ubantu下darknet的yolov3运行以及训练
- ubuntu18.04环境下的darknet+yolov3
- 环境
- darknet的安装及测试
- 1、下载代码
- 2、下载权重
- 3、测试
- 附
- 测试自己数据集
- 一、数据集标注
- 1、打开标记工具
- 2、标注过程
- 3、标注后的文件
- 二、VOC2019数据集的制作
- 1、建立文件夹
- 2、生成ImageSets中的txt
- 3、生成VOCdevkit同级目录下的txt
- 4、labels中内容
- 5、JPEGImages中内容
- 三、Imagenet上预训练权重的下载和yolo一些配置文件的修改
- 1、下载Imagenet上的预训练的权重
- 2、修改darknet-master/cfg/voc.data文件
- 3、修改darknet-master/data/voc.names文件
- 4、修改darknet-master/cfg/yolov3-voc.cfg文件
- 四、训练
- 1、开始训练
- 2、训练结果
- 3、训练中需要注意的
- 五、测试
- 1、单张图片测试
- 2、摄像头测试
- 3、视频测试
ubuntu18.04环境下的darknet+yolov3
参考链接
环境
ubuntu18.04
cuda:10.0.120
cudnn:7.6.5.32
opencv:3.2.0
darknet的安装及测试
官网
1、下载代码
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
2、下载权重
下载权重,保存在darknet的目录下
wget https://pjreddie.com/media/files/yolov3.weights
3、测试
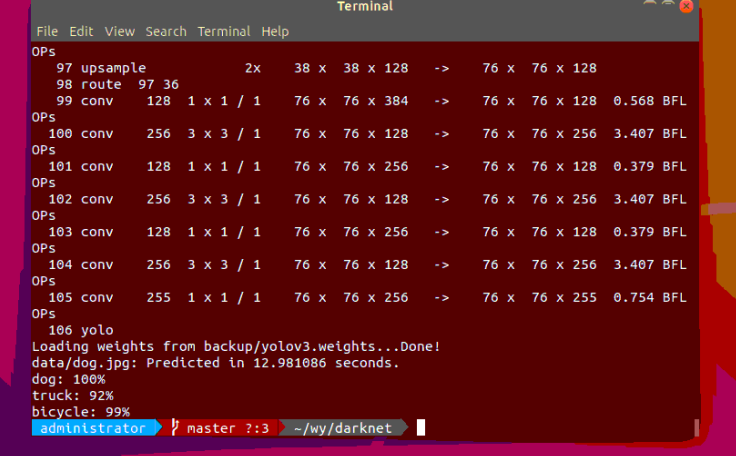
在darknet目录下打开终端,输入:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
结果如下:
附
下面是对darknet目录下的Makefile文件进行的一些修改,每次修改完都需要重新编译。
(1)如需使用gpu运算,修改如下,然后保存。
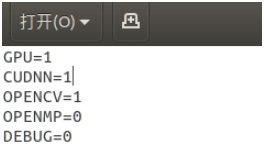
修改完后一定要重新编译,在darknet目录下打开终端,输入:
make clean
make -j8
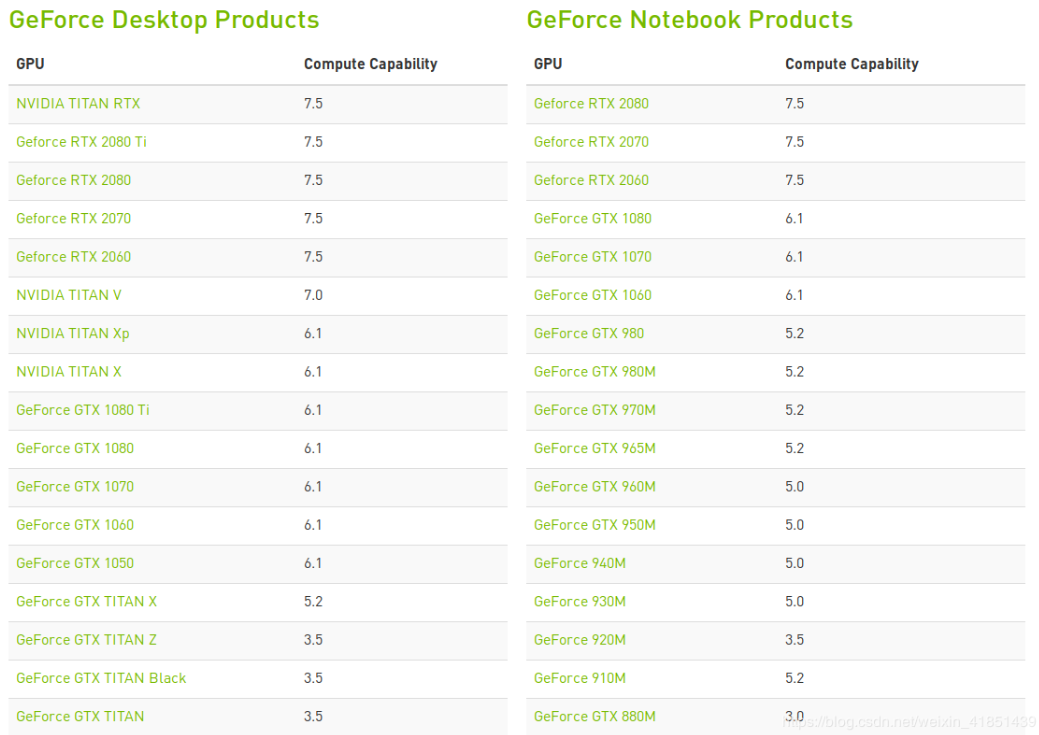
(2)根据自己电脑的硬件可在Makefile中对ARCH进行修改。例如显卡是GTX1060,算力为6.1(具体算力nvidia官网可查)。
https://developer.nvidia.com/cuda-gpus
修改如下:

显卡算力:
(3)在Makefile文件的第46行,修改为cuda的安装路径。

测试自己数据集
一、数据集标注
标记数据的可以从这里下载,提取码:m3dt。注意该工具的路径要没有中文,否则闪退。
1、打开标记工具
如图:
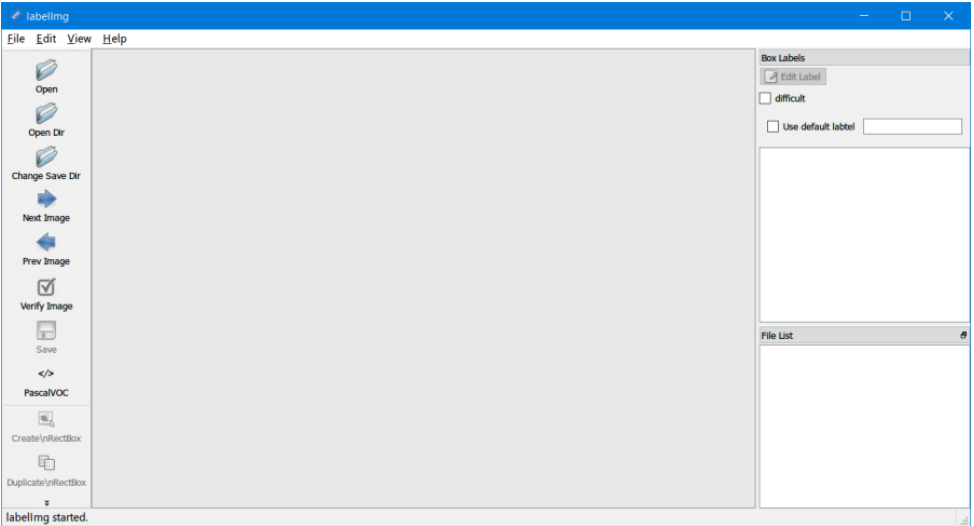
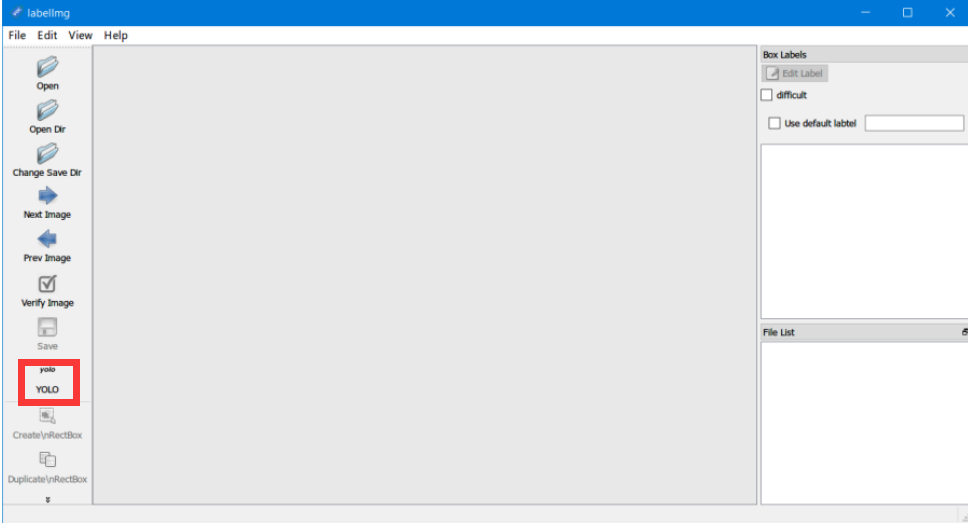
红色方框处选择yolo,而非默认的PascalVOC(我们在标注的时候就让每张图片生成的是txt文件,而不是xml文件,这样就省去了xml转txt这个步骤)如下图:
2、标注过程
点击界面上的 Open Dir,打开图片存放文件夹,图片将显示在界面中:
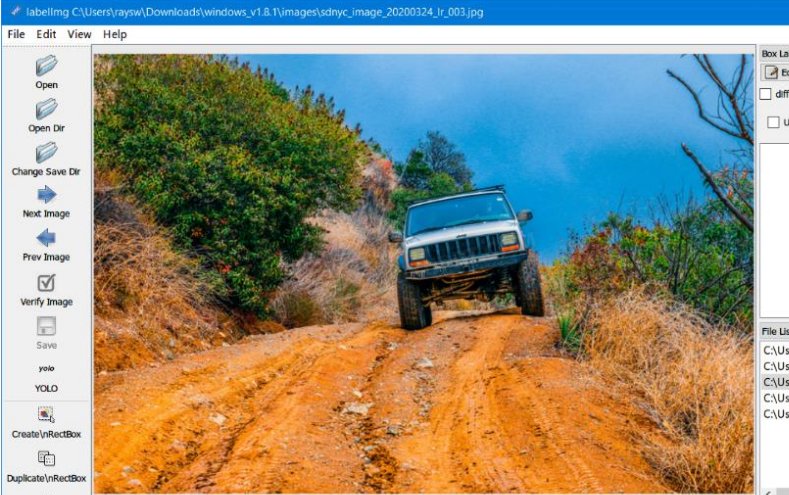
在图片上点击鼠标右键,选择“Create RectBox”,之后从左上至右下拖动鼠标画出一方框,标出待识别物体(快捷键:W)。
松开鼠标后,会弹出一个对话框,此时选择框出物体所属的类别,之后点击 OK。
确认右侧出现标注内容后点击 save 保存标注信息(快捷键:Ctrl+S)。
点击 Next Image,重复上述过程直至每张图片都完成标注(快捷键:D)。
3、标注后的文件
标注过后,就会生成对应的图片名的txt文件,以及一个所有类别的文件。
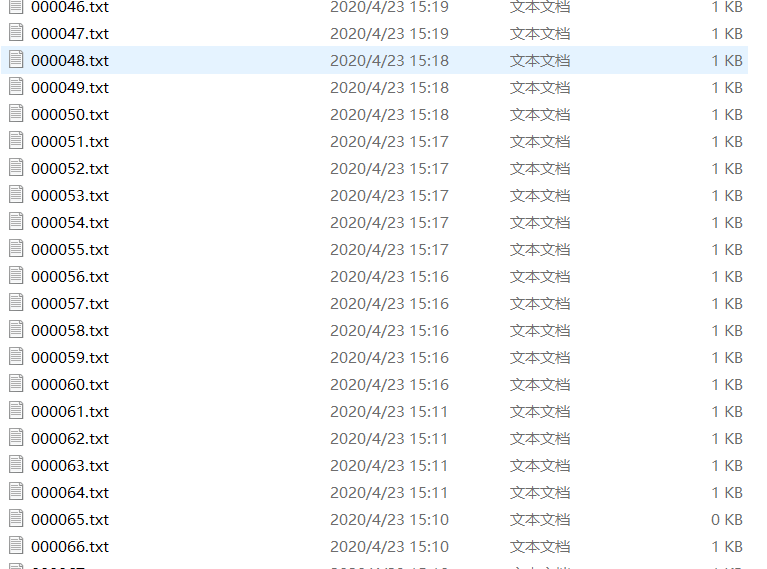
其中对于每个标注后生成的txt文件,其格式是如下所示(网上存):

二、VOC2019数据集的制作
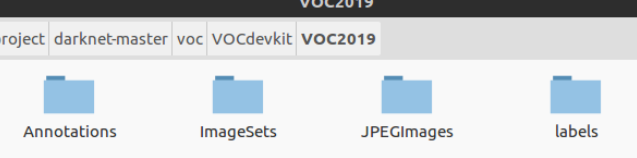
1、建立文件夹
在darnet-master下建立voc/VOCdevkit/VOC2019层次目录,然后在VOC2019目录下建立三个文件夹:Annotations、ImageSets、JPEGImages。
其中:
Annotations 存放使用labelImg软件标注所有数据集图片时生成的txt标注文件,labels存放Annotations中相同的内容;(第一步已有)
ImageSets用来存放训练和测试数据的名称,其里面存放的是Main文件夹,Main文件夹中存放的是4个txt文件,分别是存训练集图片名的train.txt、存验证集图片名的val.txt、存测试集图片名的test.txt、存测试和验证集图片名的trainval.txt;(需要生成)
JPEGImages用于存放数据集中的图片,后期还要将labels中的txt全部放到其中。
2、生成ImageSets中的txt
我们需要ImageSets/Main目录下的train.txt和val.txt,代码make_train_val.py如下:
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/*****(自己的路径)/darknet-master/voc/VOCdevkit/VOC2019/JPEGImages/'#地址是所有图片的保存地点
dest='/*****(自己的路径)/darknet-master/voc/VOCdevkit/VOC2019/ImageSets/Main/train.txt' #保存train.txt的地址,对于train.txt(在ImageSets/Main/下)和2019_train.txt(在VOCdevkit下)是不同的路径
dest2='/*****(自己的路径)/darknet-master/voc/VOCdevkit/VOC2019/ImageSets/Main/val.txt' #保存val.txt的地址,对于val.txt(在ImageSets/Main/下)和2019_val.txt(在VOCdevkit下)是不同的路径
file_list=os.listdir(source_folder) #赋值图片所在文件夹的文件列表
train_file=open(dest,'a') #打开文件
val_file=open(dest2,'a') #打开文件
for file_obj in file_list: #访问文件列表中的每一个文件
file_path=os.path.join(source_folder,file_obj)
#file_path保存每一个文件的完整路径
file_name,file_extend=os.path.splitext(file_obj)
#file_name 保存文件的名字,file_extend保存文件扩展名
file_num=int(file_name)
if(file_num<620): #保留620个文件用于训练
train_file.write(file_name+'n') #用于训练前620个的图片路径保存在train.txt里面,结尾加回车换行/生成train.txt是file_name;生成2019_train.txt是file_path
else :
val_file.write(file_name+'n') #其余的文件保存在val.txt里面/生成val.txt是file_name;生成2019_val.txt是file_path
train_file.close()#关闭文件
val_file.close()
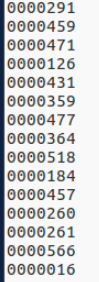
生成的train.txt文件和val.txt文件是图片名字
3、生成VOCdevkit同级目录下的txt
生成代码make_2019_train_val.py如下:
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/*****(自己的路径)/darknet-master/voc/VOCdevkit/VOC2019/JPEGImages/'#地址是所有图片的保存地点
dest='/*****(自己的路径)/darknet-master/voc/2019_train.txt' #保存train.txt的地址,对于train.txt(在ImageSets/Main/下)和2019_train.txt(在VOCdevkit下)是不同的路径
dest2='/*****(自己的路径)/darknet-master/voc/2019_val.txt' #保存val.txt的地址,对于val.txt(在ImageSets/Main/下)和2019_val.txt(在VOCdevkit下)是不同的路径
file_list=os.listdir(source_folder) #赋值图片所在文件夹的文件列表
train_file=open(dest,'a') #打开文件
val_file=open(dest2,'a') #打开文件
for file_obj in file_list: #访问文件列表中的每一个文件
file_path=os.path.join(source_folder,file_obj)
#file_path保存每一个文件的完整路径
file_name,file_extend=os.path.splitext(file_obj)
#file_name 保存文件的名字,file_extend保存文件扩展名
file_num=int(file_name)
if(file_num<620): #保留620个文件用于训练
train_file.write(file_path+'n') #用于训练前620个的图片路径保存在train.txt里面,结尾加回车换行/生成train.txt是file_name;生成2019_train.txt是file_path
else :
val_file.write(file_path+'n') #其余的文件保存在val.txt里面/生成val.txt是file_name;生成2019_val.txt是file_path
train_file.close()#关闭文件
val_file.close()
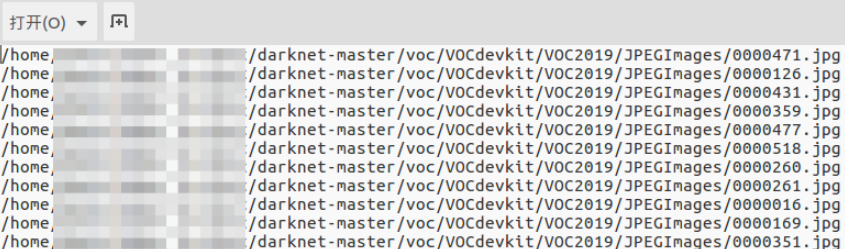
其中2019_train.txt文件中的部分内容如下(保存绝对路径):
4、labels中内容
将Annotations中的txt文件(除了classes外)全部复制到labels中
5、JPEGImages中内容
将labels中的txt全部复制到JPEGImages文件夹中,做到图片和txt一一对应。 一开始是要吧JPEGImages文件中的图片放到darknet-master/data/images目录下,现在直接把yolo的标签文件txt即labels中的内容复制到JPEGImages文件夹中就可以了。
三、Imagenet上预训练权重的下载和yolo一些配置文件的修改
1、下载Imagenet上的预训练的权重
将下载的权重文件存在darknet-master/scripts目录下
wget https://pjreddie.com/media/files/darknet53.conv.74
2、修改darknet-master/cfg/voc.data文件
classes= 9 #classes为训练样本集的类别总数,本实验选的为9类标签
train = /****(自己的路径自己改)/darknet-master/voc/2019_train.txt #train的路径为训练样本集所在的路径
valid = /****(自己的路径自己改)/darknet-master/voc/2019_val.txt #valid的路径为验证样本集所在的路径
names = data/voc.names #names的路径为data/voc.names文件所在的路径
backup = backup
3、修改darknet-master/data/voc.names文件
更换默认的类别为自己的类别
4、修改darknet-master/cfg/yolov3-voc.cfg文件
[net]
# Testing
# batch=1 #这里的batch跟subdivisions原来不是注释掉的,但是训练后没成功,有的blog上说为1的时候太小难以收敛,但是不知道下面训练模式的 batch=64 subdivisions=8 会不会覆盖掉,总之注释掉后就成功了,不过这个脚本不是很明白,还来不及验证
# subdivisions=1
# Training ### 训练模式,每次前向的图片数目 = batch/subdivisions
batch=64 #根据自己的情况进行修改
subdivisions=8 #根据自己的情况进行修改
width=416 ### 网络的输入宽、高、通道数
height=416
channels=3
momentum=0.9 ### 动量
decay=0.0005 ### 权重衰减
angle=0
saturation = 1.5 ### 饱和度
exposure = 1.5 ### 曝光度
hue=.1 ### 色调
learning_rate=0.001 ### 学习率
burn_in=1000 ### 学习率控制的参数
max_batches = 50200 ### 迭代次数
policy=steps ### 学习率策略
steps=40000,45000 ### 学习率变动步长
scales=.1,.1 ### 学习率变动因子
......
......
......
[convolutional]
size=1
stride=1
pad=1
filters=42 #---------------修改为3*(classes+5)即3*(9+5)=42
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=9 #---------------修改为标签类别个数,9类
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0 #1,如果显存很小,将random设置为0,关闭多尺度训练;(转自别的blog,还不太明白)
......
[convolutional]
size=1
stride=1
pad=1
filters=42 #---------------修改同上
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=9 #---------------修改同上
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0
......
[convolutional]
size=1
stride=1
pad=1
filters=42 #---------------修改同上
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=9 #---------------修改同上
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0
注意:在以上源码中不要有中文注释,否则会出错
batch:一批训练样本的样本数量,每batch个样本更新一次参数
subdivisions:将batch分割为subdivisions个子batch,每个子batch的大小为batch/subdivisions,作为一次性送入训练器的 样本数量。
A.filters数目是怎么计算的:3x(classes数目+5),和聚类数目分布有关,论文中有说明;
B.如果想修改默认anchors数值,使用k-means即可;
C.如果显存很小,将random设置为0,即关闭多尺度训练;
四、训练
1、开始训练
不保存训练日志的训练执行命令
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg scripts/darknet53.conv.74
保存训练日志的训练执行命令
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg scripts/darknet53.conv.74 | tee train_yolov3-voc.log
2、训练结果
可以在backup看到训练生成的权重文件
保存的训练日志文件为:train_yolov3-voc.log
3、训练中需要注意的
1、如果中间停止训练,后来又想想接着训练,则输入以下命令:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup
2、训练中,默认的是前1000轮每100轮保存一次模型,1000轮后每10000轮保存一次模型。如需修改,打开examples/detector.c文件的138行。修改完重新编译一下,在darknet目录下执行make。
3、训练的参数的解释:
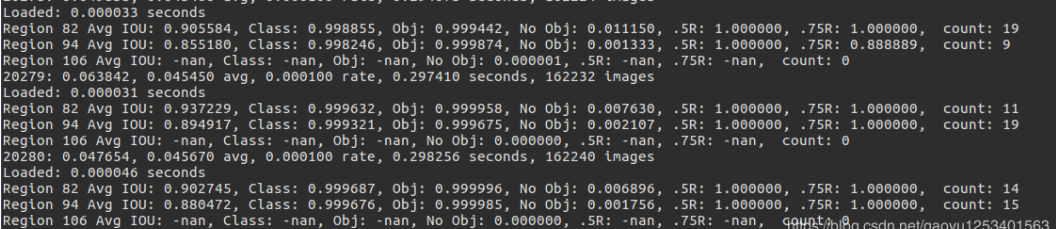
Region xx:cfg文件中yolo-layer的索引;
Avg IOU: 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class:标注物体的分类准确率,越大越好,期望数值为1;
obj:越大越好,期望数值为1;
No obj:越小越好;
.5R:以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R:以IOU=0.75为阈值时候的recall;
count:正样本数目。
————————————————
20280: 指示当前训练的迭代次数
0.047654: 是总体的Loss(损失)
0.045678 avg: 是平均Loss,这个数值应该越低越好,一般来说,一旦这个数值低于0.060730 avg就可以终止训练了。
0.000100 rate: 代表当前的学习率,是在.cfg文件中定义的。
0.298256 seconds: 表示当前批次训练花费的总时间。
162240 images: 这一行最后的这个数值表示到目前为止,参与训练的图片的总量。
4、可视化
使用以下python脚本对训练日志进行可视化,得到loss变化曲线和Avg IOU曲线(Avg IOU是标记的框和预测的框重复的部分除以他们的和,这个值越接近1越好)
visualization_train_yolov3-voc_log.py
# -*- coding: utf-8 -*-
# @Func :yolov3 训练日志可视化,把该脚本和日志文件放在同一目录下运行。
import pandas as pd
import matplotlib.pyplot as plt
import os
# ==================可能需要修改的地方=====================================#
g_log_path = "train_yolov3-voc.log" # 此处修改为你的训练日志文件名
# ==========================================================================#
def extract_log(log_file, new_log_file, key_word):
'''
:param log_file:日志文件
:param new_log_file:挑选出可用信息的日志文件
:param key_word:根据关键词提取日志信息
:return:
'''
with open(log_file, "r") as f:
with open(new_log_file, "w") as train_log:
for line in f:
# 去除多gpu的同步log
if "Syncing" in line:
continue
# 去除nan log
if "nan" in line:
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
def drawAvgLoss(loss_log_path):
'''
:param loss_log_path: 提取到的loss日志信息文件
:return: 画loss曲线图
'''
line_cnt = 0
for count, line in enumerate(open(loss_log_path, "rU")):
line_cnt += 1
result = pd.read_csv(loss_log_path, skiprows=[iter_num for iter_num in range(line_cnt) if ((iter_num < 500))],
error_bad_lines=False,
names=["loss", "avg", "rate", "seconds", "images"])
result["avg"] = result["avg"].str.split(" ").str.get(1)
result["avg"] = pd.to_numeric(result["avg"])
fig = plt.figure(1, figsize=(6, 4))
ax = fig.add_subplot(1, 1, 1)
ax.plot(result["avg"].values, label="Avg Loss", color="#ff7043")
ax.legend(loc="best")
ax.set_title("Avg Loss Curve")
ax.set_xlabel("Batches")
ax.set_ylabel("Avg Loss")
def drawIOU(iou_log_path):
'''
:param iou_log_path: 提取到的iou日志信息文件
:return: 画iou曲线图
'''
line_cnt = 0
for count, line in enumerate(open(iou_log_path, "rU")):
line_cnt += 1
result = pd.read_csv(iou_log_path, skiprows=[x for x in range(line_cnt) if (x % 39 != 0 | (x < 5000))],
error_bad_lines=False,
names=["Region Avg IOU", "Class", "Obj", "No Obj", "Avg Recall", "count"])
result["Region Avg IOU"] = result["Region Avg IOU"].str.split(": ").str.get(1)
result["Region Avg IOU"] = pd.to_numeric(result["Region Avg IOU"])
result_iou = result["Region Avg IOU"].values
# 平滑iou曲线
for i in range(len(result_iou) - 1):
iou = result_iou[i]
iou_next = result_iou[i + 1]
if abs(iou - iou_next) > 0.2:
result_iou[i] = (iou + iou_next) / 2
fig = plt.figure(2, figsize=(6, 4))
ax = fig.add_subplot(1, 1, 1)
ax.plot(result_iou, label="Region Avg IOU", color="#ff7043")
ax.legend(loc="best")
ax.set_title("Avg IOU Curve")
ax.set_xlabel("Batches")
ax.set_ylabel("Avg IOU")
if __name__ == "__main__":
loss_log_path = "train_log_loss.txt"
iou_log_path = "train_log_iou.txt"
if os.path.exists(g_log_path) is False:
exit(-1)
if os.path.exists(loss_log_path) is False:
extract_log(g_log_path, loss_log_path, "images")
if os.path.exists(iou_log_path) is False:
extract_log(g_log_path, iou_log_path, "IOU")
drawAvgLoss(loss_log_path)
drawIOU(iou_log_path)
plt.show()
将上述python脚本文件和训练日志放在同一目录下,打开此目录下的终端,运行上述.py文件可以得到loss变化曲线和Avg IOU变化曲线。同时,在当前目录下生成了train_log_iou.txt和train_log_loss.txt文件。
五、测试
1、单张图片测试
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_20000.weights voc/VOCdevkit/VOC2019/JPEGImages/0000629.jpg
2、摄像头测试
./darknet detector demo cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_20000.weights
3、视频测试
./darknet detector demo cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_50000.weights 3.mp4
注意:要将Makefile中的OpenCV设为1,然后 make 之后才可以看到视频检测效果。
最后
以上就是甜蜜信封最近收集整理的关于ubuntu18.04下darknet的yolov3运行以及训练ubuntu18.04环境下的darknet+yolov3的全部内容,更多相关ubuntu18.04下darknet内容请搜索靠谱客的其他文章。








发表评论 取消回复