目录
Hadoop体系介绍
HADOOP快速入门
什么是HADOOP
HADOOP产生背景
HADOOP在大数据、云计算中的位置和关系
国内外HADOOP应用案例介绍
离线数据分析流程介绍
需求分析
1. 集群环境准备
1.1 修改主机名
1.2 配置IP地址
1.3 关闭防火墙
1.4 添加内网域名映射
1.5 同步网络时间
1.6 安装JDK
先不做1.7和1.8
1.7 克隆虚拟机(先做1.8)
1.8 配置SSH免密登录(root用户)
2.Hadoop分布式集群搭建
2.2.1 集群规划
2.2.2 安装包准备
2.2.3 主要配置文件
2.2.4分发到从节点
2.2.5配置Hadoop系统环境变量
回去做1.7和1.8
2.2.6 启动Hadoop集群
Hadoop体系介绍
HADOOP快速入门
什么是HADOOP
1.HADOOP是apache旗下的一套开源软件平台
2.HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
3.HADOOP的核心组件有
A.HDFS(分布式文件系统)
B.YARN(运算资源调度系统)
C.MAPREDUCE(分布式运算编程框架)
4.广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
HADOOP产生背景
1.HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2.2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
分布式文件系统(GFS),可用于处理海量网页的存储
分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期
HADOOP在大数据、云计算中的位置和关系
1.云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
2.现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3.而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
国内外HADOOP应用案例介绍
1、HADOOP应用于数据服务基础平台建设
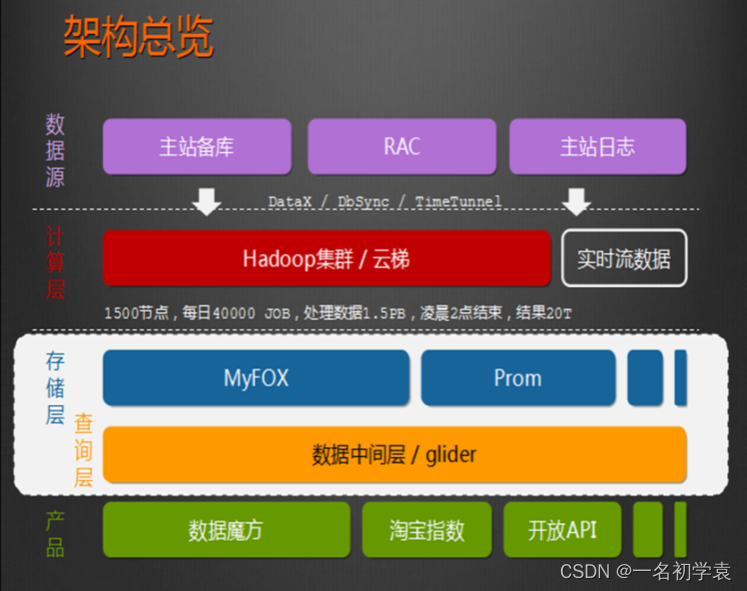
- HADOOP用于用户画像
通过访问网页亦或者是点击某点的频率确定兴趣爱好,推送相关服务,提高成交额度

- HADOOP用于网站点击流日志数据挖掘
从网点上 套索数据
HADOOP生态圈以及各组成部分的简介
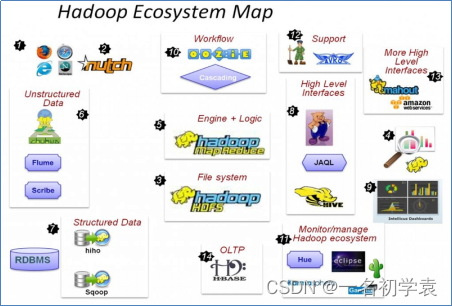
重点组件:
HDFS:分布式文件存储系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架(类似于kettle)
Sqoop:数据导入导出工具
Flume:日志数据采集框架
离线数据分析流程介绍
一个应用广泛的数据分析系统:“web日志数据挖掘”
思维导图 脑图 驾驶舱 仪表盘
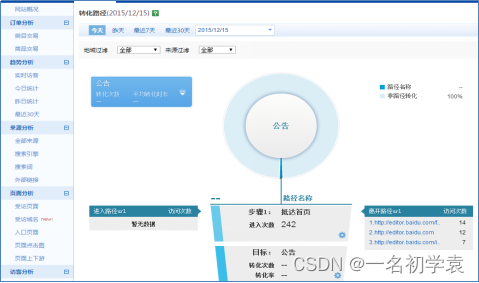
需求分析
案例名称
网站或APP点击流日志数据挖掘系统
一般中型的网站(10W的PV以上),每天会产生1G以上Web日志文件。大型或超大型的网站,可能每小时就会产生10G的数据量。
具体来说,比如某电子商务网站,在线团购业务。每日PV数100w,独立IP数5w。用户通常在工作日上午1000和下午1500访问量最大。日间主要是通过PC端浏览器访问,休息日及夜间通过移动设备访问较多。网站搜索浏量占整个网站的80%,PC用户不足1%的用户会消费,移动用户有5%会消费。
对于日志的这种规模的数据,用HADOOP进行日志分析,是最适合不过的了。
案例需求描述
“Web点击流日志”包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率、访客的来源信息,访客的终端信息等。
数据来源
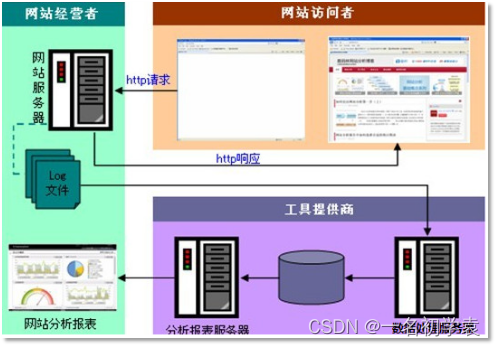
本案例的数据主要由用户的点击行为记录
获取方式:在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。
形如:
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
数据处理流程
流程图解析
整体流程如下:
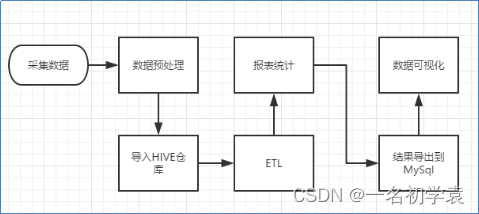
1)数据采集:定制开发采集程序,或使用开源框架FLUME
2)数据预处理:定制开发mapreduce程序运行于hadoop集群
3)数据仓库技术:基于hadoop之上的Hive
4)数据导出:基于hadoop的sqoop数据导入导出工具
5)数据可视化:定制开发web程序或使用kettle等产品
6)整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
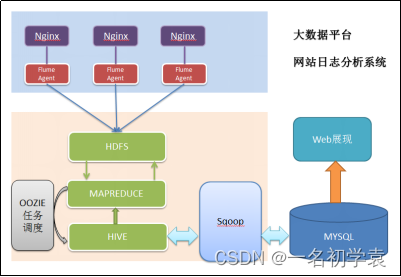
项目技术架构图
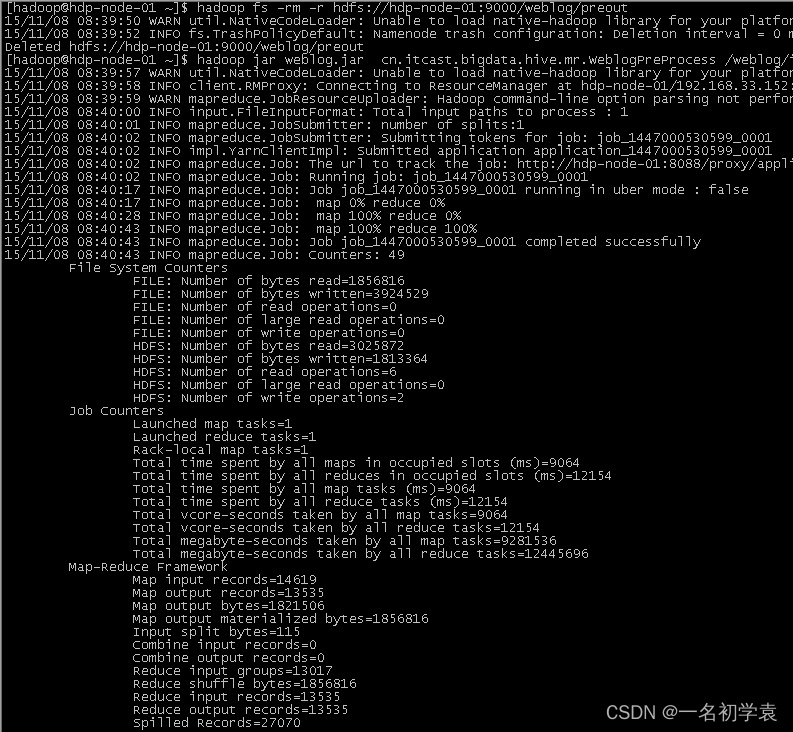
项目相关截图
- Mapreudce程序运行
- 在Hive中查询数据
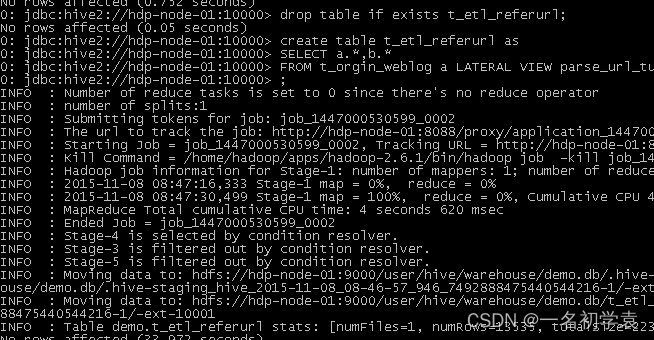
- 将统计结果导入mysql
./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-0
项目最终效果
经过完整的数据处理流程后,会周期性输出各类统计指标的报表,在生产实践中,最终需要将这些报表数据以可视化的形式展现出来,本案例采用web程序来实现数据可视化
效果如下所示:

1. 集群环境准备
1.1 修改主机名
在超级管理员root用户下,修改主机名,使用命令:
1.vi /etc/sysconfig/network
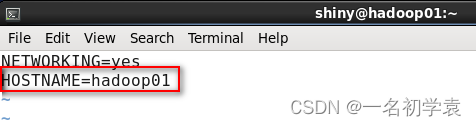
2.vi /etc/hostname

修改完成之后,按Esc热键进入末行模式,输入“:wq”保存退出。
1.2 配置IP地址
在root用户下,对配置文件进行如下修改,使用命令:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
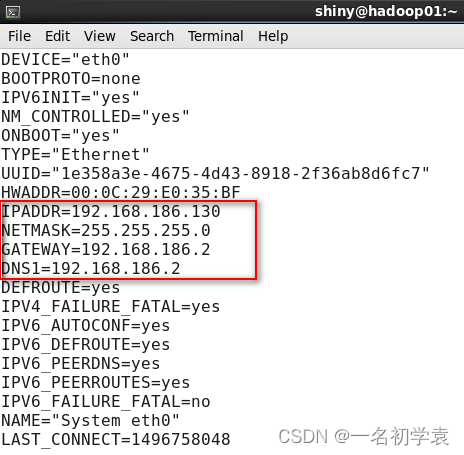
修改完成之后,按Esc热键进入末行模式,输入“:wq”保存退出。
重启网络服务,使用命令:
service network restart
1.3 关闭防火墙
在root用户下,使用命令:
service firewalld stop
systemctl disalbe firewalld
1.4 添加内网域名映射
在root用户下,修改配置文件,使用命令:
vi /etc/hosts
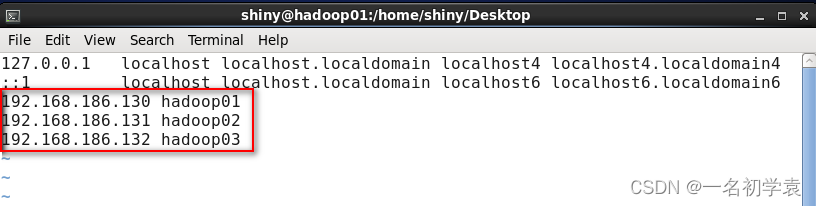
1.5 同步网络时间
ntpdate cn.pool.ntp.org
1.6 安装JDK
准备软件:jdk-8u151-linux-x64.tar.gz
把软件传到 Linux 服务器上去;
把软件解包解压缩到/home/tom/apps目录下,使用命令:
tar -zxvf jdk-8u151-linux-x64.tar.gz -C /gs
配置环境变量,使用命令:
vim ~/.bashrc
执行source ~/.bashrc命令让配置文件生效。
检测 JDK 是否安装成功,使用命令: java –version
先不做1.7和1.8
1.7 克隆虚拟机(先做1.8)
1. 首先将需要克隆的虚拟机关闭,右键单击虚拟机名称“hadoop01”,在下拉列表中选择“管理”,再选择“克隆”:
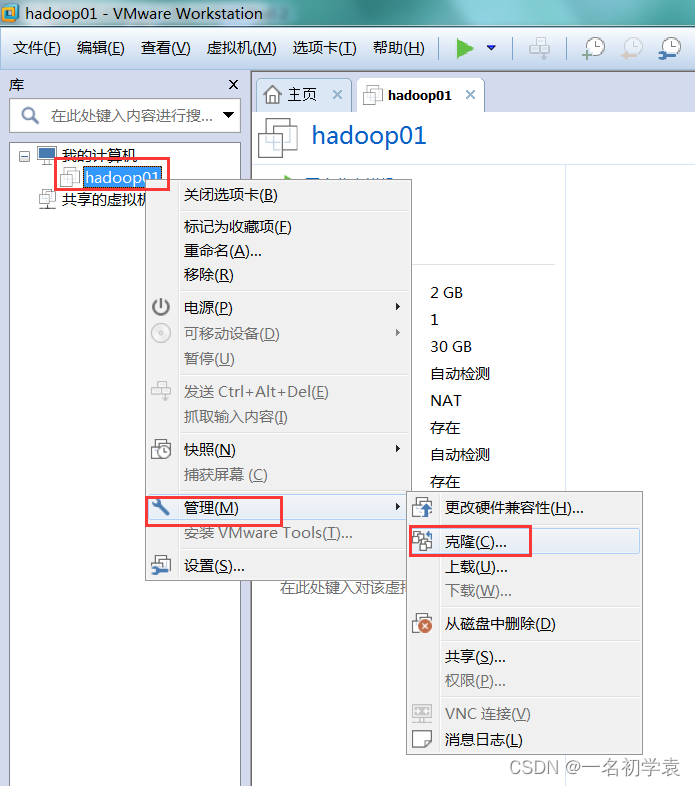
- 点击“克隆”之后,出现如下界面,直接点击“下一步”
- 选择默认,直接点击“下一步”:
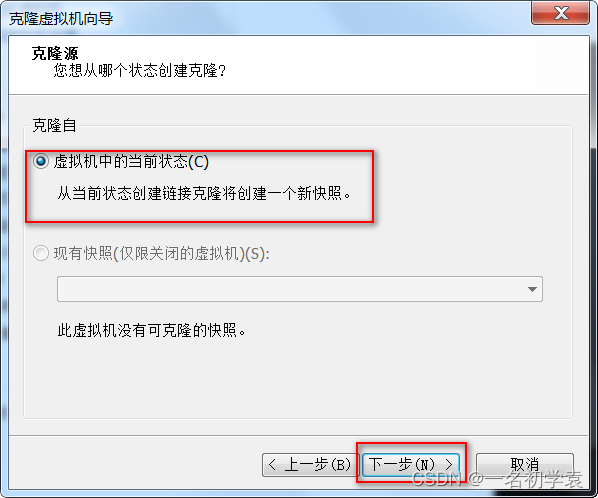
- 选择“创建链接克隆”,点击“下一步”:
- 修改虚拟机名称,这里我修改为“hadoop02”,点击“浏览”修改虚拟机存放的位置,修改完成点击“完成”即可:
- 点击“完成”之后,进入克隆状态,等待克隆完成:
- 克隆完成,点击“关闭”:
- 这时发现在VMware12的左侧“我的计算机”下,显示克隆完成的虚拟机,因为之前我定义的“虚拟机名称”是“hadoop02”,所以这里显示的也是“hadoop02”:
- 因为克隆的虚拟机“hadoop02”与“hadoop01”的所有设置都是完全一模一样的,所以需要修改主机名和IP地址,点击“开启虚拟机”:
- 首先,我们来修改网卡名称,进入超级用户root用户下,修改配置文件/etc/udev/rules.d/70-persistent-net.rules,执行以下命令
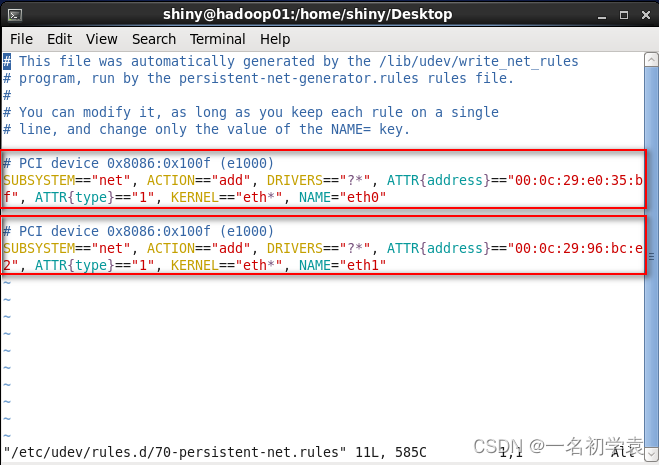
- 进入此配置文件后,发现有两个网卡,第一个红框中的网卡为“hadoop01”的网卡,所以将其删除,将第二个网卡的NAME从“eth1”修改为“eth0”:
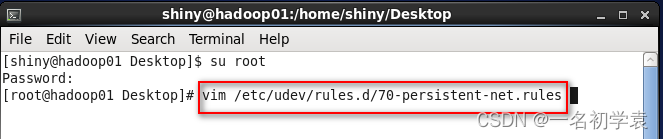
- 修改完成,如下图所示,之后按Esc热键进入末行模式,输入“:wq”保存退出即可:
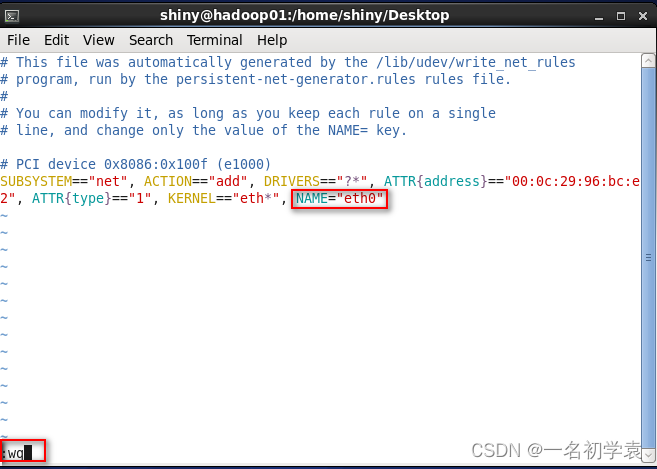
- 其次,修改网卡的相关配置信息,依旧使用超级用户root,进入/etc/sysconfig/network-scripts/ifcfg-ens33中,如下图所示:
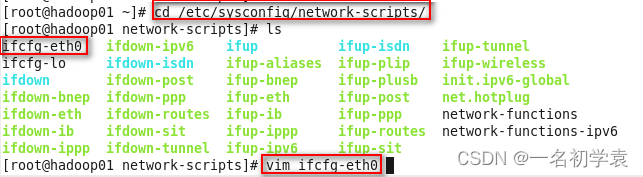
- 将红框中的“UUID”、“HWADDR”这两行删掉,重新分配一个IP地址给“IPADDR”,我这里将其修改为“192.168.186.131”:
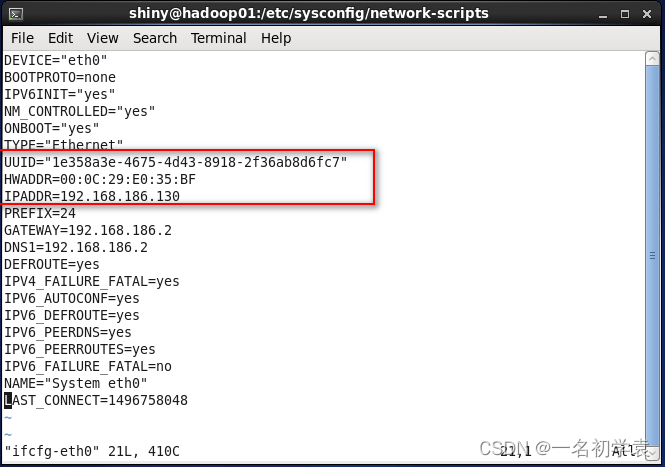
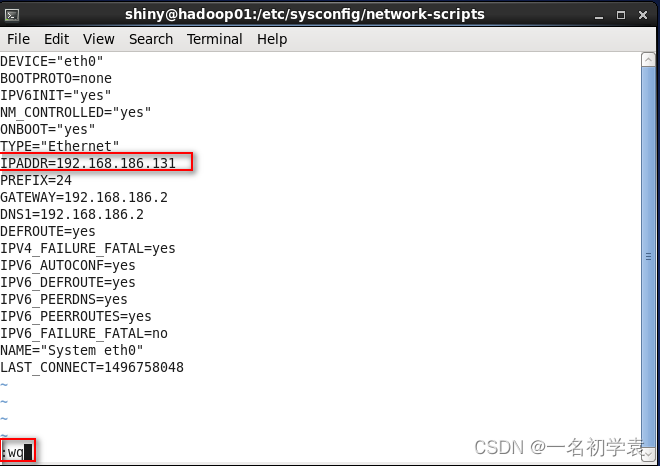
- 修改完成,如下图所示,之后按Esc热键进入末行模式,输入“:wq”保存退出,这样我们的网络就修改成功了!!!:
- 123456
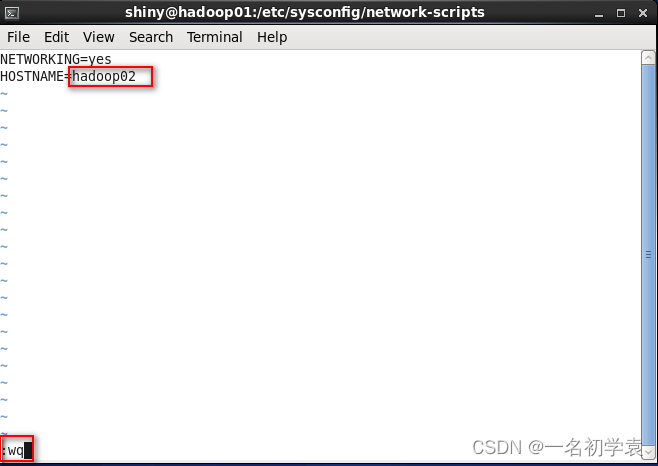
- 最后修改一下主机名,进入/etc/sysconfig/network下进行修改,命令如下:
![]()
- 进入此配置文件后,将“HOSTNAME”修改为“hadoop02”,这个名称可以随意修改,最好不要和之前已存在的虚拟机的主机名一样, 最后按Esc热键进入末行模式,输入“:wq”保存退出即可
- 修改完成后,重启虚拟机即可。使用命令“hostname”查看主机名已经修改为“hadoop02”,使用命令“ifconfig”查看网卡名称已经修改为“eth0”,IP地址已经修改为“192.168.186.131”,具体操作如下所示:
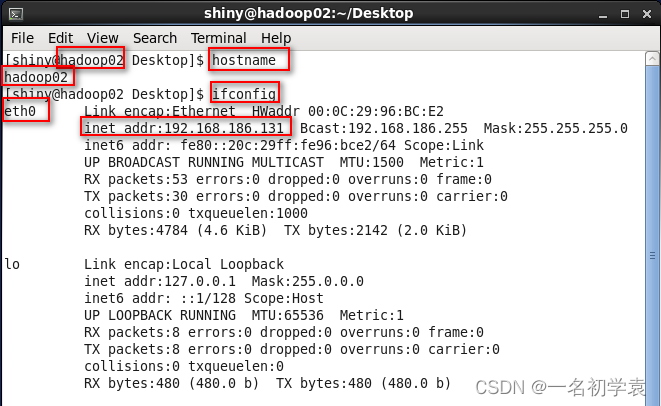
OK!大功告成!!!
1.8 配置SSH免密登录(root用户)
在3台虚拟机开启的情况下,使用命令:
ssh-keygen
之后会发现在~/.ssh目录下生成了公钥文件;
先进入id_rsa.pub所在的目录
复制公钥文件到授权列表文件 authorized_keys 中,使用命令:
cp id_rsa.pub authorized_keys
修改授权列表文件权限,使用命令:
chmod 600 ./authorized_keys
先进入家目录
将该授权列表文件 .ssh 复制到hadoop02和hadoop03上,使用命令:
scp .ssh hadoop02:$PWD
scp .ssh hadoop03:$PWD
验证免密登录是否设置成功,如下所示:
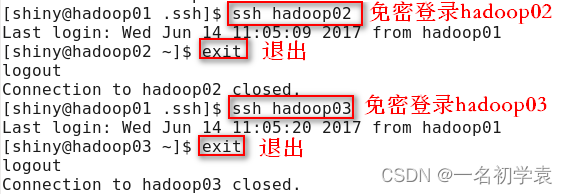
2.Hadoop分布式集群搭建
2.2.1 集群规划
集群规划:准备3台虚拟机,在3个节点上都安装DataNode,设置副本数为2

2.2.2 安装包准备
准备安装包:hadoop-2.6.5-centos-6.7.tar.gz;
上传到 Linux 服务器上去;
把软件解包解压缩到/gs目录下,使用命令:
tar -zxvf hadoop-2.6.5-centos-6.7.tar.gz -C /gs
2.2.3 主要配置文件
配置环境变量 hadoop-env.sh
环境变量文件hadoop-env.sh中,只需要配置JDK的路径
export JAVA_HOME=java的主目录
配置核心组件 core-site.xml
将下面的代码添加到<configuration></configuration>中间:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/tom/hadoopData/temp</value>
</property>
配置文件系统 hdfs-site.xml
将下面的代码加入<configuration></configuration>中间:
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/tom/hadoopData/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/tom/hadoopData/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop02:50090</value>
</property>
Vi
配置计算框架 mapred-site.xml
复制文件,因为目录下有mapred-site.xml.template
cp mapred-site.xml.template mapred-site.xml
将下面的代码加入<configuration></configuration>中间:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置文件系统 yarn-site.xml
将下面的代码加入<configuration></configuration>中间:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置slaves文件
将内容修改为:
hadoop01
hadoop02
hadoop03
2.2.4分发到从节点
分别分发到从节点hadoop02和hadoop03上,使用命令:
scp -r /home/hadoop01/apps/hadoop-2.6.5 hadoop02:$PWD
scp -r /home/hadoop01/apps/hadoop-2.6.5 hadoop03:$PWD
2.2.5配置Hadoop系统环境变量
需要在三个节点上都进行配置,使用命令:
vim ~/.bashrc
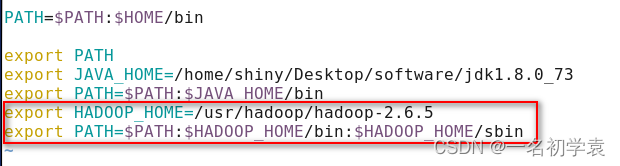
让配置文件立即生效,使用命令:
source ~/.bashrc
回去做1.7和1.8
2.2.6 启动Hadoop集群
先关所有服务器的防火墙,避免通讯失败
service firewalld stop
systemctl disable firewalld
初始化文件系统
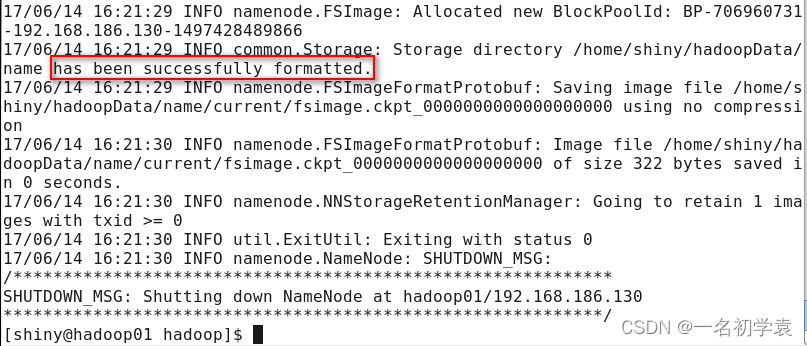
该操作需要在主节点hadoop01上执行,使用命令:
hadoop namenode -format
看到下图的打印信息表示初始化成功,如果出现Exception/Error,则表示出问题:
启动HDFS
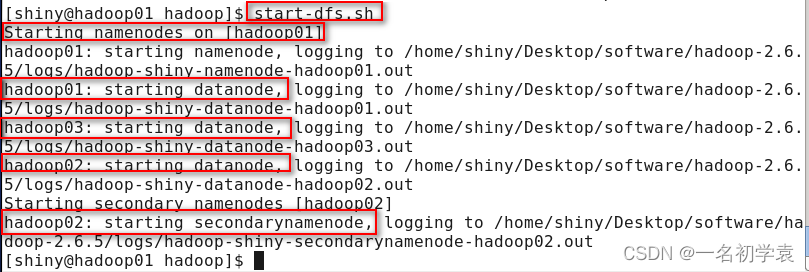
使用命令:
start-dfs.sh
结果:
在主节点hadoop01上启动了NameNode守护进程
在3个节点上都启动了DataNode守护进程
在配置的一个特定节点hadoop02上启动SecondaryNameNode 进程
启动YARN
使用命令:
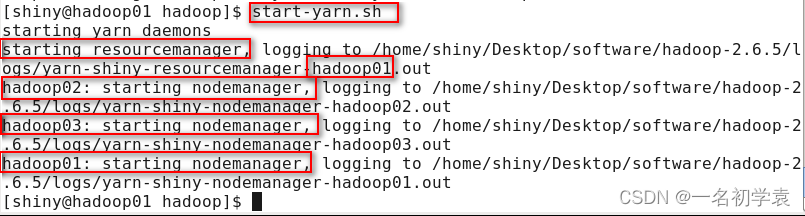
start-yarn.sh
结果:
在主节点hadoop01上启动了ResourceManager守护进程
在3个节点上都启动了NodeManager守护进程
查看进程是否启动
在hadoop01的终端执行jps命令,在打印结果中会看到5个进程,分别是ResourceManager、NodeManager、Jps、DataNode和NameNode,如果出现了这5个进程表示主节点进程启动成功。如下图所示:

在hadoop02的终端执行jps命令,在打印结果中会看到4个进程,分别是NodeManager、Jps、SecondaryNameNode和DataNode,如果出现了这4个进程表示从节点进程启动成功。如下图所示:

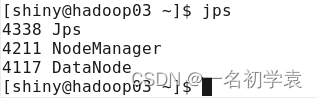
在hadoop03的终端执行jps命令,在打印结果中会看到3个进程,分别是Jps、NodeManager和DataNode,如果出现了这3个进程表示从节点进程启动成功。如下图所示:
Web UI查看集群是否成功启动
查看HDFS集群信息是否正常,web管理界面地址是 http://192.168.186.130:50070
查看MapReduce运行状态信息是否正常,web管理界面地址 是 http://192.168.186.130:8088
测试集群是否安装成功
检测HDFS是否成功启动,使用命令:
hadoop fs -ls /
检测YARN集群是否启动成功,使用提交MapReduce例子程序的方法进行测试,使用命令:
cd /usr/hadoop/hadoop-2.6.5/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.6.5.jar pi 10 10
注:若是第一次有的进程没有启动成功,可以使用单步启动,使用命令:
hadoop-daemon.sh start datanode
hadoop-daemon.sh start namenode
hadoop-daemon.sh start secondarynamenode
yarn-daemon.sh start nodemanager
yarn-daemon.sh start resourcemanager
最后
以上就是怡然秋天最近收集整理的关于Hadoop介绍与配置环境Hadoop体系介绍1. 集群环境准备2.Hadoop分布式集群搭建的全部内容,更多相关Hadoop介绍与配置环境Hadoop体系介绍1.内容请搜索靠谱客的其他文章。








发表评论 取消回复