爬虫简单来说就是爬取网页页面信息。在谈基础编写爬虫程序之前,首先了解一些计算机网页基础知识:简单来说,生活中的快递的订单跟踪,从提交订单的发货地到接收到包裹的目的地,中间的每一环都是信息的传递节点。我们的计算机网络的信息传递也是由多个不同功能的节点组成的。抽象来说,OSI模型在每一层有不同的标示,信息传递的时候在每一层都打上戳,不同层次之间通过信息加工进行传递。埋点用来记录用户的网页使用行为。
网站是什么?输入浏览器地址,得到网页信息。网页显示的东西包括图片,HTML, CSS,JS等。HTML(给节点打标签;manipulate),CSS(操作节点的一些属性;manipulate),JS(生成或者插入节点,也可以操作节点的某些性质)的代码告诉浏览器解析代码,如何呈现网页信息(图片,颜色,大小,排版)。之后再详细说明。图片来源于网络
静态网站和动态网站:动态网站是通过程序从数据库提取程序,程序再生成HTML文件,最后交给浏览器去解析;静态网站直接通过不同请求读取固定的一些HTML文件。对于两种网站的选择,要根据工程任务来定;没有好坏之分,看的是适合不适合。对于比较少的网页个数,静态网站的工作量不大;对于需要执行大量网页操作的任务,应用动态网站更合适。
网站的信息如何传输?用户输入网站之后,http 发送request到 web server , web server 接收到请求,返回响应http response,用户接收到并解析响应。https://www.programmersought.com/article/68784569117/www.programmersought.com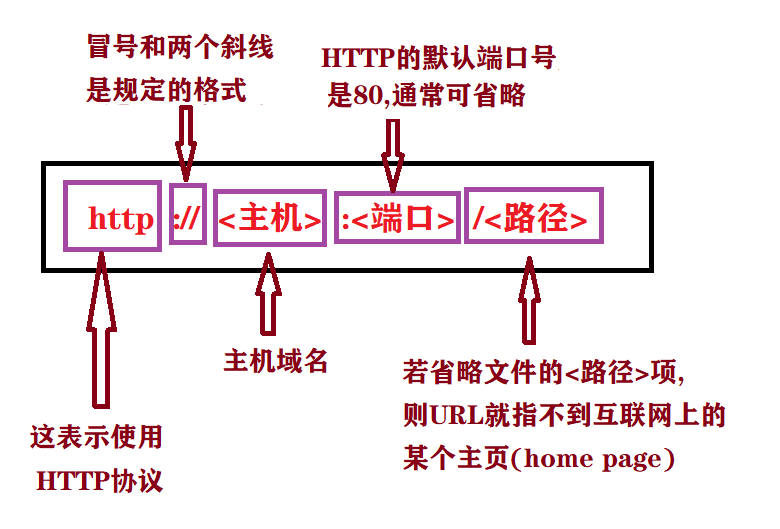 Take you to understand the HTTP protocolTake you to understand the HTTP protocolwww.programmersought.com图片来自网络
Take you to understand the HTTP protocolTake you to understand the HTTP protocolwww.programmersought.com图片来自网络
python爬虫里面用到的库有:
Request:用来爬取页面信息。Requests: HTTP for Humans™requests.readthedocs.io
BeautifulSoup中的一部分代码:Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。We called him Tortoise because he taught us.www.crummy.com
这些包都需要提前安装,安装code都是 pip install requests/bs4
import requests
from bs4 import BeautifulSoup
开始爬虫,第一步,首先确定爬虫的页面:
url='输入特定网址' #输入需要爬取信息的网页
response = requests.get(url)# 命名获取的信息
response #显示获取的结果
response.text# 显示获取的内容
soup=BeautifulSoup(response.text,'lmxl') # 文本通过lxml的形式解析出来,记得一定要加上这个形式/使用BeautifulSoup解析这段代码,能够得到一个BeautifulSoup的对象,并能按照标准的缩进格式的结构输出
接下来要输入筛选条件了,这个项目是找所有图片后面存在的超链接:
link_div = soup.find_all('div',class_='pic_panel') #在这里根据html的信息
links=[div.a.get('href') for dive in link_div]#把仅要提取的东西提取出来
links
整理一下上述代码,可以定义一个函数
def get_links(url)
response = requests.get(url)# 命名获取的信息
soup=BeautifulSoup(response.text,'lmxl') # 文本通过lxml的形式解析出来
link_div = soup.find_all('div',class_='pic_panel') #在这里根据html的信息
links=[div.a.get('href') for dive in link_div]# 设置提取的链接
return links
定义函数的好处是,之后可以直接调用函数,对其他的相似结构的页面进行处理。
对于上述的链接,可以定义一个函数
def get_url(url)
response = requests.get(url)# 命名获取的信息
soup=BeautifulSoup(response.text,'lmxl') # 文本通过lxml的形式解析出来
return soup
两个函数在一起使用,优化代码的结果为:
def get_links(url)
soup=get_url(url)
link_div = soup.find_all('div',class_='pic_panel') #在这里根据html的信息
links=[div.a.get('href') for dive in link_div]# 设置提取的链接
return links
对于一个新的student_url
soup=get_url(student_url)
links=get_links(student_url)
要提取其他的信息,继续重复代码结构:
name=soup.find('',class_='total').text#单引号里填入位置信息
age=soup.find('',class_='total').text.strip()#单引号里填入位置信息
other_info=soup.find('',class_='total').text.strip()#单引号里填入位置信息
最后
以上就是飞快盼望最近收集整理的关于python爬虫需要对象编程吗_python编写爬虫程序--简单程序入手的全部内容,更多相关python爬虫需要对象编程吗_python编写爬虫程序--简单程序入手内容请搜索靠谱客的其他文章。








发表评论 取消回复