本文首发公众号:架构精进,请移步,排版比较清晰。
经常有同学在 LeetCode 的题解中问解法的复杂度是多少。作为一个懒人,我一直在「逃避」这个问题,毕竟这东西听起来就这么「复杂」。
但本着对题解认真负责的态度(心虚),我想趁此机会做一个总结。下面我将通过一些较为经典的算法题聊一聊几种常见的时间复杂度。
什么是时间复杂度?
算法的时间复杂度(Time complexity)是一个函数,用于定性描述算法的运行时间。
提出时间复杂度的目的是:分析与比较完成同一个任务而设计的不同算法。
分析算法的结果意味着算法需要的资源,虽然有时我们关心像内存,通信带宽或者计算机硬件这类资源,但是通常我们想要度量的是计算时间。一般来说,通过分析求解某个问题的几种候选算法,我们可以选出一种最有效的算法。这种分析可能指出不止一个可行的候选算法,但是在这个过程中,我们往往可以抛弃几个较差的算法。 ——《算法导论》
大 O 符号
时间复杂度通常用 大 O 符号(Big O notation)表示。大 O 符号 又被称为渐近符号,是用于描述函数 渐近行为。
举个例子,假设我们解决一个规模为 n 的问题要花费的时间为 T(n)T(n):
T(n)=4n2−2n+2T(n)=4n2−2n+2
当 n 不断增大时,n2n2 开始占据主导地位,而其他各项可以被忽略,写作 T(n)=O(n2)T(n)=O(n2)。因此时间复杂度可被称为是 渐近 的。
常见复杂度比较
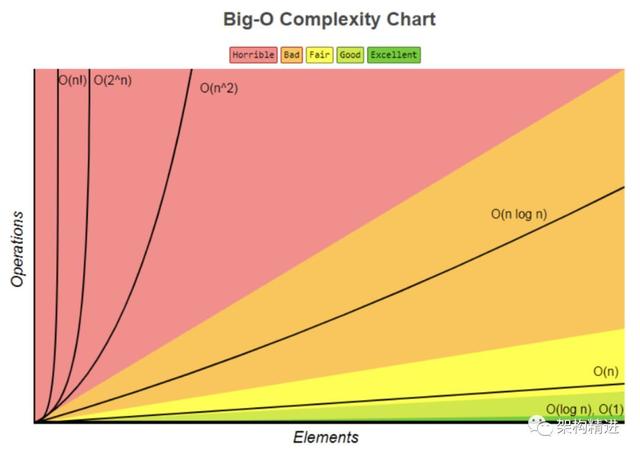
常见时间复杂度比较
常数时间
若算法 T(n)T(n) 的上界与输入大小无关,则称它具有常数时间,记作 T(n)=O(1)T(n)=O(1)。
常见的例子有:
- 访问数组中的单个元素
- 哈希表
别被循环所迷惑
例如这道题 有效的数独,需要在 9x9 的格子中判断数独是否有效。
思路:把行、列和小正方形区域出现的数字用哈希表记录下来,在遍历过程中只要判断数字是否在这三个范围出现过就行了,如果出现过就返回 False。
题解如下:

我们可以看到,虽然题解中用到了如下循环:

但由于复杂度始终是 O(9×9)O(9×9),加上使用哈希表来判断元素是否存在,所以算法的复杂度始为 O(1)O(1)。
对数时间
若 T(n)=O(logn)T(n)=O(logn),则称其具有对数时间。
常见例子:
- 二叉树相关操作
- 二分查找
为什么是 logn?
什么是对数?
首先,我们复习一下 对数。
对数 是幂运算的逆运算。假如 x=βyx=βy,那么就有 y=logβxy=logβx。其中:
- ββ 是对数的底(基底)
- yy 就是 xx(对于底数 ββ)的对数
那我们说一个算法的复杂度是 O(logn)O(logn),那么 lognlogn 这个对数的底数去哪了?
换底公式
二分查找

线性时间
如果一个算法的时间复杂度为 O(n)O(n),则称这个算法具有线性时间。随着样本数量的增加,复杂度也随之线性增加。常表现为单层循环。
来看一到例题 求众数。这里我们用了摩尔投票法,时间复杂度为 O(n)O(n)。

线性对数(准线性)时间
若算法复杂度为 T(n)=O(nlogn)T(n)=O(nlogn),则称这个算法具有线性对数时间。可以理解为执行了 n 次对数时间复杂度的操作。
有几种排序算法的平均时间复杂度都是线性对数时间,例如:
- 堆排序:前 K 个高频元素
- 快速排序:颜色分类
- 归并排序
二次时间
若算法复杂度为 T(n)=O(n2)T(n)=O(n2),则称这个算法具有二次时间,即时间复杂度随着样本数量的增加呈平方数增长。常表现为双层循环。
常见的算法中有一写比较慢的排序算法,例如:
- 冒泡排序
- 选择排序
- 插入排序
由于涉及的排序算法很多,若一一讲解的话就偏离这篇文章的侧重点了。如果大家对各类算法感兴趣可以参考:维基百科:排序算法。
算法是生活中的大智慧,而我们都是智慧的受益者。
最后
以上就是朴实砖头最近收集整理的关于a*算法的时间复杂度_从经典算法题看时间复杂度什么是时间复杂度?大 O 符号常见复杂度比较常数时间别被循环所迷惑对数时间为什么是 logn?什么是对数?换底公式二分查找线性时间线性对数(准线性)时间二次时间的全部内容,更多相关a*算法的时间复杂度_从经典算法题看时间复杂度什么是时间复杂度?大内容请搜索靠谱客的其他文章。








发表评论 取消回复