在上一篇博客中我们自己实现了k近邻算法和学习 scikit-learn 中 kNN 的使用,虽然我们自己实现了一个 kNN 算法,可是这个算法到底它的效果怎样?预测的准确率高不高?我们应该怎样判断?
判断机器学习算法的性能
我们再回顾一下机器学习算法,首先我们得有原始数据作为训练数据,然后使用训练数据训练出一个模型,具体在我们的 kNN 算法中表现为每当来了一个新的数据,这个新的数据都要求出和我们的训练数据中的每个数据之间的距离,之后找出前 k 小的那些距离,然后投票来看我们这些新的数据具体属于哪种类别。换句话说,我们是使用全部的训练数据所得到的这个模型用来预测新的数据所属的类型,但是我们需要注意,我们得到的这个模型的意义在于我们要在真实的环境中使用。可是,我们现在这样做还存在很大的问题。
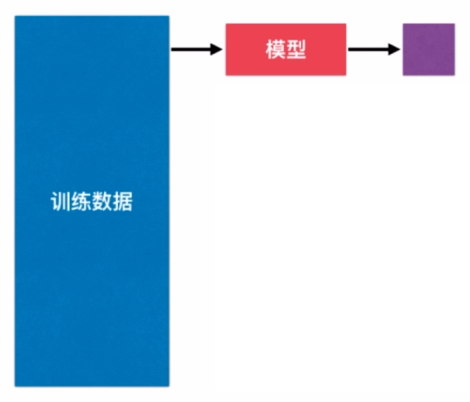
首先的问题是我们将所有的原始数据作为训练数据所得到的模型,我们就只能拿这个模型直接放到真实的环境中去使用,可是如果我们得到的这个模型很差怎么办?我们根本就没有机会去调整它,那就不能真实的去使用它了。举个栗子,比如说我们现在要预测股市的这样一个模型,使用这种方式我们根本没有机会去调整我们的模型,就只能把这个模型投入到真实的股市环境中,可是模型很差的话,就会造成真实的损失。
另外一个问题是在很多真实的场景中,很难拿到预测数据真实的 label,所以在这种情况下我们根本无从得知我们的模型是好是坏。我们训练出这个模型之后,似乎只能听天由命地让它使用在真实环境中。比如,银行发放信用卡,每个用户在银行的信用评级很可能是银行跟踪这个用户跟踪了两三年的时间所得出的客户的信用等级形成的训练数据集,供我们来生成一个预测给其他用户发送信用卡是否有风险这样一种模型,但是这个模型训练出来之后,我们直接投入到银行中使用,来了一个新的客户,那这个新的客户的信用等级到底是怎样的?可能又要经过两三年的时间才可以得到相应的信用等级,换句话说,即使有了新的数据,我们在短时间内拿不到真实的 label,即真实的分类是怎样的?我们也很难去改进这样的模型。
其实,就是想说明一点,我们用全部的原始数据作为训练数据来直接形成的一个模型投入到生产环境中这样的做法是不恰当的。那么,改进这个问题的最简单的方法被称之为是训练和测试数据集的分离。意思是我们不要将所有的原始数据都作为训练数据集,我们从原始数据集中抽出一部分作为训练数据集,剩下一部分作为测试数据集,那么我们只用训练数据集训练出一个模型,测试数据不参与训练过程。在得出一个模型之后,我们把测试数据扔进这个模型,来让这个模型预测,因为我们的测试数据中包含了真实的 label 值,我们就很容易可以看到使用训练数据训练出来的这个模型它的性能是怎样的?因此,我们就可以通过这个测试数据直接判断模型的好坏,我们就可以在模型进入真实环境前改进模型。
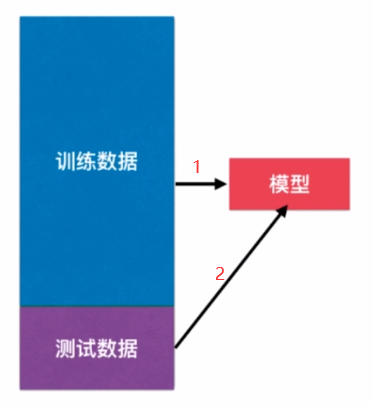
那么这样的一种方式被称为是 train test split,即训练数据集和测试数据集的一个切分。其实,这样的方式在判断机器学习算法的性能过程中也存在它的问题。至于什么问题我们在之后再提。
测试
下面我们开始测试我们的算法。还是用鸢尾花作为例子。
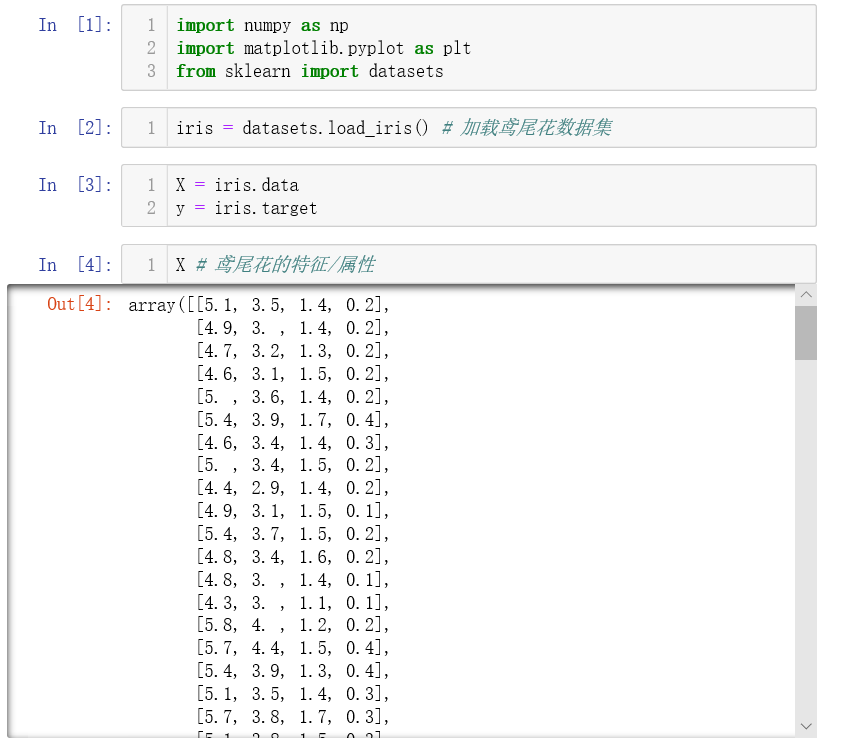
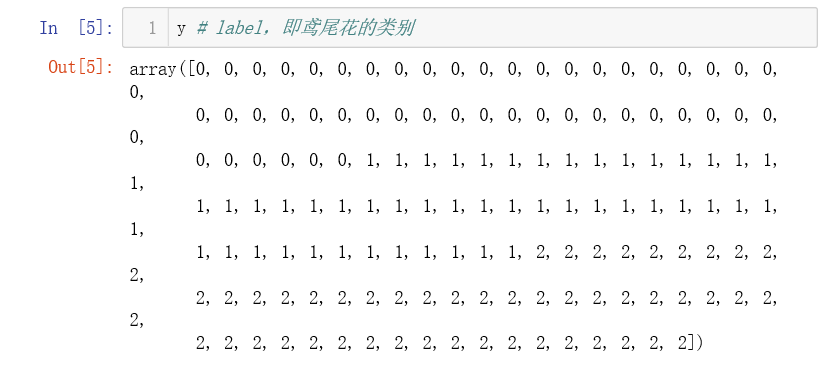
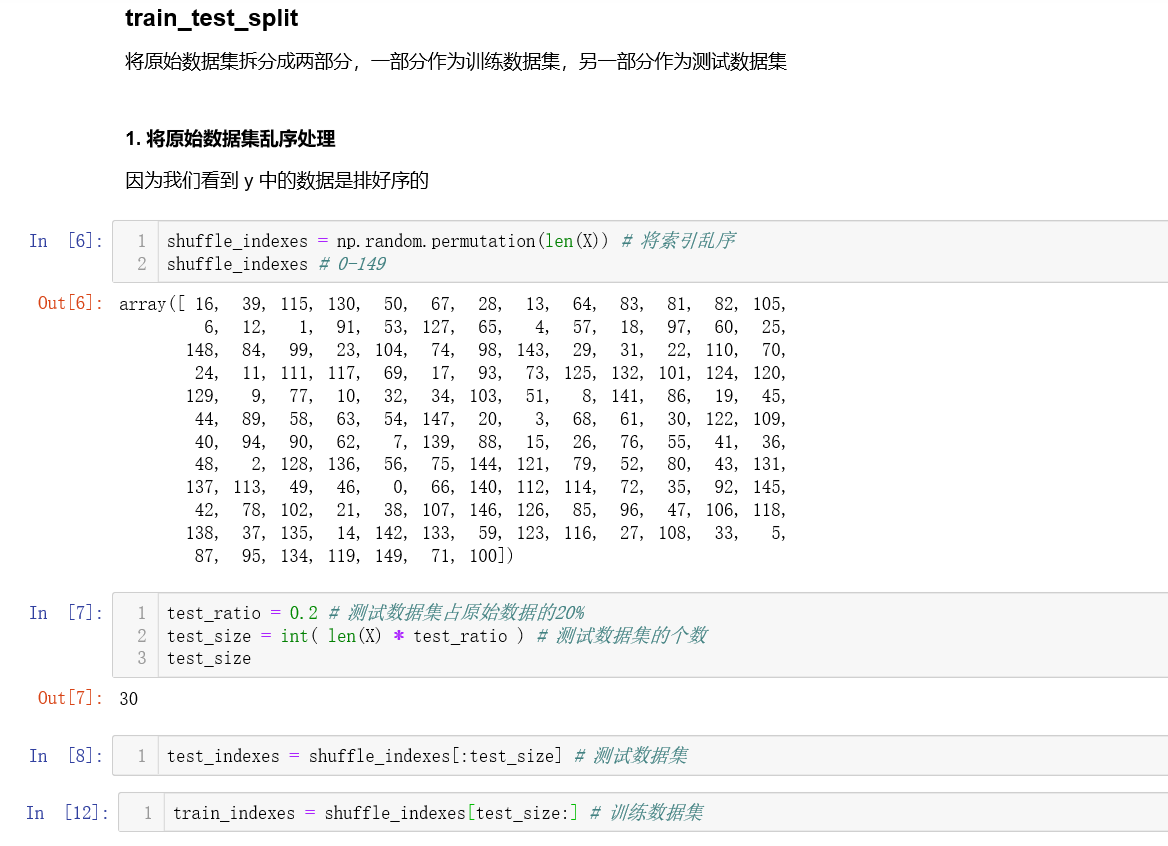
X 中存放的就是原始数据,现在我们需要将原始数据分为训练数据集和测试数据集。我们称这个过程为
train_test_split。
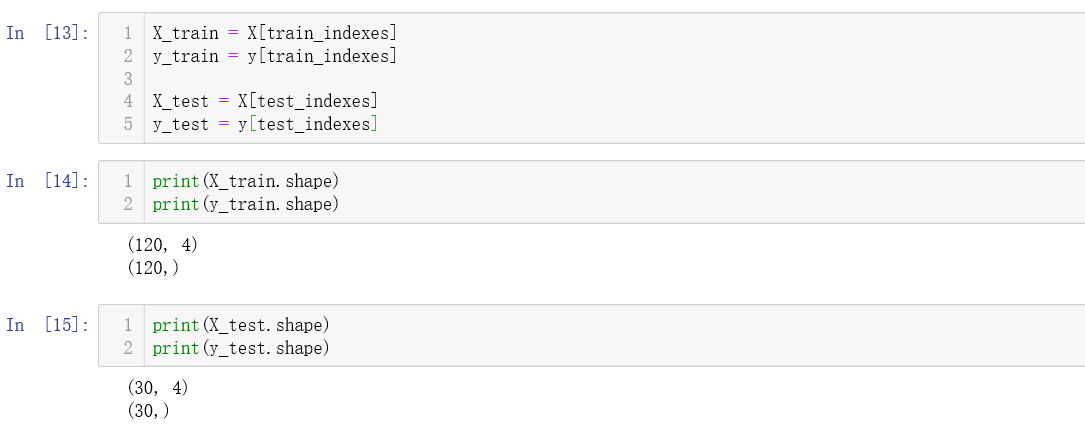
接下来我们将上面的 train_test_split 封装成一个 train_test_split 函数。
# train_test_split.py
import numpy as np
# X:原始数据集
# y:原始数据集的 label
# test_ratio:测试数据集占原始数据集的比例
# seed:随机种子
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""将数据X和y按照test_ratio分割成X_train, X_test, y_train, y_test"""
assert X.shape[0] == y.shape[0],
"the size if must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0,
"test_ratio must be valid"
if seed:
np.random.seed(seed)
shuffled_indexes = np.random.permutation(len(X))
test_size = int(len(X) * test_ratio) # 测试数据集大小
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
X_train = X[train_indexes] # 训练数据集
y_train = y[train_indexes]
X_test = X[test_indexes] # 测试数据集
y_test= y[test_indexes]
return X_train, X_test, y_train, y_test
下面我们使用我们的算法
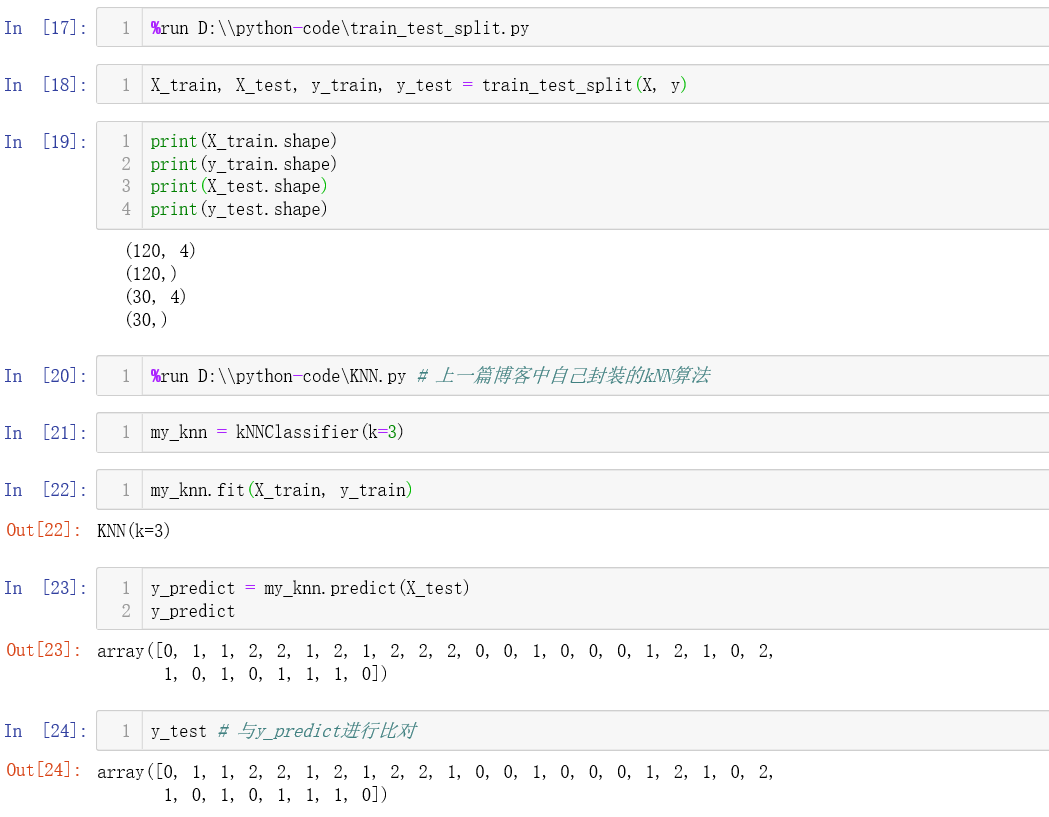

可以看见我们预测的正确率约为97%左右。
下面我们将使用 sklearn 中的 train_test_split 来对鸢尾花的数据进行预测。
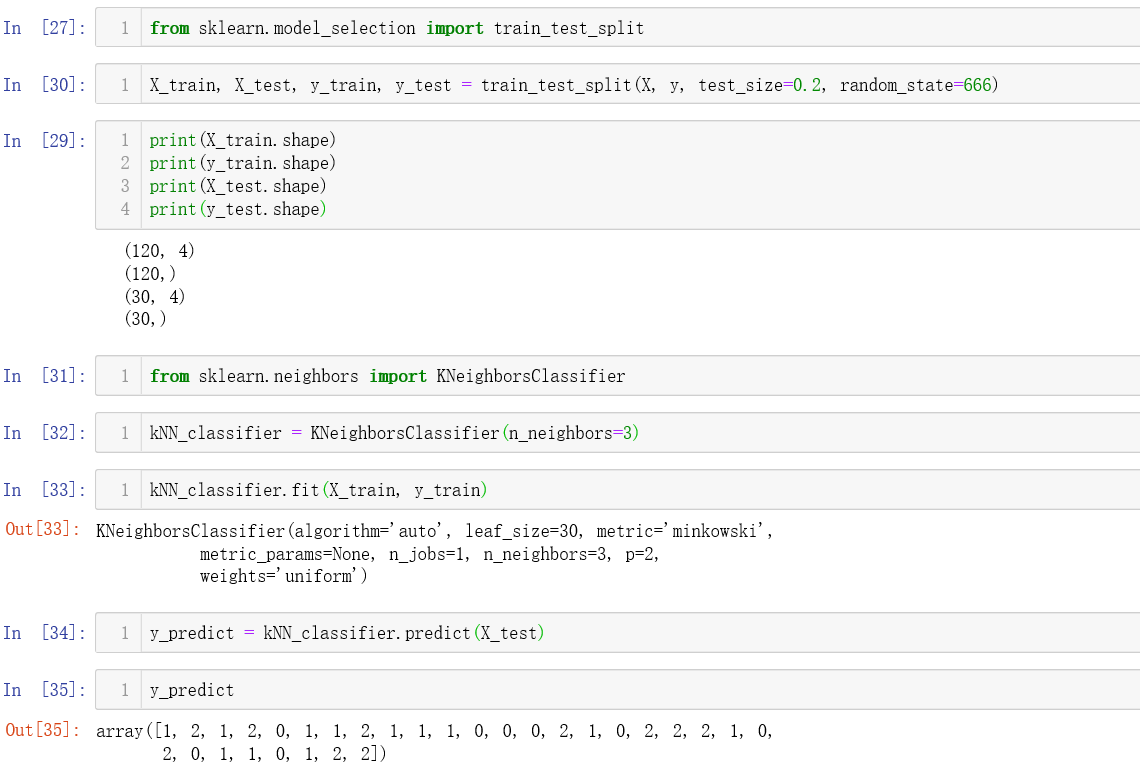

我们使用 sklearn 进行预测的准确率为 100%。
具体代码见Machine-Learning
最后
以上就是谦让哈密瓜最近收集整理的关于02-判断机器学习算法的性能的全部内容,更多相关02-判断机器学习算法内容请搜索靠谱客的其他文章。








发表评论 取消回复