1. 迭代器(iterator)是一中检查容器内元素并遍历元素的数据类型。
(1) 每种容器类型都定义了自己的迭代器类型,如vector:
vector::iterator iter;这条语句定义了一个名为iter的变量,它的数据类型是由vector定义的iterator类型。
(2) 使用迭代器读取vector中的每一个元素:
vector ivec(10,1);
for(vector::iterator iter=ivec.begin();iter!=ivec.end();++iter)
{
*iter=2; //使用 * 访问迭代器所指向的元素
}
const_iterator:
只能读取容器中的元素,而不能修改。
for(vector::const_iterator citer=ivec.begin();citer!=ivec.end();citer++)
{
cout<
//*citer=3; error
}
vector::const_iterator 和 const vector::iterator的区别
const vector::iterator newiter=ivec.begin();
*newiter=11; //可以修改指向容器的元素
//newiter++; //迭代器本身不能被修改
(3) iterator的算术操作:
iterator除了进行++,--操作,可以将iter+n,iter-n赋给一个新的iteraor对象。还可以使用一个iterator减去另外一个iterator.
const vector::iterator newiter=ivec.begin();
vector::iterator newiter2=ivec.end();
cout<
一個很典型使用vector的STL程式:#include
#include
using namespace std;
int main() {
vector ivec;
ivec.push_back(1);
ivec.push_back(2);
ivec.push_back(3);
ivec.push_back(4);
for(vector::iterator iter = ivec.begin();1. iter != ivec.end(); ++iter)
cout << *iter << endl;
}
2. Iterator(迭代器)模式
一、概述
Iterator(迭代器)模式又称Cursor(游标)模式,用于提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。或者这样说可能更容易理解:Iterator模式是运用于聚合对象的一种模式,通过运用该模式,使得我们可以在不知道对象内部表示的情况下,按照一定顺序(由iterator提供的方法)访问聚合对象中的各个元素。
由于Iterator模式的以上特性:与聚合对象耦合,在一定程度上限制了它的广泛运用,一般仅用于底层聚合支持类,如STL的list、vector、stack等容器类及ostream_iterator等扩展iterator。
根据STL中的分类,iterator包括:
Input Iterator:只能单步向前迭代元素,不允许修改由该类迭代器引用的元素。
Output Iterator:该类迭代器和Input Iterator极其相似,也只能单步向前迭代元素,不同的是该类迭代器对元素只有写的权力。
Forward Iterator:该类迭代器可以在一个正确的区间中进行读写操作,它拥有Input Iterator的所有特性,和Output Iterator的部分特性,以及单步向前迭代元素的能力。
Bidirectional Iterator:该类迭代器是在Forward Iterator的基础上提供了单步向后迭代元素的能力。
Random Access Iterator:该类迭代器能完成上面所有迭代器的工作,它自己独有的特性就是可以像指针那样进行算术计算,而不是仅仅只有单步向前或向后迭代。
这五类迭代器的从属关系,如下图所示,其中箭头A→B表示,A是B的强化类型,这也说明了如果一个算法要求B,那么A也可以应用于其中。
input output
/
forward
|
bidirectional
|
random access
图1、五种迭代器之间的关系
vector 和deque提供的是RandomAccessIterator,list提供的是BidirectionalIterator,set和map提供的 iterators是 ForwardIterator,关于STL中iterator迭代器的操作如下:
说明:每种迭代器均可进行包括表中前一种迭代器可进行的操作。
迭代器操作 说明
(1)所有迭代器
p++ 后置自增迭代器
++p 前置自增迭代器
(2)输入迭代器
*p 复引用迭代器,作为右值
p=p1 将一个迭代器赋给另一个迭代器
p==p1 比较迭代器的相等性
p!=p1 比较迭代器的不等性
(3)输出迭代器
*p 复引用迭代器,作为左值
p=p1 将一个迭代器赋给另一个迭代器
(4)正向迭代器
提供输入输出迭代器的所有功能
(5)双向迭代器
--p 前置自减迭代器
p-- 后置自减迭代器
(6)随机迭代器
p+=i 将迭代器递增i位
p-=i 将迭代器递减i位
p+i 在p位加i位后的迭代器
p-i 在p位减i位后的迭代器
p[i] 返回p位元素偏离i位的元素引用
p
p<=p1 p的位置在p1的前面或同一位置时返回true,否则返回false
p>p1 如果迭代器p的位置在p1后,返回true,否则返回false
p>=p1 p的位置在p1的后面或同一位置时返回true,否则返回false
只有顺序容器和关联容器支持迭代器遍历,各容器支持的迭代器的类别如下:
容器 支持的迭代器类别 容器 支持的迭代器类别 容器 支持的迭代器类别
vector 随机访问 deque 随机访问 list 双向
set 双向 multiset 双向 map 双向
multimap 双向 stack 不支持 queue 不支持
priority_queue 不支持
二、结构
Iterator模式的结构如下图所示:
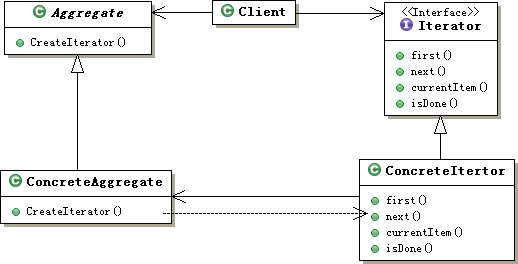
图2、Iterator模式类图示意
三、应用
Iterator模式有三个重要的作用:
1)它支持以不同的方式遍历一个聚合.复杂的聚合可用多种方式进行遍历,如二叉树的遍历,可以采用前序、中序或后序遍历。迭代器模式使得改变遍历算法变得很容易: 仅需用一个不同的迭代器的实例代替原先的实例即可,你也可以自己定义迭代器的子类以支持新的遍历,或者可以在遍历中增加一些逻辑,如有条件的遍历等。
2)迭代器简化了聚合的接口. 有了迭代器的遍历接口,聚合本身就不再需要类似的遍历接口了,这样就简化了聚合的接口。
3)在同一个聚合上可以有多个遍历 每个迭代器保持它自己的遍历状态,因此你可以同时进行多个遍历。
4)此外,Iterator模式可以为遍历不同的聚合结构(需拥有相同的基类)提供一个统一的接口,即支持多态迭代。
简单说来,迭代器模式也是Delegate原则的一个应用,它将对集合进行遍历的功能封装成独立的Iterator,不但简化了集合的接口,也使得修改、增 加遍历方式变得简单。从这一点讲,该模式与Bridge模式、Strategy模式有一定的相似性,但Iterator模式所讨论的问题与集合密切相关, 造成在Iterator在实现上具有一定的特殊性,具体将在示例部分进行讨论。
四、优缺点
正如前面所说,与集合密切相关,限制了 Iterator模式的广泛使用,就个人而言,我不大认同将Iterator作为模式提出的观点,但它又确实符合模式“经常出现的特定问题的解决方案”的 特质,以至于我又不得不承认它是个模式。在一般的底层集合支持类中,我们往往不愿“避轻就重”将集合设计成集合 + Iterator 的形式,而是将遍历的功能直接交由集合完成,以免犯了“过度设计”的诟病,但是,如果我们的集合类确实需要支持多种遍历方式(仅此一点仍不一定需要考虑 Iterator模式,直接交由集合完成往往更方便),或者,为了与系统提供或使用的其它机制,如STL算法,保持一致时,Iterator模式才值得考 虑。
五、举例
可以考虑使用两种方式来实现Iterator模式:内嵌类或者友元类。通常迭代类需访问集合类中的内部数据结构,为此,可在集合类中设置迭代类为friend class,但这不利于添加新的迭代类,因为需要修改集合类,添加friend class语句。也可以在抽象迭代类中定义protected型的存取集合类内部数据的函数,这样迭代子类就可以访问集合类数据了,这种方式比较容易添加新的迭代方式,但这种方式也存在明显的缺点:这些函数只能用于特定聚合类,并且,不可避免造成代码更加复杂。
STL的list::iterator、deque::iterator、rbtree::iterator等采用的都是外部Iterator类的形式,虽然STL的集合类的iterator分散在各个集合类中,但由于各Iterator类具有相同的基类,保持了相同的对外的接口(包括一些traits及tags等,感兴趣者请认真阅读参考1、2),从而使得它们看起来仍然像一个整体,同时也使得应用algorithm成为可能。我们如果要扩展STL的iterator,也需要注意这一点,否则,我们扩展的iterator将可能无法应用于各algorithm。
以下是一个遍历二叉树的Iterator的例子,为了方便支持多种遍历方式,并便于遍历方式的扩展,其中还使用了Strategy模式(见笔记21):
(注:1、虽然下面这个示例是本系列所有示例中花费我时间最多的一个,但我不得不承认,它非常不完善,感兴趣的朋友,可以考虑参考下面的参考材料将其补充完善,或提出宝贵改进意见。2、 我本想考虑将其封装成与STL风格一致的形式,使得我们遍历二叉树必须通过Iterator来进行,但由于二叉树在结构上较线性存储结构复杂,使访问必须 通过Iterator来进行,但这不可避免使得BinaryTree的访问变得异常麻烦,在具体应用中还需要认真考虑。3、以下只提供了Inorder遍历iterator的实现。)
最后
以上就是魔幻荷花最近收集整理的关于mysql leave iterator_c++迭代器(iterator)详解的全部内容,更多相关mysql内容请搜索靠谱客的其他文章。








发表评论 取消回复