我是靠谱客的博主 拉长楼房,这篇文章主要介绍利用Python进行数据分析笔记(伪随机数生成)在一个python群里问,发现了问题所在,魔法函数是jupyter中特有的,下面是在jupyter中的运行结果,现在分享给大家,希望可以做个参考。
- numpy.random模块填补了Python内建的random模块的不足,可以高效地生成多种概率分布下的完整样本值数组。例如,你可以使用normal来获得一个4乘4的正态分布样本数组:
>>> samples = np.random.normal(size=(4,4))
>>> samples
array([[-0.80347107, -0.84369142, 0.48835029, 0.51271581],
[ 1.04732259, -0.78429468, 1.07085205, 0.90188037],
[ 0.19654328, 0.43923879, 0.09903612, 0.40265497],
[-1.31220159, 1.72759429, 1.64704394, 0.74199871]])
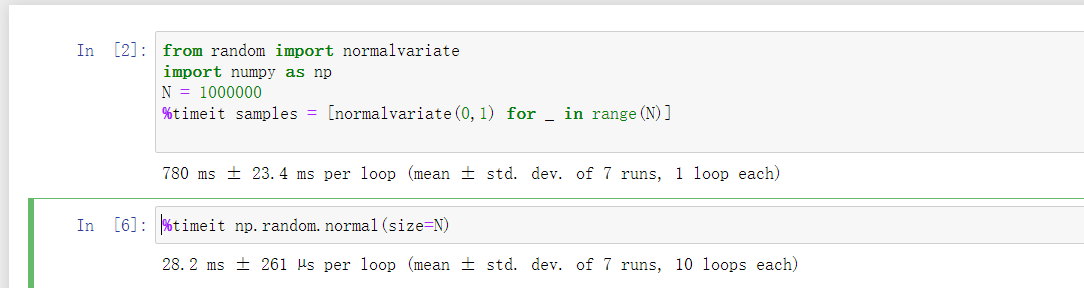
- 然而Python内建的random模块一次只能生成一个值。你可以从下面的示例中看到,numpy.random在生成大型样本时比纯Python的方式快了一个数量级:
>>> from random import normalvariate
>>> N = 1000000
>>> %timeit samples = [normalvariate(0,1) for _in range(N)]
File "<stdin>", line 1
%timeit samples = [normalvariate(0,1) for _in range(N)]
^
SyntaxError: invalid syntax
在一个python群里问,发现了问题所在,魔法函数是jupyter中特有的,下面是在jupyter中的运行结果
- 我们可以称这些为伪随机数,因为它们是由具有确定性行为的算法根据随机数生成器中的随机数种子生成的。你可以通过np.random.seed更改NumPy的随机数种子:
>>> np.random.seed(1234)
- numpy.random中的数据生成函数公用了一个全局的随机种子。为了避免全局状态,你可以使用numpy.random.RandomState生成一个随机数生成器,使数据独立于其他的随机数状态:
>>> rng = np.random.RandomState(1234)
>>> rng.randn(10)
array([ 0.47143516, -1.19097569, 1.43270697, -0.3126519 , -0.72058873,
0.88716294, 0.85958841, -0.6365235 , 0.01569637, -2.24268495])
- 下表示numpy.random中可用的部分函数。我将在下一节中借助这些函数来一次性生成大型样本数组。

最后
以上就是拉长楼房最近收集整理的关于利用Python进行数据分析笔记(伪随机数生成)在一个python群里问,发现了问题所在,魔法函数是jupyter中特有的,下面是在jupyter中的运行结果的全部内容,更多相关利用Python进行数据分析笔记(伪随机数生成)在一个python群里问,发现了问题所在,魔法函数是jupyter中特有内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复