1. matlab中自带聚类算法概述
本文简要概述了matlab统计和机器学习工具箱中可用的聚类方法,并给出了其聚类函数。在使用过程中,直接调用该函数即可,十分方便,不得不感慨matlab的强大。
聚类分析,又称分割分析或分类分析,是一种常见的无监督学习方法。无监督学习用于从无标记的输入数据中进行推理,得到数据所属的分类标签,相当于给数据“打标签”。例如,可以使用聚类分析查找未标记数据中的隐藏模式或分组。
聚类分析创建数据组或簇。属于同一个集群的对象彼此相似,属于不同集群的对象彼此不同。要量化“相似”和“不同”,可以使用应用于特定程序和数据集领域的不相似度量(或距离度量)。另外,根据自己的需求,可以考虑对数据中的变量进行缩放(或标准化),以便在聚类过程中给予它们同等的重要性。
具体的,统计和机器学习工具箱提供了这些聚类算法:
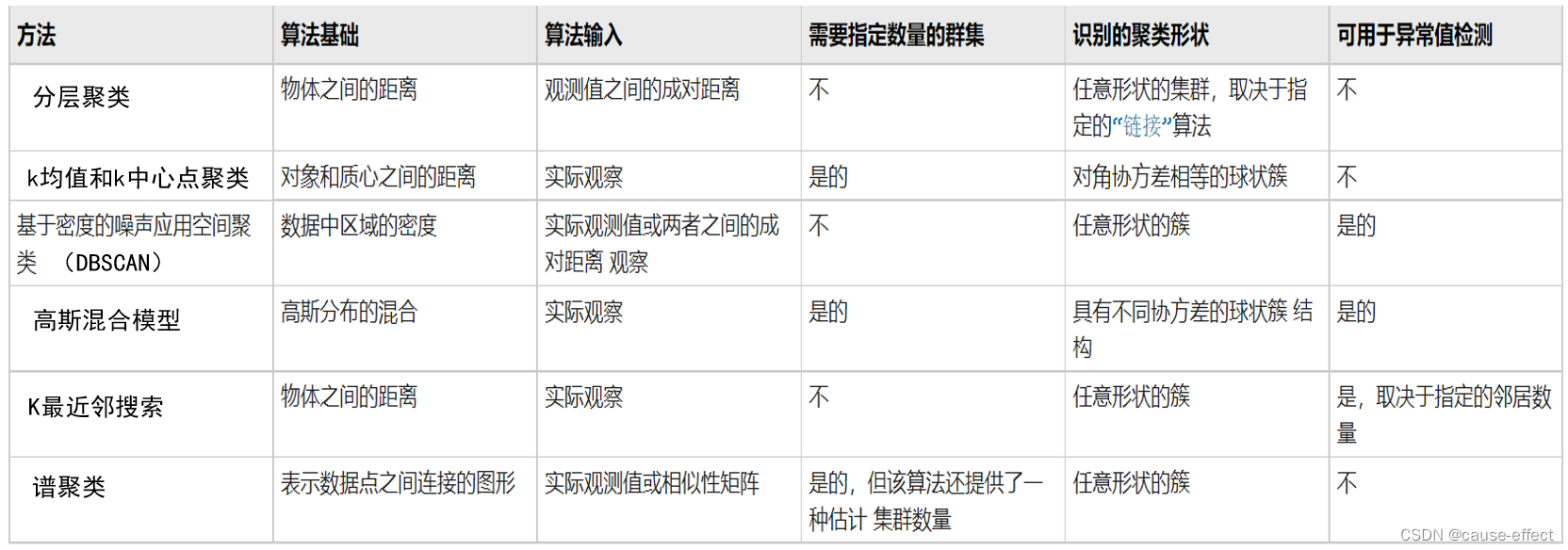
- 分层聚类 Hierarchical Clustering
- k-Means和k-Medoids聚类
- 基于密度的带噪声应用空间聚类 DBSCAN
- 高斯混合模型
- k最近邻搜索和半径搜索
- 谱聚类 Spectral Clustering
2. matlab自带的7种聚类算法介绍与应用
1)分层聚类 Hierarchical Clustering
分层聚类通过创建聚类树或树状图在不同的尺度上对数据进行分组。该树不是单一的集群集合,而是一个多层层次结构,其中一个级别的集群结合形成下一个级别的集群。这种多层层次结构允许您选择最适合您的应用程序的集群级别或规模。分层聚类将数据中的每个点分配到一个聚类中。
使用clusterdata函数即可对输入数据执行分层聚类。Clusterdata函数包含pdist、linkage, 和 cluster 3个函数,可以分别使用它们进行更详细的分析。此外,在分层聚类中,可以利用dendrogram函数绘制聚类树,得到聚类的可视化结果(分层聚类结果图)。关于分层聚类的具体介绍,这里就不再赘述,后续有时间可能会更新更详细的介绍。
T = clusterdata(X,cutoff)
但是我觉得这些已经足够使人了解基本内容,大家可根据自己的需要在matlab中查看与应用。也可以与我交流。
2)k-Means和k-Medoids聚类
k-means聚类和k-medoids聚类将数据划分为k个互斥的聚类。这些聚类方法要求预先指定聚类的数量k。k-means和k-medoids聚类都将数据中的每个点分配到一个群集;然而,与分层聚类不同的是,这些方法基于实际的观察结果(而不是不相似度度量),并创建单一级别的聚类。因此,对于大量数据,k-means或k-medoids聚类通常比分层聚类更适合。
idx = kmeans(X,k)
idx = kmedoids(X,k)
在matlab中,可直接使用kmeans和kmedoids函数分别实现k-means聚类和k-medoids聚类。对于这2种比较简单的聚类算法,应该都比较了解,无需多言。
3)基于密度的带噪声应用空间聚类 DBSCAN
DBSCAN是一种基于密度的算法,可以识别任意形状的簇和数据中的异常值(噪声)。在聚类过程中,DBSCAN识别不属于任何聚类的点,这使得该方法对于基于密度的离群点检测非常有用。与k-means和k-medoids集群不同,DBSCAN不需要预先知道聚类的数量,这是非常重要的一点。
idx = dbscan(X,epsilon,minpts)
在matlab中,可直接使用dbscan函数对输入数据矩阵或观察结果之间的成对距离执行聚类。关于DBSCAN更详细的介绍,可以查看我之前的博客:基于密度的聚类算法(1)——DBSCAN详解。
4)高斯混合模型
高斯混合模型(GMM)作为多元法向密度分量的混合物形成簇。对于给定的观测,GMM为每个成分密度(或聚类)分配后验概率。后验概率表明观察结果有一定概率属于每一个聚类。GMM可以通过选择后验概率最大的成分作为观察的指定聚类来进行硬聚类。您还可以使用GMM来执行软聚类或模糊聚类,方法是根据聚类的评分或后验概率将观察值分配给多个聚类。当聚类具有不同的大小和不同的相关结构时,GMM可能是比k-means聚类更合适的方法。
GMModel = fitgmdist(X,k)
idx = cluster(GMModel,X)
在matlab中,使用fitgmdist使gmdistribution对象适合所分析的数据。还可以使用gmdistribution通过指定分布参数来创建GMM对象。当有一个合适的GMM时,可以使用cluster函数对数据进行聚类查询。
5)k最近邻搜索和半径搜索
k近邻搜索查找数据中与一个或一组查询点最近的k个点。相比之下,半径搜索查找数据中与查询点或查询点集合在指定距离内的所有点。这些方法的结果取决于您指定的距离度量。
在matlab中,可直接使用knnsearch函数查找k个最近的邻居,或者使用rangesearch函数查找输入数据指定距离内的所有邻居。还可以使用训练数据集创建搜索器对象,并将对象和查询数据集传递给对象函数(knnsearch和rangesearch)。
Idx = knnsearch(X,Y)
6) 谱聚类 spectral clustering
谱聚类是一种基于图的聚类算法,用于在数据中找到k个任意形状的聚类。该技术涉及用低维表示数据。在低维中,数据中的集群分离得更广,这使得能够使用k-means或k-medoids聚类等算法。这个低维是基于拉普拉斯矩阵的特征向量。拉普拉斯矩阵是一种表示相似图的方法,它将数据点之间的局部邻域关系建模为无向图。
在matlab中,可直接使用spectralcluster函数对输入数据矩阵或相似图的相似矩阵执行谱聚类。Spectralcluster函数要求预先指定聚类的数量。此外,谱聚类算法也提供了一种估计数据中聚类数量的方法,具体的可在matlab中查看应用。
idx = spectralcluster(X,k)
3. 7种聚类算法的总结与比较
最后
以上就是慈祥小鸭子最近收集整理的关于matlab统计与机器学习工具箱中的7种聚类算法1. matlab中自带聚类算法概述2. matlab自带的7种聚类算法介绍与应用3. 7种聚类算法的总结与比较的全部内容,更多相关matlab统计与机器学习工具箱中的7种聚类算法1.内容请搜索靠谱客的其他文章。








发表评论 取消回复