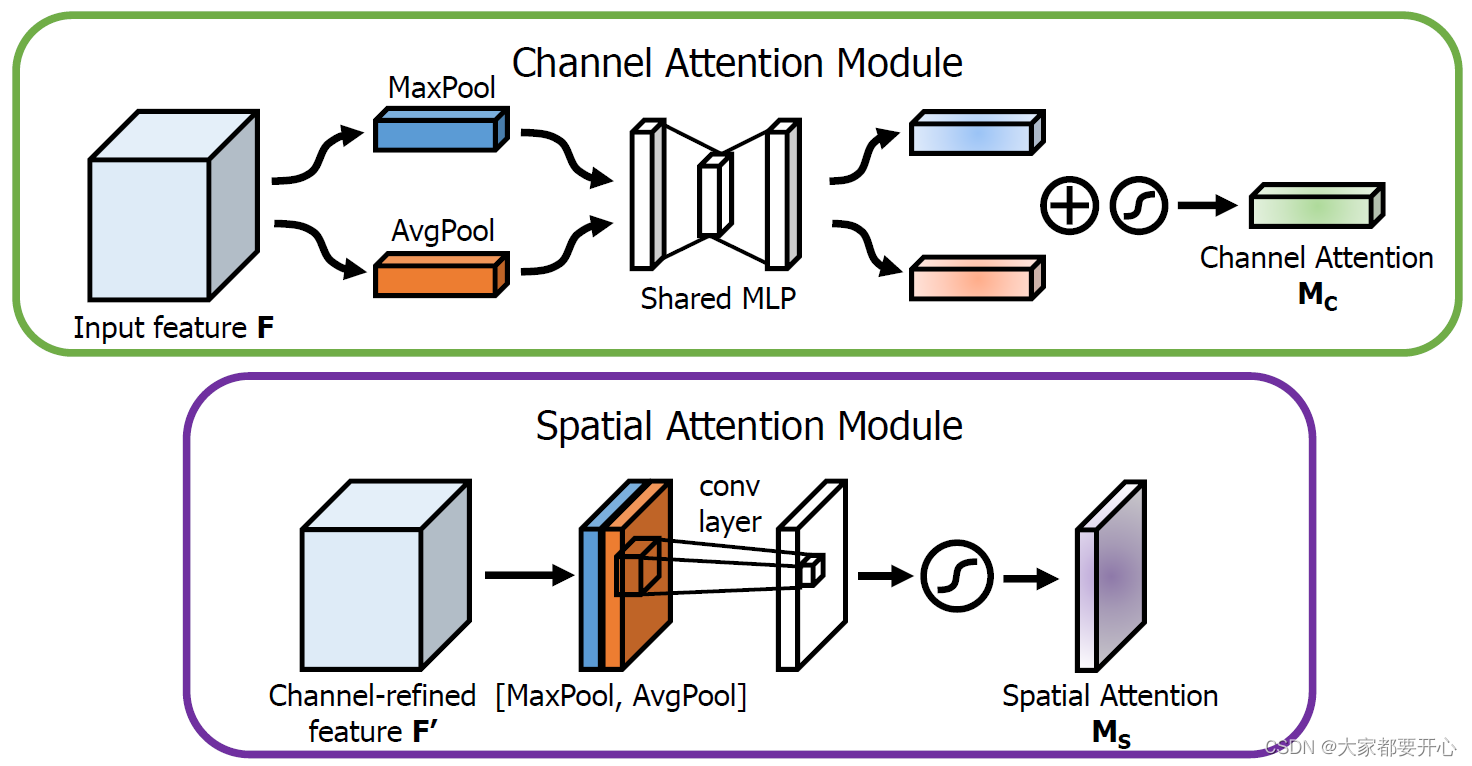
分别来用keras实现通道注意力模块和空间注意力模块。
#通道注意力机制
def channel_attention(input_feature, ratio=8):
channel_axis = 1 if K.image_data_format() == "channels_first" else -1
channel = input_feature._keras_shape[channel_axis]
shared_layer_one = Dense(channel//ratio,
activation='relu',
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
shared_layer_two = Dense(channel,
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
avg_pool = GlobalAveragePooling2D()(input_feature)
avg_pool = Reshape((1,1,channel))(avg_pool)
# Reshape: width,height,depth
#assert avg_pool._keras_shape[1:] == (1,1,channel)
avg_pool = shared_layer_one(avg_pool)
#assert avg_pool._keras_shape[1:] == (1,1,channel//ratio)
avg_pool = shared_layer_two(avg_pool)
#assert avg_pool._keras_shape[1:] == (1,1,channel)
max_pool = GlobalMaxPooling2D()(input_feature)
max_pool = Reshape((1,1,channel))(max_pool)
#assert max_pool._keras_shape[1:] == (1,1,channel)
max_pool = shared_layer_one(max_pool)
#assert max_pool._keras_shape[1:] == (1,1,channel//ratio)
max_pool = shared_layer_two(max_pool)
#assert max_pool._keras_shape[1:] == (1,1,channel)
cbam_feature = Add()([avg_pool,max_pool])
# 处理后的结果相加
cbam_feature = Activation('sigmoid')(cbam_feature)
# 获得各通道的权重图
if K.image_data_format() == "channels_first":
cbam_feature = Permute((3, 1, 2))(cbam_feature)
return multiply([input_feature, cbam_feature])通道注意力:将输入的featuremap,分别经过基于width和height的global max pooling 和global average pooling。
目的:保持通道数不变
"""
我们先分别进行一个通道维度的平均池化和最大池化得到两个 H×W×1 的通道描述,并将这两个描述按照通道拼接在一起;
然后,经过一个 7×7 的卷积层,激活函数为 Sigmoid,得到权重系数 Ms;
最后,拿权重系数和特征 F’ 相乘即可得到缩放后的新特征。
"""
def spatial_attention(input_feature):
kernel_size = 7
if K.image_data_format() == "channels_first":
channel = input_feature._keras_shape[1]
cbam_feature = Permute((2,3,1))(input_feature)
else:
channel = input_feature._keras_shape[-1]
cbam_feature = input_feature
avg_pool = Lambda(lambda x: K.mean(x, axis=3, keepdims=True))(cbam_feature)
# 对张量求平均值,改变第三维坐标,并保持原本维度
#assert avg_pool._keras_shape[-1] == 1
max_pool = Lambda(lambda x: K.max(x, axis=3, keepdims=True))(cbam_feature)
#assert max_pool._keras_shape[-1] == 1
concat = Concatenate(axis=3)([avg_pool, max_pool])
# 拼接
#assert concat._keras_shape[-1] == 2
cbam_feature = Conv2D(filters = 1,
kernel_size=kernel_size,
strides=1,
padding='same',
activation='sigmoid',
kernel_initializer='he_normal',
use_bias=False)(concat)
#assert cbam_feature._keras_shape[-1] == 1
if K.image_data_format() == "channels_first":
cbam_feature = Permute((3, 1, 2))(cbam_feature)
return multiply([input_feature, cbam_feature])空间注意力:将输入的featuremap,做一个基于channel的global max pooling 和global average pooling。
目的:保持特征图大小不变
CBAM
将Channel attention模块输出的特征图作为Spatial attention模块的输入特征图
def cbam_block(cbam_feature, ratio=8):
cbam_feature = channel_attention(cbam_feature, ratio)
cbam_feature = spatial_attention(cbam_feature)
return cbam_feature到底如何做到“随插随用”
核心思想:需要理解输入的是特征图,输出的也是注意力权重与原图相乘后的特征图。
#简单举例:输入特征图,经过卷积,BN层,最后输出的是三者的和,并输入到下一层
在相应的位置添加CBAM
inputs = x
residual = layers.Conv2D(filter, kernel_size = (1, 1), strides = strides, padding = 'same')(inputs)
residual = layers.BatchNormalization(axis = bn_axis)(residual)
cbam = cbam_block(residual)
x = layers.add([x, residual, cbam])
SE
from keras.layers import GlobalAveragePooling2D, Reshape, Dense, multiply
from keras import backend as K
def se_block(input_feature, ratio=8):
channel_axis = 1 if K.image_data_format() == "channels_first" else -1
channel = input_feature._keras_shape[channel_axis]
se_feature = GlobalAveragePooling2D()(input_feature)
se_feature = Reshape((1, 1, channel))(se_feature)
# 第一步:压缩(Squeeze), reshape成1✖️1✖️C
# assert se_feature._keras_shape[1:] == (1,1,channel)
# 第二步:激励(Excitation),
# 由两个全连接层组成,其中SERatio是一个缩放参数,这个参数的目的是为了减少通道个数从而降低计算量。
# 第一个全连接层有(C/radio)个神经元,输入为1×1×C,输出1×1×(C/radio)。
# 第二个全连接层有C个神经元,输入为1×1×(C/radio),输出为1×1×C。
se_feature = Dense(channel // ratio,
activation='relu',
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')(se_feature)
#assert se_feature._keras_shape[1:] == (1, 1, channel // ratio)
se_feature = Dense(channel,
activation='sigmoid',
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')(se_feature)
#assert se_feature._keras_shape[1:] == (1, 1, channel)
"""
# 因为keras默认为channels_last,没修改不需要加这段
if K.image_data_format() == 'channels_first':
se_feature = Permute((3, 1, 2))(se_feature)
"""
se_feature = multiply([input_feature, se_feature])
return se_feature
ECA
import math
from keras.layers import *
from keras.layers import Activation
from keras.layers import GlobalAveragePooling2D
import keras.backend as K
import tensorflow as tf
def eca_block(input_feature, b=1, gamma=2, name=""):
channel_axis = 1 if K.image_data_format() == "channels_first" else -1
channel = input_feature.shape[channel_axis]
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
avg_pool = GlobalAveragePooling2D()(input_feature)
x = Reshape((-1, 1))(avg_pool)
x = Conv1D(1, kernel_size=kernel_size, padding="same", name="eca_layer_" + str(name), use_bias=False, )(x)
x = Activation('sigmoid')(x)
x = Reshape((1, 1, -1))(x)
output = multiply([input_feature, x])
return output最后
以上就是霸气背包最近收集整理的关于keras实现注意力机制SEECA的全部内容,更多相关keras实现注意力机制SEECA内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复