目录
一、模型调参
手动调超参数
多次调参的管理
机器调参与人调参的成本比较
自动调参(AutoML)
总结
二、超参数优化
在搜索空间中选择超参数
HPO算法有哪些
Black-Box
Multi-Fidelity
总结
三、网络架构搜索
Neural Architecture Search (神经架构的搜索)
早期NAS的工作:通过强化学习(Reinforcement Learning)
One-shot 方法
可微的结构搜索(Differentiable Architecture Search)
缩放CNN
最近的研究方向的重点
总结
一、模型调参
手动调超参数
选取一个好的超参数得到一个好的结果是比较花时间的过程
一般会从一个好的基线开始。(Baseline)
基线是什么?
- 选一个质量比较高的工具包,其中设了不错的参数,虽然可能对我们的问题不算是最好的,但是是一个不错的开始点;
- 如果要做的东西是跟某些论文相关,可以看看该论文里面的超参数是什么(有些超参数跟特定的数据集有关),这些超参数在一般的情况下都不错
有了比较好的起始点之后,调整超参数后再重新训练模型,再去看看验证集上的结果(精度、损失)
- 一次调一个值,多个值同时调可能会不知道谁在起贡献
- 看看模型对超参数的敏感度是什么样子【没调好一个超参数模型可能会比较差,但是调好了也只是到了还不错的范围】
- 想对超参数没那么敏感的话,可以使用比较好的模型【在优化算法中使用Adam(对有些超参数没那么敏感,调参会简单很多)而不是SGD(在比较小的区域比较好)】
多次调参的管理
- 每次调参一定要做好笔记【任何调过的东西,最好将这些实验管理好】(训练日志、超参数记录下来,这样可以与之前的实验做比较,也好做分享,与自己重复自己的实验)
- 最简单的做法是将log记录到txt上,把超参数和关键性指标(训练误差)放在excel中【适合实验没有那么多的参数】
- Tensorboard,tensorflow开发的一个可视化工具
- weight&kbias:允许在训练的时候用他们的API,然后把实验记录下来后上传到他们的网页上,就可以进行比较
重复一个实验是非常难的
- 开发的环境:用的硬件是什么、新旧GPU可能会有点不一样;用的库的版本(Python本身也要去注意)
- 代码开发要做好版本控制(可以将每个版本的代码放在同一个地方 需求的库也放在这里)
- 要注意随机性(改变了随机种子,模型抖动比较大的话,说明代码的稳定性不是很好)【要避免换了个随机种子后,结果浮动比较大。这样的话,尝试能不能将不稳定的地方修改一下,实在不行就将多个模型做ensemble】
机器调参与人调参的成本比较
- 在小任务上很多时候已经可以用机器来做了(到最后可能都是用机器来调参【人的成本在增加】)
- 训练树模型在CPU上花10min 大概花$0.4
- 训练神经网络在GPU花1h左右 大概花$5
- 跟人比(人大概花十天左右),算法训练1000次调参数,很有可能会打败人类(90%)
自动调参(AutoML)
- AutoML在模型选择这一块做的比较好
- 超参数的优化(HPO)【比较通用】:通过搜索的方法,找到一个集合去调整模型的超参数
- NAS(Neural architecture search)【专注于神经网络】:可以构造一个比较好的神经网络模型,使得能够拟合我们的任务
- 每个年代都有最大的技术痛点,当前AutoML可能是技术瓶颈。
总结
超参数调优的目的是找到一组好的值
数据预处理比较耗时
使用算法进行调优是一种趋势
二、超参数优化
在搜索空间中选择超参数
 backBone:【合理的区间:MobileNetV2_0.25,MobileNetV3_small,MobileNetV3_large,ResNet18_V1b,ResNet18_V1b,ResNet34_V1b,ResNet50_V1b,ResNet101_V1b,VGG16_bn,se_ResNext50_32*4d,ResNest50,ResNest200】(从模型的小到大排序的一个categorical(从一堆东西里面随机挑一个出来)的分布)根据自己的任务来选择,要求耗时比较严的话,可以选择比较小一点的网络;要求比较好的精度的话,可以选择比较大的网络;
backBone:【合理的区间:MobileNetV2_0.25,MobileNetV3_small,MobileNetV3_large,ResNet18_V1b,ResNet18_V1b,ResNet34_V1b,ResNet50_V1b,ResNet101_V1b,VGG16_bn,se_ResNext50_32*4d,ResNest50,ResNest200】(从模型的小到大排序的一个categorical(从一堆东西里面随机挑一个出来)的分布)根据自己的任务来选择,要求耗时比较严的话,可以选择比较小一点的网络;要求比较好的精度的话,可以选择比较大的网络;- learning rate:【合理的区间:1e-6,1e-1】(是一个log-uniform(先把值做一次log,将值落到小的区间内,在这个区间内均匀的随机取,取完之后再做指数回去))这个东西可以在比较大的区间内选取一些数;
- batch size:【合理的区间:8,16,32,64,128,256,512】,做小批量随机梯度下降时取的批量的大小,采用的也是categorical,一般值会取2的n次方的整数,这样的话会在做计算的时候比较方便(矩阵是2的某个次方,计算的线程数也是2的某个次方,如果不能整除最后计算性能会打一点折扣),但是从优化的最后那个收敛来说其实取什么数值都差不多;
- momentum:【合理的区间:0.85,0.98】(是一个uniform的分布,就是随机采样取一个值出来);
- weight decay:【合理的区间:1e-6, 1e-2】,是一个正则化的东西;
- detector:【合理的区间:faster-rcnn,ssd,yolo-v3,center-net】,在目标检测时用的是什么算法;
这些值的选取需要有领域知识才能做很好的选取,上面这些搜索空间具有一定的通用性(换一个不同的数据集,很有可能比较好的超参数也在这个搜索空间中)。 基本上搜索空间不可以太大(搜起来比较贵,指数级增长),也不能太小(可能会找不到想要的值,导致效果比较差)。
HPO算法
- black-box:每次一个训练任务 当作一个黑盒(每挑一组超参数,然后拿去训练,然后看模型的关键的衡量指标(精度、误差),再去选下一个怎么做)【可以适用于各种机器学习算法】;
- Multi-fidelity(讨论比较多):因为训练一个模型太贵了(数据集很大,完整跑完很耗时间,还要试很多的话,太耗时了),所以可以不用把整个数据集给跑完(不关心最后的精度怎么样,只关心超参数之间的效果怎么样);
以下是做法:
- 对数据集下采样(超参数如果在小数据集上效果比较好的话,在完整数据集上也不差);
- 将模型的变小(SGD的超参数在resnet18上效果差不多的话,在resnet152上也可能是不错的);
- 在训练时会对数据扫很多遍,但是对于不好的超参数来说,它训练一遍就知道它的效果怎么样了,所以不需要等到完全训练完,看到效果不好的,及时停止;
- 上面三点就是说,通过比较比较便宜点的但又跟完整训练有关系的任务来近似一个值,然后对超参数进行排序;
Black-box 虽然会贵一点但是任务计算量比较小或优化算法不知道的话,这个方法会比较好;Multi-fidelity知道一些任务的细节,可以将任务弄小一点,这样每次试验的时候成本没有那么高。
HPO算法有哪些
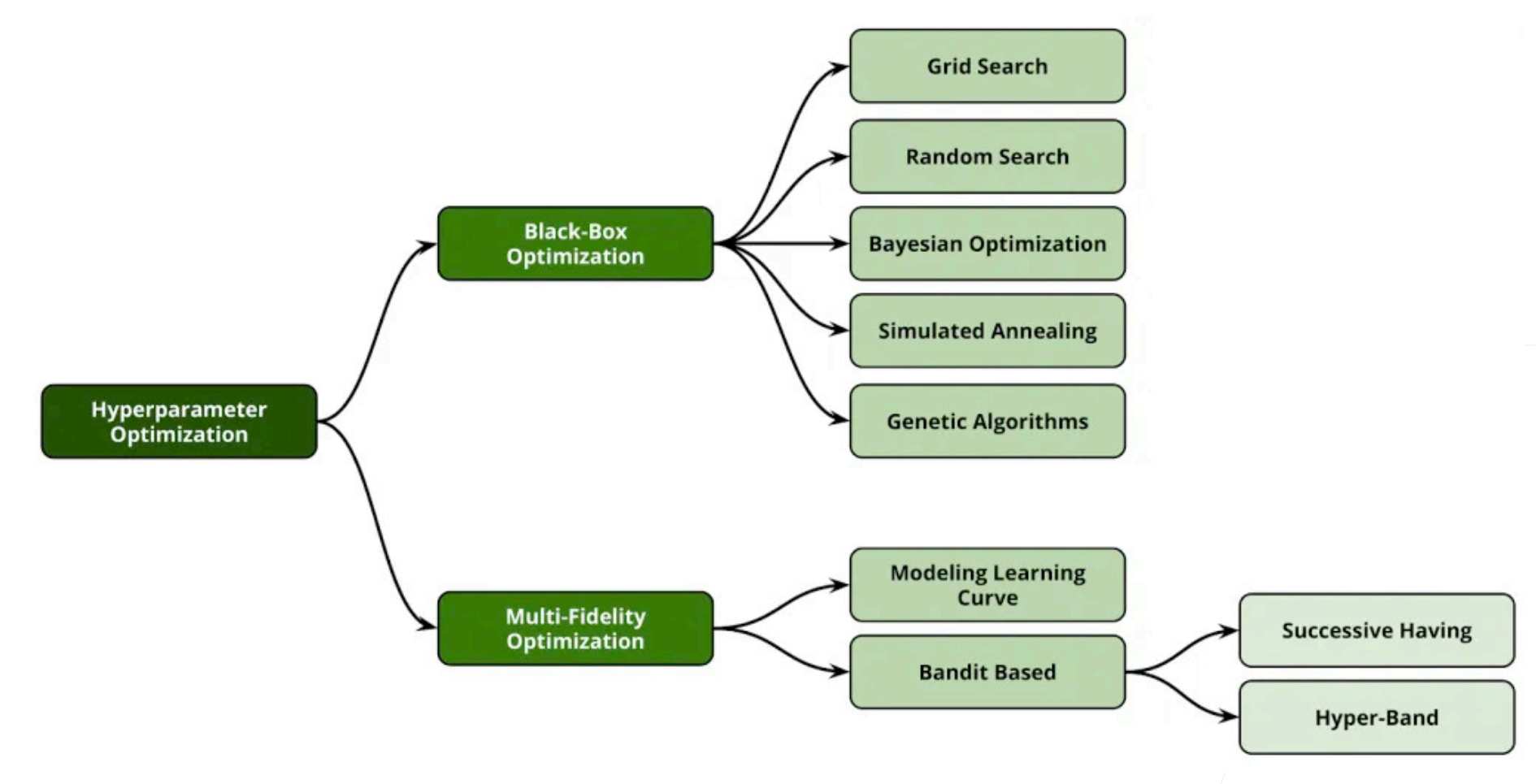
Black-Box:
- Grid Search:
- Random Search:
- Bayesian Optimization:
- Simulated Annealing
- Genetic Algorithms
Multi-Fidelity:
- Modeling Learning Curve
- Bandit Based(Successive Halving & Hyperband)
Black-Box
Grid search(网格搜索):
- 其实就是一个暴力穷举,对search space中的每一个config(每一组值),拿去训练一次然后去评价一次,把最好的结果返回出来,也就是把所有的组合过了一遍之后,再把最好的值返回出来。
- 只要搜索空间足够好,就能覆盖到比较好的值,并且一定能找出来;
- 特点就是所有都会评价(Evaluate)一遍,并且保证能找到最好值,但是有个很明显的缺点,搜索空间随着超参数的变多会指数级的增加,也就是“维度诅咒”。但是如果算法足够简单,就那几个参数选择不大的话,当然预算足够的话,也是可以的。
Random Search(随机搜索):
- 随机搜索跟前面的有点类似,虽然也是有个search space 但是 我只选择n次,每一次在搜索空间中选出一个config,拿过去训练,再得出最好结果;
- 次数n保证了我们的这个算法一定会停,可以由我们自己选取,n取过大就跟网格搜索差不多,n取过小,可能并不是那么好用,就n要取得合适;
- 一般来说,随机搜索时一个非常有效的办法,再没有更好的想法之前可以尝试随机搜索
- 其实也可以不选n,可以是等到差不多的时候(感觉精度没有什么进展)直接把它停掉
网格搜索可能会出现精度平稳之后,精度还会上升的情况;但是随机搜索很少会出现这样的情况,除非没有随机好。

Bayesian Optimization(贝叶斯优化):
- 在实际中用的不是那么多,因为相对来说比较复杂,但是是比较活跃的研究方向;
- BO(贝叶斯优化),是会学从一个超参数HP到目标函数(精度、损失)的一个函数【机器学习是数据到我们想要东西之间的一个映射的关系】,这里是说每一个数据点是一个模型;
- 就每做一个实验就会得到一个数据点,然后再拟合一个曲线出来;它在选下一个超参数去试的时候,会根据当前的评估,来的出数据点;
- Surrogate模型:就是拟合超参数与目标函数之间关系的模型,可以采用概率的一些regression模型,可以使用随机森林或者是高斯过程;
- 具体有张图:
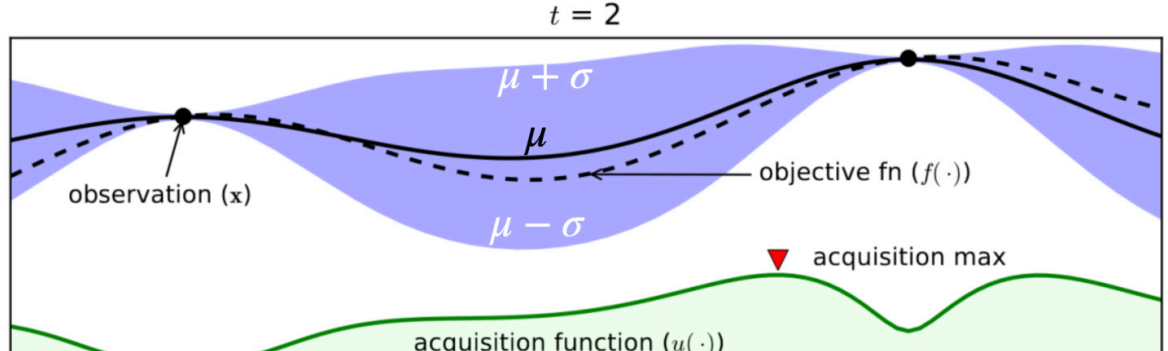
- 随着采样的越来越多,对整个模型的进步会越来越准。
- 在一开始的时候其实跟random search差不多(获取函数还不够好,就只能随机挑值来做),再后期的时候(建模比较准)会比较好一点;
- 随机搜索是并行的算法,贝叶斯优化是顺序的算法(采下一个点需要等上一个完成才行)
- 到底是什么时候会好一点,如果预算不够的话(搜的质量跟随机搜索的差不多),这样是划不来的;如果贝叶斯能在前期就做的比随机搜索好,那这样的划得来的。
- 通常贝叶斯优化比随机搜索好的时候,一般来说是模型比较简单(模型比较简单的话,随机搜索也不差),或者是超参数的那个空间不那么复杂,或者有足够多的样本(需要很多的预算)
Multi-Fidelity
以下这两个算法在现实生活中用的比较多
Successive Halving:
有很多超参数的选择,但是大部分超参数没有必要把它训练完,所以只需要把最靠谱的超参数给训练完就行了,剩下的早期就被淘汰了
首先选取n个超参数,然后每个超参数训练m个epoch(把数据扫个m遍)【通常n会取大一点,m取小一点】;然后把好的超参数留下一半,剩下的一半不要,epoch还是m;在下一次迭代,超参数还是留下一半,而epoch变成了原来的两倍;这样的过程一直重复,直至留下一个超参数为止。【这样也就是说靠谱的超参数我们给多点资源】
看图解释算法:
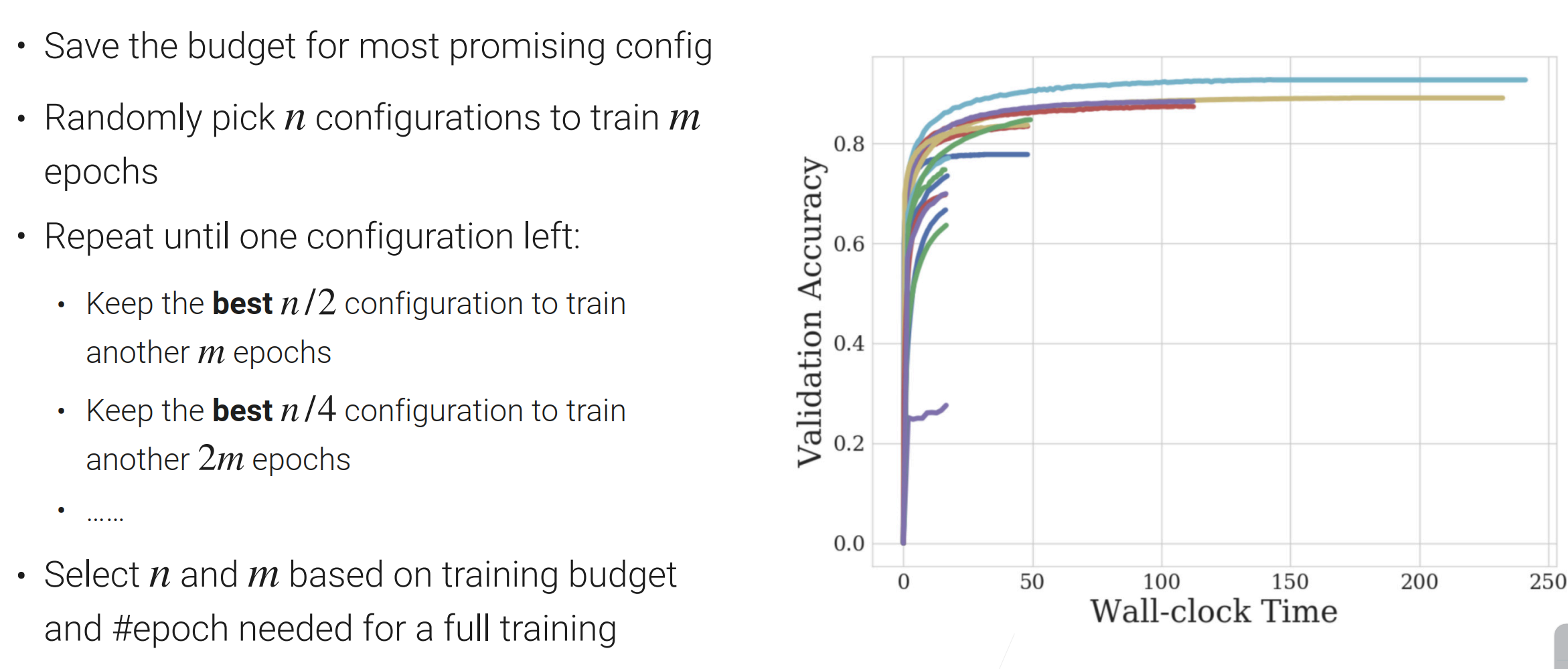
n与m的选取要基于预算而言的(预算多n就取大一点);但是n与m不好取,这其实是一个exploration和exploitation的过程,在下一个算法会做改进。
Hyperband:
- 这个是在HPO上用的比较多的算法,所以我们在实践中是可以使用它的;
- 在Successive Halving中n是一个exploration的过程(n越大每次试的东西就越多),而m是exploitation(m取决于每一个参数说跑的时间,跑的越长也就看的越准);nm代表的是每一次迭代中计算复杂度的多少;在计算的预算是固定的时候,nm应该是一个固定的数,所以在SH(Successive Halving)中每次都要调这个东西;
- Hyperband就是跑多个SH,一开始会选大一点的n和小一点的m,但后面会逐渐的讲n变小m变大;
- 看图解释算法:
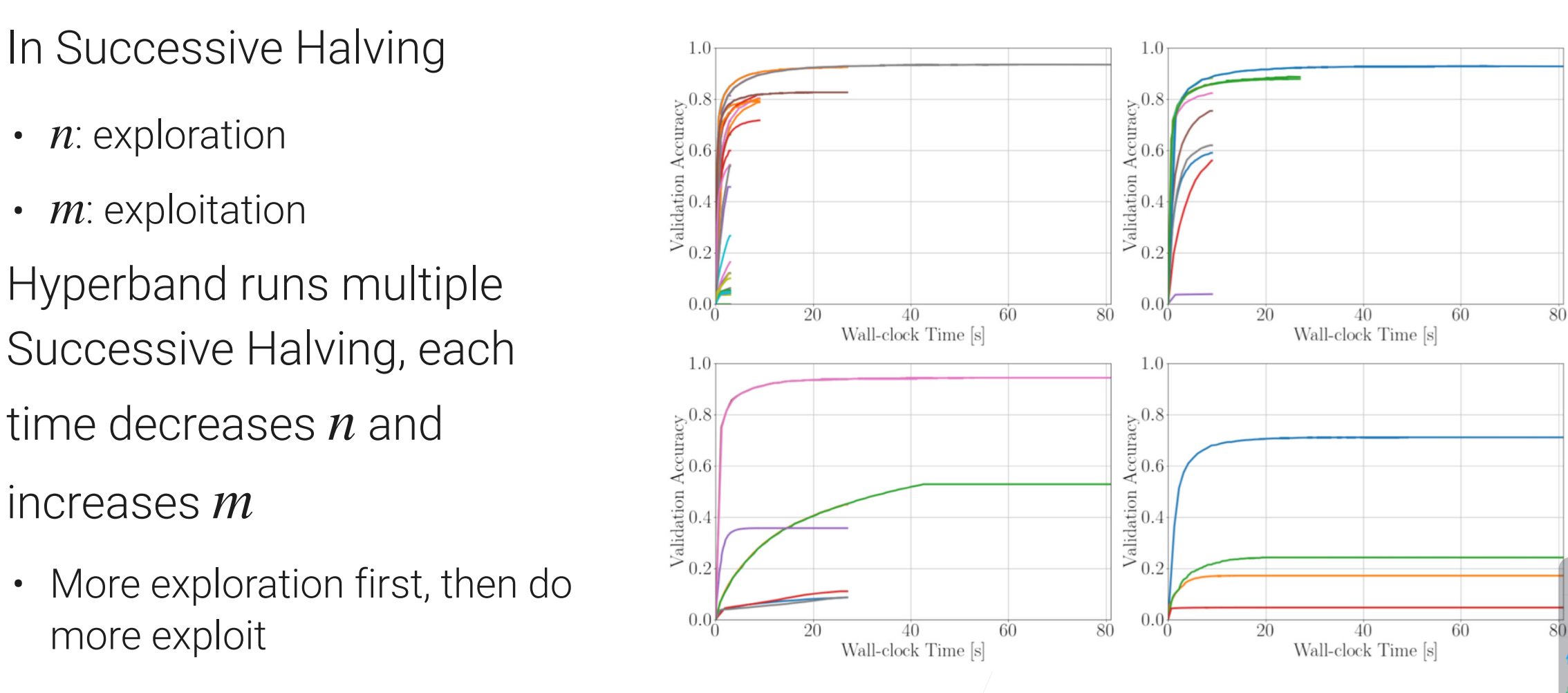
- hyperband的好处是说,对n与m的选取不会那么敏感(会多跑几次,多几个组合),这样就不用怎么操心n还有算法在exploration与exploitation的权衡,这个算法都算了一遍。
总结
- 在HPO中有两种主流的算法:黑盒与Multi-fidelity
- 黑盒:一个超参数进去一个模型出来,然后知道模型的好坏,里面有暴力搜索,随机搜索(用得比较多的,没有什么特别好的方法的话,用这个准没错),和贝叶斯优化(研究的一个大方向)
- Multi-fidelity(通常在深度学习用得比较多):如果训练时间过长会选择一个相对来说比较小的做法,包括采样一个小数据集,小版本的网络,具体说的算法是SH与Hyperband,这些是说,在训练了一些轮数的时候,把不靠谱的给淘汰掉;
- 注意一些Top performers(看看比赛中那些做的很好的人是怎么做的,看看那些算的最高分的论文在超参数的选择都差不多),在跑过很多数据集之后,会发现总有那么几个模型和几组参数在各个地方都跑的比较好,所以很有可能试那几个就行了。
三、网络架构搜索
Neural Architecture Search (神经架构的搜索)
神经网络有不同类型的超参数:如
- 网络的拓扑结构(ResNet、MobileNet(通过特殊的卷积层,把整个计算复杂度降低,使得在手机或其他低功耗设备上算的比较快)、架构的层数等);
- 具体层的参数(卷积层中核窗口的大小、输出的通道数是多少、全连接层或RNN中输出的隐藏单元的个数)。
NAS的作用:尽量的使得整个网络的设计能够自动化
- 甚至可以从零开始设计一个神经网络;
- 给出一些网络的选择,选取最优的出来(有点像HPO);
NAS需要关心的东西:
- 整个搜索的空间是什么样子的(整个神经网络的超参数【SGD的或是其他的超参数不关心】);
- 怎么样在搜索空间中搜索;
- 怎么判断网络的好坏。
基本流程:设计一个搜索空间 -> 设计搜索策略 -> 每次采样一个架构出来,查看其性能 -> 反馈回搜索策略让策略更新。
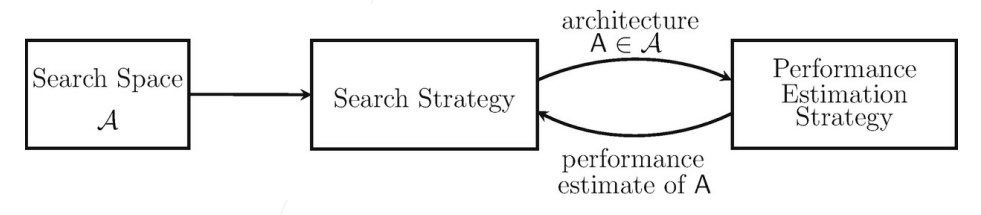
早期NAS的工作:通过强化学习(Reinforcement Learning)
主要思想:
- 将网络的超参数表示成文本;
- 用一个RNN(可以对一个时序序列建模)来生成不一样的整个网络架构;
- 生成一个之后对这个网络进行训练来算这个网络的验证精度;
- 将结果反馈给RNN网络;
- 然后RNN网络利用反馈回来的信息进行更新;
这个整个环用的就是RL(强化学习)【Agent做了一个行动,每行动一次就看下环境给出的反馈,通过反馈更新Agent】,好处:不管是什么套上RL之后可以在整个框架上显得比较优美的,坏处:十分昂贵。
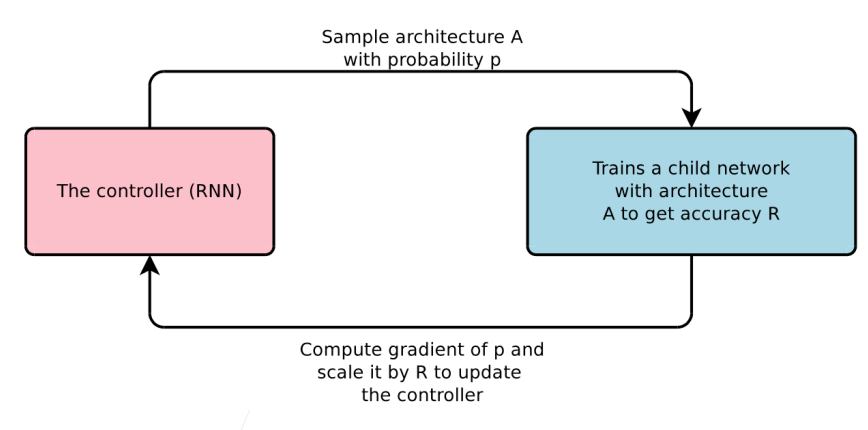
最开始的工作用了 2000 GPU per days (10个GPU训练200天) 来做的,这样才能在一个小的数据集上得到一个不错的结果;后续有很多工作是帮最原始的工作加速的:在训练网络时不要跑完整个网络;或者是在建立架构的时候重用上一个网络的一些参数,不要从随机开始【相关工作:EAS,ENAS】。
One-shot 方法
- 学习一个架构,既要学习整个网络的架构,也要学习模型里的超参数(训练一个特别大的模型,里面包含了想要看的模型的架构,然后将这个模型训练一遍,里面的子模型就是我们要考虑的架构,这样既能得到他的性能又可以得到他的参数)。
- 然而上面的方法很昂贵,甚至可能 不能放入GPU的内存中,一般来说很难将网络训练的收敛;
- 一般的做法是只关心候选架构的排名(两个架构相互比较判断其好坏,不需要知道他的精度是多少),所以可以用一个近似的指标,在训练一些轮次之后看一下精度就好了,然后把好的架构挑出来(不需要是最好的)从头开始完整的训练一遍。
可微的结构搜索(Differentiable Architecture Search)
训练一个很大的模型,具体取一条子图可能会比较难选,我们可以通过把选谁做成一个可以学习的参数;具体来说,是通过softMax 的操作来进行子路的选择;
具体看图:
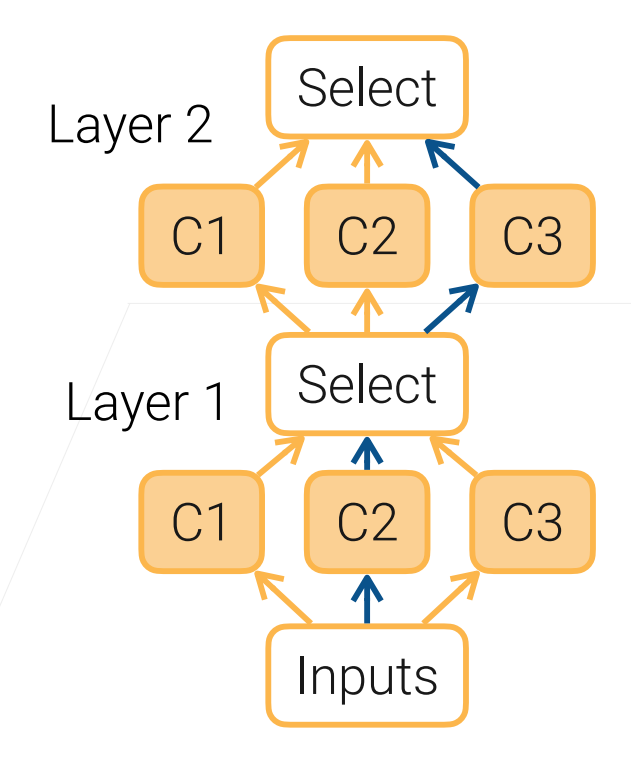
这个方法也就是通过学习来选择哪条路比较好,这样子可以避免要不断去看哪条路是最好的;
对这个方法的改进,可以对softmax 加上一个温度使得它更能趋向于0或1,而不是再0与1的中间值徘徊;
如一个更复杂的版本,DARTS,基本上使用三个GPU训练一天能训练到一个不错的精度。
缩放CNN
- EfficientNet就是用这个的方法搜出来的;这个方法有局限性:只对于一小部分的神经网络使用
卷积神经网络可以通过三种方法来调节:
- 深度:可以加更多层进去,可以将层数乘上个系数翻倍;
- 宽度(卷积层输出的通道):让输出通道翻倍
- 大的输入:将输入的图片弄大一点;
- EfficientNet是说,尽量不去动任何一个东西,你要三个东西一起动,具体的来说:
- 有四个可调的参数 α β γ φ;
- 深度可以变换 α的φ次方倍;宽度就是变换 β的φ次方倍;图片大小(分辨率)就是变换γ的φ次方倍;这些都要取整;
- α β γ 是要选择 α * β^2 * γ^2 ≈ 2 (因为整个神经网络的计算复杂度是深度 * 宽度^2 * 输出数据的高宽^2 ),但φ取1时,整个CNN的计算复杂度就会翻一倍;
- α β γ 是会手动调好的,最后只需调φ这个值,通过调整这个来放大或缩小计算复杂度;
- 从图看效果:
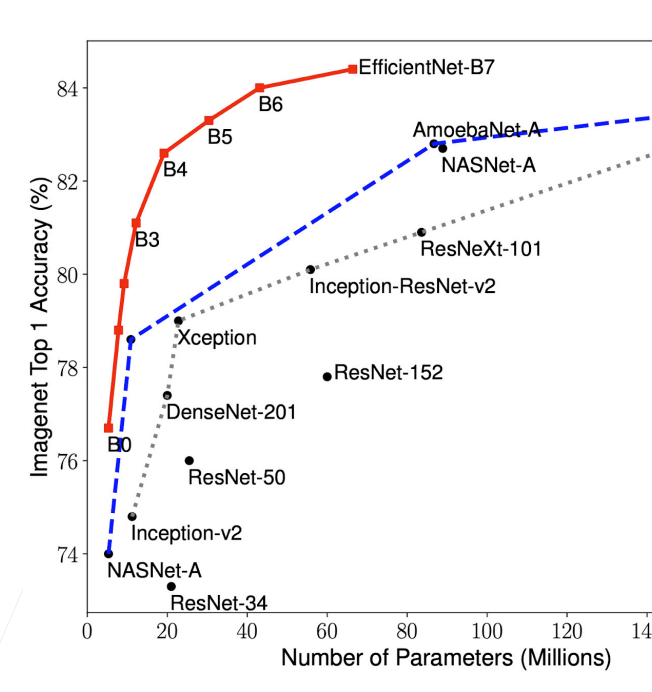
最近的研究方向的重点
- 搜出来的结果是否能解释:EfficientNet搜出来的还好一点,之前的搜出来的网络架构会没那么对称,不那么模块化,参数也很奇怪;
- 跟人去比较,意义不大;但是NAS一个不错的应用场景是在边缘设备上(手机等)
- 手机是越来越强了,神经网络可以跑在手机上;
- 神经网络跑在手机上,这样延迟会低,数据隐私会比较好(数据放在手机上,不用送去服务器);
- 边缘设备的计算性能是要考虑的点(高低端的手机CPU/GPU/DSP(数字处理信号单元)的差距比较大);功耗也是需要考虑的点;
- 在不同的设备,功耗有限制的情况下,要如何设计网络架构:对不同的手机,去自动调一个网络让在模型在手机上保证延迟和功耗的效果也不错【选一个网络架构,然后去看它验证集损失 乘以 这个网络在该设备上跑一遍的延迟的log的β次方;这个是可以调的,看看是更关注延迟还是更关注精度】。
- 更大的研究方向是说让整个机器学习的流程更加自动化。
总结
- NAS是搜索一个神经网络架构,可以有一个定制化的目标(最大化精度,或者满足对延迟的需求),可以在特定的硬件上;
- NAS现在用的还算比较多的,上面讲到的在CNN中可以将深度,宽度和输入的分辨率合起来调,基本上是调一个超参数就可以得到我们想要的不同精度下和不同性能下的各个不错的组合
- 可以使用可导的one-hot 网络来训练一个特别大的架构,里面包含了我们想要的超参数,然后通过一个softmax操作,让他去学习一个权重来决定哪一条路最好。
最后
以上就是刻苦台灯最近收集整理的关于机器学习--模型调参、超参数优化、网络架构搜索 一、模型调参二、超参数优化三、网络架构搜索的全部内容,更多相关机器学习--模型调参、超参数优化、网络架构搜索 一、模型调参二、超参数优化三、网络架构搜索内容请搜索靠谱客的其他文章。








发表评论 取消回复