一直想系统的学习一下,于是跟着前言 – 床长人工智能教程这个老师学习,也就是床长人工智能教程 - 前言_人工智能AI技术的博客-CSDN博客_床长人工智能教程这个老师。刚刚交完666的入会费。
 这是我这几年里第一次花这么贵买课程,希望物有所值。
这是我这几年里第一次花这么贵买课程,希望物有所值。
使用jupyter notebook的print没问题如下:

第一个实例
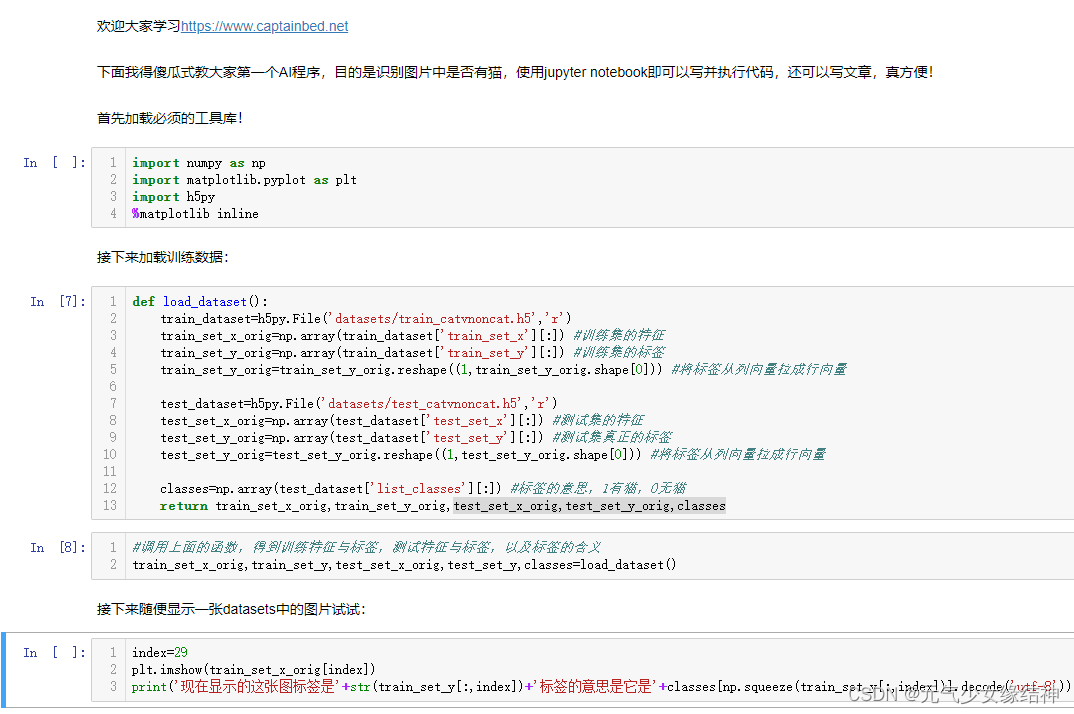
1.2.9小节的推导蛮清晰明了,适合初学者理解。对于1.2节的【实战编程】我觉得:
A,这个页面或第一个AI代码注释里,稍微提下为什么有的用[],有的却是{},不然敲的时候会疑惑;
B,jupyter notebook下定义函数比如load_dataset()下面的对齐不能按Tab,只能敲4个空格?如果直接从老师的代码复制过去,又可以按Tab?
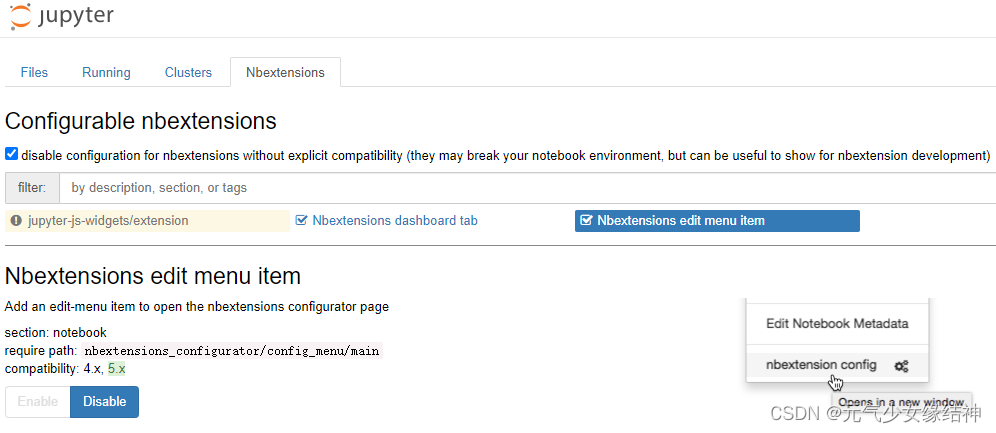
C,jupyter notebook虽然又能码代码又能写文章,但无法像spyder下对库下的方法自动加载,写函数的首字母这个函数就可以直接显示。jupyter notebook必须把函数名敲全,这不太方便。更新:按Jupyter Notebook 代码自动补全功能设置 - 知乎 按这个教程操作即可实现补全函数。但我的没有Hinterland这一项,我的是将下面选中的这个disable就可以了,然后重启后即可按tab键补全函数:
D,jupyter notebook好像没有对书写自动纠错,比如使用变量名时敲错了,没有提示?
E,不能断点调试,也不在编辑时给出语法错误。
然后自己整个敲下来的确好累,但敲的过程中理解了很多,对之前的教程进一步巩固。
这个程序运行时出现:
运行"execution_count":null,时报错:NameError: name 'null' is not defined 为什么我安装的是和老师一样的版本Anaconda3-5.1.0,还会报这个错。然后我将null换成了None,再点击Run,出现下图结果。这是没问题了吗?这个输出就是把上面红色编辑内容打印一遍一样?也再没任何报错。可是这不应该啊
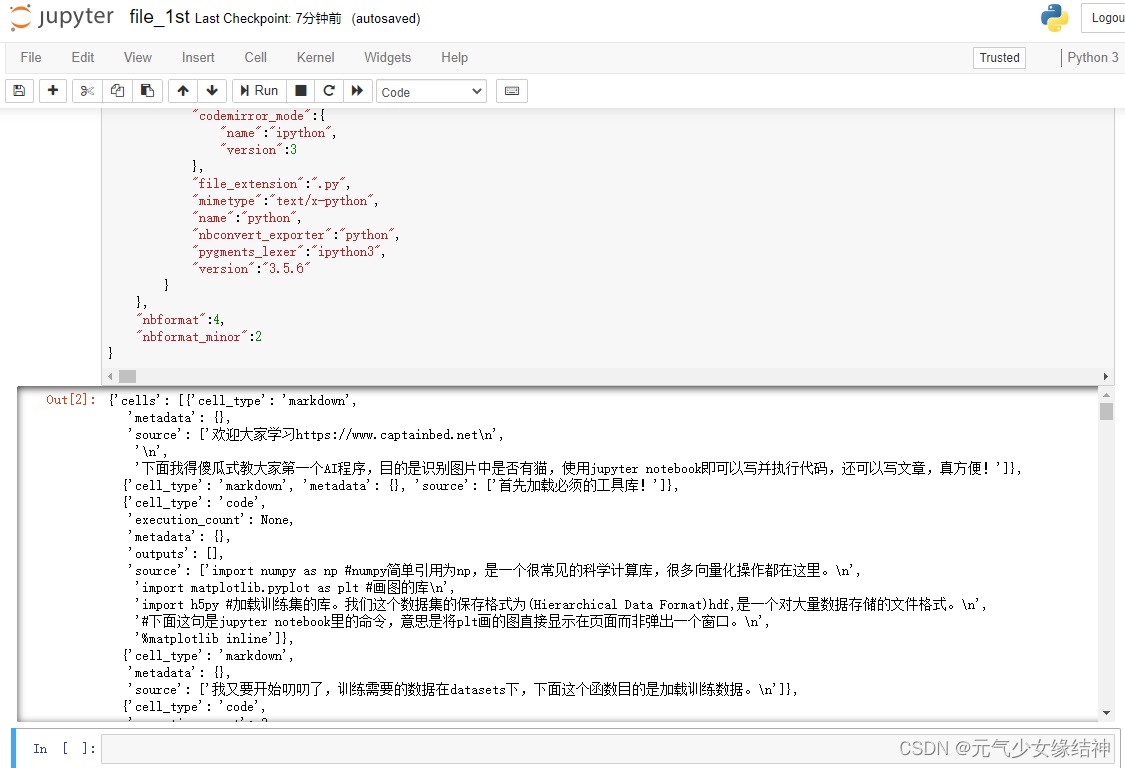 摸索很久终于迂回解决,如下第一个图所示,将老师的程序直接放入目录(我的路径是在C盘下),可以看到我将datasets和images文件夹也拷贝到了路径下,所以下面同步显示,至于下面的三个程序file_0前面是黑色表示我没打开,另外两个是绿色,表示处于打开状态。再看中间这个图就是我一个个字母敲的但运行没任何报错可就是不正确。再看右图是老师的工程,直接打开就看到这才是正常的样子,而且老师的工程运行也正常如第四个图所示:
摸索很久终于迂回解决,如下第一个图所示,将老师的程序直接放入目录(我的路径是在C盘下),可以看到我将datasets和images文件夹也拷贝到了路径下,所以下面同步显示,至于下面的三个程序file_0前面是黑色表示我没打开,另外两个是绿色,表示处于打开状态。再看中间这个图就是我一个个字母敲的但运行没任何报错可就是不正确。再看右图是老师的工程,直接打开就看到这才是正常的样子,而且老师的工程运行也正常如第四个图所示:
上面我吐槽过,老师鼓励自己敲没错,但像第一次接触jupyter有很多不习惯不方便的地方,敲得很累。所以我觉得应该自己敲代码部分即可,而不应该把时间浪费在多了一个冒号啊、括号没对齐啊少了一个啊等上面。所以我接下来如此做:看每个In[ ]之间编辑的内容是自动分段的,所以我不用再手动n,也不需要" ",像我这样编辑好:

然后为每个In[ ]设置cell-cell type-markdown即如下所示In[]消失,意思是这是文本,不是代码区:
接着Run cells and insert below就会如下,已经变成真正的文本。这样相当于边敲边运行,可以根据运行提示知道刚刚敲的是否有问题:
 所以老师的程序中下面这么多内容就可以直接只敲上面的三句话即可,而不用担心标点符号少或错或没对齐,甚至我们觉得啰嗦废话的地方可以直接复制(代码部分不建议这样,文本部分可以这样为我们节约时间):
所以老师的程序中下面这么多内容就可以直接只敲上面的三句话即可,而不用担心标点符号少或错或没对齐,甚至我们觉得啰嗦废话的地方可以直接复制(代码部分不建议这样,文本部分可以这样为我们节约时间):
 当然如果是代码部分,也只用将cell type改成code即可。如下图所示,将python代码部分改成type为code,然后Run cells and insert below可以看到右图运行出了结果:
当然如果是代码部分,也只用将cell type改成code即可。如下图所示,将python代码部分改成type为code,然后Run cells and insert below可以看到右图运行出了结果:
看到此为止我只敲了27行,但老师的原工程其实要敲到116行,学习效率快很多还可以边敲边运行。
 个人觉得这样可读性、整体性更强。
个人觉得这样可读性、整体性更强。
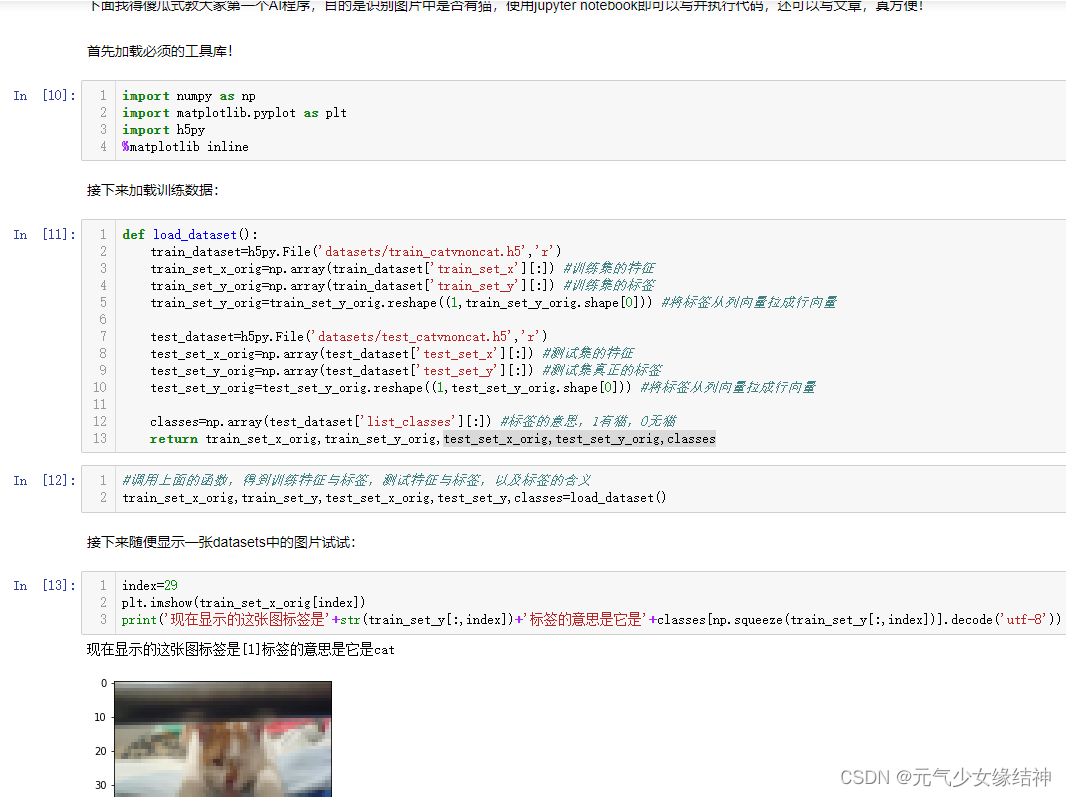
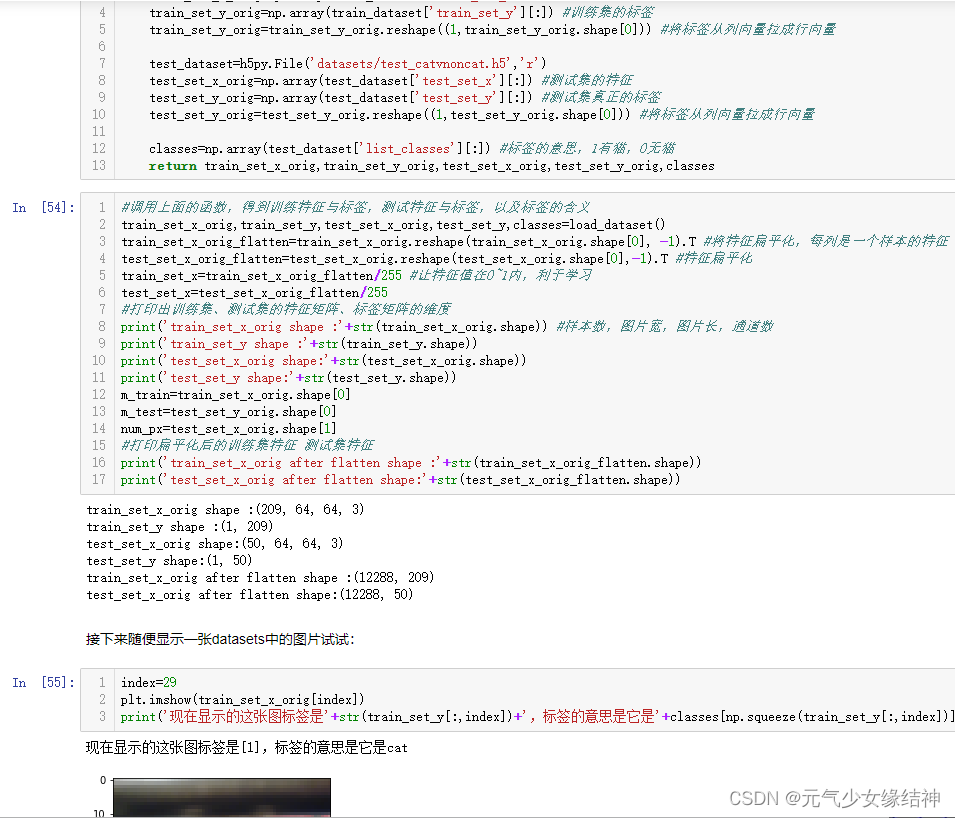
下面这部分我稍微改了点,因为老师的图片中有中文,不方便,我重新改了名如左图所示,然后运行后就是中间的图这样。 使用这种方式学习变得很快乐,效率提高而且兴趣加强很多,看右图是运行完的结果。我是半参考老师的半自己写的,因为根据老师之前的课程完全是可以做到的,而且越到后面越顺手。
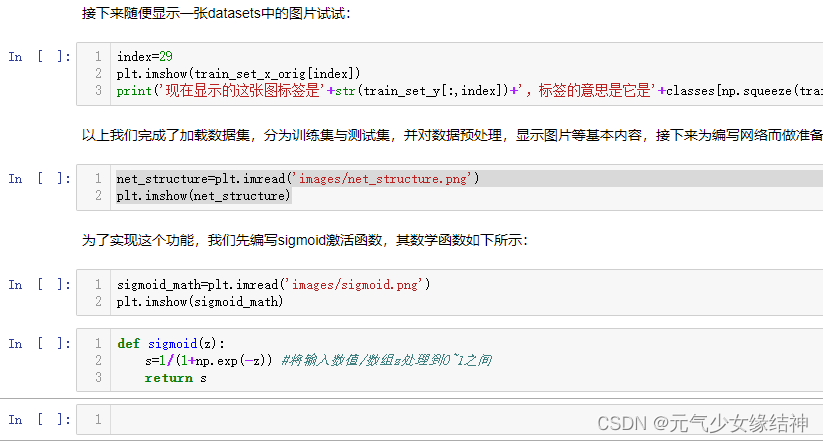
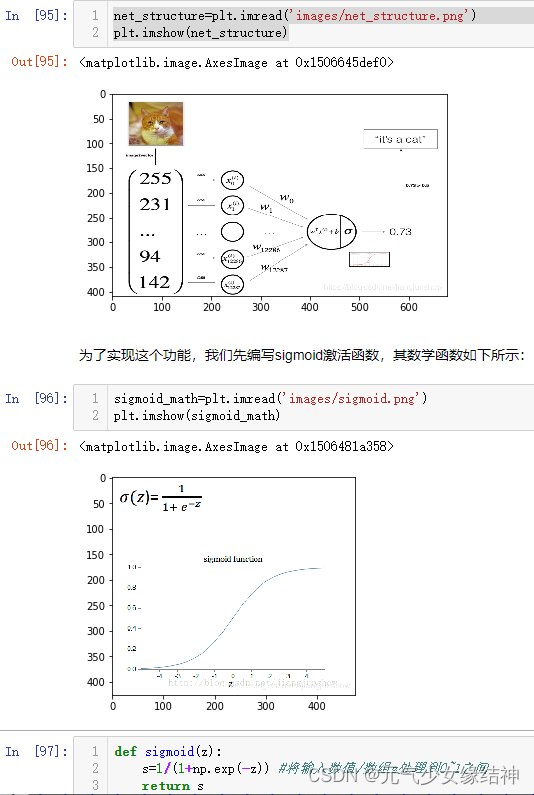
我看老师习惯性写成每列代表一个样本的所有特征,然后用转置去控制后续的维度匹配,而我习惯每行是一个样本的全部特征,所以我全部改成了习惯的写法,当然结果都相同。
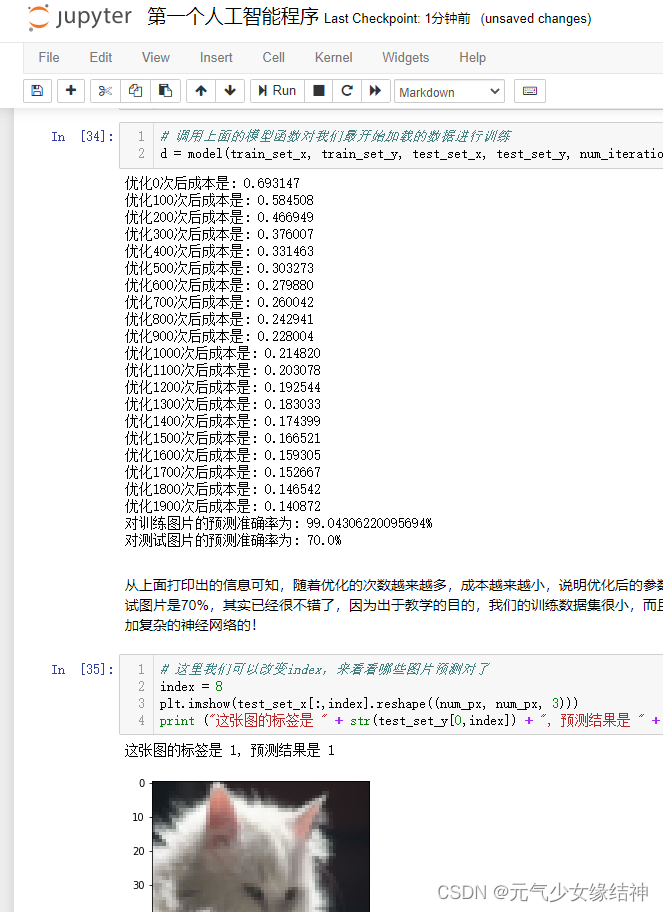
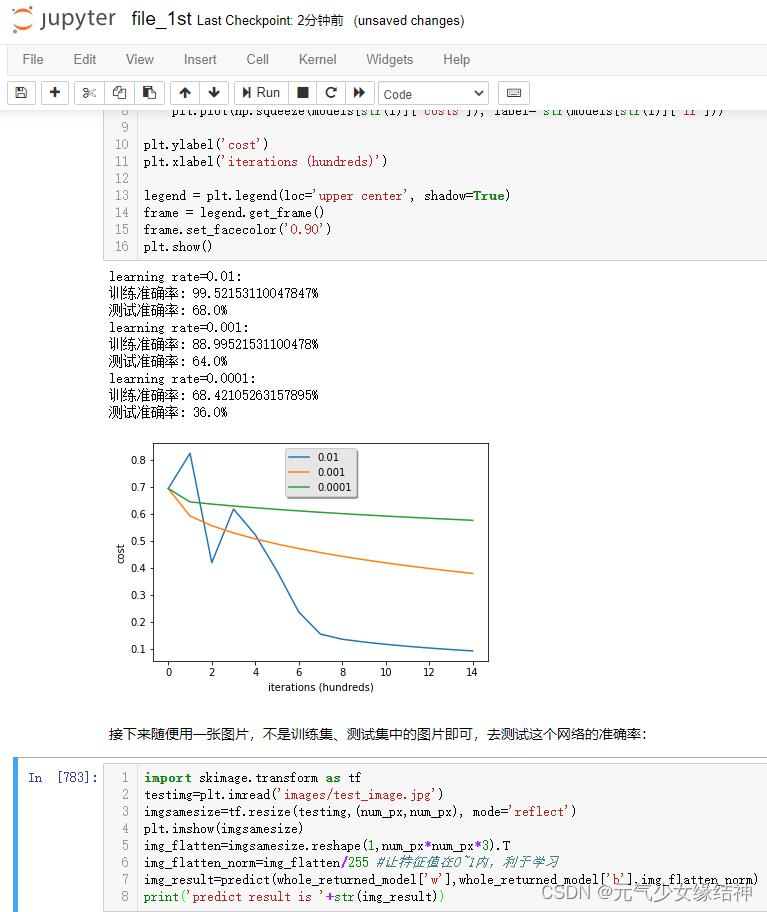
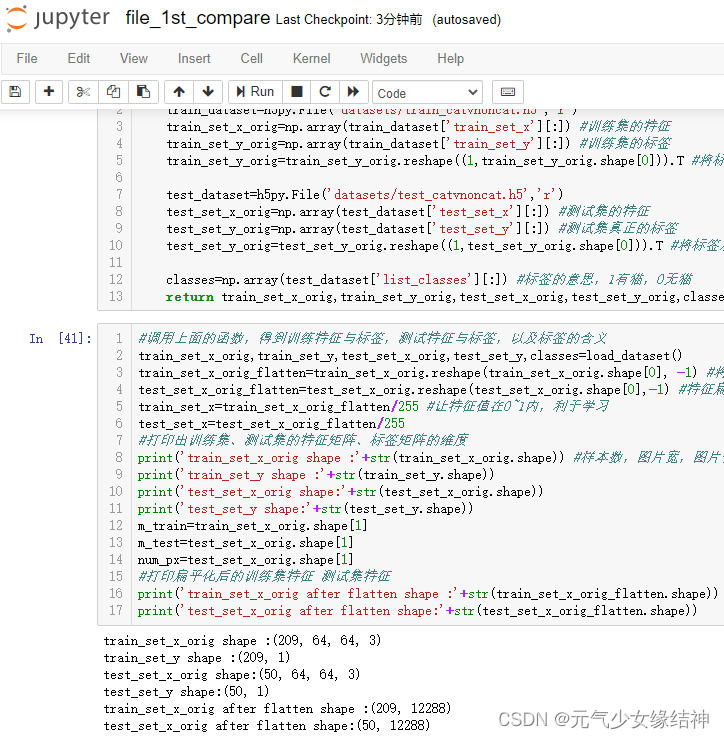 至此第一个实例已完成。这是最简单的1个神经元的模型,才209个样本,每个样本12288个特征,就有这么好的效果了,真切感受到AI的魅力。
至此第一个实例已完成。这是最简单的1个神经元的模型,才209个样本,每个样本12288个特征,就有这么好的效果了,真切感受到AI的魅力。
第二个实例
~~~~~~~~~~~~~~~~~~~接下来第二个实例~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
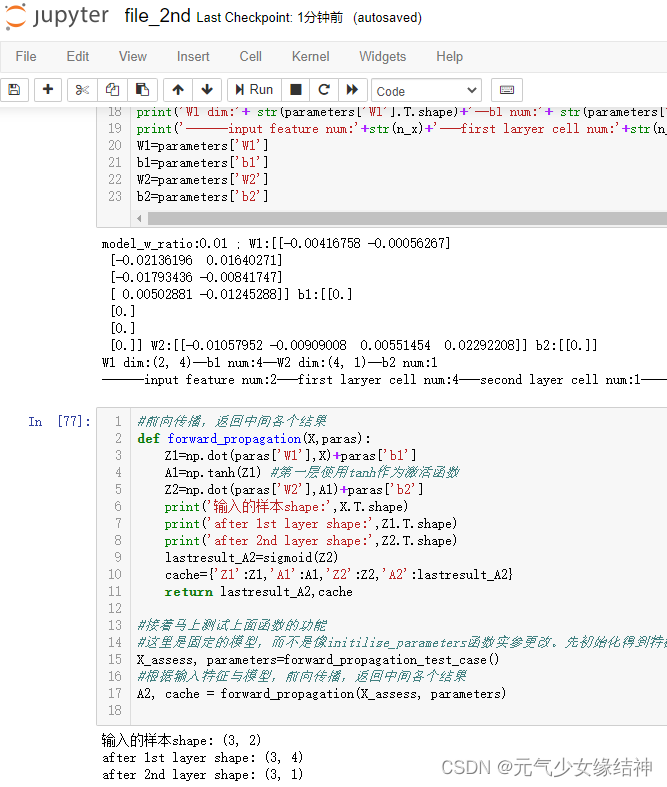
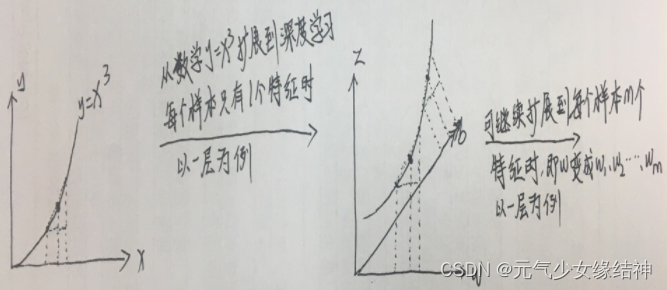
我还是习惯这样写,这样很清晰,如下图可以看到输入样本shape:(3,2)就表示3个样本,每个样本特征size是2;W1 dim:(2,4)即表示第一层的输入size是2,输出size是4;W2 dim:(4,1)即表示第二层的输入size是4,输出size是1。这样更容易理解!
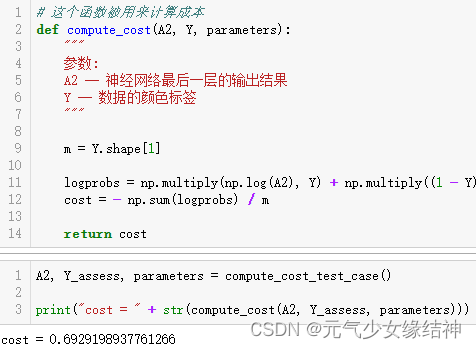
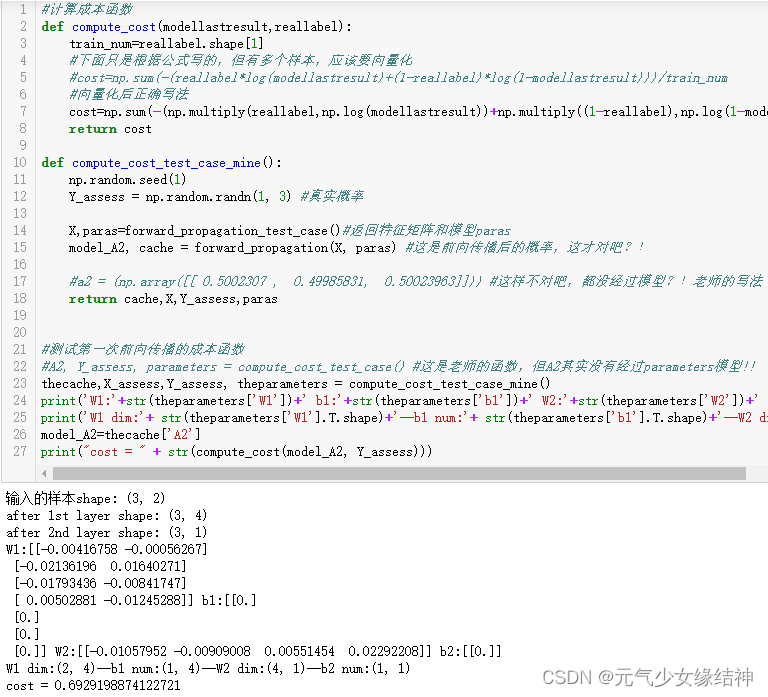
 然后对于测试成本函数的小例子,如下左图,老师使用compute_cost_test_case()函数返回模型的前向传播结果A2及真实标签Y_assess,然后像中间这幅图一样调用成本函数compute_cost计算得到成本cost。但是compute_cost_test_case()函数中老师是直接定义的前向传播结果a2,但并不是经过前向传播parameters后的结果?!我觉得应该在测试forward_propagation返回模型结果A2后,此时也已有了特征矩阵X_assess(由forward_propagation_test_case返回),然后直接调用compute_cost(A2,Y)计算得到cost打印出来。右图是我改的,就应该这样对吗?另外几个函数我也改了。
然后对于测试成本函数的小例子,如下左图,老师使用compute_cost_test_case()函数返回模型的前向传播结果A2及真实标签Y_assess,然后像中间这幅图一样调用成本函数compute_cost计算得到成本cost。但是compute_cost_test_case()函数中老师是直接定义的前向传播结果a2,但并不是经过前向传播parameters后的结果?!我觉得应该在测试forward_propagation返回模型结果A2后,此时也已有了特征矩阵X_assess(由forward_propagation_test_case返回),然后直接调用compute_cost(A2,Y)计算得到cost打印出来。右图是我改的,就应该这样对吗?另外几个函数我也改了。

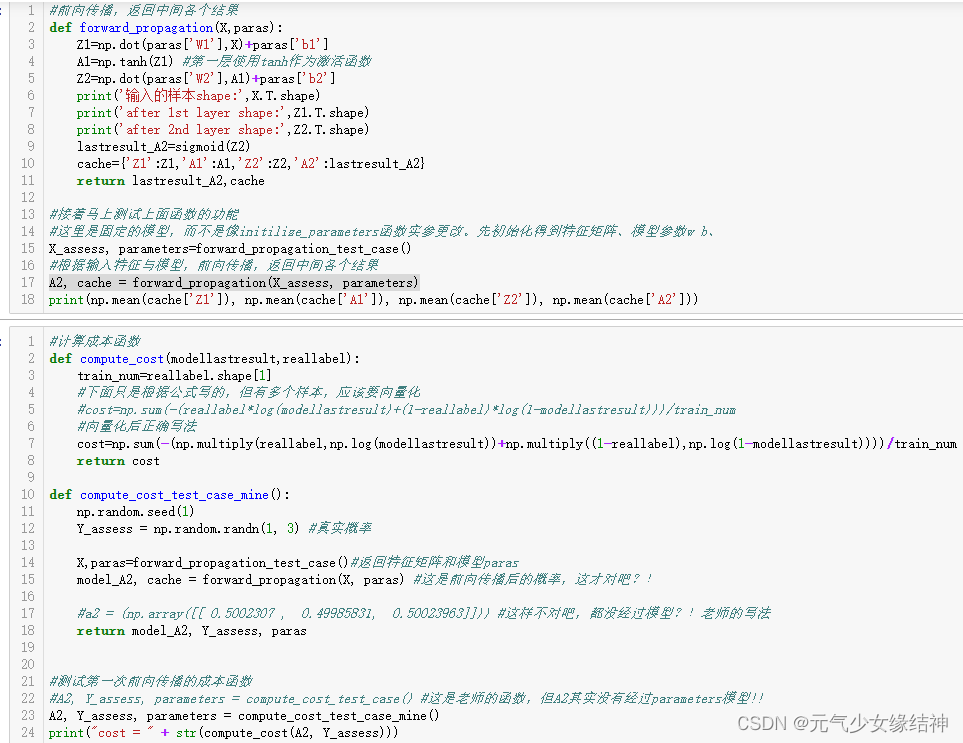
另外再次吐槽老师这个学习网站的评论功能不完善,在第i章节发表的评论或提问或疑惑,要等待助理审核,在等待过程中也许我已经学到了第n章节,此时都会忘了自己第i节的评论是否得到了回复。我觉得这个评论功能应该有一个被回复后的推送/提醒。

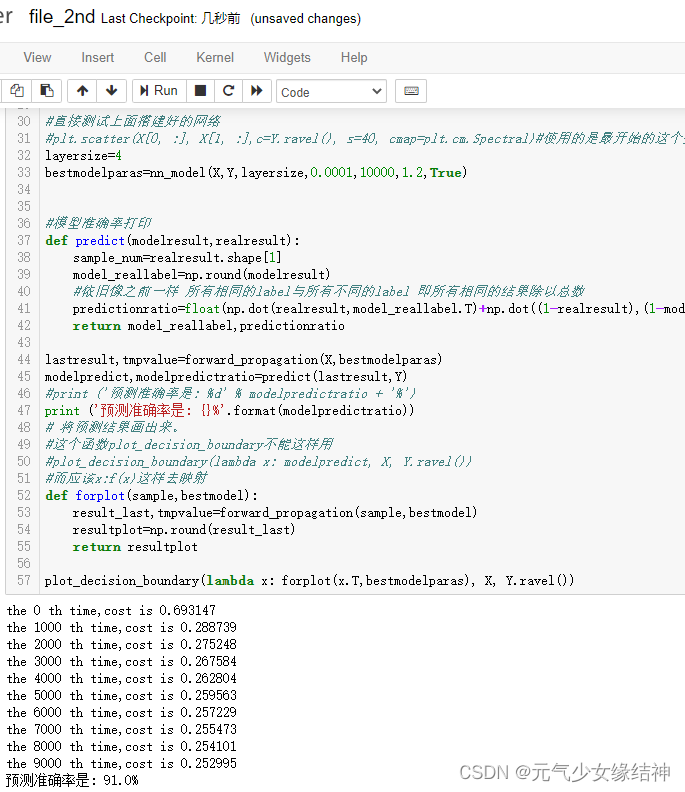
明显看到浅层神经网络比第一节所学线性模型强多了!而这个浅层神经网络仅仅2层,第一层才4个神经元,第二层1个神经元!!再次深刻感受到AI的魅力!上面的nn_model函数可以调节参数初始化大小、迭代次数、学习率去查看其分别对网络的影响。
第三个实例
~~~~~~~~~~~~~~~~~~~~接下来第三个示例~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
这个例子有4层,老师把输入层也一起放进去了,我没有这样所以顺着流程改了,与老师的结果一致:

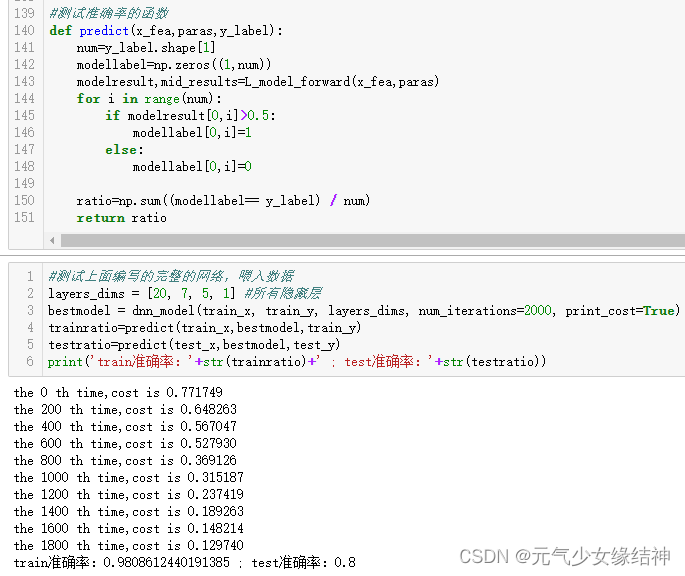
目前学到这里,感觉对教程的理解更深了一层,特别是前向传播、反向传播、参数更新的具体流程不用看教程也能写完整了。但不足之处是有时向量计算时维度上总是写反,所以导致维度不匹配,只有报错时才发现自己写反了。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~插个题外话~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
另外大家可以看下AINav.net - 一个属于AI人的导航网站 这个人收集的AI合集。今天查资料时突然看到一个公开的AI相关的比赛网址:人工智慧共創平台

看它会提供相应的奖励,不过这好像是“海对岸”那边的网址,人工智慧共創平台 它提供了很多企业、大学、研究院提出的需求,还有一些专题、比赛,也不知道“对岸这边”的人能否参加,如果有AI大佬可以去试试。
规范化Normalization与梯度消失/爆炸的理解
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~继续学~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
2.1.5小节老师说dropout传统是在激活值后a2=a2*d2,比如d2里80%是1,20%是0,表示对于第二层的激活值保留80%,但测试网络或实际应用时却没有dropout这个操作使用的是完整的网络,这就导致训练、测试的网络不一样。所以后来发明了inverted dropout,即在上面多加一行a2=a2/prob。这不是一样会导致训练时保留80%,然后让这80%的a2/prob即变得更小;测试时保留100%的a2/prob也变得小一点。但训练、测试的网络依旧不一样啊?
2.1.7小节在讲规范化的重要性时提到对成本函数J(w,b)的影响,因为老师图上看不到成本函数J的那一维,我觉得可以想象成未规范化的数据的成本函数就像变形的/间隔不一的多个扁漏斗,而规范化后的成本函数就像多个标准的/间隔相同的圆漏斗。所以对于前者,只能用较小的学习率去试探找到扁漏斗的底部即J最小点,对于后者因为是标准而且间隔相同所以很容易找到圆漏斗的底部。如下图所示:

2.1.8小节在讲延缓梯度消失与爆炸时,将随机数权重乘以一个与上一层神经元数目相关的小数其乘积作为初始化权重,因为这样做后靠近0的权重就比较多。以三层网络为例,极端写法就是a(i)=(w多个靠近0,但总和接近1)*(w多个靠近0,但总和接近1)*(w多个靠近0,但总和接近1)*a(0)=1*1*1*a(0) 所以就没有严重的梯度消失与梯度爆炸了。
2.1.9小节在讲梯度检验时将数值逼近应用到求权重w和偏置b的梯度时如下面这样画更清楚:
 图片上传后变形了,意思就是这样
图片上传后变形了,意思就是这样
第四个实例:参数初始化
~~~~~~~~~~~~~~~~~~~~~第四个实例:参数初始化~~~~~~~~~~~~~~~~~~~
主要讲不同初始化方式对模型精度的影响,奇怪的是我使用he_better初始化时怎么和老师的这个函数结果不一样?!我之所以不用老师的函数 是因为我是下面这样写的,使用he、random、zeros时与老师模型训练结果一致,可是用he_better时就不一样,为何?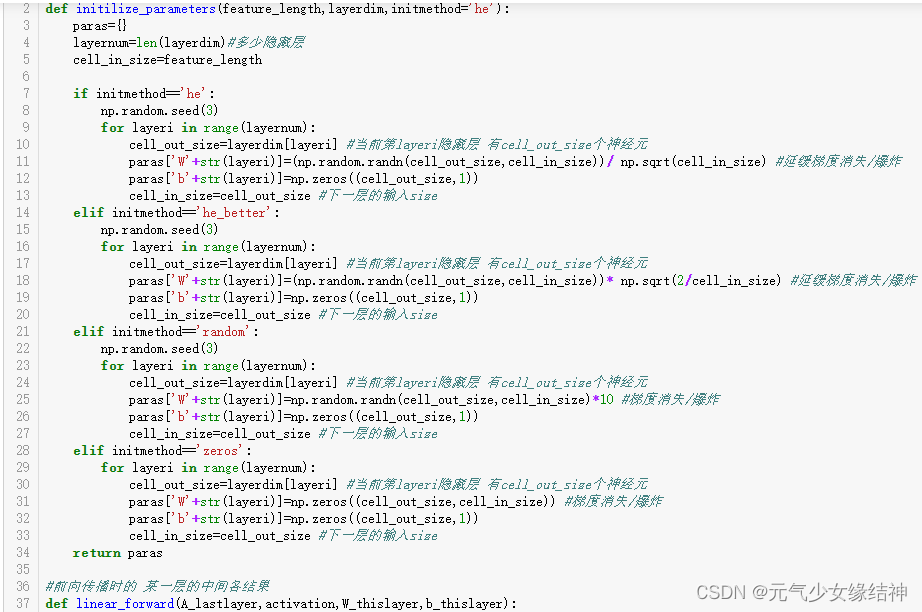 用下图的简单函数对比了一下,终于知道了原来是range(L)与 range(1,L)是有区别的。
用下图的简单函数对比了一下,终于知道了原来是range(L)与 range(1,L)是有区别的。
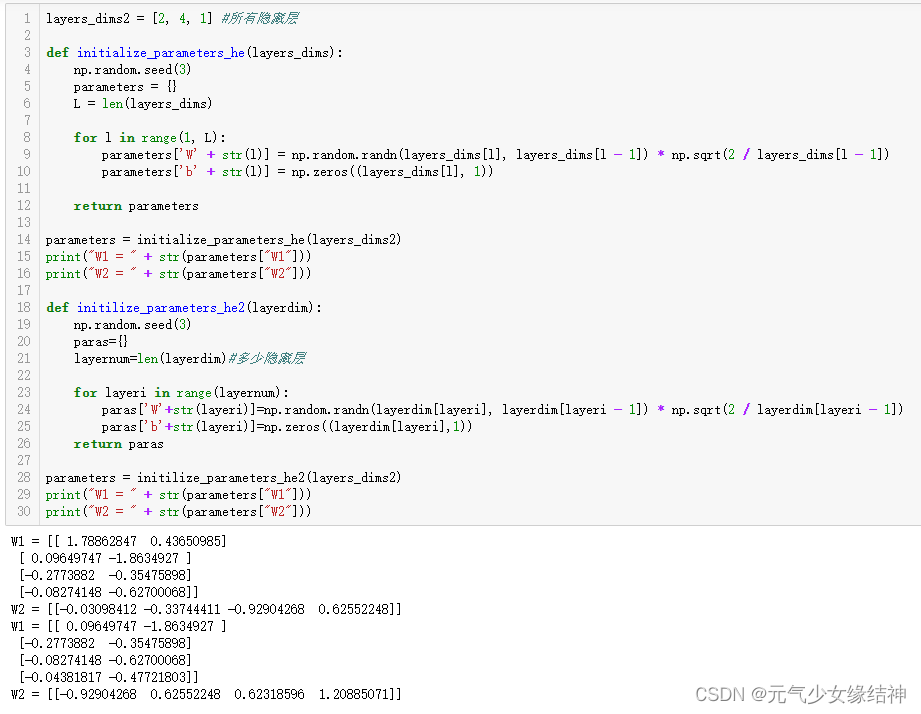 所以是这个导致了结果不同??那为什么其它几种初始化方式与老师的结果一样呢?肯定不是上面我改的函数的问题。哦我知道了,这里网络隐藏层变了不再是[10,5,1],所以结果才不同,纠正后终于正确了:
所以是这个导致了结果不同??那为什么其它几种初始化方式与老师的结果一样呢?肯定不是上面我改的函数的问题。哦我知道了,这里网络隐藏层变了不再是[10,5,1],所以结果才不同,纠正后终于正确了:
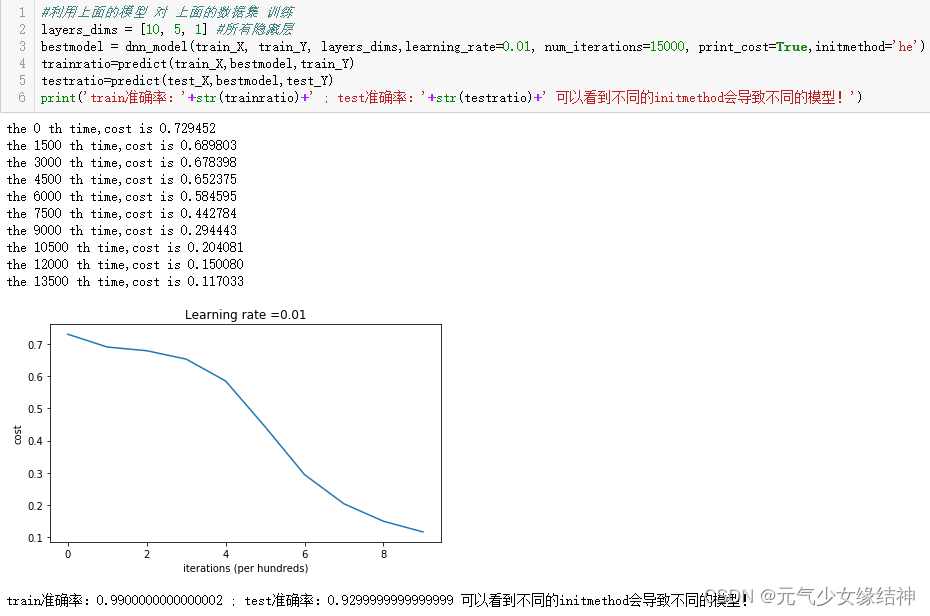
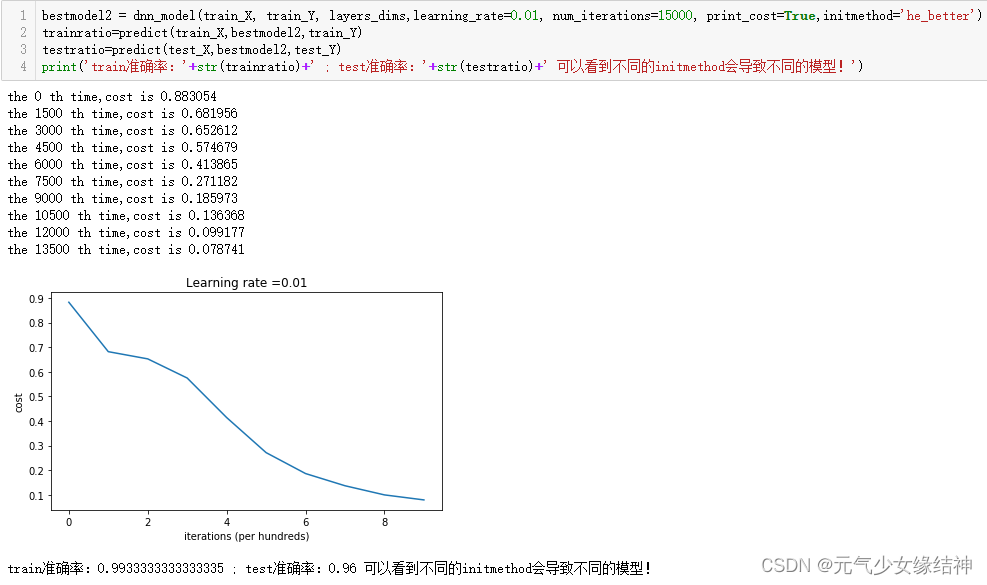 左边是he虽然也用随机数除以前一层的神经元个数平方根作为W结果,但准确率只有93%;改用he_better对随机数乘以2/前一层神经元个数的平方根作为W结果后,准确率提高到了96%!!!由此看出参数初始化真的非常重要,一点点小改变带来大不同的结果。
左边是he虽然也用随机数除以前一层的神经元个数平方根作为W结果,但准确率只有93%;改用he_better对随机数乘以2/前一层神经元个数的平方根作为W结果后,准确率提高到了96%!!!由此看出参数初始化真的非常重要,一点点小改变带来大不同的结果。
第五个实例:正则化
开始学习第五个实例,
动量梯度下降
2.2.5中动量梯度下降既然可能避开局部最小,更柔和的通过高原区即也可能避开局部最大,同理会不会也不能到达全局最小,可能只到全局最小附近。因为始终受之前的趋势影响,而那个趋势可能让梯度只是非常接近全局最小那里?
关于RMSPROP怎么纠正锯齿程度
第2.2.6 RMSPROP中算法流程后下一段老师说的我没理解,以前梯度更新学习率后乘以的是dw,现在RMS后直接用老师的公式Sdw=kSdw+(1-k)dw^2,怎么保证Sdw一定大于或小于dw呢?从而怎么保证dw/sqrt(Sdw)一定大于或小于dw呢?进而怎么保证w=w-lr*dw/sqrt(Sdw)更新就一定比w=w-lr*dw更新后大或小呢?所以较大/较小的趋势从公式上看无法保证。所以我认为无法像老师文中所述:dw较小,经过RMSPROP公式后w变得比随机梯度下降的w大。
最后
以上就是清爽秋天最近收集整理的关于人工智能AI学习第一个实例第二个实例第三个实例第四个实例:参数初始化第五个实例:正则化关于RMSPROP怎么纠正锯齿程度的全部内容,更多相关人工智能AI学习第一个实例第二个实例第三个实例第四个实例内容请搜索靠谱客的其他文章。








发表评论 取消回复