文章来源
浙江大学 2021年硕士论文
小论文 IEEE Spectrum Attention Mechanism for Time Series Classification
1 摘要
本文贡献
- 时间序列数据同时具有全局和局部模式特征,已有模型大多采用堆叠式网络,随着层数加深,网络对局部摸式的敏感性降低。并且,已有模型并未考虑到时序数据在时间维度上属性重要程度不一致的特点。针对上述问题,本文提出了用于时间序列分类的编码解码模型。该模型首先通过卷积神经网络(Convolutional NeuralNetwork,CNN)编码器提取原始数据的全局语义信息,再使用长短时记忆网络(Long Short Term Memory,LSTM )解码器将其映射为鉴别性特征,并在解码过程中引入时域注意力机制(Attention Mechanism)来加强模型对局部模式的感知能力,最后用全连接层生成类别概率分布。在4个具有代表性的时间序列数据集上的实验结杲表明,该模型的分类性能超过了其他常用算法。本文还通过可视化解码输出序列以及注意力权重,进一步说明了该模型应用于时间序列分类任务的合理性。
- 此外,受采样环境和设备以及处理方法的影响,时间序列数据通常存在大量噪声,会对分类器的性能带来不利影响。前人的方案都是在预处理阶段采用人工方式对数据进行滤波,而滤波器的设计很大程度上依赖专家经验,使得算法不具有通用性。考虑到频域滤波是对每个频率分量分配合适的权重,这与注意力机制的思路十分相似。因此,本文提出了一种作用于频谱的注意力机制(Spectrum Attention Mechanism,SAM),通过对原始数据的频谱添加可训练的掩码分支,使网络可以在训练过程中自适应地学习每个频率分量的重要性,进而实现自适应滤波,生成更利于网络训练的特征表示。此外,为了避免直接使用整条序列的频谱导致完全丟失时域信息,本文进一步提出了分段频谱注意力机制(Segxnented - SAM ,SSAM)和相应的启发式搜索分段数算法。实验结果表明,该模块的引入可以提高模型的分类准确率,使网络收敛更快,对噪声更具有鲁棒性。
- 如何建立精准且通用的时间序列分类算法一直是该领域的热门研究课题。本文在上述两个模块的基础上,分别从单模型和多模型集成两个角度展开研究,并在42个UCR数据集上与其他算法进行对比实验。对于单模型算法,本文将分段频谱注意力机制SSAM和编码解码模型CLA相结合,形成了一个强基准的单模型SSAM-CLA。实验结果表明,该模型的分类性能显著超过其他所有单模型算法。对于多模型集成算法,本文从采样策略、基模型、结合策略三个角度展开设计,提出了CODLE(Conective Of Deep Learning Ensembles)算法。它以5个常用的深度学习摸型和分段数为1~5的SSAM-CLA模型作为基模型,并采用样本釆样策略来增加基模型之间的差异。本文还分别测试了3种结合策略,分别是投票法(CODLE-I)、加权投票法(CODLE-II)和学习法(CODLE-III)。实验结果表明,CODLE-III的分类性能与当前最先进的COITE和HIVE-COTE算法在统计学意义上无显著差异,但时间开销远远降低,因此更具有现实意义。
2 背景知识
2.1 编码解码模型
RNN和LSTM可以对序列数据建模,它们的输入端和输出端均为序列数据。但是对于机器翻译、语音识别、多标签文本分类等任务,输入数据和目标输出序列的长度不一致并且位置不对齐。为了解决这一问题,谷歌首先提出编码-解码模型,并且在机器翻译领域取得当时的最佳性能。
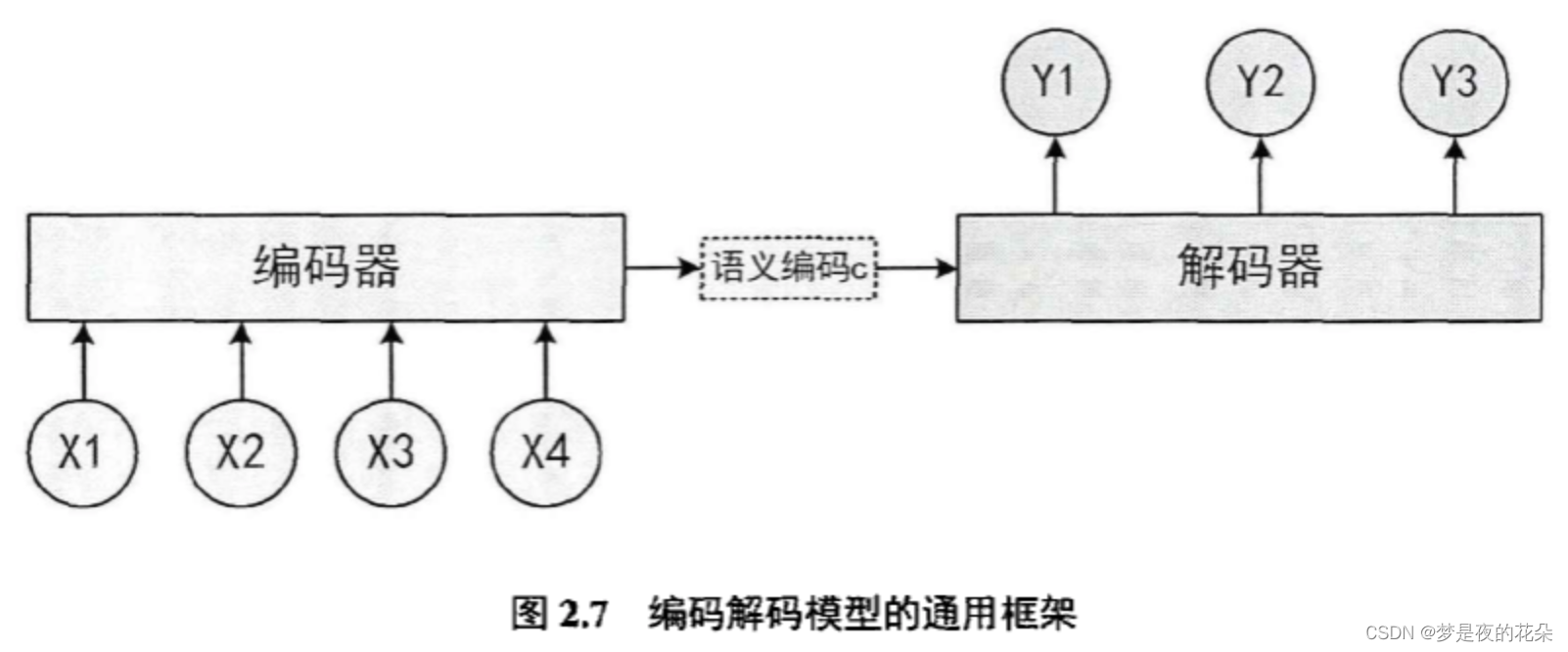
编码解码模型由两部分组成:编码器(encoder)和解码器(decoder)。如图2.7所示,编码器将输入序列转换为一个固定长度的编码向量,包含输入序列的全局语义信息;解码器的作用是将编码向量映射为输出序列。
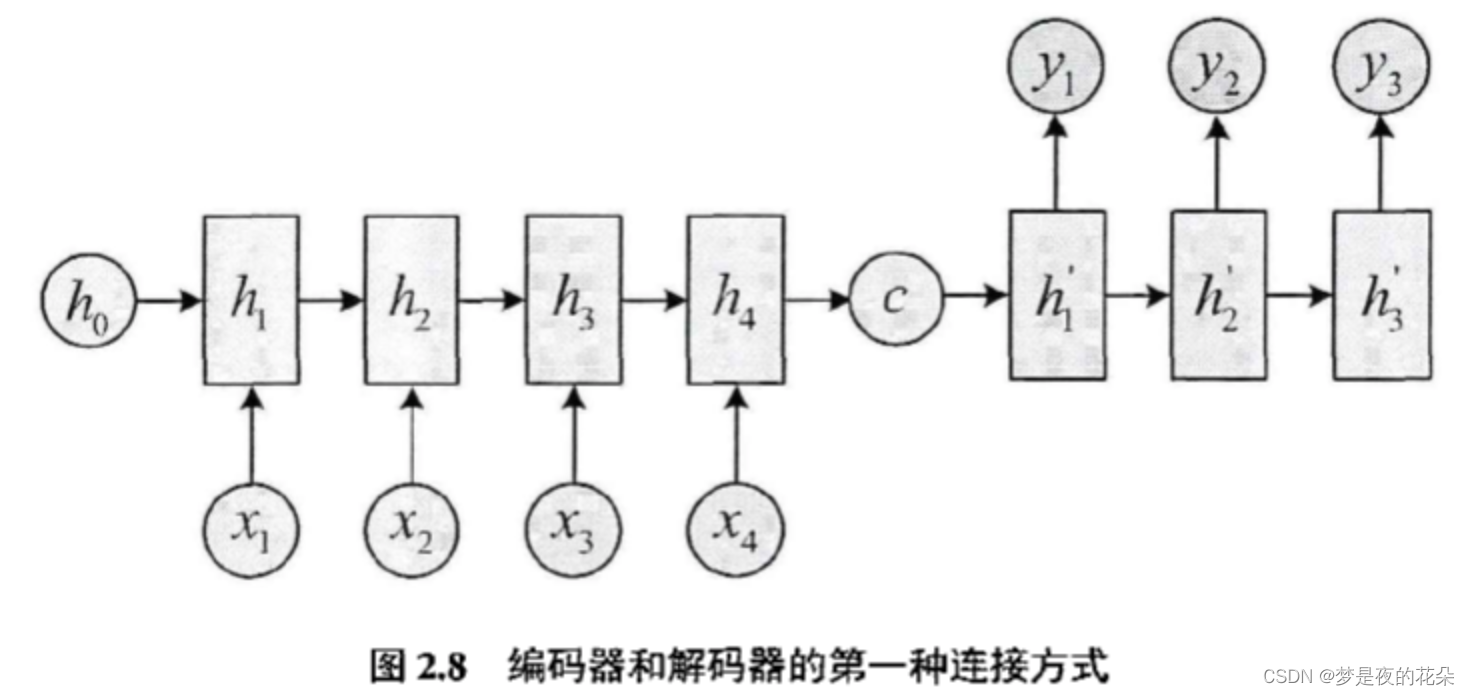
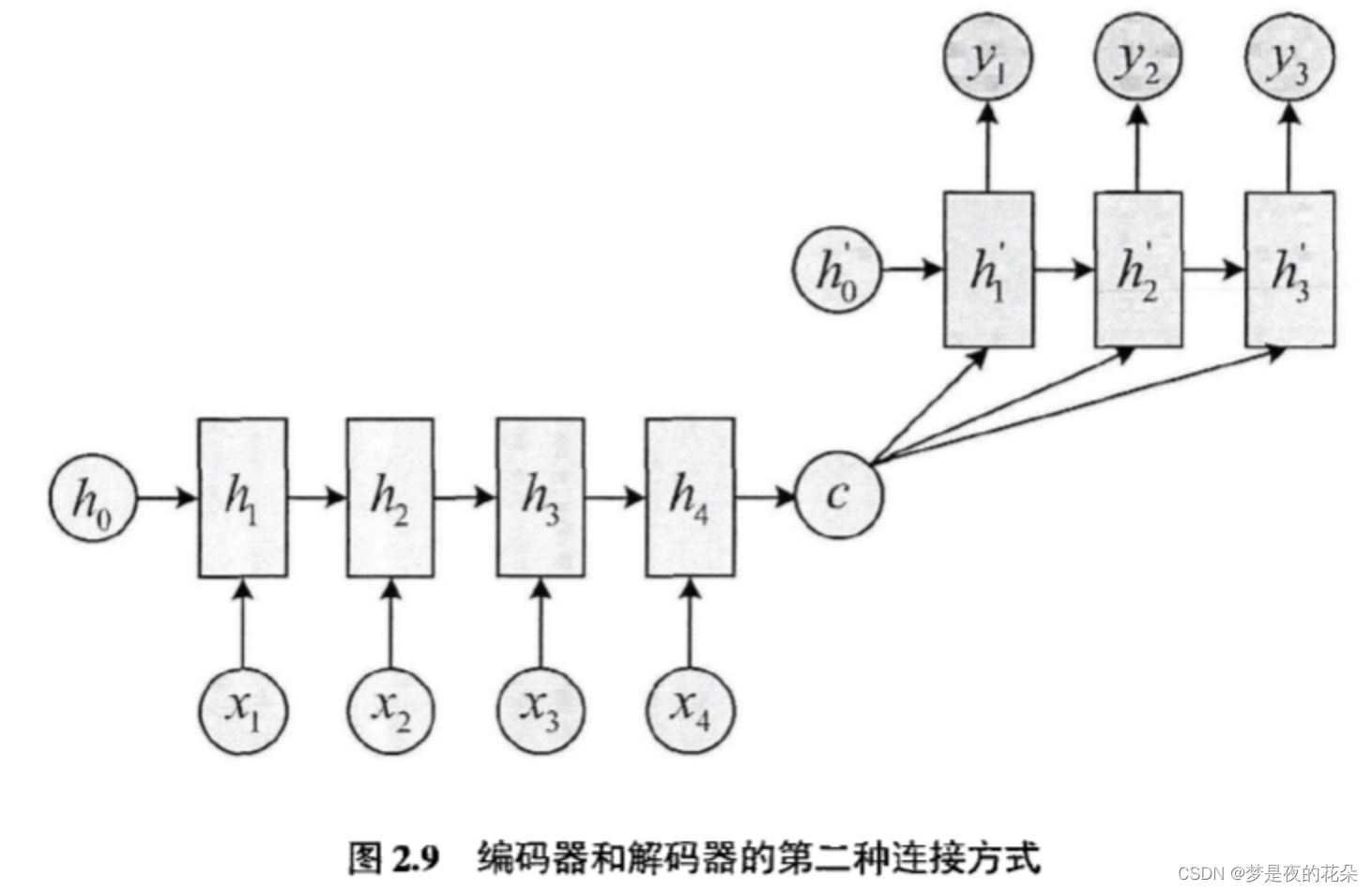
假设编码器隐藏状态为{h1,h2,h3,h4},得到编码向量c的方式有很多。最筒单的办法是将编码器的最后一个隐藏状态赋值给编码向量c,即c=h4;也可以对最后的隐藏状态做一个变换得到c,即c=q(h4);还可以对所有的隐藏状态做变换得到c,即c=q(h1,h2,h3,h4)。
2.2 注意力机制
编码-解码模型的局限性: 编码器和解码器之间唯一的联系仅有一个固定维度的编码向量c。这导致在解码器后期的隐藏状态中,早期状态的占比会变少,即逐渐“忘记”早期状态,输入序列越长,这种现象更明显。当解码器无法获得足够多的信息,解码效果自然会受到影响。
**时域注意力机制:**通过在解码阶段为每个时刻生成其对应的注意力向量ci提高了翻译的准确度。其主要思想是在解码阶段引入编码器中每个时间步的隐藏状态信息hj。具体地,假设输入序列长度为T,在解码的第i个时刻,ci的计算公式如下:


3 基于编码解码模型的时间序列分类
3.1 堆叠式卷积网络
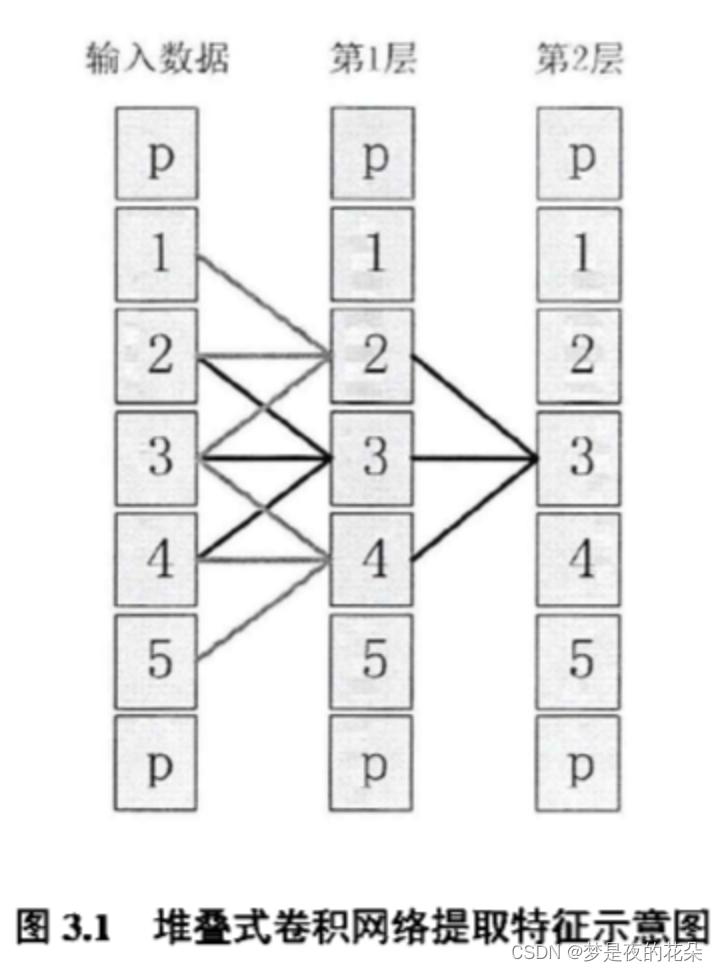
图3.1举例说明了一个长度为5的时间序列经过两层尺寸为3的一维卷积层后的感受野,其中p表示填充(padding)。从图中可以看出,第1层的特征对原始数据的感受野为3;第2层的特征对原始数据的感受野扩大为5。因此,通过不断堆叠卷积层,模型可以提取更抽象的全局模式特征。然而,对于时间序列数据,关键特征的尺寸大小和位置往往是不确定的。如杲模型采用堆叠式网络,模型的末段更多体现的全局信息,导致对这类局部模式特征不够敏感。
3.2 编码解码模型
解码器将编码向量映射为输出序列,并且通过引入时域注意力机制,来加强对局部模式特征的感知能力。时间序列分类任务的核心在于如何产生鉴别性特征。通过将体现全局模式特征的编码向量与体现局部模式特征的注意力向量相结合,模型的解码输出序列就包含了足够的信息,可以被视为鉴别性特征。将解码输出序列进一步输入到全连接层即可生成类别概率分布。
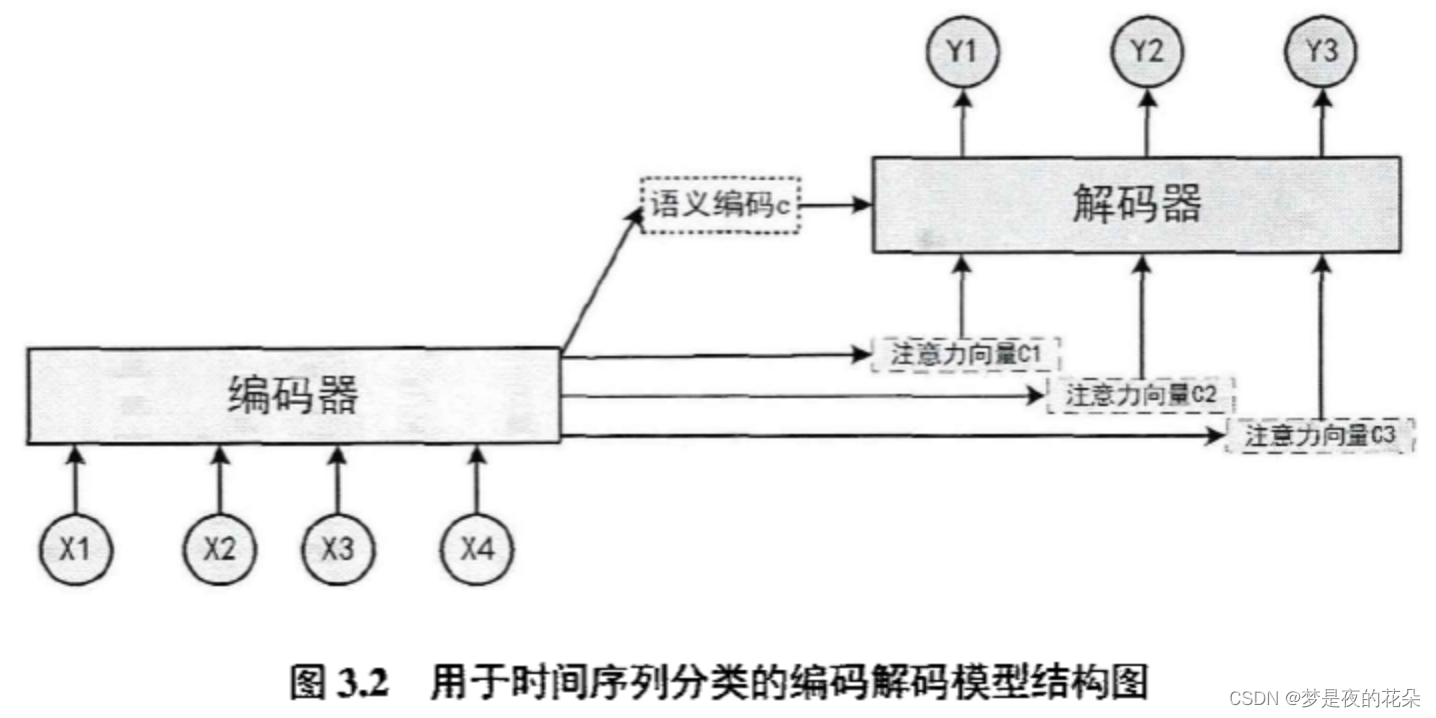
3.2.1 编码器
本章将采用卷积神经网络作为编码器:
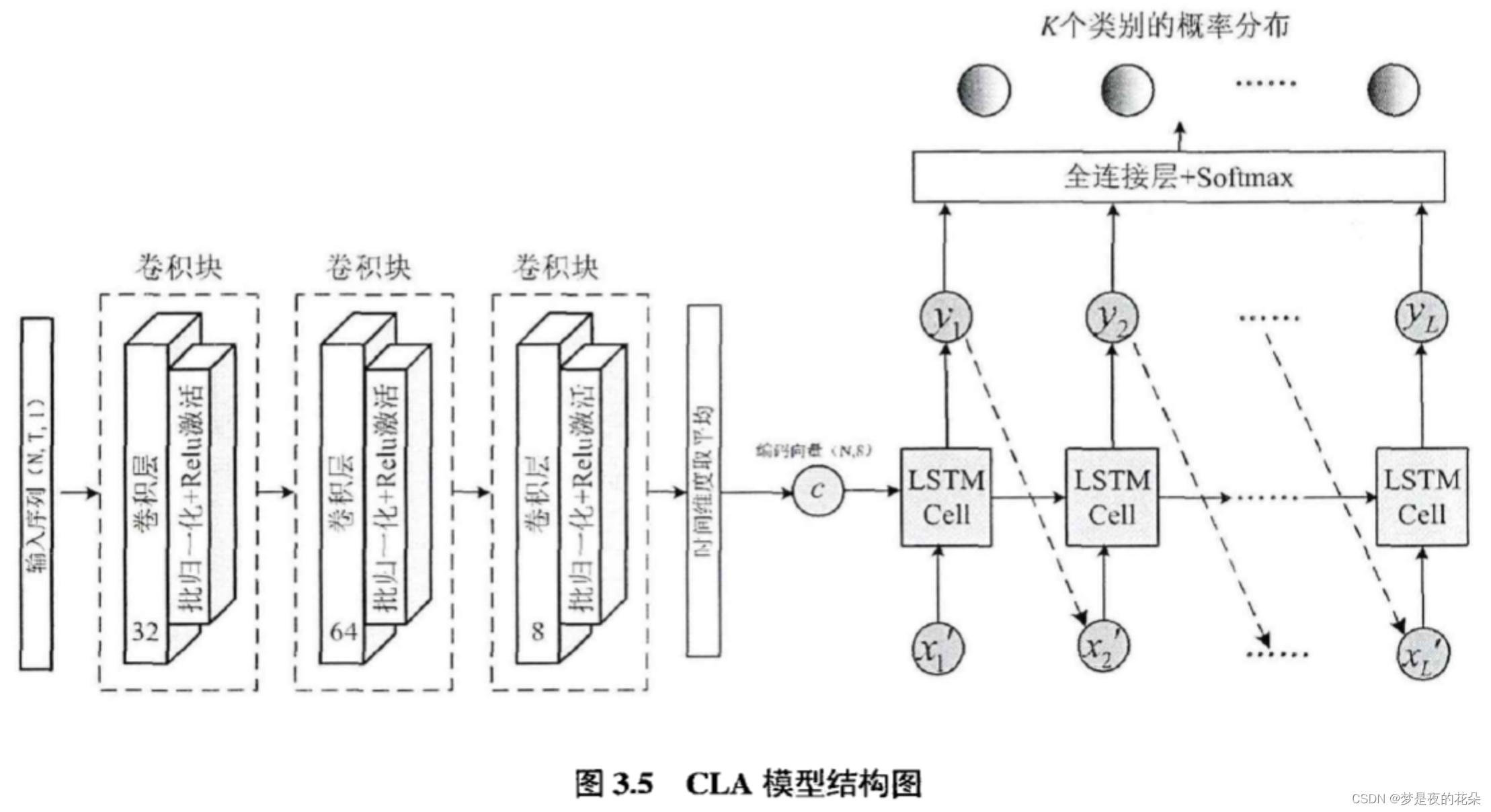
本章设计的卷积编码器由卷积块(Convolution Block)堆叠而成。卷积块由一维卷积层、批归一化层、激活层组成,式3.1~3.3展示了一个卷积块的计算流程。
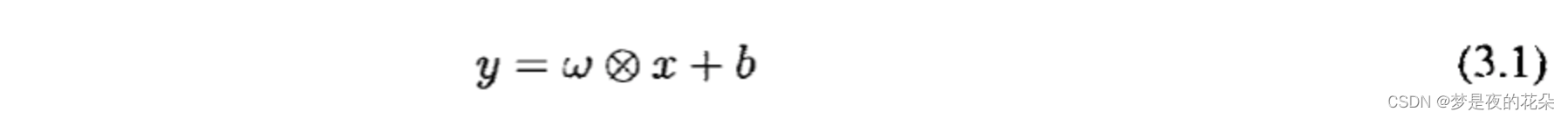
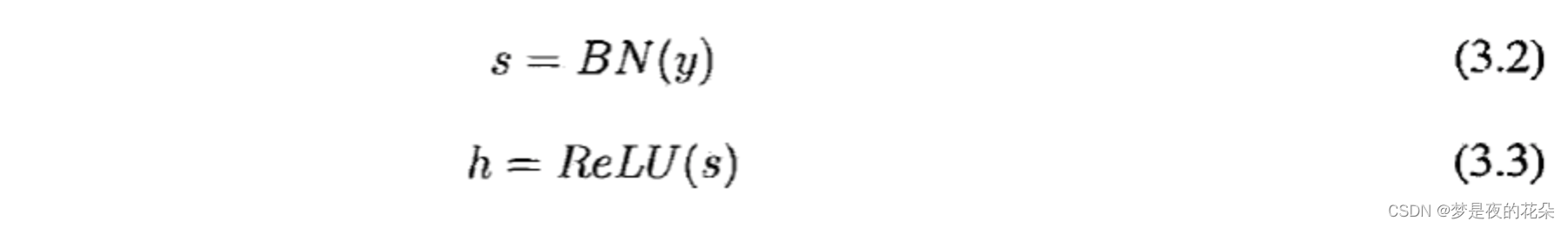
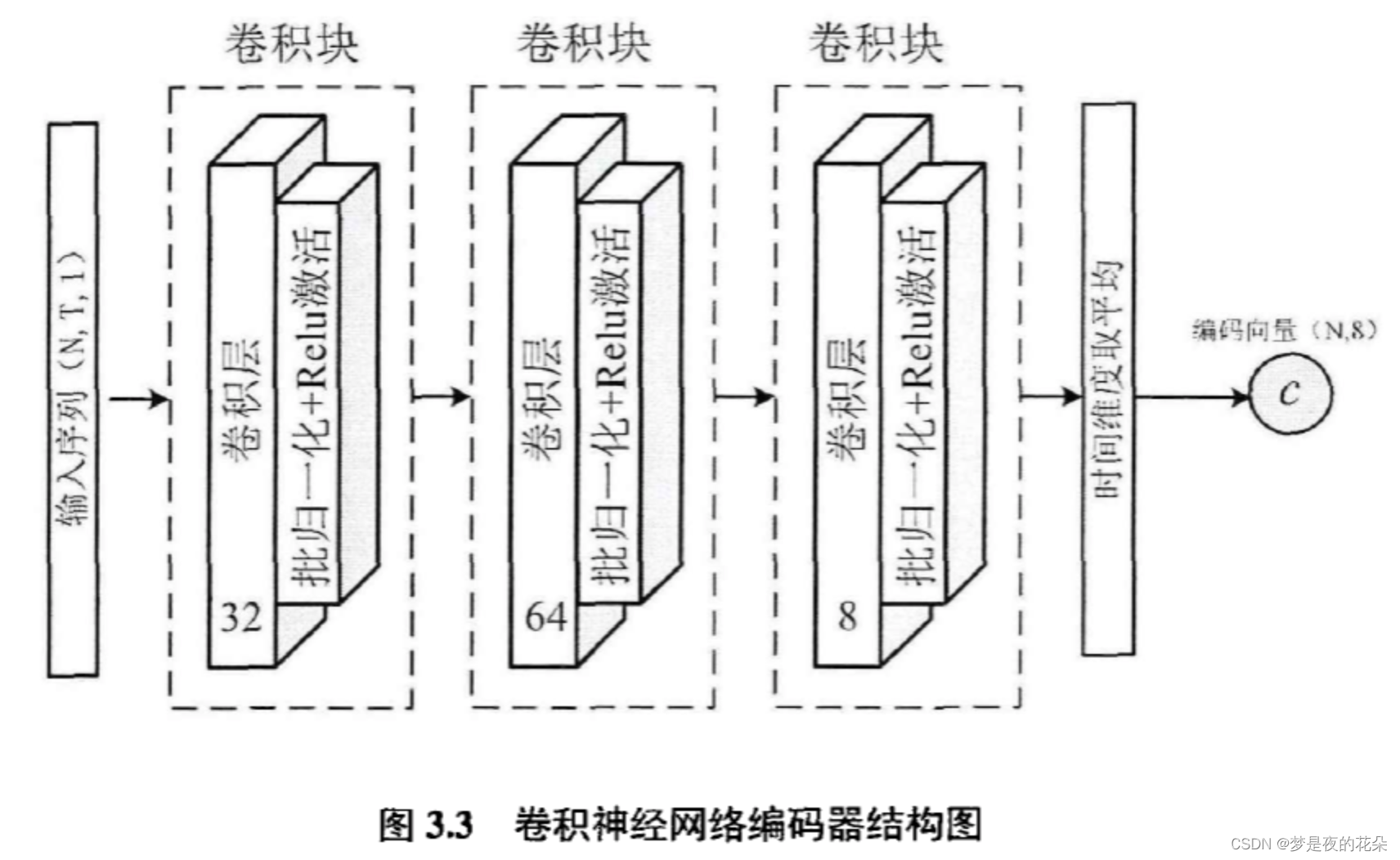
其中,卷积块的输出特征通道维度分别是{32,64,8},每个卷积核尺寸分别是{8,5,3}。此外,批归一化层的作用是加速网络收敛以及提高泛化能力。所有卷积层均使用了填充策略,以保持输入和输出的维度一致。
编码器的输入为单变量时间序列X = [x1,x2,…,xT]。经过三个卷积块后,输出为h = [h1,h2,…,hT],其中hi是8维向量。有两种方法可以获取编码向量:

由于第二种方法可以保留更多的全局模式信息,而第一种方法忽略了其他时间步提取到的特征,所以本章使用第二种方法,将顶层特征在时间维度上的的均值作为编码向量c。
3.2.2 解码器
解码器的作用是将包含全局模式特征的编码向量与包含局部模式特征的注意力向量映射为解码输出序列。再将该序列作为鉴别性特征,进一步输入到全连接层得到类别概率分布。如图3.4所示,本章的设计的解码器由单层长短时记忆网络网络(Long Short Term Memory,LSTM)组成,输出是长度为L的序列y1,y2,…,yL,其中L是一个超参数,本章将其设置为15。在应用时域注意力机制时,需要求取解码器隐藏状态与编码器每个时间步的隐藏状态的点积匹配值,所以要求二者的维度相同。因此,本章将解码器的隐藏节点数设置为8,与编码器顶层的隐藏节点数保持一致。全连接层的神经单元数为K,与类别数相同。初始记忆存储单元设置为零向量。
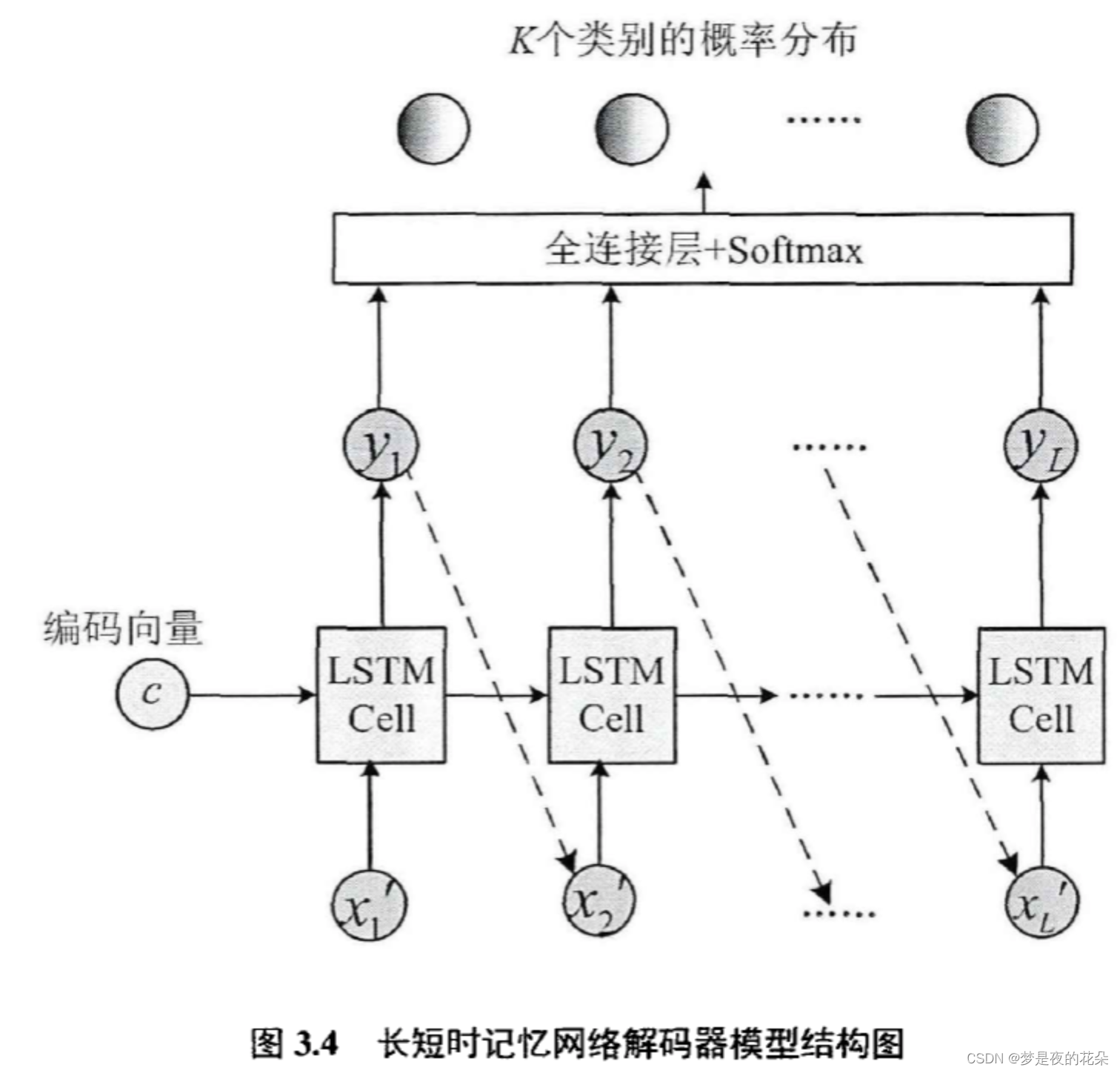
为了加强模型对局部模式特征的感知能力,模型在解码过程中引入了时域注意力机制。设编码器的顶层隐藏状态序列为解码器在 f-1 时刻的隐藏状态为Sn,则f时刻的注意力向量为:



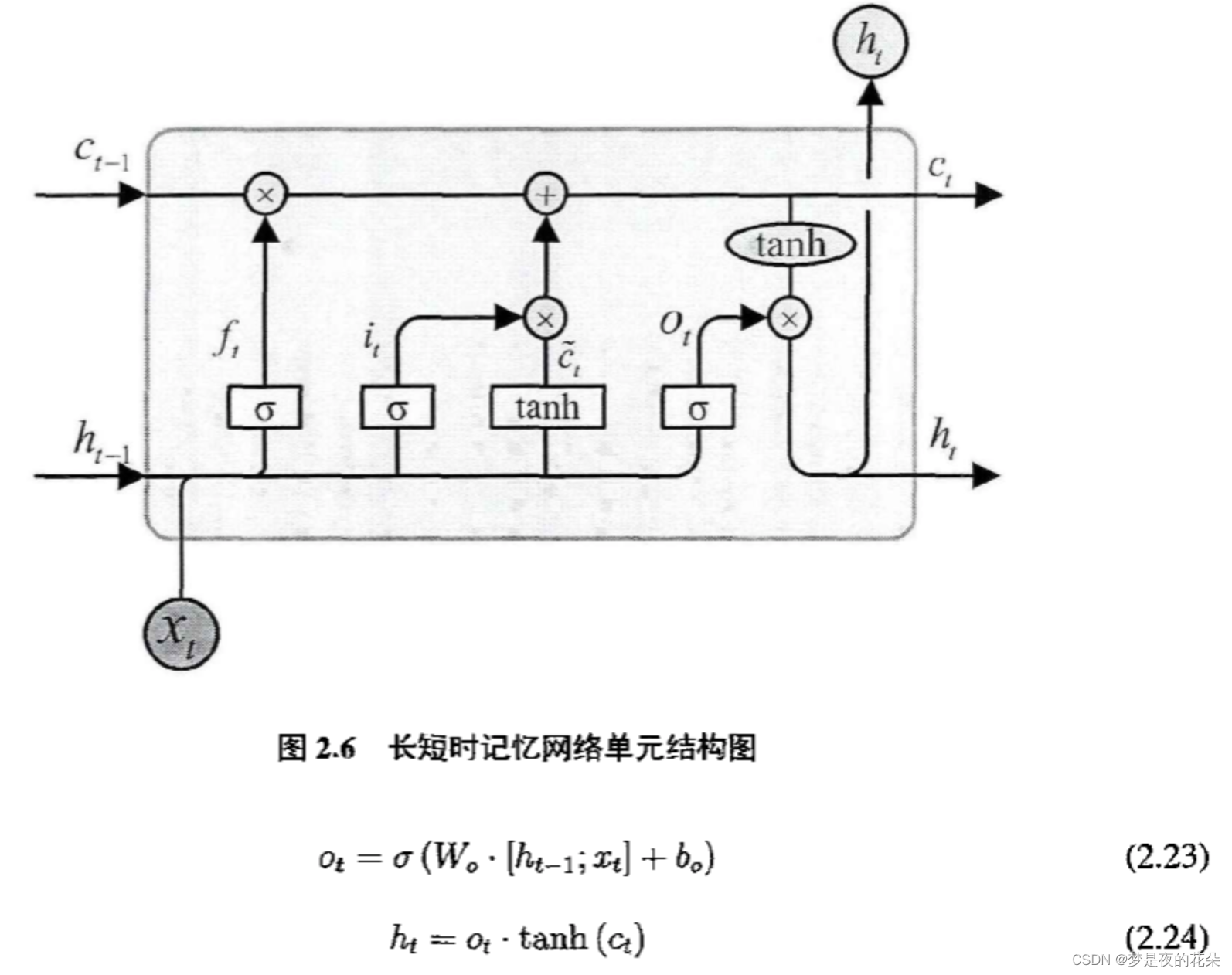
2.4 节的LSTM单元

3.2.3 小结
本章分别对编码器和解码器进行了设计。其中,编码器由三个卷积块组成,将最后一层的顶层输出特征在时间维度上的平均值作为编码向量。解码器由单层LSTM网络和全连接层构成,并且引入了时域注意力机制来捕捉局部模式特征。图3.5展示了本章设计的CLA(CNN+LSTM+Attention)模型。
3.2.4 实验
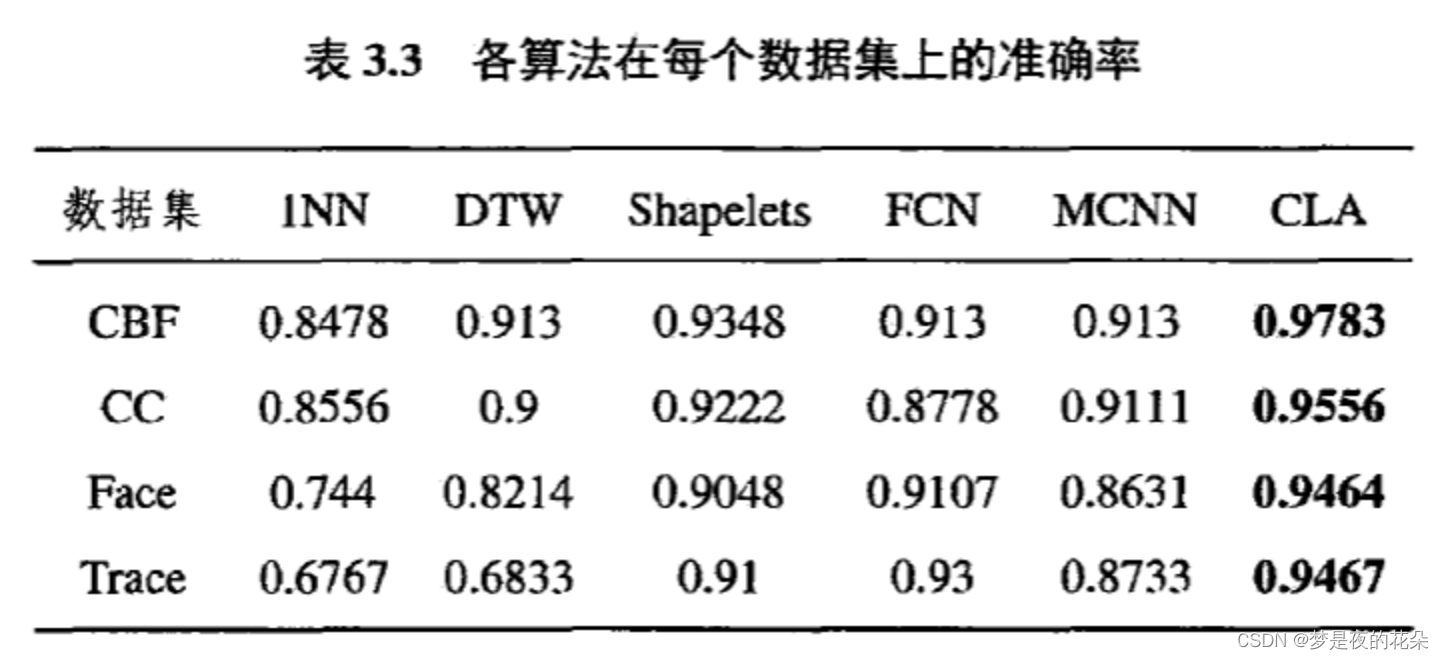
(1) 实验数据集上取得较好的分类准确率
(2)编码解码模型应用于时间序列分类任务的合理性
对于时间序列分类任务,其核心在于产生鉴别性特征。如果模型能够将不同类别的输入数据映射为更具区分度的形式,则会对分类性能有很大提升,这样的模型可以被认为是合理的。
四、针对时间序列分类的频谱注意力机制
4.1 引言
由于现实中的时间序列通常存在大量嗓音,会对算法的性能带来不利影响,所以研究者们通常会在应用算法之前首先对原始数据进行滤波。然而已有的方案都是将滤波和训练分开进行,并且滤波器的设计需要引入专家经验,这增加了算法的设计难度并且不具有通用性。考虑到频域滤波的本质是将不重要频率分量滤除并突出重要分量,这和注意力机制的思想相似。因此,本章将借鉴注意力机制的思想,设计一种可以与深度学习模型兼容的频谱注意力机制。将该模块嵌入网络首层来实现对时间序列数据的自适应滤波,进而改善原始数据的特征表示,提高模型性能。
4.2 问题描述与解决思路

频域滤波的思想:首先将原始数据变换到频域得到频谱,再根据具体情况,对部分频率分量加强或减弱,最后将频谱逆变换回时域。该过程可以用下式描述:

由于频域滤波是将不重要的频率分量忽略,保留或者加强重要波段,这和注意力机制的思想相同。因此,本章可以借助注意力机制的思想,将掩码向量设定为可训练参数,进而实现自适应滤波。
4.3 方案设计
4.3.1 频域变换

4.3.2 频谱注意力机制
由于人类的信息处理能力有限,所以经常会有选择地只关注信息的一部分,同时忽略其余部分,这种机制被称作注意力机制。注意力机制实质上是一种通用思想,并没有严格的数学公式。它通常是一个额外的神经网络,能够为输入特征的不同部分分配合适的权重,或是硬性地选择输入特征的某些部分。根据谱分析理论,时间序列可以被看作是互不相关的频率分量的叠加,并且不同频率分量的价值是不同的。==低频段包含了时间序列中的主要信息,代表长期趋势性特征,高频段往往代表噪声或离群点。==本节尝试将掩码向量设置为可训练参数,通过训练为每个频率分量分配合适的权重。
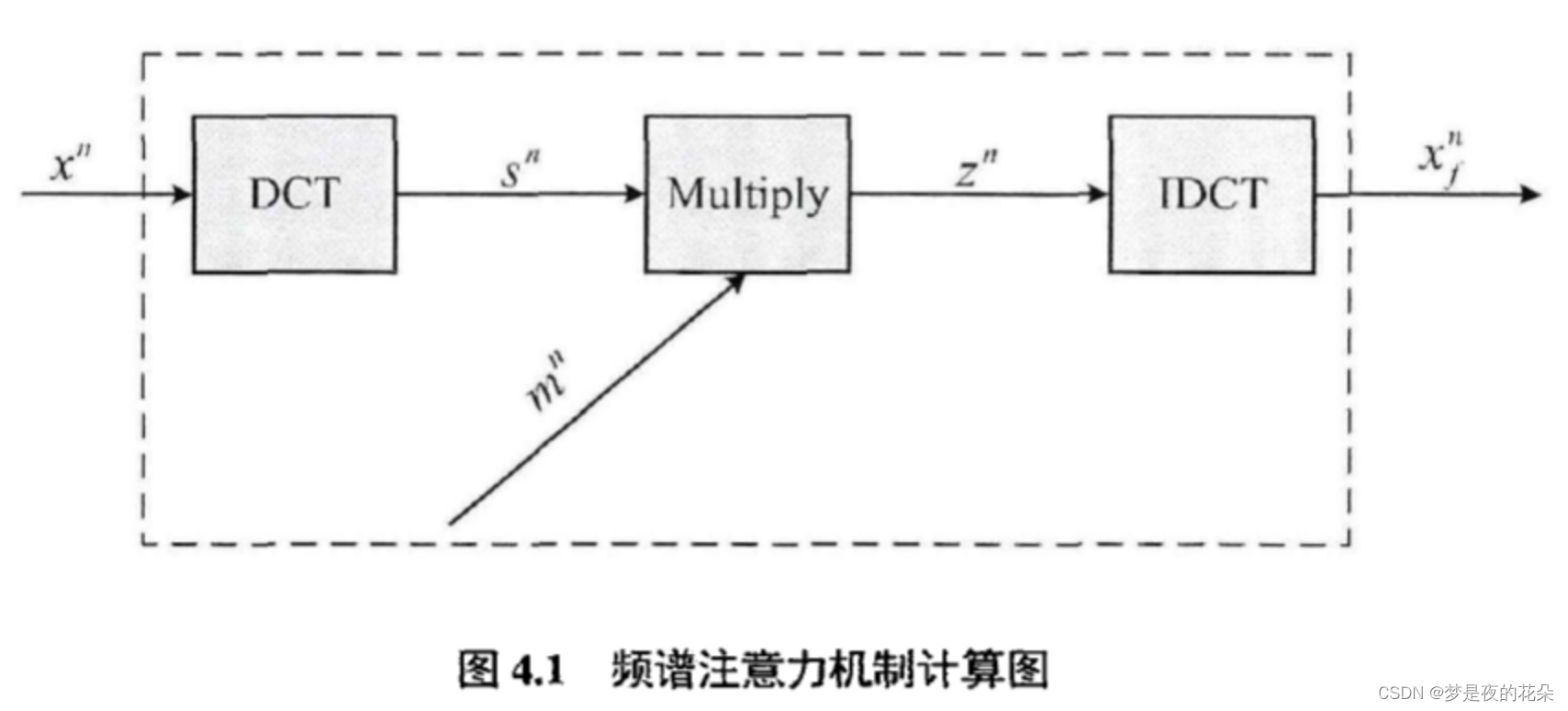
图4.1展不了本章设计的频谱注意力机制(Spectrum Attention Mechanism,SAM)。该模块包含与输入信号同维度的可训练参数mn代表每个频率分量的权重,初始值为全1向量。算法4.1给出了该模块的前向传播过程:首先将原始数据xn,变换到频域,得到其频谱sn。然后将掩码向量mn与频谱sn按位置相乘得到zn。最后将其逆变回时域得到滤波输出xnf。由于上述计算都是可导的,所以掩码向量mn能够在训练过程中被不断更新,最终学习到频率分量的最佳组合,进而实现自适应滤波,生成更利于网络训练的特征。

4.3.3 正则化
引入一种机制来产生稀疏的掩码向量,从而使不重要频率分量的权重尽量小,并突出重要分量。下面从正则化的角度来考虑这个问题。

L1正则化会让特征变得稀疏,起到特征选择的作用;
L2正则化在毎次更新时,会对特征系数进行一定比例的缩放,而非减去固定值。这会让系数趋向变小,而不容易变为0。因此,L2正则化会让模型变得更简单,以防止过拟合,而无法起到特征选择的作用。

4.3.4 分段频谱注意力机制
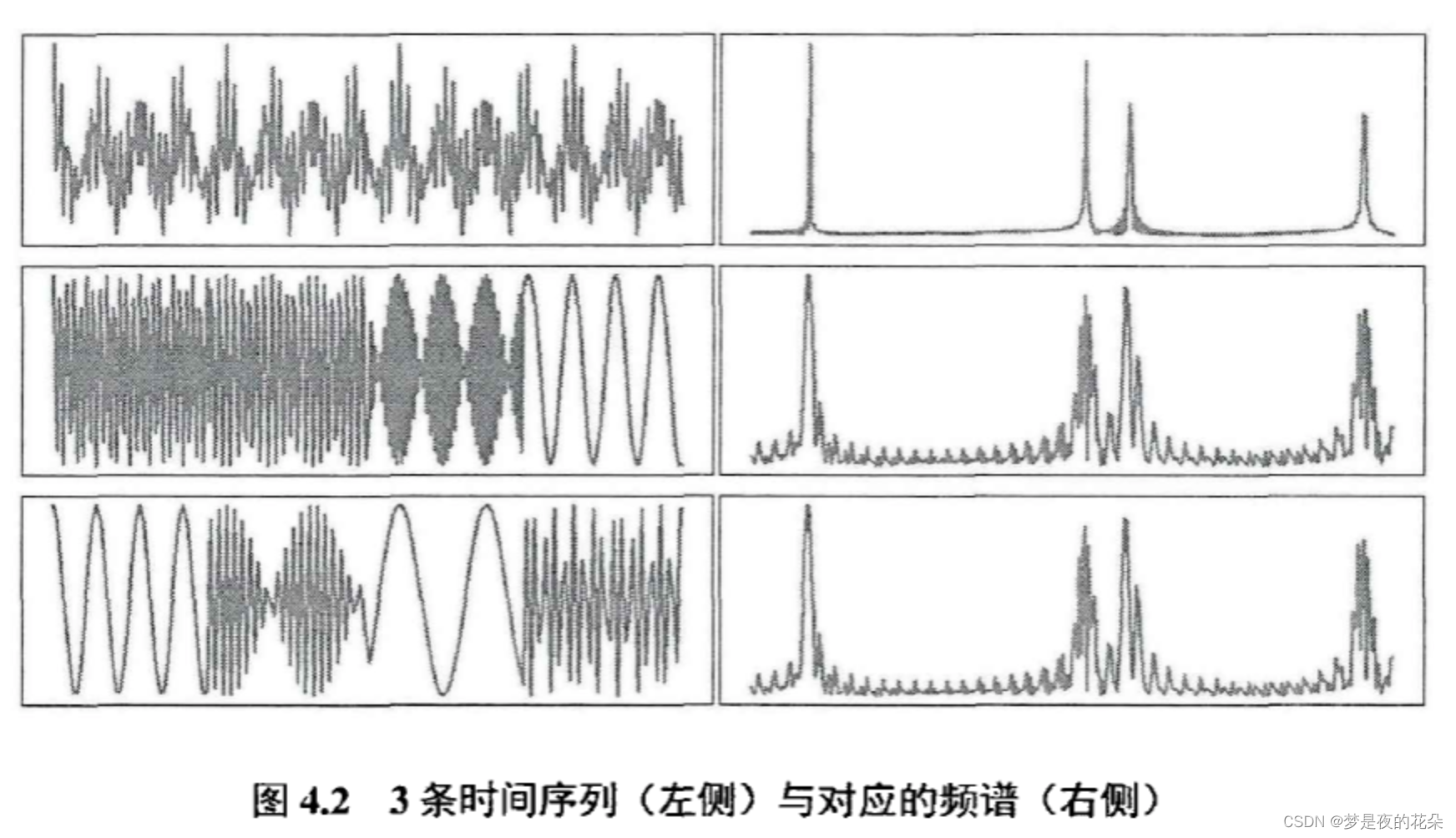
上文设计的频谱注意力机制在内部处理时使用整条序列的频谱,这会忽略原始数据的相位差异。考虑一种极端情况:图4.2展示了3条时间序列与其对应的频谱,它们包含的频率分量一致,但毎个频率分量所处的相位不同。从图中可以看出,尽菅在时域中存在巨大差异,但它们的频谱几乎一致。在这种情况下,由于频谱注意力机制模块在内部处理时使用的频谱相似,就会导致该模块无法辨识信号之间的差异。
现实中的时间序列通常也是非平稳的(频率随时间变化)。所以,为了避免完全丟失相位信息,本节提出分段频谱注意力机制(Segmented Spectrum Attention Mechanism,SSAM)模块。算法4.2 给了该模块的前向传播过程:首先,将原始数据等分为K段。然后对每一段子序列分别应用频域注意力机制。最后,将每个子序列的SAM输出在通道维度上级联,得到输出特征。经过这样处理,即使原始序列的频谱相似,在内部处理时仍然可以在通道维度上体现出序列之间的差异。

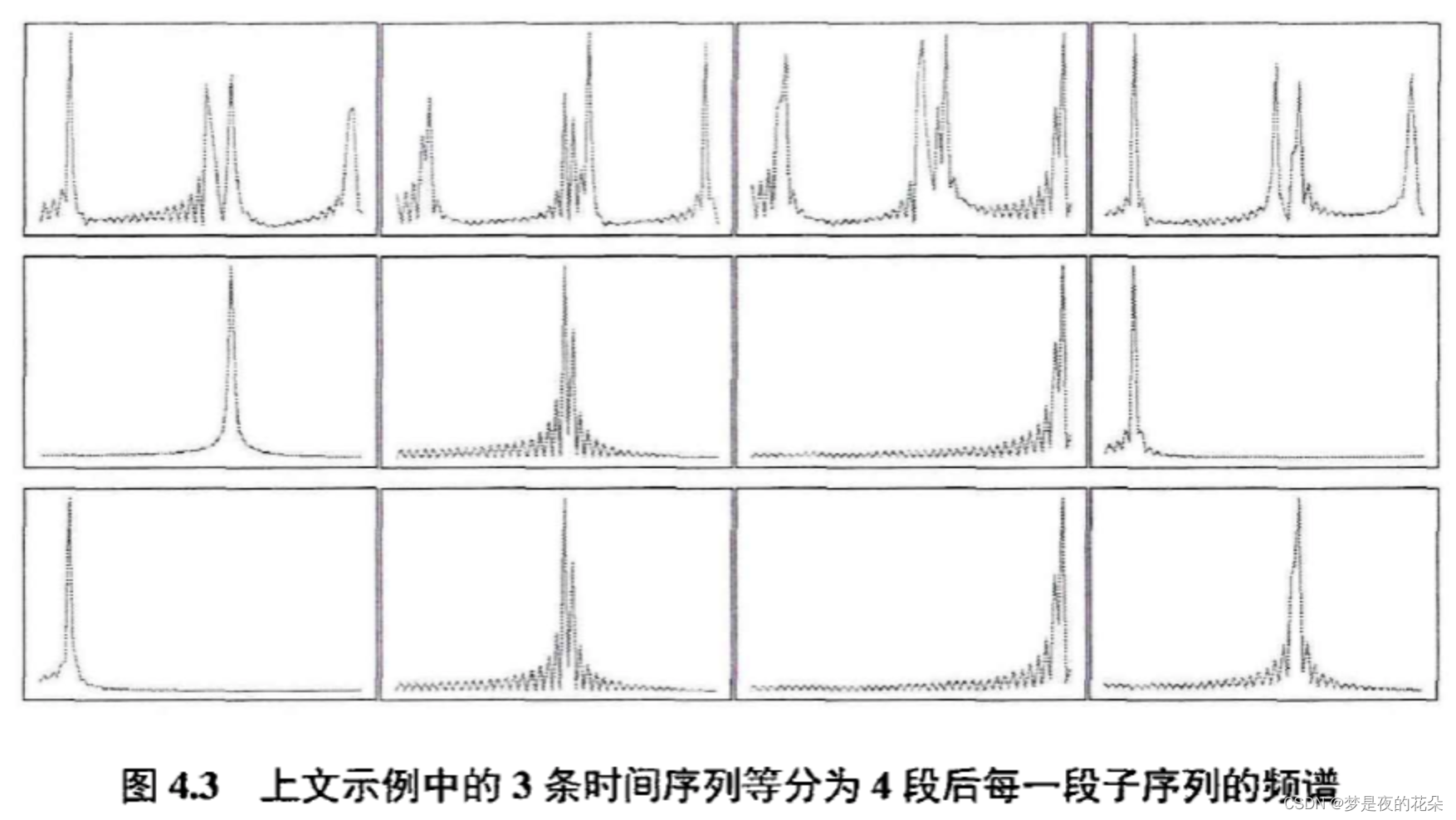
如图4.3所示,如果将上述示例中的3条时间序列等分成4段,把每一段子序列的频谱按顺序存储在每个通道中,则它们之间的差异会在通道维度上体现(比如第2条序列和第3条序列的第1通道和第4通道是不同的)。
由于分段数K是个超参数,难以直接确定。所以,本章还设计了一个启发式搜索算法。如算法4.3所示,K的候选范围是1~10,尝试使用每一个K值训练模型5轮,将最小验证损失值对应的K作为最佳参数,后续应用于模型的最终训练中。

4.3.5 模型结构
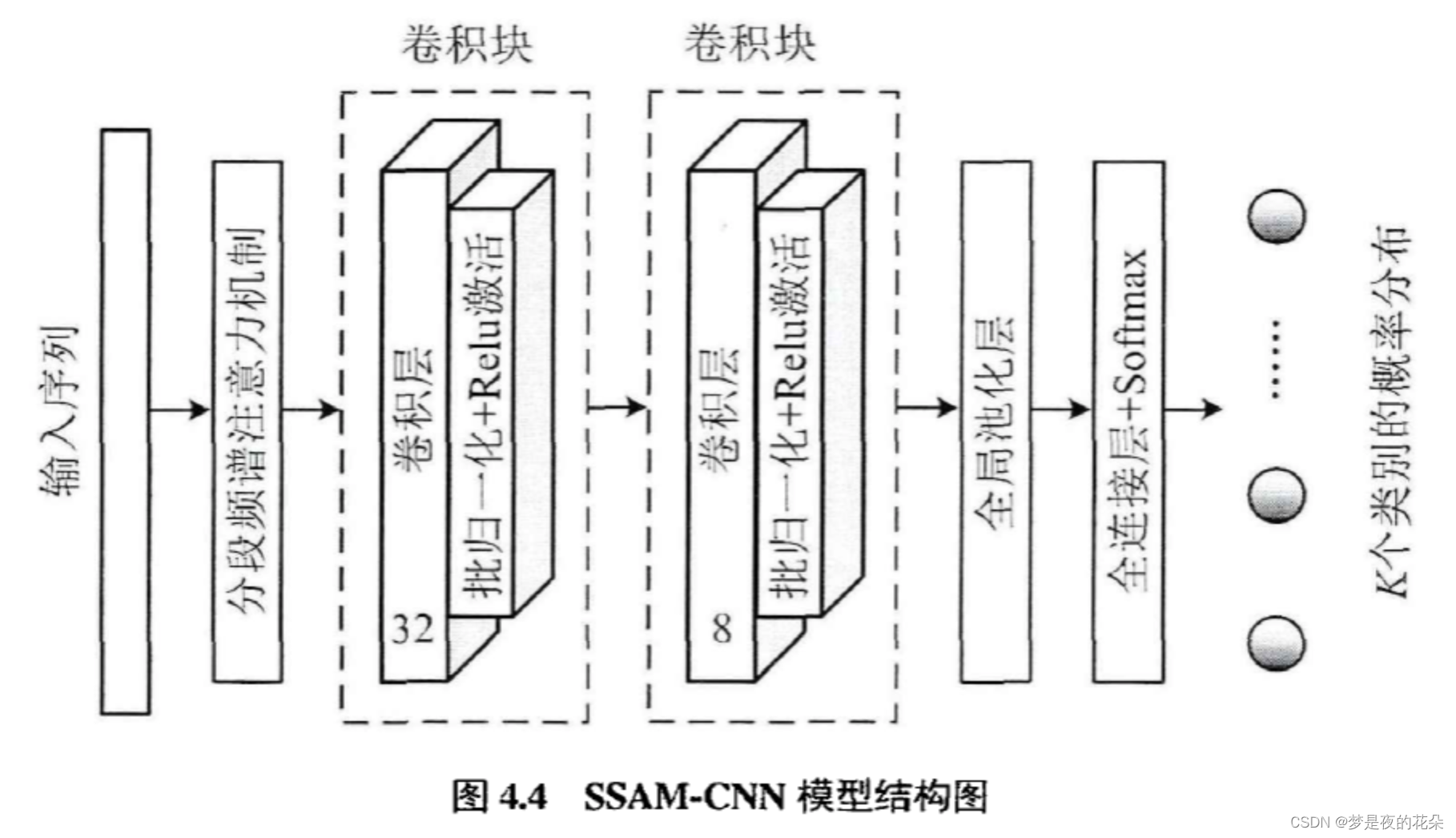
本章的整体目标是设计一种可以与深度学习模型兼容的自适应滤波模块,并通过实验来验证该模块自身的合理性和有效性,为后续章节打下基础。所以,为了避免复杂模型的强拟合能力掩盖模块自身的性能,本章设计的模型栢对筒单。如图4.4所示,本章设计的SSAM-CNN模型由分段频谱注意力机制模块、两个卷积块、全局池化层和全连接层组成。为了对比验证该模块的作用,本章将该模型的后段(去除首层)作为基础模型,参加后续的对比实验。
4.4 实验与分析
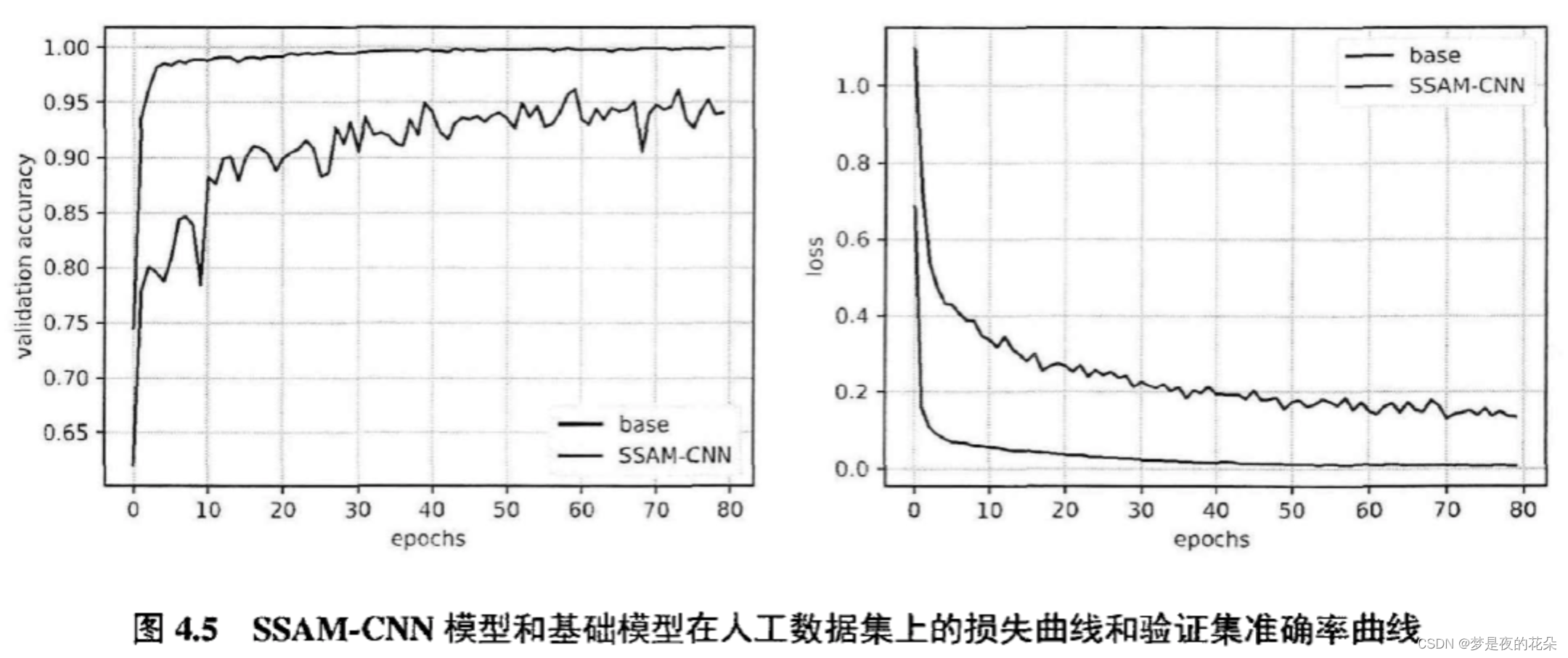
SSAM-CNN模型收敛更快,并且学习曲线更加平滑。这说明,SSAM能够将使原始特征映射为更利于网络训练的特征表示,从而加速了网络的收敛。另外,SSAM-CNN模型在人工数据集上的准确率达到了99.94%,远高于基础模型的93.09%。
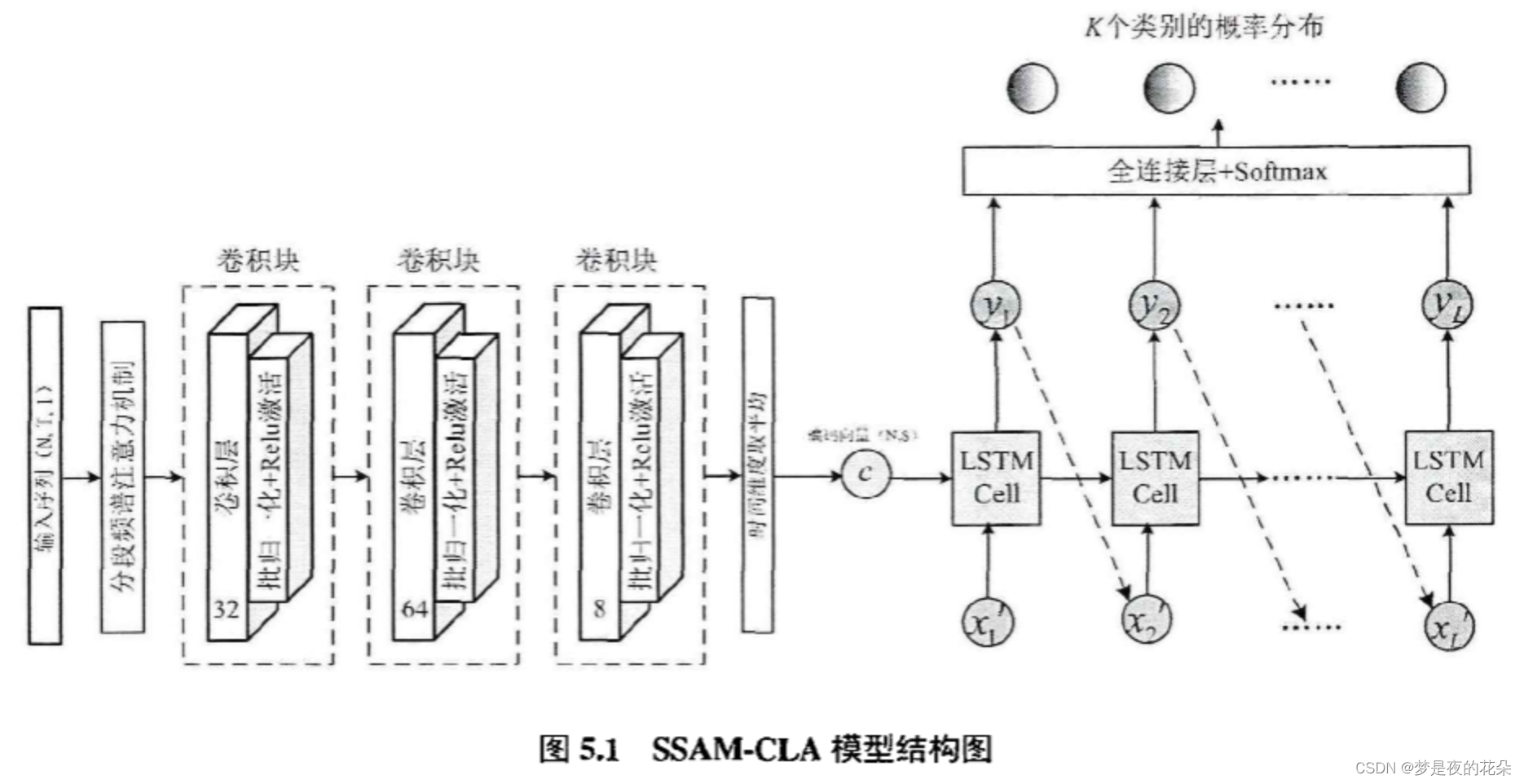
5 基于频谱注意力机制与编码解码模型的时间序列精准分类
单模型算法是指使用单个模型解决时间序列分类任务。多模型算法是指将多个模型使用某些策略结合在一起,从而获得比单一模型更高的分类准确率。一般来说,单模型算法的计算复杂度较低,适合在任务初期作为基础模型使用。
多模型算法一般准确率更高,计算复杂度也较高,在满足计算性能要求的情况下,更适合在追求极高精度的情况下使用。
5.1 基于单模型的时间序列分类
本节将二者结合,设计了SSAM-CLA模型。数据首先被输入到分段频谱注意力机制模块进行滤波,生成更利于网络训练的特征。然后输入到CLA模型中。首先编码器将其映射为固定长度的编码向量,作为解码器的启动状态。解码器结合时域注意力机制将其映射为固定长度的输出序列,作为鉴别性特征。最后由全连接层生成类别概率分布。
5.2 基于多模型集成的时间序列分类
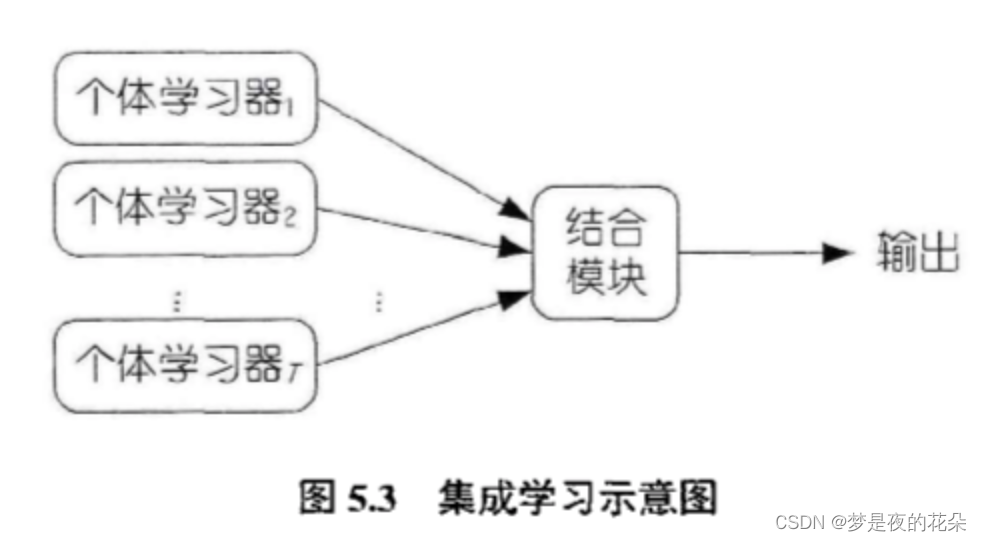
集成学习是指通过构建并结合多个分类器来完成分类任务。图5.3展示了集成学习的普遍结构:先构建一組个体学习器,再用某种策略将其融合。集成学习通过将多个学习器进行结合,常可以获得比单一学习器更好的泛化性能。
5.2.1模型集成
5.2.2 方案设计
本节设计的CODLE(Collective Of Deep Learning Ensembles)算法采用深度学习模型作为基分类器。
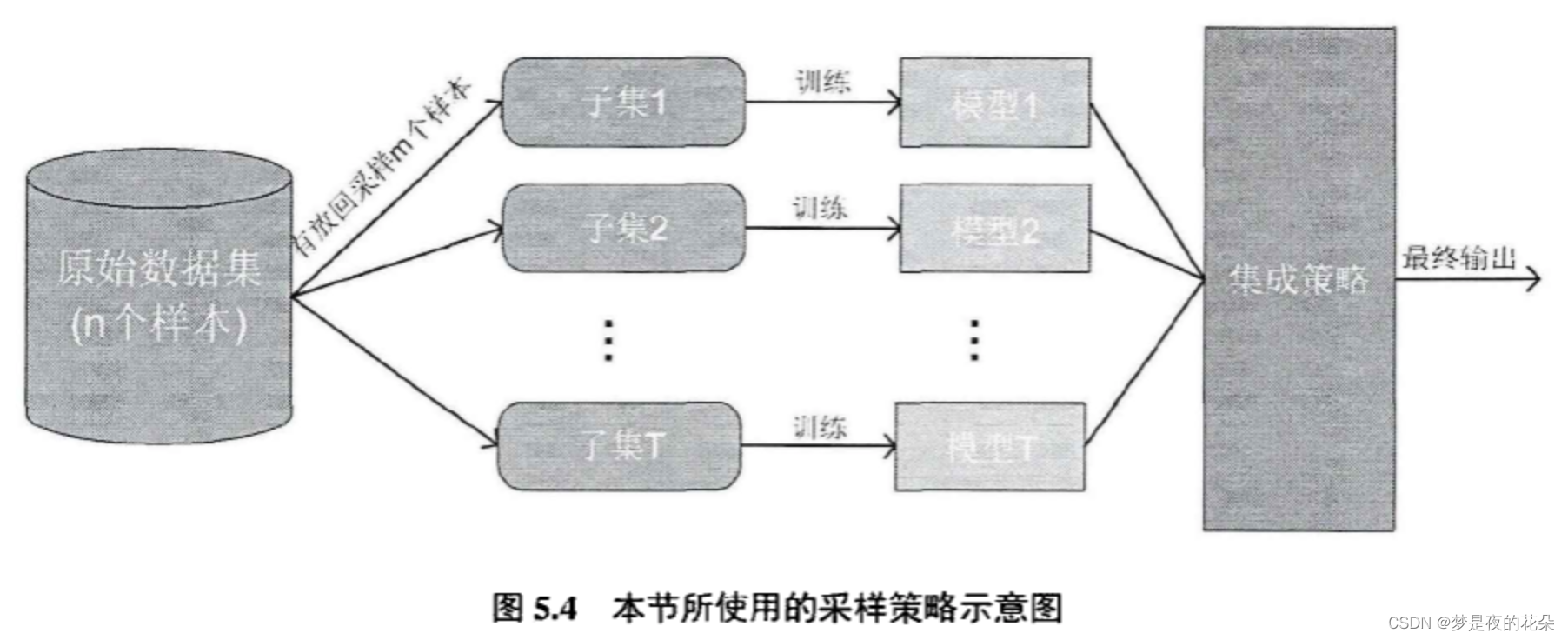
5.2.2.1 样本采样
5.2.2.2 基分类器
本节设计的CODLE算法由10个基分类器组成。分别是分段数瓦为1~5的SSAM-CLA模型,以及FCN、MCNN、MDCNN、LSTM-FCN和Inception Time模型。下面详细介绍这些基分类器。
5.2.2.3 组合策略
对于分类任务来说,分类器hi从标签集合{c1,c2,…,cK}中预测出一个标记,本节设计了三种投票策略,分别是投票法、加权投票法和学习法。接下来分别展开介绍。为便于讨论,将hi在样本x上的预测标签表示为一个K维向量(h1i(x);h2i(x),…,hKi(x))。其中hji(x)是hi在类标cj上的输出。

5.2.3 试验结果与分析
6 总结与展望
6.1 创新点
(1)本文创新性地将常用于生成任务的编码解码模型用于时间序列分类任务,并对其做了两处改动:第一,固定解码输出序列长度,将其视为鉴别性特征。第二,解码器在训练阶段和测试阶段均将前一时间步的输出作为当前时间步的输入。并通过实验证明了编码解码模型用于时间序列分类的有效性和合理性。
(2)本文创新性地提出了频谱注意力机制,将其嵌入到模型首层,可以自适应地为每个频率分量分配合适的权重,从而改善原始数据的特征表示,进而提高模型性能。
(3)本文创新性地提出了深度学习集成算法,在分类性能与当前最先进算法无显著差异的情况下,大大降低了时间消耗。
6.2 展望
(1)在进行生成任务时,为了避免前一时间步的输出不够准确,导致当前时间步无法获得精准的输入,编码解码模型采用Teacher Forcing训练机制,也就是将目标语句作为解码器的输入。对于时间序列分类任务,我们也可以尝试将人工设计的特征作为目标输出,利用该机制逬行训练。
(2)本文提出的频谱注意力机制是一种软注意力机制,通过为每个频率分量分配合适的权重来实现自适应滤波。我们也可以尝试使用硬注意力机制,即每个频率分量的权重只有0或1两种取值。此时,模型只对相关度最高的部分信息做完全处理,可能获得更高的准确率和计算效率。
(3)集成算法对于基分类器的要求是“好而不同”。如果能够采取某些策略量化模型之间的差异性,则可以进一步缩减基分类器数量并且提高算法的分类性能。
最后
以上就是含糊金毛最近收集整理的关于基于频谱注意力机制和编码解码模型的时间序列分类研究的全部内容,更多相关基于频谱注意力机制和编码解码模型内容请搜索靠谱客的其他文章。








发表评论 取消回复