HDFS分布式文件系统
学习目标:
1.1 了解HDFS的基本概念
1.2 掌握HDFS特点
1.3 掌握HDFS的构架和原理
1.4 掌握HDFS的Shell和JavaApi操作
学习内容:
1.1 HDFS的基本概念
HDFS(Hadoop Distributed File System)是一个易于扩展的分布式文件系统,运行在成百上千低成本的机器上。它与现有的分布式文件系统有许多相似之处,都是用来存储数据的系统工具,而区别在于HDFS具有高度容错能力,意在部署在低成本机器上。HDFS提供对应用程序数据的高吞吐访问,主要用于对海量文件信息进行存储和管理,也就是解决大数据文件的存储问题。
(1)NameNode(名称节点)
NameNode是HDFS集群的主服务器,通常称为名称节点或者主节点。一旦NameNode关闭,就无法访问Hadoop集群。NameNode主要以元数据的形式进行管理和存储,用于维护文件系统名称并管理客户端对文件的访问;NameNode记录对文件系统名称空间或其属性的任何更改操作;HDFS负责整个数据集群的管理,并且在配置文件中可以设置备份数量,这些信息都由NameNode存储。
(2)DataNode(数据节点)
DataNode是HDFS集群中的从服务器,通常称为数据节点。文件系统存储文件的方式是将文件切分成多个数据块,这些数据块实际上是存储在DataNode节点中的,因此DataNode机器需要位置大量磁盘空间。它与NameNode保持不断的通信,DataNode在客户端或者NameNode的调度下,存储并检索数据块,对数据块进行创建、删除等操作,并且定期向NameNode发送所存储的数据块列表,每当DataNode启动时,它将负责把持有的数据块列表发送到NameNode机器中。
(3)Block(数据块)
每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位,HDFS同样也有块(block)的概念,它是抽象的块,而非整个文件作为存储单元,在Hadoop2.x版本中,默认大小是128M,且备份3份,每个块尽可能地存储于不同的DataNode中。按块存储的好处主要是屏蔽了文件的大小(在这种情况下,可以将一个文件分成N个数据块,存储到各个磁盘,就简化了存储系统的设计。为了数据的安全,必须要进行备份,而数据块非常适合数据的备份),提供数据的容错性和可用性。
(4)Rack(机架)
Rack是用来存储部署Hadoop集群服务器的机架,不同机架之间的节点通过交换机通信,HDFS通过机架感知策略,使NameNode能够确定每个DataNode所属的机架ID,使用副本存放策略,来改进数据的可靠性、可用性和网络带宽的利用率。
(5)Metadata(元数据)
元数据从类型上可分为三种信息形式,一是维护HDFS中文件和目录的信息,如文件名、目录名、父目录信息、文件大小、创建时间、修改时间等;二是记录文件内容,存储相关信息,如文件分块情况。副本个数、每个副本所在的DataNode信息等;三是用来记录HDFS中所有DataNode的信息,用于DataNode管理。
注意:元数据是用于描述和组织具体的文件内容!具体内容不是元数据。
1.2 HDFS的特点
1. 优点
(1)高容错。
HDFS可以由成百上千台服务器组成, 每个服务器存储文件系统数据的一部分。HDFS中的副本机制会自动把数据保存多个副本,DataNode节点周期性地向NameNode发送心跳信号,当网络发生异常,可能导致DataNode与NameNode失去通信,NameNode和DataNode通过心跳监测机制,发现DataNode宕机,DataNode中副本丢失,HDFS则会从其他DataNode上面的副本自动恢复,所以HDFS具有搞的容错性。
(2)流式数据访问
HDFS的数据处理规模比较大,应用程序一次需要大量的数据,同时这些应用程序一般都是批量地处理数据,而不是用户交互式处理,所以应用程序能以流的形式访问数据集,请求访问整个数据集要比访问一条记录更加高效。
(3)支持超大文件
HDFS具有很大的数据集,意在可靠的大型集群上存储超大型文件(GB、TB、PB级别的数据),它将每个文件切分成多个小的数据块进行存储,除了最后一个数据块以外的所有数据块大小都相同,块的大小可以在指定的配置文件中进行修改,在Hadoop2.x版本中默认大小是128M。
(4)高数据吞吐量
HDFS采用的是“一次写入,多次读取”这种简单的数据一致性模型,在HDFS中,一个文件经过创建、写入、关闭后,一旦写入就不能进行修改了,只能进行追加,这样保证了数据的一致性,也有利于提高吞吐量。
(5)可构建在廉价的机器上
Hadoop的设计对硬件的要求低,无须构建在昂贵的高可用性机器上,因为在HDFS设计中充分考虑到了数据的可靠性、安全性和高可用性。
2. 缺点
(1)高延迟
HDFS不适用于低延迟数据访问的场景,例如,毫秒级实时查询。
(2)不适合小文件存取场景
对于Hadoop系统,小文件通常定义为远小于HDFS的数据块大小(128M)的文件,由于每个文件都会产生各自的元数据,Hadoop通过NameNode来存储这些信息,若小文件过多,容易导致NameNode存储出现瓶颈。
(3)不适合并发写入
HDFS目前不支持并发多用户的写操作,写操作只能在文件末尾追加数据。
1.3 HDFS的架构和原理
1.3.1 HDFS存储架构

HDFS采用主从架构(Master/Slave架构)。HDFS集群分别是由一个NameNode和多个DataNode组成。其中,NameNode是HDFS集群的主节点,负责管理文件系统的命名空间以及客户端对文件的访问;DataNode是集群的从节点,负责管理它所在的节点上的数据存储。HDFS中的NameNode和DataNode两种角色各司其职,共同协调完成分布式的文件存储服务。
在NameNode内部是以元数据的形式,维护着两个文件,分别是FsImage镜像文件和EditLog日志文件。其中,FsImage镜像文件用于存储整个文件系统命名空间的信息,EditLog日志文件用于持久化记录文件系统元数据发生的变化。当NameNode启动的时候,FsImage镜像文件就会加载到内存中,然后对内存里的数据执行记录的操作,以确保内存所保留的数据处于最新的状态,这样就加快了元数据的读取和更新操作。
随着集群运行时间长,NameNode中存储的元数据信息越来越多,这样会导致EditLog日志文件越来越大。当集群重启时,NameNode需要恢复元数据信息,首先加载上一次的FsImage镜像文件,然后重复EditLog日志文件的操作记录,一旦EditLog日志文件很大,在合并的过程中就会花费很长的时间,而且如果NameNode宕机就会丢失数据。为了解决这个问题,HDFS中提供了Secondary NameNode(辅助名称节点),它并不是要取代NameNode也不是NameNode的备份,它的职责主要是周期性地把NameNode中的EditLog日志文件合并到FsImage镜像文件中,从而减少EditLog日志文件的大小,缩短集群重启时间,并且保证了HDFS系统的完整性。
NameNode存储的是元数据信息,元数据信息并不是真正的数据,真正的数据是存储在DataNode中。DataNode是负责管理它所在节点上的数据存储。DataNode中的数据块是以文件的类型存储在磁盘中,其中包括两个文件,一是数据本身(仅数据),而是每个数据块对应的一个元数据文件(包括数据长度,块数据校验和,以及时间戳)。
1.3.2 HDFS文件读写原理
Client(客户端)对HDFS中的数据进行读写操作,分别是Client从HDFS中查找数据,即为Read(读)数据;Client从HDFS中存储数据,即为Write(写)数据。
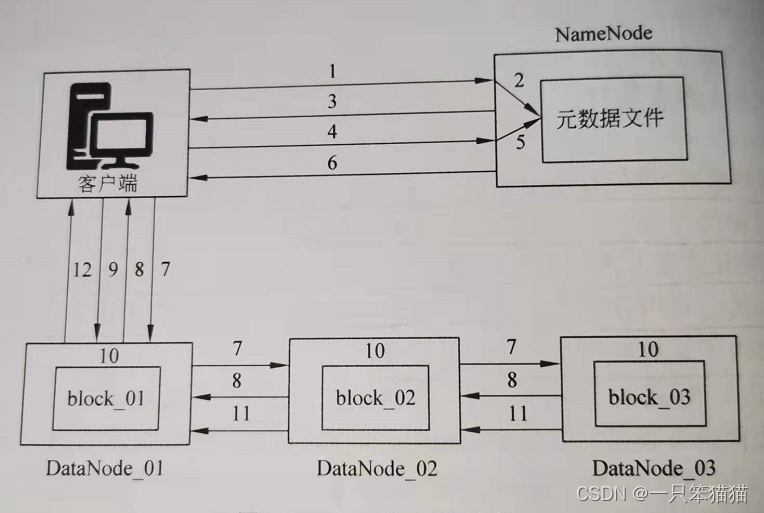
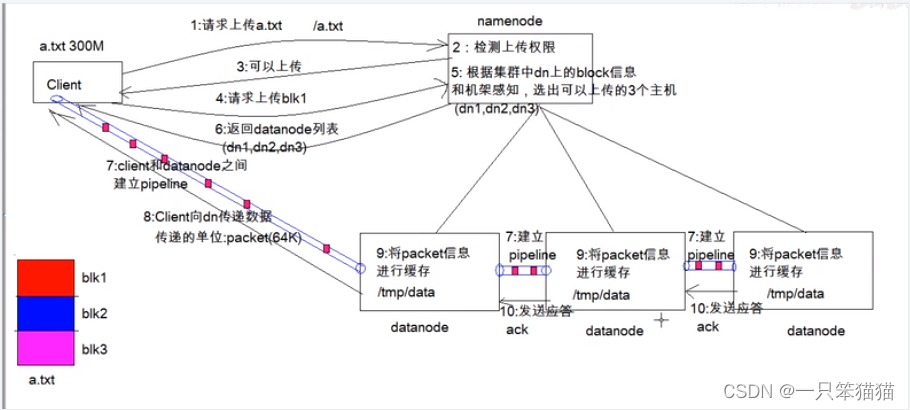
1. HDFS写数据原理
(1)客户端发起文件上传请求,通过RPC(远程过程调用)与NameNode建立通信。
(2)NameNode检查元数据文件的系统目录树。
(3)若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件。
(4)客户端请求上传第一个Block数据块,以及数据块副本的数量(可以自定义副本数量,也可以使用集群规划的副本数量)。
(5)NameNode检测元数据文件中DataNode信息池,找到可用的数据节点(dn1,dn2,dn3,dn4)。
(6)将可用的数据节点的IP地址返回给客户端。
(7)客户端请求2台节点中的一台服务器dn1,进行传送数据(本质上是一个RPC调用,建立管道Pipeline),dn1收到请求会继续调用服务器dn2,然后服务器dn2调用服务器dn3。
(8)DataNode之间建立Pipeline后,逐个返回建立完毕信息。
(9)客户端与DataNode建立数据传输流,开始发送数据包(数据是以数据包形式进行发送)。
(10)客户端向dn1上传第一个Block数据块,是以Packet为单位(默认64K)发送数据块。当dn1收到第一个Packet就会传给dn2,dn2传给dn3;dn1没传送一个Packet都会放入一个应答队列等待应答。
(11)数据被分割成一个个Packet数据包在Pipeline上一次传输,而在Pipeline反方向上,将逐个发送Ack(命令正确应答),最终由Pipeline中第一个DataNode节点dn1将Pipeline的Ack信息发送给客户端。
(12)DataNode返回给客户端,第一个Block块传输完成。客户端则会再次请求NameNode上传第二个Block块和第三个Block块到服务器上,重复上面的步骤,知道3个Block都上传完毕。
2. HDFS读取数据流程
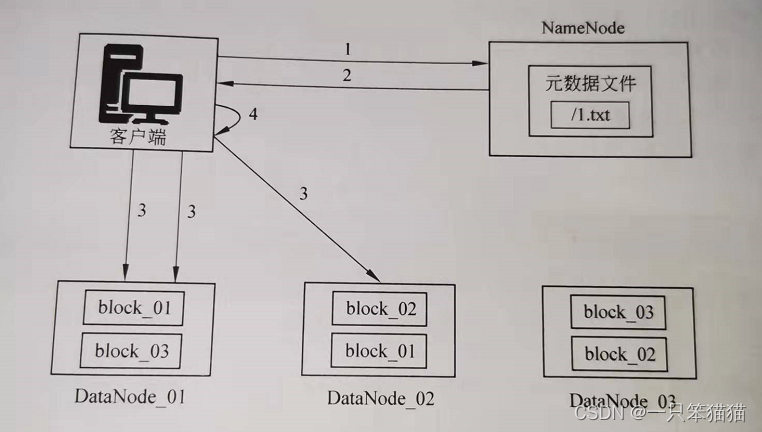
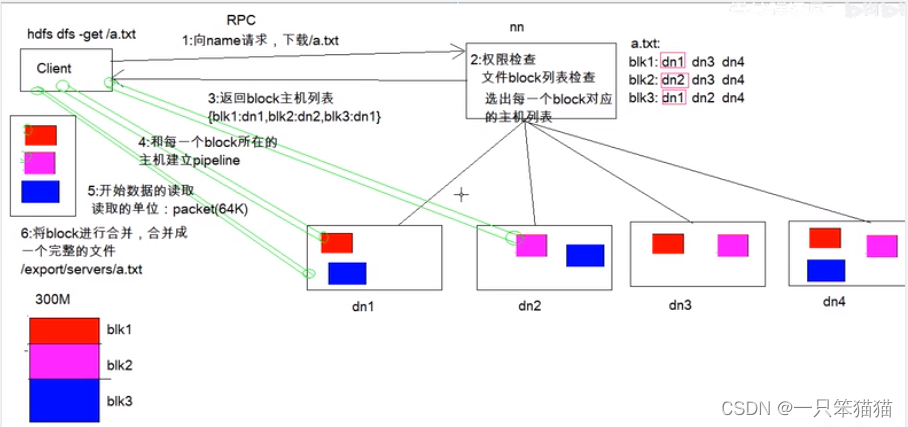
(1)客户端向NameNode发起RPC请求,来获取请求文件Block数据块所在的位置。
(2)NameNode检测元数据文件,会视情况返回部分Block块信息或者全部Block块信息,对于每个Block块,NameNode都会返回含有该Block副本的DataNode地址。
(3)客户端会选取排列靠前的DataNode来一次读取Block块(如果客户端本身就是DataNode,那么将从本地直接获取数据),每一个Block都会进行CheckSum(完整性验证),若文件不完整,则客户端会继续向NameNode获取下一批的Block列表,知道验证读取出来文件时完整的,则Block读取完毕。
(4)客户端会把最终读取出来所有的Block块合并成一个完整的最终文件。
1.4 HDFS的Shell操作
1.4.1.1 HDFS介绍
Shell在计算机科学中俗称“壳”,是提供给使用者界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。
HDFS Shell包含类似Shell的命令,示例如下:
hadoop fs <args>
hadoop dfs <args>
hdfs dfs <args>
上述命令中,hadoop fs 使用面最广,可以操作任何文件系统,如本地系统、HDFS等;hadoop dfs则主要针对HDFS,已经被hdfs dfs代替。
文件系统(FS)Shell包含了各种的类Shell的命令,可以直接与Hadoop分布式文件系统以及其他文件系统进行交互,如与Local FS、HTTP FS文件系统交互等。通过命令行的方式进行交互,具体操作命令(只列举用得多的命令)如下:
查看指定路径的目录结构:-ls
统计目录下所有文件大小:-du
移动文件:-mv
复制文件:-cp
删除文件/空白文件夹: -rm
上传文件:-put
查看文件内容:-cat
将源文件输出为文件格式:-text
创建空白文件夹:-mkdir
帮助:-help
1. ls命令
ls命名用于查看指定路径的当前目录结构,类似于 Linux 系统的 ls 命令,语法格式如下:
hadoop fs -ls [-d] [-h] [-R] <args>
其中,各项参数说明如下:
将目录显示为普通文件:-d
使用便于操作人员读取的单位信息格式:-h
递归显示所有子目录的信息:-R
示例代码如下:
$ hadoop fs -ls /
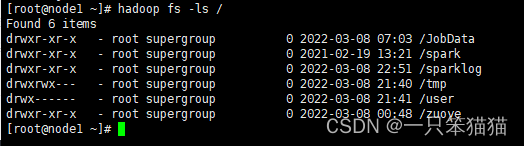
2. mkdir命令
mkdir 命令用于在指定路径下创建子目录,其中创建的路径可以采用 URI 格式进行指定,与 Linux 命令 mkdir 相同,可以创建多级目录,其语法格式如下:
hadoop fs -mkdir [-p] <paths>
其中 -p 参数表示创建子目录来先检查路径是否存在,如果不存在,则创建相应的各级目录。
示例代码如下:
$ hadoop fs -mkdir -p /itcast/hadoop

3. put命令
put 命令用于将本地系统的文件或文件夹复制到HDFS上,其语法格式如下:
hadoop fs -put [-f] [-p] <locationsrc> <det>
其中各项说明如下:
覆盖目标文件:-f
保留访问和修改时间、权限:-p
示例代码如下:
hadoop fs -put install.log /
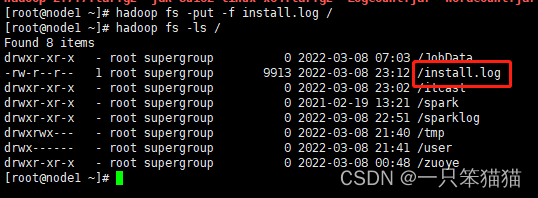
1.4.2 HDFS 的 Java API 操作
1.4.2.1 HDFS Java API 介绍
org.apache.hadoop.fs.FileSystem:它是通用文件系统的抽象基类,可以被分布式文件系统继承,它具有许多实现类,如 LocalFileSystem、DistributedFileSystem、FtpFileSystem 等。
org.apache.hadoop.fs.FileStatus:它用于向客户端展示系统中文件和目录的元数据,具体包括文件大小、块大小、副本信息、修改时间等。
org.apache.hadoop.fs.FSDataInputStream:文件输入流,用于读取 Hadoop 文件。
org.apache.hadoop.fs.FSDataOutputStream:文件输出流,用于写入 Hadoop 文件。
org.apache.hadoop.conf.Configuration:访问配置项,默认配置参数在 core-site.xml 中,用户可以添加相应的配置参数。
org.apache.hadoop.fs.Path:用于表示 Hadoop 文件系统中的一个文件或者一个目录的路径。
在 Java 中操作 HDFS ,首先需要创建一个客户端实例,主要涉及以下类:
Configuration:该类的对象封装了客户端或者服务器的配置,每个配置选项是一个键值对,通常情况下,Configuration 实例会自动加载 HDFS 的配置文件 core-site.xml ,从中获取 Hadoop 集群的配置信息。
FileSystem:该类的对象是一个文件系统对象,通过该对象的一些方法可以对文件进行操作,通常方法如下:
从本地磁盘复制文件到HDFS:copyFromLocalFile(Path src,Path dst)
从 HDFS 复制文件到本地磁盘:copyToLocalFile(Path src,Path dst)
建立子目录:mkdirs(Path f)
重命名文件或文件夹:rename(Path src,Path dst)
删除指定文件:delete(Path f)
1.4.2.2 案例——使用 Java API 操作 HDFS
笨猫猫用 eclipse 实现案例。
1、搭建项目环境
(1)创建Maven工程,如图所示。
(2)点击Maven Project后,点击Next,勾选Create a simple project,如图所示。
(3)勾选Create a simple project后,点击Next后,在Group Id 和 Artifact Id 输入相关内容后点击Finish,如图所示。
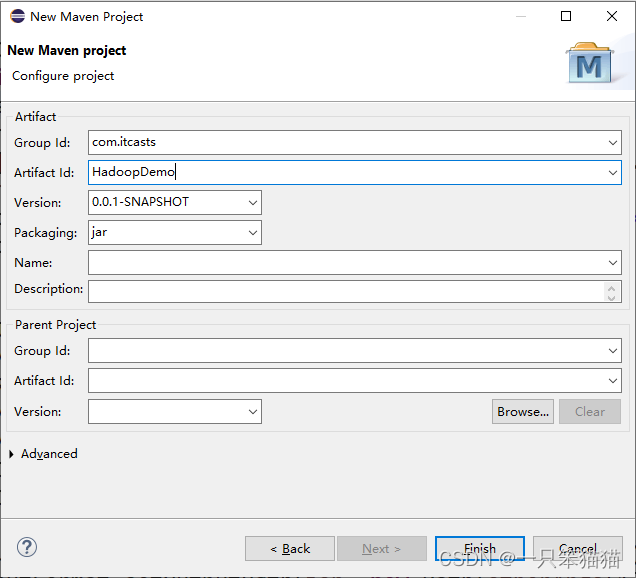
GroupId 是项目组织唯一的标识符,实际对应Java的包结构。
ArtifactId 就是项目的唯一标识符,实际对应项目的名称,就是项目根目录的名称
打包方式这里选择 jar 包方式即可,后续创建 Web 工程选择 war 包
2、对配置文件 pom.xml 编写项目所需要的依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itcast</groupId>
<artifactId>HadoopDemo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.10</version>
</dependency>
</dependencies>
</project>
注意:这里笨猫猫配置jdk.tools时所用的路径不是绝对路径,通过配置jdk的环境变量才可以使用${JAVA_HOME},不然会报路径不正确的问题,如果不配置环境变量的话,那就采用绝对路径,比如我的jdk1.8.0_161保存在 C:Program FilesJava 下,所以可以编写为:
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>C://Program Files/Java/jdk1.8.0_161/lib/tools.jar</systemPath>
</dependency>
当添加依赖完毕后,快捷键 ctrl + s 保存,Hadoop 相关 jar 包就会自动下载。部分 jar 包如图所示。
3、初始化客户端对象
首先在项目src文件夹下创建com.itcast.hdfsdemo 包,并在该包下创建HDFS_CRUD.java文件,编写Java测试类,构建Configuration和FileSystem对象,初始化一个客户端实例进行相应的操作,具体代码如下:
HDFS_CRUD.java
package com.itcast.hdfsdemo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.*;
import java.io.*;
import org.apache.hadoop.conf.Configuration;
import org.junit.Before;
import org.junit.Test;
public class HDFS_CRUD {
//初始化客户端对象
FileSystem fs = null;
@Before
public void init() throws Exception{
//构造一个配置参数对象,设置一个参数:要访问的HDFS的URI
Configuration conf = new Configuration();
//这里指定使用的是HDFS
conf.set("fs.defaultFS", "hdfs://node01:8020");
//通过如下的方式进行客户端身份的设置
System.setProperty("HADOOP_USER_NAME","root");
//通过FileSystem的静态方法获取文件系统客户端对象
fs=FileSystem.get(conf);
}
}
注意:可以在hadoop配置文件core-site.xml查看fs.defaultFS的配置信息。
上述代码中,@Before是一个用于在Junit单元测试框架中控制程序最先执行的注解,这里可以保证init()方法在程序中最先执行。
4、上传文件到HDFS
可以在HDFS_CRUD.java 文件中添加一个testAddFileToHdfs() 方法来演示本地文件上传到HDFS的示例,代码如下:
//上传文件到HDFS
@Test
public void testAddFileToHdfs() throws IOException{
//要上传的文件所在本地路径
Path src = new Path("D:/test.txt");
//要上传到HDFS的目标路径
Path dst = new Path("/testFile");
//上传文件方法
fs.copyFromLocalFile(src,dst);
//关闭资源
fs.close();
}
从上述代码可以看出,可以通过FileSystem对象的copyFromLocalFile() 方法,将本地数据上传到HDFS中。copyFromLocalFile() 方法接收两个参数,第一个参数是要上传的文件那所在的本地路径(需要提前创建),第二个参数是要上传到HDFS的目标路径。
5、从HDFS下载文件到本地
在HDFS_CRUD.java 文件中添加一个 testDownloadFileToLocal() 方法,来实现从HDFS中下载文件到本地系统的功能。具体代码如下:
//从HDFS下载文件到本地
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException,
IOException{
//下载文件
fs.copyToLocalFile(new Path("/testFile"),new Path("D:/"));
fs.close();
}
从上述代码可以看出,可以通过FileSystem对象的copyToLocalFile() 方法从HDFS 上下载文件到本地。copyToLocalFile() 方法接收两个参数,第一个参数是HDFS 上的文件路径,第二个参数是下载到本地的目标路径。
注意:如果在Windows平台开发HDFS项目时,得设置Hadoop开发环境。
直接使用下载的Linux平台下的Hadoop压缩包进行解压,然后在压缩包bin目录额外添加Windows相关依赖文件(winutils.exe、winutils.pdb、hadoop.dll),然后进行Hadoop环境变量配置(配置后重启电脑),这样运行代码后不会出现问题。
6、目录操作
在HDFS_CRUD.java 文件中添加一个testMkdirAndDeleteAndRename() 方法,实现目录的创建。删除。重命名的功能。具体代码如下:
//目录操作
//创建、删除、重命名文件
@Test
public void testMkdirAndDeleteAndRename() throws Exception{
//创建目录
fs.mkdirs(new Path("/a/b/c"));
fs.mkdirs(new Path("/a2/b2/c2"));
//重命名文件或文件夹
fs.rename(new Path("/a"), new Path("/a3"));
//删除文件夹,如果是非空文件夹,参数2必须给值true
fs.delete(new Path("/a2"),true);
}
从上述代码可以看出,可以通过调用FileSystem的mkdirs() 方法创建新的目录;调用delete() 方法可以删除文件夹,delete() 方法接收两个参数,第一个参数表示要删除的文件夹路径,第二个参数用于设置是否递归删除目录,其值为 true 或 false ,true 表示递归删除,false 表示非递归删除;调用rename() 方法可以对文件或文件夹重命名,rename() 接收两个参数,第一个参数代表需要修改的目标路径,第二个参数代表新的命名。
7、查看目录中的文件信息
在HDFS_CRUD.java 文件中添加一个 testListFiles() 方法,实现查看目录中所有文件的详情信息功能,代码如下:
//查看目录中的文件信息
//查看目录信息,只显示文件
@Test
public void testListFiles() throws FileNotFoundException,
IllegalArgumentException,IOException{
//获取迭代器对象
RemoteIterator<LocatedFileStatus>listFiles=fs.listFiles(
new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
//打印当前文件名
System.out.println(fileStatus.getPath().getName());
//打印当前文件块大小
System.out.println(fileStatus.getBlockSize());
//打印当前文件权限
System.out.println(fileStatus.getPermission());
//打印当前文件内容长度
System.out.println(fileStatus.getLen());
//获取该文件块信息(包含长度,数据块,datanode的信息)
BlockLocation[] blockLocations=
fileStatus.getBlockLocations();
for (BlockLocation b1 : blockLocations) {
System.out.println("block-length:"+b1.getLength()+
"--"+"block-offset:"+b1.getOffset());
String[] hosts = b1.getHosts();
for(String host : hosts) {
System.out.println(host);
}
}
System.out.println("-----------分割线-----------");
}
}
在上述代码中,可以调用 FileSystem 的 listFiles() 方法获取文件列表,其中第一个参数表示需要获取的目录路径,第二个参数表示的是是否递归查询,这里传入参数为true,表示需要递归查询。
最后
以上就是沉默黄豆最近收集整理的关于HDFS分布式文件系统HDFS分布式文件系统学习目标:学习内容:1.2 HDFS的特点的全部内容,更多相关HDFS分布式文件系统HDFS分布式文件系统学习目标:学习内容:1.2内容请搜索靠谱客的其他文章。








发表评论 取消回复