是高挑手链最近收集整理的关于tictoc正方形网络模型_分类网络Trick大汇总1.Baseline2.预处理阶段3.训练初始阶段4.网络结构阶段5.训练阶段的全部内容,更多相关tictoc正方形网络模型_分类网络Trick大汇总1内容请搜索靠谱客的其他文章。








发表评论 取消回复