- Deep Few-Shot Learning for Hyperspectral Image Classification
作者:Bing Liu , Xuchu Yu, Anzhu Yu, Pengqiang Zhang, Gang Wan, and Ruirui Wang
出处:IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING
发表时间:2019
1.1摘要与贡献:
目前,深度学习方法已被成功用于高光谱图像(HSI)分类。然而,想要训练一个深度学习的分类器需要成千上百个标记样本。这篇文章提出了一种深度学习方法来解决HSI分类的小样本问题。在所提出的算法中有三个新颖的策略:
通过深度3-D残差卷积神经网络提取光谱空间特征,以降低标签的不确定性。
通过episodes训练网络以学习度量空间,其中来自同一类的样本距离近,来自不同类的样本距离远。
测试样本由学习度量空间中的最近邻居分类器分类
其中最重要的是用训练样本训练deep residual 3-D CNN得到一个metric space。这样的metric space可以泛化到测试集中,对测试集的样本进行分类。模型在训练的时候是不知道测试集是什么样子的,所以这是一个纯半监督学习。
1.2方法:DFSL(Deep Few-shot Learing)
(1)训练过程
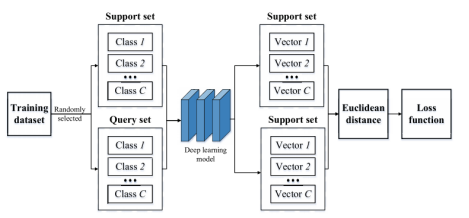
从training data set中随机选择一些类,再在每一类中选择support sample(本文中为1个),剩余的部分就是query sample,每一类的sample合在一起变成set就得到了support set和query set。随后将support set和query set输入网络模型中。这样一个训练更新权重的过程为1个episode。
一次episode过程后,在metric space这个空间里,每一个类别(1 ~ C)都有一个标准的向量,即Vector 1 ~ C,它们都有标签1 ~ C,最小化损失函数做的是使得每一个类别的query samples的在metric space中的Vector与标准的Vector距离最近。
(2)测试过程
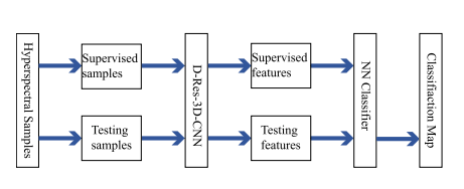
测试数据集的分类主要包括三个步骤:
a.通过预训练的深度残差3-D CNN提取嵌入特征;
b.计算标记样本和待分类样本之间的欧几里德距离;
c.通过NN分类器确定最终标签。
1.3实验结果分析(以PU数据集为例)
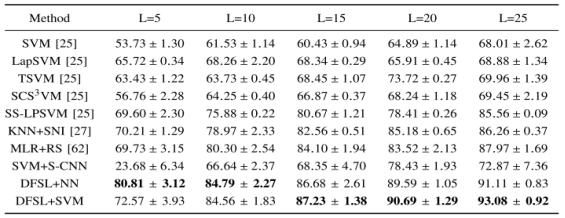
分析这些分类方法的实验结果可以得到:
a.L↑,OA↑
b.OA(semisupervised methods)>OA(standard SVM)
c.SVM+S-CNN在小样本时表现得非常差(23.68%)
d.OA(DFSL+NN、DFSL+SVM)>(other methods),其中DFSL更适合L=5、10这样极少样本的情况。
1.4 结论
论文针对HSI分类样本少的问题,提出了一种DFSL的方法,DFSL主要是训练一个合适的metric space,在这里同类样本距离近,不同类样本距离远,然后用一个简单的分类器就可以完成分类任务。在4个HSI数据集的测试结果表明D-Res-3-D模型能够泛化到测试集,当样本量L很少时,DFSL比传统的半监督分类方法好,当样本量足够时,DFSL跟其他CNN-based分类方法精度相当。
最后
以上就是勤奋日记本最近收集整理的关于Deep Few-Shot Learning for Hyperspectral Image Classification的全部内容,更多相关Deep内容请搜索靠谱客的其他文章。








发表评论 取消回复