IP数据报的格式
IP数据报的格式说明协议IP都具有什么功能。在协议IP的标准中,描述首部格式的宽度是32位(即4字节)。下图是IP数据报的完整格式。
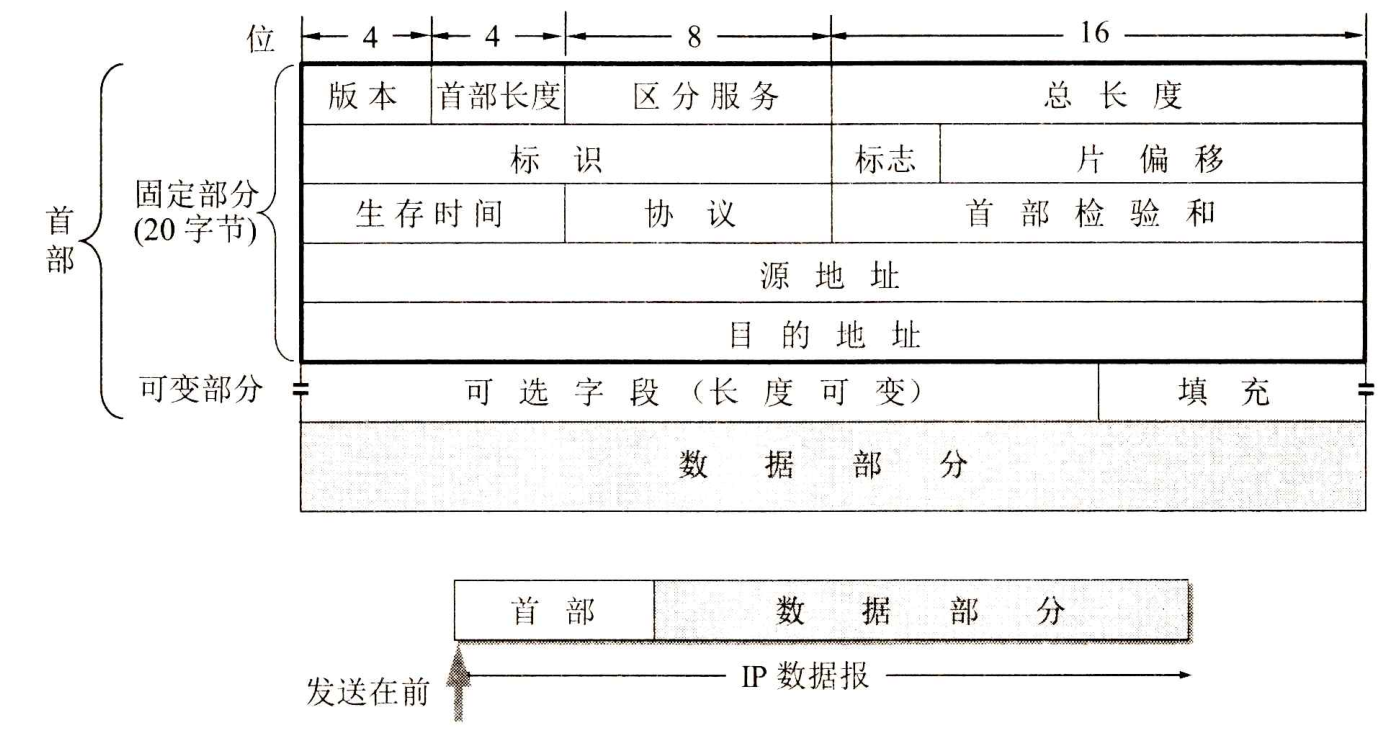
从上图可看出,一个IP数据报由首部和数据两部分组成。首部的前一部分长度是固定的,共20字节,是所有IP数据报必须具有的。在首部的固定部分的后面是一些可选字段,其长度是可变的。下面介绍首部各字段的意义。
IP数据报首部的固定部分中的各字段
版本:占4位,指协议IP的版本。
- 通信双方使用的协议IP的版本必须一致。
- 两种版本:IPv4和IPv6。
首部长度:占4位,可表示的最大十进制数值是15。
请注意,首部长度字段所表示数的单位是32位字长(1个32位字长是4字节)。
- IP首部的固定部分是20字节,
- 因此首部长度字段的最小值是5(即二进制表示的首部长度是
0101)。 - 而当首部长度字段为最大值
1111时(即十进制的15),就表明首部长度达到最大值:15个32位字长,即60字节。
- 因此首部长度字段的最小值是5(即二进制表示的首部长度是
- 当IP分组的首部长度不是4字节的整数倍时,必须利用最后的填充字段加以填充。因此IP数据报的数据部分永远在4字节的整数倍时开始,这样在实现协议IP时较为方便。
- 首部长度限制为60字节的缺点是有时可能不够用,但这样做是希望用户尽量减少开销。
- 最常用的首部长度是20字节,不使用任何可选字段。
区分服务:占8位,用来获得更好的服务。
- 这个字段在旧标准中叫作服务类型,但实际上一直没有被使用过。1998年IETF把这个字段改名为区分服务DS(DifferentiatedServices)。
- 只有在使用区分服务时,这个字段才起作用。
- 在一般的情况下都不使用这个字段。
总长度:总长度指首部和数据之和的长度,单位为字节。
- 总长度字段为16位,因此数据报的最大长度为 2 16 − 1 = 65535 2^{16}-1=65535 216−1=65535字节。然而实际上传送这样长的数据报在现实中是极少遇到的。
在IP层下面的每一种数据链路层协议都规定了一个数据帧中的数据字段的最大长度,这称为最大传送单元MTU(Maximum Transfer Unit)。
- 当一个IP数据报封装成链路层的帧时,此数据报的总长度(即首部加上数据部分)一定不能超过下面的数据链路层所规定的MTU值。
例如,最常用的以太网就规定其MTU值是1500字节。
- 若所传送的数据报长度超过数据链路层的MTU值,就必须把过长的数据报进行分片处理。
虽然使用尽可能长的IP数据报会使传输效率得到提高,但数据报短些也有好处。IP数据报越短,路由器转发的速度就越快。为此,协议IP规定,在互联网中所有的主机和路由器必须能够接受长度不超过576字节的数据报。当主机需要发送长度超过576字节的数据报时,应当先了解一下,目的主机能否接受所要发送的数据报长度。否则,就要进行分片。
这是假定上层交下来的数据长度有512字节,加上最长的IP首部60字节,再加上4字节的富余量,就得到576字节。
在进行分片时,数据报首部中的“总长度”字段是指分片后的每一个分片的首部长度与该分片的数据长度的总和。
标识(identification):占16位。
- IP软件在存储器中维持一个计数器,每产生一个数据报,计数器就加1,并将此值赋给标识字段。但这个“标识”并不是序号,因为IP是无连接服务,数据报不存在按序接收的问题。
- 当数据报由于长度超过网络的MTU而必须分片时,这个标识字段的值就被复制到所有的数据报片的标识字段中。
相同的标识字段的值使分片后的各数据报片最后能正确地重装成为原来的数据报。
标志(flag):占3位,但目前只有两位有意义。
- 标志字段中的最低位记为MF(More Fragment)。
MF=1即表示后面“还有分片”的数据报。MF=0表示这已是若干数据报片中的最后一个。
- 标志字段中间的一位记为DF(Don’t Fragment),意思是“不能分片”。
- 只有当
DF=0时才允许分片。
- 只有当
片偏移:占13位。
- 片偏移指出:较长的分组在分片后,某片在原分组中的相对位置。也就是说,相对于用户数据字段的起点,该片从何处开始。
- 片偏移以8个字节为偏移单位。这就是说,除最后一个数据报片外,其他每个分片的长度一定是8字节(64位)的整数倍。
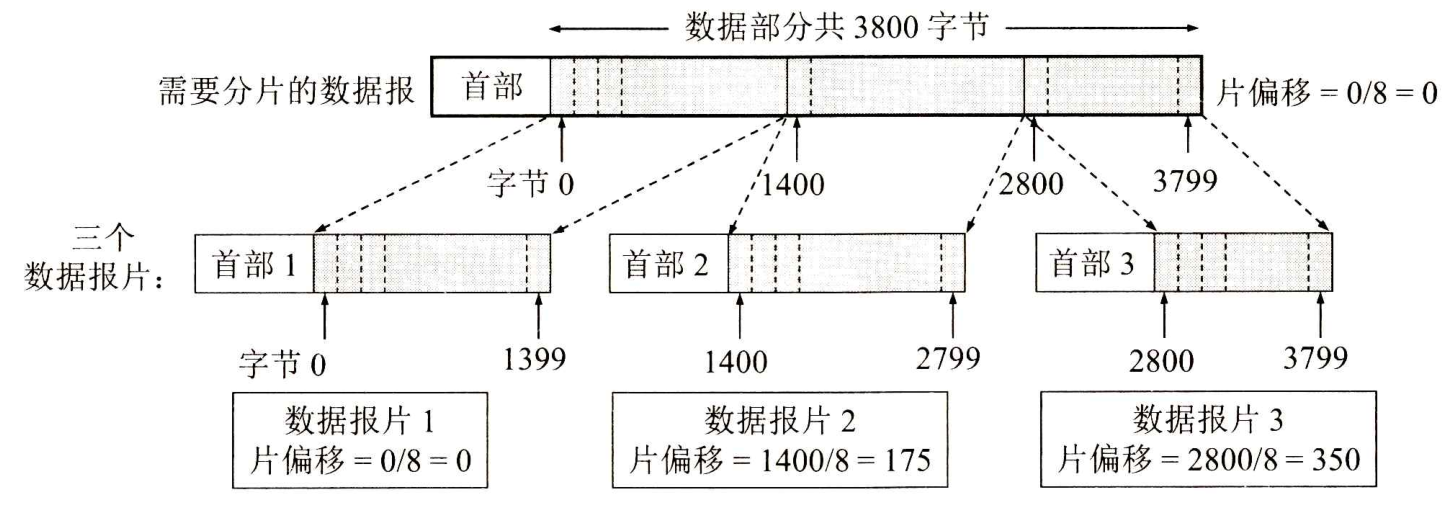
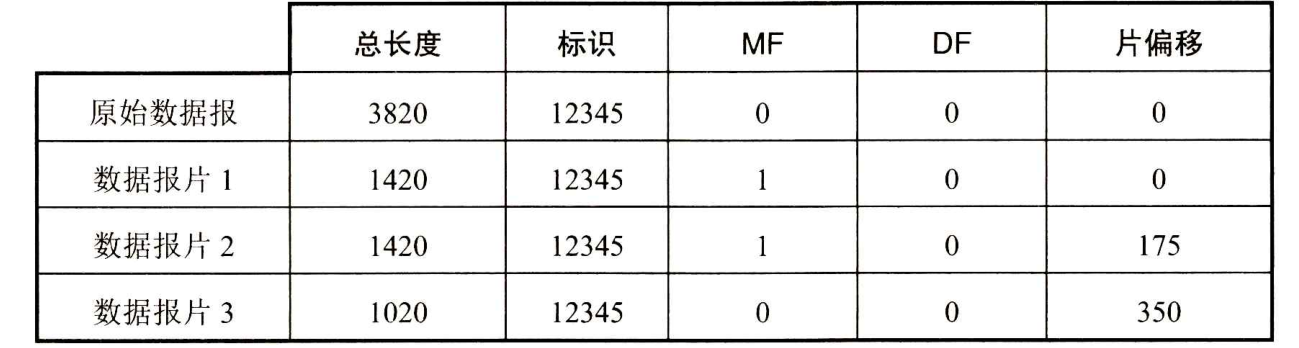
【例】一个数据报的总长度为3820字节,其数据部分为3800字节长(使用固定首部),需要分片为长度不超过1420字节的数据报片。因固定首部长度为20字节,因此每个数据报片的数据部分长度不能超过1400字节。于是分为3个数据报片,其数据部分的长度分别为1400,1400和1000字节。原始数据报首部被复制为各数据报片的首部,但必须修改有关字段的值。下图给出分片后得出的结果。
下表是本例中数据报首部与分片有关的字段中的数值,其中标识字段的值是任意给定的。具有相同标识的数据报片在目的站就可无误地重装成原来的数据报。
现在假定数据报片2经过某个网络时还需要再进行分片,即划分为数据报片2-1(携带数据800字节)和数据报片2-2(携带数据600字节)。那么这两个数据报片的总长度、标识、MF、DF和片偏移分别为:820,12345,1,0,175;620,12345,1,0,275。
生存时间:占8位,生存时间字段常用的英文缩写是TTL(Time To Live)
- 表明这是数据报在网络中的寿命。
- 由发出数据报的源点设置这个字段。其目的是防止无法交付的数据报无限制地在互联网中兜圈子,因而白白消耗网络资源。
- TTL的意义是指明数据报在互联网中至多可经过多少个路由器。
- 路由器在每次转发数据报之前就把TTL值减1。若TTL值减小到零,就丢弃这个数据报,不再转发。因此,TTL的单位是跳数。
- 数据报能在互联网中经过的路由器的最大数值是255。
- 若把TTL的初始值设置为1,就表示这个数据报只能在本局域网中传送。
协议:占8位
- 协议字段指出此数据报携带的数据使用何种协议,以便使目的主机的IP层知道应将数据部分上交给哪个协议进行处理。
- 常用的一些协议和相应的协议字段值如下:

首部检验和:占16 位。
- 这个字段只检验数据报的首部,不包括数据部分。这是因为数据报每经过一个路由器,路由器都要重新计算一下首部检验和,所以首部需要检验。
不检验数据部分可减少计算的工作量。
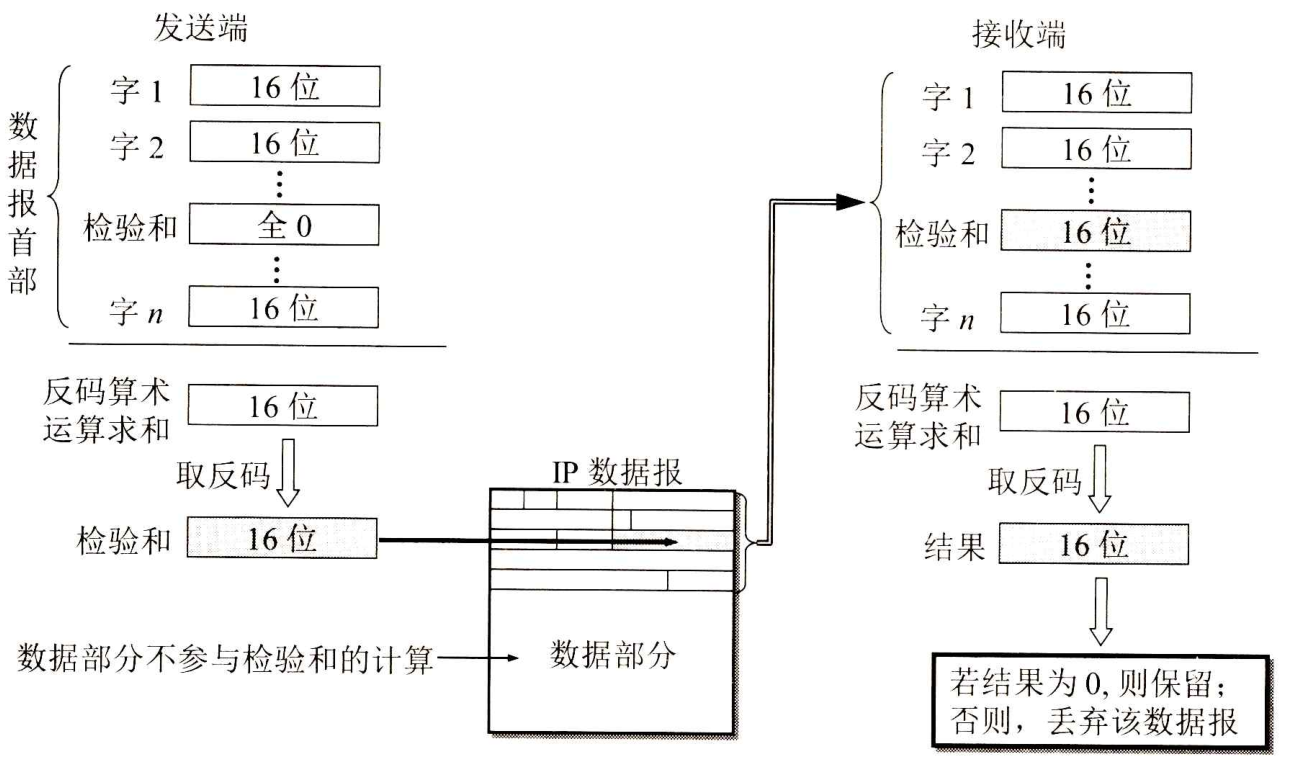
- IP首部的检验和不采用复杂的CRC检验码,而采用下面的简单计算方法:
- 在发送方,先把IP数据报首部划分为许多16位字的序列,并把检验和字段置零。用反码算术运算把所有16位字相加后,将得到的和的反码写入检验和字段。
- 接收方收到数据报后,把首部的所有16位字再使用反码算术运算相加一次。将得到的和取反码,即得出接收方检验和的计算结果。
- 若首部未发生任何变化,则此结果必为0,于是就保留这个数据报;否则即认为出差错,并将此数据报丢弃。
下图说明了IP数据报首部检验和的计算过程。
源地址:占32位。
- 发送IP数据报的主机的IP地址。
目的地址:占32位。
- 接收IP数据报的主机的P地址
IP数据报首部的可变部分
IP 数据报首部的可变部分就是一个选项字段。选项字段用来支持排错、测量以及安全等措施,内容很丰富。此字段的长度可变,从1字节到40字节不等,取决于所选择的项目。
- 某些选项项目只需要1字节,它只包括1字节的选项代码。
- 而有些选项需要多个字节,这些选项一个个拼接起来,中间不需要有分隔符,最后用全0的填充字段补齐为4字节的整数倍。
增加首部的可变部分是为了增加IP数据报的功能,但这同时也使得IP数据报的首部长度成为可变的。这就增加了每一个路由器处理数据报的开销。
实际上这些选项很少被使用。很多路由器都不考虑IP首部的选项字段,因此新的IP版本IPv6就把IP数据报的首部长度做成固定的了。
最后
以上就是阳光砖头最近收集整理的关于【计算机网络系列】网络层④:详解IP数据包的格式的全部内容,更多相关【计算机网络系列】网络层④:详解IP数据包内容请搜索靠谱客的其他文章。








发表评论 取消回复