参考:
India LTE ARQ and HARQ (Part1)| LTE ARQ and HARQ (Part2)
前言:
这里面主要基于ARQ&HARQ ,讨论的Error Detection & error correction
PDSCH: Physical downlink shared channel
PDCCH: Physical downlink control channel
PFICH: Physical formate indicator channel
PUCCH: Physical uplink control channel
https://baijiahao.baidu.com/s?id=1686562757923201007&wfr=spider&for=pc
https://blog.csdn.net/a34140974/article/details/79577942
https://blog.csdn.net/adusuccessfully/article/details/46489489
https://www.bilibili.com/read/cv12039485
https://www.renrendoc.com/paper/144632065.html
https://www.renrendoc.com/paper/157638961.html
百度安全验证
主要参考:
LTE学习笔记 HARQ、HARQ process、HARQ information、同步异步、自适应非自适应、ACKNACK反馈、上行HARQ1
目录:
- 概述
- 增量冗余例子
- HARQ Process
- HARQ information
- 同步/异步
- adaptive|non-adaptive HARQ
- Bundling& Multiplexing:
- 上行HARQ
一 概述
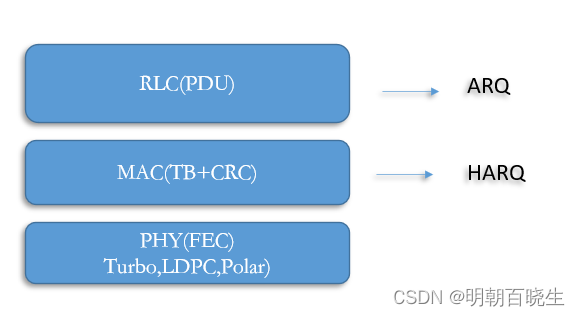
Hybrid Automatic Repeat reQuest : 混合式重传请求,
是一种结合FEC(Forward Error Correction)与 ARQ(Automatic Repeat request)数据
传输方式。
FEC: 通过增加冗余信息,使得接收端能够纠正错误,降低信道出错概率。
常用的是Turbo,Polar,LDCP,CRC
对于 FEC 无法纠正的错误,接收端会通过RLC层的AQR 请求发送端
重发数据。接收端通过CRC 校验是否出错,如果正确发送ACK,出错则发送NACK
,发送端收到NACK 后,重发相同数据。
AQR 机制采用了丢弃数据包请求重传的方法,虽然这些数据包无法被正确
解码,但其中还是包含有用的信息,可以通过HARQ with soft combining ,
收到的错误数据包保存在HARQ Buffer里面,然后与后续接收到的重传数据包进行
合并,从而得到一个比单独解码更可靠的数据包。最后对合并后的数据包进行解码,
如果还是失败,请求重传,再进行软合并。
根据重传bit信息与原始传输信息bit 是否相同分为两类

增量冗余中,每次重传不需要与初始传输相同,会多出个一个coded bit
集合,每个集合都携带相同的信息。重传时,通常传输与前一次不同的
coded bit 集合,接收端会把重传的数据与前一次传输的数据进行合并,
每次重传的code bit 集合称为一个RV(Redundancy version)
由于重传可能携带了不包含前一次传输中的额外奇偶校验parity bit
所以重传的码率会降低,每次重传可以包含与初始传输数目不同的coded bit
,且不同传输的调制方式可以不同
二 增量冗余(RV)例子
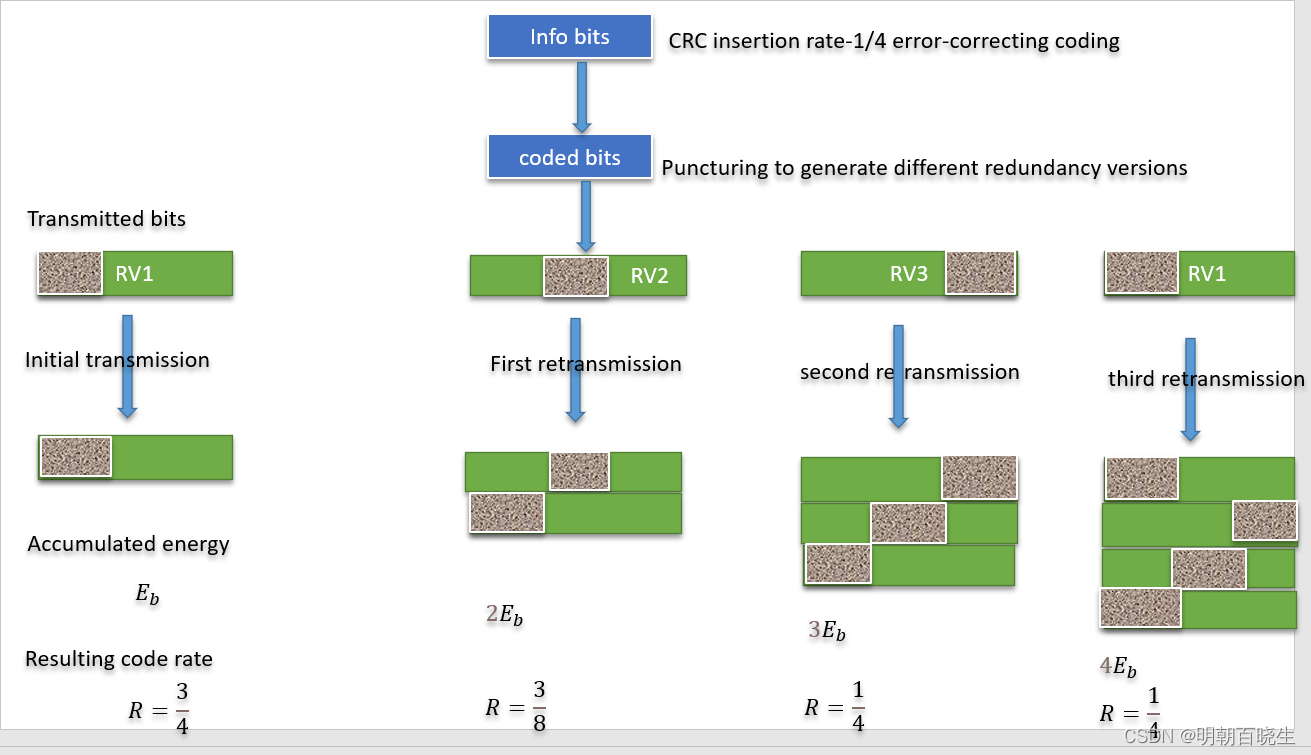
2.2 DL-SCH 物理层处理
以 DL-SCH 的物理层处理步骤来简单介绍一下冗余版本RV的生成过程
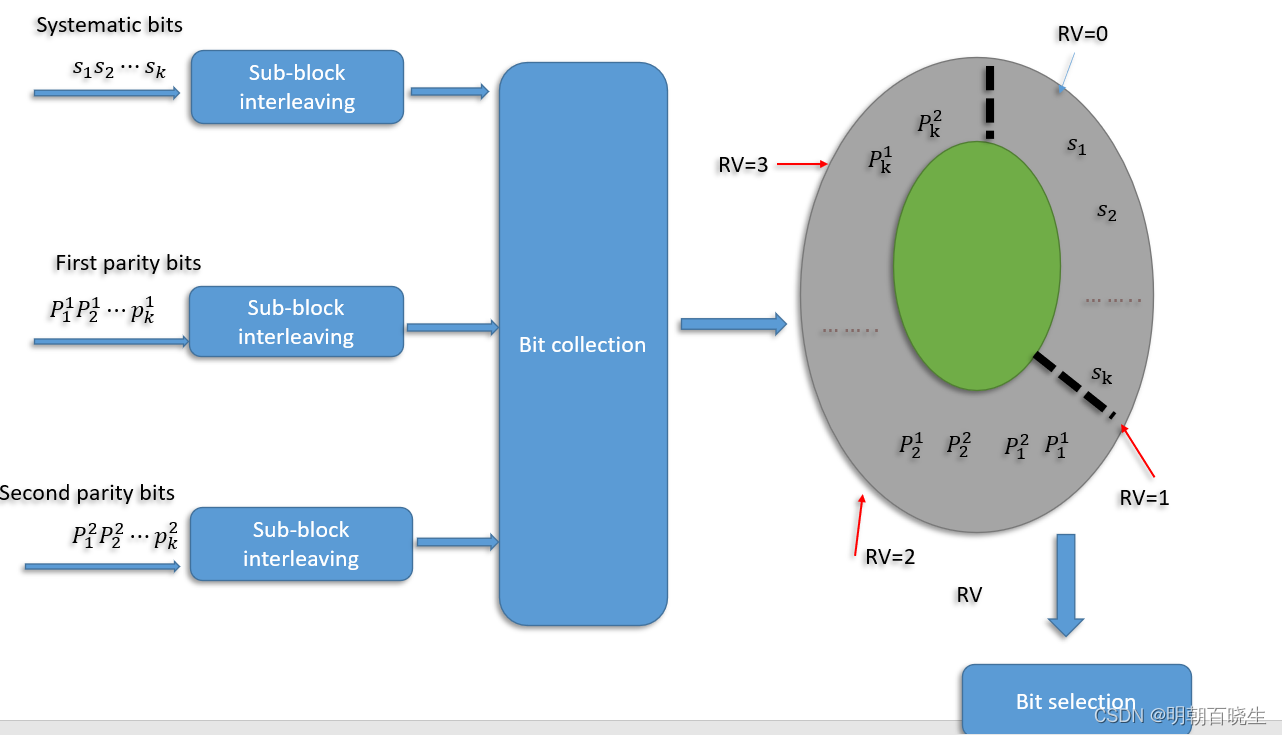
在Turbo编码后,会输出systematic bits, first parity bits & second parity bits
这些输出会进行交织,然后放入环形缓冲器(circular buffer).其中systematic
bits 会先插入,然后first parity bits 和second parity bits 交替插入。
不同的RV 意味着从环形缓存器不同起始位置来提取要发送的bit.
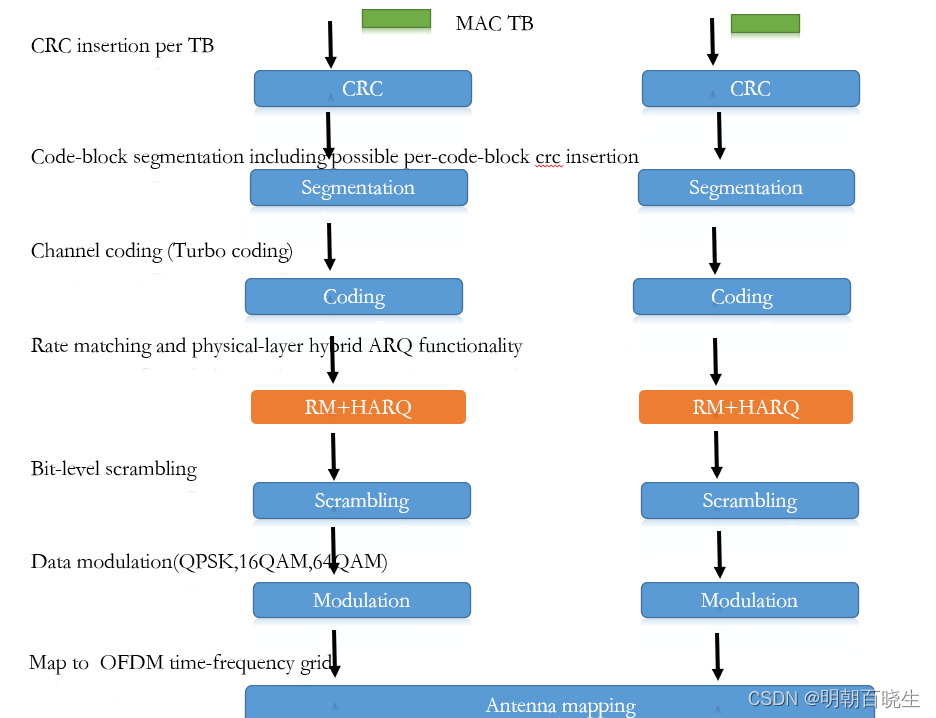
对于DL-SCH 和 UL-SCH 而言,其信道编码采用了Turbo 编码。 Turbo 编码中systematic bit比parity bit 更重要,而初传(initial transmission)中至少要包含所有的systematic bit和部分parity bit;而重传中,会包含初传中没有的pairty bit.
如果第一次传输接收质量很差,或者没收到,这时候只带parity bit的RV不如重传包含全部systematicbit 的RV 来的性能更好。
NACK 要求重传额外的parity bit,
DTX 要求重传systematic bit,基于传输尝试的信号质量来决定包含多个个systematic bit和
parity bit。
CRC 校验是在软合并进行了,HARQ 校验CRC来判断是否出错。
HARQ 功能包含物理层和MAC 层,发送端生成不同的RV(Redundancy version)
选用哪个RV 由MAC层告诉物理层,以及接收端软合并由物理层负责的。物理层需要对接收到
的数据进行软合并和解码处理
三 HARQ Process

HARQ 使用stop-and-wait 来发送数据
缺点:
在停等协议中,发送端发送一个TB后,就停下来等待确认信息。只需要1bit的信息来对该传输块进行肯定ACK 或否则NACK 确认即可。但是每次传输后发送端就停止并等待确认,会导致吞吐量很低。
改进:
LTE使用多个并行的stop-and-wait process;当一个HARQ process 在等待确认信息时,发送端可以使用另一个HARQ process 来发送数据。
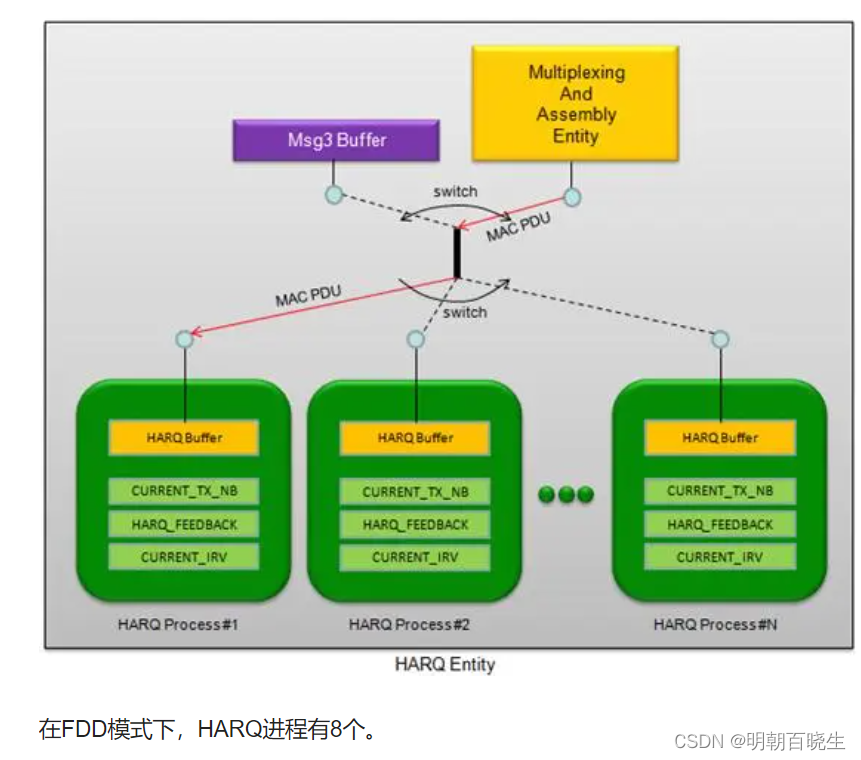
每个HARQ process 一次只处理一个TB(Transport Block,传输块)
每个HARQ process 在接收端都需要有独立的HARQ buffer 以便对接收到的数据进行软合并。
每个UE 都有一个HARQ实体,每个载波单元(Component Carrier)都有各自的HARQ实体.在空分复用中,
一个TTI会并行传输2个TB,此时每个TB都有各自的HARQ确认信息,1个HARQ 实体包含2个HARQ process集合。
使用多个并行的stop-and-wait process 可能导致接收端的MAC层送到RLC层的数据是乱序。
因此RLC层需要对收到的数据进行重新排序。在载波聚合中,RLC层同样需要负责数据的重排序,这是因为
RLC层对载波聚合不可见,而每个载波单元具有独立的HARQ实体,导致RLC层需要从多个HARQ 实体中接收数据,
而接收自多个HARQ实体的数据很可能是乱序的。
当发送端收到ACK|NACK ,需要知道对应的HARQ Process,这是通过确认信息与传输的数据之间固定的timing关系
确认的。
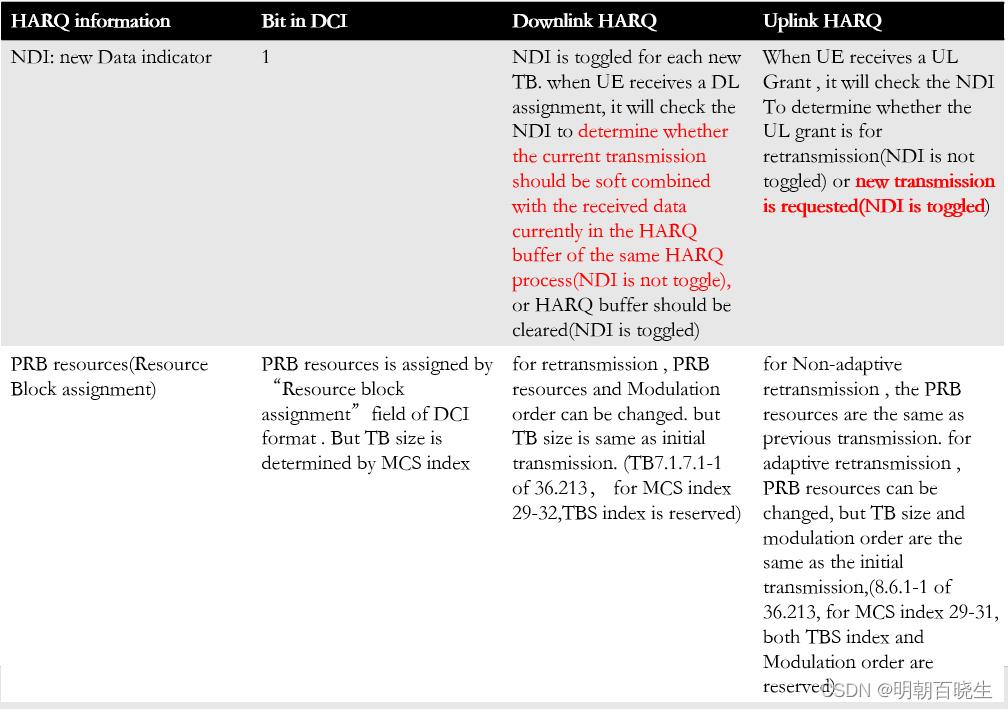
四 HARQ information

注:
1 下行DCI 包括DCI format 1/AA/1B/1D/2A/2B/2C,但不包含DCI format 1C,因为1C 不支持HARQ,上行DCI 包括DCI format 0/4。
2 重传时TB size 是不变的,因此没有必要在重传DCI中指示新的TB size,但必须保证初传的DCI 是正确接收的。
3 TB size 是通过MCS index 指定的,MCS index 有5 bit,但只使用29种组合(0~18)剩余的3种组合(29~31)是预留的,且这种组合只用于重传。
36.213 Table 7.1.7.1-1 用于下行
Table 8.6.1-1 用于上行, MCS index 29~31 TBS index 都是预留的,重传不改变TB size,但是Modulation Order可变。
4 MCS index 在取值范围0~28 和29~31 的不同处理,以及上下行含义不同
五 同步/异步
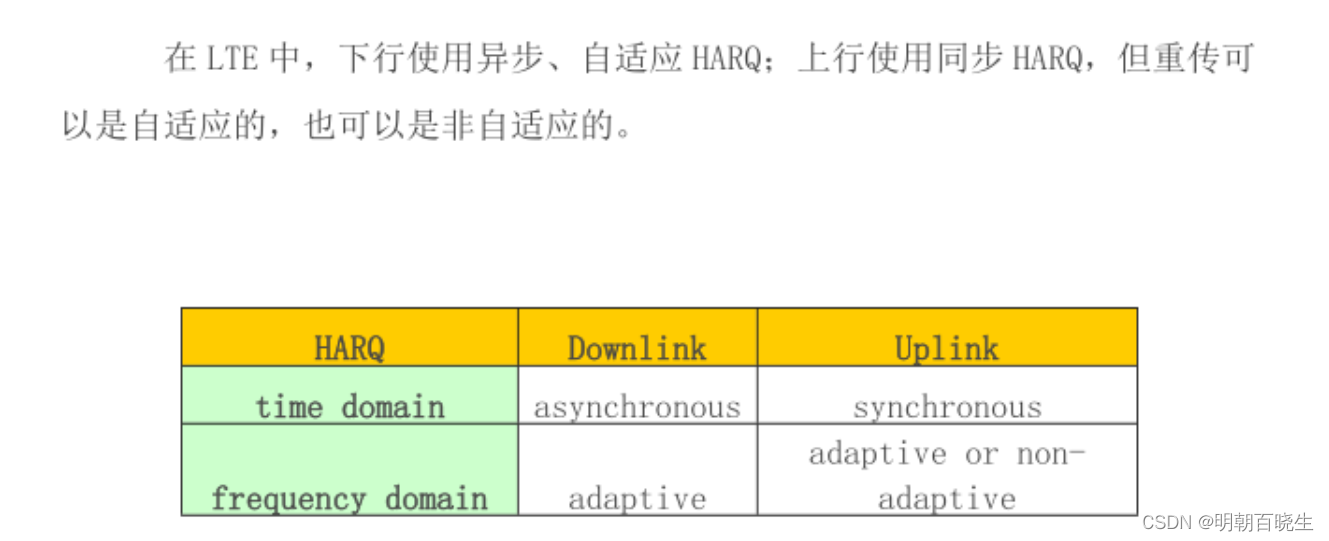
HARQ 协议在时域上分为同步(synchronous)和异步(asynchronous)两类
异步HARQ:(asynchronous)
重传可以发生在任一时刻,也意味着能以任意顺序使用HARQ process.
同步HARQ(synchronous)
只能在前一次传输后固定时刻发送,特定子帧,只能使用特定的HARQ process.
HARQ process 可以从系统帧号/子帧号推导出来
六 adaptive|non-adaptive HARQ
自适应HARQ adaptive
意味着可以改变重传使用的PRB资源以及MCS
非自适应HARQ non-adaptive HARQ
意味着重传必须与前一次传输使用相同的MCS 以及PRB 资源
总结:
HARQ 是一种结合 FEC(Forward Error Correction)与ARQ(Automatic Repeat reQuest)方法的技术Transport Block 经过信道编码(turbo coder)的数据包含三段:
第一段 可以认为基本数据,其余是两段是冗余数据
放入环形缓冲区,通过RV版本指示从这个缓冲区哪个位置读取数据。
NDI 是新数据指示指令。 3GPP LTE 的HARQ 采用了多通道停等机制,最大通道数可达8,合并方法采用chase 和IR.
HARQ 每次重传的传输块斗鱼第一次传输的相同,但是每次重传的调制方式,信道码的集合和传输的功率都可能与第一次
传输时不同,即每次重传时的可用信道比特数可能不同,即使可用信道的比特数相同,在物理信道中传输的信息比特也可能不同。
HARQ 每次重传使用的RV不同,最大有8个不同的RV,这里每个RV对应不同的编码比特子集,每个子集包含不同的比特。
chase 合并对应单一的冗余版本。
发送方在发送数据包的同事设置1比特的新数据指令NDI,每当发送新数据包则NDI 翻转一次,接收方会收到且把接收数据缓存清空。
存储新的数据;重传的时候NDI 保持不变,接收方会把它放到接收缓存中,与之前的版本进行合并译码。
七 Bundling& Multiplexing:
Bundling :(默认配置)
多个DL subframe 的每个codeword 的接收结果通过逻辑与在一个ul subframe用1 bit 反馈. 如果2个codeword 就用2 bit 反馈。bundling
是使用一个ack/nack 完成前面若干个下行数据的TTI反馈,几个ack/nack 进行and 运算,然后用一个ack/nack 来反馈,缺点是eNB不知道哪个子帧被错误接收。
如一个子帧错误,需要重传所有的子帧,所以bundling 不适合下行覆盖首先的情况。目前协议中默认的ack/nack 形式是bundling,协议中引入DAI(in DCI)
指示UE 丢失的情况,若果DAI miss,所有的码字生成NACK.
Multiplexing:
多个DL subframe 的接收结果在一个UL subframe 用多个bit 反馈.每个DL subframe 的多个codeword 通过逻辑与
变成一个bit. Multiplexing 是在一个上行时隙反馈多个ack/nack即对多个下行数据反馈它们每个的ack/nack信息。所有
ack/nack 的信息可以用2bit 来表示,利用对应的PDCCH CCE 信息计算出ack/nack 反馈资源,并用2bit 进行反馈。
- DAI字段 – 2 bits。
这个字段只在LTE-TDD中使用,在FDD中没有这个字段。对于TDD来说,这个DAI字段也只在上下行子帧配置是1~6的时候有效。我们知道,在空口中传输数据是很有可能丢失的,
对于PDSCH或PUSCH来说,可以通过HARQ和ARQ来进行保证,但对于控制信道的DCI来说,是没有握手机制的,因此网侧在发出一次PDCCH之后,并不清楚终端有没有接收到这个DCI信息,或者说终端并不知道自己有没有漏掉DCI。
那么引入这个DAI字段就可以用来判断是否有DCI的丢失,比如终端解码到了同个HARQ进程的2个DCI1A(没有其他的DCI),其中的DAI值分别是1和3,那么终端就可以知道,这个HARQ进程的DAI=2的那个DCI1A没有检测到,
被丢失了。关于DAI的更详细的内容,在后续讲解下行HARQ应答的时候再具体讨论。
————————————————
版权声明:本文为CSDN博主「阿米尔C」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m_052148/article/details/51670920
八 上行HARQ
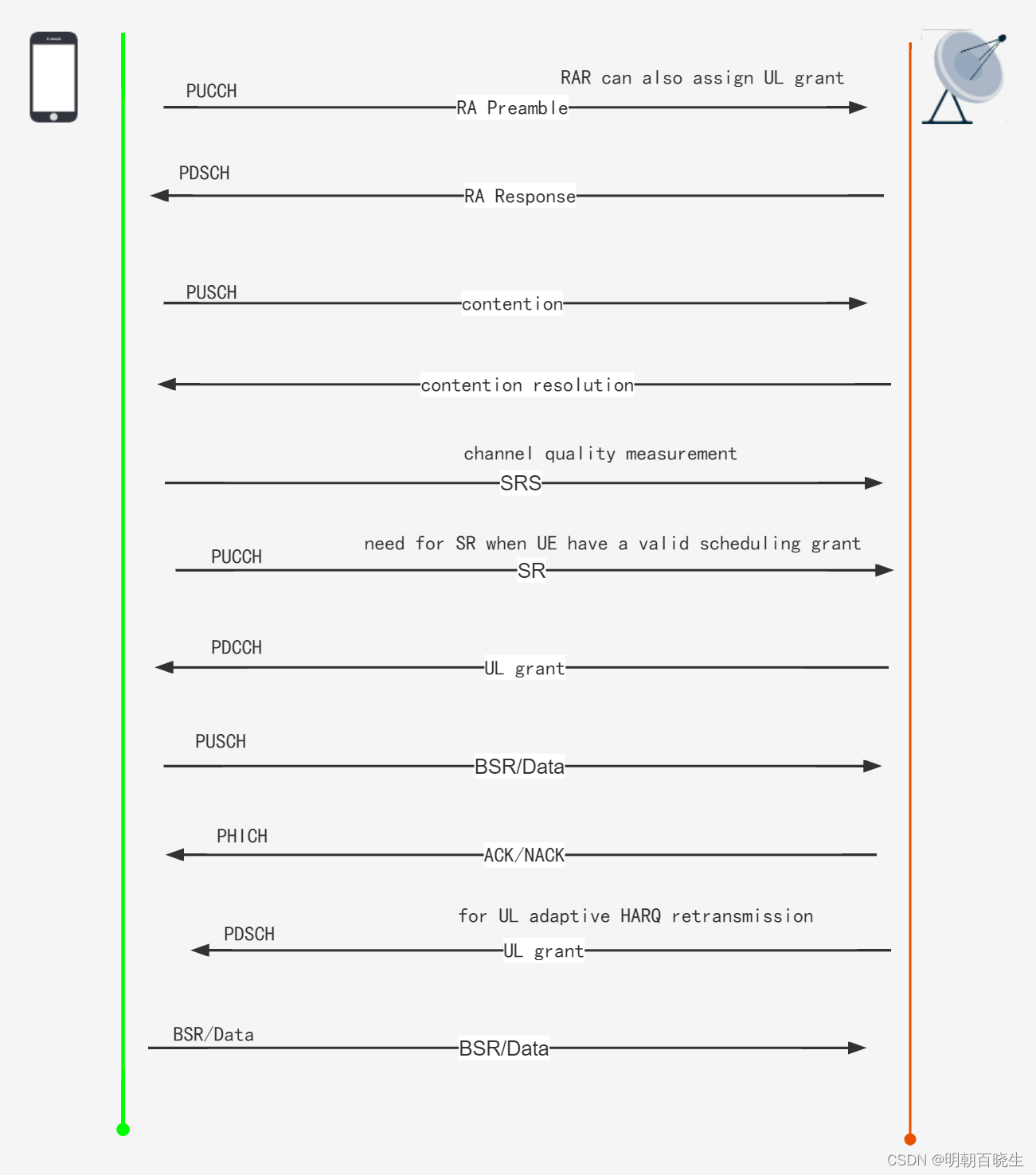
eNodeB 使用PHICH 通知UE 是否接收成功PUSCH,一个上行TB 对应一个PHICH
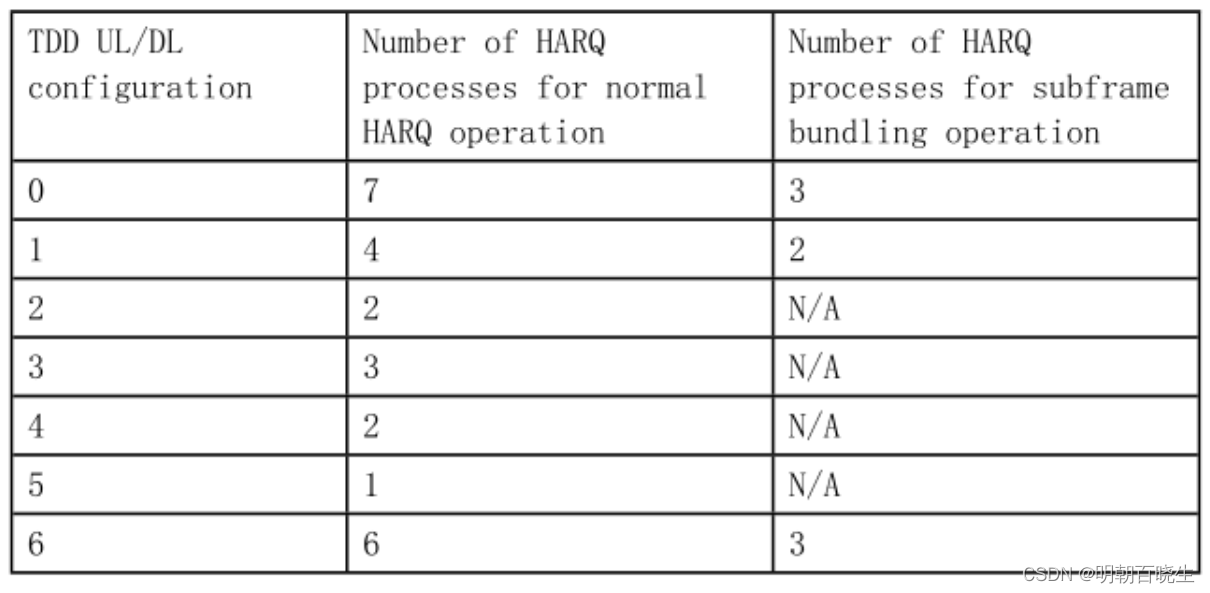
对于FDD 而言,如果上行的传输模式为TM1,则有8个上行的HARQ process; 如果上行传输模式为TM2,则有上行HARQ process 数将翻倍,为16个,此时每个子帧有2个HARQ process.
对于TDD:
如果上行传输模式为TM1,则有不同的TDD 上下行配置对应的上行HARQ process ,
如果上行传输模式为TM2,则上行HARQ process 数将翻倍,此时每个子帧有2个HARQ
process.
上行HARQ 使用同步,非自适应目的为了降低开销。
上行重传总是在可预知的子帧上(FDD ,在前一次传输的8个子帧后)
根据timing 关系可以推导出HARQ Process.
使用自适应重传 是为了避免分割上行频域资源与避免与随机接入的碰撞。
此时eNodeB不仅会发送PHICH,还会发送PDCCH(UL grant)指示重传使用的新的
PRB 资源和MCS
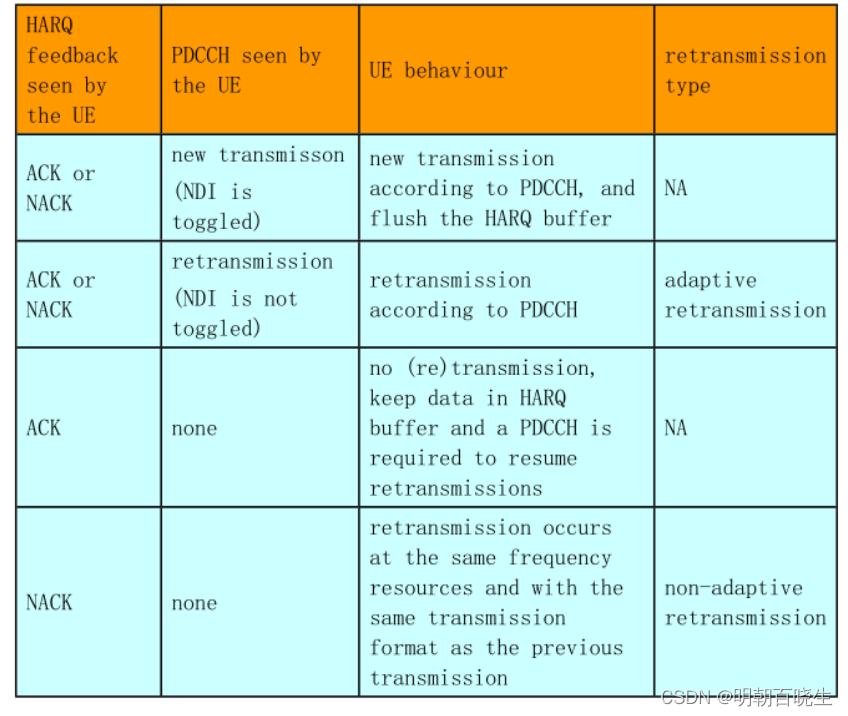
process:
即使收到的PHICH 指示为ACK,也不会清空HARQ 缓冲区。还需要通过当前子帧和后续子帧收到的UL grant中的NDI 来决定是否重传(NDI 无反转)
还是进行新的传输(NDI 反转,清空HARQ缓存区)。也即,是否清空HARQ 缓存区是由UL grant的NDI 来决定的。
假如UE 收到ACK,之后要进行重传,只能进行自适应重传,而不能进行非自适应重传。
2: 给定某个HARQ process,无论收到的PHICH 指示的是ACK 还是NACK,只要同时收到的UL grant ,则UE 会忽略PHICH 而使用UL grant来决定如何进行下一次传输。
3: 如果在某个子帧只收到PHICH(NACK),则使用非自适应重传

最后
以上就是动人手套最近收集整理的关于LTE MAC HARQ--01的全部内容,更多相关LTE内容请搜索靠谱客的其他文章。








发表评论 取消回复