
各位知乎儿大家好,这是<EYD与机器学习>专栏迁移学习系列文章的第三篇文章,在上次的文章中我们介绍了一个迁移学习与深度学习结合的算法框架(<EYD与机器学习>迁移学习:Domain Separation Networks),这次我们依旧为大家介绍一篇论文:Domain-Adversarial Training of Neural Networks(DANN)[1]。这篇文章可以说是最早将对抗网络的思想引入到迁移学习领域中的,并且引发了很大的反响。后续有很多知名的研究者都跟进,在这篇文章的基础上进行了一些列改进和拓展。
一、简介
与上一次介绍的文章不同,在这篇论文中,作者的工作重心放在了之前提到的迁移学习三个核心问题之一:How to transfer。其实作者在这篇文章中做的是域适配的工作(Domain adaptation),下面我们先简单介绍一下Domain adaptation 的主要目的是什么。
想象一个分类任务,假设现在我们手里有源域数据和目标域数据,其中源域数据是丰富并且有标记的,而目标域数据是充足但是没有标记的,但是源域和目标域的特征空间和标记空间相同。很显然,我们可以轻松的利用源域数据为源域建立一个分类器,但是由于目标域数据本身没有标记,那么我们无法通过常规方法为目标域构建分类器,这时候Domain adaptation 就可以发挥作用了,具体过程如下图所示(手绘图,希望大家能看懂):
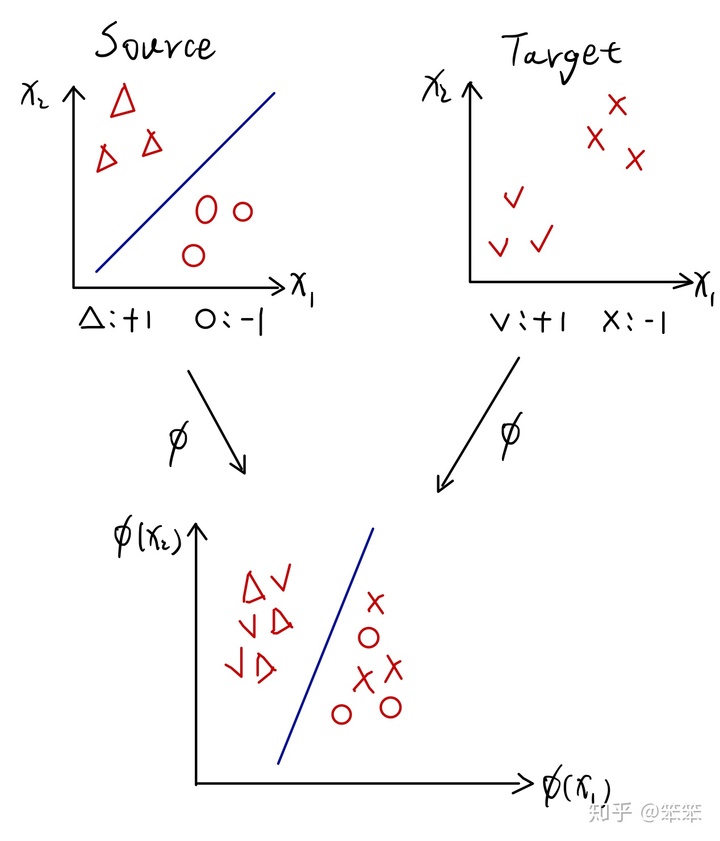
从图中可以看到,源域和目标域的特征都是{
这里最关键的一点就是在同一个特征空间中源域和目标域的分布不同,假设两者分布相同,那么我们就可以直接利用源域分类器对目标域数据进行分类了。因此,Domain adaptation的思想就是通过消除源域和目标域的分布差异,使得源域数据和目标域数据能同时被分开。在图一中,通过映射函数
二、Domain-Adversarial Training of Neural Networks(DANN)
在上面的 Domain adaptation 过程中最关键的一点就是如何做到将源域样本和目标域样本混合在一起,并且还能保证被同时分开,DANN的主要任务也是做到这一点。
首先介绍一下DANN的应用背景:源域数据充足并且有标记,目标域数据充足但是无标记,源域和目标域的特征空间和标记空间相同,任务是借助源域数据对目标域数据进行分类。
DANN的结构如下:
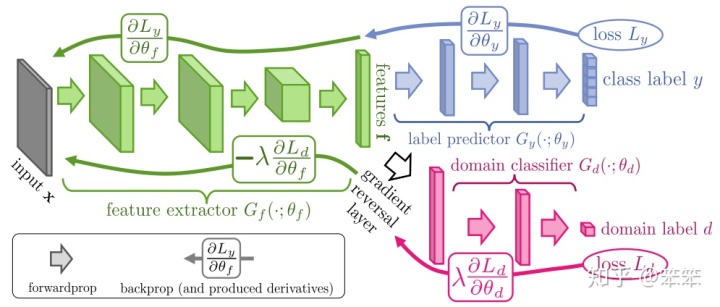
网络分为三部分:
- Feature extractor(特征提取器)
特征提取器的功能包括两部分:(1)提取后续网络完成任务所需要的特征。(2)将源域样本和目标域样本进行映射和混合。
- Label predictor (类别预测器)
利用Feature extractor提取的信息对样本进行分类。
- Domain classifier(域分类器)
判断Feature extractor提取的信息来自源域还是目标域
可见,DANN中的对抗思想蕴含在特征提取器和域分类器中。其中特征提取器的作用就像是图1 中的映射函数
特征提取器提取的信息会传入域分类器,之后域分类器会判断传入的信息到底是来自源域还是目标域,并计算损失。在反向传播更新参数的过程中,域分类器和特征提取器中间有一个梯度反转层(Gradient reversal layer),也就是说域分类器的训练目标是尽量将输入的信息分到正确的域类别(源域还是目标域),而特征提取器的训练目标却恰恰相反(由于梯度反转层的存在),特征提取器所提取的特征(或者说映射的结果)目的是是域判别器不能正确的判断出信息来自哪一个域,因此形成一种对抗关系。可见,当域分类器不能将接收的信息正确分为源域样本还是目标域样本时,特征提取器的任务就圆满完成了,因为此时源域样本和目标域样本在某个空间中已经被混合在一起不能分开了。
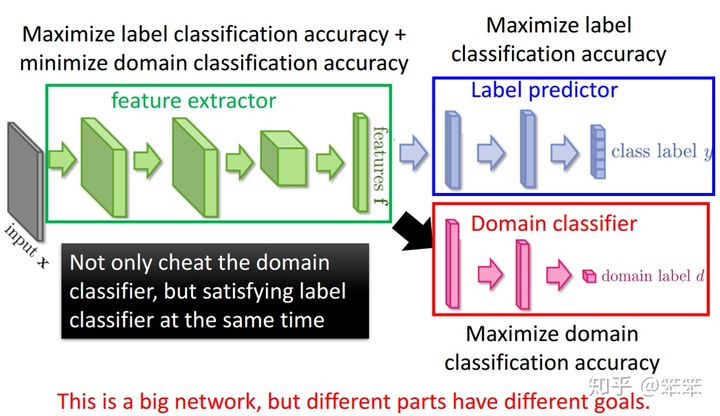
然而上述过程存在一个问题,我们最终的目的是对目标域样本进行分类,那么我们如何保证特征提取器提取的信息是能够用来分类的呢?假如无论输入什么样本给特征提取器,它都输出一个单位向量,这样依旧可以“骗过”域分类器,但是却无法完成后续的分类工作。
这时就要靠Label predictor (类别预测器)了,因为源域样本是有标记的,所以在提取特征时不仅仅要考虑后面的域判别器的情况,还要利用源域的带标记样本进行有监督训练从而兼顾分类的准确性。
综上,当把特征提取器、域分类器和类别预测器都训练完成后,就可以做到把源域和目标域混合在一起并且进行分类了。下面这幅图对整个流程进行了解释:
下面我们来看一下三个部分各自在训练时是如何计算的。具体的,以单隐层为例,对于特征提取器就是一层简单的神经元(复杂的任务中就是用多层,或者使用卷积层):
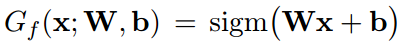
对于类别预测器(复杂任务中需要换成更深的网络进行映射和分类):
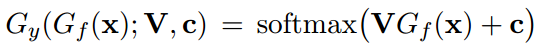
类别预测器损失函数:
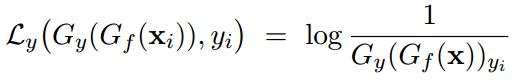
对于域分类器:
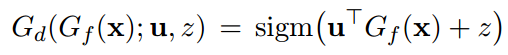
域分类器损失函数:
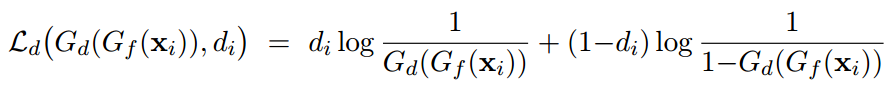
总体的损失函数就是:
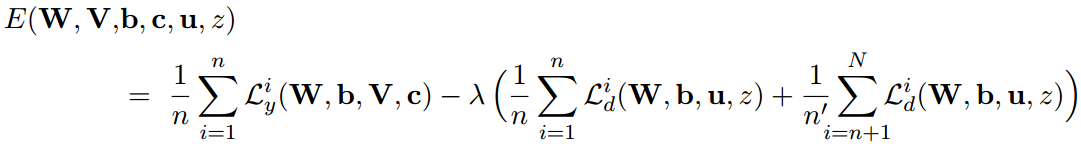
迭代时:
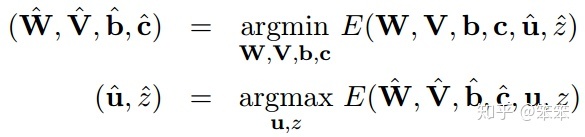
上面的单隐层例子中网络虽然简单,但是作者还是证明了即使是这种简单的网络还是能完成一些工作的。在文章后面作者使用了更加复杂的网络,在MNIST和MNIST-M这两个数据集上进行了实验,可以得到如下的对比图:

MNIST和MNIST-M都是十个类别,在图4 的(a)中,两个数据集还没有进行域适配,可以看出虽然各个类别之间是独立的,但是源域样本(蓝色点)和目标域样本(红色点)却是分开的,没有办法对没有标记的目标域进行分类。在图4的(b)中,经过域适配之后,各个类别不仅是独立的,而且源域样本和目标域样本在该空间中还是混合在一起的,这样就可以实现同时分类了。
三、总结
DANN虽然时间过去了的比较久(2016年发表),但是这种利用对抗来进行域适配的思想却被大家广泛使用。它更像是迁移学习领域的一个框架,后面不断有人向里面添加各种具有定向功能的网络来完成专门的任务。不过对于DANN这种网络而言,训练难度会比较大,而且很难从单源域拓展到多源域,这也是我们后面需要解决的问题。
本次文章中如果有哪些错误或者不严谨的地方,希望大家批评指正,后续我们会继续向大家介绍关于迁移学习的文章。
——Double_D编辑
参考文献
[1]
http://graal.ift.ulaval.ca/public/dann/ganin15a.pdfgraal.ift.ulaval.ca最后
以上就是俏皮曲奇最近收集整理的关于基于特征的对抗迁移学习论文_<EYD与机器学习>迁移学习:DANN域对抗迁移网络...的全部内容,更多相关基于特征内容请搜索靠谱客的其他文章。








发表评论 取消回复