这篇博客的笔记内容是数据的表示与运算。
一、数制与编码
1.不同进制之间的转换
1)二进制转八进制和十六进制
其整数部分,从小数点开始往左数,将一串二进制数分为3位(八进制)一组或4位(十六进制)一组,在数的最左边可根据需要加“0”补齐;对于小数部分,从小数点开始往右数,也将一串二进制数分为3位一组或4位一组,在数的最右边也可根据需要加“0”补齐。最终使总的位数为3或4的整数倍,然后分别用对应的八进制数或十六进制数取代。
同理,八进制和十六进制转为二进制则去相反操作。
2)其他进制转十进制
将任意进制数的各位数码与它们的权值相乘,再把乘积相加,就得到了一个十进制数。这种方法称为按权展开相加法。
3)十进制转为任意进制
一个十进制数转换为任意进制数,常采用基数乘除法。这种转换方法对十进制数的整数部分和小数部分将分别进行处理,对整数部分用除基取余法,对小数部分用乘基取整法,最后将整数部分与小数部分的转换结果拼接起来。
除基取余法(整数部分的转换):整数部分除基取余,最先取得的余数为数的最低位,最后取得的余数为数的最高位(即除基取余,先余为低,后余为高),商为0时结束。
乘基取整法(小数部分的转换):小数部分乘基取整,最先取得的整数为数的最高位,最后取得的整数为数的最低位(即乘基取整,先整为高,后整为低),乘积为1.0(或满足精度要求)时结束。
2.BCD码
包含8421码、余三码、2121码。
(其他类型编码如ASCII码和汉字编码)
3.校验码
1)奇偶校验码
2)汉明码(线性分组码)
3)循环冗余校验码(CRC码)
(此块内容更接近通信原理课程,更具体可参考通信原理书籍)
二、定点数的表示与运算
1.定点数的表示
1)有符号数与无符号数
无符号数:没有符号位,若机器字长为8位,则数的表示范围为0~2^8-1,即0~255。
有符号数:通常约定二进制数的最高位为符号位,即将符号位放在有效数字的前面,用“0”表示“正”号,用“1”表示“负”号,组成有符号数。
2)定点数的格式
参见:什么是定点数? - 知乎
定点小数:基本用的很少了
定点整数:整型数据基本都是用定点整数存储
3)原码、补码、反码、移码
原码:用机器数的最高位表示该数的符号,其余的各位表示数的绝对值。
反码:简单的规律是:正数的反码还是其本身,负数的反码则按位取反。
补码:基本上是真正在计算机中进行运算的码。正数的补码是本身,负数的补码是其反码并在最低权位上加1。(要注意的是基本上目前所有的计算机存储方式均是采用补码存储)
移码:移码就是在真值X上加上一个常数(偏置值),通常这个常数取2^n,相当于X在数轴上向正方向偏移了若干单位。
2.定点数的运算
1)移位运算
移位运算根据操作对象的不同分为算术移位和逻辑移位。有符号数的移位称为算术移位,逻辑移位的操作对象是逻辑代码,可视为无符号数。
算数移位:对于原码,左移一位若不产生溢出,相当于乘以2(与十进制的左移一位相当于乘以10类似),右移一位,若不考虑因移出而舍去的末位尾数,相当于除以2。
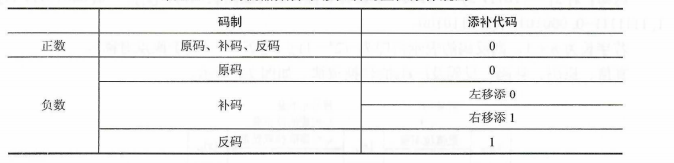
逻辑移位:
逻辑移位将操作数视为无符号数,移位规则:逻辑左移时,高位移丢,低位添0;逻辑右移时,低位移丢,高位添0。
循环移位:
循环移位操作特别适合将数据的低字节数据和高字节数据互换。
2)定点数加减法
原码定点数加减法运算:较简单
补码定点数加减法运算:
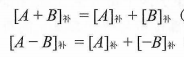
3)溢出
溢出是指运算结果超过了数的表示范围。通常,称大于机器所能表示的最大正数为上溢,称小于机器所能表示的最小负数为下溢。
仅当两个符号相同的数相加或两个符号相异的数相减才可能产生溢出。
4)定点数乘除法
这块部分太难了,比较复杂,不详细掌握。
乘法主要有:原码一位乘法和补码一位乘法。除法有不恢复余数法和加减交替法。
3.C语言中定点数的相互转换
1)有符号数与无符号数的相互转换
这一块容易理解。典型例子如下:

2)不同长度整数间的转换
当大字长变量向小字长变量强制类型转换时,系统把多余的高位字长部分直接截断,低位直接赋值。
而短字长到长字长的转换,在位值相等的条件下还要补充高位的符号位,可以理解为数值的相等。
4.数据的存储排列方式
1)大端存储与小端存储
通常用最低有效字节(LSB)和最高有效字节(MSB)来分别表示数的低位和高位。
大端方式按从最高有效字节到最低有效字节的顺序存储数据,即最高有效字节存放在前面;小端方式按从最低有效字节到最高有效字节的顺序存储数据,即最低有效字节存放在前面。
2)边界对齐方式
可参考:【考研真题】边界对齐存储_Runner_of_nku的博客-CSDN博客_边界对齐存储
个人理解(可能有误):假设存储字长为32位,可按字节、半字和字寻址。对于机器字长为32位的计算机,数据以边界对齐方式存放,半字地址一定是2的整数倍,字地址一定是4的整数倍,这样无论所取的数据是字节、半字还是字,均可一次访存取出。所存储的数据不满足上述要求时,通过填充空白字节使其符合要求。对于存放某长度为m字节的数据,存放地址需在m字节的整数倍存放,结构体整体的大小是最大成员长度的整数倍。
(其他说法:对齐原则:1)结构体变量的首地址能够被其最宽基本类型成员的对齐值所整除;2)结构体内每一个成员的相对于起始地址的偏移量能够被该变量的大小整除;3)结构体总体大小能够被最宽成员大小整除;如果不满足这些条件,编译器就会进行一个填充(padding)。)
边界对齐虽然浪费了一些存储空间,但可提高取指令和取数的速度。
三、浮点数的表示与运算
1.浮点数的表示
1)传统表示方法:
![]()
r是浮点数阶码的底(隐含),与尾数的基数相同,通常r = 2。E和M都是有符号的定点数,E称为阶码,M称为尾数。可见浮点数由阶码和尾数两部分组成。(需要注意的是传统表示方法中的阶码和尾数无特殊说明基本是补码表示)

2)传统表示方法的浮点数规格化
可参考:1.1--浮点数的规格化 - 豆丁网
即规定尾数的最高数位必须是一个有效值。所谓规格化操作,是指通过调整一个非规格化浮点数的尾数和阶码的大小,使非零的浮点数在尾数的最高数位上保证是一个有效值。
规格化浮点数的尾数M的绝对值应满足条件1/r≤|M≤1。

这里面需要注意的一个坑是:为了机器判断方便,在补码表示中往往不把-1/2列入规格化的数。故补码的尾数最大不是-1/2。还有就是-1的补码是1.000...00。
当浮点数尾数的基数为2时,原码规格化数的尾数最高位一定是1,补码规格化数的尾数最高位一定与尾数符号位相反。基数不同,浮点数的规格化形式也不同。当基数为4时,原码规格化形式的尾数最高两位不全为0;当基数为8时,原码规格化形式的尾数最高3位不全为0。
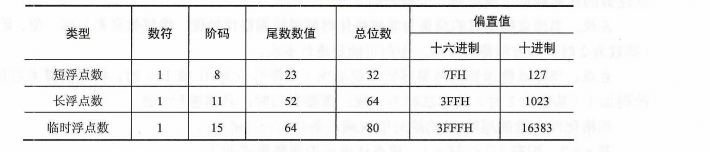
3)IEEE 754标准
经过个人测试,大部分的电脑目前都是采用IEEE 754标准进行存储。
存储形式:要注意的是,与传统浮点数表达形式不同,其尾数是用原码形式存储。

计算方法:

常见IEEE 754浮点数leixing的位数和格式:
取值范围:

2.浮点数的加减运算
可参考:浮点数的加减法运算_ruidianbaihuo的博客-CSDN博客_浮点数相加
主要步骤:对阶-->尾数求和-->规格化-->舍入(会造成精度和误差问题)-->溢出判断
3.类型转换及与定点数的区别
1)类型转换

2) 定点数和浮点数的区别

关于浮点数表示整数的精度可参考:float数在无法精确表示的整数如何舍入?-CSDN论坛
以及:浮点数不能表示的最小正整数-CSDN论坛
原因:尾数的精确度有24位,而阶数的表示范围远大于24位,最后会造成好几个相邻整数表现位同一个整数的现象。
至于浮点数表示小数则比较好理解,典型的就是0.1,因为其无法完全用2的幂去拟合。
四、算数逻辑单元(ALU)
在计算机中,运算器承担了执行各种算术和逻辑运算的工作,运算器由算术逻辑单元(Arithmetic Logic Unit,ALU)、累加器、状态寄存器和通用寄存器组等组成。ALU的基本功能包括加、减、乘、除四则运算,与、或、非、异或等逻辑运算,以及移位、求补等操作。
计算机运行时,运算器的操作和操作种类由控制器决定。运算器处理的数据来自存储器;处理后的结果数据通常送回存储器,或暂存在运算器中。
此块内容更接近数字电路课程,要深入建议看看数字电路课程教材。
1.串行加法器与并行加法器
1)串行加法器
只有一个全加器,数据逐位串行送入加法器中进行运算。串行加法器具有器件少、成本低的优点,但运算速度慢,多用于某些低速的专用运算器。
2)并行加法器
并行加法器由多个全加器组成,其位数与机器的字长相同,各位数据同时运算。通常分为串行进位和并行进位。
2.ALU
ALU是一种功能较强的组合逻辑电路,它能进行多种算术运算和逻辑运算。
最后
以上就是俏皮皮皮虾最近收集整理的关于计算机基础课--计组学习笔记(2)的全部内容,更多相关计算机基础课--计组学习笔记(2)内容请搜索靠谱客的其他文章。








发表评论 取消回复